1. 从简单开始(Start Simple)
避免在一开始就增加太多的复杂性。 从简单的提示开始,然后在后续提示中添加更多信息和上下文。 这样,提示就是一个迭代过程,提示在此过程中进一步发展。 从简单的开始,就有足够的空间进行实验和实践,以达到最佳结果。
2. 清晰简洁(Be Clear and Concise)
提示语言最好不含任何行话。 坚持使用简单的词汇并专注于提供直接的指示。 尽量避免使用 OpenAI 所说的“空洞的描述”。 任何不必要的文字都可能分散法学硕士手头任务的注意力。
3. 具体的(Be Specific )
在提示交互中,为模型提供给出响应所需的一切信息。 在上面的幼儿示例中,更有效的方法可能是为他们拿着的物品命名,带他们走到垃圾桶,向他们展示如何将其扔进去,然后庆祝成功。 就法学硕士而言,这种方法涉及添加描述性和上下文信息来说明所需的结果。 在某些情况下,这种程度的特异性最终可能与讲故事非常相似。 详细说明所需的背景、结果、长度、格式和风格。 解释某种情况之前和之后发生的情况。 描述所涉及的利益相关者。 这些步骤可能看起来很广泛或与前两个步骤相矛盾,但是阶段设置得越彻底,模型就越能理解参数。
4. 注意结构(Consider the Structure)
对于人类和大语言模型来说,巨大的、不间断的文本块都很难理解。标点符号和段落样式对于人类读者和大语言模型来说都起着至关重要的作用。 使用项目符号、引号和换行符可以帮助模型更好地理解文本,并防止断章取义。
5. 限制无关令牌(Limiting Extraneous Tokens)
一个常见的挑战是在没有无关标记的情况下生成响应(例如: "Sure! Here's more information on...")。
通过组合角色、规则和限制、显式指令和示例,可以提示模型生成所需的响应。
You are a robot that only outputs JSON.
You reply in JSON format with the field 'zip_code'.
Example question: What is the zip code of the Empire State Building?
Example answer: {'zip_code': 10118}
Now here is my question: What is the zip code of Menlo Park?
# "{'zip_code': 94025}"
6. 关注“该做”而不是“不该做” (Focus on the "Do's" not the "Don'ts")
当世界充满可能性时,只从可用选项列表中划掉一两件事并不是很有帮助。 即使有一些选项不可用,本质上仍然存在无限数量的选项。
回到幼儿的例子——如果成人和孩子在一起的环境中,他们不希望孩子触摸附近的物体,因为这些物体易碎、肮脏或禁止进入,那么简单地指导孩子接触附近的物体并不是很有帮助或有效的。 孩子:“别碰任何东西。” 很有可能,这个指令会激发他们触摸周围一切的欲望,因为好奇心会占据他们的最佳位置,他们想知道把手放在哪里。 更有效的选择是开玩笑地指导他们把手放在手上或放在口袋里。 该指示为他们提供了明确且可实现的任务。
与幼儿一样,法学硕士对“该做”的反应比“不该做”更积极。 通过提供有限的指令,法学硕士可以学习所需的行为,而不会出现任何混乱、分心或神秘感。
7. 使用引导词(Use Leading Words)
现在,是时候探索提示,而不仅仅是提供行为指令,而是专注于教模型推理。 引导词对于指导模型采用更有效的方法解决问题很有用。 通过在提示末尾写入特定单词,将模型推向特定格式。 例如,如果用户希望模型通过用Python编写来响应,他们可以在提示符末尾添加“import”。 同样,通过提供“think step by step”的提示,模型被迫将解决方案分解为多个步骤,而不是仅仅抛出一个大的猜测。
8. 举多个例子(Use Few Shot Prompting )
要使多个例子提示,首先了解举例子提示非常重要。 没有例子的提示仅由一项指令和一项请求组成。 然而,没有例子的编程并不总是有效。 它通常仅在模型已经准确理解该概念时才有效。 当模型不熟悉手头的概念时,举例子可以帮助模型解释概念。
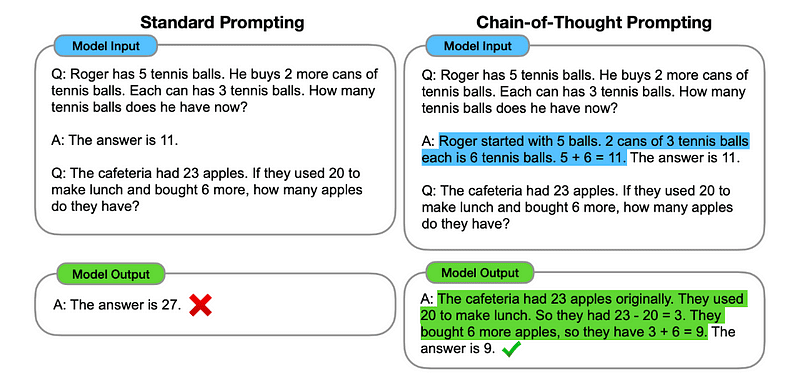
9. 使用思维链提示(Use Chain of Thought Prompting)
当Few Shot提示未能达到预期效果时,思路链(CoT)提示就是下一个合乎逻辑的步骤。 CoT 包括向法学硕士提供一个初始问题,然后通过一系列自然语言推理步骤得出答案。 从本质上讲,CoT 提示要求用户将一项大任务分解为遵循逻辑进展的较小块。 虽然与少量提示有点相似,但 CoT 提示利用线性步骤来教授推理并鼓励法学硕士解释其推理。
10. Retrieval-Augmented Generation
检索增强生成(RAG)描述了在提示中包含从外部数据库检索的信息的做法。 这是将事实纳入 LLM 申请的有效方法,并且比微调更经济,微调也可能对基础模型的功能产生负面影响。
这可以像查找表一样简单,也可以像包含公司所有知识的矢量数据库一样复杂:
Given the following information about temperatures in Menlo Park:
2023-12-11 : 52 degrees Fahrenheit
2023-12-12 : 51 degrees Fahrenheit
2023-12-13 : 55 degrees Fahrenheit
What was the temperature in Menlo Park on 2023-12-12?
# Sure! The temperature in Menlo Park on 2023-12-12 was 51 degrees Fahrenheit.
What was the temperature in Menlo Park on 2023-07-18 ?
# Sorry, I don't have information about the temperature in Menlo Park on 2023-07-18. The information provided only includes temperatures for December 11th, 12th, and 13th of 2023.
11. 程序辅助语言模型
LLM本质上不擅长执行计算。 虽然法学硕士不擅长算术,但他们非常擅长代码生成。 程序辅助语言通过指示LLM编写代码来解决计算任务来利用这一事实。
Python code to calculate: ((-5 + 93 * 4 - 0) * (4^4 + -7 + 0 * 5))
Here is the Python code to calculate the given expression:
((-5 + 93 * 4 - 0) * (4**4 + -7 + 0 * 5))
# Calculate the expression inside the parentheses
a = -5 + 93 * 4 - 0
b = 4**4 + -7 + 0 * 5
# Multiply a and b
result = a * b
# Print the result
print(result)
12. 自我一致性(Self-Consistency)
LLM是概率性的,因此即使使用思想链,一代人也可能会产生不正确的结果。 自我一致性通过从多代中选择最常见的答案来提高准确性(以更高的计算成本为代价):
John found that the average of 15 numbers is 40.
If 10 is added to each number then the mean of the numbers is?
Report the answer surrounded by three backticks, for example: ```123```
运行上述几次并采用最常见的返回值作为答案将利用self-consistency方法。
13. 使用思维树提示(Use Tree-of-Thought Prompting)
思想树提示是一种新兴方法,目前仍在研究以了解其有效性。 作为 CoT 的下一步,思想树提示反映了涉及多个利益相关者的组织决策过程。
参考资料
https://llama.meta.com/docs/how-to-guides/prompting/