目录
一.查询
1.1查询语句的格式
1.2查询过滤器
1.3查询执行器
1.4具体例子
1.4.1查询有多少个用户
1.4.2查询第一个用户
1.4.3查询id为4的用户
1.4.4查询id为4title为4的记录
1.4.5查询id为4或者title为4的记录
1.4.6查询id为[1,3,5,7,9]的记录
1.4.7查询所有记录,并以create_time排序
二.多py文件搭建Flask程序
2.1为什么要多py文件
2.2分离py文件
三.其它指令
3.1查询模型对象的所有属性
3.2获取模型对象的属性值
一.查询
flask-sqlalchemy的查询有两种方式:“使用ORM(execute)查询【2.0以后的新方法】”、“使用模型类.query查询【1.0的旧方法】”
尽管如此,作者本人仍习惯使用query查询方法,原因在于书写简单方便,缺点在于没有打印调试信息,本篇将使用query介绍查询,关于ORM查询可以参考官方文档
1.1查询语句的格式
使用“模型类.query”的查询语句一般格式为:“模型类.query.查询过滤器.查询执行器”
结果返回一个model模型对象

1.2查询过滤器
- filter():复杂过滤器,可以是函数表达式等
- filter_by():等值过滤器
- limit:限定返回结果的数量
- offset():偏移查询
- order_by():对查询结果排序
- group_by():对查询结果分组
1.3查询执行器
- all():以列表形式返回所有结果,结果为model对象
- first():返回查询到的第一个结果,如果未查到返回None
- first_or_404():查询第一个结果,如果未查到返回404
- get():返回指定主键对应的model对象,不存在返回None
- get_or_404():返回逐渐对应的model对象,不存在返回404
- count():返回查询结果的数量
1.4具体例子
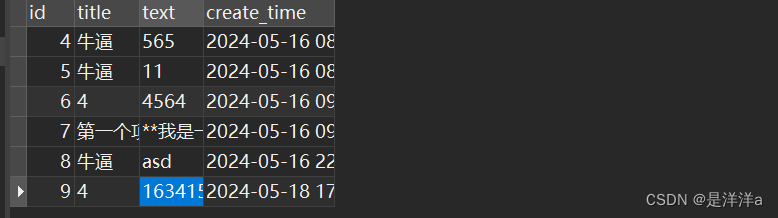
下面的例子都将以该模型代码为例:
from flask import *
from flask_sqlalchemy import SQLAlchemyapp = Flask(__name__)
app.config.from_object("config")
db = SQLAlchemy(app)@app.route("/")
def index():return "666"class Blog(db.Model):#设置表名__tablename__ = 'blog'id = db.Column(db.Integer,primary_key=True,autoincrement=True)title = db.Column(db.String(128))text = db.Column(db.TEXT)create_time = db.Column(db.String(64))#关联用户idif __name__ == "__main__":app.run(debug=True)该表中的数据为:
1.4.1查询有多少个用户
count = Blog.query.count()
print("表中记录数为:",count)结果:![]()
1.4.2查询第一个用户
count = Blog.query.first()
print("表中记录为:",count)结果:
![]()
1.4.3查询id为4的用户
三种方式:
Blog.query.filter_by(id=4).first()
Blog.query.filter(Blog.id == 4).first()
Blog.query.get(4).first()1.4.4查询id为4title为4的记录
两种方法:
from sqlalchemy import and_
Blog.query.filter(Blog.id == 4,Blog.title == 4).first()
Blog.query.filter(and_(Blog.id == 4,Blog.title == 4))1.4.5查询id为4或者title为4的记录
from sqlalchemy import or_
Blog.query.filter(or_(Blog.id == 4,Blog.title == 4))1.4.6查询id为[1,3,5,7,9]的记录
from sqlalchemy import in_
Blog.query.filter(Blog.id.in_([1,3,5,7,9])).all()1.4.7查询所有记录,并以create_time排序
Blog.query.order_by(Blog.create_time).all()
Blog.query.order_by(Blog.create_time.desc()).all()二.多py文件搭建Flask程序
2.1为什么要多py文件
在实际生产中,我们可能会有多个model模型、多个数据库连接等等,此时为方便开发与维护,我们可能会将Flask程序逻辑与数据库逻辑分离开,使它们在不同的py文件中
但是如果小白第一次尝试分离py文件,可能会产生诸多问题:“循环导入”、“上下文问题”
在这里,作者给出一种相对稳定且可以适应复杂环境的分离方式:
2.2分离py文件
我们将Flask逻辑保留在“app.py”文件中,将flask-alchemy逻辑保留在“model.py”文件中,此时只需要在app.py文件中“导入model.py”再将“db对象与app对象关联”即可
后续其它py文件想要使用数据库,可以直接“导入model.py”后使用db对象,而此时的db对象已经与app程序关联可以直接使用,或者重新关联一个app程序(注意此时一旦更换关联app对象,那么其它py文件使用的db对象也会发生改变!!这是十分危险的!!建议重新创建一个db对象!!)
下面是作者的一个示例“app.py”文件:
import secrets
from flask import *app = Flask(__name__)
# app的一些配置
app.config.from_object('config')
app.secret_key = secrets.token_hex(16)# 注册蓝图
from view import *
app.register_blueprint(index)
app.register_blueprint(blog)#导入数据库模型
from model import *
#将db数据库示例与app程序绑定
db.init_app(app)if __name__ == '__main__':app.run(debug=True)
而“model.py”文件如下:
#表-实体类
from flask_sqlalchemy import SQLAlchemydb = SQLAlchemy()#作品类
class Blog(db.Model):#设置表名__tablename__ = 'blog'id = db.Column(db.Integer,primary_key=True,autoincrement=True)title = db.Column(db.String(128))text = db.Column(db.TEXT)create_time = db.Column(db.String(64))#关联用户id#建表
def create():db.create_all()#删表
def drop():dp.drop_all()注意到:“在app.py文件引入model.py文件后,我们需要将model.py文件中的db对象与app对象关联,我们使用了app_init()方法关联”
ps:“from model import *”这条语句可以移动到开头,此时并不会影响程序,但是app_init()语句必须在app对象“创建并完成配置”后再关联,作者将两者写在一起是为了思维上更符合逻辑
三.其它指令
3.1查询模型对象的所有属性
我们可以使用模型对象的“__table__.columns”来查看对象的所有属性:
blog = Blog.query.first()
print(blog.__table__.columns)效果:
![]()
3.2获取模型对象的属性值
获取属性相对简单,有两种方式:“模型.属性名”、“getattr(模型,属性名)”
blog = Blog.query.first()
print(blog.id)
print(getattr(blog,"id"))