需求
系统 每天 运行一个任务。每个任务都独立于先前的任务。任务的状态可以是失败或是成功。
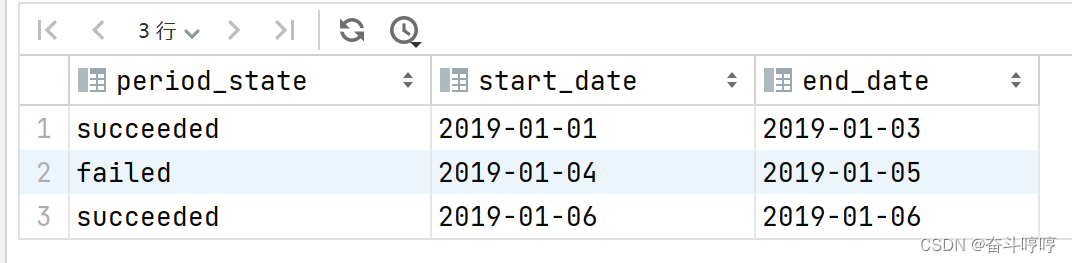
编写一个 SQL 查询 2019-01-01 到 2019-12-31 期间任务连续同状态 period_state 的起止日期(start_date 和 end_date)。即如果任务失败了,就是失败状态的起止日期,如果任务成功了,就是成功状态的起止日期。
最后结果按照起始日期 start_date 排序
输入

分析
– 对成功表,使用rank函数对其排序,并筛选出2019年的数据
– 窗口函数排序:
– row_number:1,2,3,4
– rank:1,2,2,4
– dense_rank:1,2,2,3
2.
– 拼接字符串,因为一个是date类型,一个是int类型,不能直接相减,这里将int类型拼接字符串,
– 再将其转换为interval类型,再将两者相减。得到 2018-12-31 00:00:00.000000
3.
– 对上一步的结果,对相减后的结果分组,因为时间是递增的,排序也是递增的。
– 如果时间是连续的,那么二者相减,得到的时间就是相同的,
– 使用这个时间进行分组,再求出组内最小值作为开始时间,最大值作为结束时间
4.
– 对失败表进行上面相同的操作
5.
– 合并两次查询的结果,并按照开始时间排序
输出
with t1 as (
-- 对成功表,使用rank函数对其排序,并筛选出2019年的数据
-- 窗口函数排序:-- row_number:1,2,3,4-- rank:1,2,2,4-- dense_rank:1,2,2,3
select * ,rank() over (order by success_date) as rn1
from succeeded
where success_date>='2019-01-01' and success_date<='2019-12-31'
),t2 as (
-- 拼接字符串,因为一个是date类型,一个是int类型,不能直接相减,这里将int类型拼接字符串,-- 再将其转换为interval类型,再将两者相减。得到 2018-12-31 00:00:00.000000
select *,success_date-(rn1||'day')::interval as rn2
from t1
),t3 as (
-- 对上一步的结果,对相减后的结果分组,因为时间是递增的,排序也是递增的。-- 如果时间是连续的,那么二者相减,得到的时间就是相同的,-- 使用这个时间进行分组,再求出组内最小值作为开始时间,最大值作为结束时间
select 'succeeded' as period_state,min(success_date) as start_date,max(success_date) as end_date
from t2
group by rn2
),t4 as (
-- 对失败表进行上面相同的操作
select *,fail_date-((rank() over (order by fail_date))||'day')::interval as rn3
from failed
where fail_date>='2019-01-01' and fail_date<='2019-12-31'
)
-- 合并两次查询的结果,并按照开始时间排序
select 'failed' as period_state,min(fail_date) as start_date,max(fail_date) as end_date
from t4
group by rn3
union all
select * from t3
order by start_date
;