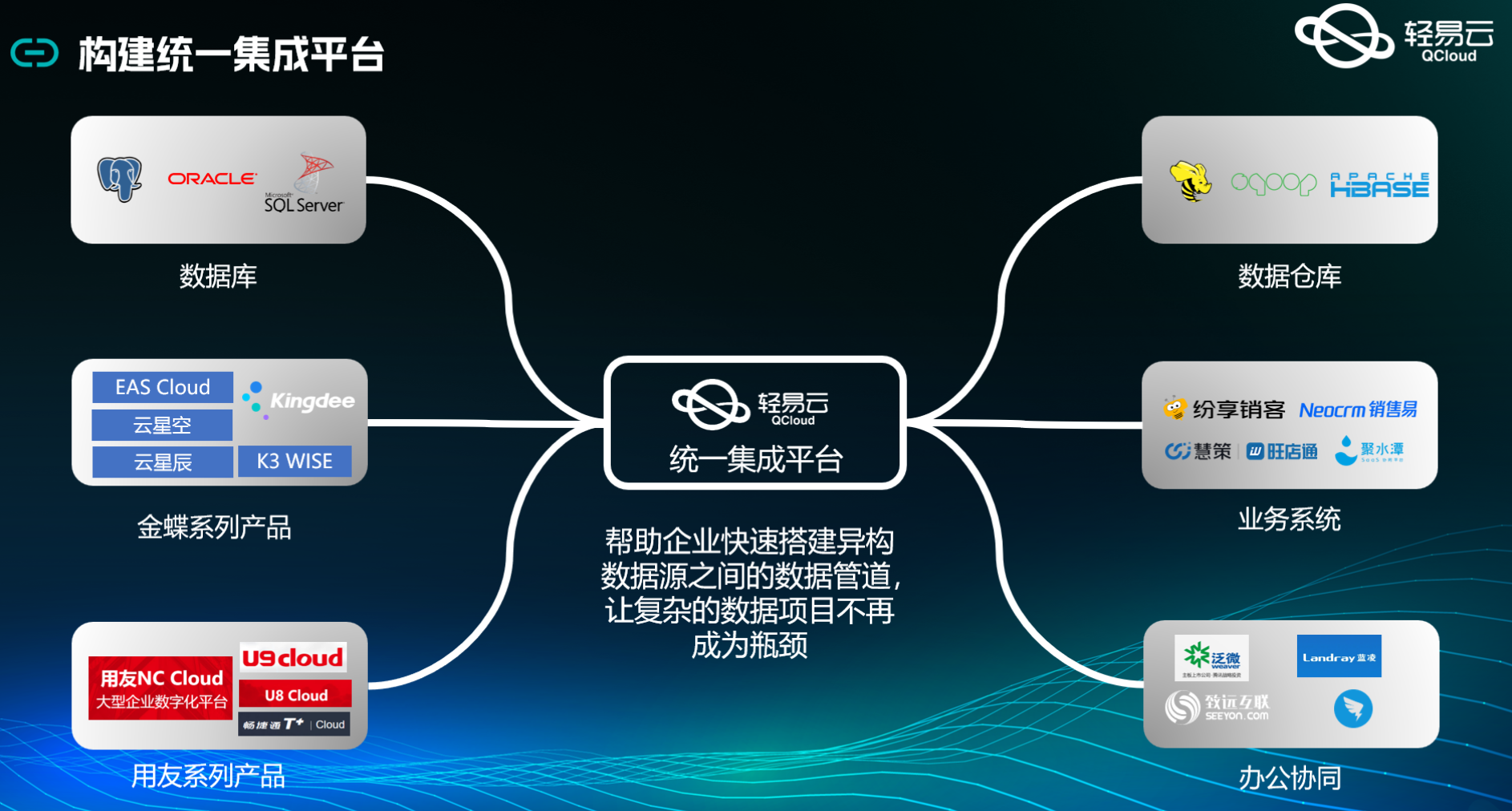
以下是一些常见的大模型的详细介绍,包括 LLaMA2、LLaMA3、BLOOM、BERT、Falcon 180B、Mistral 7B、OpenHermes、GPT-NeoX-20B、Pythia、OpenLLaMA、OlMA、GPT-4 系列、Claude-3、GLM-4、文心一言、通义千问、Abad6、qwen 等模型。
1. LLaMA2
定义和来源: LLaMA2 是 LLaMA(Large Language Model Meta AI)的第二代模型,由 Meta(前身为 Facebook)开发。
功能特点:
- 改进的架构:采用更深的网络结构和更高效的注意力机制。
- 高效训练:通过优化的训练方法和数据增强技术,提高训练效率。
- 多任务学习:支持多任务学习,适应不同的应用场景。
擅长场景:
- 自然语言处理:文本生成、机器翻译、文本分类等。
- 对话系统:聊天机器人、虚拟助手等。
- 内容生成:文章、故事、新闻报道等。
优缺点:
- 优点:高效训练、多任务学习、适应性强。
- 缺点:需要大量计算资源和数据进行训练。
2. LLaMA3
定义和来源: LLaMA3 是 LLaMA 系列的第三代模型,进一步提升了模型的性能和扩展性。
功能特点:
- 更深的网络结构:采用更深的网络结构,提升模型的表示能力。
- 高效推理:通过优化的推理算法和硬件加速技术,提高推理速度。
- 多模态支持:支持文本、图像、音频等多种模态的数据处理。
擅长场景:
- 自然语言处理:文本生成、机器翻译、文本分类等。
- 多模态生成:图像生成、音频生成、视频生成等。
- 内容生成:文章、故事、新闻报道等。
优缺点:
- 优点:高效推理、多模态支持、适应性强。
- 缺点:需要大量计算资源和数据进行训练。
3. BLOOM
定义和来源: BLOOM 是一个开源的大型语言模型,由 BigScience 团队开发,旨在推动开放科学和开放数据的研究。
功能特点:
- 开源:BLOOM 是一个开源项目,提供了模型的代码和数据。
- 多语言支持:支持多种语言的文本生成和处理。
- 社区驱动:由全球研究人员和开发者共同参与和贡献。
擅长场景:
- 自然语言处理:文本生成、机器翻译、文本分类等。
- 对话系统:聊天机器人、虚拟助手等。
- 内容生成:文章、故事、新闻报道等。
优缺点:
- 优点:开源、多语言支持、社区驱动。
- 缺点:性能可能不如一些专有模型。
4. BERT
定义和来源: BERT(Bidirectional Encoder Representations from Transformers)是由 Google 开发的预训练语言模型,通过双向编码器表示捕捉上下文信息。
功能特点:
- 双向编码:通过双向编码器表示,捕捉上下文信息。
- 预训练和微调:在大规模数据集上进行预训练,然后在特定任务上进行微调。
- 高效:在多种自然语言处理任务中表现出色。
擅长场景:
- 自然语言处理:文本分类、命名实体识别、问答系统等。
- 信息检索:文档检索、信息抽取等。
- 对话系统:聊天机器人、虚拟助手等。
优缺点:
- 优点:双向编码、高效、适应性强。
- 缺点:需要大量计算资源和数据进行预训练。
5. Falcon 180B
定义和来源: Falcon 180B 是一个大规模的语言模型,具有 1800 亿参数,专为高性能自然语言处理任务设计。
功能特点:
- 大规模参数:具有 1800 亿参数,能够捕捉复杂的语言模式。
- 高性能:在多种自然语言处理任务中表现出色。
- 多任务学习:支持多任务学习,适应不同的应用场景。
擅长场景:
- 自然语言处理:文本生成、机器翻译、文本分类等。
- 对话系统:聊天机器人、虚拟助手等。
- 内容生成:文章、故事、新闻报道等。
优缺点:
- 优点:大规模参数、高性能、多任务学习。
- 缺点:需要大量计算资源和数据进行训练。
6. Mistral 7B
定义和来源: Mistral 7B 是一个具有 70 亿参数的语言模型,专为高效自然语言处理任务设计。
功能特点:
- 高效:通过优化的架构和训练方法,提高模型的效率。
- 多任务学习:支持多任务学习,适应不同的应用场景。
- 灵活性:适用于多种自然语言处理任务。
擅长场景:
- 自然语言处理:文本生成、机器翻译、文本分类等。
- 对话系统:聊天机器人、虚拟助手等。
- 内容生成:文章、故事、新闻报道等。
优缺点:
- 优点:高效、多任务学习、灵活性强。
- 缺点:需要大量计算资源和数据进行训练。
7. OpenHermes
定义和来源: OpenHermes 是一个开源的大型语言模型,旨在推动开放科学和开放数据的研究。
功能特点:
- 开源:OpenHermes 是一个开源项目,提供了模型的代码和数据。
- 多语言支持:支持多种语言的文本生成和处理。
- 社区驱动:由全球研究人员和开发者共同参与和贡献。
擅长场景:
- 自然语言处理:文本生成、机器翻译、文本分类等。
- 对话系统:聊天机器人、虚拟助手等。
- 内容生成:文章、故事、新闻报道等。
优缺点:
- 优点:开源、多语言支持、社区驱动。
- 缺点:性能可能不如一些专有模型。
8. GPT-NeoX-20B
定义和来源: GPT-NeoX-20B 是一个具有 200 亿参数的语言模型,由 EleutherAI 开发,旨在推动开放科学和开放数据的研究。
功能特点:
- 大规模参数:具有 200 亿参数,能够捕捉复杂的语言模式。
- 开源:GPT-NeoX-20B 是一个开源项目,提供了模型的代码和数据。
- 高性能:在多种自然语言处理任务中表现出色。
擅长场景:
- 自然语言处理:文本生成、机器翻译、文本分类等。
- 对话系统:聊天机器人、虚拟助手等。
- 内容生成:文章、故事、新闻报道等。
优缺点:
- 优点:大规模参数、开源、高性能。
- 缺点:需要大量计算资源和数据进行训练。
9. Pythia
定义和来源: Pythia 是一个开源的大型语言模型,旨在推动开放科学和开放数据的研究。
功能特点:
- 开源:Pythia 是一个开源项目,提供了模型的代码和数据。
- 多语言支持:支持多种语言的文本生成和处理。
- 社区驱动:由全球研究人员和开发者共同参与和贡献。
擅长场景:
- 自然语言处理:文本生成、机器翻译、文本分类等。
- 对话系统:聊天机器人、虚拟助手等。
- 内容生成:文章、故事、新闻报道等。
优缺点:
- 优点:开源、多语言支持、社区驱动。
- 缺点:性能可能不如一些专有模型。
10. OpenLLaMA
定义和来源: OpenLLaMA 是一个开源的大型语言模型,旨在推动开放科学和开放数据的研究。
功能特点:
- 开源:OpenLLaMA 是一个开源项目,提供了模型的代码和数据。
- 多语言支持:支持多种语言的文本生成和处理。
- 社区驱动:由全球研究人员和开发者共同参与和贡献。
擅长场景:
- 自然语言处理:文本生成、机器翻译、文本分类等。
- 对话系统:聊天机器人、虚拟助手等。
- 内容生成:文章、故事、新闻报道等。
优缺点:
- 优点:开源、多语言支持、社区驱动。
- 缺点:性能可能不如一些专有模型。
11. OlMA
定义和来源: OlMA 是一个开源的大型语言模型,旨在推动开放科学和开放数据的研究。
功能特点:
- 开源:OlMA 是一个开源项目,提供了模型的代码和数据。
- 多语言支持:支持多种语言的文本生成和处理。
- 社区驱动:由全球研究人员和开发者共同参与和贡献。
擅长场景:
- 自然语言处理:文本生成、机器翻译、文本分类等。
- 对话系统:聊天机器人、虚拟助手等。
- 内容生成:文章、故事、新闻报道等。
优缺点:
- 优点:开源、多语言支持、社区驱动。
- 缺点:性能可能不如一些专有模型。
12. GPT-4 系列
定义和来源: GPT-4 系列是 OpenAI 开发的第四代生成预训练变换器(GPT)模型,具有更高的参数量和更强的生成能力。
功能特点:
- 大规模参数:具有更高的参数量,能够捕捉复杂的语言模式。
- 高性能:在多种自然语言处理任务中表现出色。
- 多任务学习:支持多任务学习,适应不同的应用场景。
擅长场景:
- 自然语言处理:文本生成、机器翻译、文本分类等。
- 对话系统:聊天机器人、虚拟助手等。
- 内容生成:文章、故事、新闻报道等。
优缺点:
- 优点:大规模参数、高性能、多任务学习。
- 缺点:需要大量计算资源和数据进行训练。
13. Claude-3
定义和来源: Claude-3 是一个大规模的语言模型,专为高性能自然语言处理任务设计。
功能特点:
- 大规模参数:具有更高的参数量,能够捕捉复杂的语言模式。
- 高性能:在多种自然语言处理任务中表现出色。
- 多任务学习:支持多任务学习,适应不同的应用场景。
擅长场景:
- 自然语言处理:文本生成、机器翻译、文本分类等。
- 对话系统:聊天机器人、虚拟助手等。
- 内容生成:文章、故事、新闻报道等。
优缺点:
- 优点:大规模参数、高性能、多任务学习。
- 缺点:需要大量计算资源和数据进行训练。
14. GLM-4
定义和来源: GLM-4 是一个大规模的语言模型,专为高性能自然语言处理任务设计。
功能特点:
- 大规模参数:具有更高的参数量,能够捕捉复杂的语言模式。
- 高性能:在多种自然语言处理任务中表现出色。
- 多任务学习:支持多任务学习,适应不同的应用场景。
擅长场景:
- 自然语言处理:文本生成、机器翻译、文本分类等。
- 对话系统:聊天机器人、虚拟助手等。
- 内容生成:文章、故事、新闻报道等。
优缺点:
- 优点:大规模参数、高性能、多任务学习。
- 缺点:需要大量计算资源和数据进行训练。
15. 文心一言
定义和来源: 文心一言 是百度开发的一个大规模语言模型,专为中文自然语言处理任务设计。
功能特点:
- 中文支持:专为中文自然语言处理任务设计,具有较强的中文理解和生成能力。
- 高性能:在多种中文自然语言处理任务中表现出色。
- 多任务学习:支持多任务学习,适应不同的应用场景。
擅长场景:
- 自然语言处理:文本生成、机器翻译、文本分类等。
- 对话系统:聊天机器人、虚拟助手等。
- 内容生成:文章、故事、新闻报道等。
优缺点:
- 优点:中文支持、高性能、多任务学习。
- 缺点:需要大量计算资源和数据进行训练。
16. 通义千问
定义和来源: 通义千问 是阿里巴巴开发的一个大规模语言模型,专为中文自然语言处理任务设计。
功能特点:
- 中文支持:专为中文自然语言处理任务设计,具有较强的中文理解和生成能力。
- 高性能:在多种中文自然语言处理任务中表现出色。
- 多任务学习:支持多任务学习,适应不同的应用场景。
擅长场景:
- 自然语言处理:文本生成、机器翻译、文本分类等。
- 对话系统:聊天机器人、虚拟助手等。
- 内容生成:文章、故事、新闻报道等。
优缺点:
- 优点:中文支持、高性能、多任务学习。
- 缺点:需要大量计算资源和数据进行训练。
17. Abad6
定义和来源: Abad6 是一个大规模的语言模型,专为高性能自然语言处理任务设计。
功能特点:
- 大规模参数:具有更高的参数量,能够捕捉复杂的语言模式。
- 高性能:在多种自然语言处理任务中表现出色。
- 多任务学习:支持多任务学习,适应不同的应用场景。
擅长场景:
- 自然语言处理:文本生成、机器翻译、文本分类等。
- 对话系统:聊天机器人、虚拟助手等。
- 内容生成:文章、故事、新闻报道等。
优缺点:
- 优点:大规模参数、高性能、多任务学习。
- 缺点:需要大量计算资源和数据进行训练。
18. qwen
定义和来源: qwen 是一个大规模的语言模型,专为高性能自然语言处理任务设计。
功能特点:
- 大规模参数:具有更高的参数量,能够捕捉复杂的语言模式。
- 高性能:在多种自然语言处理任务中表现出色。
- 多任务学习:支持多任务学习,适应不同的应用场景。
擅长场景:
- 自然语言处理:文本生成、机器翻译、文本分类等。
- 对话系统:聊天机器人、虚拟助手等。
- 内容生成:文章、故事、新闻报道等。
优缺点:
- 优点:大规模参数、高性能、多任务学习。
- 缺点:需要大量计算资源和数据进行训练。









![[代码随想录Day21打卡] 669. 修剪二叉搜索树 108.将有序数组转换为二叉搜索树 538.把二叉搜索树转换为累加树 总结篇](https://i-blog.csdnimg.cn/direct/b412a127af824b0290cb1ce13a98745b.png)