TCP:Textual-based Class-aware Prompt tuning for Visual-Language Model(CVPR2024)
- 基于文本的类感知提示调优的VLM
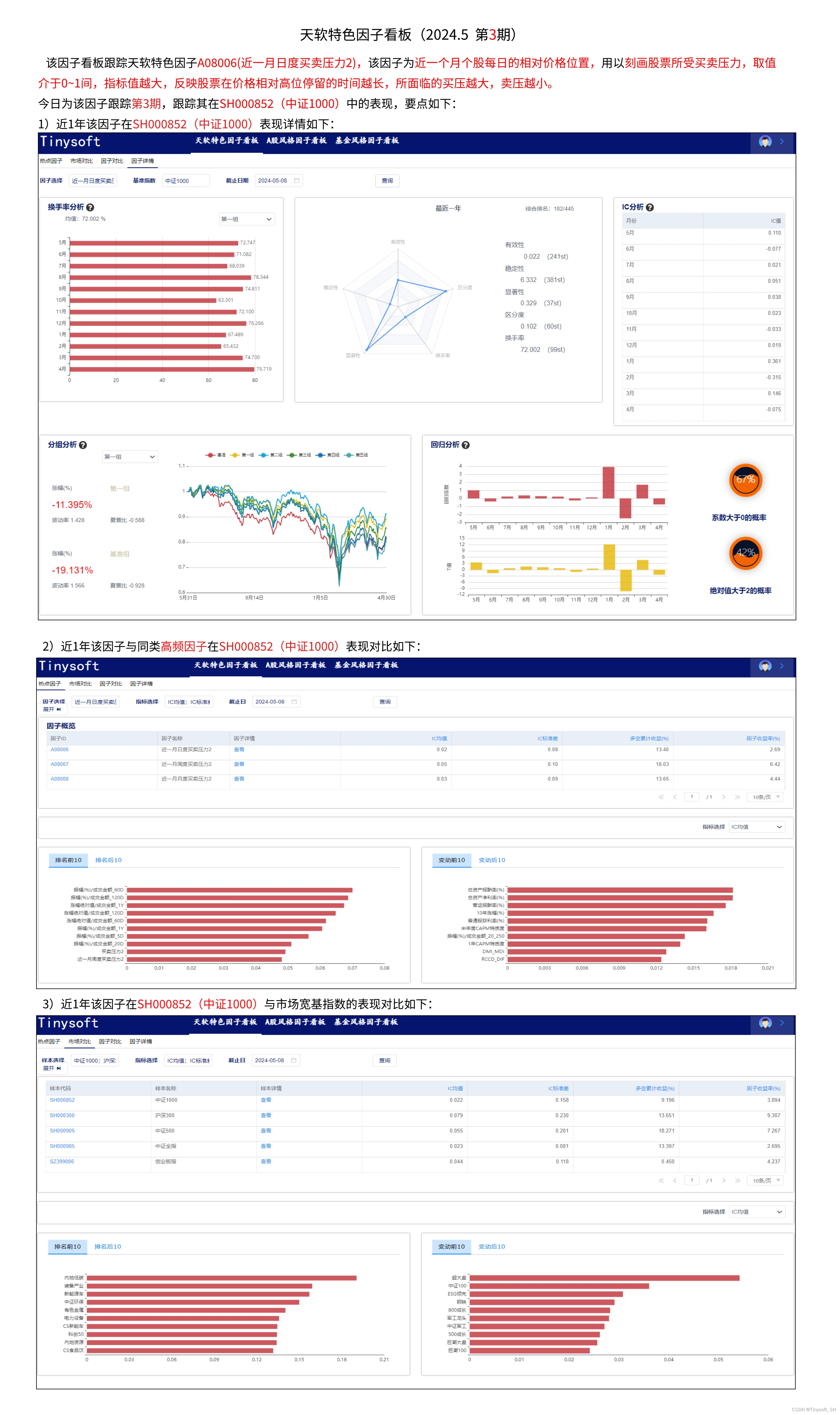
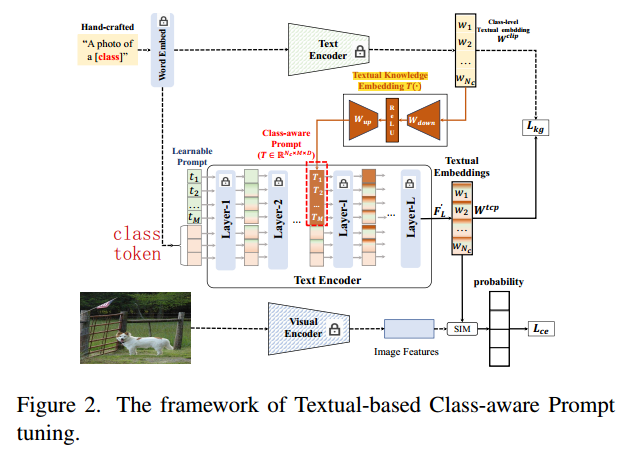
- KgCoOp为baseline,进行改进,把 w c l i p w_{clip} wclip进行投影,然后与Learnable prompts进行结合。
![![[TCPf2.png|600]]](https://img-blog.csdnimg.cn/direct/95412ea63b444bbcbf67d99359080de1.png)
Abstract
近年来,通过可学习的域共享或图像条件的文本tokens,促进生成适用于特定任务的分类器
问题:
这些textual tokens对unseen域具有有限的泛化能力,不能动态地适应测试类的分布
解决:
提出了新的基于文本的类感知提示调优(TCP,Textual-based Class-aware Prompt)。显式地结合关于类的先验知识,增强它们的可辨别性。利用文本知识嵌入(TKE),映射高泛化性的类级文本知识,到类感知文本tokens。通过无缝地将这些类感知提示集成到Text Encoder中,可以生成一个动态的类感知分类器,以增强对不可见域的可辨别性。
推断阶段,TKE动态地生成与unseen类相关的类感知提示,可作为即插即用的模型与现有方法轻松结合。
1 Introduction
图像条件文tokens封装了每个图像的特定知识,特别是测试图像,从而更容易泛化到unseen类。
3 方法
TKE将一般类级的textual embedding转化成类感知提示,然后与Learnable tokens 结合。
3.2 基于文本的类感知提示提示调优
TKE:投影class-level embedding W c l i p W^{clip} Wclip,得到class-aware prompt T
![![[TCPg2.png]]](https://img-blog.csdnimg.cn/direct/be9a6277991e4a7fb35d0d140f2e23f4.png)
![![[TCPg3.png]]](https://img-blog.csdnimg.cn/direct/9c015ef9ea534fd88b87839cf3a86e34.png)
![![[TCPg4.png]]](https://img-blog.csdnimg.cn/direct/ee67f08c2da04d83a686f04203266f53.png)
![![[TCPg1.png]]](https://img-blog.csdnimg.cn/direct/1f73cfde22d047589f856babbef84460.png)
TKE包括两层
- 下投影层
使用权重 W d o w n W_{down} Wdown将 W c l i p W^{clip} Wclip其投成低维特征 - 上投影层
使用权重 W u p W_{up} Wup将 W d w o n W^{dwon} Wdwon其投成高维特征
得到
![[TCPg5.png]]
再重塑成
![[TCPg6.png]]
插入到文本编码器的中间层
4 实验
作者将其分为tp、vp、dtp、dvp,比较了近年来的方法
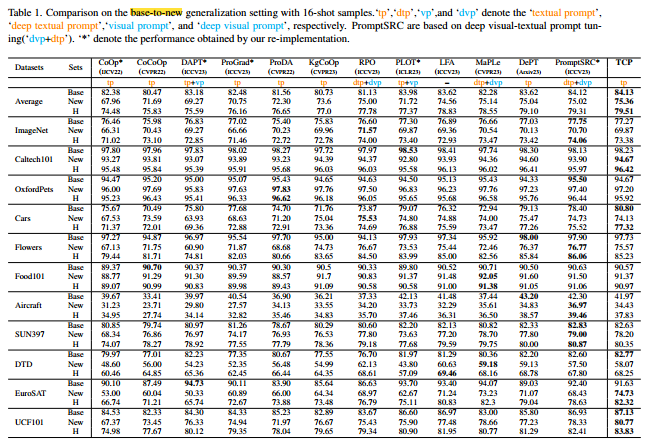
消融实验
- Prompt长度:M=8最好
- 不同模板的效果:可学习prompt最好
- Dmid的作用:128时效果最好
- 类感知prompt拼接到哪:第8层最好