本篇博客给大家带来的是用C++语言来解答有效的括号!
🐟🐟文章专栏:每日一练
🚀🚀若有问题评论区下讨论,我会及时回答
❤❤欢迎大家点赞、收藏、分享!
今日思想:不服输的少年啊,请你再努力一下!
题目描述:

思路:
我们利用栈来解答,首先遍历数组我们找左括号把他放到栈里,然后再找游括号来看看是否与之匹配。如果遍历完之后栈为空代表匹配完成返回true,反之返回false。
注意如果没学习过栈的可以看看这篇博客:【C++】数据结构 栈的实现-CSDN博客
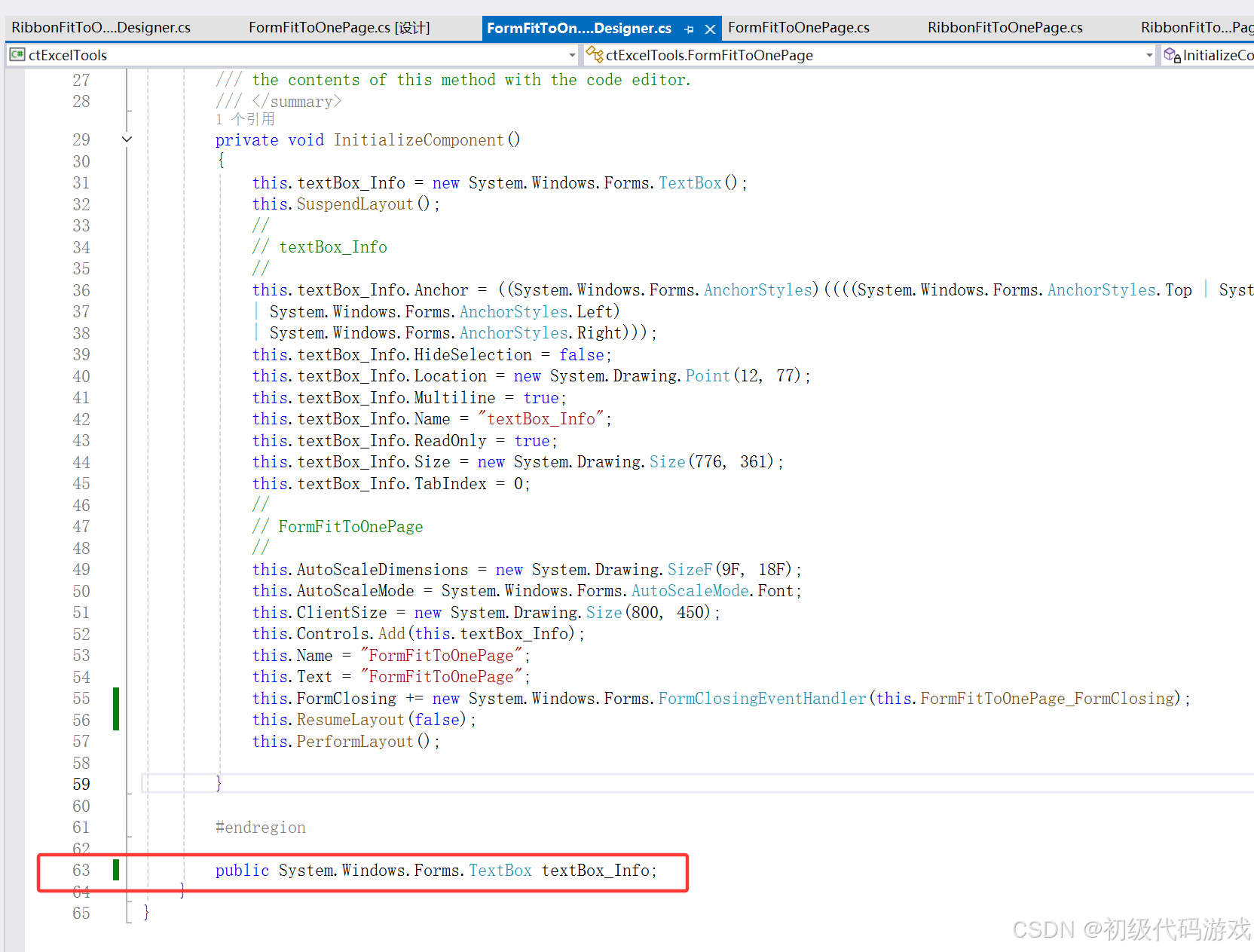
代码实例:
typedef char STDataType;
typedef struct Stack
{STDataType* arr;int top;//指向栈顶的结构int capacity;//容量
}ST;//栈的初始化
void STInit(ST* ps)
{ps->arr = NULL;ps->top = ps->capacity = 0;
}
//入栈-栈顶
void StackPush(ST* ps, STDataType x)
{assert(ps);if (ps->top == ps->capacity){//空间不够-增容int newCapacity = ps->capacity == 0 ? 4 : 2*ps->capacity;STDataType* tmp = (STDataType*)realloc(ps->arr, newCapacity * sizeof(STDataType));if (tmp == NULL){perror("realloc fail!");exit(1);}ps->arr = tmp;ps->capacity = newCapacity;}//空间够了ps->arr[ps->top++] = x;
}
//判断栈是否为空
bool StackEmpty(ST* ps)
{assert(ps);return ps->top == 0;
}
//拿栈顶的数据
STDataType StackTop(ST* ps)
{assert(!StackEmpty(ps));return ps->arr[ps->top - 1];
}
//栈的销毁
void STDestroy(ST* ps)
{if (ps->arr)free(ps->arr);ps->arr = NULL;ps->top = ps->capacity = 0;
}
//出栈-栈顶
void StackPop(ST* ps)
{assert(!StackEmpty(ps));--ps->top;
}
bool isValid(char* s)
{ST st;STInit(&st);char* pi=s;//遍历所有的字符串swhile(*pi !='\0'){if(*pi=='(' ||*pi=='[' ||*pi=='{'){StackPush(&st,*pi);}else{//找右括号并且与之匹配if(StackEmpty(&st))//判断栈是否为空{STDestroy(&st);return false;}char top=StackTop(&st);if((top=='(' && *pi != ')')|| (top=='[' && *pi !=']')|| (top=='{' && *pi !='}')){STDestroy(&st);return false;}StackPop(&st);}pi++;}//栈为空,说明所有的左括号都已经匹配完,反之非有效字符bool ret =StackEmpty(&st)?true:false;return ret;
}完!!








![[多线程]基于阻塞队列(Blocking Queue)的生产消费者模型的实现](https://i-blog.csdnimg.cn/direct/0865846099c54815b1326d140bb2a063.png#pic_center)

![[内网渗透] 红日靶场2](https://i-blog.csdnimg.cn/direct/1ef486309e614246803bf5b7da47824a.png)