报告链接:Stable Diffusion 3: Research Paper — Stability AI
文章目录
- 要点
- 表现
- 架构细节
- 通过重新加权改善整流流量
- Scaling Rectified Flow Transformer Models
- 灵活的文本编码器
- RF相关论文
引言
随着人工智能技术的飞速发展,文本到图像生成领域正经历着前所未有的变革。Stable Diffusion 3(简称SD3)作为这一领域的最新突破,以其卓越的性能和创新的技术架构,引起了业界的广泛关注。本报告旨在全面介绍Stable Diffusion 3的技术特点、创新点以及市场应用前景。
要点
- 发布研究论文,深入探讨Stable Diffuison 3的底层技术
- 基于人类偏好评估,Stable Diffusion 3 在排版和提示遵守方面优于最先进的文本到图像生成系统,例如 DALL·E 3、Midjourney v6 和 Ideogram v1
- 新的多模态扩散Transformer (MMDiT) 架构对图像和语言表示使用单独的权重集合,与以前版本的 SD3 相比,这提高了文本理解和拼写能力
继宣布 Stable Diffusion 3 的早期预览版之后,又发布了一份研究论文,概述了即将发布的模型的技术细节。
技术概述
Stable Diffusion 3采用了与Sora相同的DiT(Diffusion Transformer)架构,并在排版和提示遵守方面表现优于DALL·E 3、Midjourney v6和Ideogram v1等最先进的文本到图像生成系统。SD3模型套件的参数范围在800M和8B之间,为用户提供了从轻量级到高性能的不同选择,以满足不同场景的创意需求。
SD3的核心技术是多模态扩散变换器(MMDiT)架构,它使用分离权重集合来处理图像和语言表示,相比之前的版本,显著改善了文本理解和拼写能力。MMDiT架构结合了DiT和矩形流(RF)形式,使用两个独立的变换器来处理文本和图像嵌入,并在注意力操作中结合两种模态的序列。这种设计不仅提高了模型的文本理解能力,还增强了图像合成的细节处理和风格多样性。

以 SD3 作为基线,根据人类对视觉美学、提示跟随和版式的评估,概述其与竞争模型对比情况
将 Stable Diffusion 3 的输出图像与其他各种开放模型(包括 SDXL、SDXL Turbo、Stable Cascade、Playground v2.5 和 Pixart-α)以及闭源系统(如 DALL·E 3、Midjourney v6 和 Ideogram v1)进行基于人类反馈的性能对比。在这些测试中,向人类评估者提供了每个模型的示例输出,并要求他们根据模型输出与提示上下文的紧密程度(“提示跟随”)、基于提示的文本呈现程度(“排版”)以及哪幅图像具有更高的美学质量(“视觉美学”)来选择最佳结果。
测试结果表明Stable Diffusion 3在所有上述领域都等于或优于当前最先进的文本到图像生成系统。在早期的消费者硬件上进行的未优化推理测试中,最大的SD3模型具有8B个参数,适合RTX 4090的24GB VRAM,当使用50个采样步骤时,需要34秒能生成分辨率为1024x1024的图像。此外,Stable Diffusion 3在首次发布期间将有多种变体,从800M到8B的参数模型,以进一步消除硬件障碍。
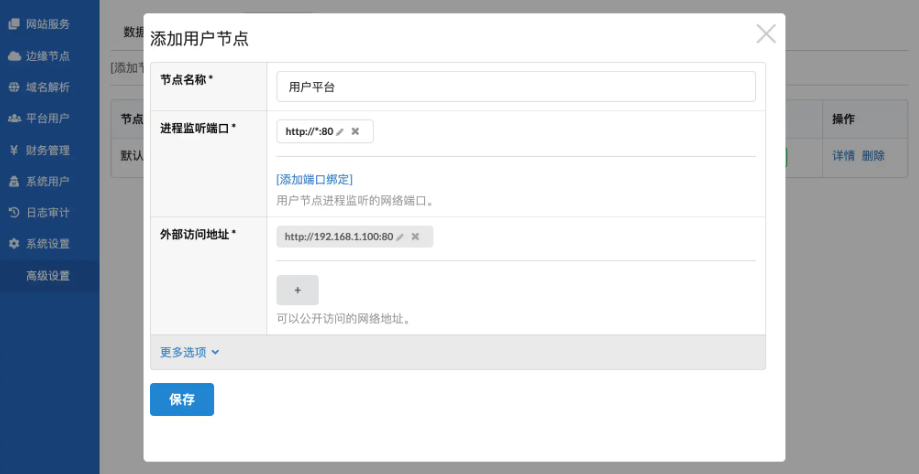
架构细节
对于文本到图像的生成,SD3模型考虑文本和图像这两种模式,这是为什么将这种新架构称为 MMDiT,指的是它处理多种模式的能力。与之前版本的稳定扩散一样,使用预训练模型来导出合适的文本和图像表示。具体来说,SD3使用三种不同的文本嵌入器(两个 CLIP 模型和 T5)来编码文本表示,并使用改进的自动编码模型来编码图像tokens。
MMDIT
SD3 架构建立在 DiT 的基础上。由于文本和图像嵌入在概念上完全不同,因此对这两种模式使用两组独立的权重。如上图所示,这相当于每种模态都有两个独立的Transformers,但是将两种模态的序列连接起来进行注意力操作,这样两种表示都可以在自己的空间中工作,同时考虑另一种表示。
训练过程中测量视觉保真度和文本对齐,MMDiT 架构优于已建立的文本到图像主干,UViT 和 DiT
通过使用这种方法,信息可以在图像和文本标记之间流动,以提高生成的输出中的整体理解和排版。正如在论文中讨论的那样,这种架构还可以轻松扩展到视频等多种模式。
得益于 Stable Diffusion 3 改进的提示跟随功能,模型能够创建专注于各种不同主题和质量的图像,同时对图像本身的风格保持高度灵活性。

技术创新
Stable Diffusion 3的技术创新主要体现在以下几个方面:
- Rectified Flow模型的优化:SD3对Rectified Flow模型的训练方法进行了改进,通过引入感知相关的尺度偏差,优化了噪声采样过程。这使得模型在图像合成上的表现更加精准和高效,从而在高分辨率文本到图像合成方面取得了比传统扩散模型更优越的性能。
- Transformer架构的创新:新提出的Transformer架构通过分离图像和文本的权重流,实现了两者之间的双向交互。这种设计不仅提高了模型对文本的理解能力,还增强了图像合成的细节处理和风格多样性。此外,MMDiT架构还可以扩展到多模态数据,如视频等,为未来的应用提供了更广阔的空间。
- 内存密集型T5文本编码器的移除:在SD3中,移除了内存密集型的T5文本编码器,显著减少了模型的内存需求,同时仅伴随少量性能损失。这一改进使得SD3能够更高效地运行在消费者硬件上,降低了使用门槛。
通过重新加权改善整流流量
Stable Diffusion 3 采用整流流 (RF) 公式,其中数据和噪声在训练期间以线性轨迹连接。这会产生更直的推理路径,从而允许用更少的步骤进行采样。此外,在训练过程中引入了一种新颖的轨迹采样计划。这个schedule给予轨迹的中间部分更多的权重,因为假设这些部分会导致更具挑战性的预测任务。使用多个数据集、指标和采样器设置进行比较,针对 60 个其他扩散轨迹(例如 LDM、EDM 和 ADM)对比测试。结果表明,虽然以前的 RF 公式在少步采样方案中表现出改进的性能,但它们的相对性能随着步数的增加而下降。相比之下,重新加权的 RF 变体不断提高性能。
Scaling Rectified Flow Transformer Models

使用重新加权的整流流公式和 MMDiT 主干对文本到图像的合成进行了缩放研究。训练模型范围从具有 15 个blocks的450M 参数到具体 38 个blocks的 8B 参数,并观察到验证损失随着模型大小和训练步骤的函数而平滑下降(上行)。为了测试这是否转化为模型输出的有意义的改进,还评估了自动图像对齐指标 (GenEval) 以及人类偏好评分 (ELO)(下行)。结果表明这些指标与验证损失之间存在很强的相关性,表明后者是整体模型性能的有力预测因子。此外,扩展趋势没有显示出饱和的迹象,可乐观地认为未来可以继续提高模型的性能。
灵活的文本编码器
通过移除用于推理的内存密集型 4.7B 参数 T5 文本编码器,SD3 的内存需求可以显着降低,而性能损失很小。删除此文本编码器不会影响视觉美感(无 T5 的胜率:50%),只会导致文本依从性略有下降(胜率 46%),如上图“性能”部分下所示。然而,建议包括 T5,以充分利用 SD3 生成书面文本的能力,因为观察到,如果没有 T5,版式生成的性能会大幅下降(胜率 38%),如下例所示:
RF相关论文
- Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow
- Building Normalizing Flows with Stochastic Interpolants
- Flow Matching for Generative Modeling
市场应用前景
Stable Diffusion 3在文本到图像生成领域的卓越性能和创新技术架构,为其在市场上的广泛应用提供了有力支持。以下是SD3可能的应用场景:
- 创意设计:设计师可以利用SD3将文本描述快速转化为高质量的图像素材,提高设计效率和质量。SD3对文本理解和图像生成的精准控制,使得生成的图像更符合设计师的创意需求。
- 广告营销:在广告营销领域,SD3可以根据广告文案快速生成符合品牌形象和宣传需求的图像素材。这种快速、高效的图像生成方式可以大大缩短广告制作周期,降低制作成本。
- 娱乐产业:在游戏、动漫等娱乐产业中,SD3可以根据剧情和角色设定快速生成高质量的图像素材。这种技术可以加速游戏开发和动漫制作流程,提高产品质量和用户体验。
- 教育培训:在教育培训领域,SD3可以帮助学生更好地理解抽象概念和复杂知识。通过将文本描述转化为直观的图像素材,可以帮助学生更快地掌握知识和技能。
Stable Diffusion 3作为文本到图像生成领域的新里程碑,以其卓越的性能和创新的技术架构,为市场带来了全新的发展机遇。随着技术的不断发展和优化,相信SD3将在未来为更多领域和行业带来深刻的变革和创新。
本文参考文章:Stable Diffusion 3报告_stable diffusion 3: research paper-CSDN博客
精彩文章合辑
基于AARRR模型的录音笔在电商平台进行推广的建议-CSDN博客
【附gpt4.0升级秘笈】AutoCoder进化:本地Rag知识库引领智能编码新时代-CSDN博客
【附gpt4.0升级秘笈】OpenAI 重磅官宣免登录用 ChatGPT_openai 4.0 免费-CSDN博客
【附升级gpt4.0方案】探索人工智能在医疗领域的革命-CSDN博客
【文末 附 gpt4.0升级秘笈】超越Sora极限,120秒超长AI视频模型诞生-CSDN博客
【附gpt4.0升级秘笈】身为IT人,你为何一直在“高强度的工作节奏”?-CSDN博客
【文末附gpt升级4.0方案】英特尔AI PC的局限性是什么-CSDN博客
【文末附gpt升级4.0方案】FastGPT详解_fastgpt 文件处理模型-CSDN博客
大模型“说胡话”现象辨析_为什么大语言模型会胡说-CSDN博客
英伟达掀起AI摩尔时代浪潮,Blackwell GPU引领新篇章-CSDN博客
如何订阅Midjourney_midjourney付费方式-CSDN博客
睡前故事001:代码的梦境-CSDN博客