持续更新和补充中…多多交流!
参考:
图像评价指标PNSR和SSIM
函数 structural_similarity
图片相似度计算方法总结
MSE和PSNR
MSE:
M S E = 1 m n ∑ i = 0 m − 1 ∑ j = 0 n − 1 [ I ( i , j ) − K ( i , j ) ] 2 MSE=\frac{1}{mn}\sum_{i=0}^{m-1}\sum_{j=0}^{n-1}[I(i,j)-K(i,j)]^2 MSE=mn1i=0∑m−1j=0∑n−1[I(i,j)−K(i,j)]2
- M S E MSE MSE:均方误差(Mean Squared Error),用于衡量两幅图像之间的差异,MSE越小表示两幅图像越相似。
- m m m:图像的行数或高度。
- n n n:图像的列数或宽度。
- I ( i , j ) I(i,j) I(i,j):原始图像的像素值,表示在位置 ( i , j ) (i,j) (i,j)处的像素值。
- K ( i , j ) K(i,j) K(i,j):处理后的图像的像素值,表示在位置 ( i , j ) (i,j) (i,j)处的像素值。
import torchdef calculate_mse(original_img, enhanced_img):# 将图像转换为 PyTorch 的 Tensororiginal_img_tensor = torch.tensor(original_img, dtype=torch.float32)enhanced_img_tensor = torch.tensor(enhanced_img, dtype=torch.float32)# 计算像素值之差的平方diff = original_img_tensor - enhanced_img_tensorsquared_diff = torch.square(diff)# 计算均方误差mse = torch.mean(squared_diff)return mse.item() # 返回均方误差的值# 示例用法
original_img = [0.1, 0.2, 0.3, 0.4] # 原始图像像素值
enhanced_img = [0.15, 0.25, 0.35, 0.45] # 处理后图像像素值mse_value = calculate_mse(original_img, enhanced_img)
print("MSE 值为:", mse_value)
PSNR基于MSE进行计算:
P S N R = 10 ⋅ l o g 10 ( M A X I 2 M S E ) \begin{aligned} PSNR=10\cdot log_{10}(\frac{MAX_{I}^{2}}{MSE}) \end{aligned} PSNR=10⋅log10(MSEMAXI2)
- MAX表示像素灰度级的最大值,如果一个像素值由B位来表示,则 M A X I = 2 B − 1 MAX_I=2^B-1 MAXI=2B−1.
- MSE表示均方误差
- 如果是彩色图像,一般有三种方法
- 分别计算 RGB 三个通道的 PSNR,然后取平均值。
- 计算 RGB 三通道的 MSE ,然后再除以 3。
- 将图片转化为 YCbCr 格式,然后只计算 Y分量也就是亮度分量的 PSNR。
import numpy as npdef calculate_mse(original_img, enhanced_img):mse = np.mean((original_img - enhanced_img) ** 2)return mseMAX = 255 # 最大灰度级
original_img = np.array([[1, 2, 3], [4, 5, 6]]) # 原始图像
enhanced_img = np.array([[3, 4, 5], [6, 7, 8]]) # 处理后的图像mse = calculate_mse(original_img, enhanced_img)
psnr = 10 * np.log10(MAX**2 / mse)
print("MSE:", mse)
print("PSNR:", psnr)
SSIM-结构相似性
SSIM(structural similarity)结构相似性,也是一种全参考的图像质量评价指标,它分别从亮度、对比度、结构三方面度量图像相似性。
S S I M ( x , y ) = [ l ( x , y ) α ⋅ c ( x , y ) β ⋅ s ( x , y ) γ ] SSIM(x,y)=[l(x,y)^\alpha\cdot c(x,y)^\beta\cdot s(x,y)^\gamma] SSIM(x,y)=[l(x,y)α⋅c(x,y)β⋅s(x,y)γ]
-
l ( x , y ) = 2 μ x μ y + C 1 μ x 2 + μ y 2 + C 1 l(x, y) = \frac{2\mu_x\mu_y + C_1}{\mu_x^2 + \mu_y^2 + C_1} l(x,y)=μx2+μy2+C12μxμy+C1是亮度相似度,
- μ x \mu_x μx和 μ y \mu_y μy分别是图像 x x x和 y y y的均值
- C 1 = ( K 1 L ) 2 C_1=(K_1L)^2 C1=(K1L)2 是平滑度常数,k1=0.01为默认值
-
c ( x , y ) = 2 σ x σ y + C 2 σ x 2 + σ y 2 + C 2 c(x, y) = \frac{2\sigma_x\sigma_y + C_2}{\sigma_x^2 + \sigma_y^2 + C_2} c(x,y)=σx2+σy2+C22σxσy+C2是对比度相似度
- σ x \sigma_x σx 和 σ y \sigma_y σy分别是图像 x x x和 y y y 的标准差
- C 2 ( K 2 L ) 2 C_2(K_2L)^2 C2(K2L)2 是对比度常数,k2=0.03为默认值
-
s ( x , y ) = σ x y + C 3 σ x σ y + C 3 s(x, y) = \frac{\sigma_{xy} + C_3}{\sigma_x\sigma_y + C_3} s(x,y)=σxσy+C3σxy+C3是结构相似度,
- σ x y \sigma_{xy} σxy是 x x x和 y y y的协方差
- C 3 C_3 C3是结构常数,常取 C 2 / 2 C_2/2 C2/2
公式中的 α , β , γ \alpha, \beta, \gamma α,β,γ是权重参数,用于控制每个相似度项的影响力。通常情况下,它们的值是 α = β = γ = 1 \alpha = \beta = \gamma = 1 α=β=γ=1。
代码: https://github.com/jorge-pessoa/pytorch-msssim
#针对𝛼,𝛽,𝛾都为1的情况
import torch
import torch.nn.functional as F
from math import exp
import numpy as np# 计算一维的高斯分布向量
def gaussian(window_size, sigma):gauss = torch.Tensor([exp(-(x - window_size//2)**2/float(2*sigma**2)) for x in range(window_size)])return gauss/gauss.sum()# 创建高斯核,通过两个一维高斯分布向量进行矩阵乘法得到
# 可以设定channel参数拓展为3通道
def create_window(window_size, channel=1):_1D_window = gaussian(window_size, 1.5).unsqueeze(1)_2D_window = _1D_window.mm(_1D_window.t()).float().unsqueeze(0).unsqueeze(0)window = _2D_window.expand(channel, 1, window_size, window_size).contiguous()return window# 计算SSIM
# 直接使用SSIM的公式,但是在计算均值时,不是直接求像素平均值,而是采用归一化的高斯核卷积来代替。
# 在计算方差和协方差时用到了公式Var(X)=E[X^2]-E[X]^2, cov(X,Y)=E[XY]-E[X]E[Y].
# 正如前面提到的,上面求期望的操作采用高斯核卷积代替。
def ssim(img1, img2, window_size=11, window=None, size_average=True, full=False, val_range=None):# Value range can be different from 255. Other common ranges are 1 (sigmoid) and 2 (tanh).if val_range is None:if torch.max(img1) > 128:max_val = 255else:max_val = 1if torch.min(img1) < -0.5:min_val = -1else:min_val = 0L = max_val - min_valelse:L = val_rangepadd = 0(_, channel, height, width) = img1.size()if window is None:real_size = min(window_size, height, width)window = create_window(real_size, channel=channel).to(img1.device)mu1 = F.conv2d(img1, window, padding=padd, groups=channel)mu2 = F.conv2d(img2, window, padding=padd, groups=channel)mu1_sq = mu1.pow(2)mu2_sq = mu2.pow(2)mu1_mu2 = mu1 * mu2sigma1_sq = F.conv2d(img1 * img1, window, padding=padd, groups=channel) - mu1_sqsigma2_sq = F.conv2d(img2 * img2, window, padding=padd, groups=channel) - mu2_sqsigma12 = F.conv2d(img1 * img2, window, padding=padd, groups=channel) - mu1_mu2C1 = (0.01 * L) ** 2C2 = (0.03 * L) ** 2v1 = 2.0 * sigma12 + C2v2 = sigma1_sq + sigma2_sq + C2cs = torch.mean(v1 / v2) # contrast sensitivityssim_map = ((2 * mu1_mu2 + C1) * v1) / ((mu1_sq + mu2_sq + C1) * v2)if size_average:ret = ssim_map.mean()else:ret = ssim_map.mean(1).mean(1).mean(1)if full:return ret, csreturn ret# Classes to re-use window
class SSIM(torch.nn.Module):def __init__(self, window_size=11, size_average=True, val_range=None):super(SSIM, self).__init__()self.window_size = window_sizeself.size_average = size_averageself.val_range = val_range# Assume 1 channel for SSIMself.channel = 1self.window = create_window(window_size)def forward(self, img1, img2):(_, channel, _, _) = img1.size()if channel == self.channel and self.window.dtype == img1.dtype:window = self.windowelse:window = create_window(self.window_size, channel).to(img1.device).type(img1.dtype)self.window = windowself.channel = channelreturn ssim(img1, img2, window=window, window_size=self.window_size, size_average=self.size_average)还可以利用函数 structural_similarity
from skimage.metrics import structural_similarity as ssim
import numpy as np# 创建两个示例图像
im1 = np.random.rand(256, 256)
im2 = np.random.rand(256, 256)# 计算 SSIM,并使用一些可选参数
ssim_index, ssim_image = ssim(im1, im2,win_size=11,gradient=True,data_range=1.0,multichannel=False,gaussian_weights=True,full=True)print(f"SSIM Index: {ssim_index}")
print(f"SSIM Image: \n{ssim_image}")
'''
def structural_similarity(*, im1, im2,win_size=None, gradient=False, data_range=None,multichannel=False, gaussian_weights=False,full=False, **kwargs)
'''| 参数名 | 类型及说明 |
|---|---|
im1, im2 | Ndarray,输入图像 |
win_size | int or none, optional,滑动窗口的边长,必须为奇数,默认值为7。当 gaussian_weights=True 时,滑动窗口的大小取决于 sigma |
gradient | bool, optional,若为 True,返回相对于 im2 的梯度 |
data_range | float, optional,图像灰度级数,图像灰度的最小值和最大可能值,默认情况下根据图像的数据类型进行估计 |
multichannel | bool, optional,值为 True 时将 img.shape[-1] 视为图像通道数,对每个通道单独计算,取平均值作为相似度 |
gaussian_weights | bool, optional,高斯权重,值为 True 时,平均值和方差在空间上的权重为归一化高斯核,宽度 sigma=1.5 |
use_sample_covariance | bool若为True,则通过N-1归一化协方差,N是滑动窗口内的像素数 |
| 其它参数 | 说明 |
|---|---|
K1,K2 | loat, 算法参数,默认值K1=0.01,K2=0.03 |
sigma | float,当gaussian_weights=True时,决定滑动窗口大小 |
full | bool, optional,值为 true 时,返回完整的结构相似性图像 |
| 返回值 | 说明 |
|---|---|
mssim | 平均结构相似度 |
grad | 结构相似性梯度 (gradient=True) |
S | 结构相似性图像(full=True) |
FIDFrechlet Inception Distance(FID)
FID是基于Inception-V3模型(预训练好的图像分类模型)的feature vectors来计算真实图片与生成图片之间的距离,用高斯分布来表示,FID就是计算两个分布之间的Wasserstein-2距离。将真实图片和预测图片分别经过Inception模型中,得到2048维度(特征的维度)的embedding vector。把生成和真实的图片同时放入Inception-V3中,然后将feature vectors取出来用于比较。
d 2 = ∣ ∣ μ 1 − μ 2 ∣ ∣ 2 + T r ( C 1 + C 2 − 2 ∗ ( C 1 ∗ C 2 ) ) d^2 = ||\mu_1 -\mu_2||^2 + Tr(C_1 + C_2 - 2*\sqrt{(C_1 *C_2)}) d2=∣∣μ1−μ2∣∣2+Tr(C1+C2−2∗(C1∗C2))
- μ 1 , μ 2 μ_1,μ_2 μ1,μ2为均值, C 1 , C 2 C_1,C_2 C1,C2为协方差, T r Tr Tr为矩阵的迹
- FID越低,说明预测分布越接近于真实的分布
- 可以评估类内多样性,例如每个类别只产生一张一模一样的照片,FID会比较高,也就意味着评估效果比较差
import numpy as np
from scipy.linalg import sqrtmdef calculate_fid(act1, act2):# 计算均值和协方差统计量mu1, sigma1 = act1.mean(axis=0), np.cov(act1, rowvar=False)mu2, sigma2 = act2.mean(axis=0), np.cov(act2, rowvar=False)# 计算均值之间的平方差之和ssdiff = np.sum((mu1 - mu2)**2.0)# 计算协方差之积的平方根covmean = sqrtm(sigma1.dot(sigma2))# 检查从sqrtm中移除的复数部分if np.iscomplexobj(covmean):covmean = covmean.real# 计算 FID 分数fid = ssdiff + np.trace(sigma1 + sigma2 - 2.0 * covmean)return fid# 示例用法
act1 = np.random.rand(100, 10) # 隐变量 act1
act2 = np.random.rand(100, 10) # 隐变量 act2fid_score = calculate_fid(act1, act2)
print("FID 分数为:", fid_score)
Inception score
Inception Score基于Inception-V3模型的分类概率来评估生成照片的质量,通过使用预训练的卷积神经网络(通常是Inception网络)来评估生成图像的质量和多样性。
K L d i v e r g e n c e = p ( y ∣ x ) ∗ ( l o g ( p ( y ∣ x ) ) − l o g ( p ( y ) ) ) \mathrm{KL~divergence=p(y|x)*(log(p(y|x))-log(p(y)))} KL divergence=p(y∣x)∗(log(p(y∣x))−log(p(y)))
- p ( y ∣ x ) p(y|x) p(y∣x):表示在给定条件 𝑥下,观测到的概率 𝑦
- p ( y ) p(y) p(y) 表示概率 𝑦的边际概率
- 对KL散度对所有类别求和再取平均值,并且取一个e指数,即可得到Inception Score。一般生成5000张照片S的值在0~1000范围内。
- 希望 p ( y ∣ x ) p(y|x) p(y∣x)应该具有低熵(即越真实),p(y)应该具有高熵即越多样,因此,IS值越大越好
- 缺点:缺乏跟真实照片之间的比较;缺乏类内多样性,例如每个类别只产生一张一模一样的照片,IS一样很高
import numpy as npdef calculate_inception_score(p_yx, eps=1E-16):# 计算 p(y):所有样本的平均值p_y = np.expand_dims(p_yx.mean(axis=0), 0)# 计算每个图像的 KL 散度kl_d = p_yx * (np.log(p_yx + eps) - np.log(p_y + eps))# 对类别求和sum_kl_d = kl_d.sum(axis=1)# 对所有图像的 KL 散度取平均值avg_kl_d = np.mean(sum_kl_d)# 撤销对数运算is_score = np.exp(avg_kl_d)return is_score# 示例用法
p_yx = np.random.rand(100, 10) # 概率分布 p(y|x)is_score = calculate_inception_score(p_yx)
print("Inception Score 值为:", is_score)
LPIPS
论文:
The Unreasonable Effectiveness of Deep Features as a Perceptual Metric
代码:
LPIPS代码实现-Pytorch
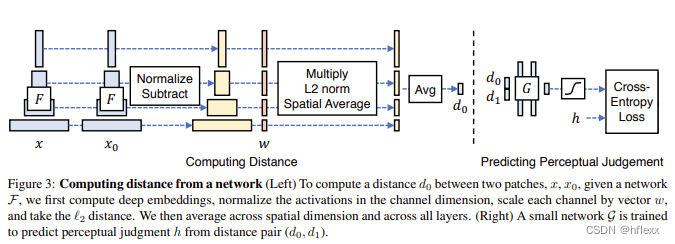
LPIPS:学习感知图像块相似度(Learned Perceptual Image Patch Similarity, LPIPS)也称为“感知损失”(perceptual loss),用于度量两张图像之间的差别,LPIPS 测量风格化图像和相应内容图像之间的内容保真度。它通过比较图像块的深层特征来工作,这些特征能够捕捉到人类视觉系统中对图像质量的感知。LPIPS的值越低表示两张图像越相似,反之,则差异越大。
步骤:从 l l l层提取特征堆(feature stack)并在通道维度中进行单位规格化(unit-normalize)。利用向量 W l W_l Wl来放缩激活通道数,最终计算 L 2 L_2 L2距离。 最后在空间上平均,在通道上求和。 d ( x , x 0 ) = ∑ l 1 H l W l ∑ h , w ∣ ∣ w l ⊙ ( y ^ h w l − y ^ 0 h w l ) ∣ ∣ 2 2 d(x,x_0)=\sum_l\frac1{H_lW_l}\sum_{h,w}||w_l\odot(\hat{y}_{hw}^l-\hat{y}_{0hw}^l)||_2^2 d(x,x0)=l∑HlWl1h,w∑∣∣wl⊙(y^hwl−y^0hwl)∣∣22
-
d ( x , x 0 ) d(x, x_0) d(x,x0):表示图像块 x x x 和 x 0 x_0 x0 之间的感知距离,即它们在感知上的差异度量。
-
l l l:表示特征堆中的层(layer)索引,用于指代不同的深度特征表示。
-
H l , W l H_l,W_l Hl,Wl:表示特征堆中第 l l l 层的高度(height)和宽度(width)。
-
h , w h, w h,w:分别表示特征堆中第 l l l 层的高度和宽度索引,用于遍历特征图中的每个位置。
-
w l w_l wl:表示用于缩放特征通道的权重向量,对应于特征堆中第 l l l 层的通道数。
-
y ^ h w l \hat{y}_{hw}^l y^hwl:表示特征堆中第 l l l 层的特征表示的一个元素,对应于在位置 ( h , w ) (h, w) (h,w) 处的特征向量。
-
y ^ 0 h w l \hat{y}_{0hw}^l y^0hwl:表示特征堆中第 l l l 层的参考特征表示的一个元素,对应于在位置 ( h , w ) (h, w) (h,w) 处的参考特征向量。
import torch
import lpips use_gpu = False
spatial = True #返回感知距离的空间地图# 创建线性校准的 LPIPS 模型
loss_fn = lpips.LPIPS(net='alex', spatial=spatial) # 使用 AlexNet 架构创建 LPIPS 模型
# loss_fn = lpips.LPIPS(net='alex', spatial=spatial, lpips=False) # 使用不同网络配置的 LPIPS 模型if use_gpu:loss_fn.cuda() # 如果 use_gpu 为 True,则将 LPIPS 模型移动到 GPU 上# 示例中使用虚拟张量
root_path = r'D:\Project\results\faces' # 存储图像的根路径
img0_path_list = [] # 存储文件名中包含 '_generated' 的图像路径列表
img1_path_list = [] # 存储文件名中包含 '_real' 的图像路径列表# 循环遍历图像路径(代码已注释,不会执行)
for root, _, fnames in sorted(os.walk(root_path, followlinks=True)):for fname in fnames:path = os.path.join(root, fname)if '_generated' in fname:img0_path_list.append(path)elif '_real' in fname:img1_path_list.append(path)distances = [] # 存储计算得到的图像对之间的感知距离
for i in range(len(img0_path_list)):dummy_img0 = lpips.im2tensor(lpips.load_image(img0_path_list[i])) # 加载并将图像转换为张量dummy_img1 = lpips.im2tensor(lpips.load_image(img1_path_list[i])) # 加载并将图像转换为张量if use_gpu:dummy_img0 = dummy_img0.cuda() # 将图像张量移动到 GPUdummy_img1 = dummy_img1.cuda() # 将图像张量移动到 GPUdist = loss_fn.forward(dummy_img0, dummy_img1) # 计算图像对之间的感知距离distances.append(dist.mean().item()) # 将平均距离添加到 distances 列表中print('Average Distances: %.3f' % (sum(distances) / len(img0_path_list))) # 打印平均感知距离
CSFD
代码:https://github.com/jiwoogit/StyleID
论文:https://jiwoogit.github.io/StyleID_site/
Content Feature Structural Distance-CFSD内容特征结构距离。在风格迁移评估中,内容保真度通常依赖于LPIPS距离,该指标使用了在ImageNet数据集上预训练的AlexNet模型的特征空间,这使得LPIPS对纹理有偏见。图像的风格信息可能会影响LPIPS分数,因为它偏向于纹理特征。为了减少风格信息对评估的影响,作者引入了CFSD,这是一种只考虑图像块之间空间相关性的新距离度量。
CFSD的计算步骤:
- 获取特征图:对于给定图像 I I I,首先获取特征图 F ∈ R h × w × c F \in \mathbb{R}^{h \times w \times c} F∈Rh×w×c,这是VGG19网络中conv3层的输出特征。
- 计算相似性矩阵:计算特征图 F F F中每对特征之间的相似性,得到相似性矩阵 M = F × F T M = F \times F^T M=F×FT,其中 M ∈ R h × w × h × w M \in \mathbb{R}^{h \times w \times h \times w} M∈Rh×w×h×w。
- 应用softmax操作:对相似性矩阵 M M M 的每个元素应用softmax操作,将其建模为概率分布,得到相关性矩阵 S = [ softmax ( M i ) ] h × w i = 1 S = [\text{softmax}(M_i)]_{h \times w}^{i=1} S=[softmax(Mi)]h×wi=1,其中 M i ∈ R 1 × h × w M_i \in \mathbb{R}^{1 \times h \times w} Mi∈R1×h×w 是第 i i i 个图像块与其他块的相似性。
- 计算KL散度:CFSD定义为两个相关性矩阵之间的Kullback-Leibler散度(KL-divergence)。
CFSD公式:
C F S D = 1 h w ∑ i = 1 h w D K L ( S i c ∣ ∣ S i c s ) , \mathrm{CFSD}=\frac{1}{hw}\sum_{i=1}^{hw}D_{\mathrm{KL}}(S_{i}^{c}||S_{i}^{cs}), CFSD=hw1i=1∑hwDKL(Sic∣∣Sics),
- S i c S_{i}^{c} Sic:内容图像对应的相关性矩阵的第i个元素,这些矩阵是通过计算图像特征图(例如,VGG19网络的conv3层输出)中每对特征之间的相似性得到的。
- S i c s S_{i}^{cs} Sics:风格图像对应的相关性矩阵的第i个元素
- D K L D_{KL} DKL:KL散度
#StyleID\evaluation\eval_artfid.py
def compute_patch_simi(path_to_stylized, path_to_content, batch_size, device, num_workers=1):"""Computes the distance for the given paths.Args:path_to_stylized (str): Path to the stylized images.path_to_style (str): Path to the style images. [注:这里应该为 path_to_content,修正为 path_to_content]batch_size (int): Batch size for computing activations.content_metric (str): Metric to use for content distance. Choices: 'lpips', 'vgg', 'alexnet' [注:缺少 content_metric 参数]device (str): Device for computing activations.num_workers (int): Number of threads for data loading.Returns:(float) FID value. [注:文档中写的是 FID value,但函数名为 compute_patch_simi,可能存在混淆,需要核对和确认]"""device = torch.device('cuda') if device == 'cuda' and torch.cuda.is_available() else torch.device('cpu')# 根据路径获取图像路径并排序以匹配样式化图像与对应的内容图像stylized_image_paths = get_image_paths(path_to_stylized, sort=True)content_image_paths = get_image_paths(path_to_content, sort=True)# 确保样式化图像和内容图像数量相等assert len(stylized_image_paths) == len(content_image_paths), 'Number of stylized images and number of content images must be equal.'# 定义图像转换方法style_transforms = ToTensor()# 创建样式化图像的数据集和数据加载器dataset_stylized = ImagePathDataset(stylized_image_paths, transforms=style_transforms)dataloader_stylized = torch.utils.data.DataLoader(dataset_stylized,batch_size=batch_size,shuffle=False,drop_last=False,num_workers=num_workers)# 创建内容图像的数据集和数据加载器dataset_content = ImagePathDataset(content_image_paths, transforms=style_transforms)dataloader_content = torch.utils.data.DataLoader(dataset_content,batch_size=batch_size,shuffle=False,drop_last=False,num_workers=num_workers)# 初始化用于计算距离的度量类metric = image_metrics.PatchSimi(device=device).to(device)dist_sum = 0.0N = 0pbar = tqdm(total=len(stylized_image_paths))# 遍历样式化图像和内容图像的批次for batch_stylized, batch_content in zip(dataloader_stylized, dataloader_content):# 在不计算梯度的上下文中进行操作,节省内存和计算资源with torch.no_grad():# 计算当前批次的距离batch_dist = metric(batch_stylized.to(device), batch_content.to(device))N += batch_stylized.shape[0]dist_sum += torch.sum(batch_dist)pbar.update(batch_stylized.shape[0])pbar.close()return dist_sum / Ndef compute_cfsd(path_to_stylized, path_to_content, batch_size, device, num_workers=1):"""Computes CFSD for the given paths.Args:path_to_stylized (str): Path to the stylized images.path_to_content (str): Path to the content images.batch_size (int): Batch size for computing activations.device (str): Device for computing activations.num_workers (int): Number of threads for data loading.Returns:(float) CFSD value."""print('Compute CFSD value...')# 计算 Patch Similarity,该函数返回样式化图像和内容图像的距离值simi_val = compute_patch_simi(path_to_stylized, path_to_content, 1, device, num_workers)# 将距离值保留四位小数simi_dist = f'{simi_val.item():.4f}'return simi_dist#evaluation\image_metrics.py
class PatchSimi(nn.Module):def __init__(self, device=None):# 初始化函数super(PatchSimi, self).__init__()# 加载预训练的 VGG19 模型,并移到指定设备上进行评估self.model = models.vgg19(pretrained=True).features.to(device).eval()# 指定层名称和替换名称的映射self.layers = {"11": "conv3"}# 图像归一化的均值和标准差self.norm_mean = (0.485, 0.456, 0.406)self.norm_std = (0.229, 0.224, 0.225)# KL 散度损失函数self.kld = torch.nn.KLDivLoss(reduction='batchmean')self.device = devicedef get_feats(self, img):features = []# 遍历 VGG19 模型的各层并提取特征for name, layer in self.model._modules.items():img = layer(img)if name in self.layers:features.append(img)return featuresdef normalize(self, input):# 图像归一化处理return transforms.functional.normalize(input, self.norm_mean, self.norm_std)def patch_simi_cnt(self, input):b, c, h, w = input.size()# 转置和重塑特征input = torch.transpose(input, 1, 3)features = input.reshape(b, h*w, c).div(c)feature_t = torch.transpose(features, 1, 2)# 计算内容图像的特征相似度patch_simi = F.log_softmax(torch.bmm(features, feature_t), dim=-1)return patch_simi.reshape(b, -1)def patch_simi_out(self, input):b, c, h, w = input.size()# 转置和重塑特征input = torch.transpose(input, 1, 3)features = input.reshape(b, h*w, c).div(c)feature_t = torch.transpose(features, 1, 2)# 计算样式化图像的特征相似度patch_simi = F.softmax(torch.bmm(features, feature_t), dim=-1)return patch_simi.reshape(b, -1)def forward(self, input, target):src_feats = self.get_feats(self.normalize(input))target_feats = self.get_feats(self.normalize(target))init_loss = 0.# 计算各层的 KL 散度并求和作为初始损失值for idx in range(len(src_feats)):init_loss += F.kl_div(self.patch_simi_cnt(src_feats[idx]), self.patch_simi_out(target_feats[idx]), reduction='batchmean')余弦相似度
cos ( θ ) = ∑ i = 1 n ( x i × y i ) ∑ i = 1 n ( x i ) 2 × ∑ i = 1 n ( y i ) 2 = a ∙ b ∣ ∣ a ∣ ∣ × ∣ ∣ b ∣ ∣ \begin{aligned} \begin{array}{c}\\{\cos( \theta )}\\\end{array} =\quad\frac{\sum_{i = 1}^{n} ( x_{i} \times y_{i} )}{\sqrt{\sum_{i = 1}^{n} ( x_{i} )^{2}} \times \sqrt{\sum_{i = 1}^{n} ( y_{i} )^{2}}} = \frac{\mathrm{a} \bullet \mathrm{b}}{| | \mathrm{a} | | \times | | \mathrm{b} | |} \end{aligned} cos(θ)=∑i=1n(xi)2×∑i=1n(yi)2∑i=1n(xi×yi)=∣∣a∣∣×∣∣b∣∣a∙b
# -*- coding: utf-8 -*-
# !/usr/bin/env python
# 余弦相似度计算
from PIL import Image
from numpy import average, dot, linalg
# 对图片进行统一化处理
def get_thum(image, size=(64, 64), greyscale=False):# 利用image对图像大小重新设置, Image.ANTIALIAS为高质量的image = image.resize(size, Image.ANTIALIAS)if greyscale:# 将图片转换为L模式,其为灰度图,其每个像素用8个bit表示image = image.convert('L')return image
# 计算图片的余弦距离
def image_similarity_vectors_via_numpy(image1, image2):image1 = get_thum(image1)image2 = get_thum(image2)images = [image1, image2]vectors = []norms = []for image in images:vector = []for pixel_tuple in image.getdata():vector.append(average(pixel_tuple))vectors.append(vector)# linalg=linear(线性)+algebra(代数),norm则表示范数# 求图片的范数norms.append(linalg.norm(vector, 2))a, b = vectorsa_norm, b_norm = norms# dot返回的是点积,对二维数组(矩阵)进行计算res = dot(a / a_norm, b / b_norm)return res
image1 = Image.open('010.jpg')
image2 = Image.open('011.jpg')
cosin = image_similarity_vectors_via_numpy(image1, image2)
print('图片余弦相似度', cosin)