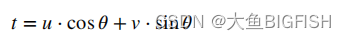目录
2 系统需求分析
2.1 系统需求概述
2.2 系统需求分析
2.2.1 系统功能要求
2.2.2 系统IPO图
2.2 系统非功能性需求分析
3 系统概要设计
3.1 设计约束
3.1.1 需求约束
3.1.2 设计策略
3.1.3 技术实现
3.3 模块结构
3.3.1 模块结构图
3.3.2 系统层次图
3.3.3 面向对象设计UML图
前面内容请移步
基于网络爬虫技术的网络新闻分析(一)
资源下载+毕业论文+答辩
基于网络爬虫技术的网络新闻分析.rar
2 系统需求分析
软件需求分析对软件系统提出了清楚、准确、全面而具体的要求,是对软件使用者意图不断进行揭示与准确判断的过程,它并不考虑系统的具体实现,而是严密地、完整地描述了软件系统应该做些什么的一种过程。
2.1 系统需求概述
要求爬虫系统能完成对凤凰网新闻、网易新闻、新浪新闻、搜狐新闻等网站新闻数据的实时抓取,并正确抽取出正文,获取新闻的点击量,实现每日定时抓取。能将抓取回来的新闻进行中文分词,利用中文分词结果来计算新闻相似度,将相似的新闻合并起来,同时也合并点击率,最后一点,能将相似因为一段事件内的用户点击趋势以合适的形式展现出来。
基于网络爬虫技术的网络新闻分析由以下几个模块构成:
网络爬虫模块。
中文分词模块。
中文相似度判定模块。
数据结构化存储模块。
数据可视化展示模块。
2.2 系统需求分析
2.2.1 系统功能要求
按照对系统需求调用的内容分析,系统功能划分为了一下五个模块:
数据采集模块:
数据采集模块负责数据采集,即热点网络新闻数据的定时采集,以及数据的初步拆分处理。
(1)中文分词模块:
中文分词模块能将数据采集模块采集到的热点网络新闻数据进行较为准确的中文分词。
(2)中文相似度判定模块:
中文相似度判定模块通过将数据采集模块采集到的热点网络新闻数据结合中文分词模块的分词结果,进行网络热点新闻的相似度分析,并能够将相似新闻进行数据合并。
(3)数据结构化存储模块:
数据结构化存储模块贯穿在其他模块之中,在数据采集模块中,负责存储采集拆分后的热点网络新闻数据;在中文分词模块中,负责从数据库读出需要分词处理的网络新闻数据;在中文相似度判定模块中,负责从将分析得到的相似新闻进行存储;在数据可视化展示模块中负责将相似热点新闻数据从数据库读出,其中涉及到大量关于数据库资源的处理。
(4)数据可视化展示模块:
数据可视化展示模块负责将中文相似度判定模块判定为相似新闻的数据以可视化的形式展示出来,展示形式可以自定义。
2.2.2 系统IPO图
整个系统的IPO图如图2-1。

图2-1 系统IPO图
爬虫输入新闻数据,然后处理分析,最后用可视化界面展示出来。
2.2 系统非功能性需求分析
本系统设计的非功能性需求涵盖了一下几个方面:
性能需求:
要求爬虫能并行爬取网络新闻,并行分析,数据库的并发处理能力要足够强。
可靠性需求:
要求系统运行能保持稳定持久状态,没有明显的BUG
易用性需求:
要求爬虫系统能做到尽可能的自动化,争取不需要人为操作。
维护性需求:
要求系统出现BUG能比较容易的修复,系统的后期拓展功能较强。
3 系统概要设计
系统概要设计的主要目的是能在此阶段将系统的主要功能逻辑设计和数据库系统的逻辑设计完全从需求分析中提取出来,在提取的过程中,不仅仅是奔着实现软件的功能而去,还得考虑上下文环境,例如系统最终的运行环境,系统以后可能增加的需求等等相关约束,在捋清楚系统约束之后在进行系统概要设计,这样软件系统之后的二次开发也不会太难。
3.1 设计约束
3.1.1 需求约束
系统能稳定运行在最低为JDK1.7的平台上。
数据库向后兼容,最低适配Mysql5.1。
要求程序有较好的跨平台性,可以同时运行在Linux、windows、Unix系统上。
要求数据库连接方面,设置的密码足够复杂,数据库连接管理良好,数据库系统能健壮运行。
禁止使用商业性软件,在本系统中使用的算法或是类库必须是免费的。
系统对系统配置的要求要尽可能低。
程序具有良好的可移植性、兼容性、安全性。
3.1.2 设计策略
为了本系统能适应未来的需求与发展,特制定如下策略:
系统具有良好的接口扩展功能,能非常容易地扩展新功能,并将可能会经常调整的部分单独提取出来作为一个模块;
系统代码具有非常良好的复用价值,新功能的添加能基于现有功能进行派生;
系统代码优化到位,很少出现或者完全不会出现内存泄露的问题,包括数据库连接池的泄露,独享资源使用未关闭句柄的问题等;
当优化问题与代码健壮性发生冲突时,则以保证代码健壮性为首要目标,可以适当调整优化。
3.1.3 技术实现
本系统设计与开发工具采用以下配置:
开发语言:java JDK版本1.7。
Java是一种具有非常棒的面向对象的设计思想的一门计算机语言语言。Java 技术具有很高的生产力,原因是大量的程序员为其贡献了大量的代码,目前Java程序广泛应用于Web、企业管理系统、云计算、大数据计算等方面,同时Java目前在全球的编程语言的稳居第一。
开发环境:Eclipse。
Eclipse 一开始是IBM旗下的一款开发工具,知道后来被IBM贡献给了开源社区,虽然开源,但是其功能一点也不逊于专业收费类型的开发IDE,Eclipse有着强大的开源活力,以及良好的扩展性,很容易在论坛上下载到各种各样为Eclipse量身定制的插件,所以开发本系统采用了Eclipse作为开发IDE。
3.3 模块结构
3.3.1 模块结构图
爬虫系统软件结构图:
向爬虫系统输入网页URL,爬虫打开网页解析处理抽出网页正文,然后输出网页正文,如图3-1所示。
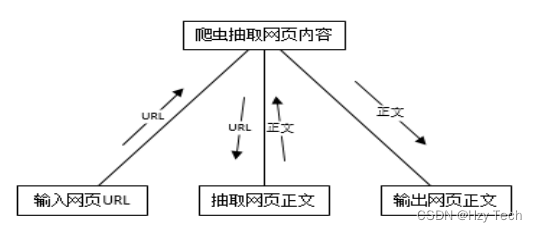
图3-1 爬虫子系统结构图
将网页正文传入系统,系统根据词库以及相关策略开始分词,最后将分词结果以数据形式(词组的形式)输出出来,如图3-2所示。
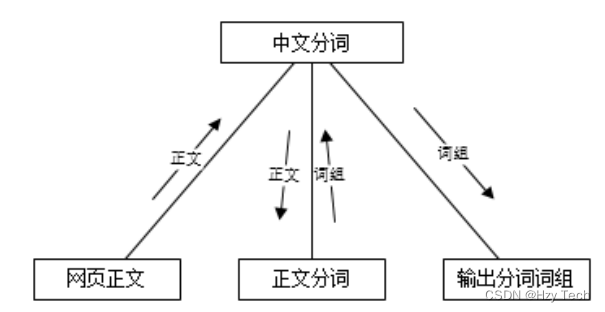
图3-2 分词子系统结构图
首先第一步输入数据:网络爬虫系统采集到的数据作为相似度匹配系统的输入,然后进入处理过程,处理过程采用了改进了的余弦定理进行处理,然后系统返回处理后的结果,最终本系统将处理后的结果作为输出,并传递给下一个子系统进行处理,如图3-3所示。

图3-3 文章相似度匹配系统结构图
3.3.2 系统层次图
本系统设计为分别由三个子系统组成,分别是:网络爬虫系统即数据采集系统、新闻分析系统即中文语料相似度分析系统和最终结果展示系统,如图3-4所示。
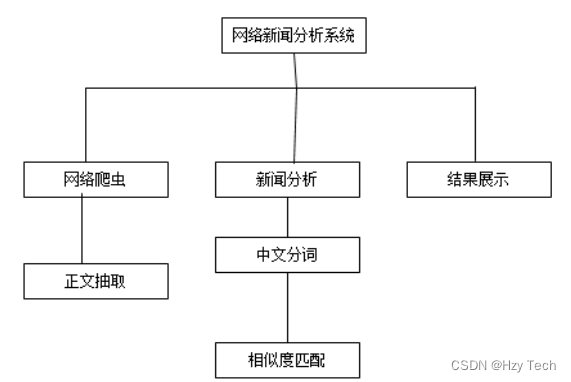
图3-4 系统层次图
3.3.3 面向对象设计UML图
(1)在这里首先介绍一下系统中使用的数据库连接池,MF_DBCP自己写的一个数据库连接池,UML类图如图3-5所示。
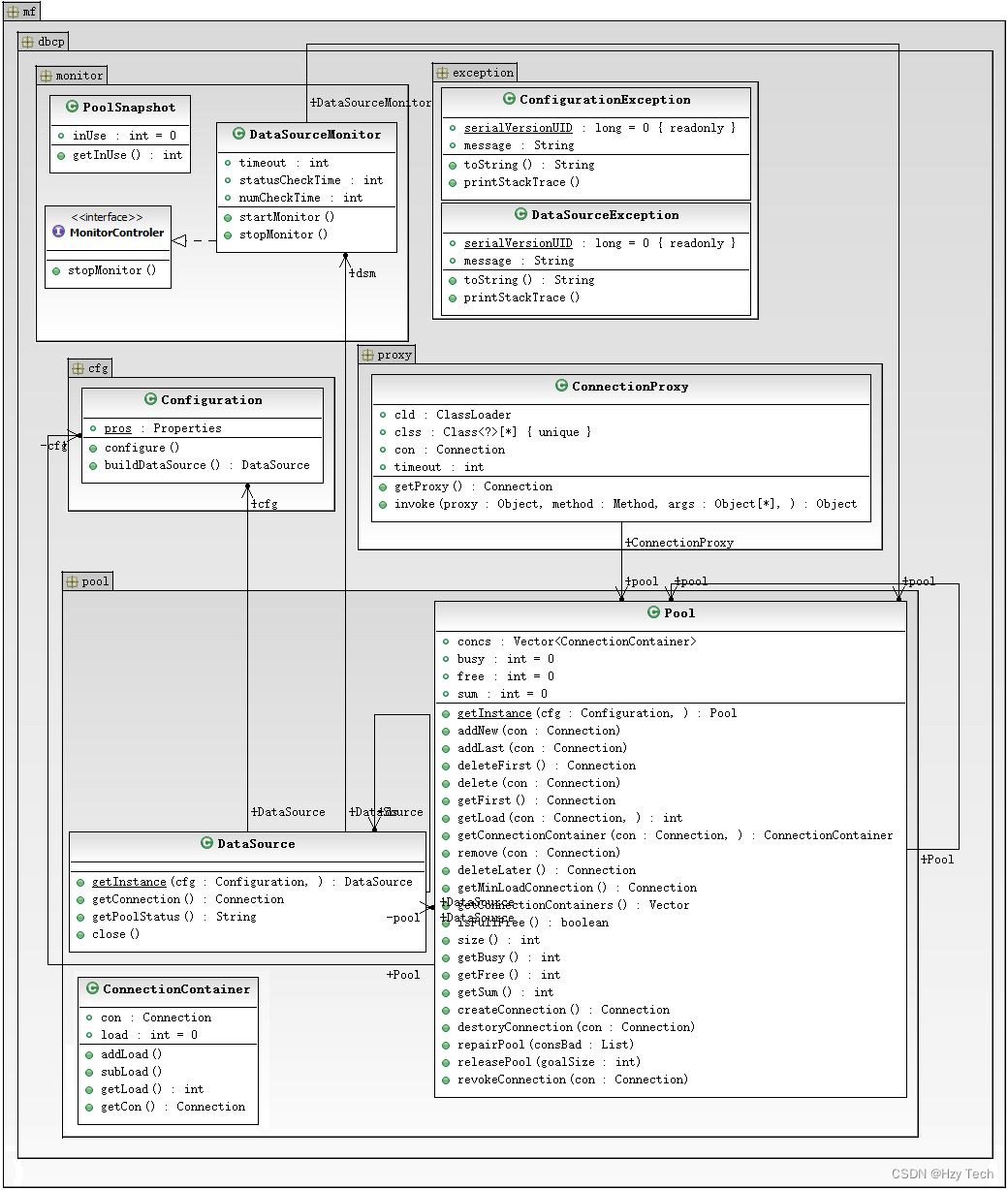
图3-5 系统类图
在DBCP连接池UML图中,定义了数据库异常抛出类,数据库配置的POJO类,数据库连接池核心类 Pool 以及代理实现了Connection的close() 方法、setAutoCommit()等方法,还有数据库连接池监视器类,用来监视数据库的健康状况等等。
(2)爬虫核心是Web类,凤凰网新闻、搜狐新闻、网易新闻分别集成了核心Web类,然后各自实现各自的解析规则,核心Web类负责一些基础操作,例如打开网页,获取网页源码,还有一些正则表达式抽取分析算法,其实,Web类也包含了POJO类的作用,也是作为爬虫爬取新闻后生成的结果的载体,如图3-5所示。
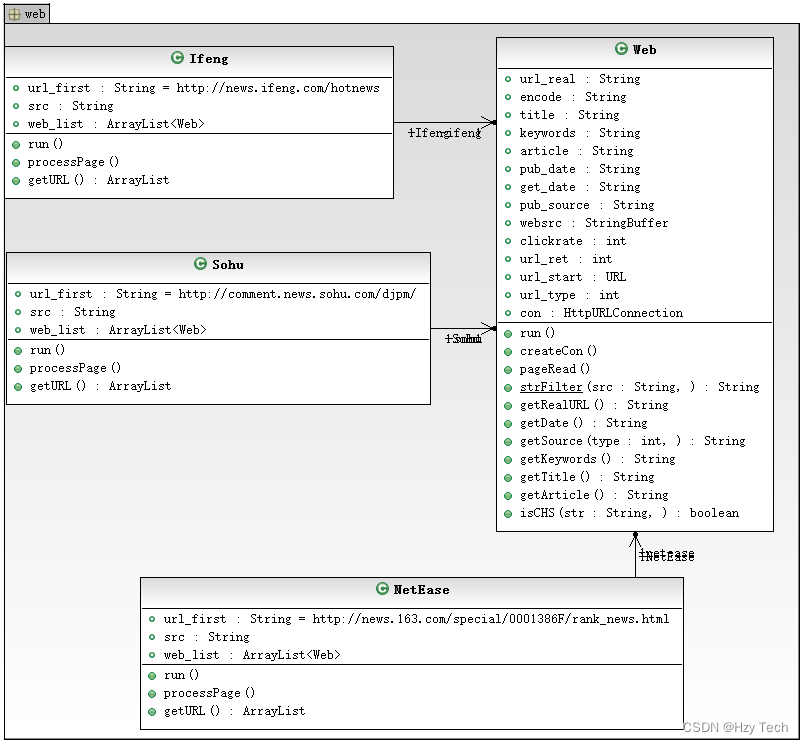
图3-5 爬虫系统类图