文章目录
- 一、背景
- 二、方法
- 2.1 Enhancing Input Resolution
- 2.2 Multi-level Description Generation
- 2.3 Multi-task Training
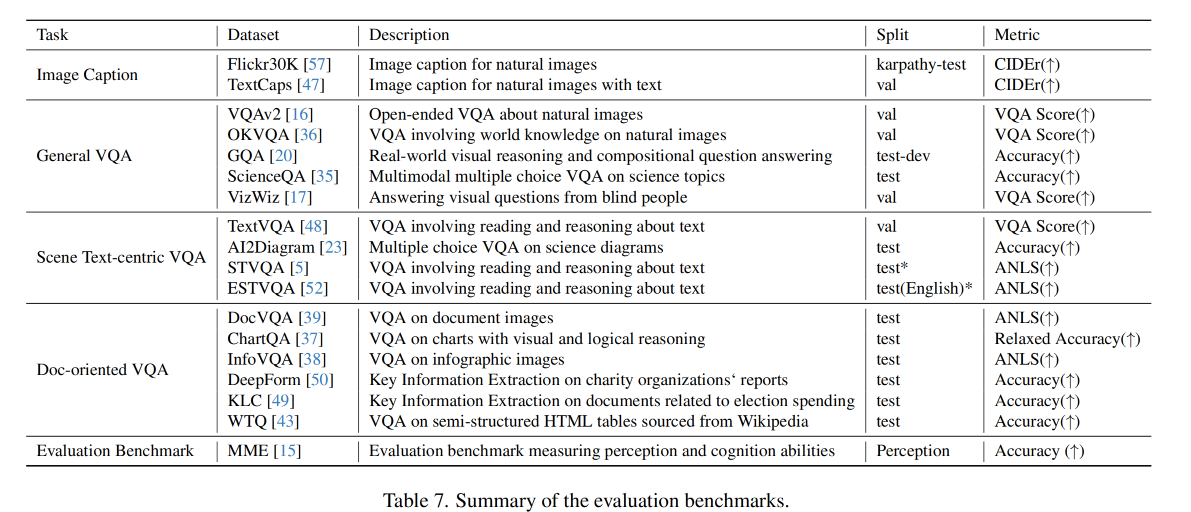
- 三、效果
- 3.1 Image Caption
- 3.2 General VQA
- 3.3 Scene Text-centric VQA
- 3.4 Document-oriented VQA
- 3.5 消融实验
- 3.6 可视化
论文:Monkey : Image Resolution and Text Label Are Important Things for Large Multi-modal Models
代码:https://github.com/Yuliang-Liu/Monkey
出处:华中科大
时间:2024.02
贡献:
- 模型支持大于 1344x896 分辨率的输入,无需预训练。比在大型语言模型(LMMs)中常用的 448x448 分辨率大了很多,能更好的识别和理解小目标或密集目标或密集文本
- 模型有很好的上下文关联。作者引入了一种多级描述生成的方法,该方法能够提高模型捕捉不同目标之间关系的能力
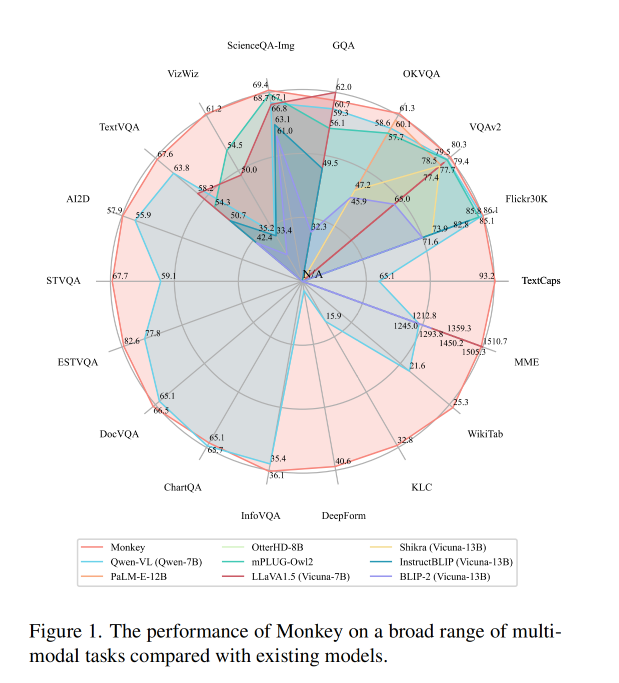
- Monkey 模型在多个测评数据集上都有很好的表现。作者在 18 个数据集上进行了测试,Monkey 模型在图像标题生成、常规视觉问题问答、以场景文本为中心的视觉问答、以文档为导向的视觉问答等任务上的表现都很好
一、背景
LMM 模型能够处理多种不同类型的数据,包括图像、文本、语音等不同模态,对于图像-文本多模态模型,LMM 模型的训练中,图片的分辨率越高,模型能够检测或捕捉到的视觉细节就越丰富,对目标的识别,目标间关系的捕捉,图像中上下文信息的捕捉就更有利,但对于模型来说,很难处理多种不同的分辨率或不同质量的图像,尤其在复杂的场景中更难。
现有的解决方案包括使用具有更大输入分辨率的预训练视觉模块(如LLaVA1.5 [29]),并通过逐渐增加训练过程中的分辨率(如Qwen-VL [3]、PaLI-3 [10]和PaLI-X [9])
但这些方法需要大量的训练资源,并且仍然难以很好的处理更大图像尺寸的图像
为了充分利用大输入分辨率的优势,很重要的一点是图像要有很详细的相关描述,这可以增强模型对图像-文本关系的理解,但是像COYO [6] 和 LAION [45] 通常只有简单的标题,难以满足需求。
Monkey 是什么:一个资源高效的方法,用于提升 LMM 的输入分辨率
- 一般的方法:直接对 ViT 进行插值来增加输入分辨率,但这样做效率不高
- Monkey 使用的方法:将大分辨率的输入图片使用滑动窗口切分成小的 patches,每个 patch 独立的输入静态(不训练)的 visual encoder,编码器经过 LoRA(Low-Rank Adaptation)调整,和一个可训练的视觉重采样器增强,增强了其功能。
- 这种方式利用了现有的大型多模态模型,避免了从头开始进行广泛预训练的需要。通常这些编码器是在较小的分辨率(例如448×448)上训练的,从头开始训练成本很高。通过将每个图像块调整到编码器支持的分辨率,可以维持原有的训练数据分布。
- 为了更好的利用大分辨率输入,作者还提出了一个自动的多级描述生成的方法,这个方法能够无缝结合多个生成器的简介,来为图片生成高质量、丰富的标题数据,利用的模型如下,作者使用这些模型生成了全面且分层的标题,能够捕捉到广泛的视觉细节:
- BLIP2:对图像-文本理解很细腻
- PPOCR:强大的 OCR 识别模型
- GRIT:擅长粒度化的图像-文本对齐
- SAM:用于语义对齐的动态模型
- ChatGPT:有很好的上下文理解和语言生成能力
Vision Transformer (ViT) 使用了 Transformer 架构来处理图像数据。在深度学习中,提升模型处理的图像分辨率通常可以帮助模型捕捉到更细粒度的特征,这在某些任务中可能会提高模型的性能。然而,直接在高分辨率的图像上训练模型会大大增加计算成本和内存需求。
为了解决这个问题,通常会采取以下几种方法之一:
-
渐进式训练:这种方法首先在低分辨率的图像上训练模型,然后逐步增加图像的分辨率。这样可以在早期阶段以较低的计算成本训练模型,并在模型逐渐适应更高分辨率的图像时增加细节。
-
插值:在某些情况下,研究人员可能会选择在预训练的模型基础上,对输入图像进行插值以提高其分辨率。这样做的目的是利用模型在低分辨率图像上学到的知识,并通过插值来适应更高分辨率的图像。插值方法可以是最近邻插值、双线性插值、双三次插值等。
-
多尺度训练:这种方法同时使用不同分辨率的图像来训练模型。模型在从不同分辨率的图像中学习特征时,可以更好地泛化到新的、更高分辨率的图像上。
对于 Vision Transformer (ViT) 而言,由于其结构是将图像分割成多个小块(patch)然后输入到 Transformer 中,因此提升分辨率时需要考虑如何调整这些小块的大小和数量。通过对 ViT 进行插值,可以在不显著改变模型架构的情况下,适应更高分辨率的图像,这是一种相对简单且有效的方法来提升模型处理高分辨率图像的能力。
二、方法
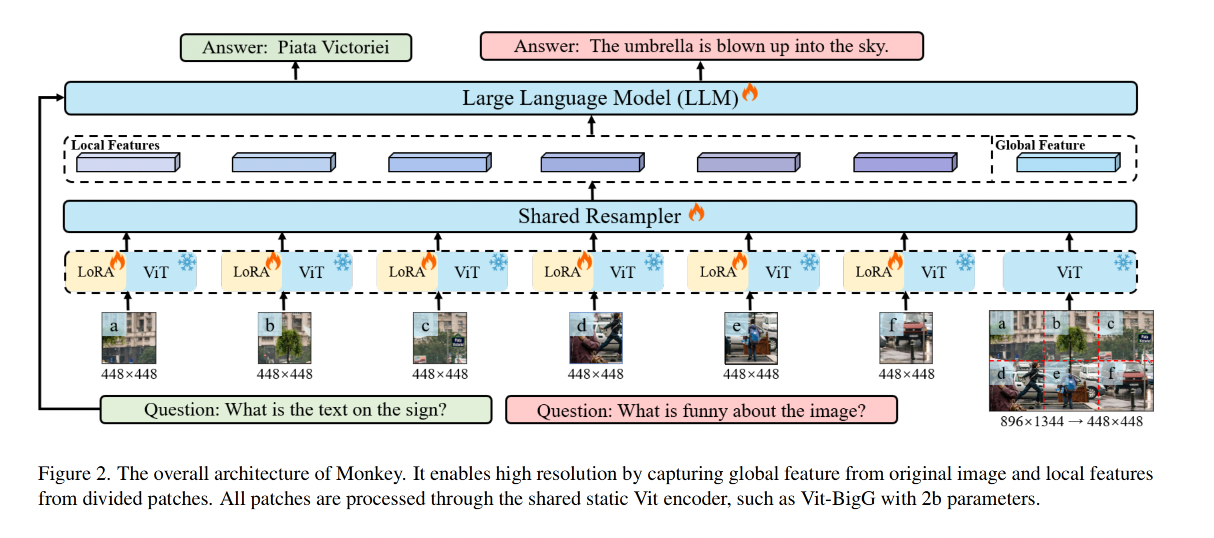
Monkey 模型的结构如图 2 所示,输入的图片被分成了 patches,这些 patches 将被输入 ViT,ViT 是共享参数的,经过 ViT 后得到特征,随后,局部和全局特征通过共享重采样器和大型语言模型(Large Language Model,简称LLM)进行处理,从而生成所需的答案。
2.1 Enhancing Input Resolution
- 首先,输入一个图片,HxWx3
- 接着,使用滑窗来进行切分(滑窗大小为 KaTeX parse error: Undefined control sequence: \time at position 5: H_v \̲t̲i̲m̲e̲ ̲W_v,滑窗大小的宽高也就是 original LMM 所支持的宽高大小),切分成小的图像块儿
- 然后,将切分后的图像块儿输入共享参数的 encoder,每个 encoder 的输入都是不同的图像块儿,此外,会给每个 encoder 搭配一个 LoRA 来适应每个 encoder 对不同位置的图像块儿的学习,有助于模型深入理解空间和上下文的关系,且没有多余引入参数。为了保证整个输入图像的结构信息,作者将原图还会 resize 到 KaTeX parse error: Undefined control sequence: \time at position 5: H_v \̲t̲i̲m̲e̲ ̲W_v 的大小,所以,作者会将独立的图像块儿和 resize 后的 global image 都经过 encoder 编码
- 再后,经过 shared resampler ,这里的 resampler 是源于 Flamingo,主要有两个作用,一个是组合所有的 visual information,另一个是捕捉更高级的语义视觉表达,映射到 language feature space。resampler 是通过 cross-attention module 实现的,其中可训练的 embedding 特征是 query,image features 是 key。
- 最后,将 shared resampler 的输出和文本问题输入一起输入大语言模型 LLM
2.2 Multi-level Description Generation
之前的方法如 LLaVa、QWen-VL 都是使用 LAION 和 COYO 或 CC3M 来训练,但这些数据的文本标签非常简单,缺失了对图像的细致的描述,所以,尽管使用了高分辨率的训练数据,确没有挖掘出图像的更细致的信息
基于此,本文提出了一种生成多层描述的方法,能够生成丰富且高质量的描述,作者使用了多个模型来实现:
- BLIP2:能够为 image 和 text 的关系提供一个很深入的理解
- PPOCR:强大的 OCR 识别模型
- GRIT:擅长粒度化的图像-文本对齐
- SAM:用于语义对齐的动态模型
- ChatGPT:有很好的上下文理解和语言生成能力
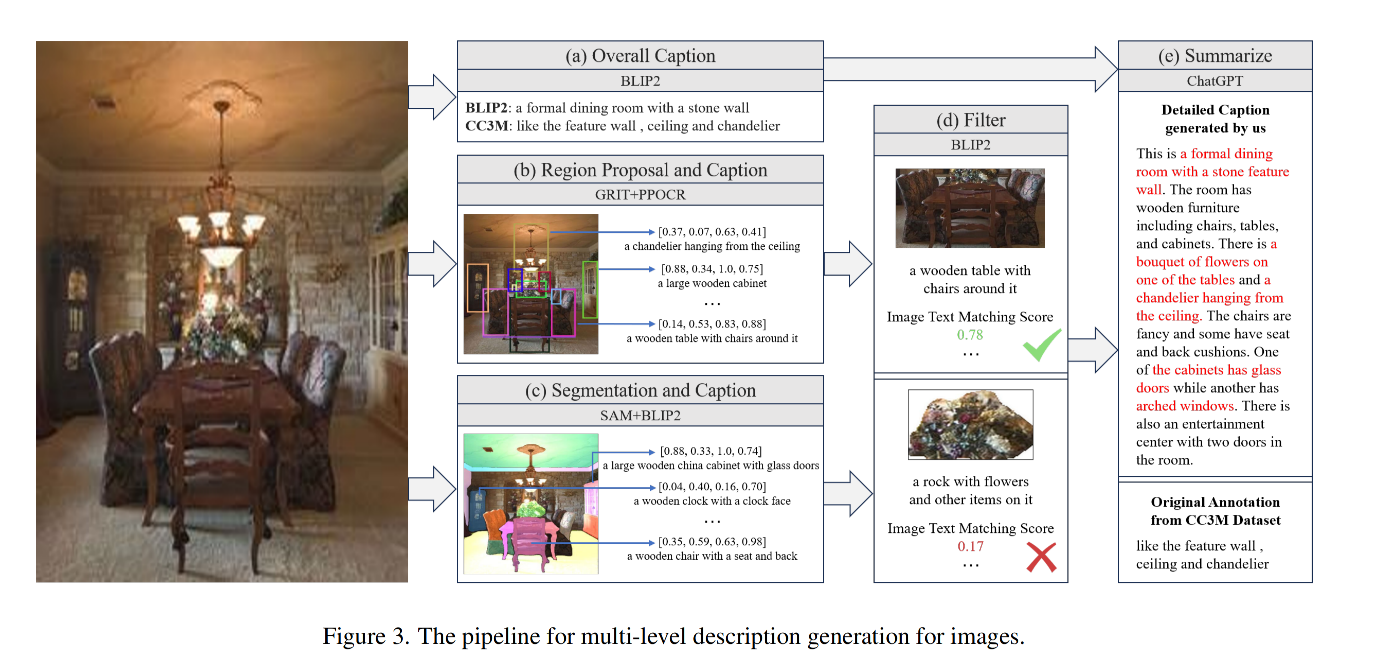
整个流程如图 3 所示:
- 第一步:使用 BLIP2 的 Q-former 来生成 overall caption,同时保留 CC3M 的注释来提供上下文;使用 GRIT 这个 region-to-text 模型,对特定区域、目标生成详细的描述,GRIT 模型能够检测目标同时生成描述, PPOCR 能够从中提取到文本 text 信息;使用 SAM 进行分割,然后使用 BLIP2 来进行描述。
- 第二步:使用 BLIP2 对 region caption 和 segmentation caption 的结果进行过滤,剔除掉分数匹配较低的 caption
- 第三步:将 global captions, localized descriptions, text extracts, object details with spatial coordinates 一起送入 ChatGPT 进行微调,让 ChatGPT 生成准确且上下文丰富的图像描述

2.3 Multi-task Training
本文模型支持多种不同的任务:
- image caption: “Generate the captionin English:” for basic captions, “Generate the detailed caption in English:” for more intricate ones
- 对 image-based 问题的回答: “{question} Answer: {answer}.”
- 同时处理 text 和 image
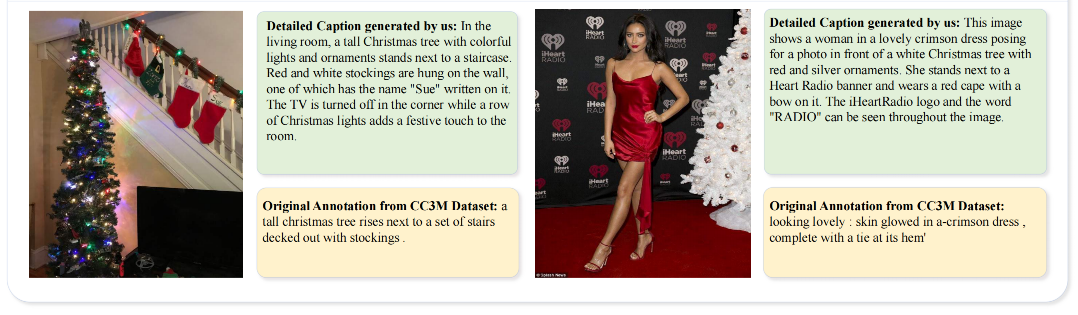
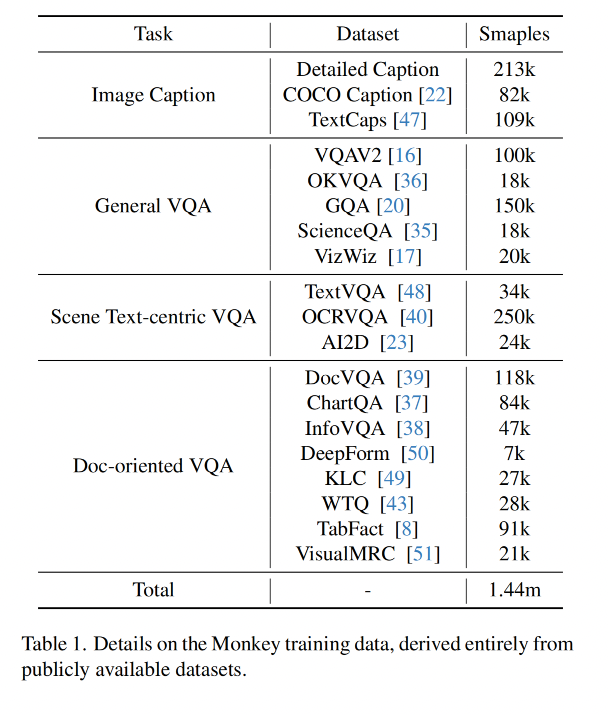
本文使用的数据集:
三、效果
模型实现细节:
- 作者使用 Vit-BigG [21] 和 LLM from QwenVL [3] 分别作为预训练好的多模态模型来使用
- 由于 vision encoder 已经训练的很好了,所以作者只做了 instruction-tuning。在 instruction-tuning 时,滑窗的宽高都使用的 448x448 来匹配 Qwen-VL 的 encoder 尺寸
- 对于所有图像块儿,作者使用的是 resampler 是一样的。可学习的查询 query 与图像的局部特征(patches)进行交互,用于提取重要信息。对于每个 patch,都使用相同的 256 维可学习 query。这些 query 是模型中的参数,可以通过训练来优化。
- 由于训练时间有限,主要实验使用的是896×896像素大小的图像
- 对于 LoRA:LoRA 是模型的一部分,用于调整模型的注意力机制和多层感知机(MLP)。在这里,注意力模块的秩设置为16,编码器中MLP的秩设置为32。秩在这里指的是LoRA中用于调整权重的参数数量,它影响模型的复杂度和能力。
- 模型参数:Monkey 总参数量 9.8B(98亿)
- 大型语言模型:包含 7.7B(Billion)参数。
- 重采样模块:包含 0.09B(Million)参数。
- 编码器:包含 1.9B(Billion)参数。
- LoRA:包含 0.117B(Billion)参数。
训练细节:
- 数据:使用 CC3M 数据集中的数据,使用本文方法生成了描述,共 427k image-text pairs
- 优化器:AdamW
- 学习率:1e-5,cosine 学习率下降模式
- batch size:1024
- 训练时长:40 A800 天 / epoch
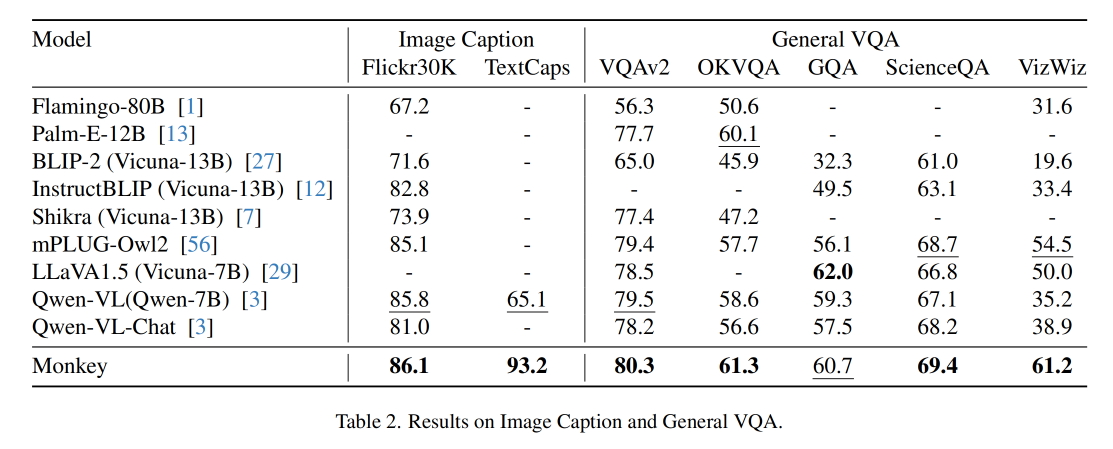
3.1 Image Caption
作者使用 Flickr30K 和 TextCaps 作者 benchmark 来测试这个任务
3.2 General VQA
General visual question answering (VQA)
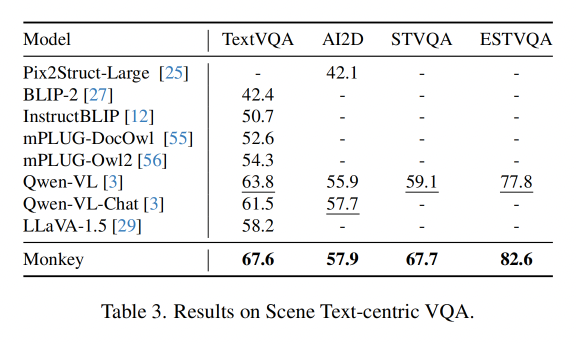
3.3 Scene Text-centric VQA
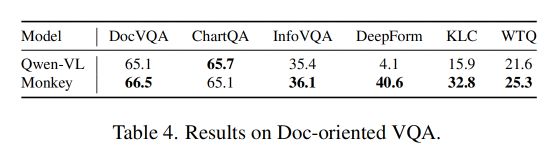
3.4 Document-oriented VQA
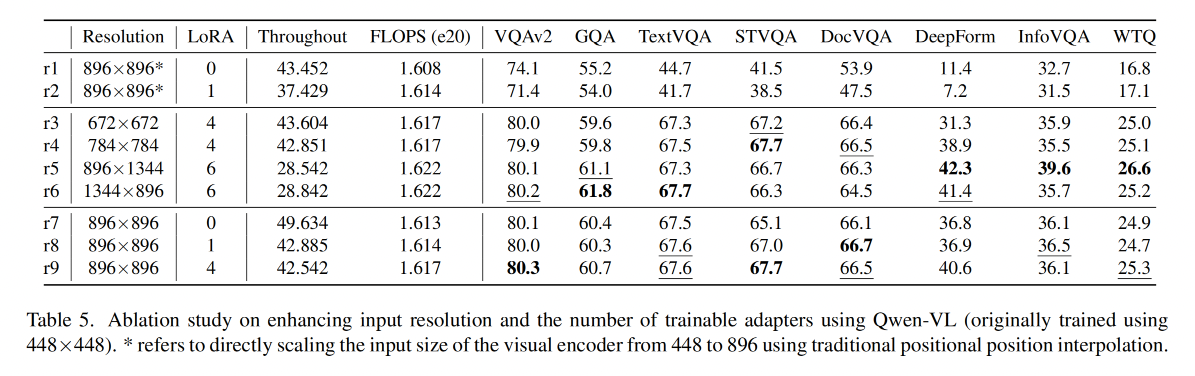
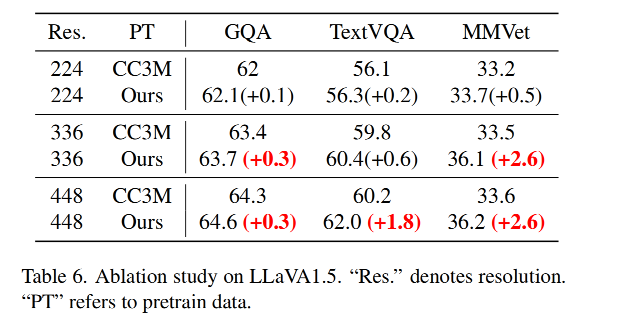
3.5 消融实验
3.6 可视化


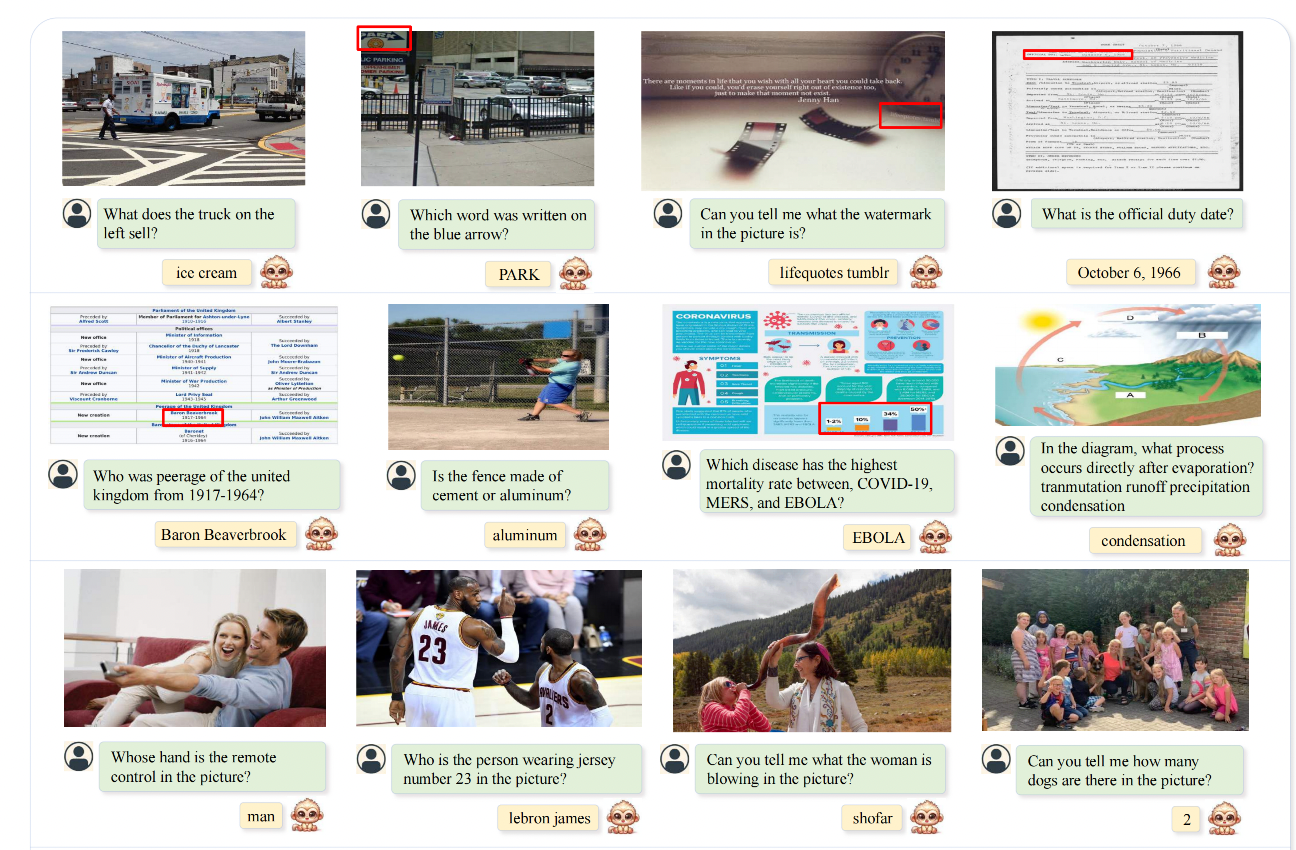

和其他模型的对比:
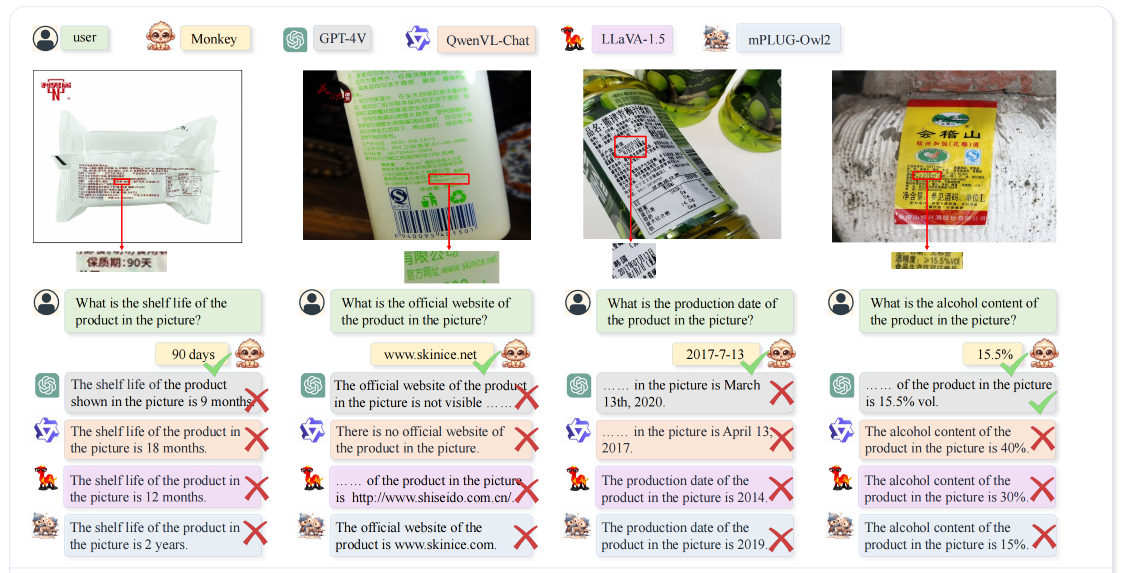
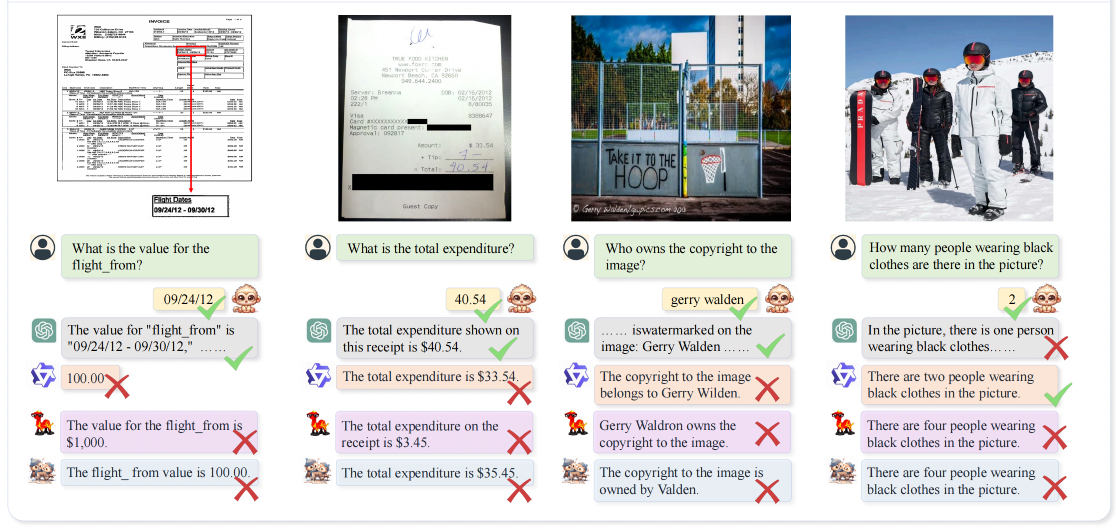
不同分辨率下识别的效果对比:分辨率越小,错误越多






![[动画详解]LeetCode151.翻转字符串里的单词](https://img-blog.csdnimg.cn/direct/6f594249c0f7473dad7adba588aec775.gif)