【背景】
今天这个主要说的是<stdio.h>头文件,大家众所周知,这个是我们学习C语言时第一个接触到的头文件了,那么为什么我不一开始就介绍这个头文件呢?我觉得有两个原因,如下:
1.一开始大家的编程思想以及函数思维还不是很成熟,就像刚拿了驾照的同志,肯定不建议一个人上高速的,因为存在着诸多的不安全因素,那么,在我们这里不安全因素可以理解为函数思维和理解深度,一开始就研究这个头文件,我敢说绝对理解的不深刻,而且会走很多弯路,为什么呢?因为这个头文件好多都是关于文件指针的操作,而且函数多达42个,所以不管从学习还是理解程度来讲,一开始就搞这个,肯定不是明智之选,那么经过我们学习了<math.h> <stdlib.h> <time.h> <limits.h> <float.h> <string.h> <ctype.h> <assert.h> <stdarg.h> <setjmp.h> <signal.h>这些头文件,那么就对函数有一定的了解,函数思维和编程思维就熟悉了很多,那么再回头来学习<stdio.h>就比较可以了,个人理解而已,也因人而异,反正我是这么觉着的哦
2.这个<stdio.h>的函数是比较多的,而且多半都是关于文件指针的操作,所以对于指针的素养是有一定的要求的哦,还就是操作字符串,这个也是个基础,因为写文件读文件等都是关于字符串的操作,没有这个基础,就比较纠结了哦
综上所述便是我个人的理解,所以我们言归正传,开始学习<stdio.h>头文件
【前言】
stdio .h 头文件定义了三个变量类型、一些宏和各种函数来执行输入和输出。
库变量
下面是头文件 stdio.h 中定义的变量类型:
| 序号 | 变量 & 描述 |
|---|---|
| 1 | size_t 这是无符号整数类型,它是 sizeof 关键字的结果。 |
| 2 | FILE 这是一个适合存储文件流信息的对象类型。 |
| 3 | fpos_t 这是一个适合存储文件中任何位置的对象类型。 |
库宏
下面是头文件 stdio.h 中定义的宏:
| 序号 | 宏 & 描述 |
|---|---|
| 1 | NULL 这个宏是一个空指针常量的值。 |
| 2 | _IOFBF、_IOLBF 和 _IONBF 这些宏扩展了带有特定值的整型常量表达式,并适用于 setvbuf 函数的第三个参数。 |
| 3 | BUFSIZ 这个宏是一个整数,该整数代表了 setbuf 函数使用的缓冲区大小。 |
| 4 | EOF 这个宏是一个表示已经到达文件结束的负整数。 |
| 5 | FOPEN_MAX 这个宏是一个整数,该整数代表了系统可以同时打开的文件数量。 |
| 6 | FILENAME_MAX 这个宏是一个整数,该整数代表了字符数组可以存储的文件名的最大长度。如果实现没有任何限制,则该值应为推荐的最大值。 |
| 7 | L_tmpnam 这个宏是一个整数,该整数代表了字符数组可以存储的由 tmpnam 函数创建的临时文件名的最大长度。 |
| 8 | SEEK_CUR、SEEK_END 和 SEEK_SET 这些宏是在 fseek 函数中使用,用于在一个文件中定位不同的位置。 |
| 9 | TMP_MAX 这个宏是 tmpnam 函数可生成的独特文件名的最大数量。 |
| 10 | stderr、stdin 和 stdout 这些宏是指向 FILE 类型的指针,分别对应于标准错误、标准输入和标准输出流。 |
这些知识点请熟悉,我们会在后面的代码中使用
【函数1:fopen】
【格式】
FILE *fopen(const char *filename, const char *mode)
【功能】
使用给定的模式 mode 打开 filename 所指向的文件
【入参】
const char *filename:字符串,表示要打开的文件名称
const char *mode:字符串,表示文件的访问模式,可以是以下表格中的值
| 模式 | 描述 |
|---|---|
| "r" | 打开一个用于读取的文件。该文件必须存在。 |
| "w" | 创建一个用于写入的空文件。如果文件名称与已存在的文件相同,则会删除已有文件的内容,文件被视为一个新的空文件。 |
| "a" | 追加到一个文件。写操作向文件末尾追加数据。如果文件不存在,则创建文件。 |
| "r+" | 打开一个用于更新的文件,可读取也可写入。该文件必须存在。 |
| "w+" | 创建一个用于读写的空文件。 |
| "a+" | 打开一个用于读取和追加的文件 |
注意 :关于filename常量,表示的是要打开的文件名称,这里可以是名称(比如:a.txt)也可以是一个路径(比如:F:\A00_code_test_C\zll_debug_00\zll_debug.txt),还有一个细节要注意就是在windows系统下运行代码的话,表示路径的话要用双斜杠(比如:F:\\A00_code_test_C\\zll_debug_00\\zll_debug.txt)
【返回值】
该函数返回一个 FILE 指针。否则返回 NULL,且设置全局变量 errno 来标识错误(这个会使文件指针fp会带有错误标识符,这个具体有什么作用,请见clearerr函数讲解)
【TestCode】
1.在当前目录下创建a.txt文件并写入数据
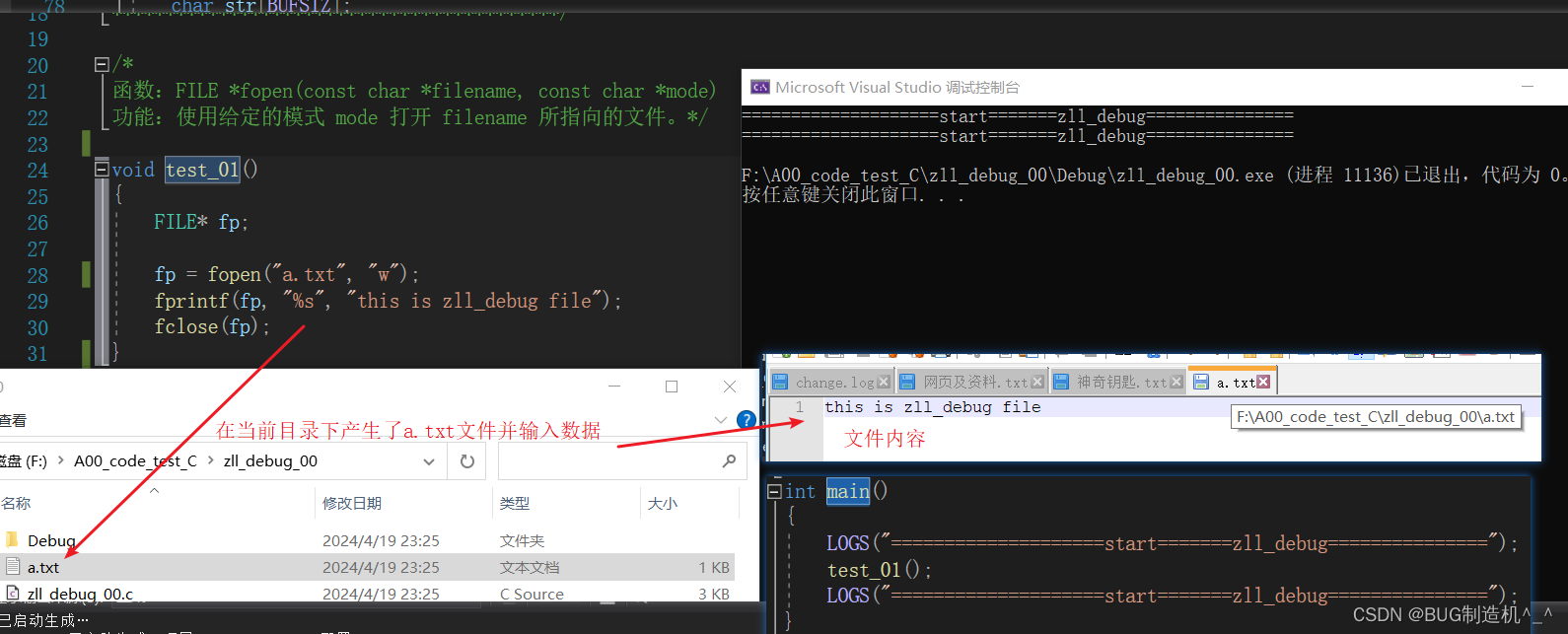
2.在当前目录下创建zll_debug.txt文件并写入数据
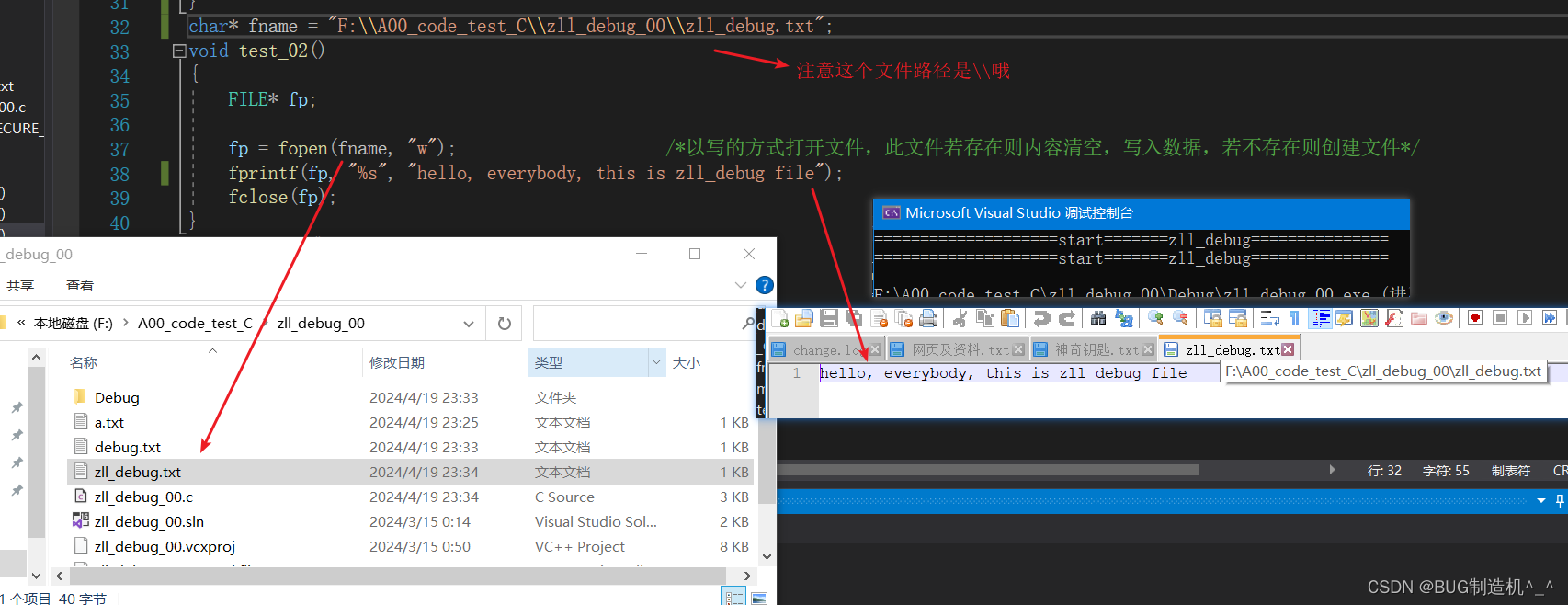
3.以读的方式打开文件zll_debug.txt并输出文件内容到终端
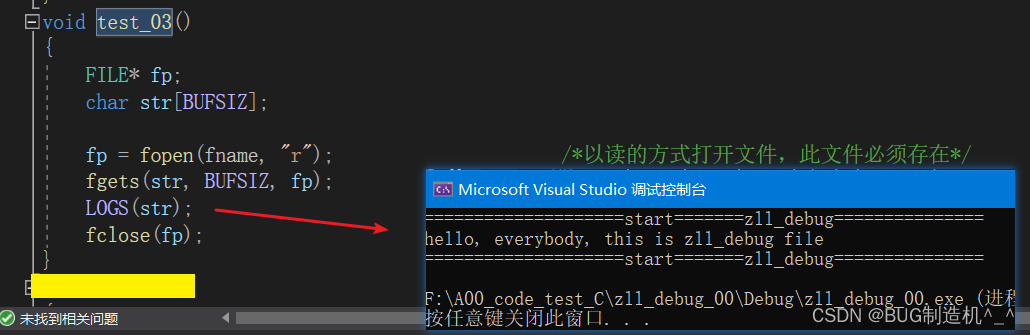
4.以追加的方式向zll_debug.txt写入数据
【总结】
1.fopen函数的操作权限大家最好多练习练习,熟能生巧
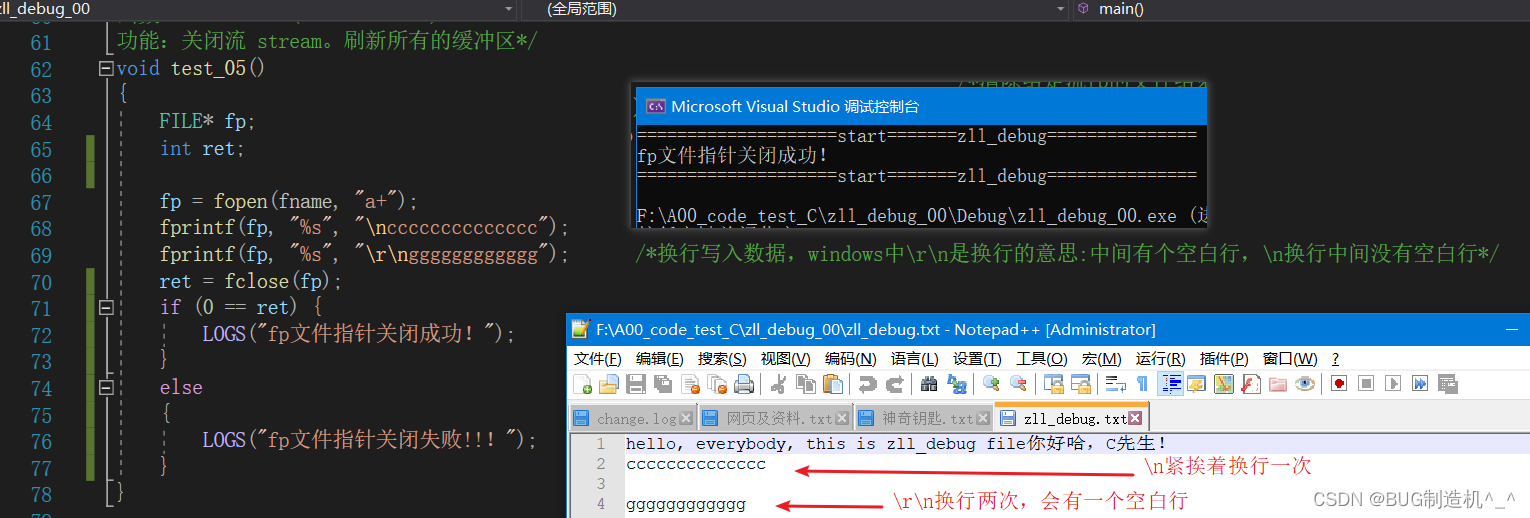
2.关于testcode中的4.大家发现没有:追加的数据是紧挨着文件中原有的数据的哦,那么如果要换行追加的话,怎么搞?换两行呢?大家可以思考下
3.关于二进制文件的操作,这个一般操作的不多,除非在汇编里可能多点,还有就是驱动力可能有些,我们先不探讨哦,这个会在linux c中到时候探讨一下
【函数2:fclose】
【格式】
int fclose(FILE *stream)
【功能】
关闭流 stream。刷新所有的缓冲区
【入参】
FILE *stream:文件流指针,指向操作的文件
【返回值】
如果流成功关闭,则该方法返回零。如果失败,则返回 EOF
【TestCode】
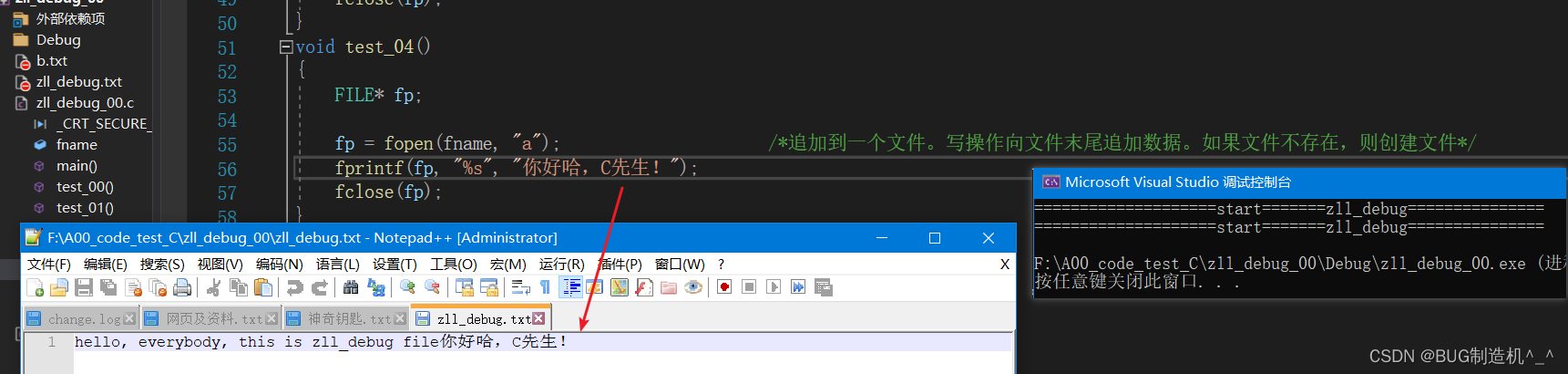
【总结】
1.切记fclose函数和fopen是成对出现的,也就是说只要你fopen了文件,就一定要fclose文件,不然的话,文件会损坏的哦
2.关于追加换行的问题,上述示例代码已演示,这个是在windows下的哦
【函数3:clearerr】
【格式】
void clearerr(FILE *stream)
【功能】
清除给定流 stream 的文件结束和错误标识符
【入参】
FILE *stream:文件流指针,指向操作的文件
【返回值】
void类型,无返回值
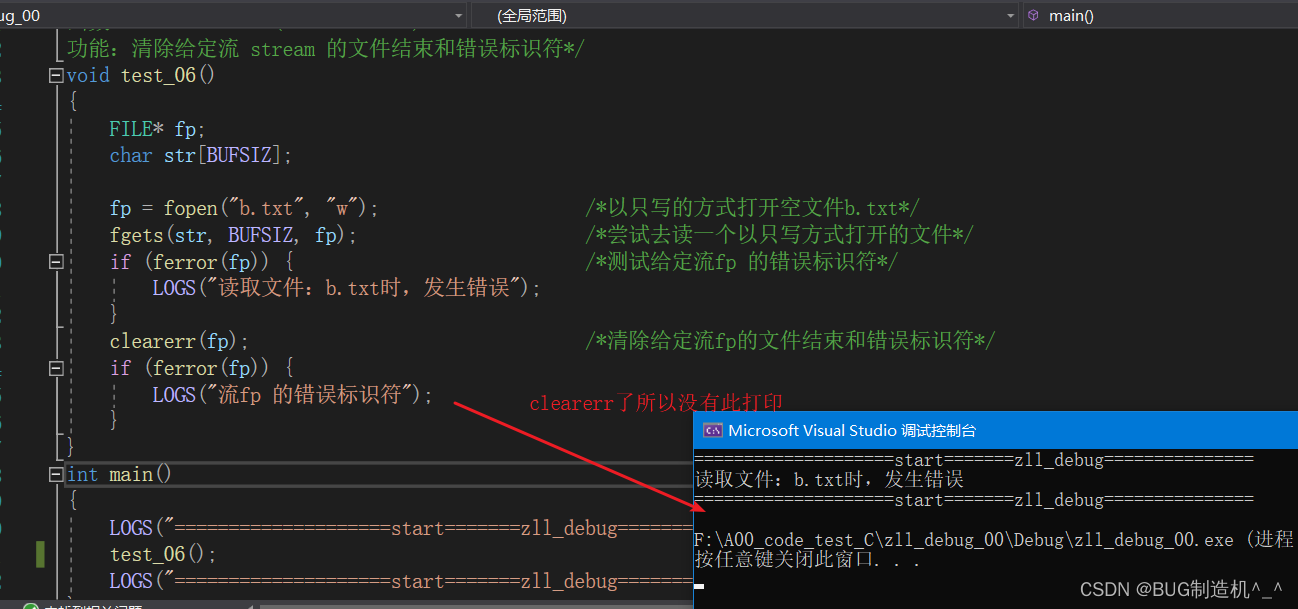
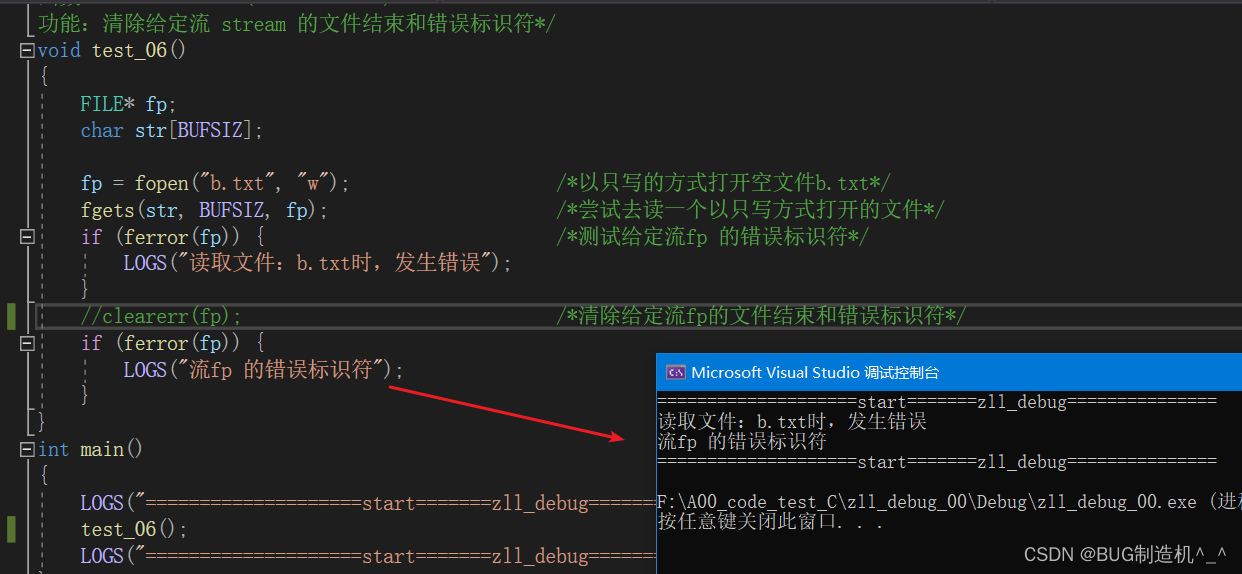
【TestCode】
clearerr后
没clearerr时
【总结】
clearerr是清除给定流 fp 的文件结束和错误标识符,这两个标识符会在我们操作文件的时候,根据相应的情况,系统自动给赋值,所以我们操作文件的时候一定要安全的操作哦
【函数4:feof】
【格式】
int feof(FILE *stream)
【功能】
测试给定流 stream 的文件结束标识符
【入参】
FILE *stream:文件流指针,指向操作的文件
【返回值】
当设置了与流关联的文件结束标识符时,该函数返回一个非零值,否则返回零
【TestCode】
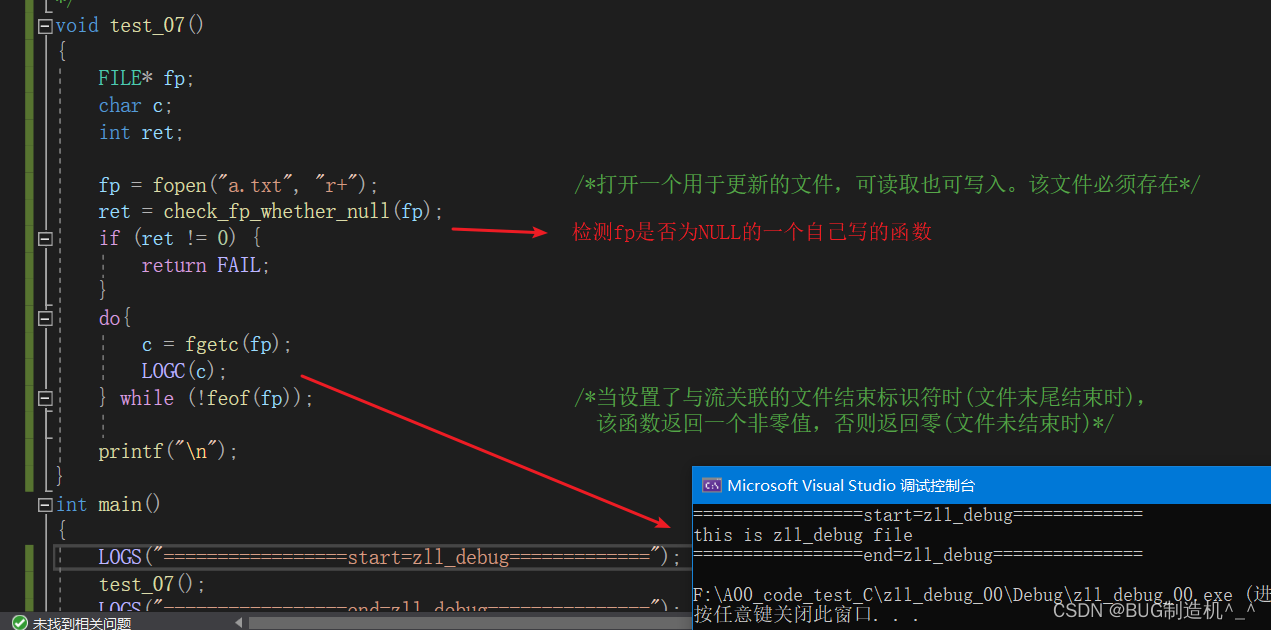
【总结】
注意理解返回值这句话:当设置了与流关联的文件结束标识符时,该函数返回一个非零值,否则返回零
这个意思是说当没有读到文件末尾的时候,feof函数并不会检测到文件结束标识符,也就是说这个时候feof(fp)返回的值为0;当读到文件末尾的时候,此时feof函数会检测到fp的文件结束标识符(这个文件结束标识符是文件系统设置的),也就是说这个时候feof(fp)返回的值为非零
【函数5:ferror】
【格式】
int ferror(FILE *stream)
【功能】
测试给定流 stream 的错误标识符
【入参】
FILE *stream:文件流指针,指向操作的文件
【返回值】
如果设置了与流关联的错误标识符,该函数返回一个非零值,否则返回一个零值
【TestCode】
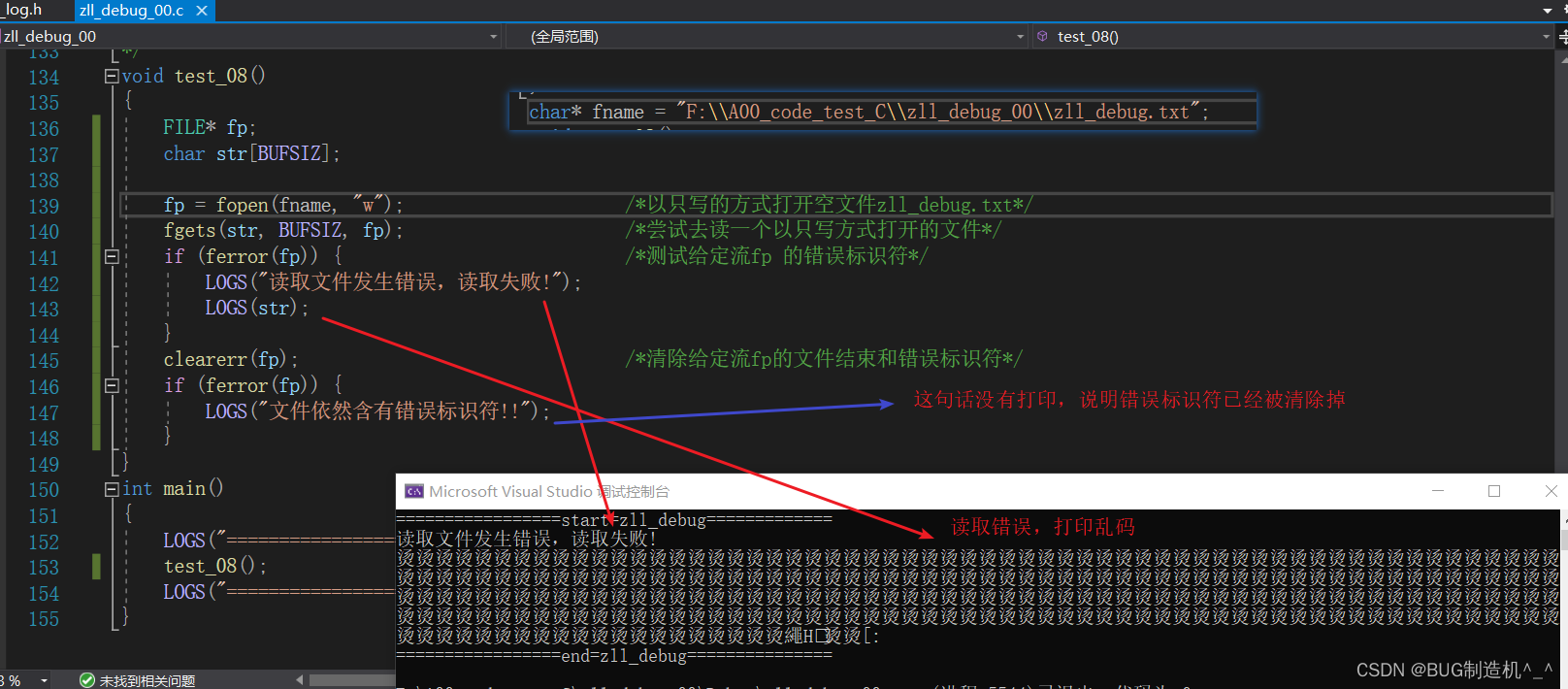
【总结】
注意理解这个错误标识符,这个是对文件进行了错误的不恰当的操作后(如例子中是以只写的方式打开文件的,却在后面进行了读操作),系统给设置的一个错误标识符,表明文件的一个当前状态,ferror可以检测到这个错误标识符的一个状态
【函数6:setbuf】
【格式】
void setbuf(FILE *stream, char *buffer)
【功能】
定义流 stream 应如何缓冲。
该函数应在与流 stream 相关的文件被打开时,且还未发生任何输入或输出操作之前被调用一次
【入参】
FILE *stream:文件流指针,指向操作的流
char *buffer:这是分配给用户的缓冲,它的长度至少为 BUFSIZ 字节,BUFSIZ 是一个宏常量,表示数组的长度
【返回值】
该函数不返回任何值
【TestCode】
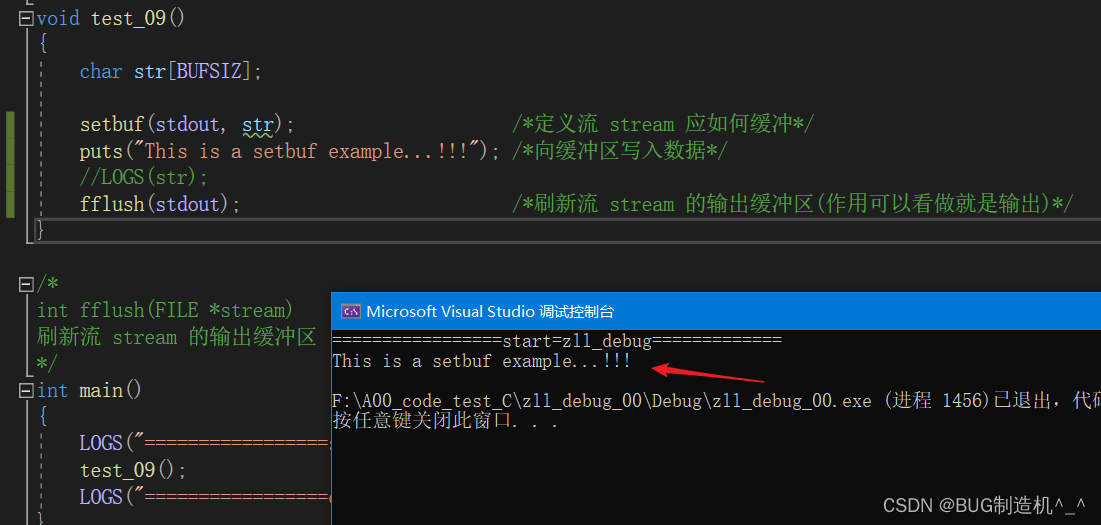
【总结】
setbuf会向缓冲区str里puts数据,等到fflush刷新缓冲区的时候,就会将这些数据输出到终端,那么,如果不刷新呢?如下:
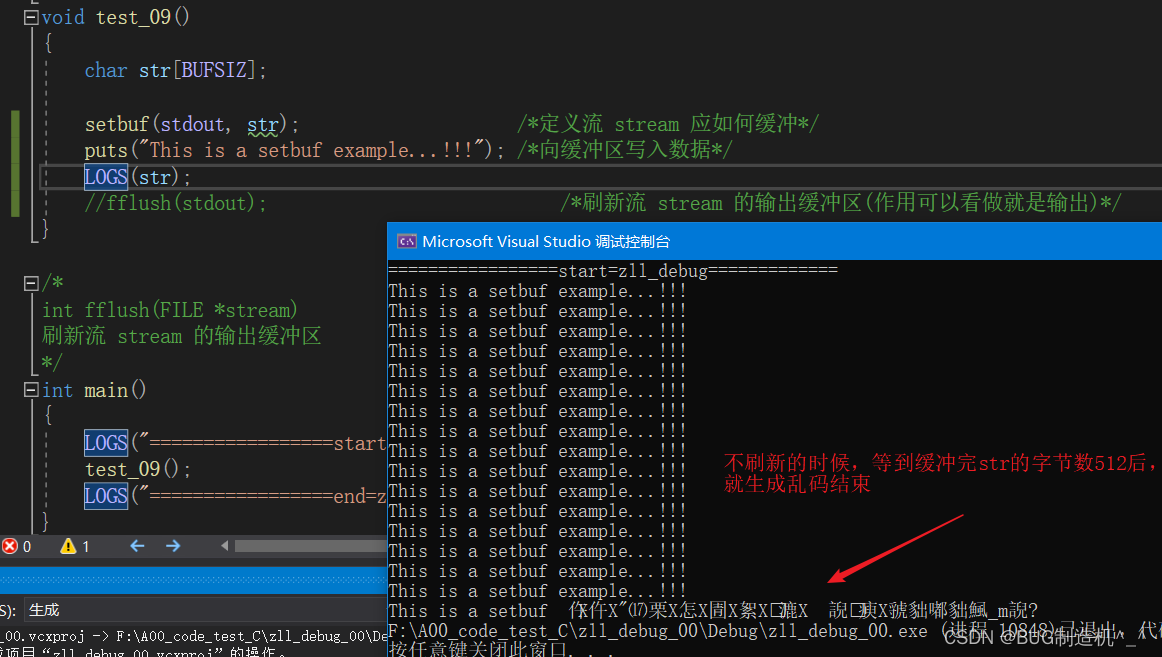
如果不使用fflush进行刷新的话,会一直缓冲到缓冲区,直到使用完str缓冲区,就会生成乱码并结束,图中一行为30个字节,一共16行,总共480字节,加上最后一行大家可以算算,所以缓冲完后,记得刷新fflush哦
【函数7:fflush】
【格式】
int fflush(FILE *stream)
【功能】
刷新流 stream 的输出缓冲区
【入参】
stream: 这是指向 FILE 对象的指针,该 FILE 对象指定了一个缓冲流
【返回值】
如果成功,该函数返回零值。如果发生错误,则返回 EOF,且设置错误标识符(即 feof)
【TestCode】
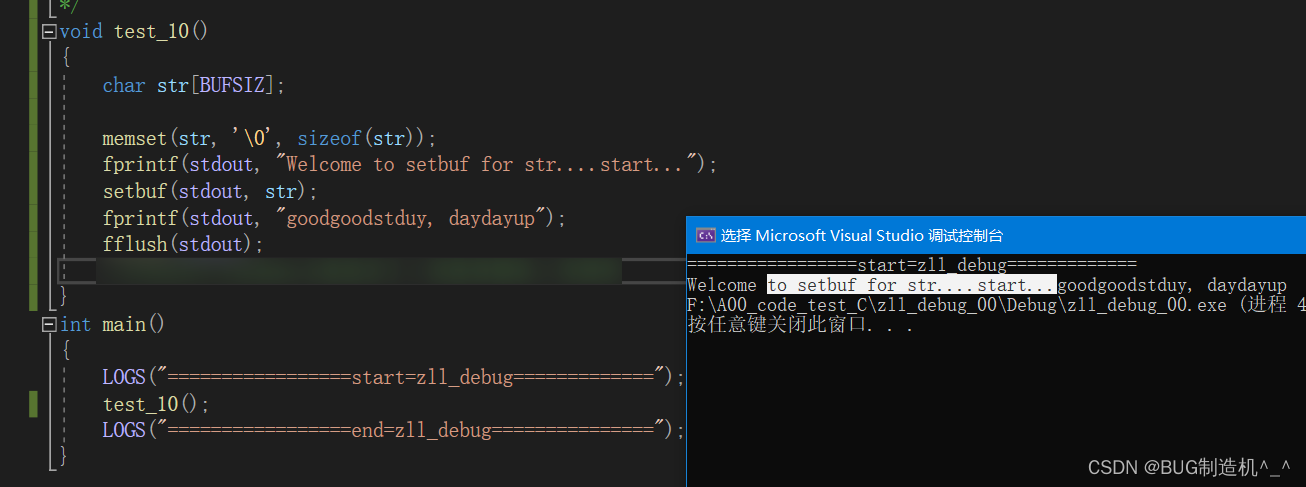
【总结】
大家有没有发现,打印==end=zll_debug==并没有打印出来,这说明了fflush调用后,直接就结束了?看实践确实是这样的,理论应该是如何的呢?这个待查明,留一个探讨吧,自己接下里再看看,深究下再回复大家
【函数8:fgetpos】
【格式】
int fgetpos(FILE *stream, fpos_t *pos)
【功能】
获取流 stream 的当前文件位置,并把它写入到 pos
【入参】
FILE *stream: 这是指向 FILE 对象的指针,该 FILE 对象标识了流
fpos_t *pos: 这是指向 fpos_t 对象的指针
【返回值】
如果成功,该函数返回零。如果发生错误,则返回非零值
【TestCode】
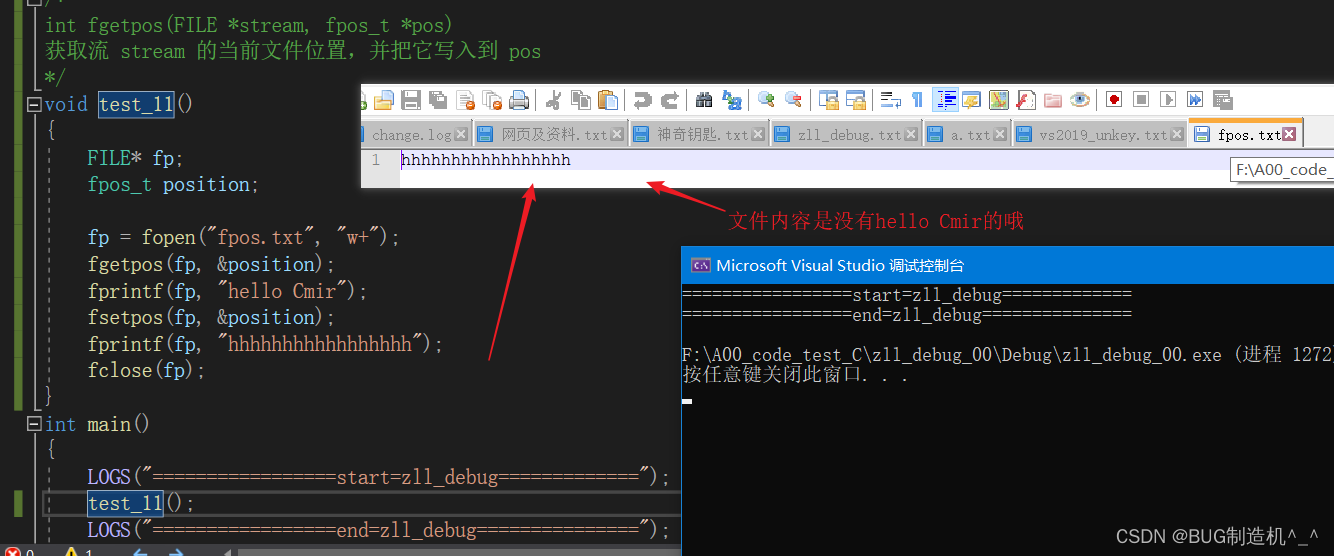
【总结】
如上例子,fgetpos函数会获取到文件的位置,不管你之前写过什么,只要记住了这个位置,然后再用fsetpos函数将光标移动到这个位置后,再写入的话,会覆盖掉之前所有的写入的哦。
【函数9:fread】
【格式】
size_t fread(void *ptr, size_t size, size_t count, FILE *stream)
【功能】
从给定流 stream 读取数据到 ptr 所指向的数组中
【入参】
void *ptr:指向目的存储块,读取到的内容放到这个内存里
size_t size:单个元素的大小
size_t count:所有元素的个数
FILE *stream:读的文件流
【返回值】
成功读取的元素总数会以 size_t 对象返回,size_t 对象是一个整型数据类型。如果总数与 nmemb 参数不同,则可能发生了一个错误或者到达了文件末尾
【TestCode】
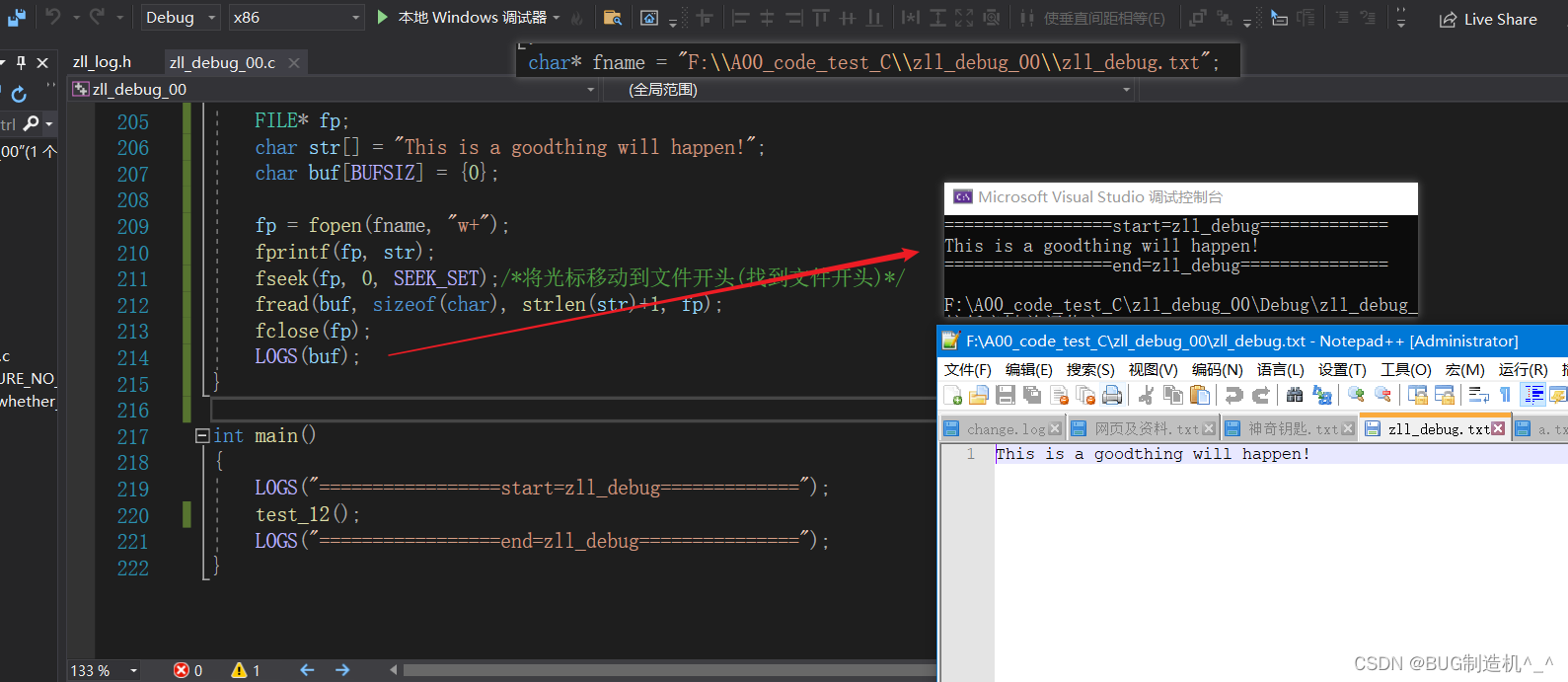
【总结】
在读取文件的时候,一定要注意将文件的光标移动到文件的开始位置,不然的话,就会读取不到内容,如下:
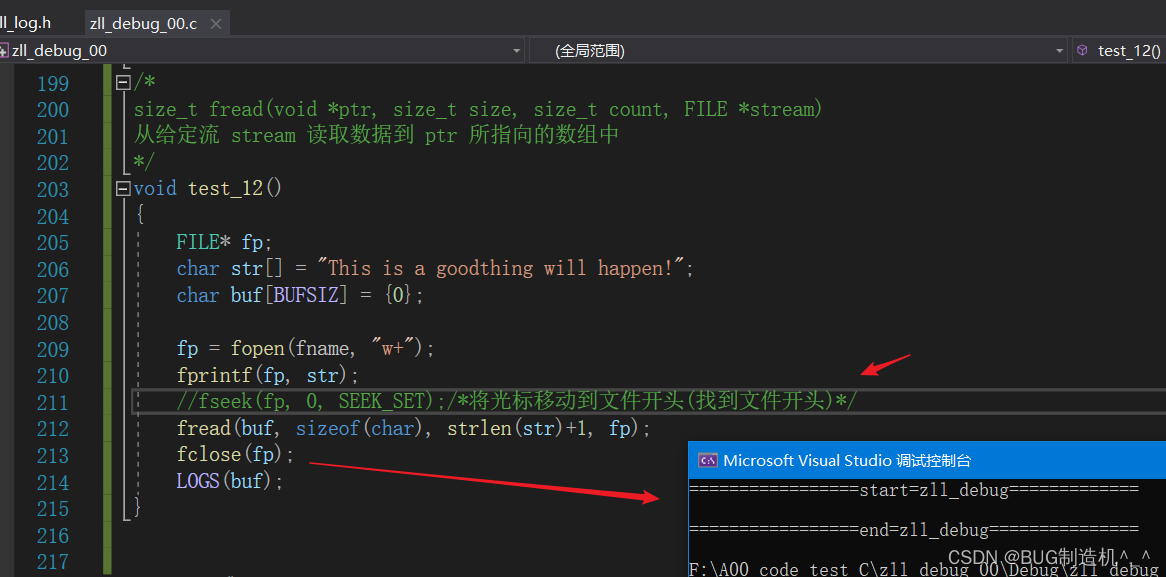
【函数10:freopen】
【格式】
FILE *freopen(const char *filename, const char *mode, FILE *stream)
【功能】
把一个新的文件名 filename 与给定的打开的流 stream 关联,同时关闭流中的旧文件
【入参】
const char *filename:字符串,包含了要打开的文件名称
const char *mode:字符串,包含了文件访问模式,模式如下:
| 模式 | 描述 |
|---|---|
| "r" | 打开一个用于读取的文件。该文件必须存在。 |
| "w" | 创建一个用于写入的空文件。如果文件名称与已存在的文件相同,则会删除已有文件的内容,文件被视为一个新的空文件。 |
| "a" | 追加到一个文件。写操作向文件末尾追加数据。如果文件不存在,则创建文件。 |
| "r+" | 打开一个用于更新的文件,可读取也可写入。该文件必须存在。 |
| "w+" | 创建一个用于读写的空文件。 |
| "a+" | 打开一个用于读取和追加的文件。 |
FILE *stream:这是指向 FILE 对象的指针,该 FILE 对象标识了要被重新打开的流
【返回值】
如果文件成功打开,则函数返回一个指针,指向用于标识流的对象。否则,返回空指针
【TestCode】
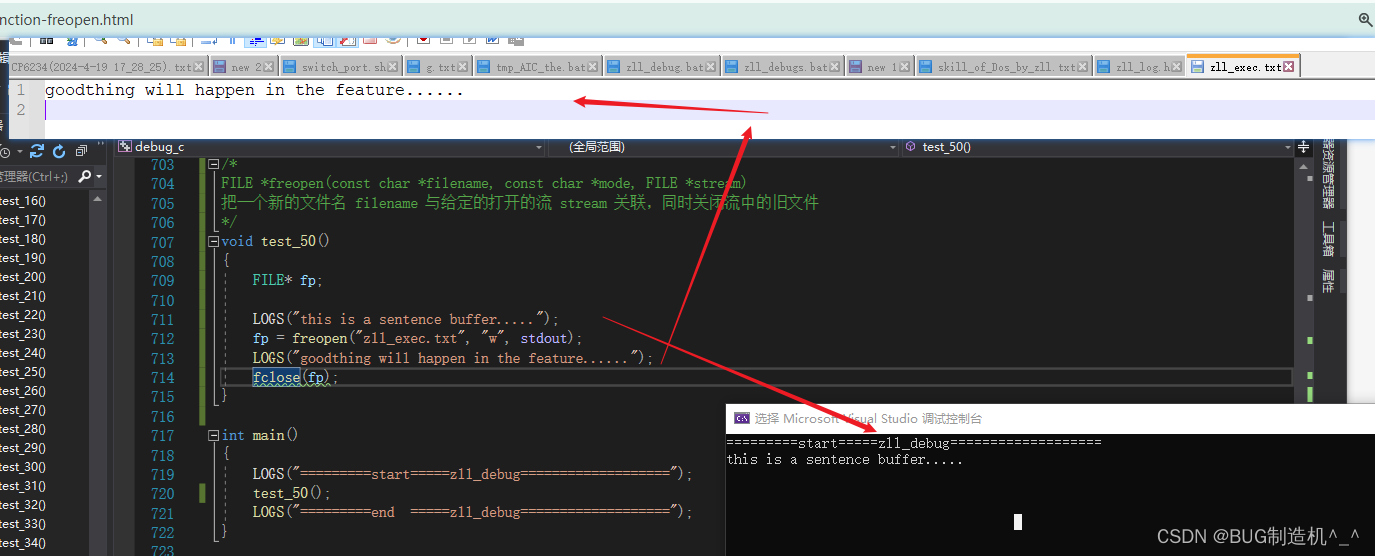
【总结】
发现没?关联后,输出的内容直接就到zll_exec.txt文件里了,说实在的,这个功能真不清楚到底用在什么场合下,还是比较烧脑的,有大神的麻烦给说道说道?
【函数11:fseek】
【格式】
int fseek(FILE *stream, long int offset, int whence)
【功能】
设置流 stream 的文件位置为给定的偏移 offset,参数 offset 意味着从给定的 whence 位置查找的字节数
【入参】
FILE *stream:指向 FILE 对象的指针,该 FILE 对象标识了流
long int offset:相对 whence 的偏移量,以字节为单位
int whence:表示开始添加偏移 offset 的位置。它一般指定为下列常量之一:
| 常量 | 描述 |
|---|---|
| SEEK_SET | 文件的开头 |
| SEEK_CUR | 文件指针的当前位置 |
| SEEK_END | 文件的末尾 |
【返回值】
如果成功,则该函数返回零,否则返回非零值。
【TestCode】
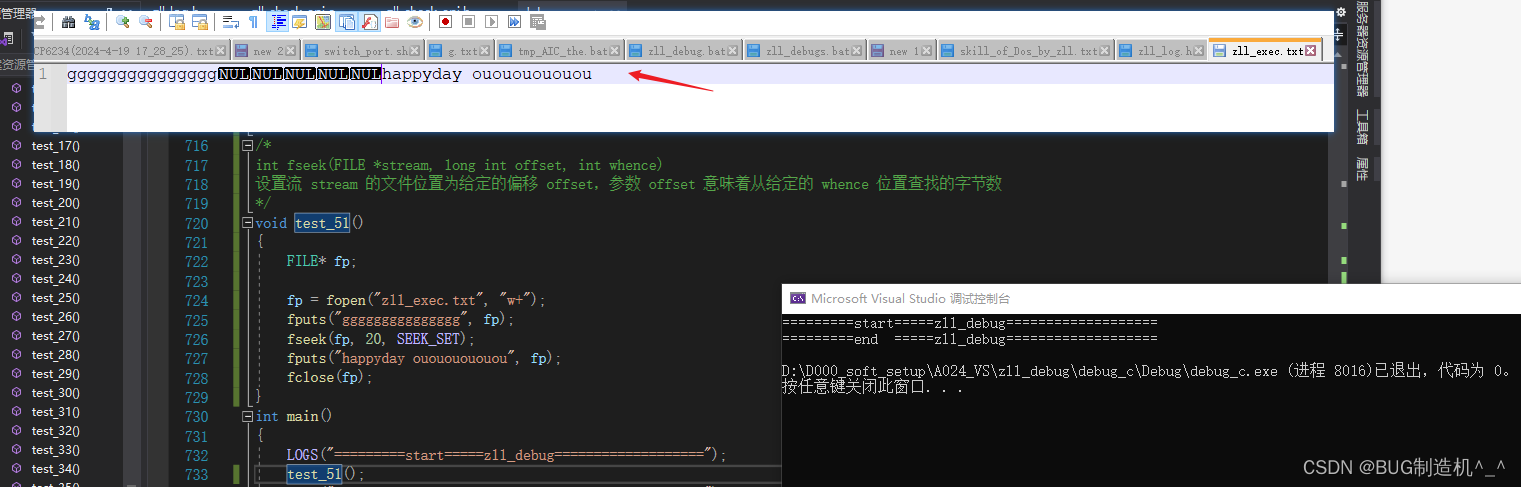
【总结】
实际fseek就是移动光标的函数,比如我们写完文件后,要去读我文件内容,最好将光标移动到文件开始位置,详见fread函数举例
【函数12:fsetpos】
【格式】
int fsetpos(FILE *stream, const fpos_t *pos)
【功能】
设置给定流 stream 的文件位置为给定的pos位置。参数 pos 是通过函数 fgetpos 获取给定的位置。
【入参】
FILE *stream:文件流指针
const fpos_t *pos:指向 fpos_t 对象的指针,该对象包含了之前通过 fgetpos 获得的位置
【返回值】
如果成功,该函数返回零值,否则返回非零值,并设置全局变量 errno 为一个正值,该值可通过 perror 来解释
【TestCode】
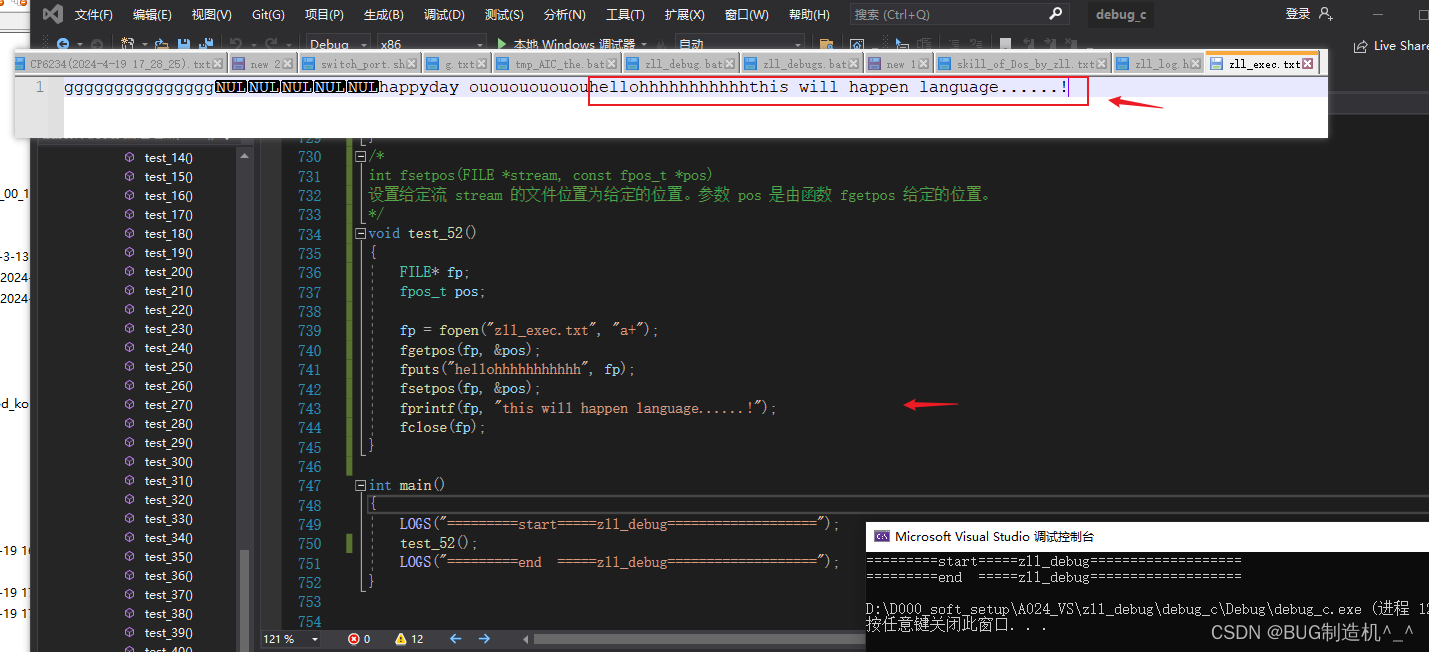
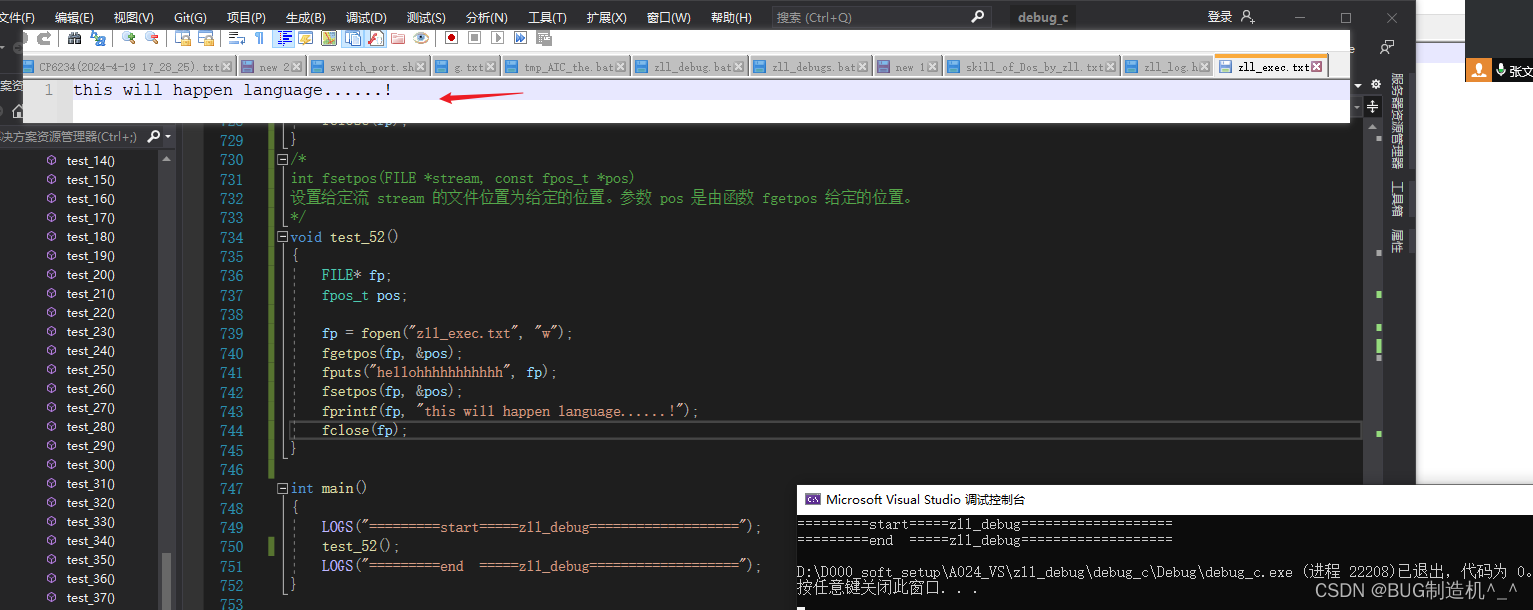
【总结】
这个函数和fgetpos函数是成对使用的,个人觉得没必要的情况下尽量别使用这个函数,容易导致文件光标或者文件内容紊乱,搞的最后自己都不知道pos在哪里了
【函数13:ftell】
【格式】
long int ftell(FILE *stream)
【功能】
返回给定流 stream 的当前文件光标位置
【入参】
FILE *stream:文件流指针
【返回值】
该函数返回位置标识符的当前值。如果发生错误,则返回 -1L,全局变量 errno 被设置为一个正值
【TestCode】
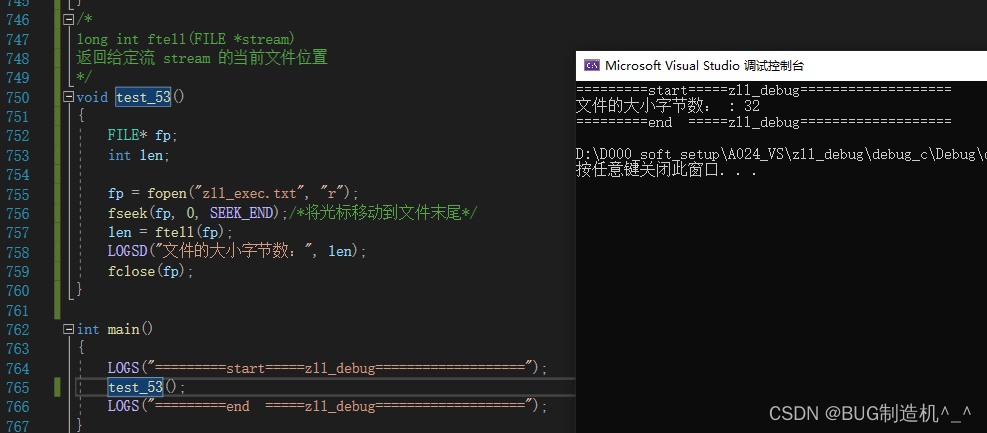
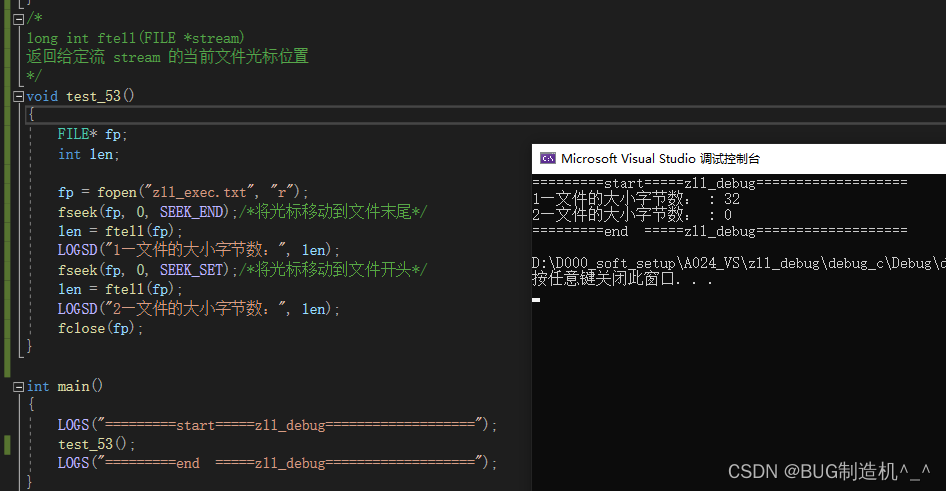
【总结】
根据个人理解,这个ftell说返回具体的光标(文件标识符)位置,会比较容易理解
【函数14:fwrite】
【格式】
size_t fwrite(const void *ptr, size_t size, size_t nmemb, FILE *stream)
【功能】
把 ptr 所指向的数组中的数据写入到给定流 stream 中
【入参】
const void *ptr:待写入的字符串内容
size_t size:写入的总字符数
size_t nmemb:单个字符,也就是单位量是多少(char = 1, int = 4...一般是sizeof(类型))
FILE *stream:目标文件
【返回值】
如果成功,该函数返回一个 size_t 对象,表示元素的总数,该对象是一个整型数据类型。如果该数字与 nmemb 参数不同,则会显示一个错误
【TestCode】
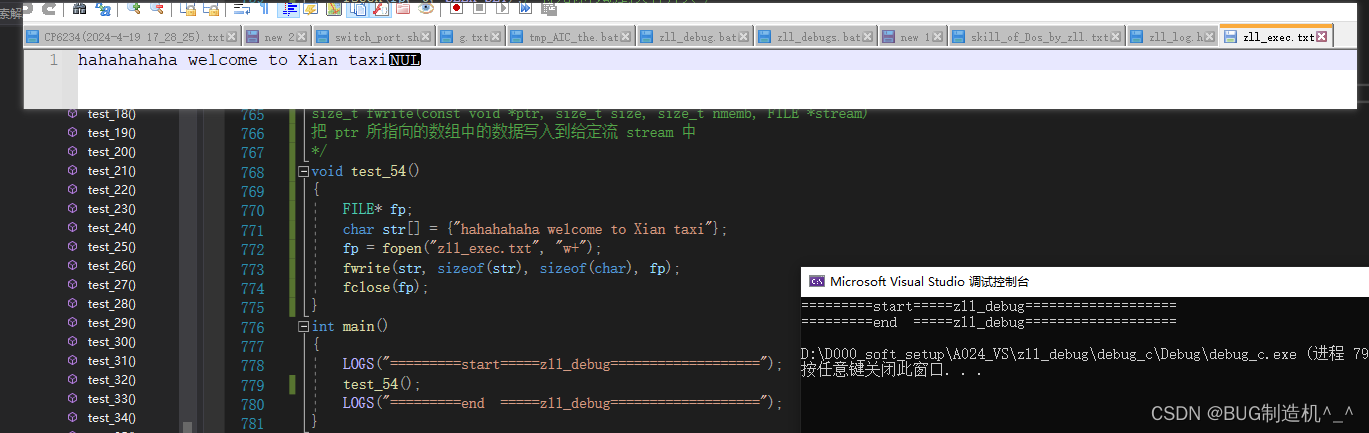
【总结】
这个写入的时候注意,最好是通过sizeof去算多少和大小,尽量不要去手算,一个是别人不好读,容易产生魔鬼数字,二是后期不好维护,好的代码风格是大牛的基础
【函数15:remove】
【格式】
int remove(const char *filename)
【功能】
删除给定的文件名 filename,以便它不再被访问(删除文件)
【入参】
const char *filename:文件名
【返回值】
如果成功,则返回零。如果错误,则返回 -1,并设置 errno
【TestCode】
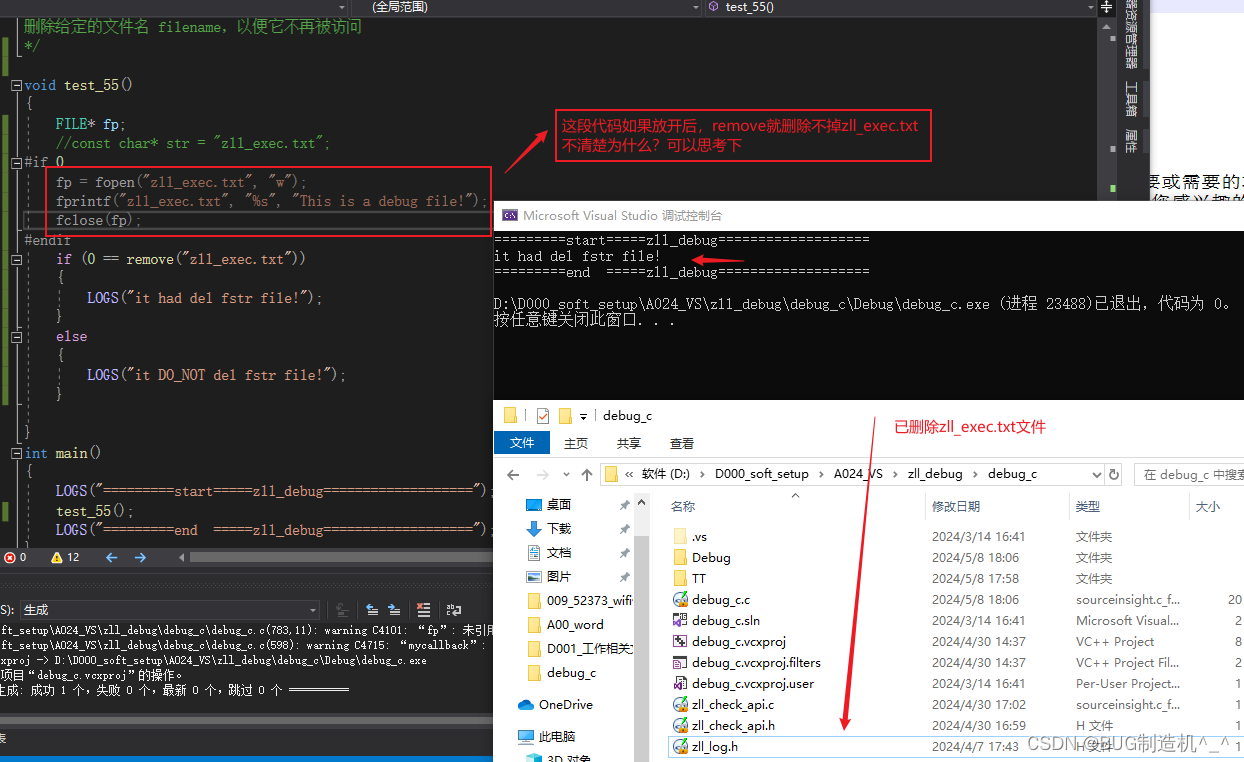
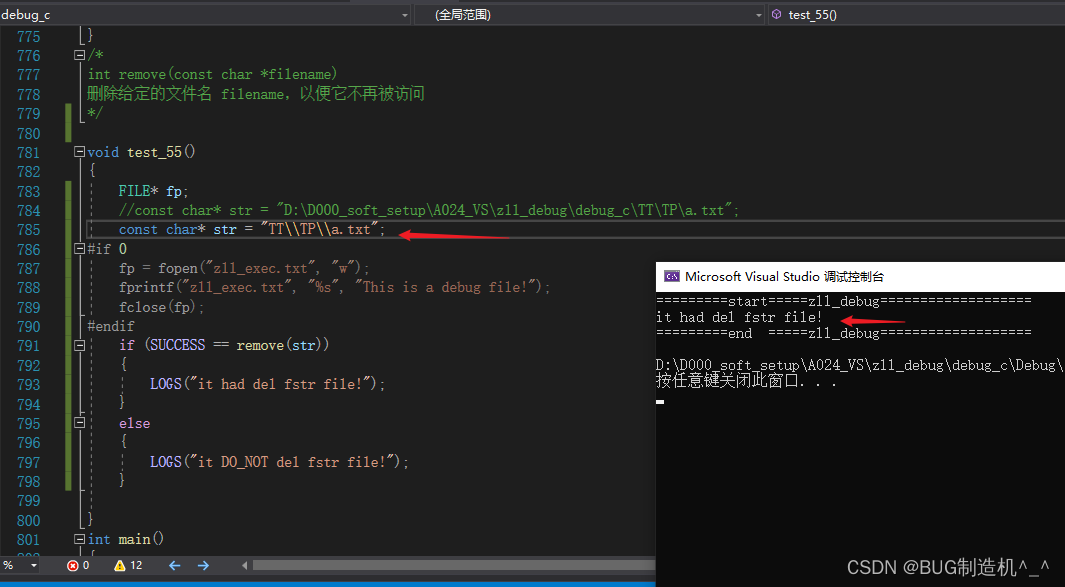
【总结】
1.注意为啥打开文件操作后关闭,再次进行remove会没有作用?
经过debug后发现,是因为我使用fprintf函数是使用错误,应该如下使用:
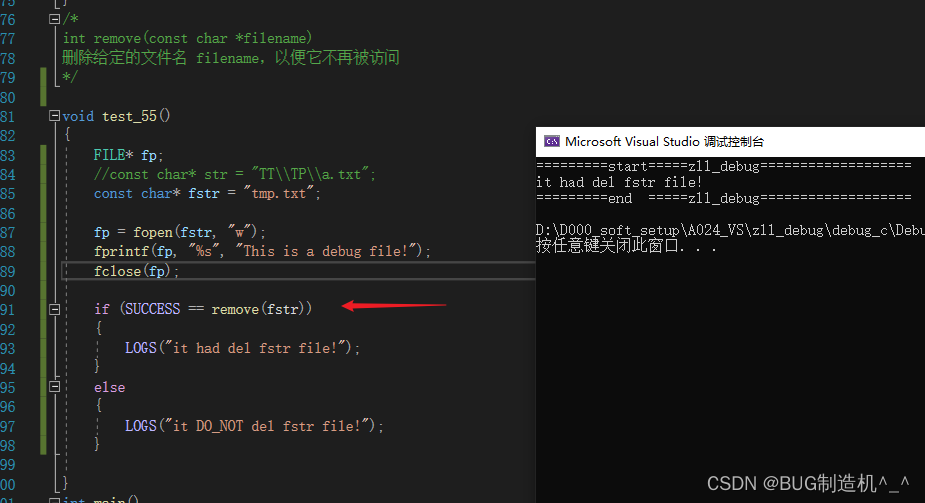
2.注意路径,是TT\\TP\\a.txt 这里是双斜线哦
【函数16:rename】
【格式】
int rename(const char *old_filename, const char *new_filename)
【功能】
把 old_filename 所指向的文件名改为 new_filename
【入参】
const char *old_filename:老文件名
const char *new_filename:新文件名
【返回值】
如果成功,则返回零。如果错误,则返回 -1,并设置 errno
【TestCode】
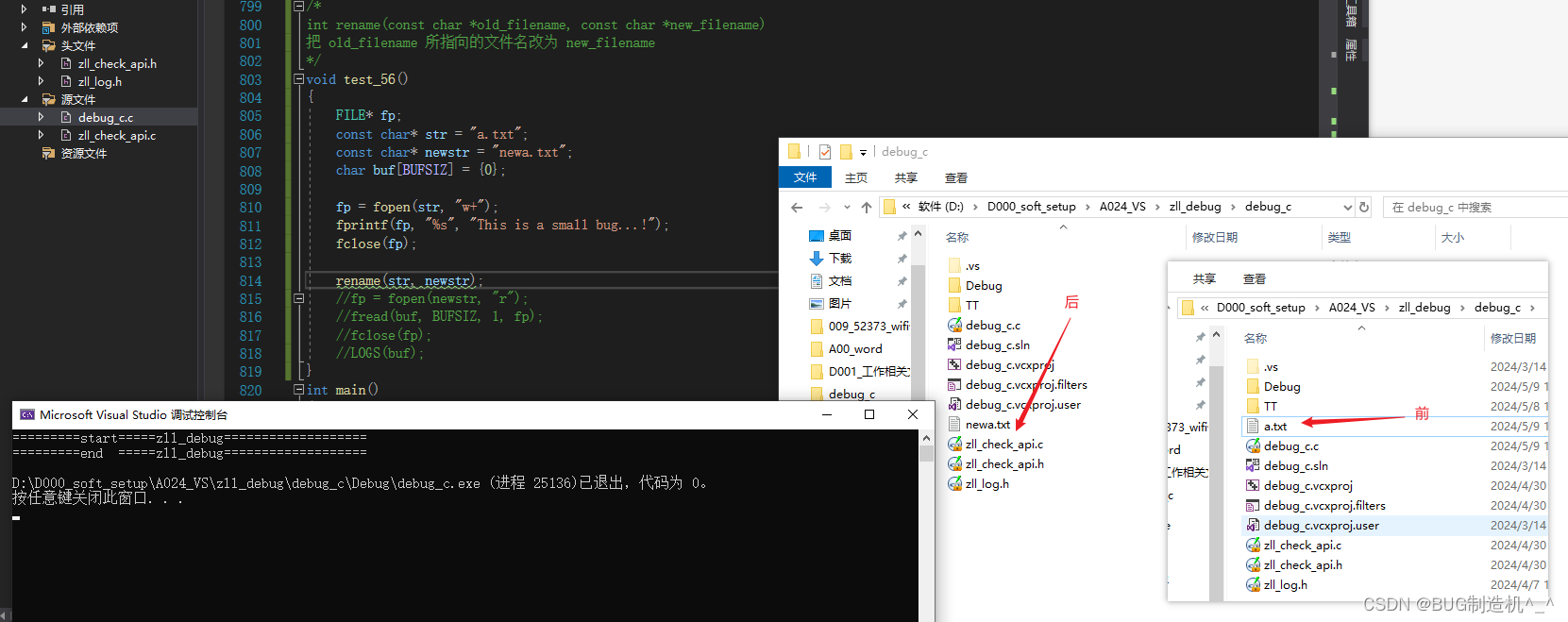

【总结】
作用就是修改文件名,在修改的时候注意文件状态,不能打开了去修改,如下:
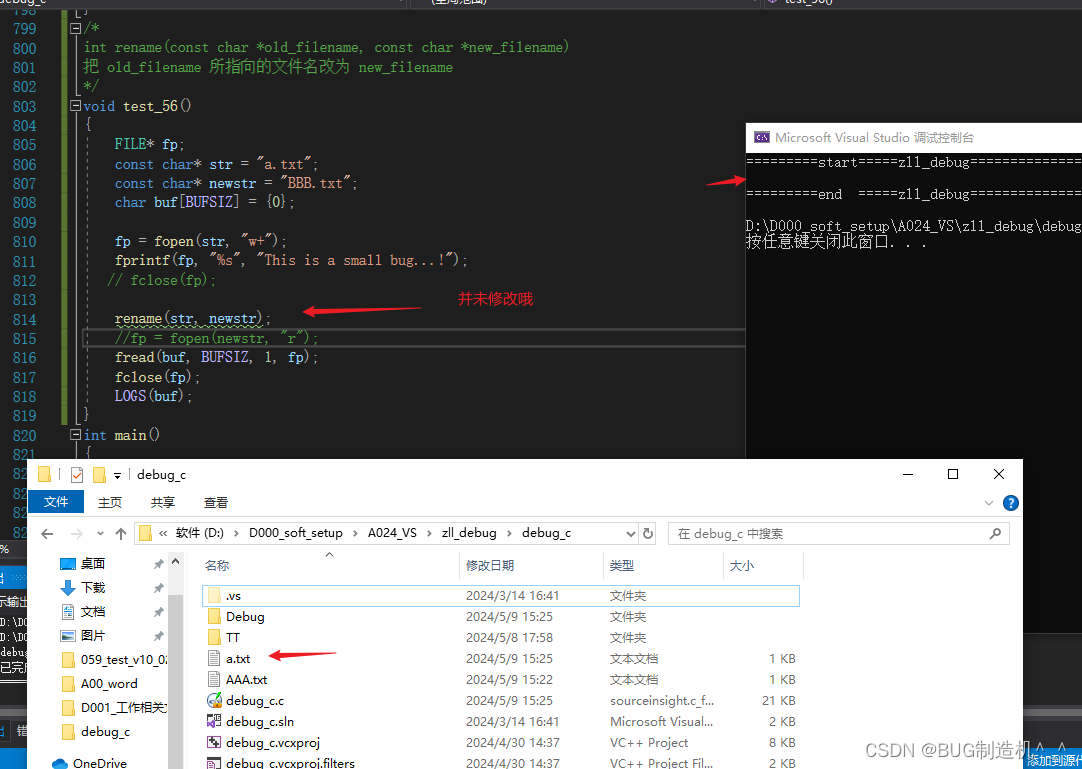
【函数17:rewind】
【格式】
void rewind(FILE *stream)
【功能】
设置文件位置为给定流 stream 的文件的开头
【入参】
FILE *stream:文件流
【返回值】
该函数不返回任何值
【TestCode】
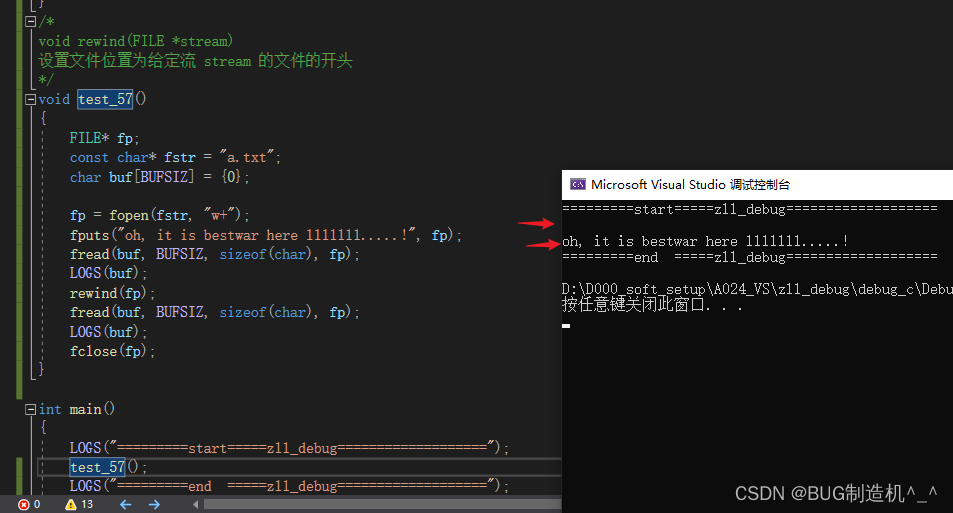
【总结】
在操作完文件后,再去读取内容的时候,一定要将光标移动到文件开始,不然可能读取不到文件内容哦
【函数18:setbuf】
【格式】
void setbuf(FILE *stream, char *buffer)
【功能】
定义流 stream 应如何缓冲
【入参】
FILE *stream:文件流
char *buffer:这是分配给用户的缓冲,它的长度至少为 BUFSIZ (512)字节,BUFSIZ 是一个宏常量,表示数组的长度
【返回值】
无返回值
【TestCode】
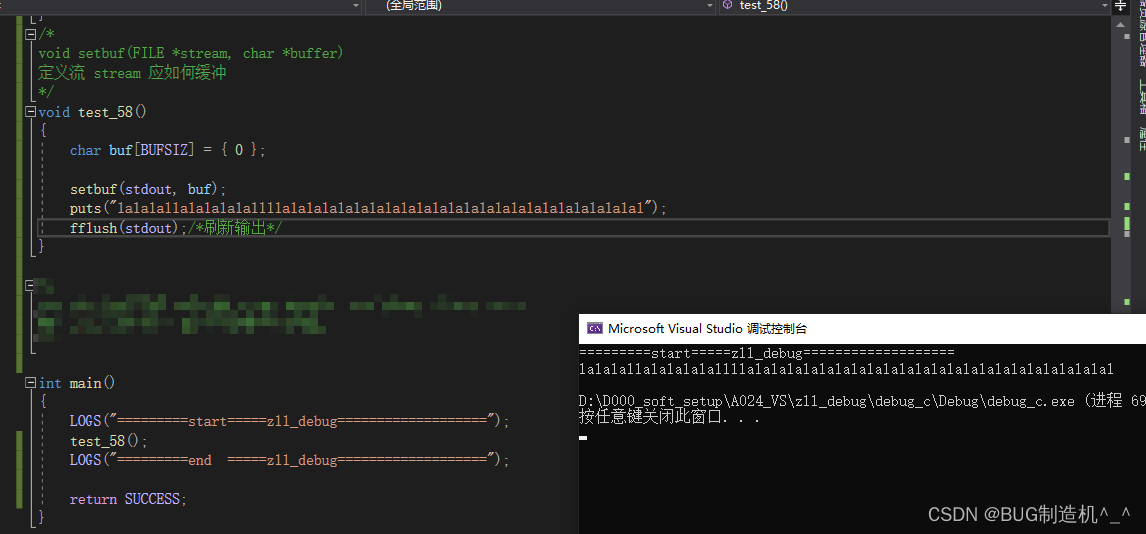
【总结】
这个主要是缓冲到一定量后进行输出,可以用fflush进行刷新输出
【函数19:setvbuf】
【格式】
int setvbuf(FILE *stream, char *buffer, int mode, size_t size)
【功能】
另一个定义流 stream 应如何缓冲的函数
【入参】
FILE *stream:文件流指针
char *buffer:分配给用户的缓冲。如果设置为 NULL,该函数会自动分配一个指定大小的缓冲
int mode:模式
| 模式 | 描述 |
|---|---|
| _IOFBF | 全缓冲:对于输出,数据在缓冲填满时被一次性写入。对于输入,缓冲会在请求输入且缓冲为空时被填充。 |
| _IOLBF | 行缓冲:对于输出,数据在遇到换行符或者在缓冲填满时被写入,具体视情况而定。对于输入,缓冲会在请求输入且缓冲为空时被填充,直到遇到下一个换行符。 |
| _IONBF | 无缓冲:不使用缓冲。每个 I/O 操作都被即时写入。buffer 和 size 参数被忽略。 |
size_t size:这里是缓存的大小,也即是你要使用的buff大小
【返回值】
如果成功,则该函数返回 0,否则返回非零值
【TestCode】
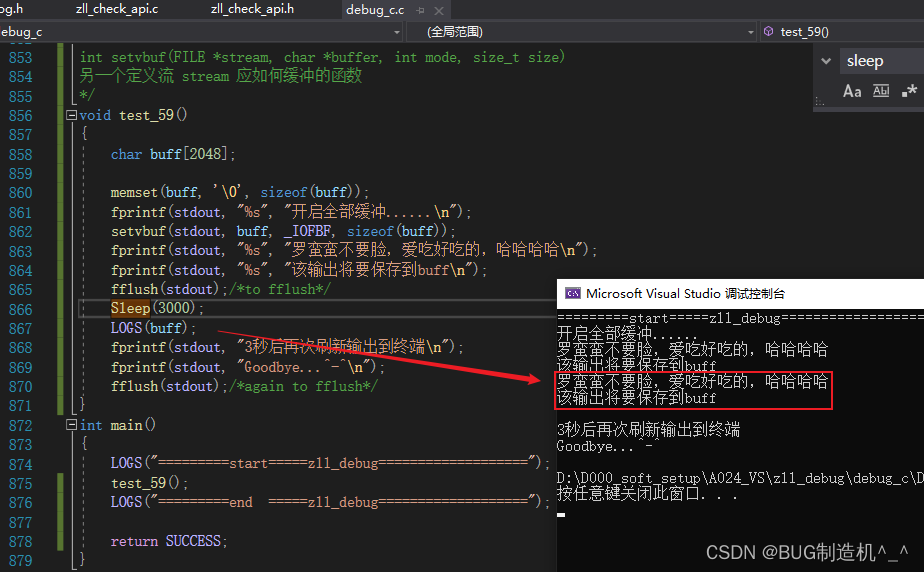
【总结】
这个函数和setbuf函数类似,但是比它更精确些,一般也不经常使用,了解就行
【函数20:tmpfile】
【格式】
FILE *tmpfile(void)
【功能】
以二进制更新模式(wb+)创建临时文件
【入参】
void:无入参
【返回值】
如果成功,该函数返回一个指向被创建的临时文件的流指针。如果文件未被创建,则返回 NULL
【TestCode】
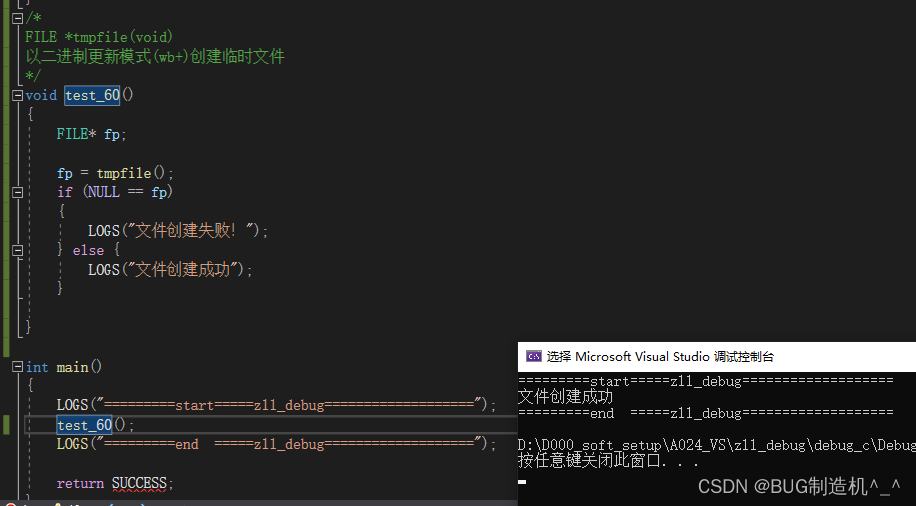
【总结】
具体也不清楚怎么用这个函数,还待深究了解
【函数21:tmpnam】
【格式】
char *tmpnam(char *str)
【功能】
生成并返回一个有效的临时文件名,该文件名之前是不存在的
【入参】
char *str:临时文件名
【返回值】
- 一个指向 C 字符串的指针,该字符串存储了临时文件名。如果 str 是一个空指针,则该指针指向一个内部缓冲区,缓冲区在下一次调用函数时被覆盖。
- 如果 str 不是一个空指针,则返回 str。如果函数未能成功创建可用的文件名,则返回一个空指针
【TestCode】
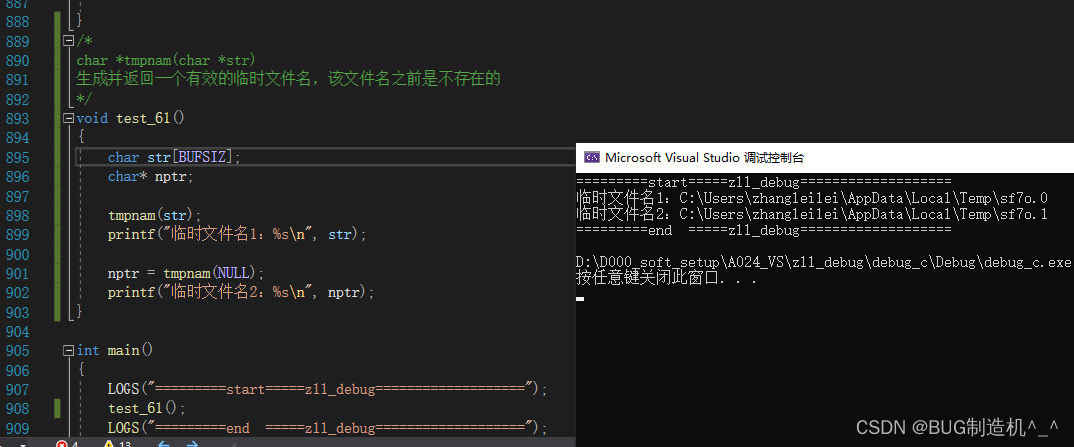
【总结】
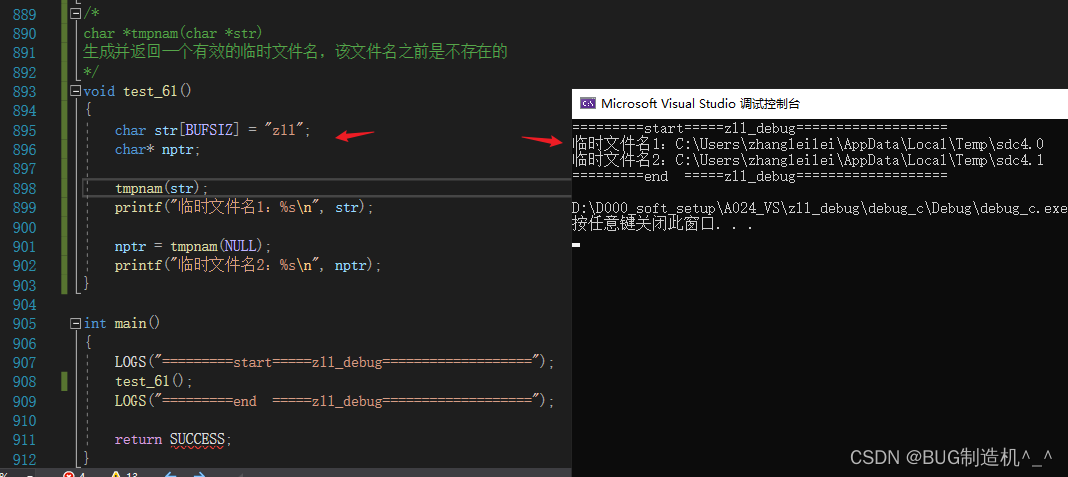
此函数使用时,入参str不能指定确定的名字哦,就算指定了系统也不会用,还会报错,如下:
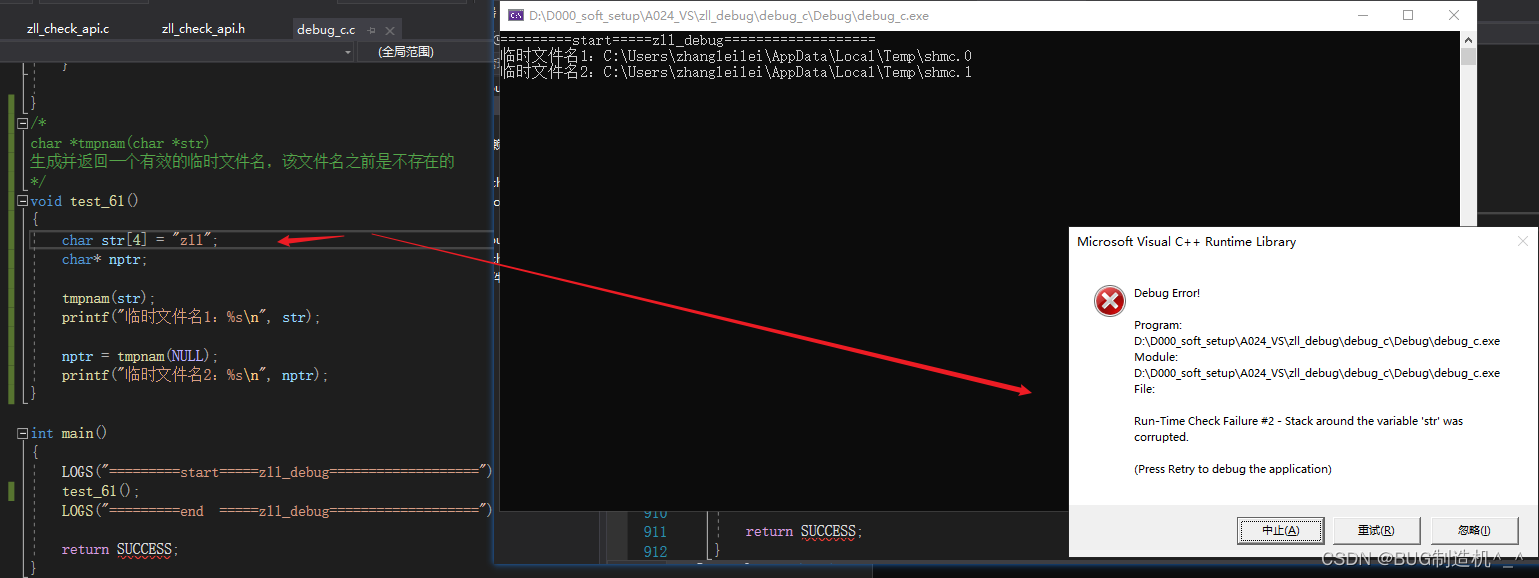
上面报错是因为数组使用完了,定义大点,就不报错,但是也没用指定的名字,如下:
【函数22:fprintf】
【格式】
int fprintf(FILE *stream, const char *format, ...)
【功能】
发送格式化输出到流 stream 中
【入参】
- stream -- 这是指向 FILE 对象的指针,该 FILE 对象标识了流。
- format -- 这是 C 字符串,包含了要被写入到流 stream 中的文本。它可以包含嵌入的 format 标签,format 标签可被随后的附加参数中指定的值替换,并按需求进行格式化。format 标签属性是 %[flags][width][.precision][length]specifier,具体讲解如下:
| specifier(说明符) | 输出 |
|---|---|
| c | 字符 |
| d 或 i | 有符号十进制整数 |
| e | 使用 e 字符的科学科学记数法(尾数和指数) |
| E | 使用 E 字符的科学科学记数法(尾数和指数) |
| f | 十进制浮点数 |
| g | 自动选择 %e 或 %f 中合适的表示法 |
| G | 自动选择 %E 或 %f 中合适的表示法 |
| o | 有符号八进制 |
| s | 字符的字符串 |
| u | 无符号十进制整数 |
| x | 无符号十六进制整数 |
| X | 无符号十六进制整数(大写字母) |
| p | 指针地址 |
| n | 无输出 |
| % | 字符 |
| flags(标识) | 描述 |
|---|---|
| - | 在给定的字段宽度内左对齐,默认是右对齐(参见 width 子说明符)。 |
| + | 强制在结果之前显示加号或减号(+ 或 -),即正数前面会显示 + 号。默认情况下,只有负数前面会显示一个 - 号。 |
| (space) | 如果没有写入任何符号,则在该值前面插入一个空格。 |
| # | 与 o、x 或 X 说明符一起使用时,非零值前面会分别显示 0、0x 或 0X。 与 e、E 和 f 一起使用时,会强制输出包含一个小数点,即使后边没有数字时也会显示小数点。默认情况下,如果后边没有数字时候,不会显示显示小数点。 与 g 或 G 一起使用时,结果与使用 e 或 E 时相同,但是尾部的零不会被移除。 |
| 0 | 在指定填充 padding 的数字左边放置零(0),而不是空格(参见 width 子说明符)。 |
| width(宽度) | 描述 |
|---|---|
| (number) | 要输出的字符的最小数目。如果输出的值短于该数,结果会用空格填充。如果输出的值长于该数,结果不会被截断。 |
| * | 宽度在 format 字符串中未指定,但是会作为附加整数值参数放置于要被格式化的参数之前。 |
| .precision(精度) | 描述 |
|---|---|
| .number | 对于整数说明符(d、i、o、u、x、X):precision 指定了要写入的数字的最小位数。如果写入的值短于该数,结果会用前导零来填充。如果写入的值长于该数,结果不会被截断。精度为 0 意味着不写入任何字符。 对于 e、E 和 f 说明符:要在小数点后输出的小数位数。 对于 g 和 G 说明符:要输出的最大有效位数。 对于 s: 要输出的最大字符数。默认情况下,所有字符都会被输出,直到遇到末尾的空字符。 对于 c 类型:没有任何影响。 当未指定任何精度时,默认为 1。如果指定时不带有一个显式值,则假定为 0。 |
| .* | 精度在 format 字符串中未指定,但是会作为附加整数值参数放置于要被格式化的参数之前。 |
| length(长度) | 描述 |
|---|---|
| h | 参数被解释为短整型或无符号短整型(仅适用于整数说明符:i、d、o、u、x 和 X)。 |
| l | 参数被解释为长整型或无符号长整型,适用于整数说明符(i、d、o、u、x 和 X)及说明符 c(表示一个宽字符)和 s(表示宽字符字符串)。 |
| L | 参数被解释为长双精度型(仅适用于浮点数说明符:e、E、f、g 和 G)。 |
- 附加参数 -- 根据不同的 format 字符串,函数可能需要一系列的附加参数,每个参数包含了一个要被插入的值,替换了 format 参数中指定的每个 % 标签。参数的个数应与 % 标签的个数相同
【返回值】
如果成功,则返回写入的字符总数,否则返回一个负数
【TestCode】
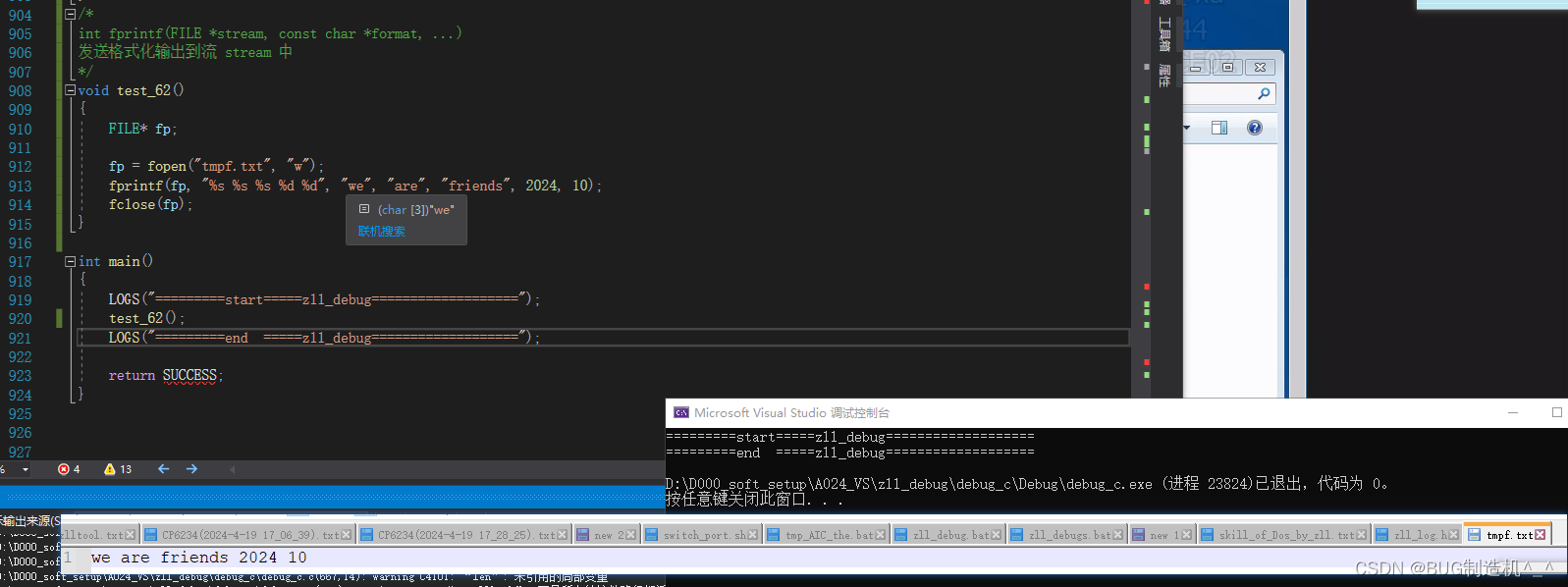
【总结】
根据不同的 format 字符串,函数可能需要一系列的附加参数,每个参数包含了一个要被插入的值,替换了 format 参数中指定的每个 % 标签。参数的个数应与 % 标签的个数相同
【函数23:printf】
【格式】
int printf(const char *format, ...)
【功能】
发送格式化输出到标准输出 stdout
printf("输出格式",<参数表>);
【入参】
-
format -- 这是字符串,包含了要被写入到标准输出 stdout 的文本。它可以包含嵌入的 format 标签,format 标签可被随后的附加参数中指定的值替换,并按需求进行格式化。format 标签属性是 %[flags][width][.precision][length]specifier,具体讲解如下:
| 格式字符 | 意义 |
|---|---|
| a, A | 以十六进制形式输出浮点数(C99 新增)。 实例 printf("pi=%a\n", 3.14); 输出 pi=0x1.91eb86p+1。 |
| d | 以十进制形式输出带符号整数(正数不输出符号) |
| o | 以八进制形式输出无符号整数(不输出前缀0) |
| x,X | 以十六进制形式输出无符号整数(不输出前缀Ox) |
| u | 以十进制形式输出无符号整数 |
| f | 以小数形式输出单、双精度实数 |
| e,E | 以指数形式输出单、双精度实数 |
| g,G | 以%f或%e中较短的输出宽度输出单、双精度实数 |
| c | 输出单个字符 |
| s | 输出字符串 |
| p | 输出指针地址 |
| lu | 32位无符号整数 |
| llu | 64位无符号整数 |
| flags(标识) | 描述 |
|---|---|
| - | 在给定的字段宽度内左对齐,默认是右对齐(参见 width 子说明符)。 |
| + | 强制在结果之前显示加号或减号(+ 或 -),即正数前面会显示 + 号。默认情况下,只有负数前面会显示一个 - 号。 |
| 空格 | 如果没有写入任何符号,则在该值前面插入一个空格。 |
| # | 与 o、x 或 X 说明符一起使用时,非零值前面会分别显示 0、0x 或 0X。 与 e、E 和 f 一起使用时,会强制输出包含一个小数点,即使后边没有数字时也会显示小数点。默认情况下,如果后边没有数字时候,不会显示显示小数点。 与 g 或 G 一起使用时,结果与使用 e 或 E 时相同,但是尾部的零不会被移除。 |
| 0 | 在指定填充 padding 的数字左边放置零(0),而不是空格(参见 width 子说明符)。 |
| width(宽度) | 描述 |
|---|---|
| (number) | 要输出的字符的最小数目。如果输出的值短于该数,结果会用空格填充。如果输出的值长于该数,结果不会被截断。 |
| * | 宽度在 format 字符串中未指定,但是会作为附加整数值参数放置于要被格式化的参数之前。 |
| .precision(精度) | 描述 |
|---|---|
| .number | 对于整数说明符(d、i、o、u、x、X):precision 指定了要写入的数字的最小位数。如果写入的值短于该数,结果会用前导零来填充。如果写入的值长于该数,结果不会被截断。精度为 0 意味着不写入任何字符。 对于 e、E 和 f 说明符:要在小数点后输出的小数位数。 对于 g 和 G 说明符:要输出的最大有效位数。 对于 s: 要输出的最大字符数。默认情况下,所有字符都会被输出,直到遇到末尾的空字符。 对于 c 类型:没有任何影响。 当未指定任何精度时,默认为 1。如果指定时不带有一个显式值,则假定为 0。 |
| .* | 精度在 format 字符串中未指定,但是会作为附加整数值参数放置于要被格式化的参数之前。 |
| length(长度) | 描述 |
|---|---|
| h | 参数被解释为短整型或无符号短整型(仅适用于整数说明符:i、d、o、u、x 和 X)。 |
| l | 参数被解释为长整型或无符号长整型,适用于整数说明符(i、d、o、u、x 和 X)及说明符 c(表示一个宽字符)和 s(表示宽字符字符串)。 |
| L | 参数被解释为长双精度型(仅适用于浮点数说明符:e、E、f、g 和 G)。 |
-
附加参数 -- 根据不同的 format 字符串,函数可能需要一系列的附加参数,每个参数包含了一个要被插入的值,替换了 format 参数中指定的每个 % 标签。参数的个数应与 % 标签的个数相同
【返回值】
如果成功,则返回写入的字符总数,否则返回一个负数
【TestCode】

【总结】
和fprintf用法类似,只不过fprintf是网文件流里写数据,而printf是往sdtout输出数据
注意点:
根据不同的 format 字符串,函数可能需要一系列的附加参数,每个参数包含了一个要被插入的值,替换了 format 参数中指定的每个 % 标签。参数的个数应与 % 标签的个数相同
【函数24:sprintf】
【格式】
int sprintf(char *str, const char *format, ...)
【功能】
发送格式化输出到字符串
【入参】
- str -- 这是指向一个字符数组的指针,该数组存储了 C 字符串。
- format -- 这是字符串,包含了要被写入到字符串 str 的文本。它可以包含嵌入的 format 标签,format 标签可被随后的附加参数中指定的值替换,并按需求进行格式化。format 标签属性是 %[flags][width][.precision][length]specifier,具体讲解如下:
| specifier(说明符) | 输出 |
|---|---|
| c | 字符 |
| d 或 i | 有符号十进制整数 |
| e | 使用 e 字符的科学科学记数法(尾数和指数) |
| E | 使用 E 字符的科学科学记数法(尾数和指数) |
| f | 十进制浮点数 |
| g | 自动选择 %e 或 %f 中合适的表示法 |
| G | 自动选择 %E 或 %f 中合适的表示法 |
| o | 有符号八进制 |
| s | 字符的字符串 |
| u | 无符号十进制整数 |
| x | 无符号十六进制整数 |
| X | 无符号十六进制整数(大写字母) |
| p | 指针地址 |
| n | 无输出 |
| % | 字符 |
| flags(标识) | 描述 |
|---|---|
| - | 在给定的字段宽度内左对齐,默认是右对齐(参见 width 子说明符)。 |
| + | 强制在结果之前显示加号或减号(+ 或 -),即正数前面会显示 + 号。默认情况下,只有负数前面会显示一个 - 号。 |
| (space) | 如果没有写入任何符号,则在该值前面插入一个空格。 |
| # | 与 o、x 或 X 说明符一起使用时,非零值前面会分别显示 0、0x 或 0X。 与 e、E 和 f 一起使用时,会强制输出包含一个小数点,即使后边没有数字时也会显示小数点。默认情况下,如果后边没有数字时候,不会显示显示小数点。 与 g 或 G 一起使用时,结果与使用 e 或 E 时相同,但是尾部的零不会被移除。 |
| 0 | 在指定填充 padding 的数字左边放置零(0),而不是空格(参见 width 子说明符)。 |
| width(宽度) | 描述 |
|---|---|
| (number) | 要输出的字符的最小数目。如果输出的值短于该数,结果会用空格填充。如果输出的值长于该数,结果不会被截断。 |
| * | 宽度在 format 字符串中未指定,但是会作为附加整数值参数放置于要被格式化的参数之前。 |
| .precision(精度) | 描述 |
|---|---|
| .number | 对于整数说明符(d、i、o、u、x、X):precision 指定了要写入的数字的最小位数。如果写入的值短于该数,结果会用前导零来填充。如果写入的值长于该数,结果不会被截断。精度为 0 意味着不写入任何字符。 对于 e、E 和 f 说明符:要在小数点后输出的小数位数。 对于 g 和 G 说明符:要输出的最大有效位数。 对于 s: 要输出的最大字符数。默认情况下,所有字符都会被输出,直到遇到末尾的空字符。 对于 c 类型:没有任何影响。 当未指定任何精度时,默认为 1。如果指定时不带有一个显式值,则假定为 0。 |
| .* | 精度在 format 字符串中未指定,但是会作为附加整数值参数放置于要被格式化的参数之前。 |
| length(长度) | 描述 |
|---|---|
| h | 参数被解释为短整型或无符号短整型(仅适用于整数说明符:i、d、o、u、x 和 X)。 |
| l | 参数被解释为长整型或无符号长整型,适用于整数说明符(i、d、o、u、x 和 X)及说明符 c(表示一个宽字符)和 s(表示宽字符字符串)。 |
| L | 参数被解释为长双精度型(仅适用于浮点数说明符:e、E、f、g 和 G)。 |
- 附加参数 -- 根据不同的 format 字符串,函数可能需要一系列的附加参数,每个参数包含了一个要被插入的值,替换了 format 参数中指定的每个 % 标签。参数的个数应与 % 标签的个数相同
【返回值】
如果成功,则返回写入的字符总数,不包括字符串追加在字符串末尾的空字符。如果失败,则返回一个负数
【TestCode】
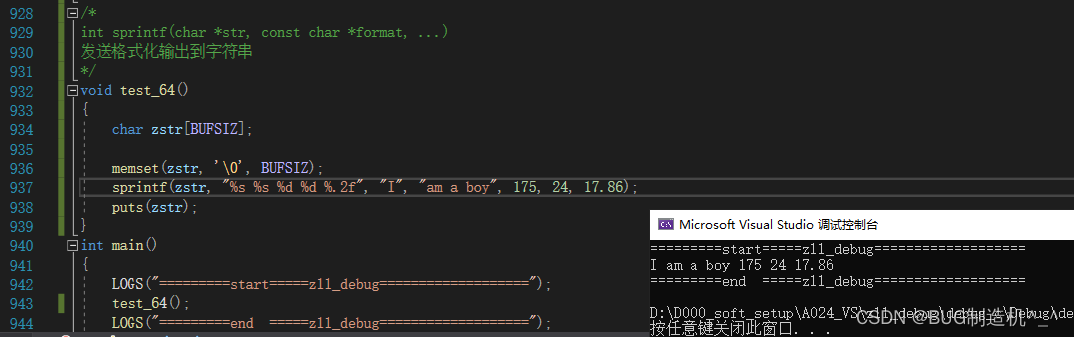
【总结】
这个与fprintf和printf用法类似,但是这个是往数组里写入数据的哦,注意点如下:
1.注意附加参数的使用方法
2.注意数组不要越界
【函数25:vfprintf】
【格式】
int vfprintf(FILE *stream, const char *format, va_list arg)
【功能】
使用参数列表发送格式化输出到流 stream 中
【入参】
- stream -- 这是指向 FILE 对象的指针,该 FILE 对象标识了流。
- format -- 这是 C 字符串,包含了要被写入到流 stream 中的文本。它可以包含嵌入的 format 标签,format 标签可被随后的附加参数中指定的值替换,并按需求进行格式化。format 标签属性是 %[flags][width][.precision][length]specifier,具体讲解如下:
| specifier(说明符) | 输出 |
|---|---|
| c | 字符 |
| d 或 i | 有符号十进制整数 |
| e | 使用 e 字符的科学科学记数法(尾数和指数) |
| E | 使用 E 字符的科学科学记数法(尾数和指数) |
| f | 十进制浮点数 |
| g | 自动选择 %e 或 %f 中合适的表示法 |
| G | 自动选择 %E 或 %f 中合适的表示法 |
| o | 有符号八进制 |
| s | 字符的字符串 |
| u | 无符号十进制整数 |
| x | 无符号十六进制整数 |
| X | 无符号十六进制整数(大写字母) |
| p | 指针地址 |
| n | 无输出 |
| % | 字符 |
| flags(标识) | 描述 |
|---|---|
| - | 在给定的字段宽度内左对齐,默认是右对齐(参见 width 子说明符)。 |
| + | 强制在结果之前显示加号或减号(+ 或 -),即正数前面会显示 + 号。默认情况下,只有负数前面会显示一个 - 号。 |
| (space) | 如果没有写入任何符号,则在该值前面插入一个空格。 |
| # | 与 o、x 或 X 说明符一起使用时,非零值前面会分别显示 0、0x 或 0X。 与 e、E 和 f 一起使用时,会强制输出包含一个小数点,即使后边没有数字时也会显示小数点。默认情况下,如果后边没有数字时候,不会显示显示小数点。 与 g 或 G 一起使用时,结果与使用 e 或 E 时相同,但是尾部的零不会被移除。 |
| 0 | 在指定填充 padding 的数字左边放置零(0),而不是空格(参见 width 子说明符)。 |
| width(宽度) | 描述 |
|---|---|
| (number) | 要输出的字符的最小数目。如果输出的值短于该数,结果会用空格填充。如果输出的值长于该数,结果不会被截断。 |
| * | 宽度在 format 字符串中未指定,但是会作为附加整数值参数放置于要被格式化的参数之前。 |
| .precision(精度) | 描述 |
|---|---|
| .number | 对于整数说明符(d、i、o、u、x、X):precision 指定了要写入的数字的最小位数。如果写入的值短于该数,结果会用前导零来填充。如果写入的值长于该数,结果不会被截断。精度为 0 意味着不写入任何字符。 对于 e、E 和 f 说明符:要在小数点后输出的小数位数。 对于 g 和 G 说明符:要输出的最大有效位数。 对于 s: 要输出的最大字符数。默认情况下,所有字符都会被输出,直到遇到末尾的空字符。 对于 c 类型:没有任何影响。 当未指定任何精度时,默认为 1。如果指定时不带有一个显式值,则假定为 0。 |
| .* | 精度在 format 字符串中未指定,但是会作为附加整数值参数放置于要被格式化的参数之前。 |
| length(长度) | 描述 |
|---|---|
| h | 参数被解释为短整型或无符号短整型(仅适用于整数说明符:i、d、o、u、x 和 X)。 |
| l | 参数被解释为长整型或无符号长整型,适用于整数说明符(i、d、o、u、x 和 X)及说明符 c(表示一个宽字符)和 s(表示宽字符字符串)。 |
| L | 参数被解释为长双精度型(仅适用于浮点数说明符:e、E、f、g 和 G)。 |
- arg -- 一个表示可变参数列表的对象。这应被 <stdarg> 中定义的 va_start 宏初始化
【返回值】
如果成功,则返回写入的字符总数,否则返回一个负数
【TestCode】
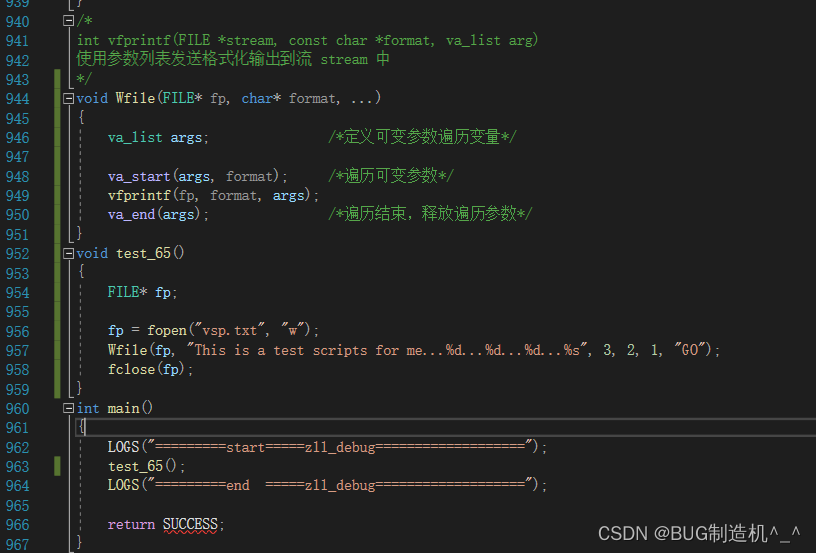
【总结】
009_C标准库函数之<stdarg.h>-CSDN博客
对于可变参数可以看上面这个文章,熟悉后再来使用vfprintf函数,会事半功倍
【函数26:vprintf】
【格式】
int vprintf(const char *format, va_list arg)
【功能】
使用参数列表发送格式化输出到标准输出 stdout
【入参】
- format -- 这是字符串,包含了要被写入到标准输出 stdout 的文本。它可以包含嵌入的 format 标签,format 标签可被随后的附加参数中指定的值替换,并按需求进行格式化。format 标签属性是 %[flags][width][.precision][length]specifier,具体讲解如下:
| specifier(说明符) | 输出 |
|---|---|
| c | 字符 |
| d 或 i | 有符号十进制整数 |
| e | 使用 e 字符的科学科学记数法(尾数和指数) |
| E | 使用 E 字符的科学科学记数法(尾数和指数) |
| f | 十进制浮点数 |
| g | 自动选择 %e 或 %f 中合适的表示法 |
| G | 自动选择 %E 或 %f 中合适的表示法 |
| o | 有符号八进制 |
| s | 字符的字符串 |
| u | 无符号十进制整数 |
| x | 无符号十六进制整数 |
| X | 无符号十六进制整数(大写字母) |
| p | 指针地址 |
| n | 无输出 |
| % | 字符 |
| flags(标识) | 描述 |
|---|---|
| - | 在给定的字段宽度内左对齐,默认是右对齐(参见 width 子说明符)。 |
| + | 强制在结果之前显示加号或减号(+ 或 -),即正数前面会显示 + 号。默认情况下,只有负数前面会显示一个 - 号。 |
| (space) | 如果没有写入任何符号,则在该值前面插入一个空格。 |
| # | 与 o、x 或 X 说明符一起使用时,非零值前面会分别显示 0、0x 或 0X。 与 e、E 和 f 一起使用时,会强制输出包含一个小数点,即使后边没有数字时也会显示小数点。默认情况下,如果后边没有数字时候,不会显示显示小数点。 与 g 或 G 一起使用时,结果与使用 e 或 E 时相同,但是尾部的零不会被移除。 |
| 0 | 在指定填充 padding 的数字左边放置零(0),而不是空格(参见 width 子说明符)。 |
| width(宽度) | 描述 |
|---|---|
| (number) | 要输出的字符的最小数目。如果输出的值短于该数,结果会用空格填充。如果输出的值长于该数,结果不会被截断。 |
| * | 宽度在 format 字符串中未指定,但是会作为附加整数值参数放置于要被格式化的参数之前。 |
| .precision(精度) | 描述 |
|---|---|
| .number | 对于整数说明符(d、i、o、u、x、X):precision 指定了要写入的数字的最小位数。如果写入的值短于该数,结果会用前导零来填充。如果写入的值长于该数,结果不会被截断。精度为 0 意味着不写入任何字符。 对于 e、E 和 f 说明符:要在小数点后输出的小数位数。 对于 g 和 G 说明符:要输出的最大有效位数。 对于 s: 要输出的最大字符数。默认情况下,所有字符都会被输出,直到遇到末尾的空字符。 对于 c 类型:没有任何影响。 当未指定任何精度时,默认为 1。如果指定时不带有一个显式值,则假定为 0。 |
| .* | 精度在 format 字符串中未指定,但是会作为附加整数值参数放置于要被格式化的参数之前。 |
| length(长度) | 描述 |
|---|---|
| h | 参数被解释为短整型或无符号短整型(仅适用于整数说明符:i、d、o、u、x 和 X)。 |
| l | 参数被解释为长整型或无符号长整型,适用于整数说明符(i、d、o、u、x 和 X)及说明符 c(表示一个宽字符)和 s(表示宽字符字符串)。 |
| L | 参数被解释为长双精度型(仅适用于浮点数说明符:e、E、f、g 和 G)。 |
- arg -- 一个表示可变参数列表的对象。这应被 <stdarg> 中定义的 va_start 宏初始化
【返回值】
如果成功,则返回写入的字符总数,否则返回一个负数
【TestCode】
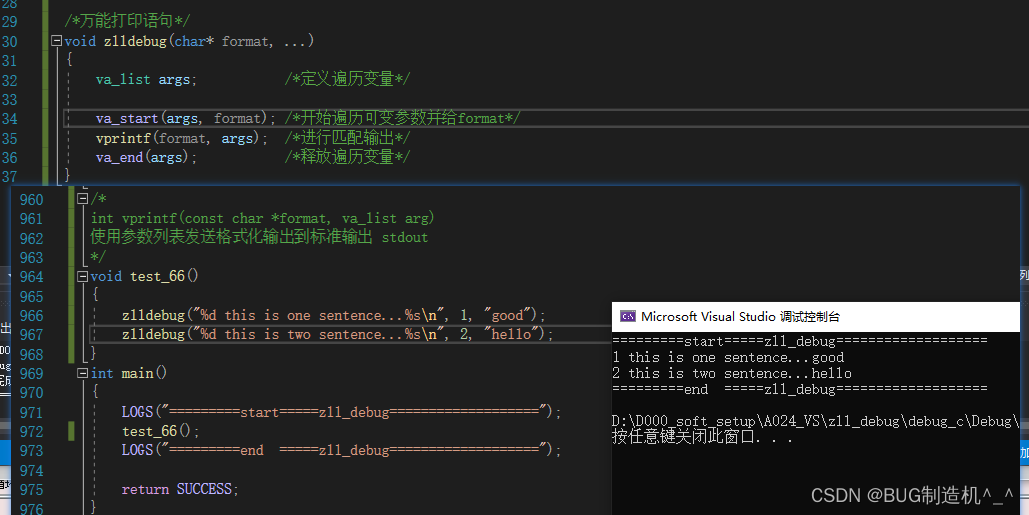
【总结】
记得在使用vprintf的时候,一定要包含stdarg.h头文件,因为有va_list args;变量需要定义
说实话,我感觉这个vprintf和printf函数没多大区别,都是往终端输出自定义内容格式的,为啥要这么搞?有清楚的大神麻烦解释下,小弟在此谢过,3Q
【函数27:vsprintf】
【格式】
int vsprintf(char *str, const char *format, va_list arg)
【功能】
使用参数列表发送格式化输出到字符串
【入参】
- str -- 这是指向一个字符数组的指针,该数组存储了 C 字符串。
- format -- 这是字符串,包含了要被写入到字符串 str 的文本。它可以包含嵌入的 format 标签,format 标签可被随后的附加参数中指定的值替换,并按需求进行格式化。format 标签属性是 %[flags][width][.precision][length]specifier,具体讲解如下:
| specifier(说明符) | 输出 |
|---|---|
| c | 字符 |
| d 或 i | 有符号十进制整数 |
| e | 使用 e 字符的科学科学记数法(尾数和指数) |
| E | 使用 E 字符的科学科学记数法(尾数和指数) |
| f | 十进制浮点数 |
| g | 自动选择 %e 或 %f 中合适的表示法 |
| G | 自动选择 %E 或 %f 中合适的表示法 |
| o | 有符号八进制 |
| s | 字符的字符串 |
| u | 无符号十进制整数 |
| x | 无符号十六进制整数 |
| X | 无符号十六进制整数(大写字母) |
| p | 指针地址 |
| n | 无输出 |
| % | 字符 |
| flags(标识) | 描述 |
|---|---|
| - | 在给定的字段宽度内左对齐,默认是右对齐(参见 width 子说明符)。 |
| + | 强制在结果之前显示加号或减号(+ 或 -),即正数前面会显示 + 号。默认情况下,只有负数前面会显示一个 - 号。 |
| (space) | 如果没有写入任何符号,则在该值前面插入一个空格。 |
| # | 与 o、x 或 X 说明符一起使用时,非零值前面会分别显示 0、0x 或 0X。 与 e、E 和 f 一起使用时,会强制输出包含一个小数点,即使后边没有数字时也会显示小数点。默认情况下,如果后边没有数字时候,不会显示显示小数点。 与 g 或 G 一起使用时,结果与使用 e 或 E 时相同,但是尾部的零不会被移除。 |
| 0 | 在指定填充 padding 的数字左边放置零(0),而不是空格(参见 width 子说明符)。 |
| width(宽度) | 描述 |
|---|---|
| (number) | 要输出的字符的最小数目。如果输出的值短于该数,结果会用空格填充。如果输出的值长于该数,结果不会被截断。 |
| * | 宽度在 format 字符串中未指定,但是会作为附加整数值参数放置于要被格式化的参数之前。 |
| .precision(精度) | 描述 |
|---|---|
| .number | 对于整数说明符(d、i、o、u、x、X):precision 指定了要写入的数字的最小位数。如果写入的值短于该数,结果会用前导零来填充。如果写入的值长于该数,结果不会被截断。精度为 0 意味着不写入任何字符。 对于 e、E 和 f 说明符:要在小数点后输出的小数位数。 对于 g 和 G 说明符:要输出的最大有效位数。 对于 s: 要输出的最大字符数。默认情况下,所有字符都会被输出,直到遇到末尾的空字符。 对于 c 类型:没有任何影响。 当未指定任何精度时,默认为 1。如果指定时不带有一个显式值,则假定为 0。 |
| .* | 精度在 format 字符串中未指定,但是会作为附加整数值参数放置于要被格式化的参数之前。 |
| length(长度) | 描述 |
|---|---|
| h | 参数被解释为短整型或无符号短整型(仅适用于整数说明符:i、d、o、u、x 和 X)。 |
| l | 参数被解释为长整型或无符号长整型,适用于整数说明符(i、d、o、u、x 和 X)及说明符 c(表示一个宽字符)和 s(表示宽字符字符串)。 |
| L | 参数被解释为长双精度型(仅适用于浮点数说明符:e、E、f、g 和 G)。 |
- arg -- 一个表示可变参数列表的对象。这应被 <stdarg> 中定义的 va_start 宏初始化
【返回值】
如果成功,则返回写入的字符总数,否则返回一个负数
【TestCode】

【总结】
1.vsprintf主要是往字符数组里写入固定格式的字符内容
2.返回值字符总数并不包括结束符'\0'
【函数28:fscnaf】
【格式】
int fscanf(FILE *stream, const char *format, ...)
【功能】
从流 stream 读取格式化输入
【入参】
- stream -- 这是指向 FILE 对象的指针,该 FILE 对象标识了流。
- format -- 这是 C 字符串,包含了以下各项中的一个或多个:空格字符、非空格字符 和 format 说明符。
format 说明符形式为 [=%[*][width][modifiers]type=],具体讲解如下:
| 参数 | 描述 |
|---|---|
| * | 这是一个可选的星号,表示数据是从流 stream 中读取的,但是可以被忽视,即它不存储在对应的参数中。 |
| width | 这指定了在当前读取操作中读取的最大字符数。 |
| modifiers | 为对应的附加参数所指向的数据指定一个不同于整型(针对 d、i 和 n)、无符号整型(针对 o、u 和 x)或浮点型(针对 e、f 和 g)的大小: h :短整型(针对 d、i 和 n),或无符号短整型(针对 o、u 和 x) l :长整型(针对 d、i 和 n),或无符号长整型(针对 o、u 和 x),或双精度型(针对 e、f 和 g) L :长双精度型(针对 e、f 和 g) |
| type | 一个字符,指定了要被读取的数据类型以及数据读取方式。具体参见下一个表格。 |
fscanf 类型说明符:
| 类型 | 合格的输入 | 参数的类型 |
|---|---|---|
| c | 单个字符:读取下一个字符。如果指定了一个不为 1 的宽度 width,函数会读取 width 个字符,并通过参数传递,把它们存储在数组中连续位置。在末尾不会追加空字符。 | char * |
| d | 十进制整数:数字前面的 + 或 - 号是可选的。 | int * |
| e,E,f,g,G | 浮点数:包含了一个小数点、一个可选的前置符号 + 或 -、一个可选的后置字符 e 或 E,以及一个十进制数字。两个有效的实例 -732.103 和 7.12e4 | float * |
| o | 八进制整数。 | int * |
| s | 字符串。这将读取连续字符,直到遇到一个空格字符(空格字符可以是空白、换行和制表符)。 | char * |
| u | 无符号的十进制整数。 | unsigned int * |
| x,X | 十六进制整数。 | int * |
- 附加参数 -- 根据不同的 format 字符串,函数可能需要一系列的附加参数,每个参数包含了一个要被插入的值,替换了 format 参数中指定的每个 % 标签。参数的个数应与 % 标签的个数相同
【返回值】
如果成功,该函数返回成功匹配和赋值的个数。如果到达文件末尾或发生读错误,则返回 EOF
【TestCode】

【总结】
注意下面这段代码:
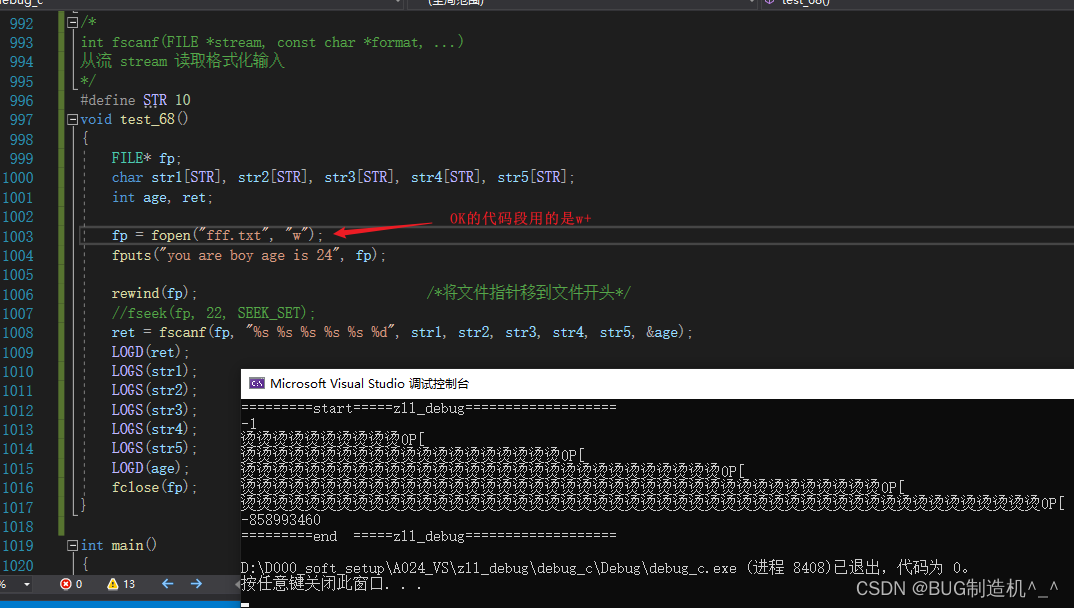
我们看下w和w+的区别,如下:
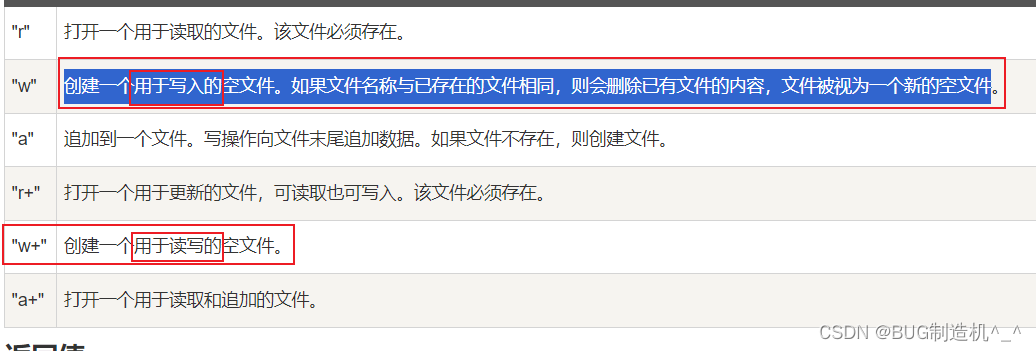
就是说w会创建一个用于写入的空文件,这个模式下是不支持读的,所以我们会返回EOF(-1);w+模式是支持读写的,所以我们读的时候是OK的哦,那么如果我们就是想用w,怎么办呢?如下:
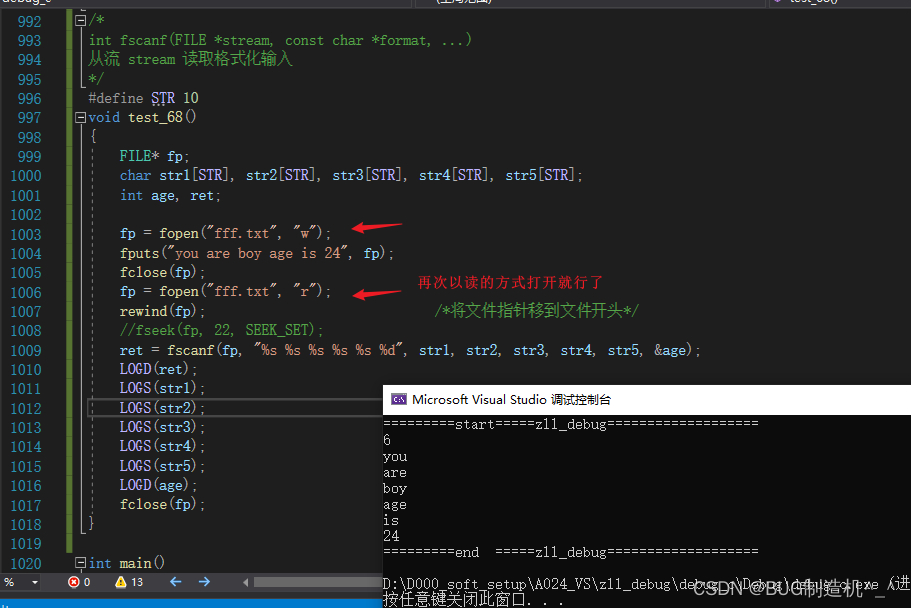
还有就是注意:fscnaf是以format格式从文件流中读出数据再写入变量中,供我们使用的!
【函数29:scanf】
【格式】
int scanf(const char *format, ...)
【功能】
从标准输入 stdin 读取格式化输入
【入参】
- format -- 这是 C 字符串,包含了以下各项中的一个或多个:空格字符、非空格字符 和 format 说明符。
format 说明符形式为:
[=%[*][width][modifiers]type=]
具体讲解如下:
| 参数 | 描述 |
|---|---|
| * | 这是一个可选的星号,表示数据是从流 stream 中读取的,但是可以被忽视,即它不存储在对应的参数中。 |
| width | 这指定了在当前读取操作中读取的最大字符数。 |
| modifiers | 为对应的附加参数所指向的数据指定一个不同于整型(针对 d、i 和 n)、无符号整型(针对 o、u 和 x)或浮点型(针对 e、f 和 g)的大小: h :短整型(针对 d、i 和 n),或无符号短整型(针对 o、u 和 x) l :长整型(针对 d、i 和 n),或无符号长整型(针对 o、u 和 x),或双精度型(针对 e、f 和 g) L :长双精度型(针对 e、f 和 g) |
| type | 一个字符,指定了要被读取的数据类型以及数据读取方式。具体参见下一个表格。 |
scanf 类型说明符:
| 类型 | 合格的输入 | 参数的类型 |
|---|---|---|
| %a、%A | 读入一个浮点值(仅 C99 有效)。 | float * |
| %c | 单个字符:读取下一个字符。如果指定了一个不为 1 的宽度 width,函数会读取 width 个字符,并通过参数传递,把它们存储在数组中连续位置。在末尾不会追加空字符。 | char * |
| %d | 十进制整数:数字前面的 + 或 - 号是可选的。 | int * |
| %e、%E、%f、%F、%g、%G | 浮点数:包含了一个小数点、一个可选的前置符号 + 或 -、一个可选的后置字符 e 或 E,以及一个十进制数字。两个有效的实例 -732.103 和 7.12e4 | float * |
| %i | 读入十进制,八进制,十六进制整数 。 | int * |
| %o | 八进制整数。 | int * |
| %s | 字符串。这将读取连续字符,直到遇到一个空格字符(空格字符可以是空白、换行和制表符)。 | char * |
| %u | 无符号的十进制整数。 | unsigned int * |
| %x、%X | 十六进制整数。 | int * |
| %p | 读入一个指针 。 | |
| %[] | 扫描字符集合 。 | |
| %% | 读 % 符号。 |
- 附加参数 -- 根据不同的 format 字符串,函数可能需要一系列的附加参数,每个参数包含了一个要被插入的值,替换了 format 参数中指定的每个 % 标签。参数的个数应与 % 标签的个数相同
【返回值】
如果成功,该函数返回成功匹配和赋值的个数。如果到达文件末尾或发生读错误,则返回 EOF
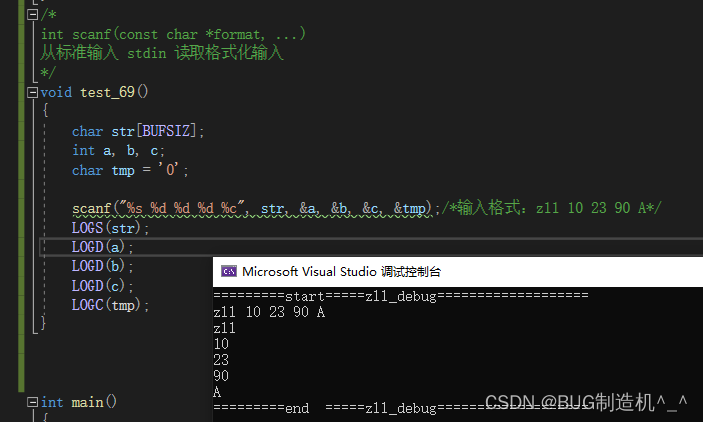
【TestCode】
没有逗号的输入
有逗号的输入
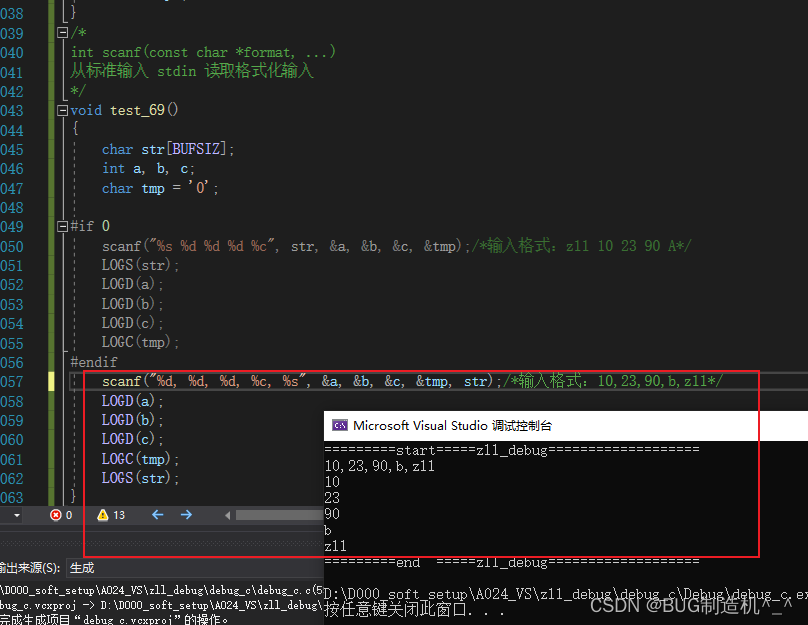
【总结】

这样的时候会乱码,为什么?因为str比较大,会把所有的输入都装进去,目前最好的解决方法就是放到末尾进行输入,如下:
scanf的输入会根据格式而有所不同,所以这个一定要谨慎,一定要验证验证验证!
【函数30:sscanf】
【格式】
int sscanf(const char *str, const char *format, ...)
【功能】
从字符串读取格式化输入
【入参】
- str -- 这是 C 字符串,是函数检索数据的源。
- format -- 这是 C 字符串,包含了以下各项中的一个或多个:空格字符、非空格字符 和 format 说明符。
format 说明符形式为 [=%[*][width][modifiers]type=],具体讲解如下:
| 参数 | 描述 |
|---|---|
| * | 这是一个可选的星号,表示数据是从流 stream 中读取的,但是可以被忽视,即它不存储在对应的参数中。 |
| width | 这指定了在当前读取操作中读取的最大字符数。 |
| modifiers | 为对应的附加参数所指向的数据指定一个不同于整型(针对 d、i 和 n)、无符号整型(针对 o、u 和 x)或浮点型(针对 e、f 和 g)的大小: h :短整型(针对 d、i 和 n),或无符号短整型(针对 o、u 和 x) l :长整型(针对 d、i 和 n),或无符号长整型(针对 o、u 和 x),或双精度型(针对 e、f 和 g) L :长双精度型(针对 e、f 和 g) |
| type | 一个字符,指定了要被读取的数据类型以及数据读取方式。具体参见下一个表格。 |
sscanf 类型说明符:
| 类型 | 合格的输入 | 参数的类型 |
|---|---|---|
| c | 单个字符:读取下一个字符。如果指定了一个不为 1 的宽度 width,函数会读取 width 个字符,并通过参数传递,把它们存储在数组中连续位置。在末尾不会追加空字符。 | char * |
| d | 十进制整数:数字前面的 + 或 - 号是可选的。 | int * |
| e,E,f,g,G | 浮点数:包含了一个小数点、一个可选的前置符号 + 或 -、一个可选的后置字符 e 或 E,以及一个十进制数字。两个有效的实例 -732.103 和 7.12e4 | float * |
| o | 八进制整数。 | int * |
| s | 字符串。这将读取连续字符,直到遇到一个空格字符(空格字符可以是空白、换行和制表符)。 | char * |
| u | 无符号的十进制整数。 | unsigned int * |
| x,X | 十六进制整数。 | int * |
- 附加参数 -- 这个函数接受一系列的指针作为附加参数,每一个指针都指向一个对象,对象类型由 format 字符串中相应的 % 标签指定,参数与 % 标签的顺序相同。
针对检索数据的 format 字符串中的每个 format 说明符,应指定一个附加参数。如果您想要把 sscanf 操作的结果存储在一个普通的变量中,您应该在标识符前放置引用运算符(&)
【返回值】
如果成功,该函数返回成功匹配和赋值的个数。如果到达文件末尾或发生读错误,则返回 EOF
【TestCode】
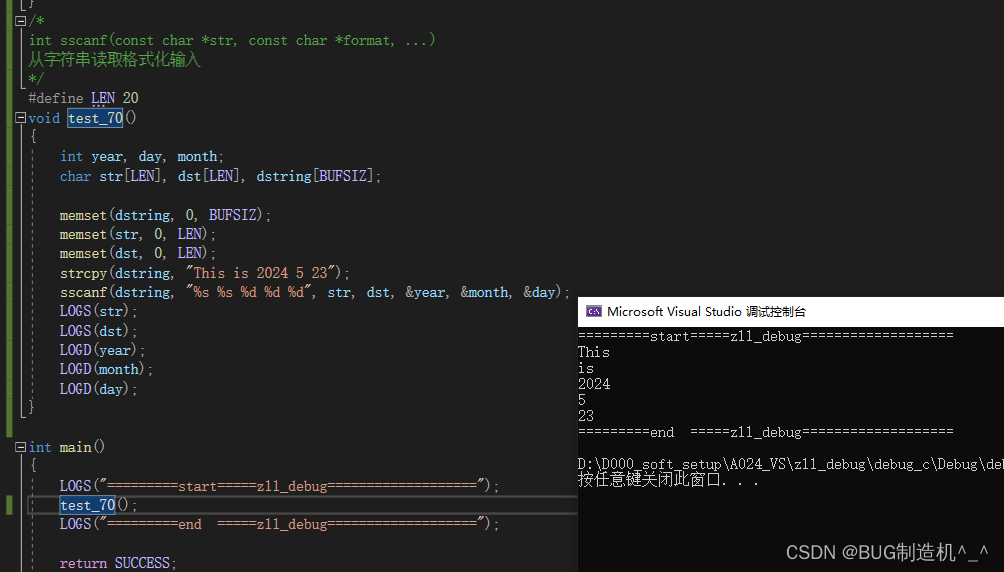
【总结】
注意区分fscanf和sscanf的区别:fscanf是从文件流中读取数据内容,填写到变量中;sscanf是从串中读取数据内容,填写到变量中,两者的源文件目标不同,但是格式和目的变量是一样的用法哦
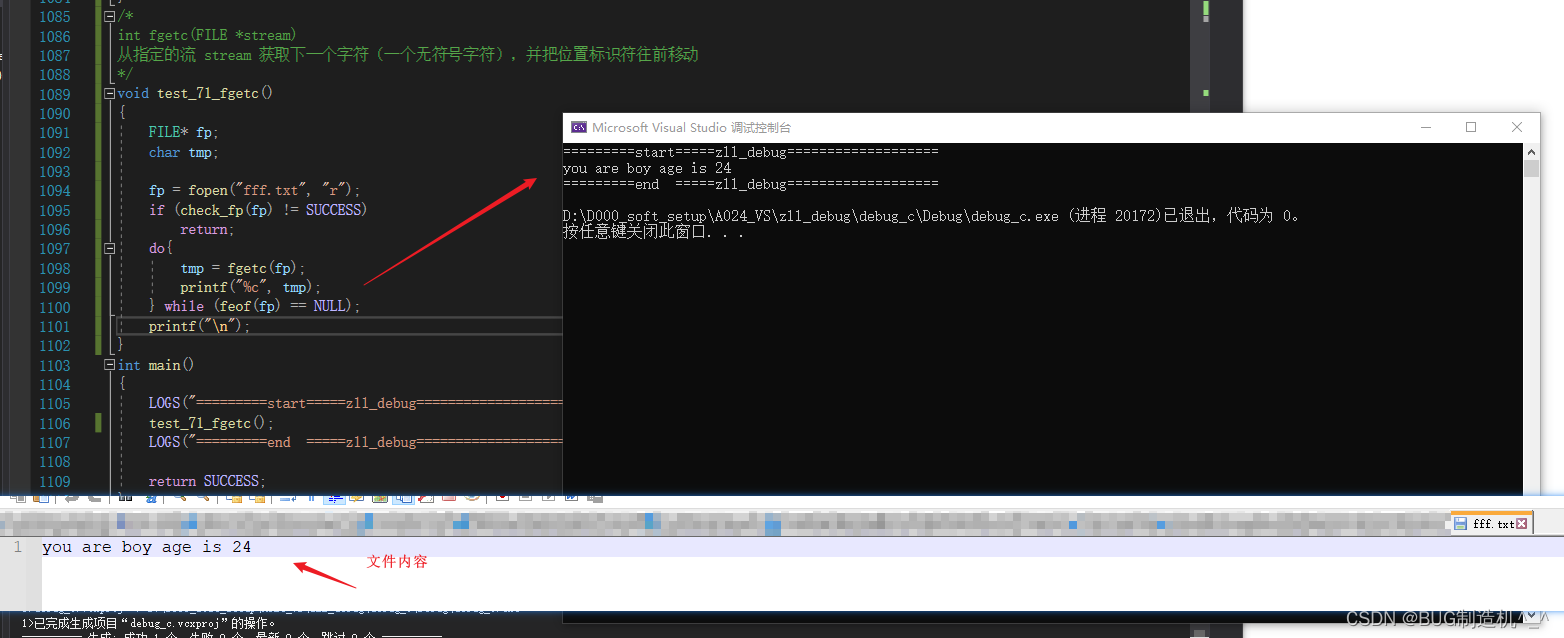
【函数31:fgetc】
【格式】
int fgetc(FILE *stream)
【功能】
从指定的流 stream 获取下一个字符(一个无符号字符),并把位置标识符往前移动
【入参】
stream -- 这是指向 FILE 对象的指针,该 FILE 对象标识了要在上面执行操作的流
【返回值】
该函数以无符号 char 强制转换为 int 的形式返回读取的字符,如果到达文件末尾或发生读错误,则返回 EOF
【TestCode】
【总结】
fgetc函数是逐一的去读取字符,完后,光标向后自动移动一格,所以我们读取的时候要使用do_while结构去操作下,条件就是feof函数去检测是否到了文件流末尾
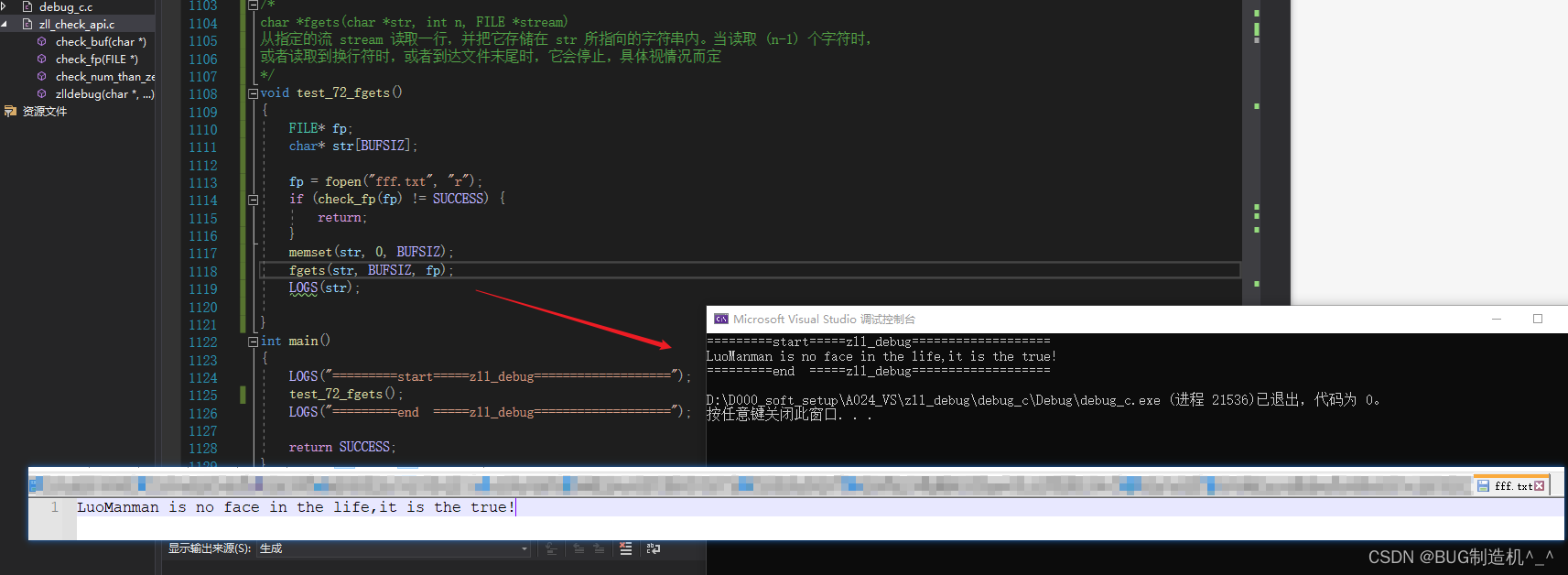
【函数32:fgets】
【格式】
char *fgets(char *str, int n, FILE *stream)
【功能】
从指定的流 stream 读取一行,并把它存储在 str 所指向的字符串内。当读取 (n-1) 个字符时,
或者读取到换行符时,或者到达文件末尾时,它会停止,具体视情况而定
【入参】
- str -- 这是指向一个字符数组的指针,该数组存储了要读取的字符串。
- n -- 这是要读取的最大字符数(包括最后的空字符)。通常是使用以 str 传递的数组长度。
- stream -- 这是指向 FILE 对象的指针,该 FILE 对象标识了要从中读取字符的流
【返回值】
如果成功,该函数返回相同的 str 参数。如果到达文件末尾或者没有读取到任何字符,str 的内容保持不变,并返回一个空指针。如果发生错误,返回一个空指针
【TestCode】
读取一行的情况:
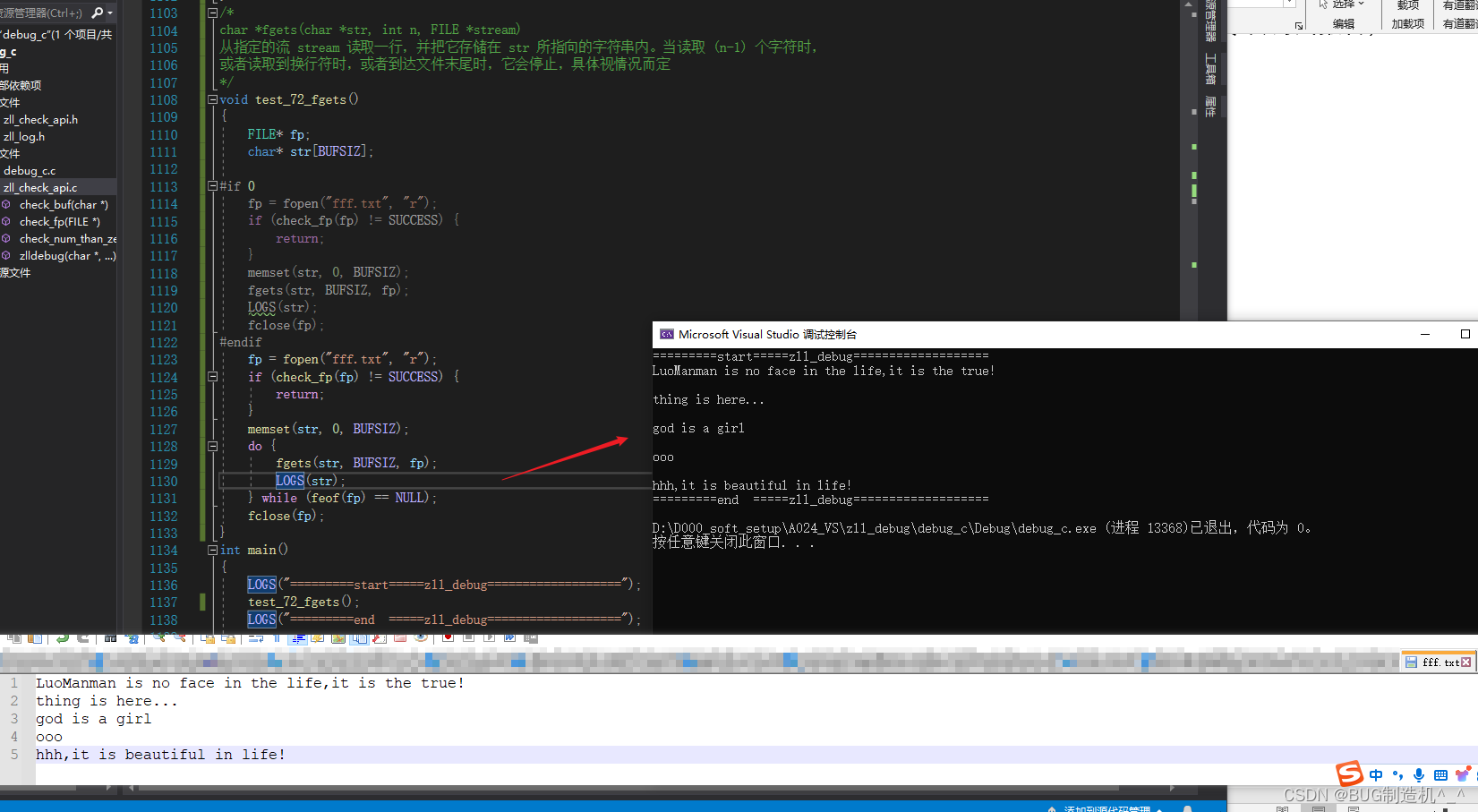
读取多行时,如下:

明显不是我们想要的结果,那么该如何做呢?如下:
【总结】
fgets虽然是读取整行,但是一定要注意它遇到换行符时,或者到达文件末尾时,它会停止,具体视情况而定,这个一定要记住,不然可能读取的内容并非你想要的内容
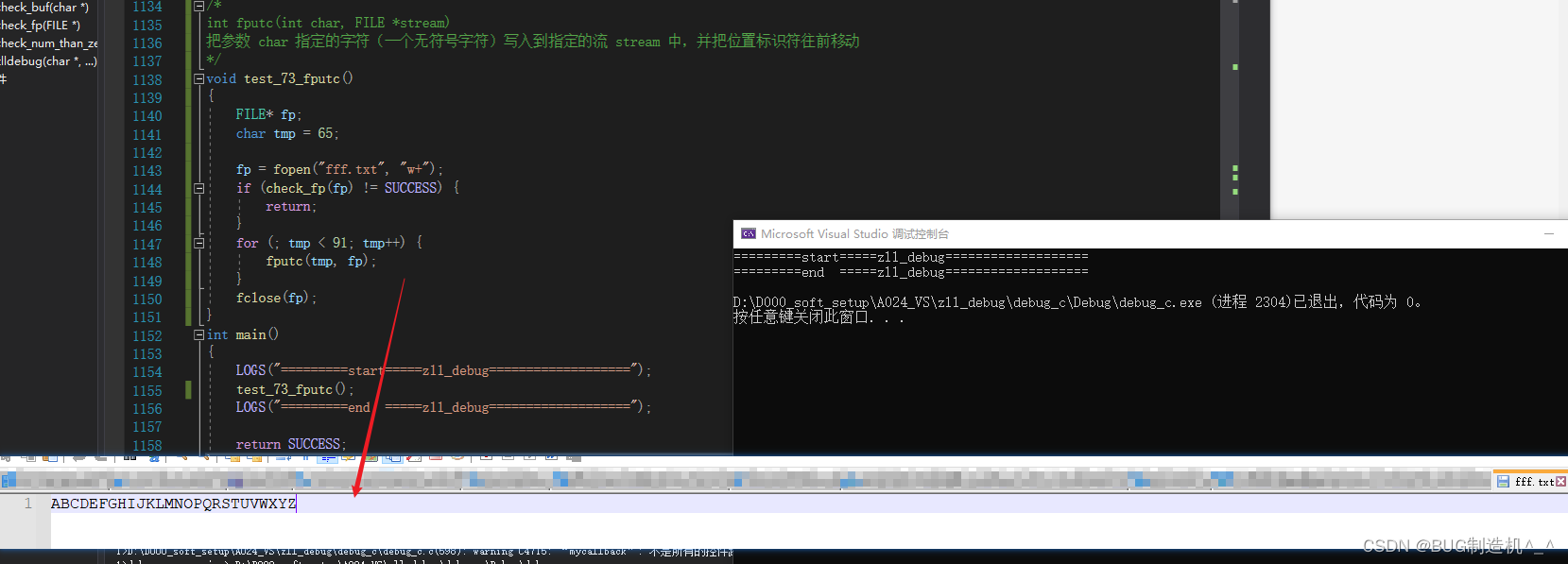
【函数33:fputc】
【格式】
int fputc(int char, FILE *stream)
【功能】
把参数 char 指定的字符(一个无符号字符)写入到指定的流 stream 中,并把位置标识符往前移动
【入参】
- char -- 这是要被写入的字符。该字符以其对应的 int 值进行传递。
- stream -- 这是指向 FILE 对象的指针,该 FILE 对象标识了要被写入字符的流
【返回值】
如果没有发生错误,则返回被写入的字符。如果发生错误,则返回 EOF,并设置错误标识符
【TestCode】
【总结】
fputc是逐一将字符写入文件流中,所以一般都需要用到for循环或者do_while结构
【函数34:fputs】
【格式】
int fputs(const char *str, FILE *stream)
【功能】
把字符串写入到指定的流 stream 中,但不包括空字符
【入参】
- str -- 这是一个数组,包含了要写入的以空字符终止的字符序列。
- stream -- 这是指向 FILE 对象的指针,该 FILE 对象标识了要被写入字符串的流
【返回值】
该函数返回一个非负值,如果发生错误则返回 EOF
【TestCode】
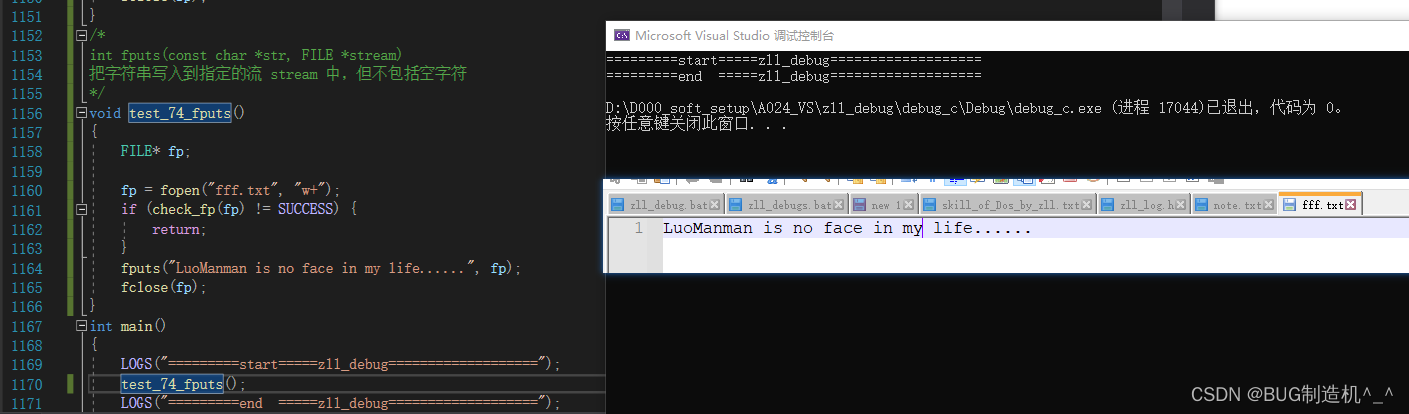
【总结】
注意,多行写入的时候,使用fputs的话,它不会自动换行的哦
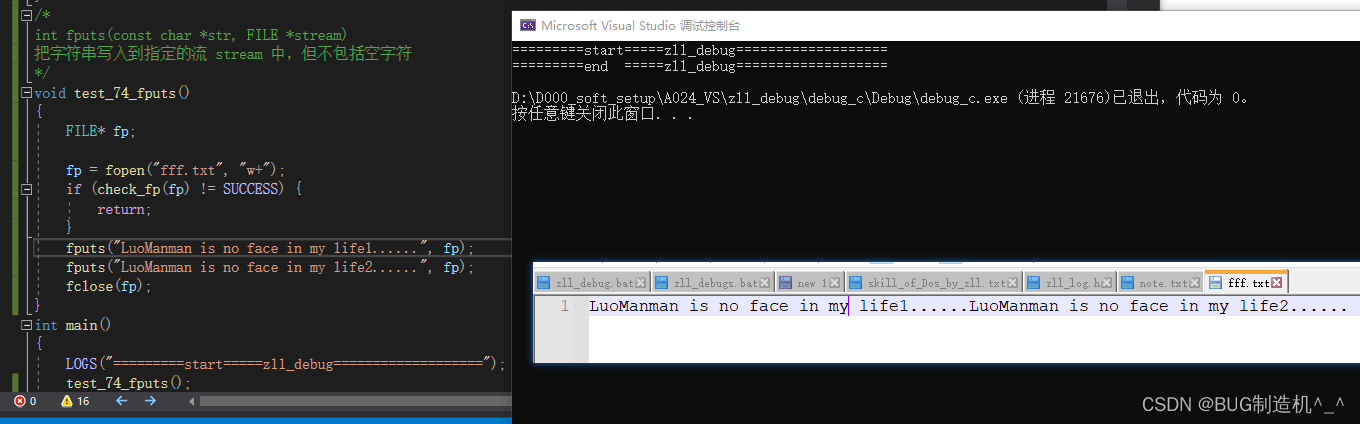
想要换行的话,就自己加,如下:
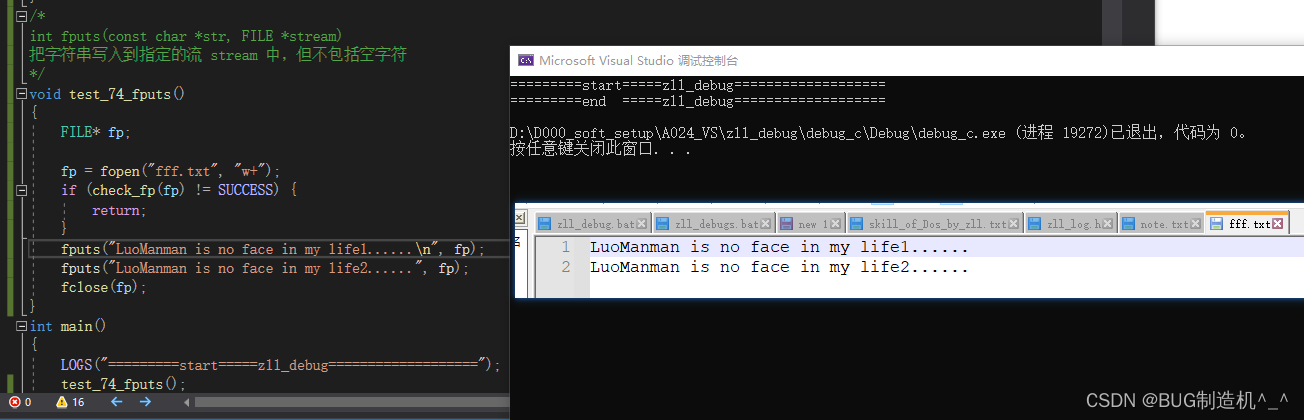
【函数35:getc】
【格式】
int getc(FILE *stream)
【功能】
从指定的流 stream 获取下一个字符(一个无符号字符),并把位置标识符往前移动
【入参】
stream -- 这是指向 FILE 对象的指针,该 FILE 对象标识了要在上面执行操作的流
【返回值】
该函数以无符号 char 强制转换为 int 的形式返回读取的字符,如果到达文件末尾或发生读错误,则返回 EOF
【TestCode】
从文件流读取内容:
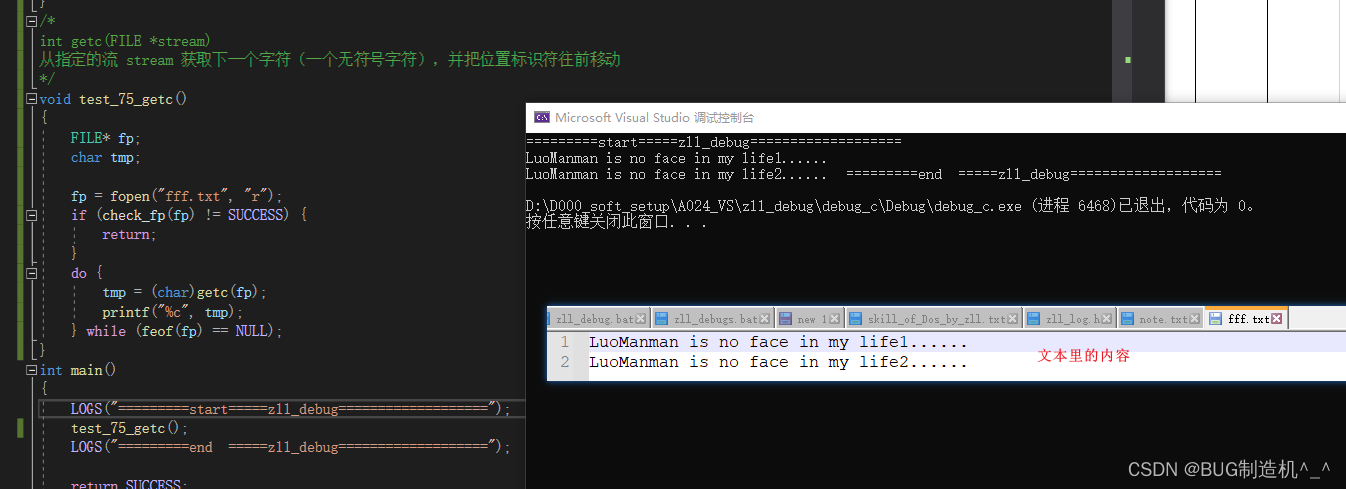
从stdin获取内容:
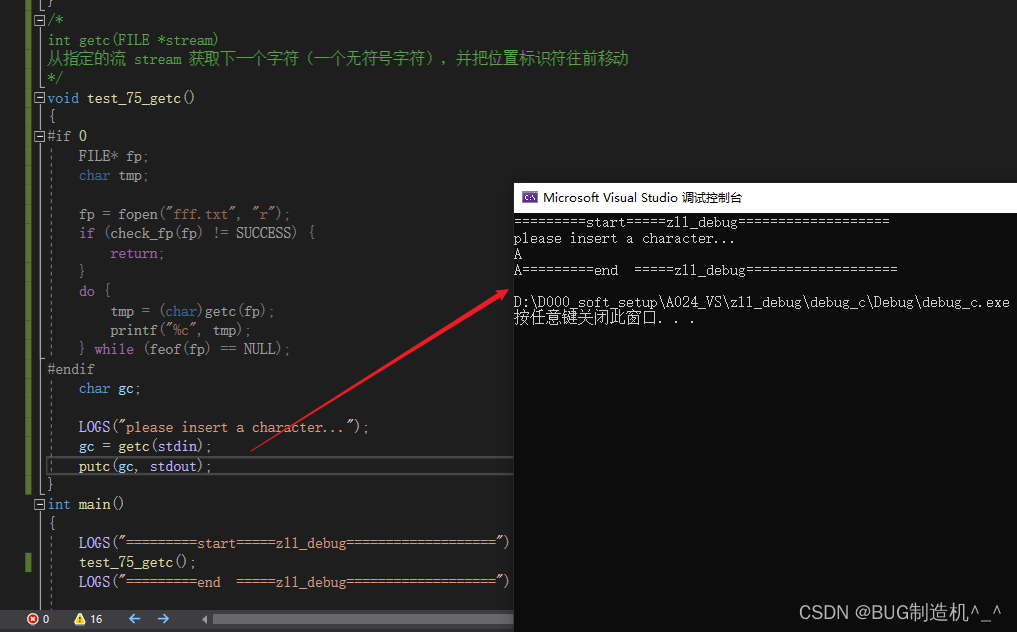
【总结】
1.关于stdin和stdout在linux的时候会经常用到,那么我们先简单说下,一个文件一般都有:标准输入,标准输出,标准错误输入,分别定义为0,1,2,对应的就是stdin,stdout,stderr,
2.getc感觉和scanf有些相似,但是还是区别很大的:scanf是获取输入的内容,这个内容不仅仅是字符哦,而且scanf只能从标准输入stdin获取;而getc只是获取一个字符,不仅可以从文件流利获取的,而且也可以从标准输入stdin获取哦
【函数36:getchar】
【格式】
int getchar(void)
【功能】
从标准输入 stdin 获取一个字符(一个无符号字符)
【入参】
void:空入参
【返回值】
该函数以无符号 char 强制转换为 int 的形式返回读取的字符,如果到达文件末尾或发生读错误,则返回 EOF
【TestCode】
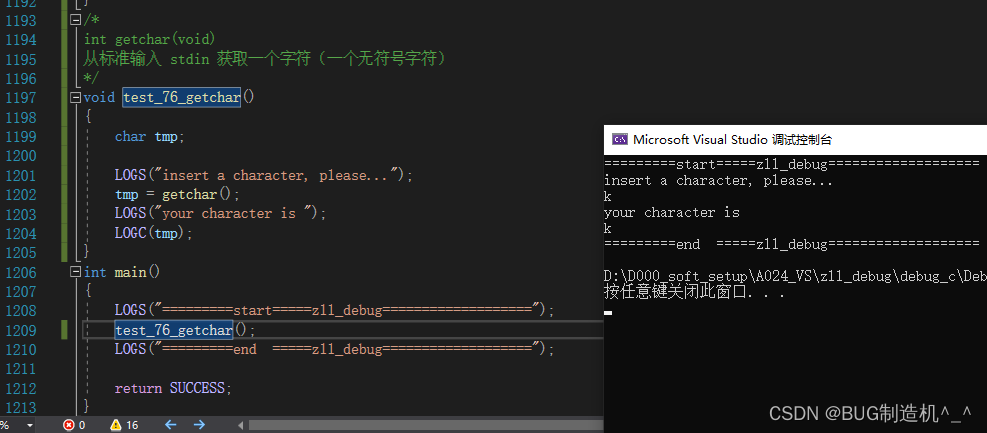
【总结】
getc和getchar还是有些区别的,前者是从文件流或者标准输入(stdin)中获取字符,是必须要有入参的,而后者是从标准输入(stdin)中获取字符的,但是不需要入参哦
【函数37:gets】
【格式】
char *gets(char *str)
【功能】
从标准输入 stdin 读取一行,并把它存储在 str 所指向的字符串中。
当读取到换行符时,或者到达文件末尾时,它会停止,具体视情况而定
【入参】
str -- 这是指向一个字符数组的指针,该数组存储了 C 字符串
【返回值】
如果成功,该函数返回 str。如果发生错误或者到达文件末尾时还未读取任何字符,则返回 NULL
【TestCode】

【总结】
1.gets的返回值是str的地址
2.gets的入参是要填入字符串的那个数组的地址
【函数38:putc】
【格式】
int putc(int char, FILE *stream)
【功能】
把参数 char 指定的字符(一个无符号字符)写入到指定的流 stream 中,并把位置标识符往前移动
【入参】
- char -- 这是要被写入的字符。该字符以其对应的 int 值进行传递。
- stream -- 这是指向 FILE 对象的指针,该 FILE 对象标识了要被写入字符的流
【返回值】
该函数以无符号 char 强制转换为 int 的形式返回写入的字符,如果发生错误则返回 EOF
【TestCode】
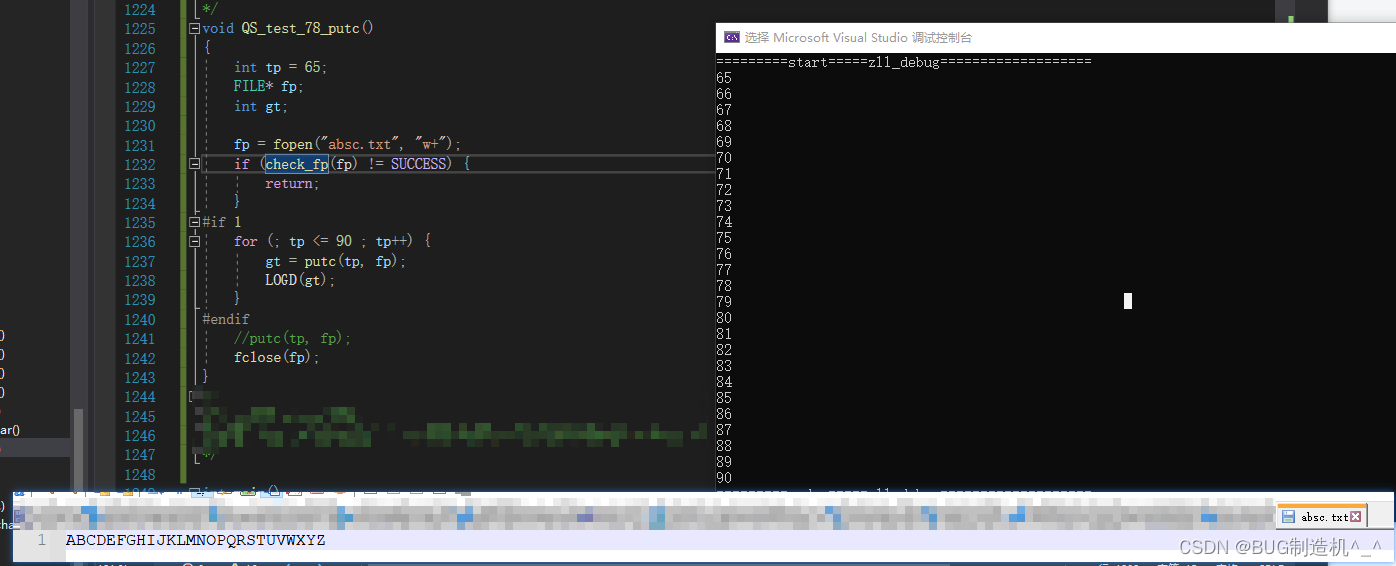
【总结】
putc和fputc几乎是一样的作用,那么到底有啥区别呢?
1.返回值区别
2.fputc一旦发生错误,会给文件设置错误标识符,但是putc并不会这样
【函数39:putchar】
【格式】
int putchar(int char)
【功能】
把参数 char 指定的字符(一个无符号字符)写入到标准输出 stdout 中
【入参】
char -- 这是要被写入的字符。该字符以其对应的 int 值进行传递
【返回值】
该函数以无符号 char 强制转换为 int 的形式返回写入的字符,如果发生错误则返回 EOF。
【TestCode】
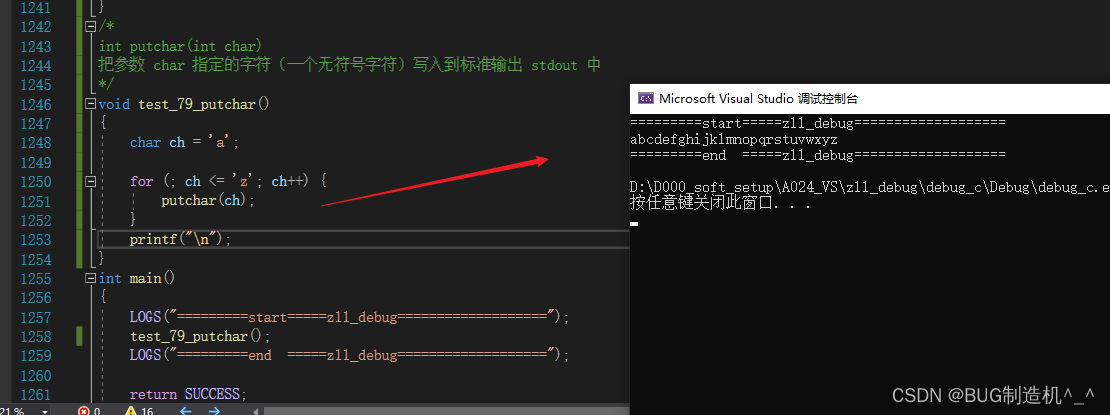
【总结】
putchar函数是将输出直接输出到标准输出上的哦
【函数40:puts】
【格式】
int puts(const char *str)
【功能】
把一个字符串写入到标准输出 stdout,直到空字符,但不包括空字符。
换行符会被追加到输出中
【入参】
str -- 这是要被写入的 C 字符串
【返回值】
如果成功,该函数返回一个非负值为字符串长度(包括末尾的 \0),如果发生错误则返回 EOF
【TestCode】
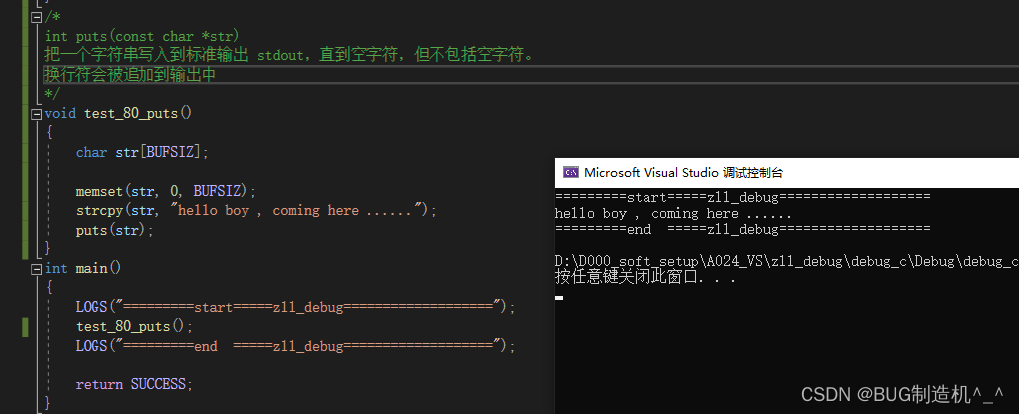
【总结】
这个是直接输出到终端上,和putchar也是有些区别的,请仔细思考一下下
【函数41:ungetc】
【格式】
int ungetc(int char, FILE *stream)
【功能】
把字符 char(一个无符号字符)推入到指定的流 stream 中,以便它是下一个被读取到的字符
【入参】
- char -- 这是要被推入的字符。该字符以其对应的 int 值进行传递。
- stream -- 这是指向 FILE 对象的指针,该 FILE 对象标识了输入流
【返回值】
如果成功,则返回被推入的字符,否则返回 EOF,且流 stream 保持不变
【TestCode】
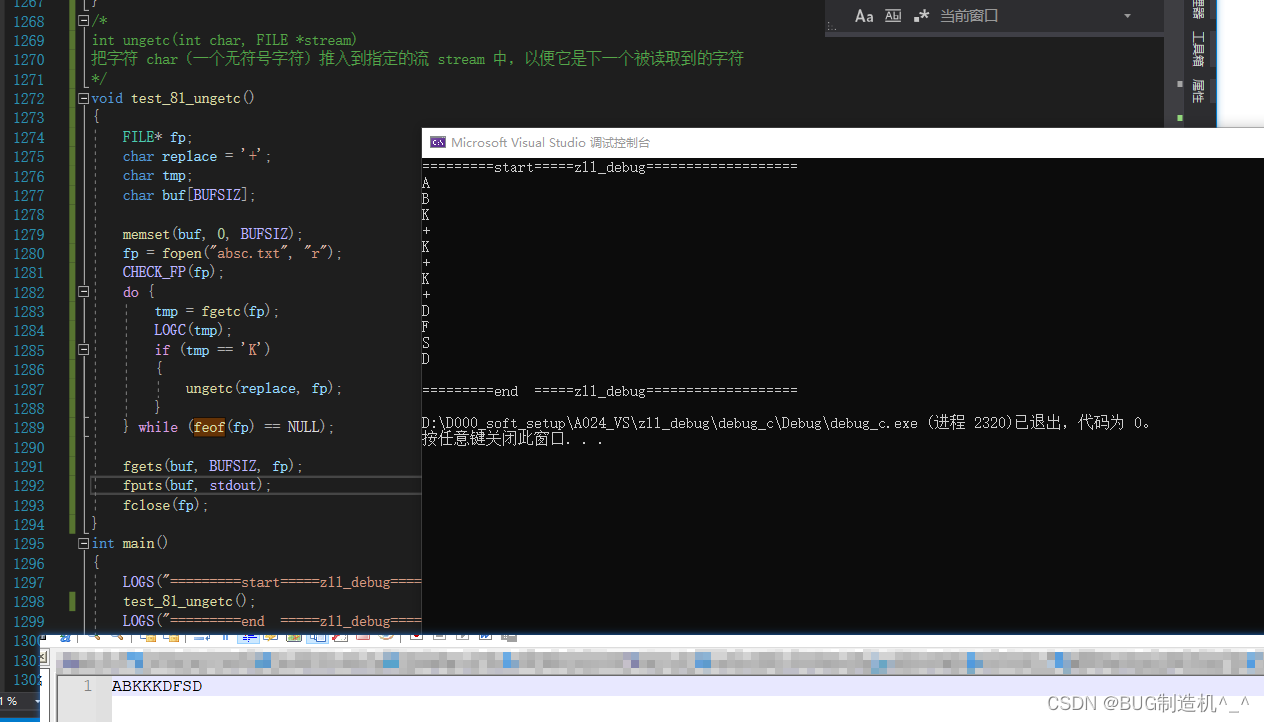
【总结】
注意理解这句话:把字符 char(一个无符号字符)推入到指定的流 stream 中,以便它是下一个被读取到的字符;尤其后半句:这句意思并不是替换那个字符,而是在那个字符后面推入你要加入的字符,并不是替换原来的字符哦
【函数42:perror】
【格式】
void perror(const char *str)
【功能】
把一个描述性错误消息输出到标准错误 stderr。
首先输出字符串 str,后跟一个冒号,然后是一个空格
【入参】
str -- 这是 C 字符串,包含了一个自定义消息,将显示在原本的错误消息之前
【返回值】
该函数不返回任何值
【TestCode】
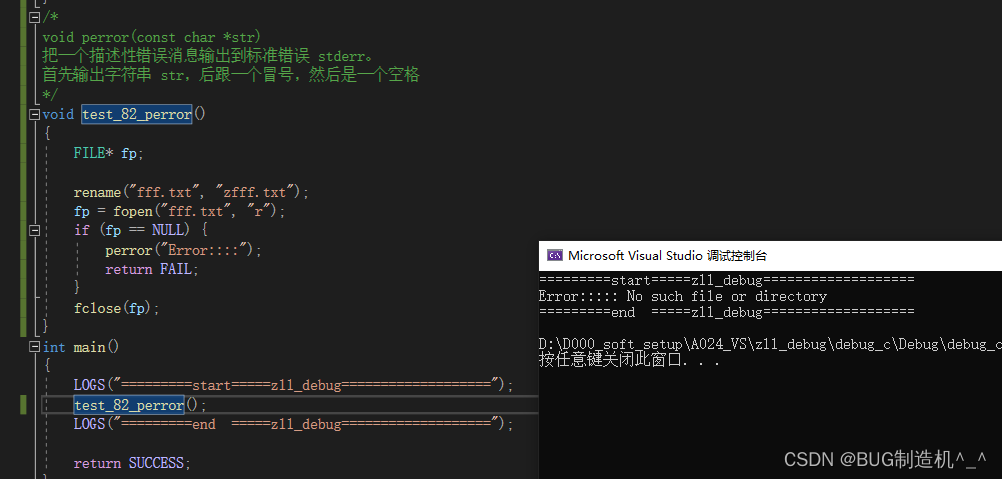
【总结】
perror的入参const char* str就是你要编辑的额debug信息或者标注性打印信息,以便于出问题的时候,能快速的定位到对应的问题点
【函数43:snprintf】
【格式】
int snprintf(char *str, size_t size, const char *format, ...)
【功能】
把格式字符串写到 str 中
【入参】
- str -- 目标字符串,用于存储格式化后的字符串的字符数组的指针。
- size -- 字符数组的大小。
- format -- 格式化字符串。
- ... -- 可变参数,可变数量的参数根据 format 中的格式化指令进行格式化
【返回值】
snprintf() 函数的返回值是输出到 str 缓冲区中的字符数,不包括字符串结尾的空字符 \0。如果 snprintf() 输出的字符数超过了 size 参数指定的缓冲区大小,则输出的结果会被截断,只有 size - 1 个字符被写入缓冲区,最后一个字符为字符串结尾的空字符 \0。
需要注意的是,snprintf() 函数返回的字符数并不包括字符串结尾的空字符 \0,因此如果需要将输出结果作为一个字符串使用,则需要在缓冲区的末尾添加一个空字符 \0
【TestCode】
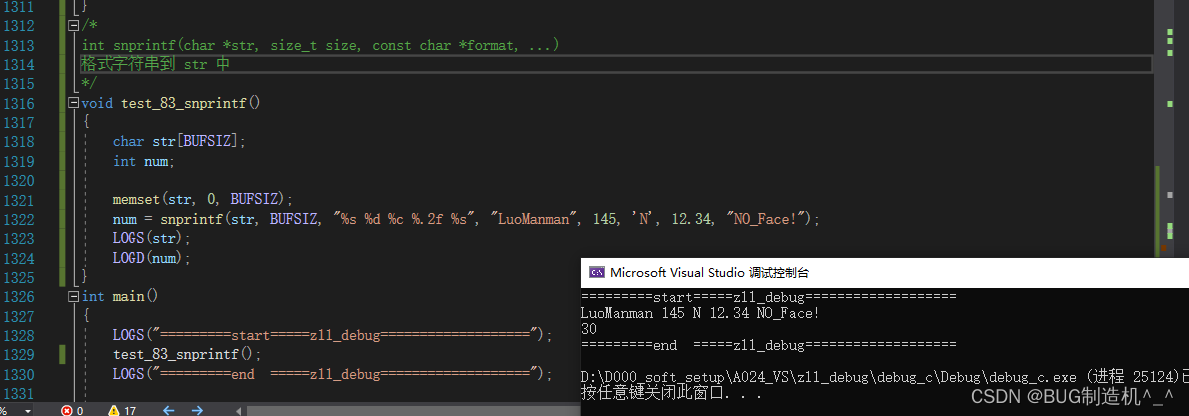
【总结】
snprintf() 是一个 C 语言标准库函数,用于格式化输出字符串,并将结果写入到指定的缓冲区,与 sprintf() 不同的是,snprintf() 会限制输出的字符数,避免缓冲区溢出。
C 库函数 int snprintf(char *str, size_t size, const char *format, ...) 设将可变参数(...)按照 format 格式化成字符串,并将字符串复制到 str 中,size 为要写入的字符的最大数目,超过 size 会被截断,最多写入 size-1 个字符。
与 sprintf() 函数不同的是,snprintf() 函数提供了一个参数 size,可以防止缓冲区溢出。如果格式化后的字符串长度超过了 size-1,则 snprintf() 只会写入 size-1 个字符,并在字符串的末尾添加一个空字符(\0)以表示字符串的结束
注意事项:
-
缓冲区大小:
snprintf()函数会限制输出的字符数,但是需要确保传入的缓冲区大小足够,以便容纳格式化后的字符串。否则,字符串可能会截断,导致信息丢失。 -
字符串结束符:
snprintf()函数会在缓冲区最后添加一个空字符作为字符串的结束符,但这个字符不计入返回值中。因此,在使用snprintf()输出字符串时,需要确保缓冲区的大小足够,以便容纳字符串的所有字符以及结尾的空字符。 -
格式化字符串:在使用
snprintf()格式化字符串时,需要确保格式化字符串中的格式说明符和可变参数的类型相匹配。否则,输出的结果可能会出现错误。 -
返回值:
snprintf()函数的返回值为写入缓冲区的字符数,但不包括字符串结尾的空字符。如果返回值等于缓冲区的大小,则表明输出的结果被截断了。 -
可变参数:
snprintf()函数的可变参数是通过...传递的,这意味着需要使用与格式说明符相匹配的类型传递可变参数。在使用可变参数时,应该避免使用未初始化的变量,否则会出现不可预测的结果。
总之,在使用 snprintf() 函数时,需要注意缓冲区大小、字符串结束符、格式化字符串、返回值和可变参数等问题,以确保输出结果正确无误。