这里写目录标题
- 通俗讲解分布式锁:场景和使用方法
- 前言
- 引入业务场景
- 业务场景一出现
- 业务场景二出现:
- 业务场景三出现:
- 分布式锁的使用场景
- 分布式锁的几种特性
- 分布式锁的几种实现方式
- 一、基于 Mysql 实现分布式锁
- 二、基于单Redis节点的分布式锁
- 三、分布式锁 Redlock
- 四、基于zk实现分布式锁
通俗讲解分布式锁:场景和使用方法
前言
对于锁大家肯定不会陌生,比如 synchronized 关键字 和 ReentrantLock 可重入锁,一般我们用其在多线程环境中控制对资源的并发访问。但是随着业务的发展,分布式的概念逐渐出现在我们系统中,我们在开发的过程中经常需要进行多个系统之间的交互,于是上面的加锁方法就会失去作用。于是在分布式锁就自然而然的诞生了,接下来我们来聊一聊分布式锁实现的几种方式。
引入业务场景
业务场景一出现
因为小T刚接手项目,正在吭哧吭哧对熟悉着代码、部署架构。在看代码过程中发现,下单这块代码可能会出现问题,这可是分布式部署的,如果多个用户同时购买同一个商品,就可能导致商品出现 库存超卖 (数据不一致) 现象,对于这种情况代码中并没有做任何控制。
原来一问才知道,以前他们都是售卖的虚拟商品,没啥库存一说,所以当时没有考虑那么多…
这次不一样啊,这次是售卖的实体商品,那就有库存这么一说了,起码要保证不能超过库存设定的数量吧。
小T大眼对着屏幕,屏住呼吸,还好提前发现了这个问题,赶紧想办法修复,不赚钱还赔钱,老板不得疯了,还想不想干了~
业务场景二出现:
小T下面的一位兄弟正在压测,发现个小问题,因为在终端设备上跟鹅厂有紧密合作,调用他们的接口时需要获取到access_token,但是这个access_token过期时间是2小时,过期后需要重新获取。
压测时发现当到达过期时间时,日志看刷出来好几个不一样的access_token,因为这个服务也是分布式部署的,多个节点同时发起了第三方接口请求导致。
虽然以最后一次获取的access_token为准,也没什么不良副作用,但是会导致多次不必要的对第三方接口的调用,也会短时间内造成access_token的 重复无效获取(重复工作)。
业务场景三出现:
下单完成后,还要通知仓储物流,待用户支付完成,支付回调有可能会将多条订单消息发送到MQ,仓储服务会从MQ消费订单消息,此时就要 保证幂等性,对订单消息做 去重 处理。
以上便于大家理解为什么要用分布式锁才能解决,勾勒出的几个业务场景。
上面的问题无一例外,都是针对共享资源要求串行化处理,才能保证安全且合理的操作。
用一张图来体验一下:
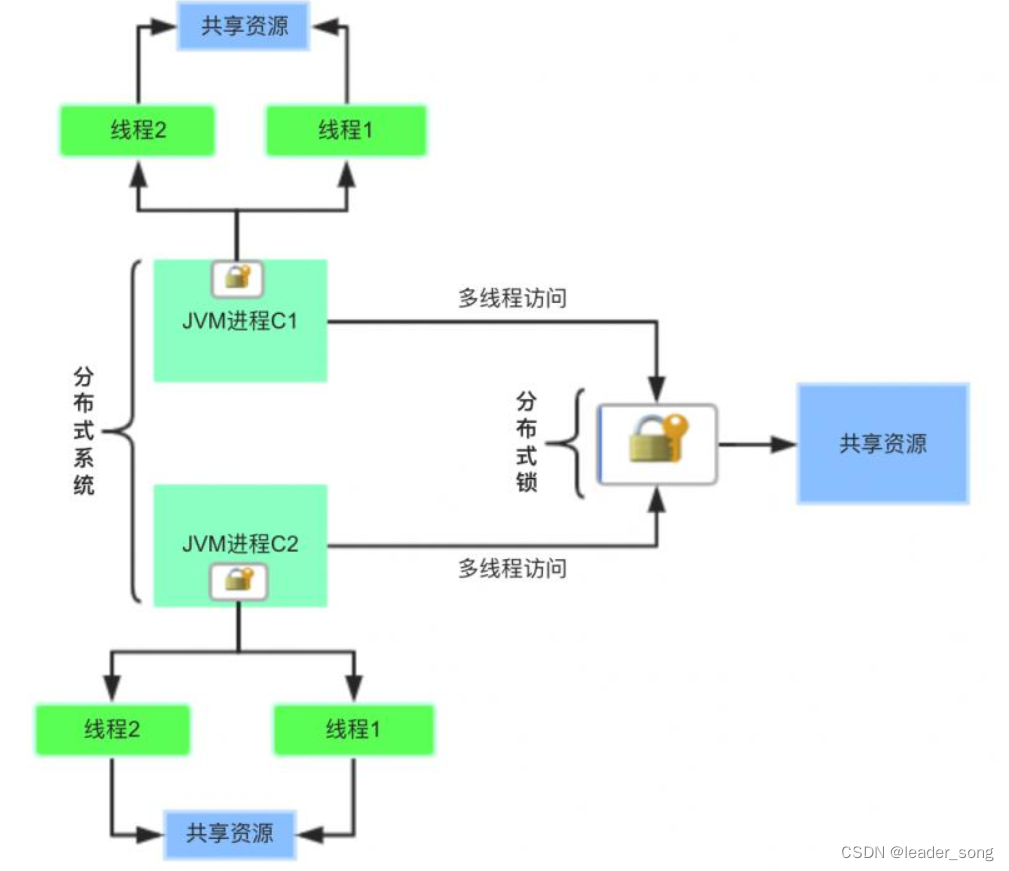
此时,使用Java提供的Synchronized、ReentrantLock、ReentrantReadWriteLock…,仅能在单个JVM进程内对多线程对共享资源保证线程安全,在分布式系统环境下统统都不好使,心情是不是拔凉呀。这个问题得请教 分布式锁 家族来支持一下,听说他们家族内有很多成员,每个成员都有这个分布式锁功能,接下来就开始探索一下。
分布式锁的使用场景
效率性:使用分布式锁可以避免不同节点重复相同的工作。
正确性:分布式锁可以避免破坏正确性的发生,如果两个节点在同一条数据上面操作,比如多个节点机器对同一个订单操作不同的流程有可能会导致该笔订单最后状态出现错误,造成损失。
分布式锁的几种特性
互斥性:和我们本地锁一样互斥性是最基本,但是分布式锁需要保证在不同节点的不同线程的互斥。
可重入性:同一个节点上的同一个线程如果获取了锁之后那么也可以再次获取这个锁。
锁超时:和本地锁一样支持锁超时,防止死锁。
高效,高可用:加锁和解锁需要高效,同时也需要保证高可用防止分布式锁失效,可以增加降级。
支持阻塞和非阻塞:和ReentrantLock一样支持lock和trylock以及tryLock(long timeOut)。
支持公平锁和非公平锁(可选):公平锁的意思是按照请求加锁的顺序获得锁,非公平锁就相反是无序的。
分布式锁的几种实现方式
分布式锁有以下几个方式:
- MySql
- Zk
- Redis
- 一些自研的分布式锁(Chubby)
一、基于 Mysql 实现分布式锁
1、首先,我们需要创建一个锁表:
复制代码
CREATE TABLE `resource_lock` (`id` int(11) unsigned NOT NULL AUTO_INCREMENT,`resource_name` varchar(128) NOT NULL DEFAULT '' COMMENT '资源名称','node_info' varchar(128) DEFAULT '0' COMMENT '节点信息','count' int(11) NOT NULL DEFAULT '0' COMMENT '锁的次数,统计可重入锁','desc' varchar(128) DEFAULT NULL COMMENT '额外的描述信息',`create_time` DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',`update_time` DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间',PRIMARY KEY ('id'),UNIQUE KEY 'un_resource_name' ('resource_name')
) ENGINE=InnoDB DEFAULT CHARSET = utf8mb4;
复制代码
2、lock
先进行查询,如果有值,那么需要比较 node_info 是否一致,这里的 node_info 可以用机器 IP 和线程名字来表示,如果一致那么就加可重入锁 count 的值,如果不一致那么就返回 false 。如果没有值那么直接插入一条数据。伪代码如下:
复制代码
// 添加事务,原子性
@Transaction
public void lock() {if (select * from resource_lock where resource_name = 'xxx' for update;) {// 判断节点信息是否一致if (currentNodeInfo == resultNodeInfo) {// 保住锁的可重入性update resource_lock set count = count + 1 where resource_name = 'xxx';return true;} else {return false;}} else {// 插入新数据insert into resourceLock;return true;}
}
复制代码
3、tryLock
伪代码如下:
复制代码
public boolean tryLock(long timeOut) {long stTime = System.currentTimeMillis();long endTimeOut = stTime + timeOut;while (endTimeOut > stTime) {if (mysqlLock.lock()) {return true;}// 休眠3s后重试LockSupport.parkNanos(1000 * 1000 * 1000 * 1);stTime = System.currentTimeMillis();}return false;
}
复制代码
4、unlock
伪代码如下:
复制代码
@Transaction
public boolean unlock() {// 查询是否有数据if (select * from resource_lock where resource_name = 'xxx' for update;) {// count为1那么可以删除,如果大于1那么需要减去1。if (count > 1) {update count = count - 1;} else {delete;}} else {return false;}
}
复制代码
5、定时清理因为机器宕机导致的锁未被释放的问题
启动一个定时任务,当这个锁远超过任务的执行时间,没有被释放我们就可以认定是节点挂了然后将其直接释放。
二、基于单Redis节点的分布式锁
首先,Redis客户端为了获取锁,向Redis节点发送如下命令:
SET resource_name my_random_value NX PX 30000
上面的命令如果执行成功,则客户端成功获取到了锁,接下来就可以访问共享资源了;而如果上面的命令执行失败,则说明获取锁失败。
注意,在上面的SET命令中:
-
my_random_value是由客户端生成的一个随机字符串,它要保证在足够长的一段时间内在所有客户端的所有获取锁的请求中都是唯一的。
-
NX表示只有当resource_name对应的key值不存在的时候才能SET成功。这保证了只有第一个请求的客户端才能获得锁,而其它客户端在锁被释放之前都无法获得锁。
-
PX 30000表示这个锁有一个30秒的自动过期时间。当然,这里30秒只是一个例子,客户端可以选择合适的过期时间。
最后,当客户端完成了对共享资源的操作之后,执行下面的Redis Lua脚本来释放锁
:
if redis.call("get",KEYS[1]) == ARGV[1] thenreturn redis.call("del",KEYS[1])elsereturn 0end
这段Lua脚本在执行的时候要把前面的my_random_value作为 ARGV[1] 的值传进去,把 resource_name 作为 KEYS[1] 的值传进去。
至此,基于单Redis节点的分布式锁的算法就描述完了。
关键点总结
第一点:过期时间
首先第一个问题,这个锁必须要设置一个过期时间。否则的话,当一个客户端获取锁成功之后,假如它崩溃了,或者由于发生了网络分割(network partition)导致它再也无法和Redis节点通信了,那么它就会一直持有这个锁,而其它客户端永远无法获得锁了,而且把这个过期时间称为锁的有效时间(lock validity time)。获得锁的客户端必须在这个时间之内完成对共享资源的访问。
第二点:获取锁
第二个问题,第一步获取锁的操作,网上不少文章把它实现成了两个Redis命令:
SETNX resource_name my_random_value
EXPIRE resource_name 30
虽然这两个命令和前面算法描述中的一个SET命令执行效果相同,但却不是原子的。如果客户端在执行完SETNX后崩溃了,那么就没有机会执行EXPIRE了,导致它一直持有这个锁。
第三点:my_random_value
第三个问题,设置一个随机字符串 my_random_value 是很有必要的,它保证了一个客户端释放的锁必须是自己持有的那个锁。
假如获取锁时SET的不是一个随机字符串,而是一个固定值,那么可能会发生下面的执行序列:
- 客户端1获取锁成功。
- 客户端1在某个操作上阻塞了很长时间。
- 过期时间到了,锁自动释放了。 客户端2获取到了对应同一个资源的锁。
- 客户端1从阻塞中恢复过来,释放掉了客户端2持有的锁。
- 之后,客户端2在访问共享资源的时候,就没有锁为它提供保护了。
第四点:Lua脚本
第四个问题,释放锁的操作必须使用Lua脚本来实现。释放锁其实包含三步操作:获取、判断和删除,用Lua脚本来实现能保证这三步的原子性。
否则,如果把这三步操作放到客户端逻辑中去执行的话,就有可能发生与前面第三个问题类似的执行序列:
-
客户端1获取锁成功。
-
客户端1访问共享资源。
-
客户端1为了释放锁,先执行’GET’操作获取随机字符串的值。
-
客户端1判断随机字符串的值,与预期的值相等。
-
客户端1由于某个原因阻塞住了很长时间。 过期时间到了,锁自动释放了。
-
客户端2获取到了对应同一个资源的锁。
客户端1从阻塞中恢复过来,执行DEL操纵,释放掉了客户端2持有的锁。
实际上,在上述第三个问题和第四个问题的分析中,如果不是客户端阻塞住了,而是出现了大的网络延迟,也有可能导致类似的执行序列发生。
这四个问题,只要实现分布式锁的时候加以注意,就都能够被正确处理。
但除此之外,还有一个问题,是由 failover(故障转移) 引起的,却是基于单Redis节点的分布式锁无法解决的。正是这个问题催生了Redlock的出现。
多个Redis节点的情况下会产生的问题
这个问题是这样的。假如Redis节点宕机了,那么所有客户端就都无法获得锁了,服务变得不可用。为了提高可用性,我们可以给这个Redis节点挂一个Slave,当Master节点不可用的时候,系统自动切到Slave上(failover)。但由于Redis的主从复制(replication)是异步的,这可能导致在failover过程中丧失锁的安全性。
例如下面的执行序列:
-
客户端1从Master获取了锁。
-
Master宕机了,存储锁的key还没有来得及同步到Slave上。
-
Slave升级为Master。
-
客户端2从新的Master获取到了对应同一个资源的锁。
于是,客户端1和客户端2同时持有了同一个资源的锁。锁的安全性被打破。
三、分布式锁 Redlock
前面介绍的基于单Redis节点的分布式锁在failover的时候会产生解决不了的安全性问题,因此antirez提出了新的分布式锁的算法Redlock,它基于N个完全独立的Redis节点(通常情况下N可以设置成5)。
运行Redlock算法的客户端依次执行下面各个步骤,来完成获取锁的操作:
1、获取当前时间(毫秒数)。
2、按顺序依次向N个Redis节点执行获取锁的操作。这个获取操作跟前面基于单Redis节点的获取锁的过程相同,包含随机字符串my_random_value,也包含过期时间(比如PX 30000,即锁的有效时间)。
为了保证在某个Redis节点不可用的时候算法能够继续运行,这个获取锁的操作还有一个超时时间(time out),它要远小于锁的有效时间(几十毫秒量级)。客户端在向某个Redis节点获取锁失败以后,应该立即尝试下一个Redis节点。
这里的失败,应该包含任何类型的失败,比如该Redis节点不可用,或者该Redis节点上的锁已经被其它客户端持有(注:Redlock原文中这里只提到了Redis节点不可用的情况,但也应该包含其它的失败情况)。
3、计算整个获取锁的过程总共消耗了多长时间,计算方法是用当前时间减去第1步记录的时间。如果客户端从大多数Redis节点(>= N/2+1)成功获取到了锁,并且获取锁总共消耗的时间没有超过锁的有效时间(lock validity time),那么这时客户端才认为最终获取锁成功;否则,认为最终获取锁失败。
4、如果最终获取锁成功了,那么这个锁的有效时间应该重新计算,它等于最初的锁的有效时间减去第3步计算出来的获取锁消耗的时间。
5、如果最终获取锁失败了(可能由于获取到锁的Redis节点个数少于N/2+1,或者整个获取锁的过程消耗的时间超过了锁的最初有效时间),那么客户端应该立即向所有Redis节点发起释放锁的操作(即前面介绍的Redis Lua脚本)。
上面描述的只是获取锁的过程,而释放锁的过程比较简单:客户端向所有Redis节点发起释放锁的操作,不管这些节点当时在获取锁的时候成功与否。
由于N个Redis节点中的大多数能正常工作就能保证Redlock正常工作,因此理论上它的可用性更高。我们前面讨论的单Redis节点的分布式锁在failover的时候锁失效的问题,在Redlock中不存在了,但如果有节点发生崩溃重启,还是会对锁的安全性有影响的。具体的影响程度跟Redis对数据的持久化程度有关。
节点崩溃可能导致的问题
假设一共有5个Redis节点:A, B, C, D, E。设想发生了如下的事件序列:
1、客户端1成功锁住了A, B, C,获取锁成功(但D和E没有锁住)。
2、节点C崩溃重启了,但客户端1在C上加的锁没有持久化下来,丢失了。
3、节点C重启后,客户端2锁住了C, D, E,获取锁成功。
4、这样,客户端1和客户端2同时获得了锁(针对同一资源)。
在默认情况下,Redis的AOF持久化方式是每秒写一次磁盘(即执行fsync),因此最坏情况下可能丢失1秒的数据。为了尽可能不丢数据,Redis允许设置成每次修改数据都进行fsync,但这会降低性能。当然,即使执行了fsync也仍然有可能丢失数据(这取决于系统而不是Redis的实现)。
所以,上面分析的由于节点重启引发的锁失效问题,总是有可能出现的。为了应对这一问题,antirez又提出了延迟重启(delayed restarts)的概念。
也就是说,一个节点崩溃后,先不立即重启它,而是等待一段时间再重启,这段时间应该大于锁的有效时间(lock validity time)。这样的话,这个节点在重启前所参与的锁都会过期,它在重启后就不会对现有的锁造成影响。
客户端应该向所有Redis节点发起释放锁的操作?
在最后释放锁的时候,antirez在算法描述中特别强调,客户端应该向所有Redis节点发起释放锁的操作。也就是说,即使当时向某个节点获取锁没有成功,在释放锁的时候也不应该漏掉这个节点。这是为什么呢?
设想这样一种情况,客户端发给某个Redis节点的获取锁的请求成功到达了该Redis节点,这个节点也成功执行了SET操作,但是它返回给客户端的响应包却丢失了。这在客户端看来,获取锁的请求由于超时而失败了,但在Redis这边看来,加锁已经成功了。
因此,释放锁的时候,客户端也应该对当时获取锁失败的那些Redis节点同样发起请求。实际上,这种情况在异步通信模型中是有可能发生的:客户端向服务器通信是正常的,但反方向却是有问题的。
四、基于zk实现分布式锁
ZooKeeper是以Paxos算法为基础分布式应用程序协调服务。Zk的数据节点和文件目录类似,所以我们可以用此特性实现分布式锁。
基本实现步骤如下:
1、客户端尝试创建一个znode节点,比如/lock。那么第一个客户端就创建成功了,相当于拿到了锁;而其它的客户端会创建失败(znode已存在),获取锁失败。
2、持有锁的客户端访问共享资源完成后,将znode删掉,这样其它客户端接下来就能来获取锁了。
注意:这里的znode应该被创建成ephemeral的(临时节点)。这是znode的一个特性,它保证如果创建znode的那个客户端崩溃了,那么相应的znode会被自动删除。这保证了锁一定会被释放。
可能存在的问题
看起来这个锁相当完美,没有Redlock过期时间的问题,而且能在需要的时候让锁自动释放。但其实也存在这其中也存在问题。
ZooKeeper是怎么检测出某个客户端已经崩溃了呢?
实际上,每个客户端都与ZooKeeper的某台服务器维护着一个Session,这个Session依赖定期的心跳(heartbeat)来维持。如果ZooKeeper长时间收不到客户端的心跳(这个时间称为Sesion的过期时间),那么它就认为Session过期了,通过这个Session所创建的所有的ephemeral类型的znode节点都会被自动删除。
假如按照下面的顺序执行:
1、客户端1创建了znode节点/lock,获得了锁。
2、客户端1进入了长时间的GC pause。
3、客户端1连接到ZooKeeper的Session过期了。znode节点/lock被自动删除。
4、客户端2创建了znode节点/lock,从而获得了锁。
5、客户端1从GC pause中恢复过来,它仍然认为自己持有锁。
由上面的执行顺序,可以发现最后客户端1和客户端2都认为自己持有了锁,冲突了。所以说,用ZooKeeper实现的分布式锁也不一定就是安全的,该有的问题它还是有。
zk的watch机制
ZooKeeper有个很特殊的机制–watch机制。这个机制可以这样来使用,比如当客户端试图创建 /lock 节点的时候,发现它已经存在了,这时候创建失败,但客户端不一定就此对外宣告获取锁失败。
客户端可以进入一种等待状态,等待当/lock节点被删除的时候,ZooKeeper通过watch机制通知它,这样它就可以继续完成创建操作(获取锁)。这可以让分布式锁在客户端用起来就像一个本地的锁一样:加锁失败就阻塞住,直到获取到锁为止。
参考文章
https://www.cnblogs.com/javazhiyin/p/15822051.html
https://www.cnblogs.com/aoshicangqiong/p/12173550.html
https://my.oschina.net/u/1377774/blog/529847