Assistants API:以开发人员为中心。
有状态的API:允许存储以前的消息、上传文件、访问内置工具(代码解释器)、通过函数调用控制其他工具。
认知架构应用的两个组件:(1)如何提供上下文给应用 (2)应用如何推理
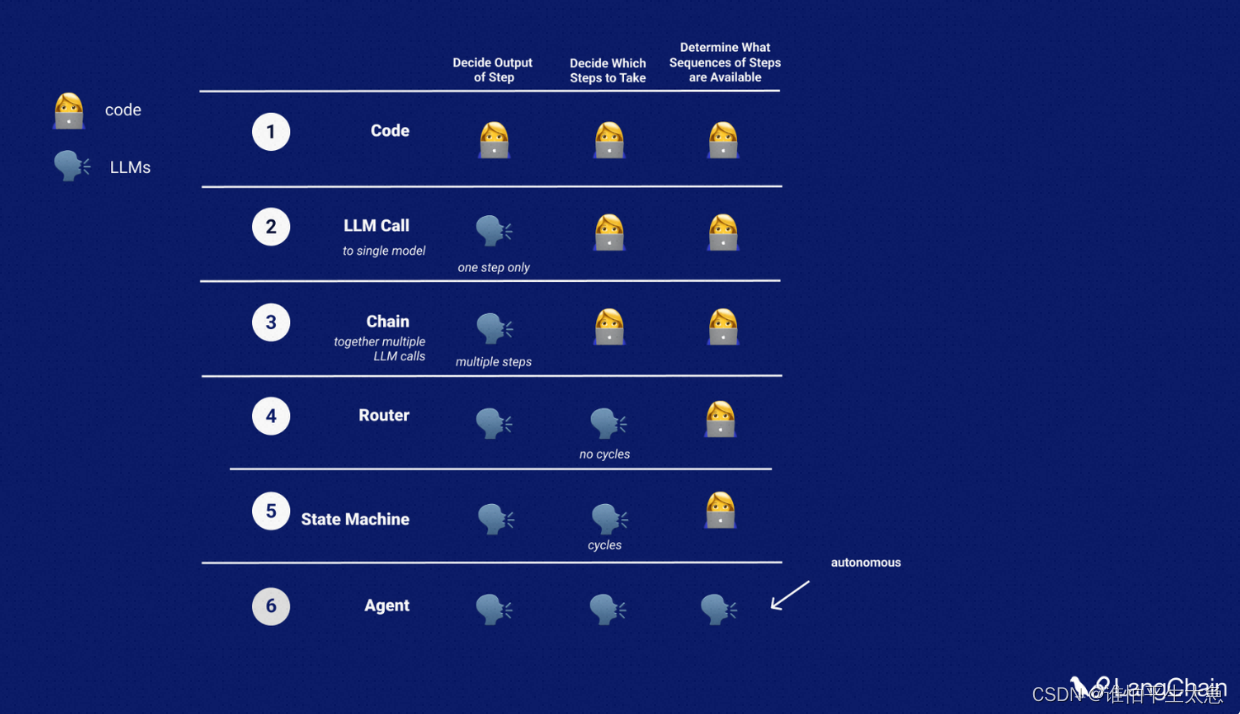
不同级别的认知架构:
(1)单个LLM、仅得到输出
(2)一连串LLM、仅得到输出
(3)LLM作为路由、选择要使用的操作(工具、检索器、提示)
(4)状态机、使用LLMs在步骤之间进行路由,某种程度上形成了循环,但仍然在代码中枚举了允许的转换选项
(5)Agents、移除大量脚手架,便于完全有LLMs决定转换选项
表格形式呈现不同认知架构的对比情况:
agent scratchpad:代理草稿本。
Action & observation 动作及其对应的观察结果
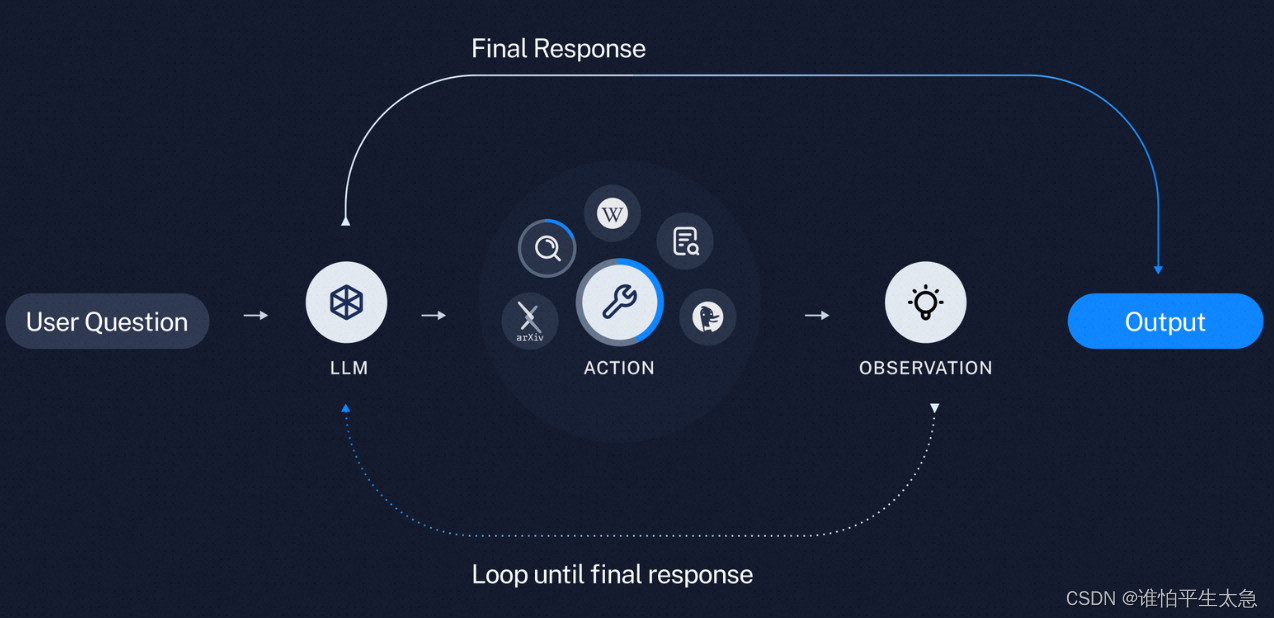
当前问题:从各个方面来看,这种Agent的认知架构并不足以支持严肃的应用。
目前看到的实际有用的 自主代理 Autonomous agents 在两个关键方面有所不同:
(1)实际不是Agent认知架构,而是复杂的Chains,更像是状态机。比如 GPT-Researcher 和Sweep.dev。GPT-Researcher:从执行图来看,是朝一个方向流动的,执行了许多复杂的步骤,但以明确的方式进行:首先生成子问题,然后获得子问题的链接,总结每个链接,最后将摘要合并到研究报告中。
(2)如何向Agent提供上下文。尽管描述的是上下文感知推理应用程序,但实际上需要pulling或者pushing来实现。意味着agent决定它需要什么上下文,然后请求它。比如sql相关的agent,可能需要知道sql数据库中存在哪些表。因此可以给它一个返回数据库中表列表的工具,并且可以在开始时调用工具。实际上,Langchain中SQL和Pandas代理将表模式作为系统消息的一部分。这种上下文的pulling和pushing操作再次为开发人员提供了更多的控制权。
观点:认知架构和LLM一样,也是封闭的,同样了决定了最终效果,LLM逐渐转向成为操作系统。这似乎是一个五五开的分配,一半是在于核心模型的改进,另一半是在于弄清楚如何以一种具有代理性的方式将它们最佳连接。
Jeff Bezos: only do what makes your beer taste better 只做能让你的啤酒口感更佳的事情。这和第一性原理相通。
优化认知架构符合第一性原理吗? 作者持肯定观点。原因有三:
(1)首先:让复杂的代理真正发挥作用是非常困难的。如果你的应用依赖于代理的工作,而让代理工作又是具有挑战性的,那么几乎可以说如果你能做好这一点,你就会比你的竞争对手拥有优势。
(2)第二个原因是,我们经常看到通用人工智能(GenAI)应用的价值与认知架构的性能紧密相关。当前许多公司都在销售用于编程的代理、用于客户支持的代理。在这些情况下,认知架构就是产品本身。
(3)最后一个原因也是我难以相信公司会愿意将自己锁定在由单一公司控制的认知架构中的原因。
LangChain 在构建Agent认知架构,提供很多助力。需要大量的工程工作。 LCEL可以用来灵活组合链条。 LangChain提供了超过 600 个集成,可以全面灵活地选择使用模型/向量存储/数据库。LangSmith,提供调试,并包括各项管理工具(回归测试、监控、数据标注、提示中心),便于线上管理整个系统。
OpenAI押注认知架构