💓博主CSDN主页:杭电码农-NEO💓
⏩专栏分类:高阶数据结构专栏⏪
🚚代码仓库:NEO的学习日记🚚
🌹关注我🫵带你学习更多数据结构
🔝🔝

高阶数据结构
- 1. 前言
- 2. B+树讲解
- 3. B*树讲解
- 4. 索引原理
- 5. 总结
1. 前言
B树并不常用,就是因为有B+树的存在. MySQL的索引底层其实就是使用了B+树,请听我娓娓道来
本章重点:
本篇文章着重讲解B+树, B*树的概念和结构, 讲解引擎:MyISAM和 InnoDB的索引的底层原理
2. B+树讲解
B+树是B树的变形,是在B树基础上优化的多路平衡搜索树,B+树的规则跟B树基本类似,但是又在B树的基础上做了以下几点改进优化:
- 分支节点的子树指针与关键字个数相同
- 分支节点的子树指针p[i]指向关键字值大小在[k[i],k[i+1])区间之间
- 所有叶子节点增加一个链接指针链接在一起
- 所有关键字及其映射数据都在叶子节点出现
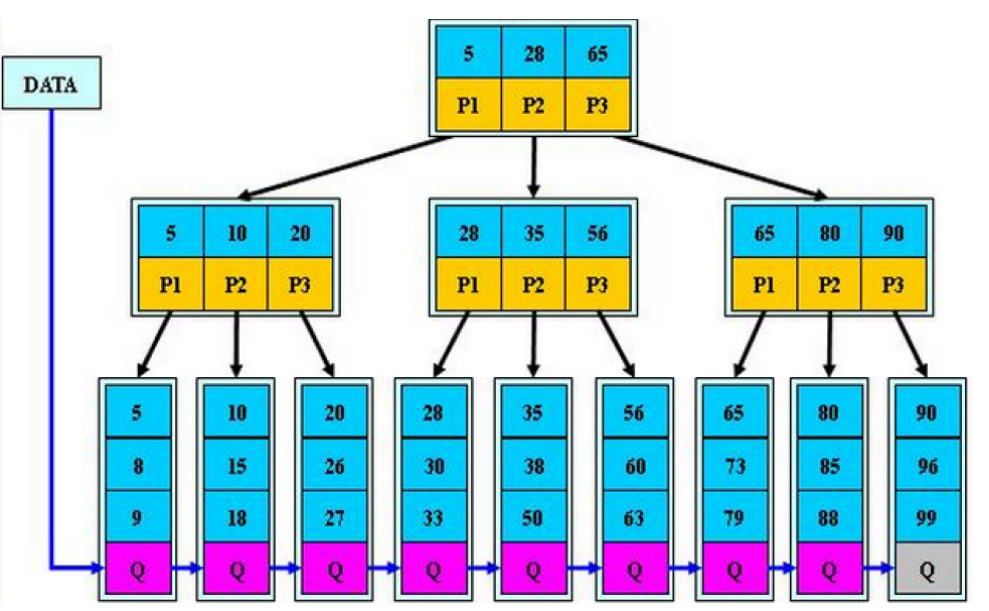
B+树的这个改进有效的减少了B树的消耗. 在最左边的叶子节点中, 是用链表将不同值链接起来的,并且父节点的关键字5就是链表的第一个元素, 链表中所有的元素都满足 5<=x<10. 所以可以看出, B树系列的数据结构就是一颗矮胖树,设计成为矮胖树的原因是查找时, 进行磁盘OI的次数少了,自然就提高效率了. 某种意义上来讲,B树系列更像是书本前面的目录, 方便你轻松的查找到一个值

B+树的分裂:
当一个结点满时,分配一个新的结点,并将原结点中1/2的数据复制到新结点,最后在父结点中增加新结点的指针;B+树的分裂只影响原结点和父结点,而不会影响兄弟结点,所以它不需要指向兄弟的指针。
分裂属于拓展,有兴趣可自行查资料
3. B*树讲解
B*树是B+树的变形,在B+树的非根和非叶子节点再增加指向兄弟节点的指针。
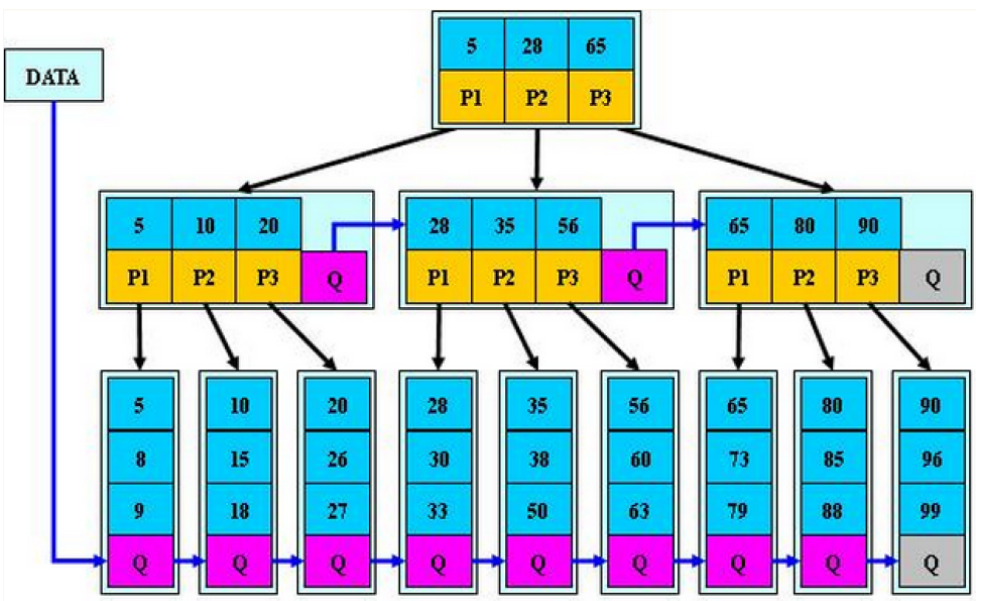
B*树的分裂:
当一个结点满时,如果它的下一个兄弟结点未满,那么将一部分数据移到兄弟结点中,再在原结点插入关键字,最后修改父结点中兄弟结点的关键字(因为兄弟结点的关键字范围改变了);如果兄弟也满了,则在原结点与兄弟结点之间增加新结点,并各复制1/3的数据到新结点,最后在父结点增加新结点的指针。所以,B*树分配新结点的概率比B+树要低,空间使用率更高;

虽然说B*树的空间利用率更高, 但是它的设计更绕更复杂, 所以在实际生活中, 反而B+树的运用场景比较多
4. 索引原理
B-树最常见的应用就是用来做索引。索引通俗的说就是为了方便用户快速找到所寻之物,比如:
书籍目录可以让读者快速找到相关信息,hao123网页导航网站,为了让用户能够快速的找到有价
值的分类网站,本质上就是互联网页面中的索引结构。
MySQL官方对索引的定义为:索引(index)是帮助MySQL高效获取数据的数据结构,简单来说:索引就是数据结构。

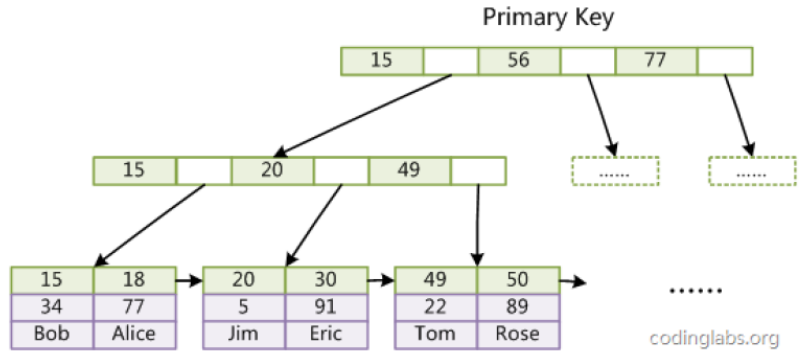
MyISAM引擎: B+树
MyISAM引擎的B+树的叶子节点只是保存了表数据的地址, 当你通过索引查找对应的地址后, 再使用此地址直接找到数据. 这种索引方式称为非聚簇索引
InnoDB引擎: B+
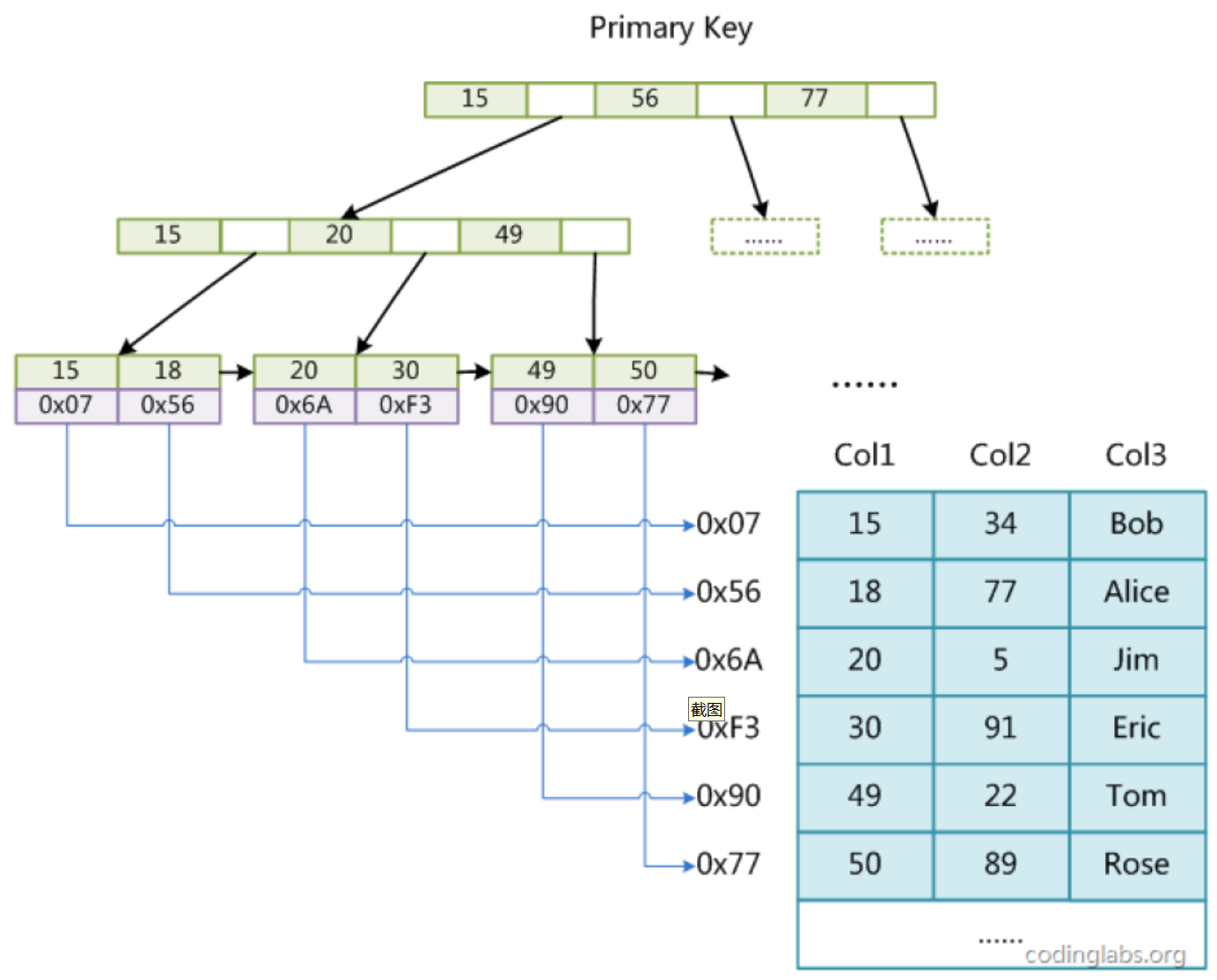
InnoDB支持B+树索引、全文索引、哈希索引。但InnoDB使用B+Tree作为索引结构时,具体实现方式却与MyISAM截然不同。第一个区别是InnoDB的数据文件本身就是索引文件。MyISAM索引文件和数据文件是分离的,索引文件仅保存数据记录的地址。而InnoDB索引,表数据文件本身就是按B+Tree组织的一个索引结构,这棵树的叶节点data域保存了完整的数据记录。这个索引的key是数据表的主键,因此InnoDB表数据文件本身就是主索引.
叶节点包含了完整的数据记录,这种索引叫做聚集索引. 因为InnoDB的数据文件本身要按主键聚集,所以InnoDB要求表必须有主键. 学过MySQL的伙伴可能知道, 不仅仅主键可以根据主键创建索引, 还有唯一键索引,普通索引等. 那么他们是怎样工作的呢? 答案是, 非主键索引的B+树的叶子节点中存储的是这一行对应的主键值, 然后再根据这个主键值去主键索引中找到所有数据
5. 总结
B树系列的应用一般是在磁盘,也就是外数据的查询, 它的思想是值得我们学习的