【class4】



【回顾class】

上上次的课程里,我们使用csv模块读取了一份CSV文件。
该文件里存储了各电商平台上对某品牌电视机的评价,以及每条评价所对应的正负面性。
我们将读取后的数据存储在了列表data里。
对应的代码:
# 导入csv模块
import csv
# 使用open()函数打开数据集,并将返回的文件对象存储在变量file中
file = open("/Users/yequ/TVComments.csv", "r")
# 使用csv.reader()函数读取数据集,并赋值给变量reader
reader = csv.reader(file)
# 创建一个空列表data
data = []
# 使用for循环遍历reader,将遍历的数据存储到变量info中
for info in reader:
# 使用append()函数,将info逐一添加到data列表中
data.append(info)
# 输出data变量
print(data)
上次的课程里,我们通过jieba模块对该文件里的评价进行了分词处理。然后,使用join()和append()函数将分词结果以字符串的形式存储在列表word中。
# 导入jieba模块
import jieba
# 创建一个空列表word存储结果
word = []
# 使用for循环遍历data列表
for row in data:
# 获取具体的评价内容,并赋值给变量text
text = row[0]
# 使用jieba.lcut()将text进行分词,并把结果赋值给ret
ret = jieba.lcut(text)
# 使用join()函数,将分词结果以空格合并为一个完整的字符串
ret = ' '.join(ret)
# 使用append()函数,添加分词结果到列表word中
word.append(ret)
# 输出word进行查看
print(word)
完成分词后,我们使用sklearn模块,先构造了一个词袋模型。生成的结果是很多类似于“(499, 1218) 1” 这样的数字数据,表示编号1218的词语在第500条评价里出现了1次。
# 从sklearn.feature_extraction.text中导入CountVectorizer
from sklearn.feature_extraction.text import CountVectorizer
# 创建CountVectorizer对象,并存储在vect中
vect = CountVectorizer(max_features=15)
# 通过vect.fit_transform()和word,构造词袋模型
X = vect.fit_transform(word)
# 输出X
print(X)
然后,我们通过get_feature_names()提取出了评价里前15个出现频率最高的词语。
# 对vect对象使用get_feature_names(),并将结果赋值给keywords
keywords = vect.get_feature_names()
# 输出keywords
print(keywords)
复习结束~接着前两节课的内容,今天我们要构建一个人工智能系统。它的目的是像人类一样,区分评价的情感是正面还是负面的。
在自然语言处理中,像这样对带有情感色彩(褒义贬义/正向负向)的文本进行分析,以确定该文本的情感倾向,被称为情感分析(或情感分类)。接下来,我们会通过监督学习完成情感分析。

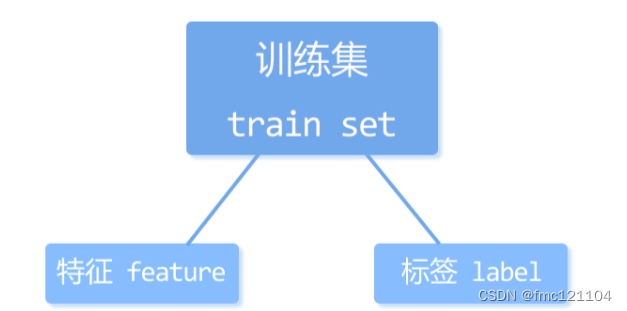
在监督学习中,用于训练模型的数据都既有特征(feature)又有对应标签(label)。我们将这样的数据集称为训练集(train set)。
比如:
一组照片,每一张上都有是否是“猫”的标签;
一组邮件,每一封都有是否是“垃圾邮件”的标签等。
通常,特征需要使用代码提取,标签则是人工直接标注在数据集上的。
我们打开包含电视机评价的数据集,可以看到每条评论都有被标记好的“正面”或“负面”的标签。而每条评论的文本特征则需要我们来提取。其实,昨天构造词袋模型就是在提取文本特征(词频)。当我们提取评价的文本特征后,就可以发现,每一条评论的文本特征都有一一对应的“好评”或“差评”的标签。
例如,「清晰」和「不错」是“好评”的文本特征,而「太差」和「漏光」对应的则是“差评”。


分类器:
X正向词,y负向词,x=y为分类器
例如,下图评论2个正向词,0个负向词 y=x线下为好评,线下为差评


测试集(test set)
分类器形成后,在正式使用它对未标记数据进行预测前,我们还需要通过一组“已标记”的数据来检验它的最终效果。这类已标记并用于做模型最终评估的数据集被称为测试集(test set)。
因此,原始的已标记数据集在提取特征和标签后,通常会被随机分为两个部分:
1. 80%用于训练模型的训练集(train set)
2. 20%用于检验模型效果的测试集(test set)
训练集相当于上课学知识;
测试集则相当于期末考试,用来最终评估学习效果。
通过测试集的评估,我们会得到一些最终的评估指标,例如:模型的准确率等。
至此,模型就算是建立好了,通过该模型我们便能对未被标注的评价进行预测。
在对没有标签的数据进行预测的过程中,我们也需要先提取数据的文本特征。然后将这些特征输入到分类器中,生成对应的标签。
那么通过监督学习搭建模型的流程大概可以分为6步:
1. 提取数据集的文本特征和对应的标签
2. 将数据集划分为训练集和测试集
3. 选择一个合适的监督学习算法
4. 在训练集上执行算法,生成一个分类器模型
5. 通过测试集来评估模型的准确率
6. 对“没有标签”的评价进行预测
Ps:
监督学习是机器学习中的一种训练方式在监督学习中,
我们会将人工标注好标签(label)的数据集给机器进行学习和训练
在对没有标签的数据进行预测的过程中,也需要先提取数据的文本特征
了解完监督学习后,我们就可以尝试用代码实现情感分析啦~按照刚刚的步骤,首先需要提取数据集中的文本特征和对应的标签。
上节课,我们在构造词袋模型时,只想提取前15个出现频率最高的词语,所以传入了可选参数max_features=15。
构造的词袋模型是一个稀疏矩阵(sparse matrix),用于记录每一条评价里,每个词语出现的次数。
提取数据集中的文本特征
但是当我们训练分类器模型时,必须提取数据集中每一条评价的文本特征。
因此,在构造词袋模型时,不需要传入参数max_features=15。
可以明显感觉到这次多了更多输出内容,因为我们提取了所有评价的文本特征,而不只是前15个高频词语。
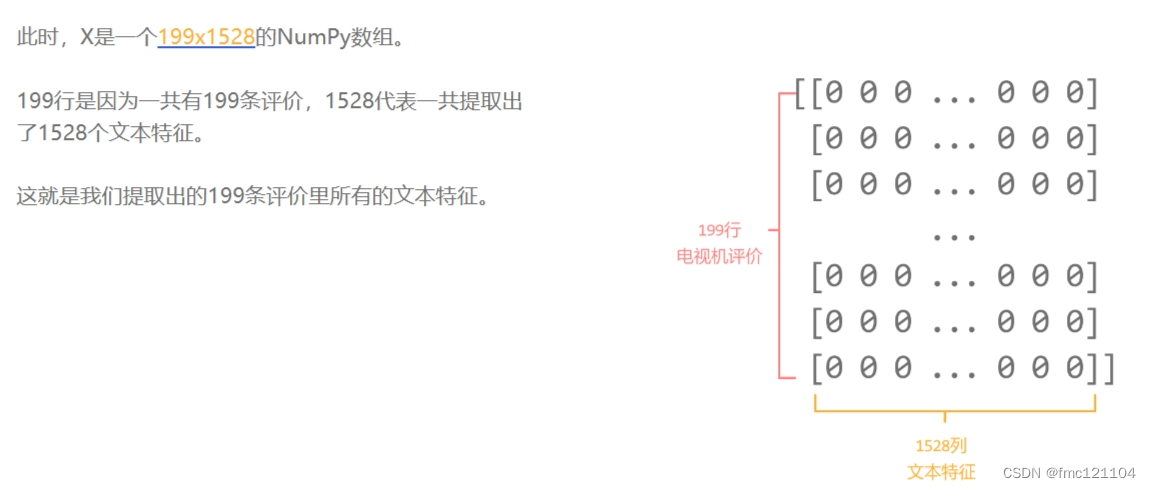
为了训练分类器模型,我们需要将文本特征从稀疏矩阵转换为一个二维的NumPy数组。
这是因为每条评价都对应多个特征,通过二维数组的行和列,可以清晰定位出某一个词语在某条评价里出现的次数。同时,不论之后选择哪一种机器学习的算法,都可以直接传入NumPy数组进行训练,非常方便。
我们只需对X使用toarray()函数,就可以将其转换为二维数组了。
示例代码:
# 创建CountVectorizer对象,并存储在vect中
vect = CountVectorizer()
# 将word中的数据传递给vect
X = vect.fit_transform(word)
# 使用toarray()函数,将x转换为数组
X = X.toarray()
# 输出X进行查看
print(X)
提取数据集中的标签
接下来,我们需要提取这199条评价里每一个文本特征所对应的标签,是“正面”还是“负面”。
回忆一下,我们将“正面”或“负面”这一列信息存储在了哪里呢?
没错,标签存储在data中每个小列表的第二个元素里。
那么和上节课读取评价内容一样,只需:
1. 创建一个空列表y用于存储标签数据
2. 使用for循环来遍历data中的每一行数据
3. 只从中提取标签部分,即每行的第二个数据,allInfo[1]
4. 将每行的标签数据逐一添加到列表 y 中
代码实现:
# 创建一个空列表y,用于存储标签
y = []
# 使用for循环遍历data,将遍历的数据存储到allInfo变量中
for allInfo in data:
# 提取allInfo中的标签数据
label = allInfo[1]
# 将标签逐一添加到列表y中
y.append(label)
# 输出列表y进行查看
print(y)

完成了第一步提取文本特征和标签后,我们就可以进行第二个步骤啦:将数据集划分为训练集和测试集。
我们可以人为划分数据集,但这样的结果并不够随机和客观。
因此,可以借助sklearn.model_selection这个模块,它包含了划分数据的相关功能。
该模块中有一个train_test_split类,其中的train_test_split()函数,可按照用户设定的比例,将数据集随机划分为训练集和测试集。
举一个简单的示例:假如我们将刚刚提取的电视机评论的文本特征和标签依次传入到train_test_split()函数。
该函数会默认按照3:1的比例,将其分为:
训练集的文本特征和标签
测试集的文本特征和标签
 )
) 
1. 导入模块
首先,需要使用from...import... 从sklearn.model_selection模块中导入train_test_split类。
2. 划分数据集:train_test_split()
导入模块后,就可以使用train_test_split()函数来对数据集进行划分了。调用该函数时,需依次传入文本特征、标签、训练集比例等数据。
必选参数:数据集的文本特征
将需要进行划分的数据集的文本特征X,作为必选参数,传入到train_test_split()函数中。
必选参数:数据集的标签
train_test_split()函数的第二个必选参数,需传入数据集的标签y。
可选参数:训练集大小
通过可选参数train_size来规定训练集的大小。
如果传入的是浮点数,值应在 0.0 和 1.0 之间,表示训练集占数据集的比例;
如果传入的是整数,表示训练集里数据的个数。
train_size=0.8
这里,我们将0.8赋值给train_size,表示将80%的数据集划分为训练集。
可选参数:随机数种子
每次运行程序时,train_test_split()函数都是根据随机数来对数据进行“洗牌”,从而达到随机划分数据的效果。
随机数的产生取决于随机数种子,可以理解为随机数种子是随机数的编号。
也就是说,如果想要每次划分数据的结果保持一致,可以让随机数种子固定。
random_state=1
我们可以设置random_state参数来让每次划分数据的结果保持一致。
这里,我们将random_state参数赋值为1,该数字没有特殊含义,可以换成其它任意整型(int),它相当于一个种子参数,使得每次划分数据的结果一致。
返回的对象
使用train_test_split()函数划分数据集后,我们将结果赋值给变量result,并输出进行查看。

为了方便后续调用,可以通过索引依次提取出列表result中:
训练集的文本特征、测试集的文本特征、训练集的标签和测试集的标签。
我们将它们分别赋值给了变量train_feature、test_feature、train_label和test_label。
我们把测试集的标签test_label输出进行查看。
以上是步骤三的一二小步

![BUU-[GXYCTF2019]Ping Ping Ping](https://img-blog.csdnimg.cn/img_convert/1e92ba03eb96e506cb63f9c509916c5a.png)