参考资料:活用pandas库
apply是指把函数同时作用于DataFrame的每一行或每一列。类似于编写一些跨每行或每列的for循环,并同时调用apply函数。
1、函数
函数是对python代码进行分组和复用的一种方法。如果某段代码会被多次使用,并且使用时是需要做少量修改,这时就应该考虑把这段代码放入一个函数中。
# 编写一个函数
# 求平方的函数
def my_sq(x):"""求平方"""return x**2# 求平均数的函数
def my_avg(x,y):"""求两个数的平均值"""return(x+y)/2三重引号中的文本是文档字符串。在查找某个函数的帮助文档时,就会看到它们。可以是使用这些文档字符串为自定的函数创建帮助文档。

2、使用函数
# 导入库
import pandas as pd# 创建一个DataFrame
df=pd.DataFrame({'a':[10,20,30],'b':[20,30,40]
})(1)Series的apply方法
Series有一个apply方法。该方法有一个func参数。当传递给它一个函数之后,apply方法就会把传入的函数应用于Series的每个元素。
# 把自定义的平方函数应用于列a
sq=df['a'].apply(my_sq)
print(sq)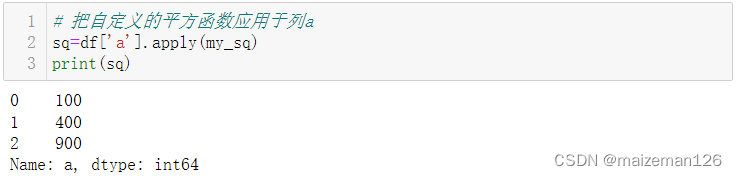
请注意,当把my_sq传递给apply时,不要在my_sq后面加上圆括号。
当自定函数有多个参数时,系统会将Series数据分配给第一个参数。
# 定义一个幂函数,包含两个参数
def my_exp(x,e):return x**e
# 当把my_exp函数应用于一个Series时,除了要把my_exp传递给apply之外,
# 还要多久传递一个参数,用于指定指数的大小。
# 传递改参数时,可以使用关键字参数。
ex=df['a'].apply(my_exp,e=3)
print(ex)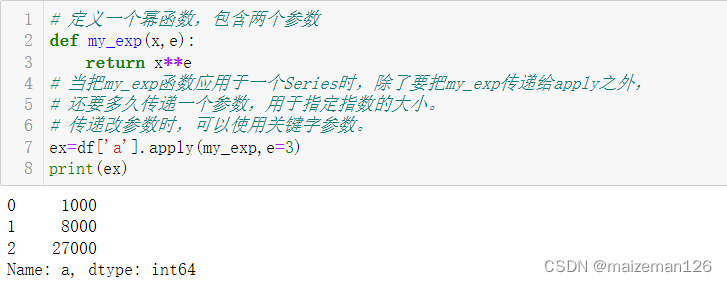
(2)DataFrame的apply方法
DataFrame通常有至少两个维度(或称字段/列)。因此,当向DataFrame应用一个函数时,首先需要指定应用该函数的轴,例如逐行或逐列。
如果把apply方法的axis参数设置为0(默认值),则表示按列应用指定函数。如果把axis参数设置为1,则按行应用指定函数。
当向DataFrame应用一个函数时(默认按列应用),这个轴(如列)会传递到函数的第一个参数中。
# 自定义一个函数,它接收一个值,并将其输出。
def print_me(x):print(x)# 按列应用,函数的第一个参数就是一个完整数据列,而不是一列的某个值
df.apply(print_me)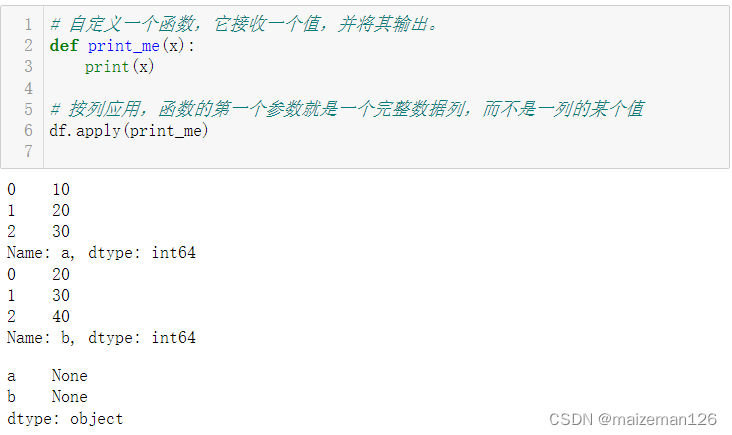
如下的应用函数则会报错:
# 自定义一个函数,含有3个参数
def avg_3(x,y,z):return (x+y+z)/3
#
df.apply(avg_3)
正确的函数应用应该是:
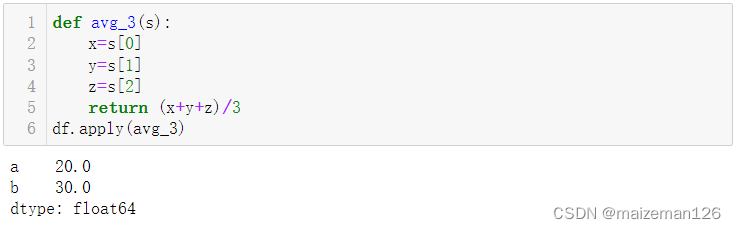

3、apply高级用法
# 导入numpy库
import numpy as np
# 导入Titanic数据集
titanic=pd.read_csv(r"...\seaborn常用数据案例\titanic.csv")
# 查看数据集的基本信息
print(titanic.info())# 编写函数
def count_missing(vec):"""计算一个向量中缺失值的个数"""# 根据值是否缺失获取一个由True/False值组成的向量null_vec=pd.isnull(vec)# 得到null_vec中的null值得个数# null值对应True,True为1,False为0null_count=np.sum(null_vec)# 返回向量中缺失值的个数return null_countdef prop_missing(vec):"""计算向量中缺失值的占比"""# 调用count_missing函数计算缺失值的个数num=count_missing(vec)# 获得向量中元素的个数dem=vec.size# 返回缺失值的占比return num/demdef prop_complete(vec):"""向量中非缺失值的占比"""# 调用prop_missing函数计算缺失值的占比return 1-prop_missing(vec)# 按列应用,用于对列的缺失数据情况进行分析
cmis_col=titanic.apply(count_missing)
pmis_col=titanic.apply(prop_missing)
pcom_col=titanic.apply(prop_complete)
print(cmis_col)
print(pmis_col)
print(pcom_col)# 按行应用,用于行的缺失数据分析
cmis_row=titanic.apply(count_missing,axis=1)
pmis_row=titanic.apply(prop_missing,axis=1)
pcom_row=titanic.apply(prop_complete,axis=1)
print(cmis_row.head())
print(pmis_row.head())
print(pcom_row.head())