有了 24 小时前 OpenAI 用 GPT-4o 带来的炸场之后,今年的 Google I/O 还未开始,似乎就被架在了一个相当尴尬的地位,即使每个人都知道 Google 将发布足够多的新 AI 内容,但有了 GPT-4o 的珠玉在前,即使是 Google 也不得不面临巨大的压力。
Gemini 带来的 AI Search
Gemini 1.5 Pro 还从原本的一百万 Token 上下文升级至两百万 Token 上下文识别。这意味着在多模态处理中能处理超过三万行代码,或是超过一小时的视频文件。
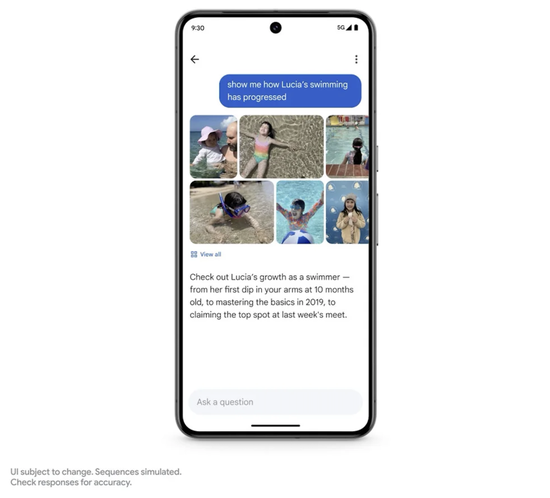
在介绍了 Gemini 本身之后,就到了 Gemini 真正的长处 —— 应用内整合体验中,皮查伊先是演示了整合在相册中的功能,在停车并给车拍了照片之后,当你找不到停车的位置,可以直接问 Gemini “我的车在哪”,它就能帮你自动识别相关照片中的信息,提示你车停在了哪里。
这个功能被称为。Ask Photos,将于今年正式发布。

在 Google 办公套件中,如今也迎来了 Gemini 更深度的整合,不仅能在 Gmail 中生成线上会议纪要、在所有邮件中提取关键信息。还能与 Google 表格联动,自动整理邮件中包括的表格文件,甚至是生成一个数据分析表格。
在现场的演示中,NotebookLM 不仅能很好地充当一个老师的身份、讲述一组简单的物理课程,还能模拟两个演讲者,生成一个类似对话的讲解内容。在用户提问“你能举个例子吗”这样的问题时,实时给出一个准确的回答。让你能够更准确地掌握物理原理中的细节。
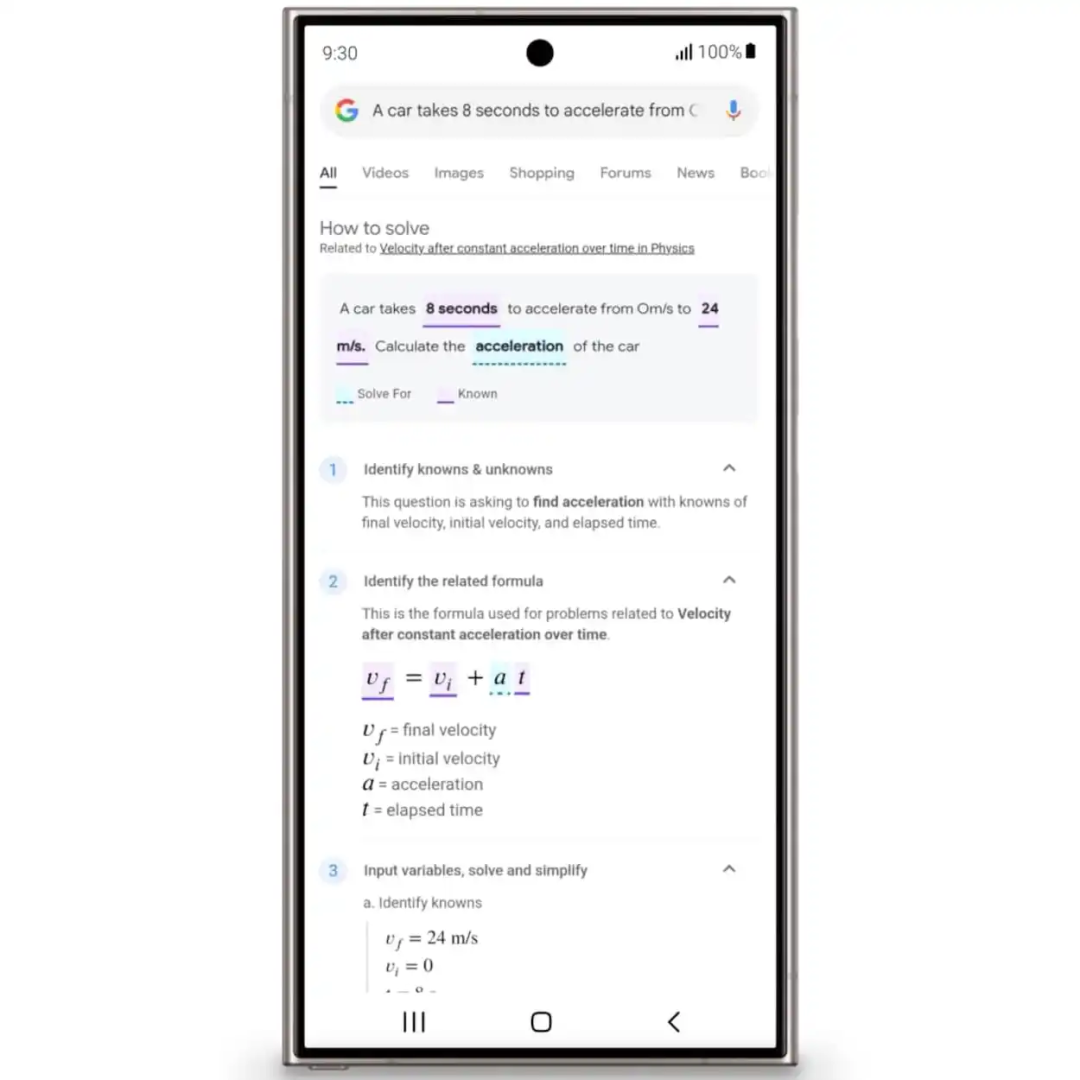
Google 同时还针对去年发布、在 Android 手机上实现画圈搜索功能的“Circle to Search”功能加入了更多教育相关的使用场景:现在这个功能已经支持识别画面中的数学题以及符号公示等复杂的内容。
看到这里我都怀疑 Google 是不是被 Microsoft 和 OpenAI 夺舍了,全是云办公竞品。今年预计年中会开源 Gemma 2,大家敬请期待。
Imagen 3

Imagen 3是Google最高质量的文本到图像生成模型。它能生成细节丰富、栩栩如生的图像,视觉干扰明显少于之前的模型。并且能更好地理解自然语言和提示背后的意图,结合长提示中的细微细节,掌握多种风格。它还是迄今为止Google最好的文字渲染模型,使生成个性化生日祝福和演示文稿标题页成为可能。
从今天起,Imagen 3将作为ImageFX中的私人预览提供给特定创作者,用户可以注册加入候补名单。很快,Imagen 3也将在Vertex AI上提供。
此外,Google还设计并构建了音乐AI工具Music AI Sandbox,旨在为创意打开新的天地,让人们从零开始创作新的器乐部分并以新的方式转换声音。
Veo:比Sora更强的视觉模型
Veo能够生成超过一分钟的高质量1080p视频,涵盖多种电影和视觉风格。据介绍,Veo具备高级的自然语言和视觉语义理解能力,能准确呈现细节并捕捉情感基调。它理解“延时摄影”等电影术语,提供高度创作控制,生成的镜头中人、动物和物体的运动非常真实。
Google已邀请电影制片人和创作者试用Veo,并根据他们的反馈改进技术。Veo基于Google多年生成视频模型的工作,如GQN、DVD-GAN、Imagen-Video等,结合新技术提高质量和分辨率。Veo将作为VideoFX的私人预览提供给特定创作者,所有人可申请注册候补名单,未来可能直接引入YouTube Shorts。
Imagen 和 Veo 都有他们自家的 SynthID 水印,已经有和 OpenAI Dalle 3 以及 Sora 扳扳手腕的意思了。
Google 很早就布局AI领域,研究自动驾驶(Autonomous Driving)。但是在这块领域的投资上却抱着跟闹着玩的心态,先是被 Uber 挖墙脚,后被 Tesla 量产后彻底完虐。虽然在Android上与Apple稍占优势,但是如今的 DeepMind 却在AI领域被 OpenAI 小辈牵着鼻子溜街,这或许就是硅谷大企业摆脱不了的魔咒啊。