Python数据读入篇
前置条件:
- GEE预处理影像导出保存为tfrecord的数据包,并下载到本地
- tensorflow的深度学习环境
本篇文章的目的主要是把Tfrecord格式的数据加载为tf可使用的数据集格式
设定超参数
首先需要设定导出时的波段名称和数据格式,用于解析数据。
变量名:
- KERNEL_SIZE :单个patch的大小
- FEATURES:波段的名称
- dtype=tf.float32 :数据格式
# 所有波段的名称
BANDS = ["B2","B3","B4","B5","B6","B7","B8","B8A","B11","B12"]
TIMES = 12
ALLBANDS = [ "%d_"%(i)+s for i in range(TIMES) for s in BANDS ]
print('所有的波段名称为:',ALLBANDS)
RESPONSE = 'soya'
FEATURES = ALLBANDS + [RESPONSE]
#输出:
#所有的波段名称为: ['0_B2', '0_B3', '0_B4', '0_B5', '0_B6', '0_B7', '0_B8', '0_B8A', '0_B11', '0_B12', '1_B2', '1_B3', '1_B4', '1_B5', '1_B6', '1_B7', '1_B8', '1_B8A', '1_B11', '1_B12', '2_B2', '2_B3', '2_B4', '2_B5', '2_B6', '2_B7', '2_B8', '2_B8A', '2_B11', '2_B12', '3_B2', '3_B3', '3_B4', '3_B5', '3_B6', '3_B7', '3_B8', '3_B8A', '3_B11', '3_B12', '4_B2', '4_B3', '4_B4', '4_B5', '4_B6', '4_B7', '4_B8', '4_B8A', '4_B11', '4_B12', '5_B2', '5_B3', '5_B4', '5_B5', '5_B6', '5_B7', '5_B8', '5_B8A', '5_B11', '5_B12', '6_B2', '6_B3', '6_B4', '6_B5', '6_B6', '6_B7', '6_B8', '6_B8A', '6_B11', '6_B12', '7_B2', '7_B3', '7_B4', '7_B5', '7_B6', '7_B7', '7_B8', '7_B8A', '7_B11', '7_B12', '8_B2', '8_B3', '8_B4', '8_B5', '8_B6', '8_B7', '8_B8', '8_B8A', '8_B11', '8_B12', '9_B2', '9_B3', '9_B4', '9_B5', '9_B6', '9_B7', '9_B8', '9_B8A', '9_B11', '9_B12', '10_B2', '10_B3', '10_B4', '10_B5', '10_B6', '10_B7', '10_B8', '10_B8A', '10_B11', '10_B12', '11_B2', '11_B3', '11_B4', '11_B5', '11_B6', '11_B7', '11_B8', '11_B8A', '11_B11', '11_B12','soya']# 单个patch的大小和数据类型
KERNEL_SIZE = 64
KERNEL_SHAPE = [KERNEL_SIZE, KERNEL_SIZE]
COLUMNS = [tf.io.FixedLenFeature(shape=KERNEL_SHAPE, dtype=tf.float32) for k in FEATURES
]
FEATURES_DICT = dict(zip(FEATURES, COLUMNS))# 单个数据包中样本的数量
BUFFER_SIZE = 160
解析数据
编写解析数据包的函数
parse_tfrecord( )和get_dataset( )函数是基本固定的
to_HWTCtuple(inputs)函数可根据自己的数据格式进行修改。数据的归一化和标准化、拓展特征等处理操作都可以放在此函数里。本文此处仅仅将折叠120维的数据展开为12(时相)×10(波段),数据集单个样本(HWTC格式)的大小为此时64×64×12×10。
def parse_tfrecord(example_proto):"""The parsing function.Read a serialized example into the structure defined by FEATURES_DICT.Args:example_proto: a serialized Example.Returns:A dictionary of tensors, keyed by feature name."""return tf.io.parse_single_example(example_proto, FEATURES_DICT)
def to_HWTCtuple(inputs):"""Function to convert a dictionary of tensors to a tuple of (inputs, outputs).Turn the tensors returned by parse_tfrecord into a stack in HWCT shape.Args:inputs: A dictionary of tensors, keyed by feature name.Returns:A tuple of (inputs, outputs)."""# 读取出多时相多波段影像inputsList = [inputs.get(key) for key in ALLBANDS]label = inputs.get(RESPONSE)stacked = tf.stack(inputsList, axis=0)# 从通道维展开出时间维,TIMES在前,len(BANDS)在后,不可以反#stacked = tf.reshape(stacked, [12,10,KERNEL_SIZE, KERNEL_SIZE])stacked = tf.reshape(stacked, [TIMES,len(BANDS),KERNEL_SIZE, KERNEL_SIZE])# Convert from TCHW to HWTCstacked = tf.transpose(stacked, [2,3,0,1])return stacked, label
def get_dataset(namelist):"""Function to read, parse and format to tuple a set of input tfrecord files.Get all the files matching the pattern, parse and convert to tuple.Args:namelist: A file list in a Cloud Storage bucket.Returns:A tf.data.Dataset"""dataset = tf.data.TFRecordDataset(namelist, compression_type='GZIP')dataset = dataset.map(parse_tfrecord, num_parallel_calls=5)dataset = dataset.map(to_HWTCtuple, num_parallel_calls=5)return dataset
编写训练集和验证机的加载函数,根据自己的需求加载指定路径的数据包。BATCH_SIZE可根据自己GPU显存设置,此处为8
trainPath = 'data/guoyang/training_patches_g%d.tfrecord.gz'
trainIndex = [14,20,19,25,13,31,24,15,18,7,30,26,21,29,16,8,28,27,12,11,17,33,4,32,9,10,22]
training_patches_size = 27
BATCH_SIZE = 8
def get_training_dataset():"""Get the preprocessed training datasetReturns: A tf.data.Dataset of training data."""namelist = [trainPath%(i) for i in trainIndex]dataset = get_dataset(namelist)dataset = dataset.shuffle(BUFFER_SIZE).batch(BATCH_SIZE,drop_remainder=True).repeat()return datasetevalPath = 'data/guoyang/eval_patches_g%d.tfrecord.gz'
evalIndex = [9,12,13,3,5,1,6,4,2]
eval_patches_size = 9
EVAL_BATCH_SIZE = 8
def get_eval_dataset():"""Get the preprocessed evaluation datasetReturns: A tf.data.Dataset of evaluation data."""namelist = [evalPath%(i) for i in evalIndex]dataset = get_dataset(namelist)dataset = dataset.batch(EVAL_BATCH_SIZE,drop_remainder=True).repeat()return datasetevaluation = get_eval_dataset()training = get_training_dataset()
读取单个样本,测试数据集是否加载成功。
data,label = iter(training.take(1)).next()
i = 3
print(data.shape)
#(8, 64, 64, 12, 10)
可视化
首先编写并测试显示所需要的函数。
#测试显示函数
import tensorflow as tf
import matplotlib.pyplot as plt
import numpy as np
from PIL import Image
from matplotlib.colors import ListedColormapdef show_image(tensor,index ,savename =None):# 从HWTC到THWCtensor = np.transpose(tensor, (2, 0,1,3))# 获取 tensor 中每个通道的数据r_channel = tensor[:, :, :, index[0]-2] # 红色通道g_channel = tensor[:, :, :, index[1]-2] # 绿色通道b_channel = tensor[:, :, :, index[2]-2] # 蓝色通道# 将通道的数据拼接成一个 RGB 图像image = np.stack([r_channel, g_channel, b_channel], axis=3)# 定义一个变量来保存图片数量num_images = image.shape[0]# 定义每行显示的图片数量num_images_per_row = 4# 计算行数和列数num_rows = int(np.ceil(num_images / num_images_per_row))num_columns = num_images_per_row# 定义画布的大小fig, axes = plt.subplots(num_rows, num_columns, figsize=(15, 15))# 展示每张图片for i, ax in enumerate(axes.flat):# 如果图片数量不足,则跳过if i >= num_images:break# 分别计算每个波段的%2的像素值img = image[i]vmin_b1, vmax_b1 = np.percentile(img[:, :, 0], (2, 98))vmin_b2, vmax_b2 = np.percentile(img[:, :, 1], (2, 98))vmin_b3, vmax_b3 = np.percentile(img[:, :, 2], (2, 98))# 线性拉伸每个波段并合并为RGB彩色图像image_r = np.interp(img[:, :, 0], (vmin_b1, vmax_b1), (0, 1))image_g = np.interp(img[:, :, 1], (vmin_b2, vmax_b2), (0, 1))image_b = np.interp(img[:, :, 2], (vmin_b3, vmax_b3), (0, 1))image_rgb = np.dstack((image_r, image_g, image_b))# 显示图片ax.imshow(image_rgb)if savename:Image.fromarray(np.uint8(image_rgb*255)).save(f"img/{savename}_{i}.png") #.resize((512,512),resample = Image.NEAREST)ax.set_title('TimeSeries Image%d'%(i))# 关闭刻度线ax.axis('off')# 展示所有图片plt.show()
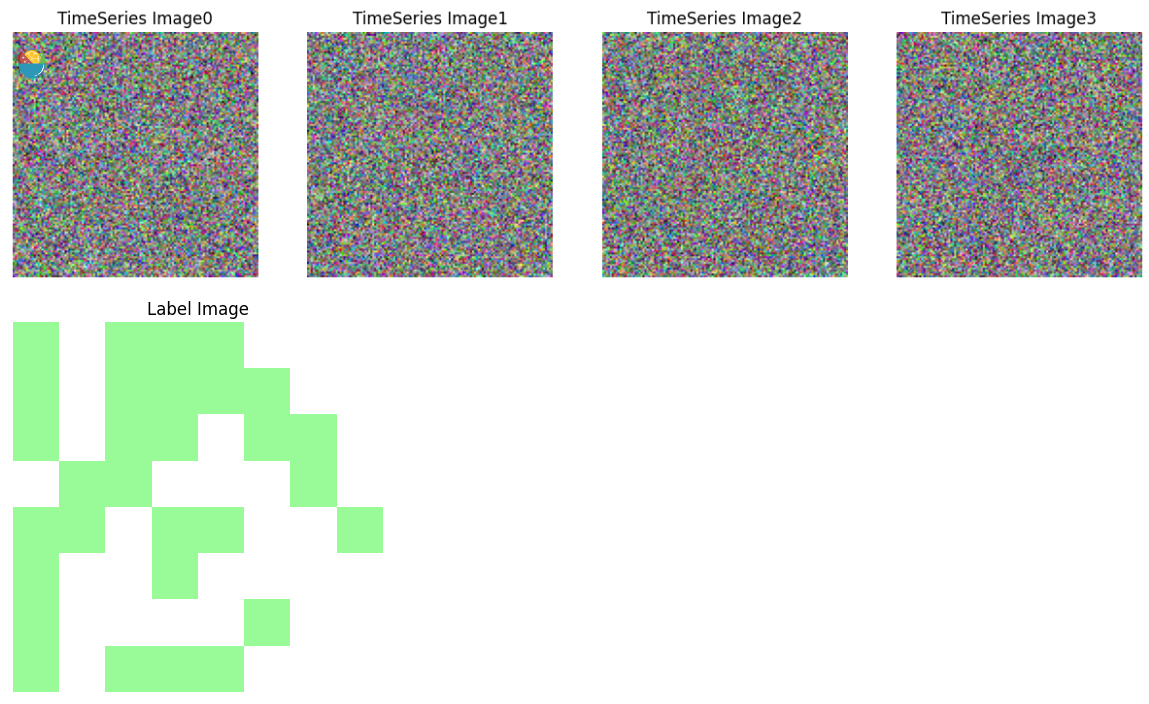
def show_label(tensor , savename =None):# 创建一个浅绿色的 colormapcmap = ListedColormap(['white', 'palegreen'])# 显示二值化图像fig, ax = plt.subplots()ax.imshow(tensor, cmap=cmap)if savename:Image.fromarray(np.uint8(tensor*255)).save(f"img/{savename}.png") #.resize((512,512),resample = Image.NEAREST)# 隐藏坐标轴ax.axis('off')ax.set_title('Label Image')plt.show()# 随机生成一个大小为 [2, 128, 128, 10] 的张量
tf.random.set_seed(0)
tensor = tf.random.normal([128, 128,4,10])# 调用 show_image 函数进行展示
show_image(tensor.numpy(),[2,3,4])# 随机生成一个 8x8 的二值化图像
image = np.random.randint(2, size=(8, 8))
show_label(image)
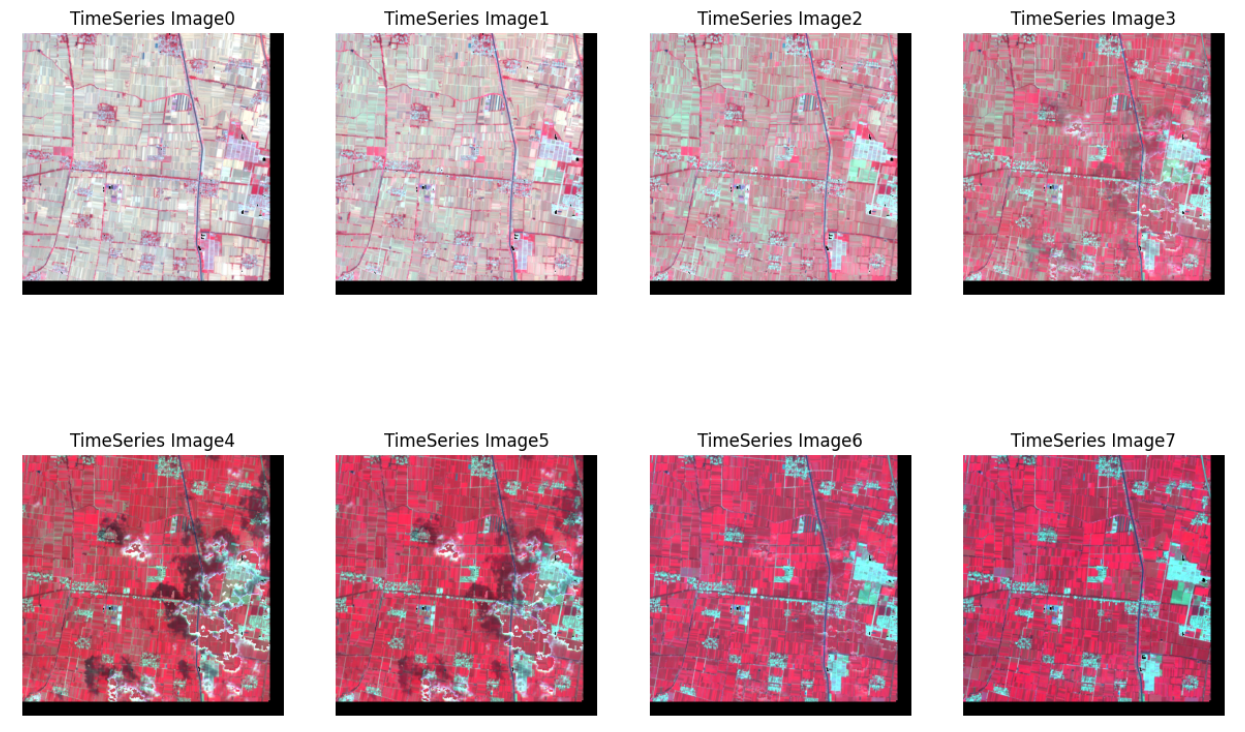
编写区块拼接函数,测试区块通常是通过滑窗的方式裁切出多个样本,因此在导出最终结果的时候需要将整个区块拼接起来并保存。
此函数部分需要根据实际情况进行具体调整,因为GEE导出时边缘似乎是不太固定的(未解决的问题),所以导出的时候需要增加缓冲区,在此处再将缓冲区裁剪掉。num_rows 和 num_cols代表区块内patch的行列数,可以从GEE导出的json格式文件中获取,num_rows和num_cols不一致是因为GEE导出坐标系为默认EPSG:4326(地理坐标系),作者后来更改为EPSG:32650(投影坐标系),num_rows和num_cols就相同了(区块为矩形)。
def mosicImage(data,core_size = 32,num_rows = 15,num_cols = 18):buffer = int(core_size/2)# 创建大图的空数组big_image = np.zeros(((num_rows+1) * core_size, (num_cols+1) * core_size, 12, 10))# 遍历原始数据index = 0for i in range(num_rows):for j in range(num_cols):# 计算当前核心区域的索引范围start_row = i * core_size end_row = (i + 1) * core_size start_col = j * core_sizeend_col = (j + 1) * core_size# 提取当前核心区域的数据core_data = data[index,buffer:buffer+core_size, buffer:buffer+core_size,:,:]# 将核心区域的数据放入大图的对应位置big_image[start_row:end_row, start_col:end_col,:,:] = core_dataindex = index +1 index = index - num_cols#拼接完(480*608)还要拼接最后一列#拼接最后一边缘行 拼接完(16*608)for j in range(num_cols):# 计算当前核心区域的索引范围start_row = num_rows * core_size end_row = (num_rows) * core_size + bufferstart_col = j * core_sizeend_col = (j + 1) * core_size# 提取当前核心区域的数据core_data = data[index,buffer+core_size:, buffer:buffer+core_size,:,:]# 将核心区域的数据放入大图的对应位置big_image[start_row:end_row, start_col:end_col,:,:] = core_dataindex = index +1 index = 1for j in range(num_rows):# 计算当前核心区域的索引范围start_col = num_cols * core_size end_col = (num_cols) * core_size + bufferstart_row = j * core_sizeend_row = (j + 1) * core_size# 提取当前核心区域的数据core_data = data[index*num_cols-1,buffer:buffer+core_size,buffer+core_size:,:,:]# 将核心区域的数据放入大图的对应位置big_image[start_row:end_row, start_col:end_col,:,:] = core_dataindex = index +1 #拼接完(496*608)#根据实际情况调整big_image = big_image[8:8+500,8:8+500]big_image = tf.constant(big_image)return big_image
def mosicLabel(data,core_size = 32,num_rows = 15,num_cols = 18):buffer = int(core_size/2)# 创建大图的空数组big_image = np.zeros(((num_rows+1) * core_size, (num_cols+1) * core_size))# 遍历原始数据index = 0for i in range(num_rows):for j in range(num_cols):# 计算当前核心区域的索引范围start_row = i * core_size end_row = (i + 1) * core_size start_col = j * core_sizeend_col = (j + 1) * core_size# 提取当前核心区域的数据core_data = data[index,buffer:buffer+core_size, buffer:buffer+core_size]# 将核心区域的数据放入大图的对应位置big_image[start_row:end_row, start_col:end_col] = core_dataindex = index +1 index = index - num_cols#拼接完(480*608)还要拼接最后一列#拼接最后一边缘行 拼接完(16*608)for j in range(num_cols):# 计算当前核心区域的索引范围start_row = num_rows * core_size end_row = (num_rows) * core_size + bufferstart_col = j * core_sizeend_col = (j + 1) * core_size# 提取当前核心区域的数据core_data = data[index,buffer+core_size:, buffer:buffer+core_size]# 将核心区域的数据放入大图的对应位置big_image[start_row:end_row, start_col:end_col] = core_dataindex = index +1 #拼接完(496*608)index = 1for j in range(num_rows):# 计算当前核心区域的索引范围start_col = num_cols * core_size end_col = (num_cols) * core_size + bufferstart_row = j * core_sizeend_row = (j + 1) * core_size# 提取当前核心区域的数据core_data = data[index*num_cols-1,buffer:buffer+core_size,buffer+core_size:]# 将核心区域的数据放入大图的对应位置big_image[start_row:end_row, start_col:end_col] = core_dataindex = index +1 #根据实际情况调整big_image = big_image[8:8+500,8:8+500]big_image = tf.constant(big_image)return big_image
设置数据包路径,拼接、显示并保存区块。
directory = 'data/yangfang/' # 替换为你要列出文件的目录路径
files = ['2022training_patches_g2.tfrecord.gz']
# 遍历多个样方
for file in files:data = []labels = []dataset = get_dataset([directory+file])for example in dataset:data.append(example[0])labels.append(example[1]) data = tf.stack(data)labels = tf.stack(labels)print(data.shape) # 拼接数据 big_image = mosicImage(data)big_label = mosicLabel(labels)#显示 并保存savename = file.split('.')[0]savePath = f"yangfang/{savename}/"if not os.path.exists('img/'+savePath):os.makedirs('img/'+savePath)print(f'{savePath}文件夹已创建!')show_image(big_image.numpy(),[8,4,3],savePath+f"{savename}")show_label(big_label.numpy(),savePath+f"{savename}-label")
文件夹内保存的文件:

其他
数据增广
数据增广是一种有用的技术,可以增加训练数据的数量和多样性。首先将原始瓷砖图像顺时针随机旋转 90°、180° 或 270° ;然后,将旋转的图像乘以 0.9 和 1.1 之间的随机值(波段间相同,时相间不同),以增加样本数据时间序列曲线的波动。此外,每个原始平铺图像被垂直或水平翻转,随后将翻转的图像乘以0.9和1.1之间的随机数。训练数据集增广为原来的4倍。
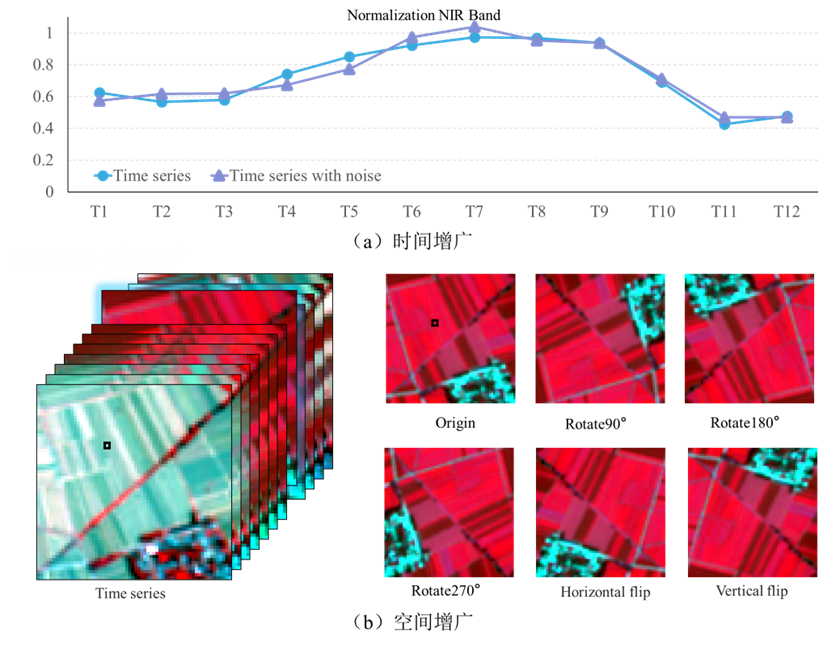
trainPath = 'data/guoyang/training_patches_g%d.tfrecord.gz'
trainIndex = [14,20,19,25,13,31,24,15,18,7,30,26,21,29,16,8,28,27,12,11,17,33,4,32,9,10,22]
training_patches_size = 27
BATCH_SIZE = 8
def to_HWTCtuple(inputs):# 读取出多时相多波段影像inputsList = [inputs.get(key) for key in ALLBANDS]label = inputs.get(RESPONSE)stacked = tf.stack(inputsList, axis=0)# 从通道维展开出时间维,TIMES在前,len(BANDS)在后,不可以反#stacked = tf.reshape(stacked, [12,10,KERNEL_SIZE, KERNEL_SIZE])stacked = tf.reshape(stacked, [TIMES,len(BANDS),KERNEL_SIZE, KERNEL_SIZE])# Convert from TCHW to HWTCstacked = tf.transpose(stacked, [2,3,0,1]) return stacked, label
def generate_augment():#生成增强函数#method = 1 2 3 4 5 #对应 旋转90°、 180°、 270°、水平翻转、竖直翻转 #用法:dataset = dataset.map(generate_augment(), num_parallel_calls=5)def augment_data(time_series,label):label = tf.expand_dims(label, -1) #(H,W)-->(H,W,1)# 旋转 90°、180°、 270°、水平翻转、数值翻转 time_series = tf.transpose(time_series, perm=[2, 0, 1, 3]) #(T ,H ,W,C)# 生成1到5之间的整数 [1,6)method = np.random.randint(1,6)if method <=3:time_series = tf.image.rot90(time_series, k=method)label = tf.image.rot90(label, k=method)elif method == 4:time_series = tf.image.flip_left_right(time_series)label = tf.image.flip_left_right(label)elif method == 5:time_series = tf.image.flip_up_down(time_series)label = tf.image.flip_up_down(label)else:raise ValueError("没有此类数据增广方法")time_series = tf.transpose(time_series, perm=[1, 2, 0, 3]) #(H ,W, T,C) # 随机选择时间序列缩放因子scale_factor = tf.random.uniform(shape=(12,), minval=0.9, maxval=1.1,seed = 0)scale_factor = tf.expand_dims(scale_factor, 0) #(1,12)scale_factor = tf.expand_dims(scale_factor, 0) #(1,1,12)scale_factor = tf.expand_dims(scale_factor, -1) #(1,1,12,1)# 时间序列缩放time_series *= scale_factorlabel = tf.squeeze(label)return time_series,labelreturn augment_data
def get_augment_training_dataset():namelist = [trainPath%(i) for i in trainIndex]dataset = get_dataset(namelist)augment_dataset1 = dataset.map(generate_augment(), num_parallel_calls=5)augment_dataset2 = dataset.map(generate_augment(), num_parallel_calls=5)augment_dataset3 = dataset.map(generate_augment(), num_parallel_calls=5) dataset = dataset.concatenate(augment_dataset1).concatenate(augment_dataset2).concatenate(augment_dataset3)dataset = dataset.shuffle(BUFFER_SIZE).batch(BATCH_SIZE,drop_remainder=True).repeat()return dataset