数据可视化(图形绘制基础)
- 前言
- 一、图形绘制基础
- Matplotlib简介
- 使用过程
- sin函数示例
- 二、常用图形绘制
- 折线图的绘制
- plot
- 示例
- 散点图的绘制
- scatter()
- 示例
- 柱状图的绘制
- bar
- 示例
- 箱型图绘制
- plot.box
- 示例
- 饼状图的绘制
- pie
- 示例
- 三、图形绘制的组合情况
- 多个折线图的组合绘制
- 示例
- 折线图和散点图的组合绘制
- 示例
- 柱状图与折线图的组合绘制
- 示例
- 四、拓展
- 热力图
- heatmap
- 改变数据采样频率
- resample
- 示例
- 创建多个子图
- subplots()
- 调整子图之间的间距
- subplots_adjust
- 决策树
- plot_tree
前言
推荐一个网站给想要了解或者学习人工智能知识的读者,这个网站里内容讲解通俗易懂且风趣幽默,对我帮助很大。我想与大家分享这个宝藏网站,请点击下方链接查看。
https://www.captainbed.cn/f1
数据可视化是指利用图形、表格、图表等方式将数据展示出来,使得数据更加清晰、易于理解和分析。图形绘制是数据可视化的基础,通过绘制各种图形呈现数据,可以更加直观地了解数据之间的关系和趋势。
如果画图过程中出现
FutureWaring问题
import warning
warnings.filterwarnings('ignore')
针对中文不显示
plt.rcParams['font.family'] = ['sans-serif']
plt.rcParams['font.sans-serif'] = ['SimHei']
在当今数字化时代,数据分析已成为各行各业中不可或缺的一环。Python,作为数据分析领域的明星语言,凭借其强大的数据处理能力和丰富的库资源,正逐渐受到越来越多数据分析师的青睐。而在数据分析的过程中,数据可视化作为直观展示数据特征和规律的重要手段,更是不可或缺。
Python中,有许多专门用于数据可视化的库,其中最为著名的莫过于Matplotlib和Seaborn。Matplotlib作为Python中最早的数据可视化库,提供了丰富的绘图函数和灵活的配置选项,可以满足大部分基本的绘图需求。而Seaborn则是在Matplotlib的基础上,进一步封装和优化,提供了更加美观和高级的绘图接口。
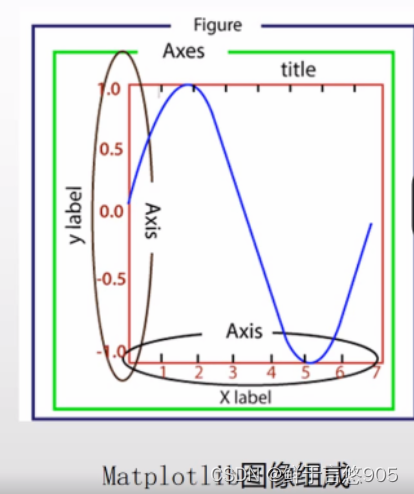
在图形绘制基础方面,我们需要掌握几个核心概念,包括坐标轴、图例、标题、标签等。坐标轴是图表的基础,用于展示数据的分布情况;图例用于区分不同系列的数据;标题和标签则用于说明图表的主题和内容。
接下来,我们通过几个简单的例子来演示如何使用Matplotlib进行基本的图形绘制。
我们使用Matplotlib来绘制一个简单的折线图。假设我们有一组关于某公司股票价格的数据,我们可以通过折线图来展示股票价格的走势。在Matplotlib中,我们可以使用plot()函数来绘制折线图,通过设置x轴和y轴的数据,以及图表的标题、坐标轴标签等参数,就可以生成一个基本的折线图。
当然,除了折线图和箱线图之外,还有许多其他类型的图形可以用于数据可视化,如柱状图、散点图、饼图等。每种图形都有其适用的场景和优缺点,需要根据具体的数据特征和需求来选择合适的图形类型。
一、图形绘制基础
Matplotlib简介
Matplotlib是目前应用最为广泛的python扩展绘图模块库,是Python中最受欢迎的数据可视化软件包之一。Matplotlib支持跨平台运行,能让使用者很轻松地将数据转化为高质量图形,并且提供了多样化的输出格式,常用于绘制2D图形,同时也提供了一部分3D绘图接口。
Matplotlib提供了类似于MATLAB的绘图函数,对于熟悉MATLAB的使用者来说,可以很容易的使用它。Matplotlib通常与NumPy和pandas扩展包一起使用,最常见的使用方式是根据NumPy库的N维数组类型ndarray来绘制2D图像,使用简单、代码清晰易懂,深受广大技术爱好者的喜爱,是数据分析中不可或缺的重要工具之一。
使用过程
使用pylab或pyplot绘图时一般过程为:首先读入数据,然后根据实际需要绘制折线图、散点图、柱状图、饼状图、雷达图或三维曲线和曲面,接下来设置轴和图形属性,最后显示或保存绘图结果。
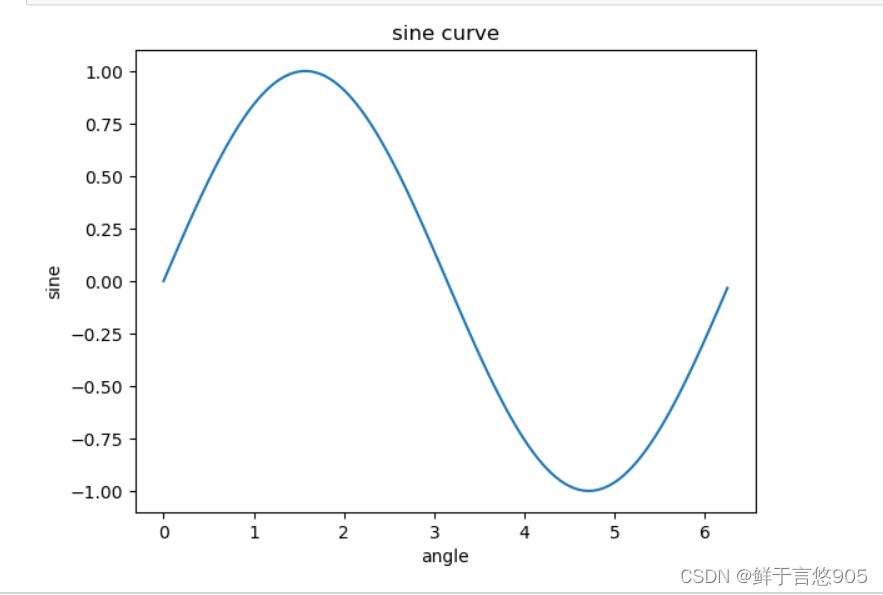
sin函数示例
【例7.1】请利用python绘制正弦函数曲线。
关键技术:采用Matplotlib包Pyplot模块的plot函数绘制曲线图。
from matplotlib import pyplot as plt
import numpy as np
import pandas as pd
import math
plt.rcParams['font.family'] = ['sans-serif']
plt.rcParams['font.sans-serif'] = ['SimHei']
x = np.arange(0,math.pi*2,0.05)
y = np.sin(x)
plt.plot(x,y)
plt.xlabel("angle")
plt.ylabel("sine")
plt.title("sine curve")
plt.show()

二、常用图形绘制
折线图的绘制
折线图是最基本的图表类型,是用点和点之间连线的上升或下降表示指标的连续变化趋势。折线图反映了一段时间内事物连续的动态变化规律,适用于描述一个变量随另一个变量变化的趋势,通常用于绘制连续数据,适合数据点较多的情况。
plot
matplotlib是一个用于绘制图形的Python库,其中的plot函数用于绘制线条图。下面是matplotlib中plot函数的详细解释:
plot(x, y, label, linestyle, color, linewidth, marker)
参数说明:
x:表示x轴上的数据序列,可以是一个列表、数组或Series类型的数据,也可以是一个数字,此时表示生成从0到该数字的等间隔的数据序列。y:表示y轴上的数据序列,要求与x轴上的数据序列长度相同。label:给绘制的线条指定一个标签,可以在绘制图例时使用。linestyle:线条的样式,可以是实线(‘solid’)、虚线(‘dashed’)、点线(‘dotted’)等,默认为实线。color:线条的颜色,可以是一个关键字字符串(如’red’、'blue’等),也可以是一个RGB元组表示的颜色(如(0.1, 0.2, 0.3)),默认为蓝色。linewidth:线条的宽度,可以是一个数字,默认为1。marker:线条上的标记点的样式,可以是一个关键字字符串(如’+'、‘o’等),也可以是一个标记字符(如’x’、's’等),默认为没有标记点。
使用plot函数可以绘制不同样式的线条图,可以通过设置不同的参数来定制线条的样式、颜色、宽度、标记点等。在绘制完所有的线条后,可以使用plt.legend()函数来添加图例,使得不同线条对应的标签在图中显示出来。
示例
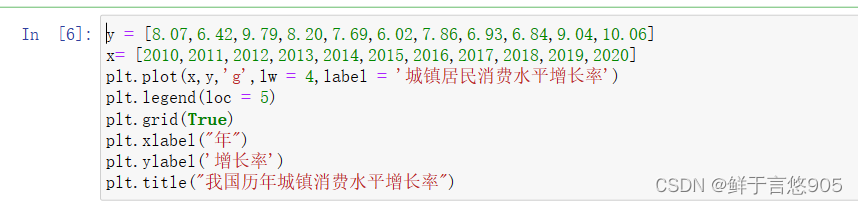
【例7.4】请根据给定的两组数据x和y,分别代表某城镇居民消费水平增长率和对应的年份,利用Python绘制城镇居民消费水平增长率折线图。
关键技术:利用matplotlib包的plot方法进行折线图的绘制。
y = [8.07,6.42,9.79,8.20,7.69,6.02,7.86,6.93,6.84,9.04,10.06]
x= [2010,2011,2012,2013,2014,2015,2016,2017,2018,2019,2020]
plt.plot(x,y,'g',lw = 4,label = '城镇居民消费水平增长率')
plt.legend(loc = 5)
plt.grid(True)
plt.xlabel("年")
plt.ylabel('增长率')
plt.title("我国历年城镇消费水平增长率")
散点图的绘制
散点图是以直角坐标系中各点的密集程度和变化趋势来表示两种现象间的相关关系,常用于显示和比较数值。当要在不考虑时间的情况下比较大量数据点时,使用散点图比较数据方便直观。散点图将序列显示为一组点,其中每个散点值都由该点在图表中的坐标位置表示。对于不同类别的点,则由图表中不同形状或颜色的标记符表示。同时,也可以设置标记符的颜色或大小。
scatter()
scatter是matplotlib库中用于绘制散点图的函数。散点图是一种用于展示两个变量之间关系的图形,其中每个点代表一个数据样本。
scatter函数可以接受一系列的x和y坐标作为输入,然后将这些坐标在图中绘制成散点。
下面是scatter函数的基本用法:
import matplotlib.pyplot as plt# 准备散点的x和y坐标
x = [1, 2, 3, 4, 5]
y = [2, 4, 6, 8, 10]# 绘制散点图
plt.scatter(x, y)# 显示图形
plt.show()
这段代码会生成一个简单的散点图,其中x坐标为1, 2, 3, 4, 5,y坐标为2, 4, 6, 8, 10。
scatter函数还可以接受一些常用的参数,用于调整散点图的样式和外观,例如:
s:设置散点的大小。可以传入一个常数,表示所有散点的大小;也可以传入一个数组,表示每个散点的大小。c:设置散点的颜色。可以传入一个常数,表示所有散点的颜色;也可以传入一个数组,表示每个散点的颜色。marker:设置散点的形状。可以传入一个字符,表示所有散点的形状;也可以传入一个数组,表示每个散点的形状。alpha:设置散点的透明度。
下面是一个示例代码,展示了如何使用这些参数调整散点图的样式:
import matplotlib.pyplot as plt
import numpy as np# 生成随机数据
np.random.seed(0)
x = np.random.randn(100)
y = np.random.randn(100)# 绘制散点图,设置散点的大小、颜色和形状
plt.scatter(x, y, s=50, c='r', marker='o', alpha=0.5)# 显示图形
plt.show()
这段代码会生成一个具有随机数据的散点图,散点的大小为50,颜色为红色,形状为圆形,透明度为0.5。
除了基本的用法和常用参数,scatter函数还有其他一些参数,用于进一步控制散点图的样式和外观,例如:
edgecolors:设置散点边缘的颜色。linewidths:设置散点边缘的宽度。cmap:设置颜色映射,用于根据数值变化为散点着色。norm:设置归一化器,用于归一化数值。label:设置散点图的标签,用于图例显示。
可以参考Matplotlib官方文档获取更多关于scatter函数的详细说明和示例代码。
示例
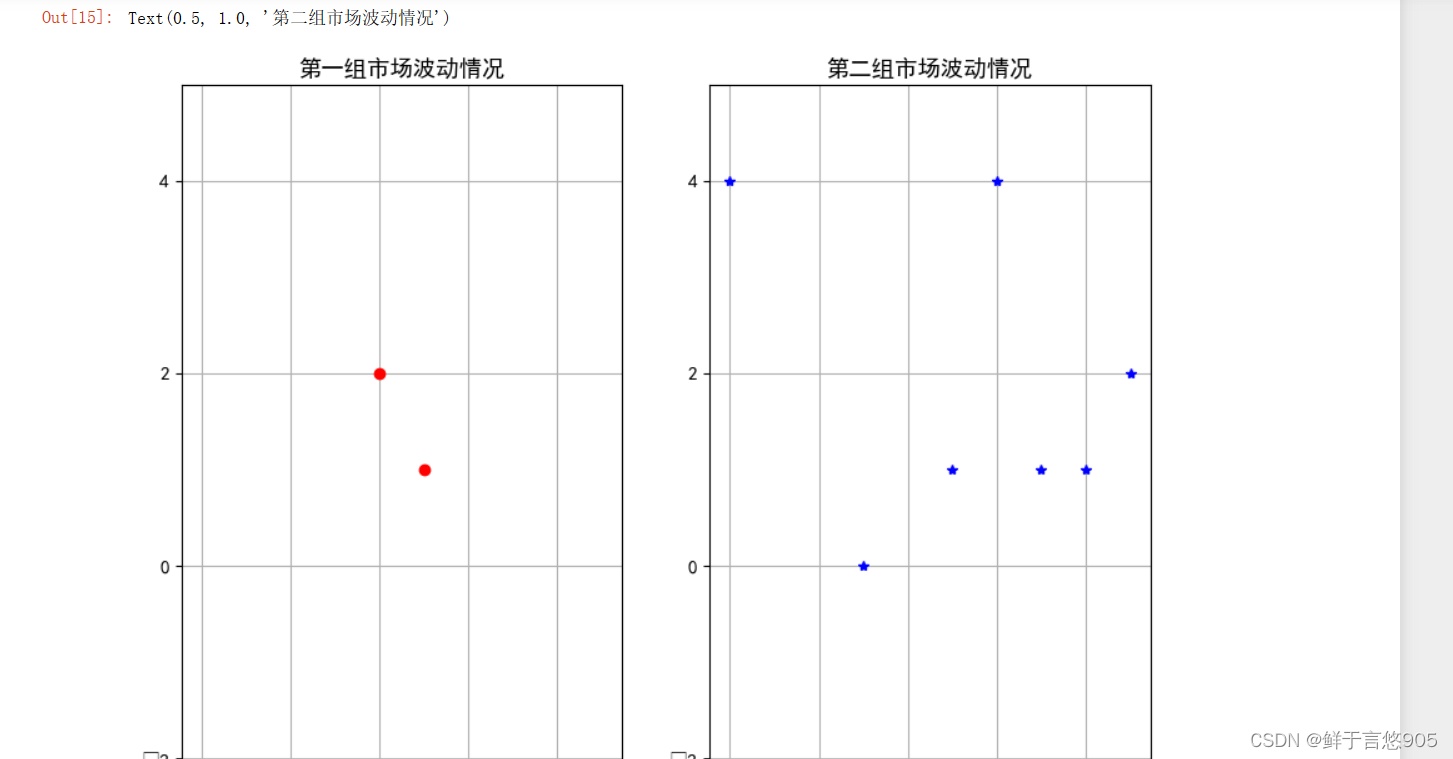
【例7.5】对于给定的两个市场收益率的波动情况数据x和y,请利用Python绘制散点图来反映两个市场的波动率情况。
关键技术:利用matplotlib包的plot函数进行散点图的绘制,与绘制折线图相比,绘制散点图只用到一组数据,而绘制折线图需要用到两组对应的数据。
x = np.random.randint(0,5,10)
y = np.random.randint(0,5,10)
plt.figure(figsize = (10,10))
plt.subplot(121)
plt.ylim((-5,5))
plt.plot(x,'ro',label = '第一组')
plt.grid(True)
plt.title('第一组市场波动情况')
plt.subplot(122)
plt.ylim((-5,5))
plt.plot(y,'b*',label = '第二组')
plt.grid(True)
plt.title('第二组市场波动情况')
plt.savefig('test',dpi = 600)
plt.show()

柱状图的绘制
bar
matplotlib的bar函数用于绘制柱状图,它是一个非常常用的数据可视化工具。
下面是bar函数的详细介绍:
语法:
matplotlib.pyplot.bar(x, height, width=0.8, bottom=None, align='center', data=None, **kwargs)
参数:
x:柱状图的x轴位置,可以是一个数值或者一个数组,表示每个柱状图的位置。height:柱状图的高度,可以是一个数值或者一个数组,表示每个柱状图的高度。width:柱状图的宽度,默认值为0.8。bottom:柱状图的底部位置,默认为None,表示从0开始绘制柱状图。align:柱状图的对齐方式,默认为’center’,表示柱状图的中心与给定位置对齐。data:传入一个DataFrame或者一个类似结构的数据集,x和height参数可以直接从data中获取。
其他常用参数:
color:柱状图的颜色,可以是一个字符串,表示柱状图颜色的名称,也可以是一个列表,表示每个柱状图的颜色。edgecolor:柱状图的边框颜色,默认为None,表示不显示边框。label:柱状图的标签,可以在图例中显示。tick_label:柱状图的刻度标签,可以在x轴上显示。alpha:柱状图的透明度,取值范围为0到1。
用例:
import matplotlib.pyplot as plt
import numpy as npx = np.arange(5)
y = [1, 4, 3, 2, 5]
plt.bar(x, y, color='blue', align='center')plt.xlabel('x')
plt.ylabel('y')
plt.title('Bar Chart')
plt.show()
此代码将绘制一个简单的柱状图,x轴是0到4,y轴是给定的数组y的值。柱状图的颜色为蓝色,对齐方式为居中。在图像的x轴标签、y轴标签和标题上显示对应的文字。最后调用plt.show()来显示图像。
以上提供了matplotlib的bar函数的详细介绍和一个简单的用例。通过使用不同的参数和组合,您可以根据自己的需求绘制出各种类型的柱状图。
示例
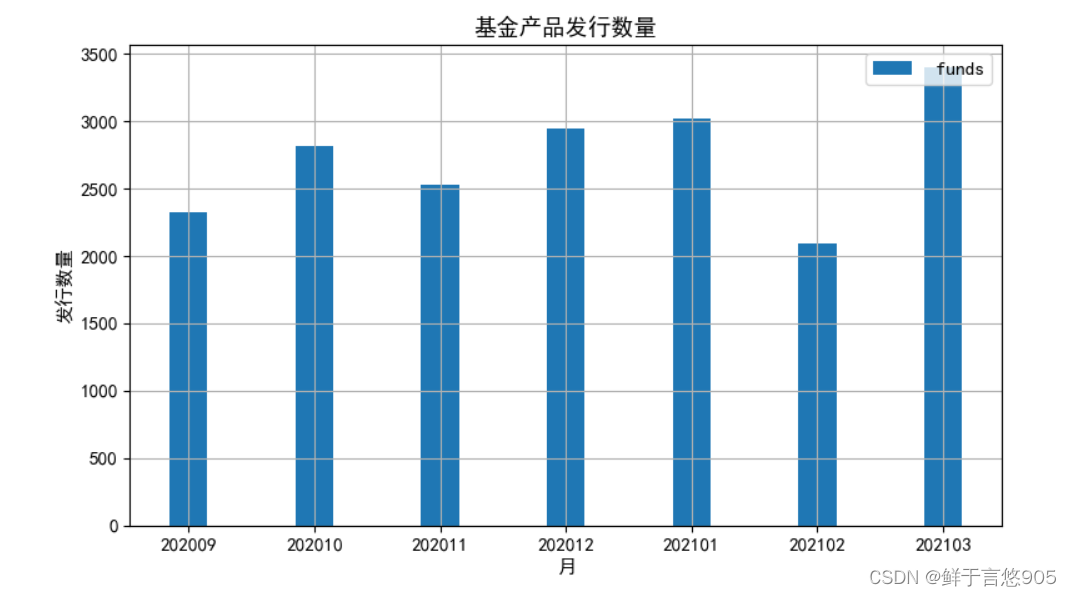
【例7.7】对于给定的2020年9月至2021年3月期间某基金产品发行数量的数据,该数据以字典形式存储,形式如下所示。请利用Python将其以柱状图的形式绘制出来。
{'202009': 2324,'202010': 2814,'202011': 2525,'202012':2946,'202101': 3019,'202102': 2087,'202103': 3398}
关键技术:可以利用Python的matplotlib包的bar方法进行柱状图绘制。
dict = {'202009': 2324,'202010': 2814,'202011': 2525,'202012': 2946,'202101': 3019,'202102': 2087,'202103': 3398}
plt.figure (figsize= (9,5) )
plt.bar (dict.keys (),dict.values (),width=0.3, align='center' , label=' funds')
plt.grid (True)
plt.legend (loc=1)
plt.xlabel ('月')
plt.ylabel('发行数量')
plt.title('基金产品发行数量')
plt.savefig ( 'test', dpi=600)

箱型图绘制
plot.box
plot.box是matplotlib库中的一个函数,用于绘制箱线图。箱线图是一种统计图表,用于展示一组数据的分布情况。它显示了数据的中位数、上下四分位数、最小值和最大值,以及异常值。
箱线图可以帮助我们了解数据的偏态、离散度和异常值情况。
plot.box的基本语法为:
matplotlib.pyplot.boxplot(x, notch=None, sym=None, vert=None, whis=None, positions=None, widths=None, patch_artist=None, bootstrap=None, usermedians=None, conf_intervals=None, meanline=False, showmeans=False, showcaps=True, showbox=True, showfliers=True, boxprops=None, labels=None, flierprops=None, medianprops=None, meanprops=None, capprops=None, whiskerprops=None, manage_xticks=True, autorange=False, zorder=None)
参数说明:
x:要绘制箱线图的数据,可以是一个一维数组或一个二维数组。notch:箱线图的缺口,默认为None。sym:异常值的标记,默认为None。vert:箱线图的方向,默认为True(垂直方向),设置为False可以绘制水平方向的箱线图。whis:决定绘制箱线图上下边界的位置,默认为1.5。boxprops:箱线图的属性设置,包括颜色、线宽等,默认为None。flierprops:异常值的属性设置,默认为None。medianprops:中位数的属性设置,默认为None。meanprops:均值的属性设置,默认为None。capprops:边界线的属性设置,默认为None。whiskerprops:whisker的属性设置,默认为None。manage_xticks:是否自动管理x轴的刻度,默认为True。autorange:是否自动确定y轴的范围,默认为False。zorder:图层顺序,默认为None。
除了以上参数,plot.box还可以接受一些其他参数,用于设置标题、坐标轴标签、图例等。详细的参数说明可以参考matplotlib官方文档。
下面是一个简单的示例代码,演示如何使用plot.box绘制箱线图:
import matplotlib.pyplot as plt
import numpy as np# 生成一组随机数据
np.random.seed(123)
data = np.random.normal(0, 1, 100)# 绘制箱线图
plt.boxplot(data)# 添加标题和坐标轴标签
plt.title('Box Plot')
plt.xlabel('Data')# 显示图形
plt.show()
运行以上代码,会生成一个简单的箱线图,显示了随机数据的中位数、上下四分位数、最小值和最大值,以及异常值(如果有)。
除了上述的示例代码,plot.box还可以接受一维或二维的数据作为参数,用于绘制多组数据的箱线图。可以通过设置参数来修改箱线图的样式,如颜色、线宽等。此外,还可以使用matplotlib的其他函数和方法来进一步自定义绘图。
示例
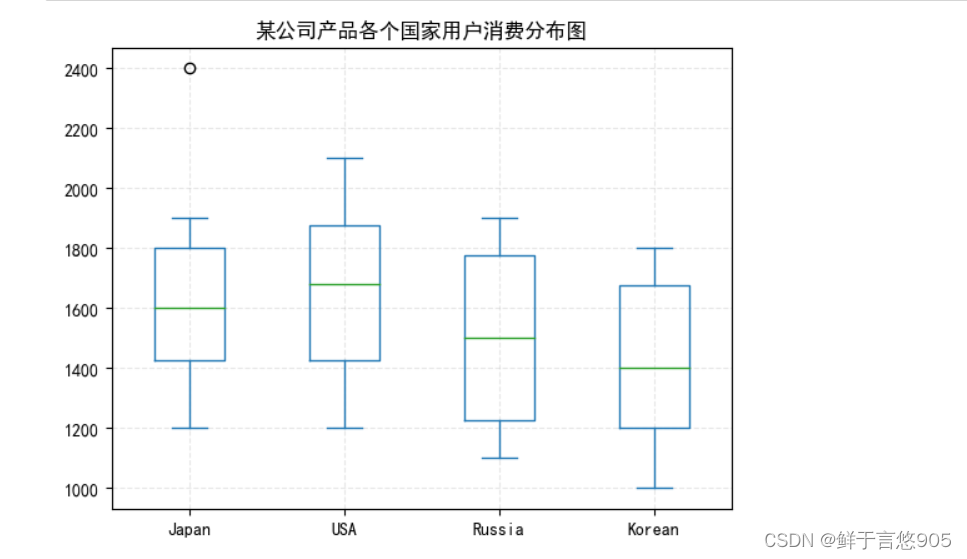
【例7.8】下面给定的数据是某公司产品在各个国家用户的消费分布图,请根据以下数据利用Python绘制箱型图。
'Japan': [1200, 1300, 1500, 1400, 1600, 1600, 1800, 1800, 1900, 2400],
'USA': [1200, 1350, 1400, 1500, 1660, 1800, 1700, 1900, 2100, 2000],
'Russia': [1100, 1200, 1200, 1400, 1300, 1600, 1700, 1900, 1900, 1800],
"Korean": [1200, 1100, 1000, 1300, 1200, 1500, 1600, 1700, 1800, 1800]
关键技术:可以利用Python的plot.box绘制箱型图。
data = {'Japan': [1200,1300,1500,1400,1600,1600,1800,1800,1900,2400],
'USA': [1200, 1350, 1400, 1500, 1660, 1800, 1700, 1900, 2100, 2000],
'Russia': [1100, 1200, 1200, 1400, 1300, 1600, 1700, 1900, 1900, 1800],
"Korean": [1200, 1100, 1000, 1300, 1200, 1500, 1600, 1700, 1800, 1800]}
df = pd.DataFrame(data)
df.plot.box(title = "某公司产品各个国家用户消费分布图")
plt.grid(linestyle = '--',alpha = 0.3)
plt.savefig('test',dpi = 600)
plt.show()

饼状图的绘制
pie
在matplotlib中,可以使用pie函数绘制饼图。饼图用于展示各类别的占比关系,适用于数据的相对比较。下面是使用pie函数绘制饼图的详细步骤和参数说明。
导入库:
import matplotlib.pyplot as plt
准备数据:
labels = ['A', 'B', 'C', 'D']
sizes = [15, 30, 45, 10]
绘制饼图:
plt.pie(sizes, labels=labels)
plt.show()
绘制饼图时,主要使用了两个参数:
sizes:代表各类别的占比值,要求是一个一维数组或列表。labels:代表各类别的标签,要求是一个与sizes长度相同的一维数组或列表。可选参数,默认值为None。
除此之外,还可以使用其他一些参数进行饼图的个性化设置,比如:
autopct:控制饼图中百分比的显示方式。可选参数,默认值为None。可以使用字符串格式控制显示,例如'%.1f%%'表示保留一位小数的百分比。explode:控制各类别之间的间隔。可选参数,默认值为None。可以使用一维数组或列表来指定各类别的偏移量,例如[0, 0.1, 0, 0]表示第二个类别偏移0.1。colors:控制各类别的颜色。可选参数,默认值为None。可以使用一维数组或列表来指定颜色,例如['red', 'blue', 'green', 'yellow']。startangle:控制饼图的起始角度,逆时针方向。可选参数,默认值为0。shadow:控制是否显示阴影。可选参数,默认值为False。
下面是一个综合使用了上述参数的例子:
labels = ['A', 'B', 'C', 'D']
sizes = [15, 30, 45, 10]
explode = [0, 0.1, 0, 0]
colors = ['red', 'blue', 'green', 'yellow']plt.pie(sizes, explode=explode, labels=labels, colors=colors, autopct='%.1f%%', startangle=90, shadow=True)
plt.axis('equal')
plt.show()
通过调整上述参数,可以根据具体需求绘制出个性化的饼图。
示例
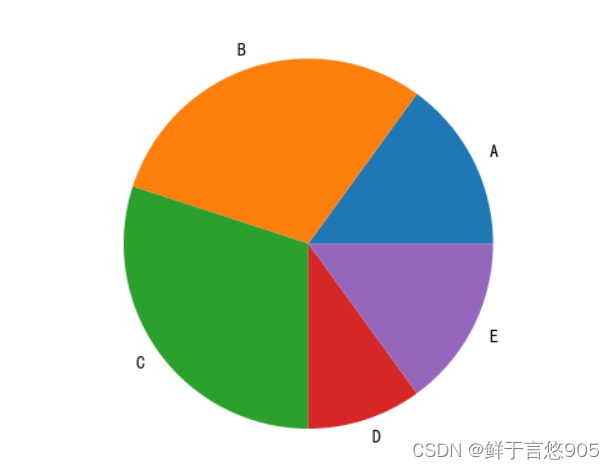
【例7.9】某公司有A、B、C、D、E五种商品,每种商品占有的市场份额分别为15%、30%、30%、10%和15%,请利用Python的饼状图绘制上述数据的分布图。
关键技术:可以利用Python的matplotlib包中的pie函数绘制饼状图。
import pandas as pd
import matplotlib.pyplot as plt
labels = ['A', 'B', 'C', 'D', 'E']
x = [15,30,30,10,15]
plt.pie(x, labels=labels)
plt.savefig('test',dpi=600)
plt.show ()

三、图形绘制的组合情况
多个折线图的组合绘制
示例
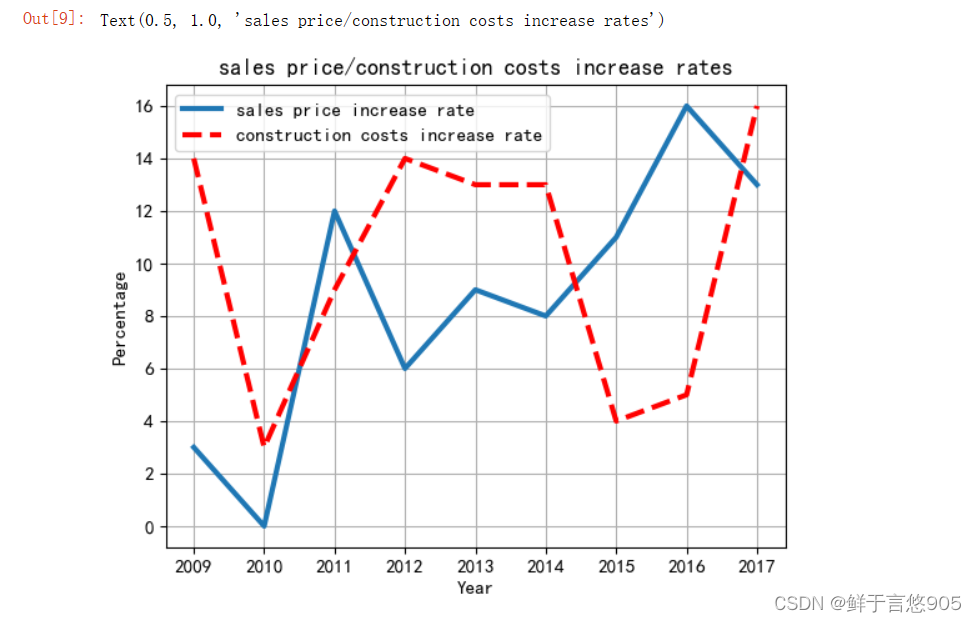
【例7.10】给定时间范围在2009年至2017年间两种商品的市场销售价格增长率数据集data1, data2。请利用Python的折线图将两种商品价格的增长率信息进行绘制,反映到图上。
关键技术:可以利用matplotlib包的plot函数进行多折线图的绘制。
data1 = np.random.randint(0,20,9)
data2 = np.random.randint(0,20,9)
year=[2009,2010,2011,2012,2013,2014,2015,2016,2017]
plt.plot(year,data1,lw=3,label='sales price increase rate')
plt.plot(year,data2,'r--',lw=3,label='construction costs increase rate')
plt.legend(loc=0)
plt.grid(True)
plt.xlabel('Year')
plt.ylabel('Percentage')
plt.title('sales price/construction costs increase rates')
折线图和散点图的组合绘制
示例
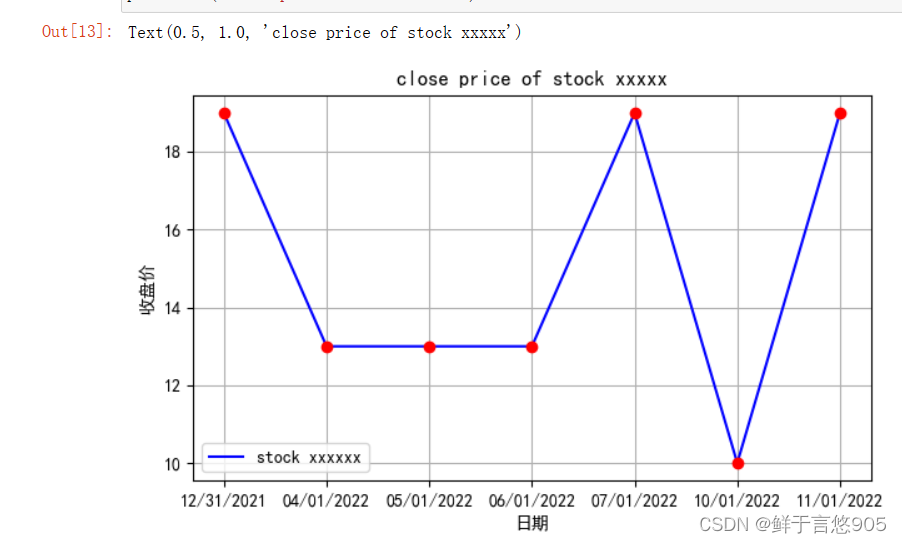
【例7.11】给定某只股票从2021年12月31日到2022年1月11日的收盘价格,请利用Python的折线图和散点图组合图形式进行数据的绘制。
关键技术:可以利用Python的plot函数进行绘制。
data = np.random.randint(10,20,7)
date = ['12/31/2021','04/01/2022','05/01/2022','06/01/2022','07/01/2022','10/01/2022','11/01/2022']
plt.figure(figsize=(7,4))
plt.plot(date,data,'b',label='stock xxxxxx')
plt.plot(date,data,'ro')
plt.grid(True)
plt.legend(loc=0)
plt.xlabel('日期')
plt.ylabel('收盘价')
plt.title('close price of stock xxxxx')

柱状图与折线图的组合绘制
示例
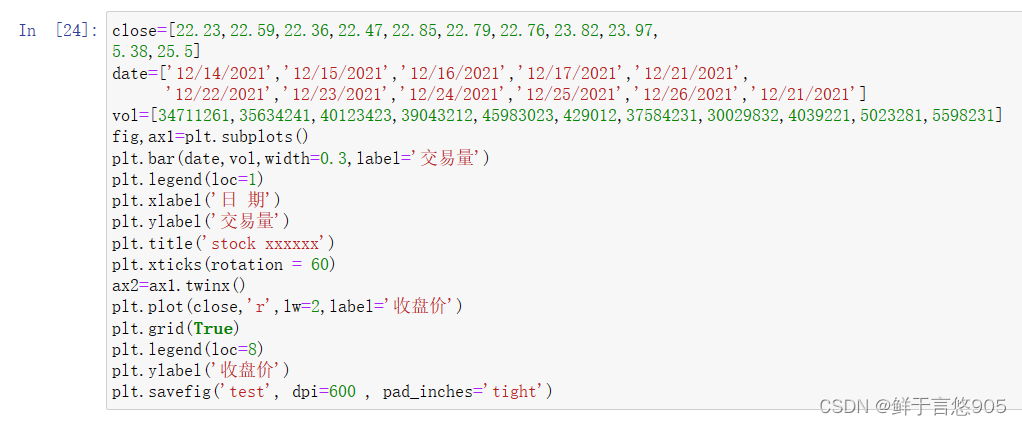
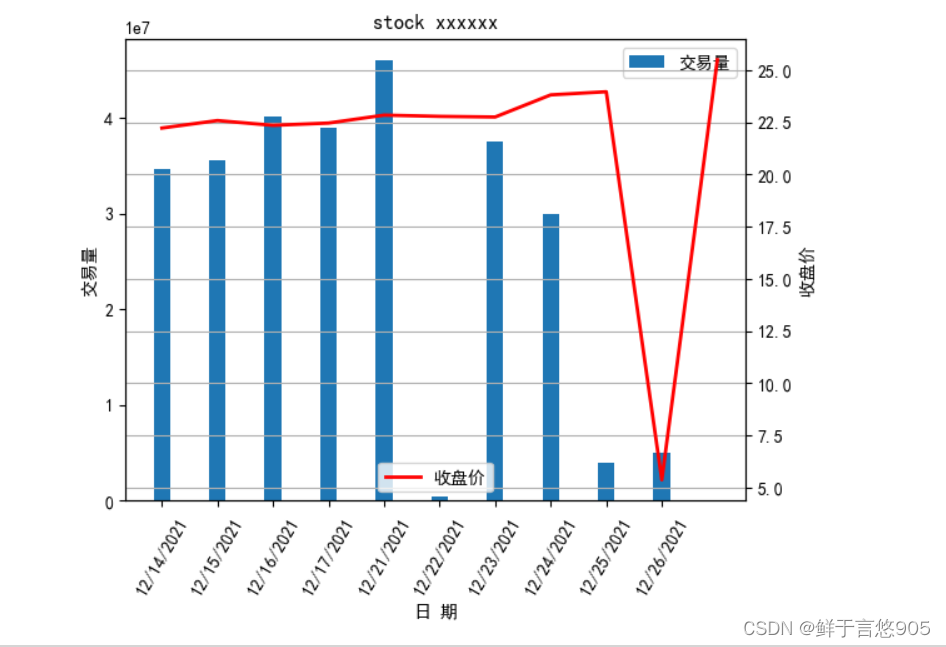
【例7.11】 【例7.12】已知给定的某股票在2021年12月14日至2021年12月28日的收盘价格和交易量,请利用Python绘制双坐标轴图,其中左坐标轴反映交易量,以柱状图表示;右坐标轴反映成交价格,以折线图表示。
close=[22.23,22.59,22.36,22.47,22.85,22.79,22.76,23.82,23.97,
5.38,25.5]
date=['12/14/2021','12/15/2021','12/16/2021','12/17/2021','12/21/2021','12/22/2021','12/23/2021','12/24/2021','12/25/2021','12/26/2021','12/21/2021']
vol=[34711261,35634241,40123423,39043212,45983023,429012,37584231,30029832,4039221,5023281,5598231]
fig,ax1=plt.subplots()
plt.bar(date,vol,width=0.3,label='交易量')
plt.legend(loc=1)
plt.xlabel('日 期')
plt.ylabel('交易量')
plt.title('stock xxxxxx')
plt.xticks(rotation = 60)
ax2=ax1.twinx()
plt.plot(close,'r',lw=2,label='收盘价')
plt.grid(True)
plt.legend(loc=8)
plt.ylabel('收盘价')
plt.savefig('test', dpi=600 , pad_inches='tight')
四、拓展
热力图
热力图是一种可视化数据的图表方式,通过不同颜色的区块来表示数据的密度或强度。热力图通常用于显示热点、密度分布或者数据趋势。
在热力图中,颜色的深浅表示数据的强度或频率,通常深色表示高强度或高频率,浅色表示低强度或低频率。通过观察热力图的颜色变化,可以直观地发现数据的分布情况或趋势。
热力图可以用于各种领域,例如地理信息系统(GIS)、流量分析、市场研究等。在地理信息系统中,热力图可以用来显示人口密度、空气质量、交通流量等信息。在流量分析中,热力图可以用来显示用户活跃度、点击量等数据。在市场研究中,热力图可以用来显示产品销售热点、用户偏好等信息。
绘制热力图可以使用各种工具和编程语言,例如Python的matplotlib库、R语言的ggplot2包等。这些工具提供了丰富的功能和选项,可以根据具体需求进行定制。
heatmap
seaborn是一个基于matplotlib的数据可视化库,它提供了许多简洁而美观的绘图函数。seaborn中的heatmap()函数用于绘制热力图,热力图可以用来可视化矩阵或数据表中数值的大小和分布。
下面是一个使用heatmap()函数绘制热力图的示例代码:
import seaborn as sns
from matplotlib import pyplot as plt# 创建矩阵或数据表
data = [[1, 2, 3],[4, 5, 6],[7, 8, 9]]# 绘制热力图
sns.heatmap(data)# 显示图表
plt.show()
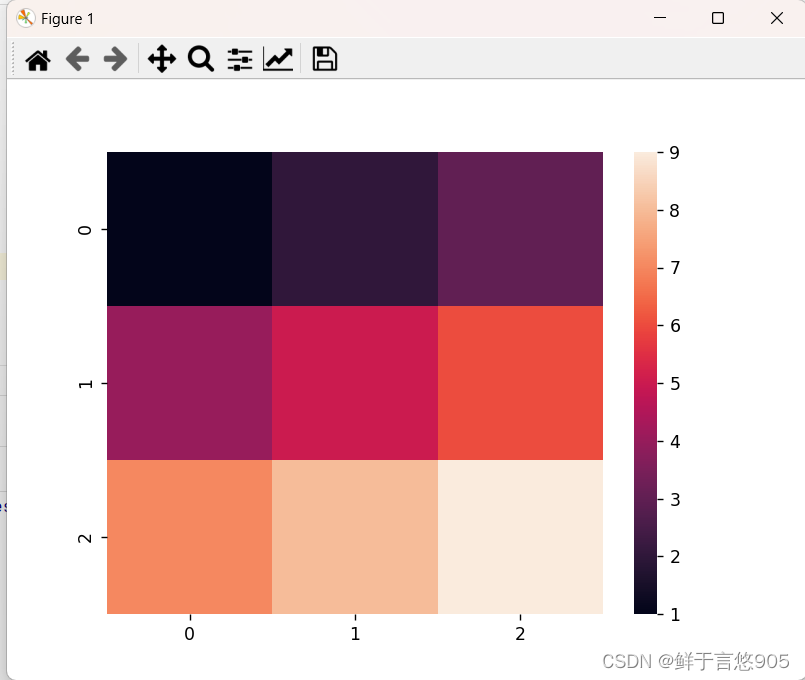
运行代码后,将会弹出一个窗口显示绘制的热力图。默认情况下,heatmap()函数将根据数据的值自动选择颜色渐变,并在图表中显示颜色条以表示值的大小。你还可以通过设置参数来自定义热力图的样式和属性,例如调整颜色映射、添加标签、设置标题等。具体的参数设置可以参考seaborn的官方文档。

改变数据采样频率
resample
在matplotlib中,resample是一个用于改变数据采样频率的函数。它可以用于将数据从高频率采样转换为低频率采样,或者从低频率采样转换为高频率采样。这个函数可以用于处理时间序列数据,通过平均、求和等方式来对数据进行采样。
resample函数的基本语法如下:
resample(rule, how=None, axis=0, fill_method=None, closed=None, label=None, limit=None, kind=None, convention=None)
其中,rule参数用于指定新的采样频率,可以是字符串形式的时间间隔,比如’1D’代表每天采样一次,'1H’代表每小时采样一次,也可以是整数形式的数字,代表每个指定数量的样本进行一次采样。
-
how参数用于指定进行采样时使用的聚合函数,比如’mean’代表计算均值,'sum’代表计算总和。 -
axis参数用于指定进行采样的轴,默认是0,表示对行进行采样。 -
fill_method参数用于指定进行采样时缺失数据的填充方式。 -
closed和label参数用于指定进行采样时边界的处理方式。 -
limit参数用于指定进行采样时最大允许的缺失样本数量。 -
kind参数用于指定进行采样时的插值方式。 -
convention参数用于指定进行采样时的约定方式。
示例
下面是一个使用resample函数对时间序列数据进行重新采样的例子:
import matplotlib.pyplot as plt
import pandas as pd# 创建一个DataFrame对象,包含时间序列数据
data = pd.DataFrame({'value': [1, 2, 3, 4, 5]}, index=pd.date_range(start='2022-01-01', periods=5, freq='D'))# 将数据从每天采样一次转换为每两天采样一次
resampled_data = data.resample('2D').mean()# 打印结果
print(resampled_data)
执行上述代码,将会得到如下输出:
value
2022-01-01 1.5
2022-01-03 4.5
这里使用了resample函数将每天采样一次的数据转换为每两天采样一次的数据,并使用均值方式进行采样。所以结果中的第一个值为前两天的数据的均值((1+2)/2=1.5),第二个值为后两天的数据的均值((4+5)/2=4.5)。
创建多个子图
subplots()
matplotlib.pyplot.subplots函数是用于创建多个子图的工具。它返回一个包含所有子图的Figure对象和一个包含所有子图轴对象的Axes对象数组。
subplots函数的一般语法如下:
fig, axes = plt.subplots(nrows=1, ncols=1, figsize=None, ...)
参数说明:
nrows:子图的行数。ncols:子图的列数。figsize:一个元组,指定图形的宽度和高度。
例如,如果我们要创建一个包含两行两列的子图,可以这样做:
import matplotlib.pyplot as pltfig, axes = plt.subplots(nrows=2, ncols=2)
然后,我们可以使用axes数组中的元素来操作每个子图轴对象。例如,可以使用axes[0, 0]表示第一个子图的轴对象。
以下是一个完整的示例:
import numpy as np
import matplotlib.pyplot as plt# 创建一个包含两行两列的子图
fig, axes = plt.subplots(nrows=2, ncols=2)# 生成一些随机数据
x = np.linspace(0, 2*np.pi, 100)
y1 = np.sin(x)
y2 = np.cos(x)
y3 = np.tan(x)
y4 = np.exp(x)# 在每个子图中绘制不同的函数
axes[0, 0].plot(x, y1)
axes[0, 1].plot(x, y2)
axes[1, 0].plot(x, y3)
axes[1, 1].plot(x, y4)plt.show()
上述代码将创建一个2x2的子图网格,并在每个子图中绘制不同的函数。
调整子图之间的间距
subplots_adjust
subplots_adjust是matplotlib中的一个函数,用于调整子图之间的间距。它可以用于调整子图布局,使得子图之间的间距更合适。
函数的语法如下:
matplotlib.pyplot.subplots_adjust(left=None, bottom=None, right=None, top=None, wspace=None, hspace=None)
参数说明如下:
left:左边界的位置。默认为0.125。bottom:底边界的位置。默认为0.1。right:右边界的位置。默认为0.9。top:顶边界的位置。默认为0.9。wspace:子图之间的宽度间距。默认为0.2。hspace:子图之间的高度间距。默认为0.2。
调用subplots_adjust函数后,可以通过调整上述参数的值来达到调整子图布局的效果。
决策树
plot_tree
plot_tree是scikit-learn库中DecisionTreeClassifier和DecisionTreeRegressor类的一个方法,用于绘制决策树模型的树形图。
使用plot_tree需要先对DecisionTreeClassifier或DecisionTreeRegressor类进行训练,然后传入已经训练好的模型对象,以及需要绘制的树形图的配置参数。
下面是plot_tree的常用参数:
decision_tree:训练好的决策树模型对象。feature_names:特征的名称列表。class_names:类别的名称列表。filled:是否给节点填充颜色,默认为False。rounded:是否将节点的框圆角化,默认为False。special_characters:是否使用特殊字符,默认为False。
使用示例:
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.tree import plot_tree# 加载数据集
iris = datasets.load_iris()
X, y = iris.data, iris.target# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)# 创建决策树分类器并训练
clf = DecisionTreeClassifier()
clf.fit(X_train, y_train)# 绘制决策树模型的树形图
plot_tree(clf, filled=True, rounded=True, feature_names=iris.feature_names, class_names=iris.target_names)
上述代码将会绘制出一个决策树模型的树形图,其中每个节点代表一个判断条件,通过树形图可以清晰地了解决策树的结构和特征的重要性。