1.背景
现在有这样一个场景,我们需要在本地选择一个文件后,然后上传到网络上。
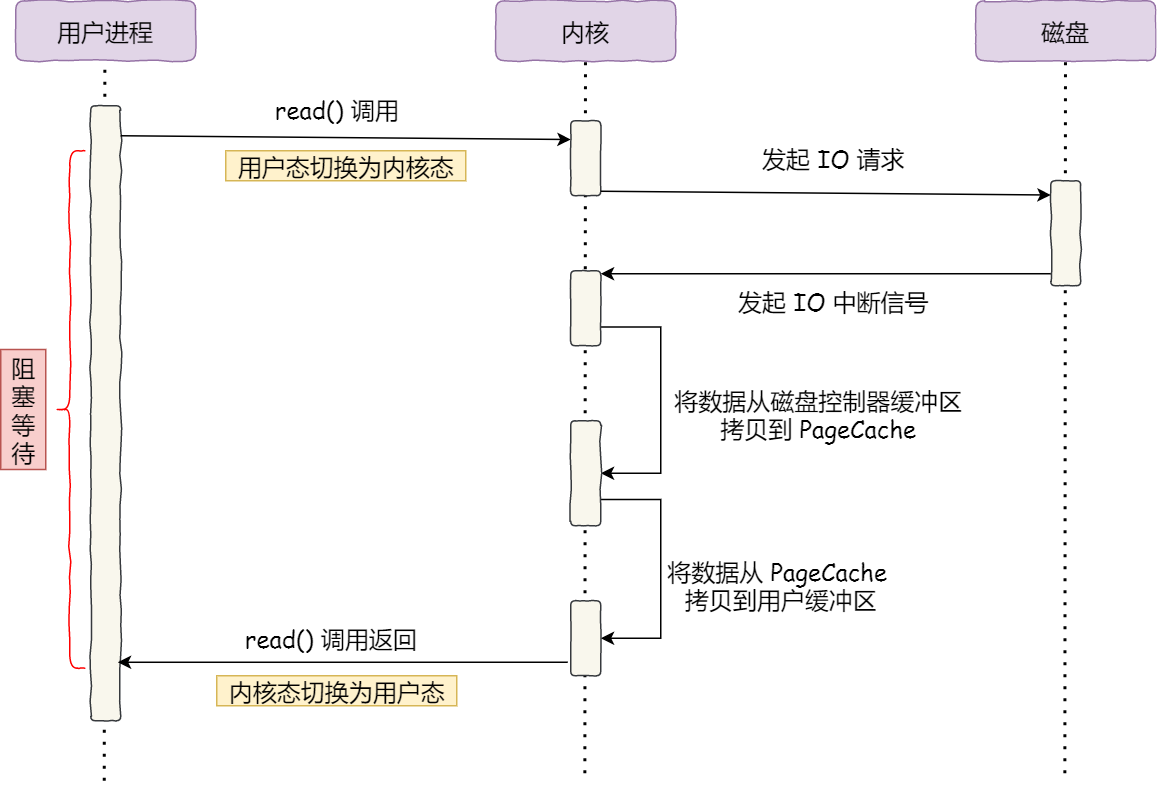
我们再看看文件的内容数据的具体搬运过程:

你会发现,在整个文件搬运的过程中,发生了多次的数据拷贝和上下文转换。
4次数据拷贝:
- 第一次:
磁盘文件 -> 内核缓存(内核缓冲区,Page Cache),该过程由DMA负责完成,CPU可以执行其他任务。 - 第二次:
内核缓存 -> 用户缓冲区,该过程由CPU负责完成。 - 第三次:
用户缓冲区 -> 内核缓存,该过程由CPU负责完成。 - 第四次:
内核缓存 -> 网卡的设备缓冲区,该过程由DMA负责完成,CPU可以执行其他任务。
4次上下文转换:
每一次的系统调用均会涉及到两次上下文转换:
- 第一次:用户发起系统调用,上下文将由
用户态 -> 内核态。 - 第二次:系统调用执行完成,上下文将由执行时的环境
内核态 -> 用户态。
而上面的文件搬运过程用到了read和write这两个系统调用。
通过上面的分析,不难看出,内核态与用户态的交互部分完全没有存在的必要(前提是你不会对加载进用户缓冲区的数据进行二次加工),因此,我们需要去除掉这部分冗余的交互过程。诺,零拷贝这不就登场了嘛。

2.实现方式
2.1 mmap + write
2.1.1 概述
mmap():一个系统调用函数,该函数会将内核缓冲区中的数据直接映射到用户空间,这样做就省去了 内核缓存 -> 用户缓冲区 这一拷贝过程。
write():在发现所要拷贝的数据是内核缓冲区经mmap直接映射过来的,因此,它将直接对应的内核缓存中拷贝数据到Socket缓冲区,但是此过程需要由CPU负责进行数据的拷贝。

2.2.2 评估
通过将read系统调用替换为mmap系统调用,我们减少了一次由内核缓存 -> 用户缓冲区的拷贝过程,但是,我们的系统调用次数没有减少,因此,这种方式还不是最理想的零拷贝方案。
2.2 sendfile
2.2.1 概述
**sendfile()**:一个系统调用函数,它能够代替前面的read()和write()这两个系统调用函数,因此,它能够免去两次上下文切换的开销。同时,它也将内核缓存的数据不经过用户缓冲区而直接拷贝到Socket缓冲区(就本场景而言),因此,也能够免去一次内核缓存 -> 用户缓冲区的拷贝过程。

适用环境:Linux 2.1+
2.2.2 评估
该方案同时免去了一次拷贝过程和两次上下文切换所带来的开销,但是,CPU还是参与了一次内存的拷贝,因此这个方案还不是最优解。
2.3 sendfile + SG-DMA
2.3.1 概述
如果网卡支持SG-DMA(可以通过ethtool -k eth0 | grep scatter-gather指令来查看是否支持SG-DMA),拷贝到内核缓存的数据将不再由CPU拷贝至Socket缓冲区了,而是直接由SG-DMA控制器负责直接拷贝至网卡的缓冲区中。

适用环境:Linux 2.4+
2.3.2 评估
CPU全程没有参与到数据的拷贝过程中来,而且系统调用次数也比最初降低了一半,数据拷贝次数也降低了一半,整体执行效率大致提升了一倍!
3.应用
Kafka底层大量调用了Java的NIO库中的transferTo方法,而该方法又最终发起了sendfile系统调用(如果运行环境支持的话),因此,Kafka在处理海量数据上快如闪电、所向披靡!NGINX目前也支持配置sendfile。
4.注意事项
- 零拷贝技术要求数据不能进行二次加工,如:压缩数据后发送,这种就不能使用零拷贝技术。
- 零拷贝技术依赖于
PageCache(即内核缓存)。
5.大文件传输
51 背景
大文件传输将不走内核缓存。原因如下:
- 大文件会占用较多的
Page Cache,会挤占热点小(针对于大文件而言)数据的空间,从而使热点数据的命中率下降。 - 大文件缓存在
Page Cache中,其本身的命中率也不高。
由于大文件传输不走Page Cache,因此前面所说的零拷贝技术它也就用不了了。
5.2 解决方案
5.2.1 异步I/O + 直接I/O
传统的数据拷贝过程:
采用异步I/O + 直接I/O下的大文件拷贝过程:
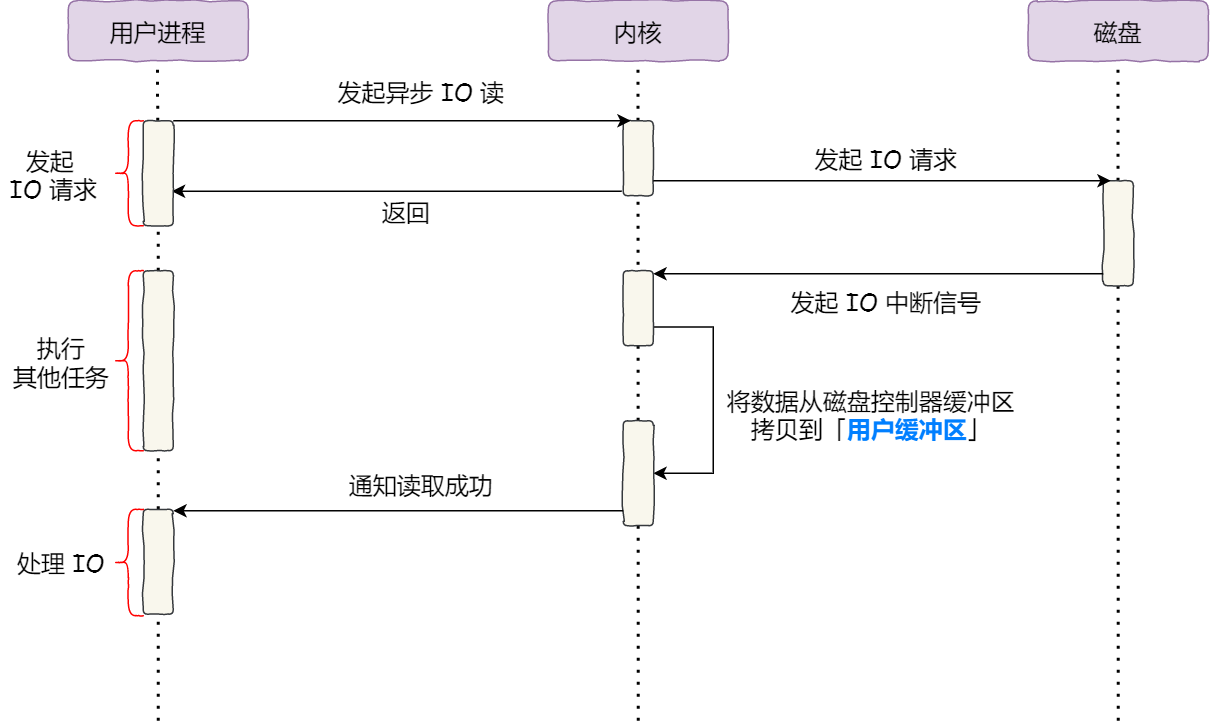
你会发现,我们数据的拷贝不再经过中间的Page Cache,因此这种I/O方式不就是我们在文件系统(二)中所谈到的直接I/O吗?
同时,我们用户进程并没有持续等待I/O操作的完成,而是立刻返回,继续执行其他任务,因此,我们也达到了异步I/O的目的。
5.3 评估
综合前面的解决方案,我们有:
- 对于小文件传输,尽可能地采用零拷贝技术。
- 对于大文件传输,尽可能地采用
异步I/O + 直接I/O的方式进行加速传输。
参考文档
9.1 什么是零拷贝?