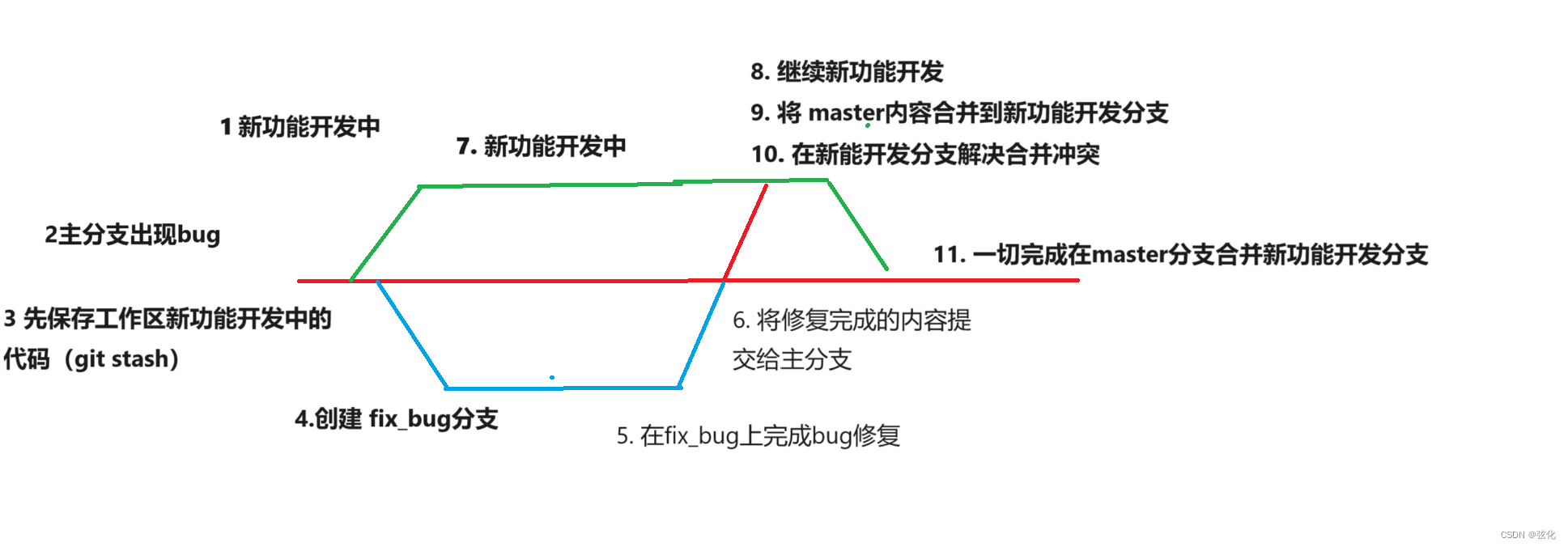
目录
- 第二门课: 改善深层神经网络:超参数调试、正 则 化 以 及 优 化 (Improving Deep Neural Networks:Hyperparameter tuning, Regularization and Optimization)
- 第二周:优化算法 (Optimization algorithms)
- 2.3 指数加权平均数(Exponentially weighted averages)
第二门课: 改善深层神经网络:超参数调试、正 则 化 以 及 优 化 (Improving Deep Neural Networks:Hyperparameter tuning, Regularization and Optimization)
第二周:优化算法 (Optimization algorithms)
2.3 指数加权平均数(Exponentially weighted averages)
我想向你展示几个优化算法,它们比梯度下降法快,要理解这些算法,你需要用到指数加权平均,在统计中也叫做指数加权移动平均,我们首先讲这个,然后再来讲更复杂的优化算法。
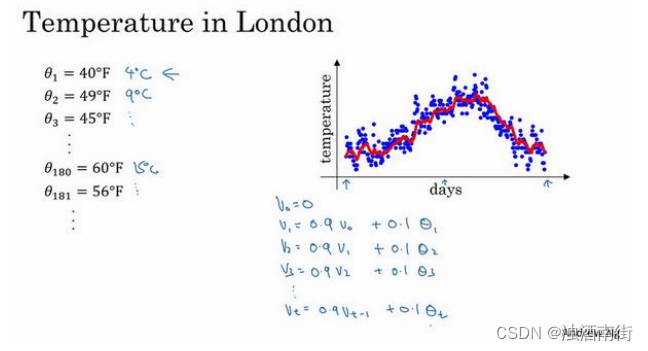
虽然现在我生活在美国,实际上我生于英国伦敦。比如我这儿有去年伦敦的每日温度,所以1 月 1 号,温度是 40 华氏度,相当于 4 摄氏度。我知道世界上大部分地区使用摄氏度,但是美国使用华氏度。在 1 月 2 号是 9 摄氏度等等。在年中的时候,一年 365 天,年中就是
说,大概 180 天的样子,也就是 5 月末,温度是 60 华氏度,也就是 15 摄氏度等等。夏季温度转暖,然后冬季降温。
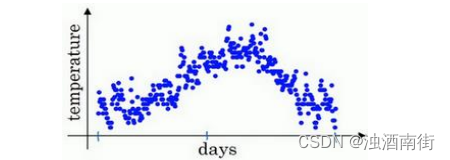
你用数据作图,可以得到以下结果,起始日在 1 月份,这里是夏季初,这里是年末,相当于 12 月末。这里是 1 月 1 号,年中接近夏季的时候,随后就是年末的数据,看起来有些杂乱,如果要计算趋势的话,也就是温度的局部平均值,或者说移动平均值。

你要做的是,首先使𝑣0 = 0,每天,需要使用 0.9 的加权数之前的数值加上当日温度的0.1 倍,即𝑣1 = 0.9𝑣0 + 0.1𝜃1,所以这里是第一天的温度值。第二天,又可以获得一个加权平均数,0.9 乘以之前的值加上当日的温度 0.1 倍,即𝑣2 =0.9𝑣1 + 0.1𝜃2,以此类推。第二天值加上第三日数据的 0.1,如此往下。大体公式就是某天的𝑣等于前一天𝑣值的 0.9加上当日温度的 0.1。
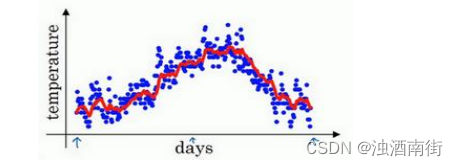
如此计算,然后用红线作图的话,便得到这样的结果。
看一下上一张幻灯片里的公式,𝑣𝑡 = 0.9𝑣𝑡−1 + 0.1𝜃𝑡,我们把 0.9 这个常数变成𝛽,将之
前的 0.1 变成(1 − 𝛽),即 v t = β v t − 1 + ( 1 − β ) θ t v_t = βv_{t−1} + (1 − β)θ_t vt=βvt−1+(1−β)θt

由于以后我们要考虑的原因,在计算时可视𝑣𝑡大概是 1(1−𝛽)的每日温度,如果𝛽是 0.9,你会想,这是十天的平均值,也就是红线部分。
我们来试试别的,将𝛽设置为接近 1 的一个值,比如 0.98,计算 1(1−0.98)= 50,这就是粗略平均了一下,过去 50 天的温度,这时作图可以得到绿线。

这个高值𝛽要注意几点,你得到的曲线要平坦一些,原因在于你多平均了几天的温度,所以这个曲线,波动更小,更加平坦,缺点是曲线进一步右移,因为现在平均的温度值更多,要平均更多的值,指数加权平均公式在温度变化时,适应地更缓慢一些,所以会出现一定延迟,因为当𝛽 = 0.98,相当于给前一天的值加了太多权重,只有 0.02 的权重给了当日的值,所以温度变化时,温度上下起伏,当𝛽 较大时,指数加权平均值适应地更缓慢一些。
我们可以再换一个值试一试,如果𝛽是另一个极端值,比如说 0.5,根据右边的公式(1(1−𝛽)),这是平均了两天的温度。
作图运行后得到黄线。
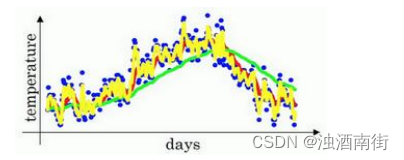
由于仅平均了两天的温度,平均的数据太少,所以得到的曲线有更多的噪声,有可能出现异常值,但是这个曲线能够更快适应温度变化。
所以指数加权平均数经常被使用,再说一次,它在统计学中被称为指数加权移动平均值,我们就简称为指数加权平均数。通过调整这个参数(𝛽),或者说后面的算法学习,你会发现这是一个很重要的参数,可以取得稍微不同的效果,往往中间有某个值效果最好,𝛽为中间值时得到的红色曲线,比起绿线和黄线更好地平均了温度。
现在你知道计算指数加权平均数的基本原理,下一个视频中,我们再聊聊它的本质作用。