文章目录
- 一、grep文本处理工具
- 二、sed文本处理工具
- 基本用法
- sed脚本格式
- 搜索替代
一、grep文本处理工具
| 选项 | 含义 |
|---|---|
| -color | 对匹配到的文本着色显示 |
| -m +次数 | 匹配到规定的次数后停止 |
| -v | 显示不被命令匹配到的行,即取反 |
| -i | 忽略字符大小写 |
| -n | 显示匹配的行号 |
| -c | 统计匹配的行数 |
| -o | 仅显示匹配到的字符串 |
| -q | 静默模式,不输出任何信息,多用于写脚本 |
| -A | after,将匹配到的行的后n行显示出来 |
| -B | before,将匹配到的行的前n行显示出来 |
| -C | context,将匹配到的行的前后n行显示出来 |
| -e | 实现多个选项间的逻辑or关系 |
| -w | 匹配整个单词 |
| -E 等价于egrep | 启用扩展正则表达式 |
| -F | 不支持正则表达式,相当于fgrep |
| -f | 处理两个文件相同内容 把第一个文件作为匹配条件 |
| -r | 递归目录,但不处理软链接 |
| -R | 递归目录,但处理软链接 |

思考题:统计当前主机的连接状态

二、sed文本处理工具
sed 即 Stream EDitor,和 vi 不同,sed是行编辑器。
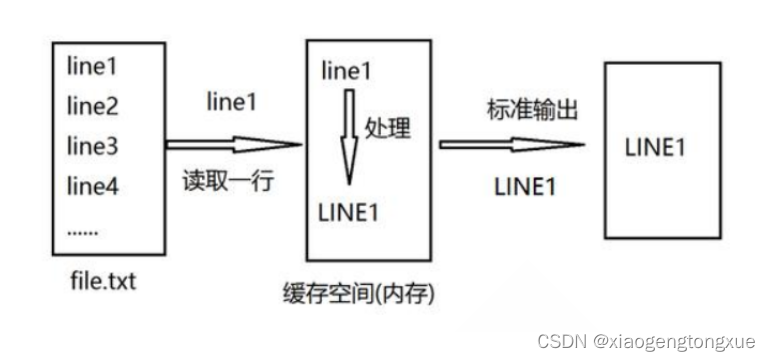
Sed是从文件或管道中读取一行,处理一行,输出一行;再读取一行,再处理一行,再输出一行,直到最后一行。每当处理一行时,把当前处理的行存储在临时缓冲区中,称为模式空间(PatternSpace),接着用sed命令处理缓冲区中的内容,处理完成后,把缓冲区的内容送往屏幕。接着处理下一行,这样不断重复,直到文件末尾。一次处理一行的设计模式使得sed性能很高,sed在读取大文件时不会出现卡顿的现象。如果使用vi命令打开几十M上百M的文件,明显会出现有卡顿的现象,这是因为vi命令打开文件是一次性将文件加载到内存,然后再打开。Sed就避免了这种情况,一行一行的处理,打开速度非常快,执行速度也很快
基本用法
| 选项 | 含义 |
|---|---|
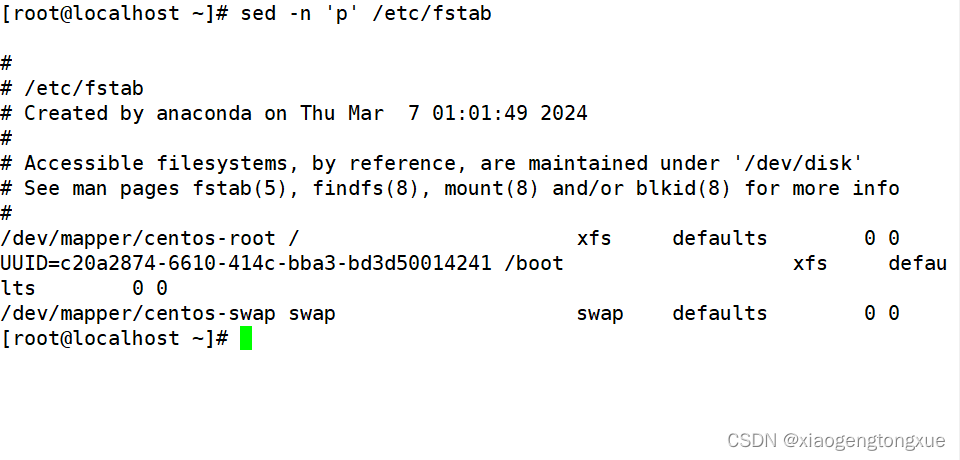
| -n | 不输出模式空间内容到屏幕,即不自动打印 |
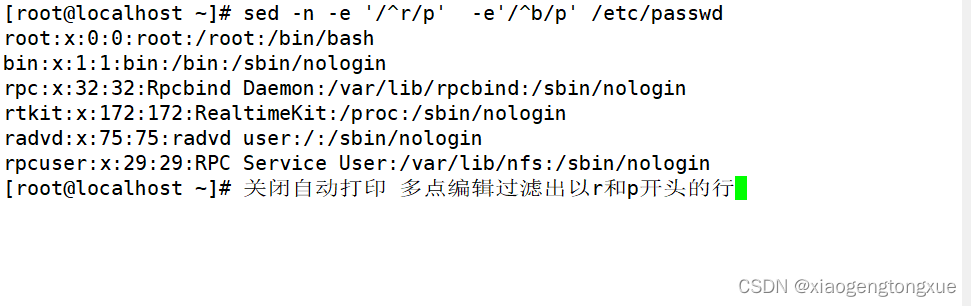
| -e | 多点编辑 |
| -f FILE | 从指定文件中读取编辑脚本 |
| -r, -E | 使用扩展正则表达式 |
| -i.bak | 备份文件并原处编辑 |
注意:
-ir 不支持
-i -r 支持
-ri 支持
-ni 会清空文件
支持重定向,下图是重定向输入
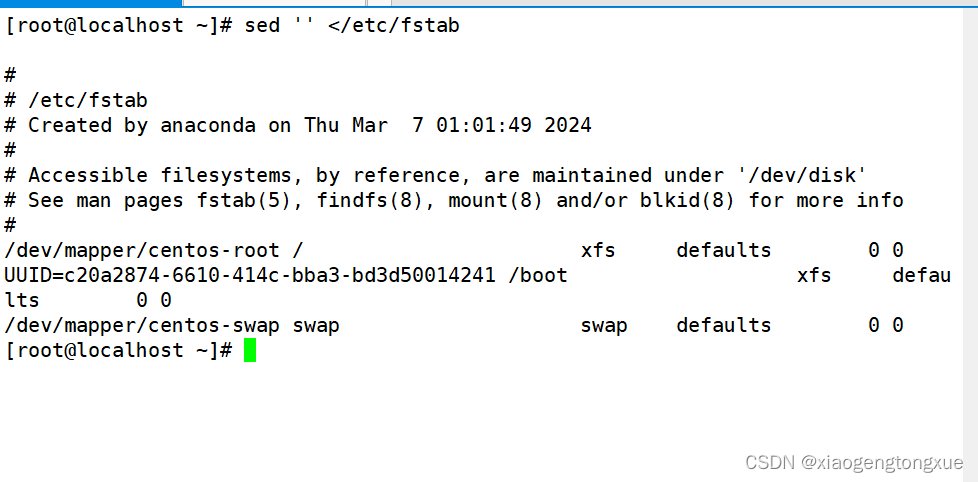
sed脚本格式
'地址+命令’组成
地址:
1.不给地址:对全文进行处理
2.单地址:
#:指定的行,$:最后一行
/pattern/:被此处模式所能够匹配到的每一行,正则表达式
3. 地址范围:
#,# 从#行到第#行,3,6 从第3行到第6行
#,+# 从#行到+#行,3,+4 表示从3行到第7行
/pat1/,/pat2/ 第一个正则表达式 到 第二个正则表达式之间的行
#,/pat/ 从#号行为开始找到 pat为止 3 , /^r/
/pat/,# 从pat开始直到找到#号为止
4. 步进:~
1~2 奇数行
2~2 偶数行
sed -n ‘n;p’ file1 #打印偶数行
sed -n ‘2,${n;p}’ file1
命令:
- a:增加,在当前行下面增加一行指定内容。
- c:替换,将选定行替换为指定内容。
- d:删除,删除选定的行。
- i:插入,在选定行上面插入一行指定内容。
- p:打印,如果同时指定行,表示打印指定行;如果不指定行,则表示打印所有内容;如果有非打印字符,则以 ASCII码输出。其通常与“-n”选项一起使用。
- s:替换,替换指定字符。
- y:字符转换。
- -e 或–expression=:表示用指定命令或者脚本来处理输入的文本文件。
- -f 或–file=:表示用指定的脚本文件来处理输入的文本文件。
- -h 或–help:显示帮助。
- -n、–quiet 或 silent:表示仅显示处理后的结果。
- -i:直接编辑文本文件。
- -r 使用扩展正则表达式
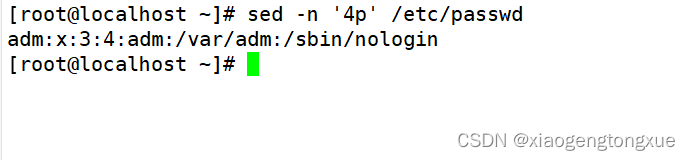
显示文件的第四行
显示文件的3-5行

显示文件的奇数行
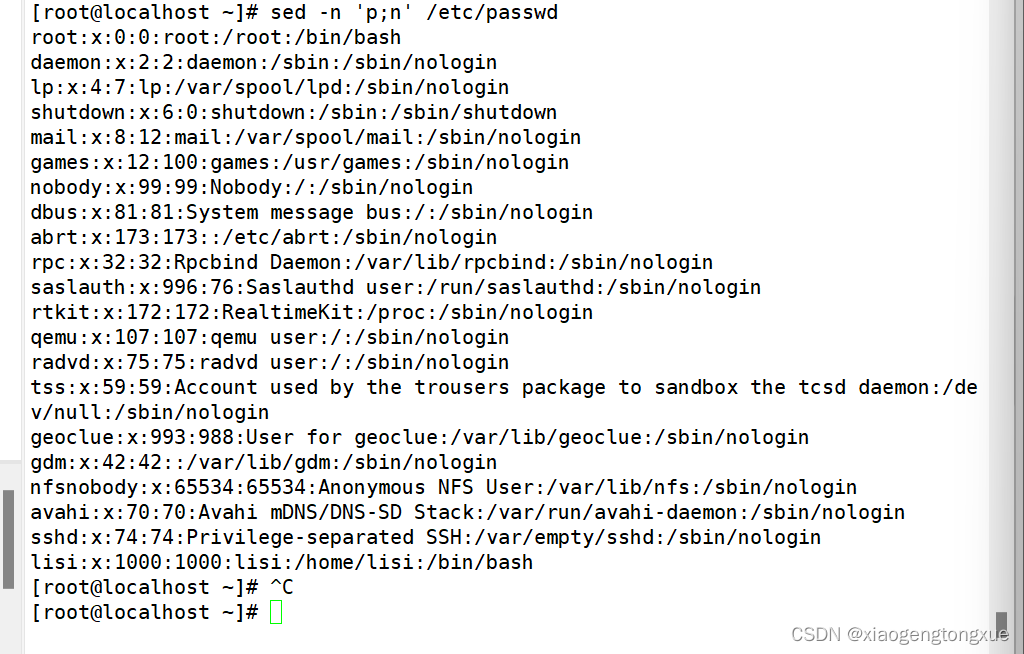
解释:
1.sed 读取 /etc/passwd 文件的第一行。
2.p 命令打印当前行(第一行)。
3.n 命令读取下一行(第二行),但不打印。
4.sed 继续读取文件的第三行。
5.p 命令打印当前行(第三行)。
6.n 命令读取下一行(第四行),但不打印。
重复步骤4-6,直到文件结束。
显示偶数行,则把两者调换位置即可,但需要注意两者都为命令,需要将其用分号隔开。
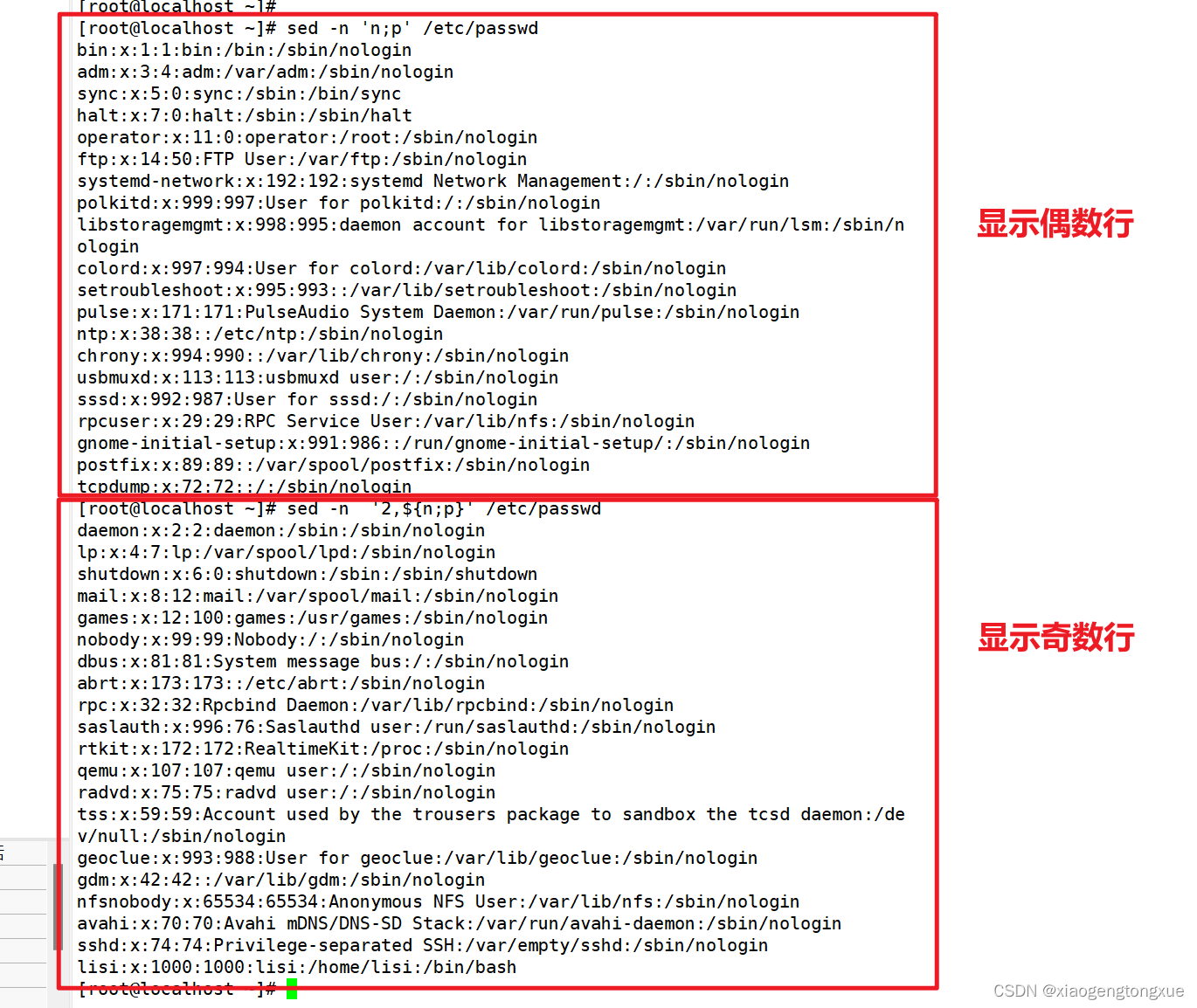
显示奇数行命令解释:
打印 /etc/passwd 文件中从第二行开始的偶数行,直到文件末尾。
‘2,${n;p}’: 是一个sed脚本,包含一个地址范围和两个命令:
2,$: 地址范围,表示从第二行开始到文件末尾。其中 $ 表示最后一行。
n: 读取下一行,但不打印。
p: 打印当前行。
显示奇数行命令执行过程:
1.sed 读取 /etc/passwd 的第一行,但不执行任何操作,因为地址范围从第二行开始。
2.sed 读取第二行。
3.n 命令读取下一行(第三行),但不打印。
4.p 命令打印当前行(第二行)。
5.sed 继续读取第四行。
6.n 命令读取下一行(第五行),但不打印。
7.p 命令打印当前行(第四行)。
8.重复步骤5-7,直到文件结束。
sed支持正则表达式
基本格式 ‘/表达式1/,/表达式2/p’ (不要忘记打印)p 文件名

匹配方式:
如果有多个复核条件的表达式,先开始找b开头一直找到f开头,然后再重新找b开头,一找到f开头,没有f开头就全显示,重复循环。
如果需要显示几点到几分之间的日志,即可用上述的方法。
示例:sed -n ‘/2018:08:09/,/2018:09:42:37/p’ access_log
奇偶数表示

-d选项 (删除)

将第三行删除
-i选项 用于备份,常常用于修改配置文件时,备份原本文件
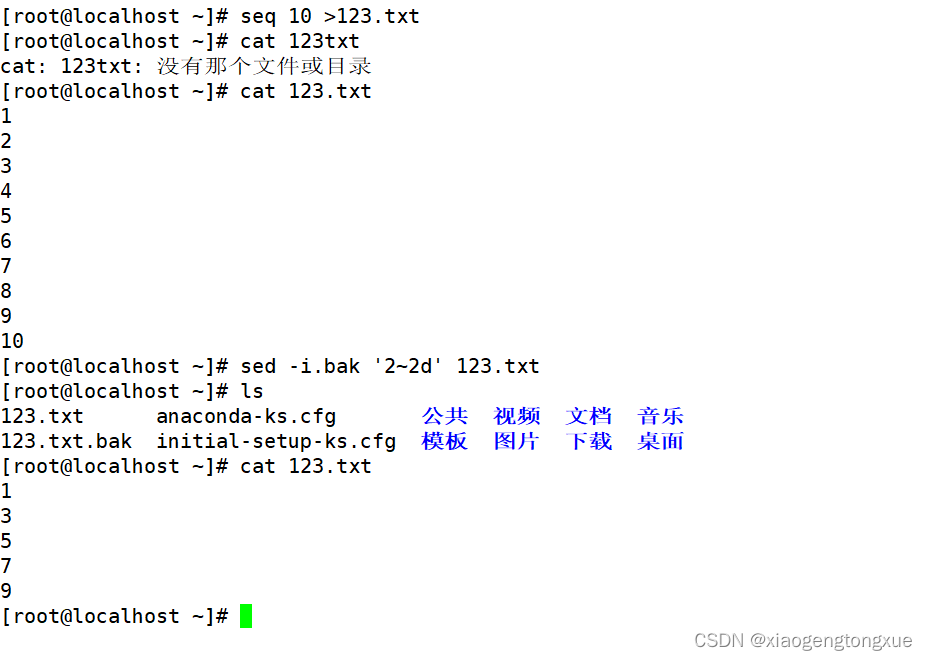
-a 追加

i 表示在第n行插入
c表示替换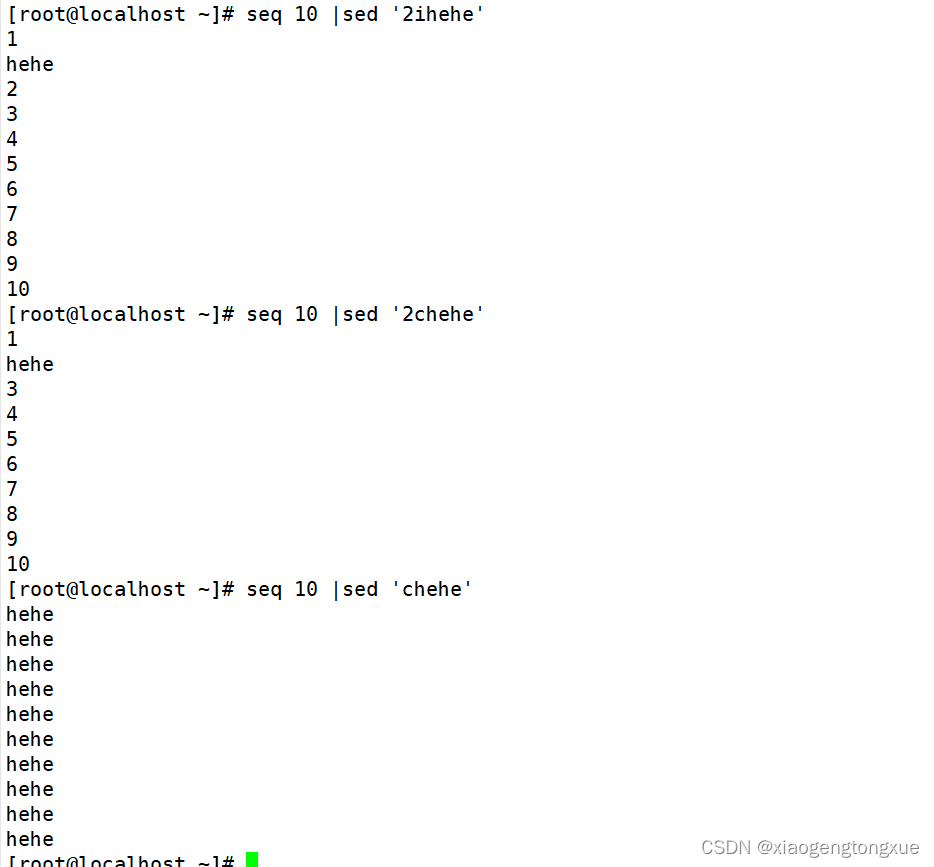
!取反
r后面跟文件名代表插入整个文件
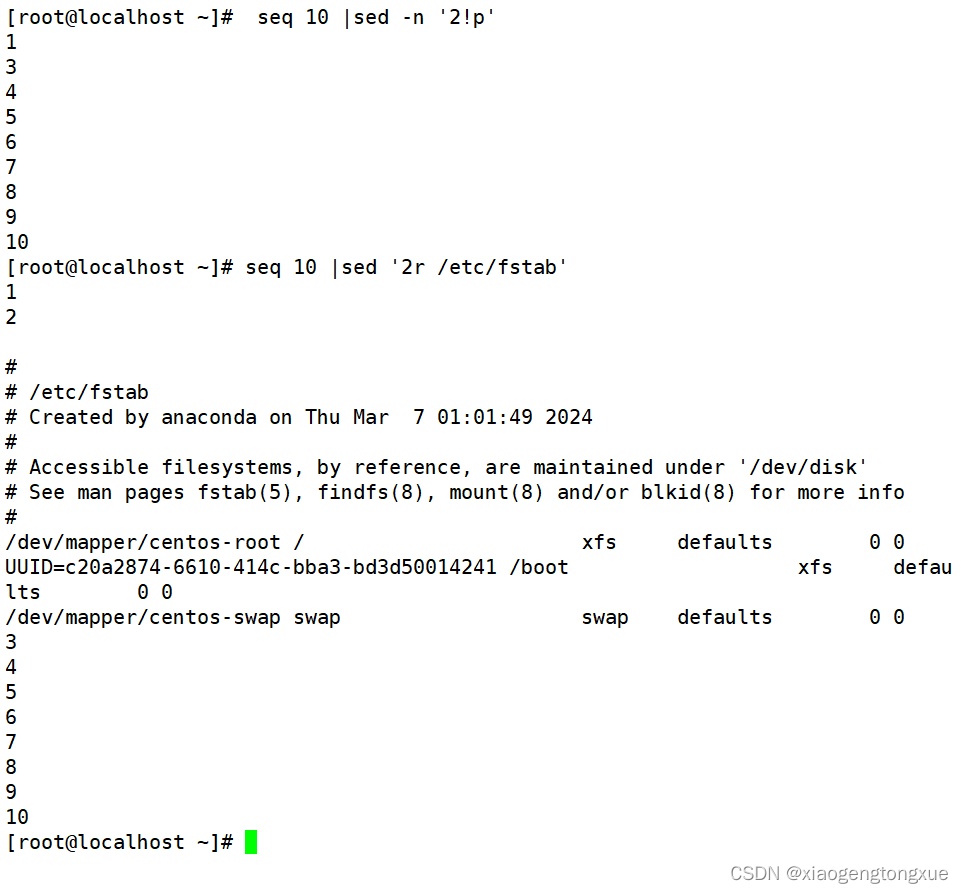
保存行至指定文件

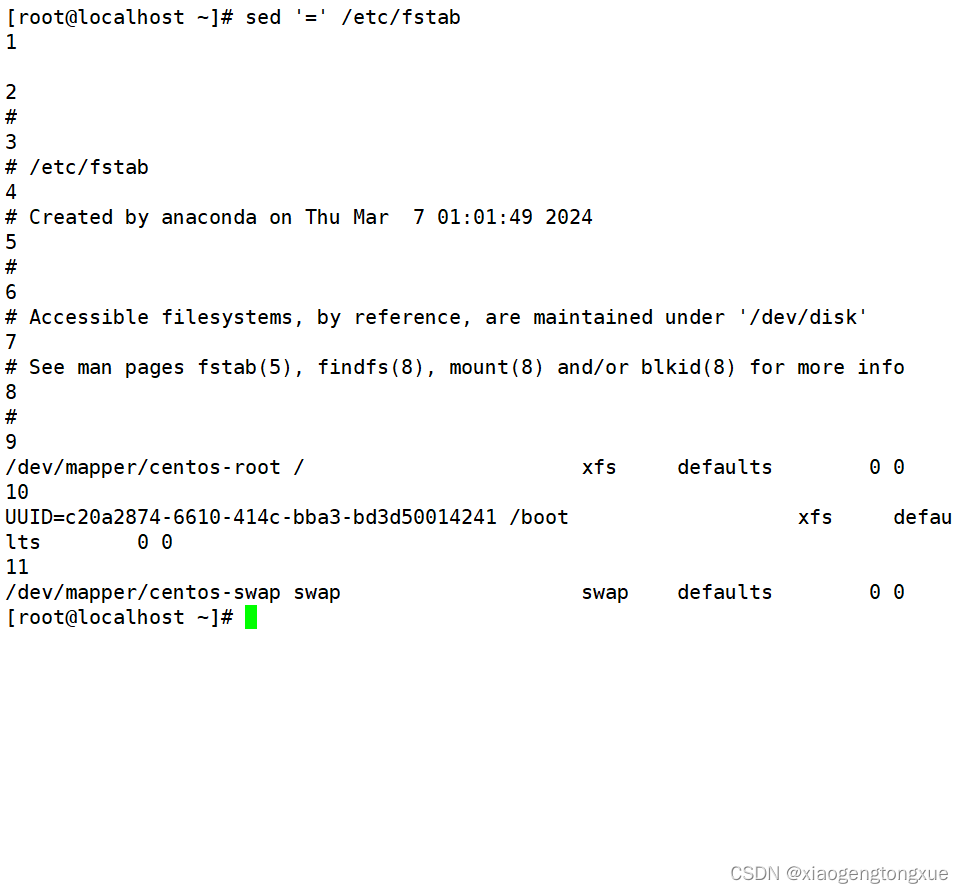
‘=’ 开启行号
搜索替代
s/pattern/string/修饰符
查找替换,支持使用其它分隔符,可以是其它形式:s@@@,s###
修饰符:
- g 行内全局替换
- p 显示替换成功的行
- w /PATH/FILE 将替换成功的行保存至文件中
- I,i 忽略大小写
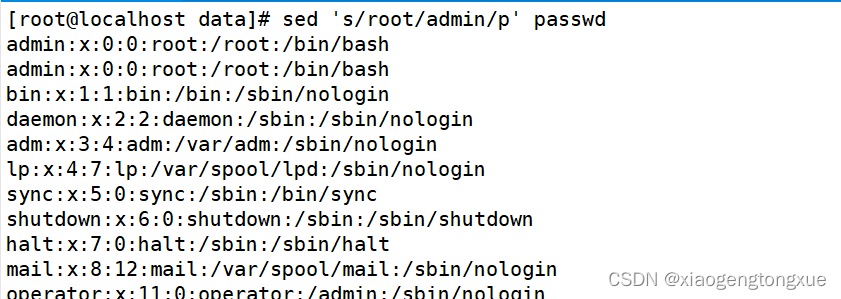
&可以只带之前的内容,在遇到正则表达式时很有用。
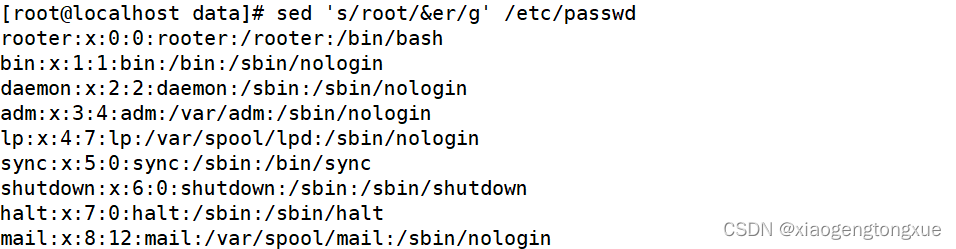
sed ‘s/r…t/&er/g’ /etc/passwd
用()代表分组 \1,\2代表留下的组
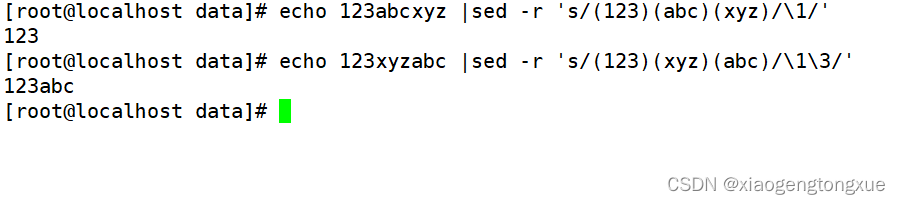
正则表达式 (123)(abc)(xyz) 匹配输入字符串,并将其分为三个捕获组:
第一个捕获组: “123”
第二个捕获组: “abc”
第三个捕获组: “xyz”
替换字符串 /\1/ 引用第一个捕获组的内容 “123”,并删除其他捕获组的内容。
示例:
1.提取IP地址
ifconfig ens33|sed -rn ‘2s/.inet ([0-9.]+) ./\1/p’
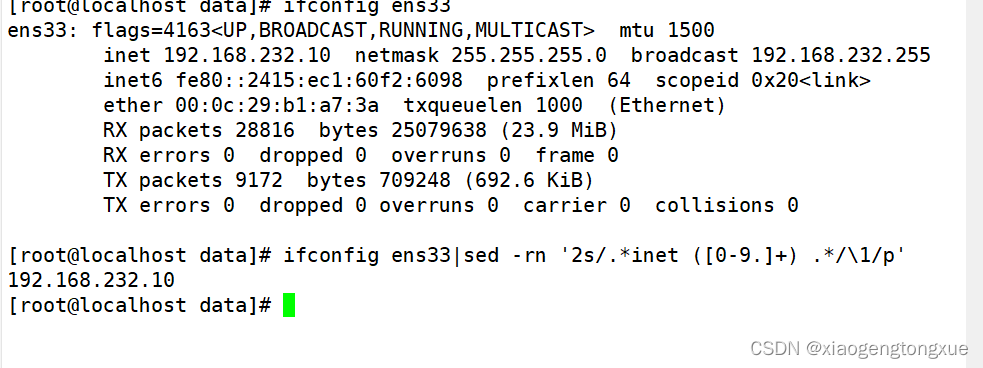
.*inet ([0-9.]+) .*: 正则表达式模式,用于匹配包含IP地址的行:
.*: 匹配任意字符,直到遇到 inet 关键字。
inet: 匹配字符串 “inet”。
([0-9.]+): 匹配IP地址,即由数字和点组成的字符串,并将其捕获到一个组中。
.*: 匹配IP地址后的任意字符,直到行尾。
2.删除部分路径
echo /etc/sysconfig/network-scripts/ifcfg-ens33 |sed -nr 's@^(.*)/([^/]+)@\2@p'
s@: 替换命令的语法开始标记,使用 @ 作为分隔符而不是默认的 /。
^(.)/([^/]+): 正则表达式模式,用括号将文件路径分为两个捕获组:
第一个捕获组 (.): 匹配路径部分,即从开头到最后一个 / 之前的所有字符。
第二个捕获组 ([^/]+): 匹配文件名部分,即最后一个 / 之后的所有字符,直到行尾。
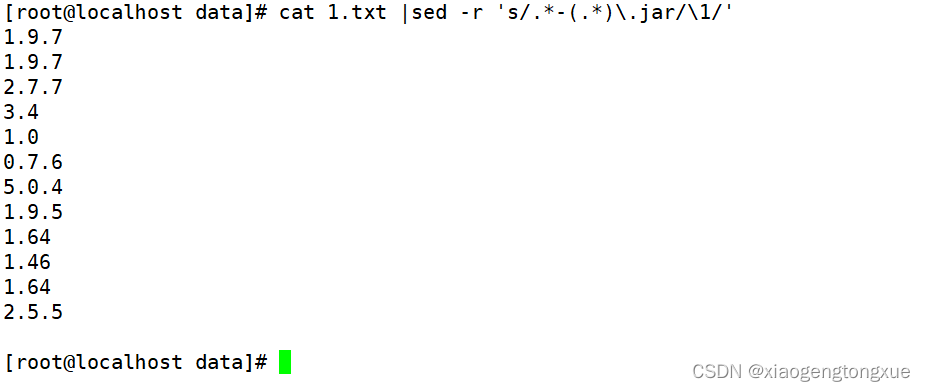
3.提取版本号
grep的方式

sed的方式