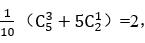目录
算法代码
原理
算法流程
xgb.train中的参数介绍
params
min_child_weight
gamma
技巧
算法代码
代码获取方式:链接:https://pan.baidu.com/s/1QV7nMC5ds5wSh-M9kuiwew?pwd=x48l
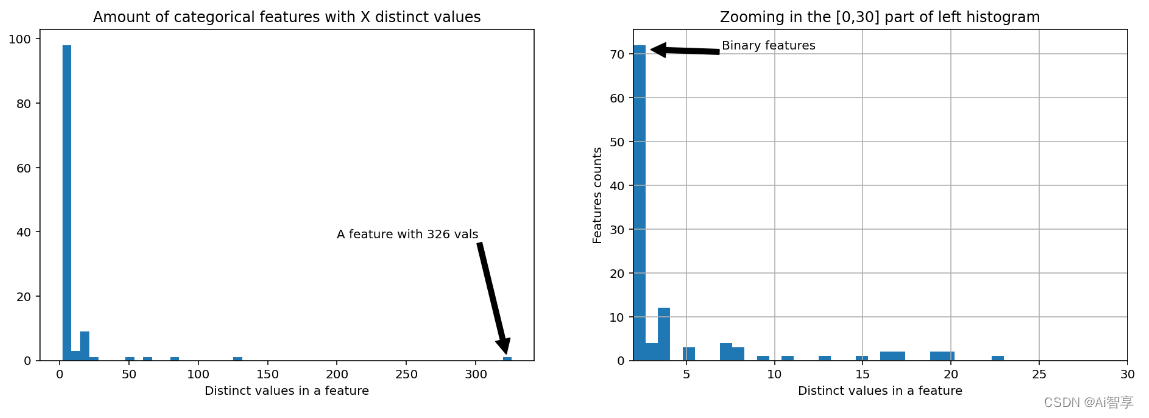
提取码:x48l特征直方图统计:
fig, (ax1, ax2) = plt.subplots(1,2) fig.set_size_inches(16,5) ax1.hist(uniq_values_in_categories.unique_values, bins=50)
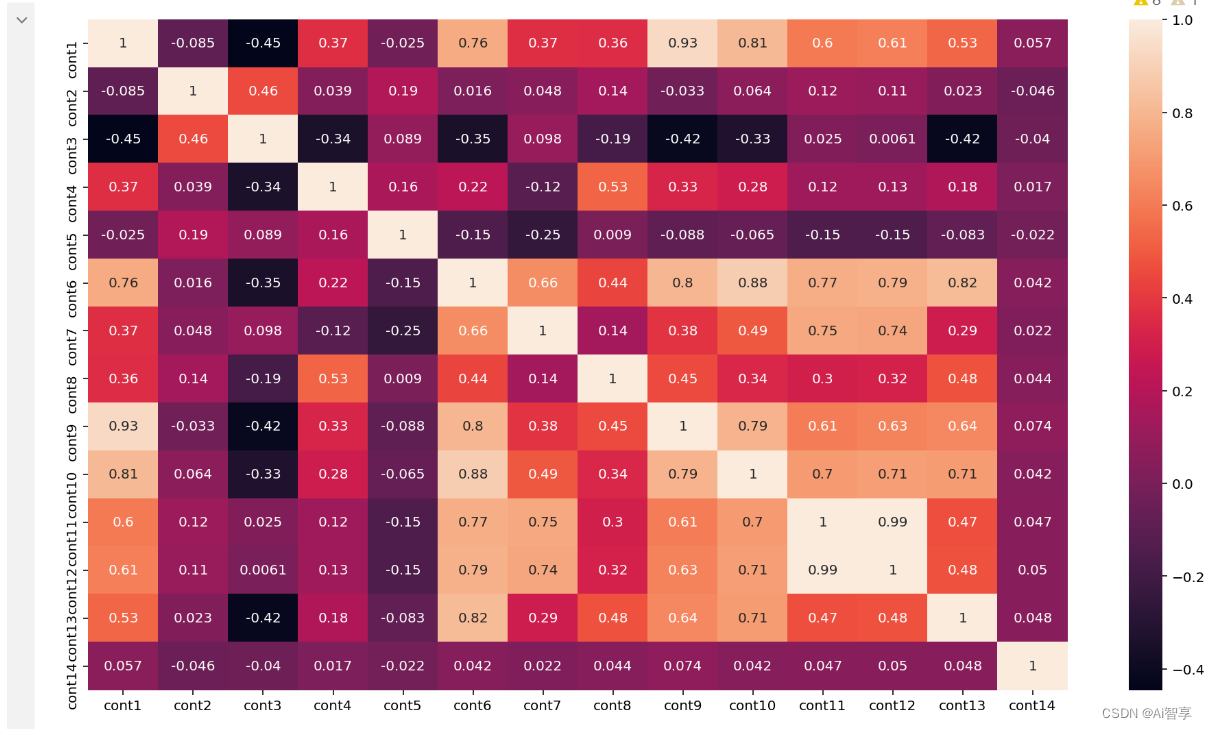
特征相关性分析
plt.subplots(figsize=(16,9)) correlation_mat = train[cont_features].corr() sns.heatmap(correlation_mat, annot=True)
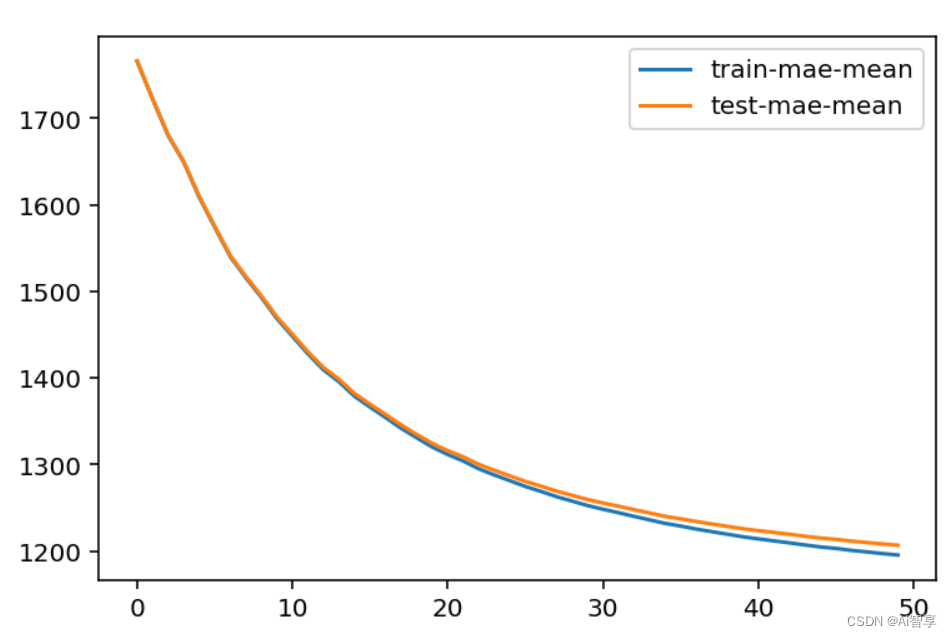
交叉验证调参
plt.figure() bst_cv1[['train-mae-mean', 'test-mae-mean']].plot()
交叉验证获取核心参数
mean_test_score = scores['mean_test_score'] std_test_score = scores['std_test_score'] params = scores['params']_params = [] _params_mae = [] for i in range(len(mean_test_score)):_params.append(params[i])_params_mae.append(mean_test_score[i]) params = np.array(_params) grid_res = np.column_stack((_params,_params_mae)) print(grid_res) print(grid_res.shape) return [grid_res[:,i] for i in range(grid_res.shape[1])]

原理
xgboost可以处理二分类、多分类、回归问题;
Extreme Gradient Boosting。XGBoost(Extreme Gradient Boosting)是一种基于决策树的集成学习算法,它在梯度提升(Gradient Boosting)框架下进行了改进和优化。其基本原理包括以下几个关键步骤:
集成学习
XGBoost采用集成学习的思想,通过结合多个弱学习器(通常是决策树)来构建一个强大的集成模型。每个弱学习器都是针对数据的不同部分进行训练,然后将它们组合起来形成最终的预测模型。
决策树的串行训练与集成
XGBoost通过串行训练决策树来构建集成模型。在每一轮训练中,新的决策树被设计为纠正前一轮模型的残差,以逐步减少训练误差。通过迭代添加树模型,XGBoost构建了一个更强大的整体模型。
正则化
XGBoost引入了正则化技术来控制模型的复杂度,防止过拟合。正则化项包括对树结构的惩罚,以及对叶子节点样本权重的约束,这有助于提高模型的泛化能力。
特征重要性评估
XGBoost提供了对特征重要性的评估,可以帮助用户了解哪些特征对模型的预测贡献最大。这有助于特征选择和模型解释。
高效的工程实现
XGBoost在算法和工程实现上都进行了优化,具有高效的训练速度和内存利用率,使其能够处理大规模数据集。
总的来说,XGBoost通过串行训练决策树、引入正则化和特征重要性评估等技术,构建了一种高效而强大的集成学习模型,适用于各种机器学习任务,特别是在结构化数据和表格数据上表现优异。
算法流程
XGBoost(eXtreme Gradient Boosting)是一种基于梯度提升树(Gradient Boosting Tree)的机器学习算法,它在提升树算法的基础上进行了优化和改进,以提高模型的性能和效率。以下是XGBoost算法的基本流程:
- 初始化模型参数:包括树的深度、学习率、树的数量等。
- 构建初始树:用一个简单的回归树或分类树作为初始模型。
- 迭代优化
1.计算损失函数的梯度:根据当前模型对训练数据的预测结果,计算损失函数的梯度。常用的损失函数包括平方损失函数(用于回归问题)和对数损失函数(用于分类问题)。
2.构建新树:基于损失函数的梯度,构建一棵新的回归树或分类树,该树的叶子节点数通常比较少。
3.更新模型:通过将新建的树与之前的模型相加,更新模型的预测结果。为了防止过拟合,通常会乘以一个小于1的学习率。
4.正则化:为了控制模型的复杂度和防止过拟合,可以引入正则化项,如树的深度限制、叶子节点权重的L1和L2正则化。
5. 迭代终止条件:可以设定迭代次数、达到一定的模型性能或损失下降率等作为终止条件。
6.输出最终模型:当满足终止条件时,输出最终的集成模型。
XGBoost通过优化目标函数的梯度提升树模型,采用了一些技术和策略,如加权损失函数、子采样、列抽样、树剪枝等,以提高模型的泛化能力和训练速度。
xgb.train中的参数介绍
xgb.train 函数是用于训练模型的主要函数之一。它允许你手动指定模型的各种参数,以定制化地训练 XGBoost 模型。
params
字典类型,表示要传递给 XGBoost 模型的参数。常见的参数包括:reg:linear 表示 XGBoost 将使用线性回归作为优化目标,即模型的输出是一个连续值,目标是最小化预测值与实际值之间的均方误差(MSE)或其他回归损失函数。
binary:logistic 是 XGBoost 中用于二分类问题的一种优化目标(objective)。使用逻辑回归(Logistic Regression)作为优化目标,用于解决二分类问题。
在二分类任务中目标是将样本分为两个类别,正类和负类。而binary:logistic 的作用是训练一个模型,使得对于给定的输入特征,模型能够输出一个概率值,表示样本属于正类的概率。然后设定一个阈值,将这个概率转换为类别标签,例如大于阈值则预测为正类,小于阈值则预测为负类。
使用 binary:logistic 作为优化目标时,模型的输出会通过逻辑函数(sigmoid 函数)转换为 0 到 1 之间的概率值,表示正类的概率。然后,模型会根据损失函数(通常是对数损失函数)来优化模型参数,以最大化预测的概率与实际标签的一致性。
multi:softmax多分类问题的一种优化目标(objective)设置。具体来说,multi:softmax 表示 XGBoost 将使用 Softmax 函数作为优化目标,用于多类别分类。Softmax 函数可以将模型的原始输出转换为每个类别的概率分布,使得概率之和为 1。在训练过程中,XGBoost 会优化模型参数,以最大化实际类别的概率与预测类别的概率之间的一致性。
XGBoost 将会训练一个多分类模型,该模型会尝试在给定数据集上学习出最佳的分类决策边界,以便能够将样本正确地分到多个类别中去。
对于回归任务(如 reg:linear),常用的评估指标包括均方误差(rmse)、平均绝对误差(mae)等。
对于二分类任务(如 binary:logistic),常用的评估指标包括准确率(error)、AUC(auc)等。
对于多分类任务(如 multi:softmax),常用的评估指标包括准确率(merror)、多分类对数损失(mlogloss)等。
min_child_weight
较大的 min_child_weight 值会导致更加保守的树模型,因为它限制了每个叶子节点的样本权重总和,使得树的生长更加受限制。相反,较小的 min_child_weight 值允许模型更多地考虑每个叶子节点的样本,可能导致模型过拟合。
注意:在决策树的训练过程中,每个样本都会被分配一个权重,这个权重可以用来调节样本对模型的贡献程度。
当训练一棵决策树时,XGBoost 会根据样本的权重来计算叶子节点的样本权重。这个过程涉及到样本在树的每个节点上的传递和累积,最终得到每个叶子节点所包含的样本的权重之和。
通过调节叶子节点的样本权重,我们可以控制模型对不同样本的关注程度,进而影响模型的泛化能力和性能。
选择合适的min_child_weight值通常需要通过交叉验证来进行调整。如果min_child_weight设置得太大,可能会导致模型欠拟合;如果设置得太小,可能会导致模型过拟合。
通过调节 subsample 参数,可以控制每棵树的训练样本的多少,从而影响模型的方差和泛化能力。较小的 subsample 值可以降低模型的方差,因为每棵树使用的样本更少,模型更加稳定,但可能会增加偏差。较大的 subsample 值可以提高模型的拟合能力,但可能导致过拟合。
通过调节 colsample_bytree 参数,可以控制每棵树使用的特征的数量,从而增加模型的多样性,减少过拟合的风险。较小的 colsample_bytree 值可以降低模型的方差,增加模型的泛化能力,但可能会增加模型的偏差。较大的 colsample_bytree 值可以提高模型的拟合能力,但也可能导致过拟合。
- dtrain: 训练数据集(DMatrix 格式),是 XGBoost 特有的数据结构,用于高效存储和处理大型数据集。
- evals: 需要评估的数据集列表,通常包括训练数据集和验证数据集。
- obj: 自定义目标函数(可选)。
- feval: 自定义评估函数(可选)。
- early_stopping_rounds: 当验证指标不再提升时,停止训练的迭代次数。
early_stopping_rounds 参数指定了在多少个迭代轮次内,如果模型的性能在验证集上没有改善,就停止训练。例如如果将 early_stopping_rounds 设置为 10,那么在训练过程中如果连续 10 个迭代轮次内模型的性能都没有提升,训练就会提前终止。
verbose_eval: 控制输出信息的频率。如果设置为一个非负整数,则表示每隔指定的迭代轮次输出一次训练信息。例如,如果 verbose_eval 设置为 100,那么每隔 100 个迭代轮次就会输出一次训练信息。
如果设置为 True,则表示在每个迭代轮次结束后都输出训练信息。
callbacks: 回调函数列表,用于在训练过程中执行自定义操作(如保存模型)。callbacks 参数可以用于指定回调函数,在训练过程中执行特定的操作。常见的用途包括提前停止训练、保存模型、记录训练过程中的指标等。
gamma
`gamma` 参数是一个用于控制模型复杂度的关键参数,它是在构建决策树时用来进行剪枝的。`gamma` 参数的值越大,模型就越保守,倾向于剪枝,这样可以避免过拟合。相反,`gamma` 参数的值越小,模型就越自由,可以生长更多的叶子节点,这可能会导致过拟合。
`gamma` 参数实际上代表了在添加一个新的分裂点时,所需的最小减少的损失。如果一个分裂点不能至少减少 `gamma` 这么多的损失,那么这个分裂点就会被忽略。因此,`gamma` 可以被视为一个正则化项,用于控制模型的复杂度。
在数学上,`gamma` 参数与树的叶子节点的数量和深度直接相关。较大的 `gamma` 值会导致生成较浅的树,因为需要更大的损失减少来创建新的分裂。较小的 `gamma` 值会导致生成较深的树,因为较小的损失减少就足够创建新的分裂。
在实际应用中,调整 `gamma` 参数可以帮助找到模型复杂度和性能之间的最佳平衡点。如果模型的性能在验证集上不佳,可能需要增加 `gamma` 值来减少过拟合。相反,如果模型在训练集上的性能不佳,可能需要减小 `gamma` 值来增加模型的复杂度。
`gamma` 被设置为 0,这意味着默认情况下不会有额外的剪枝。在实际应用中,你可能需要通过交叉验证等方法来调整 `gamma` 的值,以找到最佳的模型配置。
技巧
train.select_dtypes: 选择不同数据类型的特征;
偏度概念
scipy库中,stats.mstats.skew()函数用于计算数据的偏度(skewness)。偏度是描述数据分布不对称性的一个统计量,它是衡量数据分布相对于平均值的偏斜程度。
偏度的计算公式为:
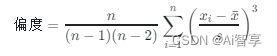
其中:
- ( n ) 是数据点的数量。
- ( x_i ) 是第 ( i ) 个数据点。
- ( bar{x} ) 是数据的平均值。
- ( s ) 是标准差。
- 如果偏度为正数,数据分布是右偏的,即数据点倾向于分布在平均值的右侧。
- 如果偏度为负数,数据分布是左偏的,即数据点倾向于分布在平均值的左侧。
- 如果偏度为零,数据分布是对称的,即数据点均匀分布在平均值两侧。
- 偏度值接近于零,表示数据分布比较对称。
- 偏度值远大于零或远小于零,表示数据分布非常偏斜。 在scipy.stats.mstats.skew()函数中,如果bias参数设置为True,则计算的是无偏估计量,即考虑了数据点的数量对偏度的影响。如果bias参数设置为False,则计算的是未调整偏度的原始估计量,这通常只在理论分析中使用。 例如,使用scipy.stats.mstats.skew()函数计算数据集的偏度:
连续数值特征与分类特征需要分开处理;
使用直方图可视化,统计频率分布;
corr()计算特征之间相关系数;并用sns.heatmap绘制热力图;
保险预测--回归问题;
在Python的pandas库中,astype('category') 方法将pandas的DataFrame或Series列转换为类别类型(categorical type)。这通常用于处理具有有限数量的不同值的列,例如性别、国家代码等。转换为类别类型可以节省内存,并且可以加快某些操作的处理速度。
使用 cat.codes 属性来获取每个类别值的数字编码。这些编码是整数,表示每个唯一类别在类别列表中的位置。例如,如果有一个包含三个不同国家的列,那么这些国家可能会被编码为0、1和2。
GridSearchCV(XGBoostRegressor): 交叉验证获取最佳参数,例如max_depth; min_child_weight;
一般交叉验证调参
Step 1: 选择一组初始参数
Step 2: 改变 max_depth 和 min_child_weight.
Step 3: 调节 gamma 降低模型过拟合风险.
Step 4: 调节 subsample 和 colsample_bytree 改变数据采样策略.
Step 5: 调节学习率 eta.(与数的深度反复调节)
ETA和num_boost_round依赖关系不是线性的,但是有些关联。