目录
概述
HBase 的主要特点包括:
HBase 的典型应用场景包括:
访问接口
1. Java API:
2. REST API:
3. Thrift API:
4. 其他访问接口:
HBase 数据模型
概述
该模型具有以下特点:
1. 面向列:
2. 多维:
3. 稀疏:
数据存储:
数据访问:
HBase 的数据模型具有以下优点:
HBase 的数据模型也存在一些缺点:
相关概念
1. 行键(Row Key)
2. 列族(Column Family)
3. 列限定符(Column Qualifier)
4. 单元格(Cell)
数据坐标
概念视图
矩阵表示示例
优点
缺点
物理视图
存储结构
数据存储方式
数据访问
性能优化
面向列的存储
HBase 的实现原理
功能组件
1. ZooKeeper:
2. Master 服务器:
3. Region 服务器:
4. HLog:
5. MemStore:
6. StoreFile:
表和 Region
表
Region
表与 Region 的关系
Region 的定位
元数据信息
Region 定位的优化
HBase 的运行机制
HBase 系统架构
1. ZooKeeper:
2. Master 服务器:
3. Region 服务器:
4. HLog:
5. MemStore:
6. StoreFile:
Region 服务器的工作原理
工作流程
MemStore 和 StoreFile
Store 的工作原理
Store 的职责
Store 的工作流程
MemStore 和 StoreFile
HLog 的工作原理
HLog 的作用
HLog 的工作流程
HLog 的特性
编程实践
常用的 Shell 命令
表管理
数据操作
其他命令
示例
常用的 Java API 及应用实例
1. HBaseAdmin:用于管理 HBase 表
2. HTable:用于访问 HBase 表中的数据
3. Put:用于向 HBase 表中插入数据
4. Get:用于从 HBase 表中读取数据
5. Scan:用于扫描 HBase 表中的数据
总结
概述
HBase 是一个开源的、分布式的、面向列的 NoSQL 数据库,它是 Apache 软件基金会的 Hadoop 项目的一部分。HBase 旨在为海量结构化、弱结构化和非结构化数据提供高可靠性、高性能、可扩展的存储服务。它借鉴了 Google Bigtable 的设计理念,并进行了扩展,使其更加适用于大规模数据存储和处理场景。
HBase 的主要特点包括:
- 分布式: HBase 将数据分布存储在多个节点上,能够有效利用集群资源,提高数据处理能力。
- 面向列: HBase 采用面向列的存储模型,每个列族可以独立扩展,这使得 HBase 非常适合存储稀疏数据。
- 高可靠性: HBase 采用多副本机制来保证数据的可靠性,即使部分节点故障,数据也不会丢失。
- 高性能: HBase 采用高效的存储和索引机制,能够提供快速的数据读写操作。
- 可扩展性: HBase 可以通过添加节点来进行水平扩展,以满足不断增长的数据存储需求。
HBase 的典型应用场景包括:
- 日志分析: HBase 可以高效地存储和分析海量日志数据。
- 社交网络数据存储: HBase 可以存储和管理社交网络中的人际关系、用户信息等数据。
- 物联网数据存储: HBase 可以存储和管理来自物联网设备的传感器数据。
- 实时数据处理: HBase 可以支持实时的数据读写操作,适用于实时数据处理场景。
访问接口
HBase 提供多种访问接口,包括 Java API、REST API、Thrift API 等。用户可以通过这些接口来访问和操作 HBase 中的数据。其中,Java API 是最常用的接口,它提供了对 HBase 各种功能的全面支持。
1. Java API:
- 简介: Java API 是 HBase 最常用的访问接口,它提供了对 HBase 各种功能的全面支持,包括数据的插入、查询、删除、更新等操作。
- 优点: 功能全面、性能优异、与 Hadoop 生态系统紧密集成。
- 缺点: 使用较为复杂,需要一定的 Java 开发经验。
- 适用场景: 需要对 HBase 进行深入操作,追求高性能和大数据量处理的场景。
2. REST API:
- 简介: REST API 是一种基于 HTTP 协议的 RESTful 风格的访问接口,易于使用,无需额外的客户端库支持。
- 优点: 使用简单,无需 Java 开发经验,支持跨语言调用。
- 缺点: 功能相对有限,性能略逊于 Java API。
- 适用场景: 对 HBase 操作要求不复杂,需要跨语言调用的场景。
3. Thrift API:
- 简介: Thrift API 是一种跨语言的 RPC 框架,支持多种编程语言,如 Java、C++、Python 等。
- 优点: 跨语言支持好,代码生成效率高。
- 缺点: 相对较新的接口,社区活跃度略低。
- 适用场景: 需要跨语言访问 HBase 的场景。
4. 其他访问接口:
除了上述三种主要的访问接口之外,HBase 还提供了 Avro API、Phoenix API 等其他访问接口,满足不同用户的多样化需求。
HBase 数据模型
概述
HBase 的数据模型是一种面向列的存储模型,它将数据存储在一个大型的多维稀疏矩阵中。矩阵的行对应于 HBase 中的行键(row key),列对应于列族(column family)和列限定符(column qualifier)的组合,矩阵的每个元素对应于一个单元格(cell)。
该模型具有以下特点:
1. 面向列:
- HBase 中的数据按列组织,每个列族可以独立扩展,这使得 HBase 非常适合存储稀疏数据。
- 列族中可以包含多个列,每个列都有一个唯一的列限定符来标识。
- 列限定符可以用来对列进行进一步的组织和分组。
2. 多维:
- HBase 的数据模型是多维的,除了行和列之外,HBase 还支持时间戳。
- 时间戳用于标识每个单元格数据的版本,可以用来查询数据的历史记录。
3. 稀疏:
- HBase 的数据模型是稀疏的,这意味着并非每个行和列都需要存储数据。
- 只有实际存储了数据的行和列才会被保存,这可以节省存储空间。
数据存储:
- 在 HBase 中,数据存储在单元格中。
- 每个单元格由行键、列族、列限定符和时间戳以及数据值组成。
- 行键是唯一标识一行数据的键,它通常由用户自定义。
- 列族用于组织相关的数据,它类似于关系数据库中的表。
- 列限定符用于进一步标识列,它类似于关系数据库中的列名。
- 时间戳用于标识数据的版本,它可以用来查询数据的历史记录。
- 数据值是存储在单元格中的实际数据,它可以是任意类型的字符串。
数据访问:
- HBase 提供多种数据访问方式,包括 Java API、REST API、Thrift API 等。
- 用户可以通过这些接口来访问和操作 HBase 中的数据。
- HBase 的数据访问模式主要包括以下几种:
- 获取: 根据行键和列限定符来获取单元格中的数据。
- 扫描: 扫描一列或多个列中的所有数据。
- 过滤: 根据条件来过滤数据。
- 更新: 更新单元格中的数据。
- 删除: 删除单元格中的数据。
HBase 的数据模型具有以下优点:
- 灵活性: HBase 的数据模型非常灵活,可以存储各种类型的数据,包括结构化、半结构化和非结构化数据。
- 可扩展性: HBase 的数据模型可以水平扩展,以满足不断增长的数据存储需求。
- 高性能: HBase 的数据模型提供了高性能的数据读写操作。
HBase 的数据模型也存在一些缺点:
- 复杂性: HBase 的数据模型比传统的关系数据库模型要复杂一些。
- 一致性: HBase 的数据模型在一定程度上牺牲了一致性,以换取更高的性能。
相关概念
HBase 是一种面向列的 NoSQL 数据库,其数据模型由以下几个重要的概念组成:
1. 行键(Row Key)
- 行键是 HBase 表中的主键,用于唯一标识每一行数据。
- 行键必须是唯一的,并且可以由用户自定义。
- 行键通常由字符串或数字组成,并且可以包含多个分隔符来组织数据。
- 行键在 HBase 中至关重要,它决定了数据的存储方式和访问方式。
2. 列族(Column Family)
- 列族是一组相关列的集合,用于对列进行分类和管理。
- 列族类似于关系数据库中的表,可以包含多个列。
- 列族名称必须是唯一的,并且可以由用户自定义。
- 列族可以提高数据组织性和查询效率。
3. 列限定符(Column Qualifier)
- 列限定符用于唯一标识列族中的每一列。
- 列限定符可以由用户自定义,并且可以包含多个分隔符来组织数据。
- 列限定符可以用来进一步组织和分组列族中的列。
4. 单元格(Cell)
- 单元格是 HBase 数据模型中最基本的存储单元,它包含一个值和多个版本。
- 每个单元格由行键、列族、列限定符和时间戳以及数据值组成。
- 时间戳用于标识每个单元格数据的版本,可以用来查询数据的历史记录。
- 数据值是存储在单元格中的实际数据,它可以是任意类型的字符串。
行键、列族和列限定符共同构成了 HBase 数据模型的索引。 行键用于标识行,列族用于标识列组,列限定符用于标识列。这三个概念使得 HBase 能够高效地存储和检索大规模的数据。
注:
- 行键的选择对于 HBase 的性能至关重要,建议用户选择能够均匀分布数据的行键。
- 列族可以根据需要进行动态添加和删除。
- 列限定符可以重复使用,只要它们属于不同的列族。
- HBase 还支持版本控制,用户可以查询和恢复数据的历史版本。
数据坐标
在 HBase 中,每个数据单元格都有一个唯一的坐标,称为 数据坐标。数据坐标由以下四个部分组成:
-
行键(Row Key):行键是唯一标识一行数据的键,也是表中的主键。它必须是唯一的,并且可以由用户自定义。行键在 HBase 中至关重要,它决定了数据的存储方式和访问方式。
-
列族(Column Family):列族是一组相关列的集合,用于对列进行分类和管理。列族名称必须是唯一的,并且可以由用户自定义。列族可以提高数据组织性和查询效率。
-
列限定符(Column Qualifier):列限定符用于唯一标识列族中的每一列。列限定符可以由用户自定义,并且可以包含多个分隔符来组织数据。列限定符可以用来进一步组织和分组列族中的列。
-
时间戳(Timestamp):时间戳用于标识每个单元格数据的版本,可以用来查询数据的历史记录。时间戳是一个 64 位的整数,表示从 Unix 纪元(1970-01-01 00:00:00 UTC)开始的毫秒数。
数据坐标示例:
<row key>1234567890</row key>
<column family>info</column family>
<column qualifier>name</column qualifier>
<timestamp>1652751932000</timestamp>
<value>Zhang San</value>在这个例子中,数据坐标为:
- 行键:
1234567890 - 列族:
info - 列限定符:
name - 时间戳:
1652751932000
该数据坐标表示表中 info 列族中的 name 列的最新版本,其值为 Zhang San。
数据坐标的作用:
数据坐标在 HBase 中起着至关重要的作用,它具有以下功能:
- 唯一标识数据: 数据坐标是唯一标识数据单元格的依据,可以确保数据的唯一性。
- 组织数据: 数据坐标可以用来组织和管理数据,例如按行键、列族或时间戳进行排序和过滤。
- 版本控制: 时间戳用于标识数据版本,可以用来查询和恢复数据的历史记录。
概念视图

从概念上讲,HBase 的数据模型可以看作是一个大型的多维稀疏矩阵,其中:
- 行 对应于 HBase 表中的 行键。
- 列 对应于 HBase 表中的 列族 和 列限定符 的组合。
- 元素 对应于 HBase 表中的 单元格。
- 值 对应于单元格中的 数据值。
稀疏性 体现在并非所有行和列都需要存储数据,只有实际存储了数据的行和列才会被保存。
多维性 体现在除了行和列之外,HBase 还支持 时间戳。时间戳用于标识每个单元格数据的版本,可以用来查询数据的历史记录。
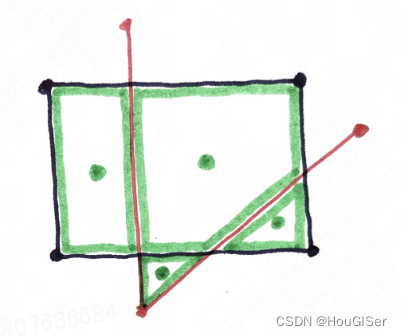
矩阵表示示例
假设有一个名为 user_info 的 HBase 表,该表包含以下列:
user_id:行键,表示用户的唯一标识。name:列族info中的列,表示用户的姓名。age:列族info中的列,表示用户的年龄。create_time:时间戳,表示用户记录的创建时间。
那么,该表可以表示为以下多维稀疏矩阵:
| user_id | name (info) | age (info) | create_time |
|---|---|---|---|
| 10001 | 张三 | 30 | 1652751932000 |
| 10002 | 李四 | 25 | 1652751932001 |
| 10003 | 王五 | 32 | 1652751932002 |
| ... | ... | ... | ... |
drive_spreadsheet导出到 Google 表格
在这个矩阵中,只有实际存储了数据的行和列才会显示。例如,用户 10004 的数据可能尚未存储,因此该行不会出现在矩阵中。
优点
HBase 的多维稀疏矩阵数据模型具有以下优点:
- 灵活性: 可以存储各种类型的数据,包括结构化、半结构化和非结构化数据。
- 可扩展性: 可以水平扩展以满足不断增长的数据存储需求。
- 高性能: 提供高性能的数据读写操作。
缺点
HBase 的多维稀疏矩阵数据模型也存在一些缺点:
- 复杂性: 比传统的关系数据库模型要复杂一些。
- 一致性: 在一定程度上牺牲了一致性,以换取更高的性能。
物理视图
在物理上,HBase 将数据存储在分布式文件系统(如 HDFS)中,并使用 Key-Value 对的形式存储数据。
存储结构
HBase 的物理存储结构主要包括以下几个部分:
- HRegion: 是 HBase 中存储数据的基本单元,对应于一个表中的一段行数据。
- StoreFile: 是 HBase 中存储数据的物理文件,每个 HRegion 由多个 StoreFile 组成。
- HFile: 是 StoreFile 中存储数据的基本单元,由多个块(Block)组成。
- Block: 是 HFile 中存储数据的最小单元,大小通常为 64KB。
数据存储方式
HBase 将数据存储在 Key-Value 对的形式中,其中:
- Key: 由行键、列族、列限定符和时间戳组成,用于唯一标识一个数据单元。
- Value: 是数据单元的实际值,可以是任意类型的字符串。
HBase 的数据存储方式具有以下特点:
- 面向列: 数据按列存储,每个列族可以独立扩展。
- 稀疏: 只有实际存储了数据的行和列才会被保存。
- 版本化: 支持多版本控制,可以查询和恢复数据的历史记录。
数据访问
HBase 提供多种数据访问方式,包括 Java API、REST API、Thrift API 等。用户可以通过这些接口来访问和操作 HBase 中的数据。
HBase 的数据访问方式主要包括以下几种:
- 获取: 根据行键和列限定符来获取单元格中的数据。
- 扫描: 扫描一列或多个列中的所有数据。
- 过滤: 根据条件来过滤数据。
- 更新: 更新单元格中的数据。
- 删除: 删除单元格中的数据。
性能优化
HBase 采用了多种技术来优化性能,包括:
- 缓存: 将经常访问的数据缓存到内存中。
- 压缩: 对数据进行压缩以节省存储空间。
- 批量处理: 批量处理数据以提高效率。
面向列的存储
HBase 是一种面向列的 NoSQL 数据库,与传统的关系型数据库(RDBMS)相比,它具有以下面向列存储的优势:
1. 高效存储稀疏数据:
- 在关系型数据库中,数据通常按行存储,即使某一行中只有部分列有数据,也需要为所有列分配存储空间。这对于稀疏数据来说非常浪费存储空间。
- 而在 HBase 中,数据按列存储,每个列族可以独立扩展。这意味着只有实际存储了数据的列才会占用存储空间,对于稀疏数据来说可以大大节省存储空间。
2. 高效读取数据:
- 在关系型数据库中,查询数据时通常需要读取整行数据,即使只需要其中的一列或几列数据。这对于大规模数据来说效率低下。
- 而在 HBase 中,查询数据时只需要读取所需的列,可以大大提高查询效率。
3. 高效写入数据:
- 在关系型数据库中,更新数据通常需要更新整行数据,即使只需要更新其中的一列或几列数据。这对于高并发场景来说效率低下。
- 而在 HBase 中,更新数据只需要更新所需的列,可以大大提高写入效率。
4. 易于扩展:
- 关系型数据库通常采用垂直扩展的方式来扩展,即通过增加硬件资源来提高性能。这种方式的扩展成本高,且扩展能力有限。
- 而 HBase 采用分布式架构,可以水平扩展,即通过增加节点来提高性能。这种方式的扩展成本低,且扩展能力强。
5. 高可用性:
- 关系型数据库通常采用单主或主从复制的方式来保证数据高可用性。这种方式的可用性受限于主节点,如果主节点出现故障,则会影响数据库的可用性。
- 而 HBase 采用分布式架构,每个节点都存储部分数据,并且支持自动故障转移。这意味着即使某个节点出现故障,也不会影响数据库的可用性。
总而言之,HBase 面向列存储的优势使其非常适合于存储和处理海量
HBase 的实现原理
功能组件
HBase 是一种分布式、可扩展、高可靠的 NoSQL 数据库,它主要由以下几个功能组件组成:
1. ZooKeeper:
- ZooKeeper 是一个开源的分布式协调服务,用于维护 HBase 集群的元数据信息,并协调集群中的各个节点。
- 具体来说,ZooKeeper 存储以下信息:
- HBase 集群的拓扑结构,包括所有 Region 服务器的地址和状态。
- 表的元数据,包括表的名称、列族、列限定符等信息。
- Region 的分配情况,即每个 Region 存储在哪个 Region 服务器上。
- ZooKeeper 使用一种称为 Zab 的分布式一致性协议来确保元数据的强一致性。
2. Master 服务器:
- Master 服务器是 HBase 集群的中心管理节点,负责管理和监控整个 HBase 集群。
- Master 服务器的主要职责包括:
- 负责分配 Region 到 Region 服务器上。
- 负责处理表和 Region 的创建、删除、修改等操作。
- 负责监控 Region 服务器的状态,并及时处理故障。
- 负责进行负载均衡,以确保每个 Region 服务器的负载均匀分布。
3. Region 服务器:
- Region 服务器是 HBase 集群中的存储节点,负责管理和存储数据,并处理来自客户端的读写请求。
- 每个 Region 服务器存储一个或多个 Region,每个 Region 存储一个表中的一段行数据。
- Region 服务器的主要职责包括:
- 负责存储和管理分配给它的 Region。
- 处理来自客户端的读写请求,并将数据存入或取出 Region。
- 负责将数据更新写入 HLog。
- 负责与 Master 服务器通信,汇报 Region 的状态和负载情况。
4. HLog:
- HLog 是 HBase 的WAL(Write Ahead Log)日志,用于记录对数据的修改,以便在发生故障时进行恢复。
- HLog 是一个分布式的、可复制的日志,每个 Region 服务器都维护一个自己的 HLog。
- 当客户端向 Region 服务器发送写请求时,Region 服务器首先将数据更新写入内存中的 MemStore,然后将更新操作记录到 HLog 中,最后才将数据持久化到 StoreFile 中。
- 如果 Region 服务器发生故障,则可以从 HLog 中恢复数据。
5. MemStore:
- MemStore 是 HBase 的内存缓存,用于缓存 Region 中的数据,以提高读写性能。
- MemStore 是一个基于 LSM(Log-Structured Merge)的缓存,将数据存储在内存中,并定期将数据持久化到 StoreFile 中。
- 当客户端向 Region 服务器发送读请求时,Region 服务器首先会尝试从 MemStore 中读取数据,如果 MemStore 中没有数据,则会从 StoreFile 中读取数据。
- MemStore 的使用可以显著提高 HBase 的读写性能,特别是对于热点数据来说。
6. StoreFile:
- StoreFile 是 HBase 的文件存储格式,用于将数据存储在磁盘上,并提供数据压缩和索引功能。
- StoreFile 是一个基于 HFile 的文件格式,HFile 是一个高效的压缩文件格式。
- StoreFile 中的数据存储在多个块(Block)中,每个块的大小通常为 64KB。
- StoreFile 支持数据压缩和索引,可以提高数据存储效率和查询效率。
表和 Region
表
表是 HBase 中的基本数据组织单位,用于存储一组相关的数据。每个表都有一个唯一的名称,并且可以包含多个列族(Column Family)。
表的概念类似于关系型数据库中的表,但 HBase 的表具有以下特点:
- 面向列: HBase 的表是面向列的,这意味着数据按列存储,而不是按行存储。这使得 HBase 非常适合于存储和处理稀疏数据。
- 可扩展: HBase 的表可以水平扩展,即通过增加 Region 服务器来增加表的存储容量。
- 高可用性: HBase 的表是高可用的,即使某个 Region 服务器发生故障,也不会影响表的可用性。
Region
Region 是 HBase 中数据管理的基本单位,它代表了表中的一段连续的行键范围。每个 Region 都存储在一个 Region 服务器上,并由以下几个部分组成:
- Store: 每个 Region 中包含一个或多个 Store,每个 Store 存储一个列族中的数据。
- MemStore: MemStore 是一个内存缓存,用于缓存 Region 中的数据,以提高读写性能。
- StoreFile: StoreFile 是一个文件存储格式,用于将数据存储在磁盘上。
- HLog: HLog 是一个 WAL(Write Ahead Log)日志,用于记录对数据的修改,以便在发生故障时进行恢复。
Region 的概念类似于关系型数据库中的分区,但 HBase 的 Region 具有以下特点:
- 自动拆分: HBase 会自动拆分 Region,以确保每个 Region 的大小均匀。
- 负载均衡: HBase 会自动进行负载均衡,以确保每个 Region 服务器的负载均匀分布。
- 故障转移: HBase 会自动进行故障转移,以确保在 Region 服务器发生故障时数据仍然可用。
表与 Region 的关系
表与 Region 之间的关系可以概括为以下几点:
- 一个表可以包含多个 Region。
- 每个 Region 都属于一个表。
- 一个 Region 存储了表中的一段连续的行键范围。
- HBase 会自动管理 Region 的拆分和合并,以确保表的数据均匀分布在各个 Region 服务器上。
Region 的定位
当客户端需要访问某个行键的数据时,HBase 会首先根据行键定位到对应的 Region,然后再从 Region 服务器中获取数据。Region 的定位过程主要分为以下几个步骤:
- 客户端向 RegionLocator 请求 Region 信息: 客户端会首先向 RegionLocator 请求目标行键所在的 Region 信息。RegionLocator 是 HBase 中的一个类,用于定位 Region。
- RegionLocator 查询 ZooKeeper: RegionLocator 会从 ZooKeeper 中查询元数据信息,以定位目标行键所在的 Region。ZooKeeper 是一个分布式的协调服务,用于存储 HBase 的元数据信息。
- ZooKeeper 返回 Region 信息: ZooKeeper 会返回目标行键所在的 Region 的地址和端口号。
- 客户端连接 Region 服务器: 客户端会根据 ZooKeeper 返回的信息连接到目标行键所在的 Region 服务器。
- 客户端获取数据: 客户端会向 Region 服务器发送请求,获取目标行键的数据。
元数据信息
HBase 的元数据信息存储在 ZooKeeper 中,主要包括以下几类:
- 表信息: 包括表的名称、列族、列限定符等信息。
- Region 信息: 包括 Region 的名称、起始行键、结束行键、Region 服务器地址等信息。
- Namespace 信息: 包括命名空间的名称、表信息等信息。
Region 定位的优化
为了提高 Region 定位的效率,HBase 采用了以下几种优化策略:
- 缓存: RegionLocator 会缓存最近访问过的 Region 信息,以避免每次都需要查询 ZooKeeper。
- 本地缓存: Region 服务器会缓存自己管理的 Region 信息,以避免每次都需要查询 ZooKeeper。
- 预分区: 用户可以预先将表划分为多个 Region,以减少 Region 定位的开销。
HBase 的运行机制
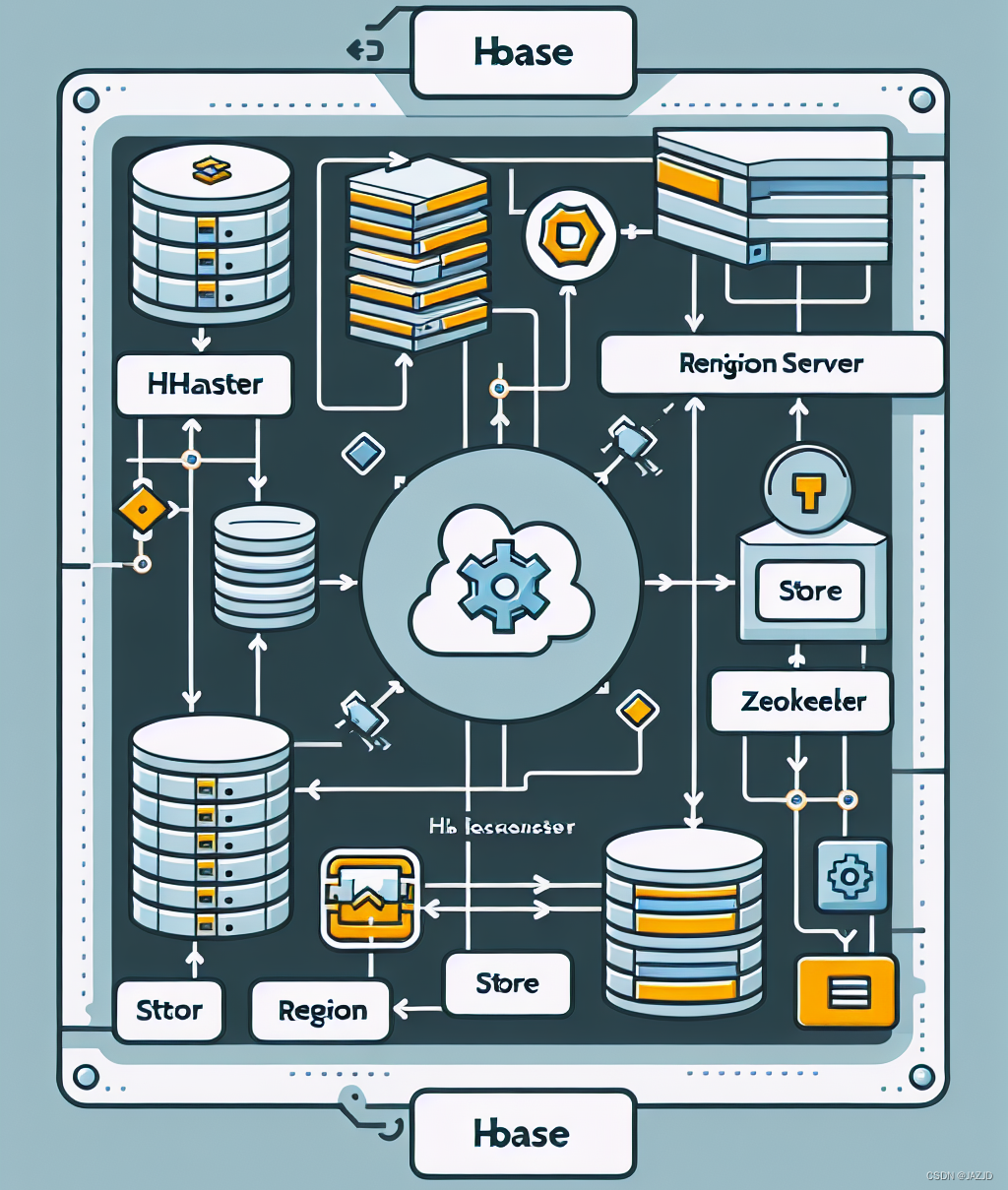
HBase 系统架构
HBase 采用主从架构,由 Master 服务器和多个 Region 服务器组成。Master 服务器负责管理和监控整个集群,Region 服务器负责存储和处理数据。如下图所示:
1. ZooKeeper:
- ZooKeeper 是一个开源的分布式协调服务,用于维护 HBase 集群的元数据信息,并协调集群中的各个节点。
- 具体来说,ZooKeeper 存储以下信息:
- HBase 集群的拓扑结构,包括所有 Region 服务器的地址和状态。
- 表的元数据,包括表的名称、列族、列限定符等信息。
- Region 的分配情况,即每个 Region 存储在哪个 Region 服务器上。
- ZooKeeper 使用一种称为 Zab 的分布式一致性协议来确保元数据的强一致性。
2. Master 服务器:
- Master 服务器是 HBase 集群的中心管理节点,负责管理和监控整个 HBase 集群。
- Master 服务器的主要职责包括:
- 负责分配 Region 到 Region 服务器上。
- 负责处理表和 Region 的创建、删除、修改等操作。
- 负责监控 Region 服务器的状态,并及时处理故障。
- 负责进行负载均衡,以确保每个 Region 服务器的负载均匀分布。
3. Region 服务器:
- Region 服务器是 HBase 集群中的存储节点,负责管理和存储数据,并处理来自客户端的读写请求。
- 每个 Region 服务器存储一个或多个 Region,每个 Region 存储一个表中的一段行数据。
- Region 服务器的主要职责包括:
- 负责存储和管理分配给它的 Region。
- 处理来自客户端的读写请求,并将数据存入或取出 Region。
- 负责将数据更新写入 HLog。
- 负责与 Master 服务器通信,汇报 Region 的状态和负载情况。
4. HLog:
- HLog 是 HBase 的WAL(Write Ahead Log)日志,用于记录对数据的修改,以便在发生故障时进行恢复。
- HLog 是一个分布式的、可复制的日志,每个 Region 服务器都维护一个自己的 HLog。
- 当客户端向 Region 服务器发送写请求时,Region 服务器首先将数据更新写入内存中的 MemStore,然后将更新操作记录到 HLog 中,最后才将数据持久化到 StoreFile 中。
- 如果 Region 服务器发生故障,则可以从 HLog 中恢复数据。
5. MemStore:
- MemStore 是 HBase 的内存缓存,用于缓存 Region 中的数据,以提高读写性能。
- MemStore 是一个基于 LSM(Log-Structured Merge)的缓存,将数据存储在内存中,并定期将数据持久化到 StoreFile 中。
- 当客户端向 Region 服务器发送读请求时,Region 服务器首先会尝试从 MemStore 中读取数据,如果 MemStore 中没有数据,则会从 StoreFile 中读取数据。
- MemStore 的使用可以显著提高 HBase 的读写性能,特别是对于热点数据来说。
6. StoreFile:
- StoreFile 是 HBase 的文件存储格式,用于将数据存储在磁盘上,并提供数据压缩和索引功能。
- StoreFile 是一个基于 HFile 的文件格式,HFile 是一个高效的压缩文件格式。
- StoreFile 中的数据存储在多个块(Block)中,每个块的大小通常为 64KB。
- StoreFile 支持数据压缩和索引,可以提高数据存储效率和查询效率。
Region 服务器的工作原理
工作流程
当客户端向 HBase 集群发送读写请求时,Region 服务器的工作流程如下:
- 客户端向 RegionLocator 请求 Region 信息: 客户端会首先向 RegionLocator 请求目标行键所在的 Region 信息。RegionLocator 是 HBase 中的一个类,用于定位 Region。
- RegionLocator 查询 ZooKeeper: RegionLocator 会从 ZooKeeper 中查询元数据信息,以定位目标行键所在的 Region。ZooKeeper 是一个分布式的协调服务,用于存储 HBase 的元数据信息。
- ZooKeeper 返回 Region 信息: ZooKeeper 会返回目标行键所在的 Region 的地址和端口号。
- 客户端连接 Region 服务器: 客户端会根据 ZooKeeper 返回的信息连接到目标行键所在的 Region 服务器。
- 客户端发送请求: 客户端向 Region 服务器发送读写请求,请求中包含目标行键和列限定符等信息。
- Region 服务器定位 Region: Region 服务器根据请求中的行键定位到对应的 Region。
- Region 服务器处理请求: Region 服务器从 MemStore 或 StoreFile 中获取数据,并根据请求的操作类型进行处理。
- Region 服务器返回结果: Region 服务器将处理结果返回给客户端。
MemStore 和 StoreFile
MemStore 是 HBase 的内存缓存,用于缓存 Region 中的数据,以提高读写性能。StoreFile 是 HBase 的文件存储格式,用于将数据存储在磁盘上。
- MemStore: MemStore 是一个基于 LSM(Log-Structured Merge)的缓存,将数据存储在内存中,并定期将数据持久化到 StoreFile 中。当客户端向 Region 服务器发送读请求时,Region 服务器首先会尝试从 MemStore 中读取数据,如果 MemStore 中没有数据,则会从 StoreFile 中读取数据。MemStore 的使用可以显著提高 HBase 的读写性能,特别是对于热点数据来说。
- StoreFile: StoreFile 是一个基于 HFile 的文件格式,HFile 是一个高效的压缩文件格式。StoreFile 中的数据存储在多个块(Block)中,每个块的大小通常为 64KB。StoreFile 支持数据压缩和索引,可以提高数据存储效率和查询效率。
Store 的工作原理
Store 是 HBase Region 服务器中的一个重要组件,它负责管理和存储一个列族中的数据。每个 Region 可以包含多个 Store,每个 Store 对应于一个列族。Store 将数据存储在内存中的 MemStore 和磁盘上的 StoreFile 中。
Store 的职责
Store 的主要职责包括:
- 存储列族数据: Store 负责存储一个列族中的所有数据,包括行键、列限定符和数据值。
- 维护 MemStore: Store 维护一个 MemStore,用于缓存列族数据。MemStore 是一个基于 LSM(Log-Structured Merge)的缓存,将数据存储在内存中,并定期将数据持久化到 StoreFile 中。
- 管理 StoreFile: Store 负责管理 StoreFile,StoreFile 是 HBase 的文件存储格式,用于将数据存储在磁盘上。StoreFile 支持数据压缩和索引,可以提高数据存储效率和查询效率。
- 处理数据请求: Store 会处理来自客户端的读写请求,并将数据从 MemStore 或 StoreFile 中获取,并返回给客户端。
Store 的工作流程
Store 的工作流程主要包括以下几个步骤:
- 客户端发送请求: 客户端向 Region 服务器发送读写请求,请求中包含目标行键、列限定符和数据值等信息。
- Region 服务器定位 Region 和 Store: Region 服务器根据请求中的行键定位到对应的 Region,并根据请求中的列限定符定位到对应的 Store。
- Store 处理请求:
- 读请求: 如果是读请求,Store 会首先尝试从 MemStore 中读取数据,如果 MemStore 中没有数据,则会从 StoreFile 中读取数据。
- 写请求: 如果是写请求,Store 会将数据写入 MemStore 中。当 MemStore 达到一定大小时,就会将数据刷写到 StoreFile 中。
MemStore 和 StoreFile
MemStore 和 StoreFile 是 Store 存储数据的主要方式。
- MemStore: MemStore 是一个基于 LSM(Log-Structured Merge)的缓存,将数据存储在内存中,并定期将数据持久化到 StoreFile 中。MemStore 的使用可以显著提高 HBase 的读写性能,特别是对于热点数据来说。
- StoreFile: StoreFile 是一个基于 HFile 的文件格式,HFile 是一个高效的压缩文件格式。StoreFile 中的数据存储在多个块(Block)中,每个块的大小通常为 64KB。StoreFile 支持数据压缩和索引,可以提高数据存储效率和查询效率。
HLog 的工作原理
HLog(Write Ahead Log)是 HBase Region 服务器中的一个重要组件,它用于记录对数据的修改。当客户端向 Region 服务器发送写请求时,Region 服务器首先将数据写入 HLog 中,然后再写入 MemStore 中。HLog 可以保证数据的持久性和原子性,并在发生故障时用于数据恢复。
HLog 的作用
HLog 的主要作用包括:
- 保证数据的持久性: HLog 首先将数据写入 HLog 中,然后再写入 MemStore 中。即使 MemStore 发生故障,数据也不会丢失。
- 保证数据的原子性: HLog 中的数据以顺序写入,并使用 WAL(Write Ahead Log)机制来保证数据的原子性。即使 Region 服务器在写入 HLog 的过程中发生故障,也不会导致数据不一致。
- 支持数据恢复: HLog 可以用于在 Region 服务器发生故障时恢复数据。
HLog 的工作流程
HLog 的工作流程主要包括以下几个步骤:
- 客户端发送写请求: 客户端向 Region 服务器发送写请求,请求中包含目标行键、列限定符和数据值等信息。
- Region 服务器定位 Region 和 Store: Region 服务器根据请求中的行键定位到对应的 Region,并根据请求中的列限定符定位到对应的 Store。
- Store 将数据写入 HLog: Store 将数据写入 HLog 中。HLog 中的数据以顺序写入,并使用 WAL(Write Ahead Log)机制来保证数据的原子性。
- Store 将数据写入 MemStore: Store 将数据写入 MemStore 中。MemStore 是一个基于 LSM(Log-Structured Merge)的缓存,将数据存储在内存中,并定期将数据持久化到 StoreFile 中。
HLog 的特性
HLog 的主要特性包括:
- 顺序写入: HLog 中的数据以顺序写入,这可以保证数据的原子性。
- WAL 机制: HLog 使用 WAL(Write Ahead Log)机制来保证数据的原子性。WAL 机制要求数据必须先写入日志,然后再写入内存或磁盘。这样,即使在写入过程中发生故障,也可以从日志中恢复数据。
- 可持久化: HLog 中的数据可以持久化到磁盘上,这可以保证数据的安全性。
编程实践
常用的 Shell 命令
HBase 提供了一个 Shell 命令行工具,用于管理和操作 HBase 集群。该工具提供了丰富的命令,可以用来执行各种操作,例如创建表、管理数据、监控集群等。以下是一些常用的 HBase Shell 命令:
表管理
-
create: 创建一个新的表。 语法:create 'table_name' 'column_family1' [GC-params] [column_family2] [GC-params] ...例如:create 'test_table' 'cf1' 'cf2' MEMSTORE_SIZE=1024M MEMSTORE_INDEX_SIZE=256M -
list: 列出所有表。 语法:list -
describe: 显示一个表的详细信息。 语法:describe 'table_name'例如:describe 'test_table' -
disable: 禁用一个表。 语法:disable 'table_name' -
enable: 启用一个表。 语法:enable 'table_name' -
drop: 删除一个表。 语法:drop 'table_name'
数据操作
-
put: 向表中插入数据。 语法:put 'table_name' 'rowkey' 'column_family:column' 'value'例如:put 'test_table' 'row1' 'cf1:col1' 'value1' 'cf2:col2' 'value2' -
get: 从表中读取数据。 语法:get 'table_name' 'rowkey' [column_family:column]例如:get 'test_table' 'row1' 'cf1:col1' 'cf2:col2' -
scan: 扫描表中的所有数据。 语法:scan 'table_name' [STARTROW [STOPROW]] [STARTCOLUMN [STOPCOLUMN]] [FILTER expression]例如:scan 'test_table' 'row1' 'row10' 'cf1' 'cf2' -
delete: 删除表中的数据。 语法:delete 'table_name' 'rowkey' [column_family:column] [timestamp]例如:delete 'test_table' 'row1' 'cf1:col1' 1595469383000
其他命令
-
status: 查看 HBase 集群的状态。 语法:status -
version: 查看 HBase 的版本信息。 语法:version -
help: 查看 HBase Shell 命令的帮助信息。 语法:help [command]
示例
以下是一些使用 HBase Shell 命令的示例:
- 创建一个名为
test_table的表,其中包含两个列族cf1和cf2:
create 'test_table' 'cf1' 'cf2' MEMSTORE_SIZE=1024M MEMSTORE_INDEX_SIZE=256M
- 向表
test_table中插入一行数据:
put 'test_table' 'row1' 'cf1:col1' 'value1' 'cf2:col2' 'value2'
- 从表
test_table中读取一行数据:
get 'test_table' 'row1' 'cf1:col1' 'cf2:col2'
- 扫描表
test_table中的所有数据:
scan 'test_table' 'row1' 'row10' 'cf1' 'cf2'
- 删除表
test_table中row1行的cf1:col1列数据:
delete 'test_table' 'row1' 'cf1:col1'常用的 Java API 及应用实例
HBase 提供了 Java API 来方便开发者访问和操作 HBase 集群中的数据。常用的 Java API 类和方法包括:
1. HBaseAdmin:用于管理 HBase 表
createTable(TableName tableName, HTableDescriptor tableDescriptor):创建一张新的 HBase 表。deleteTable(TableName tableName):删除一张现有的 HBase 表。modifyTable(TableName tableName, HTableDescriptor tableDescriptor):修改一张现有的 HBase 表的表定义。isTableAvailable(TableName tableName):检查一张 HBase 表是否存在。
2. HTable:用于访问 HBase 表中的数据
put(byte[] row, byte[] family, byte[] qualifier, byte[] value):向 HBase 表中插入一行数据。get(byte[] row, byte[] family, byte[] qualifier):从 HBase 表中读取一行数据。delete(byte[] row, byte[] family, byte[] qualifier, long timestamp):从 HBase 表中删除一行数据。scan(Scan scan):扫描 HBase 表中的数据。
3. Put:用于向 HBase 表中插入数据
addColumn(byte[] family, byte[] qualifier, byte[] value):向 Put 对象中添加一列数据。setTimestamp(long timestamp):设置 Put 对象中数据的版本时间戳。
4. Get:用于从 HBase 表中读取数据
setRow(byte[] row):设置 Get 对象中要读取的行键。addColumn(byte[] family, byte[] qualifier):指定要读取的列。setTimestamp(long timestamp):指定要读取的数据的版本时间戳。
5. Scan:用于扫描 HBase 表中的数据
setStartRow(byte[] startRow):设置扫描的起始行键。setStopRow(byte[] stopRow):设置扫描的结束行键。addScanFilter(Filter filter):向 Scan 对象中添加过滤器,用于过滤扫描结果。
示例:向 HBase 表中插入数据
以下是一个使用 Java API 向 HBase 表 test_table 中插入数据的示例代码:
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.*;public class HBaseDemo {public static void main(String[] args) throws Exception {// 创建 HBase 配置对象Configuration configuration = HBaseConfiguration.create();// 创建 HTable 对象HTable table = new HTable(configuration, TableName.valueOf("test_table"));// 创建 Put 对象Put put = new Put(Bytes.toBytes("row1"));// 向 Put 对象中添加数据put.addColumn(Bytes.toBytes("cf1"), Bytes.toBytes("col1"), Bytes.toBytes("value1"));put.addColumn(Bytes.toBytes("cf2"), Bytes.toBytes("col2"), Bytes.toBytes("value2"));// 向 HBase 表中插入数据table.put(put);// 关闭 HTable 连接table.close();}
}
总结
HBase 是一个分布式、面向列的开源非关系型数据库,它非常适合于存储和处理大规模数据。本文介绍了 HBase 的概述、访问接口、数据模型、实现原理和运行机制,并提供了常见的 Shell 命令和 Java API 示例。希望通过本文的介绍,可以帮助读者更好地了解和使用 HBase 这个强大的分布式数据库。