目录
1.了解进程通信
1.1进程为什么要通信
1.2 进程如何通信
1.3进程间通信的方式
2.管道
2.1管道的初步理解
2.2站在文件描述符的角度-进一步理解管道
2.3 管道的系统调用接口(匿名管道)
2.3.1介绍接口函数:
2.3.2编写一个管道的代码
1.了解进程通信
1.1进程为什么要通信
以下是进程间通信的几个主要原因:
- 数据共享与协作:
- 当多个进程需要共同访问或修改同一份数据时,它们需要通过某种方式进行通信,以确保数据的一致性和完整性。
- 进程间通信允许进程协同工作,共同完成任务。例如,一个进程负责数据收集,而另一个进程负责数据处理和存储。
- 系统效率:
- 进程间通信可以减少不必要的数据复制和重复计算,提高系统效率。
- 通过共享内存或消息传递等方式,进程可以直接访问所需的数据或资源,而无需经过额外的拷贝或转换。
- 模块化与解耦:
- 在软件设计中,模块化是一个重要的原则。通过将不同的功能划分为独立的进程,可以提高代码的可维护性和可重用性。
- 进程间通信是实现模块化设计的重要手段之一。通过定义明确的通信接口和协议,不同的进程可以独立地开发和测试,然后再通过通信接口进行集成。
- 并发与并行:
- 并发和并行是现代操作系统和计算机架构的重要特性。它们允许多个进程同时运行,以提高系统的吞吐量和响应速度。
- 进程间通信是实现并发和并行编程的关键技术之一。通过适当的通信机制,不同的进程可以协调彼此的工作,确保并发和并行操作的正确性和高效性。
- 分布式系统与网络应用:
- 在分布式系统和网络应用中,不同的进程可能位于不同的计算机或设备上。它们需要通过网络进行通信,以交换数据、共享资源和协调操作。
- 进程间通信是分布式系统和网络应用中的核心技术之一。它允许不同的进程在物理上分离的情况下仍然能够相互协作和通信。
- 操作系统与内核功能:
- 操作系统和内核提供了许多基本的服务和功能,如文件系统、设备驱动、进程调度等。这些服务和功能通常需要由多个进程共同协作完成。
- 进程间通信允许操作系统和内核中的不同进程之间进行通信和协作,以实现更高级别的功能和服务。
1.2 进程如何通信
进程间通信的前提:先让不同的进程,看到同一份(由操作系统提供的)资源(“一段内存”)。
假如进程A要和进程B进行通信,肯定不能让B直接访问到A进程中的资源,这就不符合进程具有独立性的概念了。那么,这时候就只能借助操作系统的帮助了。当进程A需要与进程B进行通信的时候,操作系统需要确保进程间通信的安全性和隔离性,OS会创建一个共享资源,满足进程间资源的读写。OS提供了很多的系统调用,OS创建的共享资源不同,系统调用接口不同,进程间的通信就会有不同的种类!
1.3进程间通信的方式
以下三种都属于本地通信:
管道(Pipe)
管道是一种最基本的进程间通信(IPC)机制,它用于在具有亲缘关系的进程之间(通常指父子进程)进行单向数据传输。管道是基于文件描述符实现的,分为无名管道(也称为匿名管道)和命名管道(也称为FIFO)。(直接复用内核代码直接通信)
- 匿名管道:仅能在具有亲缘关系的进程间使用。在进程创建时,由父进程创建管道,然后父进程将读/写端通过文件描述符的形式传递给子进程,子进程从该描述符中读取或写入数据。
- 命名管道:可以在任意两个进程间使用,具有一个唯一的名称,在文件系统中以文件的形式存在。任何具有访问权限的进程都可以通过该名称访问命名管道,并进行数据的读写操作。
System V进程间通信(IPC)
System V IPC是UNIX系统V版本提供的一组进程间通信机制,包括消息队列、信号量和共享内存。
- 消息队列:允许进程间发送和接收消息。消息队列是保存在内核中的消息链表,发送方将消息添加到队列的尾部,接收方从队列的头部取走消息。每个消息具有一个唯一的类型,接收方可以根据类型选择性地接收消息。
- 信号量:用于同步和互斥。信号量是一个整数变量,用于表示某种资源的数量。进程可以通过对信号量进行P(减)和V(加)操作来实现对资源的访问控制。
- 共享内存:允许两个或多个进程共享同一块内存空间。共享内存是进程间通信中最快的方式,因为数据直接在内存中传递,不需要进行内核和用户空间的数据拷贝。但是,共享内存需要进程间进行同步以防止数据的不一致。
POSIX进程间通信(IPC)
POSIX IPC是POSIX(Portable Operating System Interface)标准定义的一组进程间通信机制,包括消息队列、信号量、共享内存以及套接字等。POSIX IPC与System V IPC的主要区别在于它们的接口和语义有所不同,但它们都提供了类似的通信功能。
- POSIX消息队列:与System V消息队列类似,但具有更丰富的功能和更灵活的接口。
- POSIX信号量:与System V信号量类似,但提供了更丰富的操作,如等待多个信号量等。
- POSIX共享内存:与System V共享内存类似,但提供了更简洁的接口和更丰富的功能,如内存映射文件等。
2.管道
2.1管道的初步理解
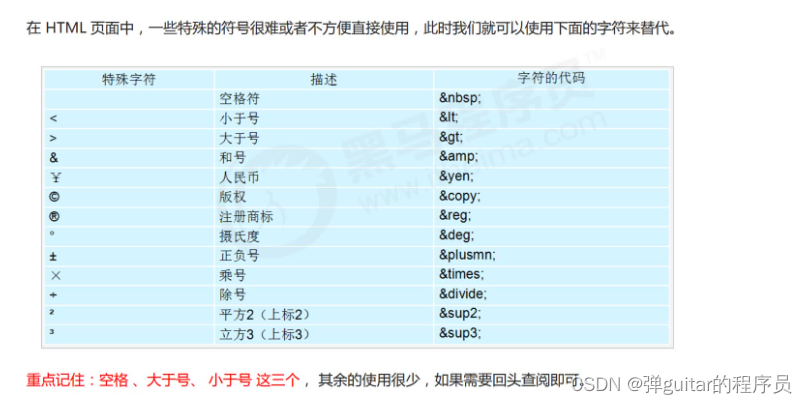
如果我们以两种不同的方式(读和写)打开同一个文件(hello.txt),这时会创建两个不同的文件结构体对象,但操作系统只会加载一份该文件的(inode,内核级文件缓冲区,操作发方法集合,内容和属性)。
理解一种现象:为什么父子进程会向同一个显示器终端打印数据?
因为进程默认会打开三个标准输入输出:0,1,2。怎么做到的?因为bash打开了,我们在OS中运行的进程都是bash的子进程,因此所有的子进程也就默认打开了。
close():为什么我们的子进程主动close(0/1/2),不影响父进程继续使用显示器文件呢?
因为文件的结构体对象中包含了内存级的引用计数,父进程的关闭只会导致引用计数--,只有当引用计数为0时,文件资源才会被彻底的释放。
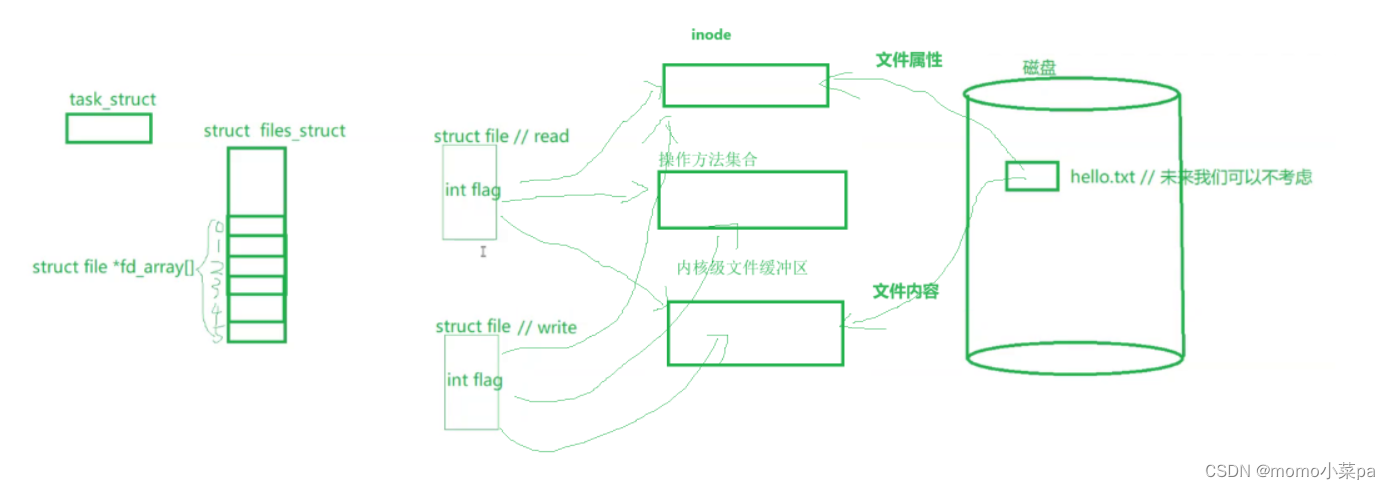
当我们创建一个子进程后,子进程会继承父进程的内核数据结构(这里指文件的),但内容不会,子进程中管理文件的数据结构,包含了指向文件的结构体对象的指针,当然也可以通过文件的结构体对象,对打开的文件进行读写。多个进程都可以通过内核级文件缓冲区看到文件的资源,我们将这个内核级文件缓冲区称作:管道文件!未来父进程往管道文件中写,子进程向管道文件中读,就实现进程通信了!!!
这种通信,只允许父和子的单向通信,这意味着数据只能从管道的写端流向读端,而不能反过来。这样的设计目:管道最初被设计为一种简单的进程间通信机制,主要用于父子进程之间的数据传递。它的设计目标就是实现单向数据流,以满足这种简单的通信需求。(父->子 / 子->父)
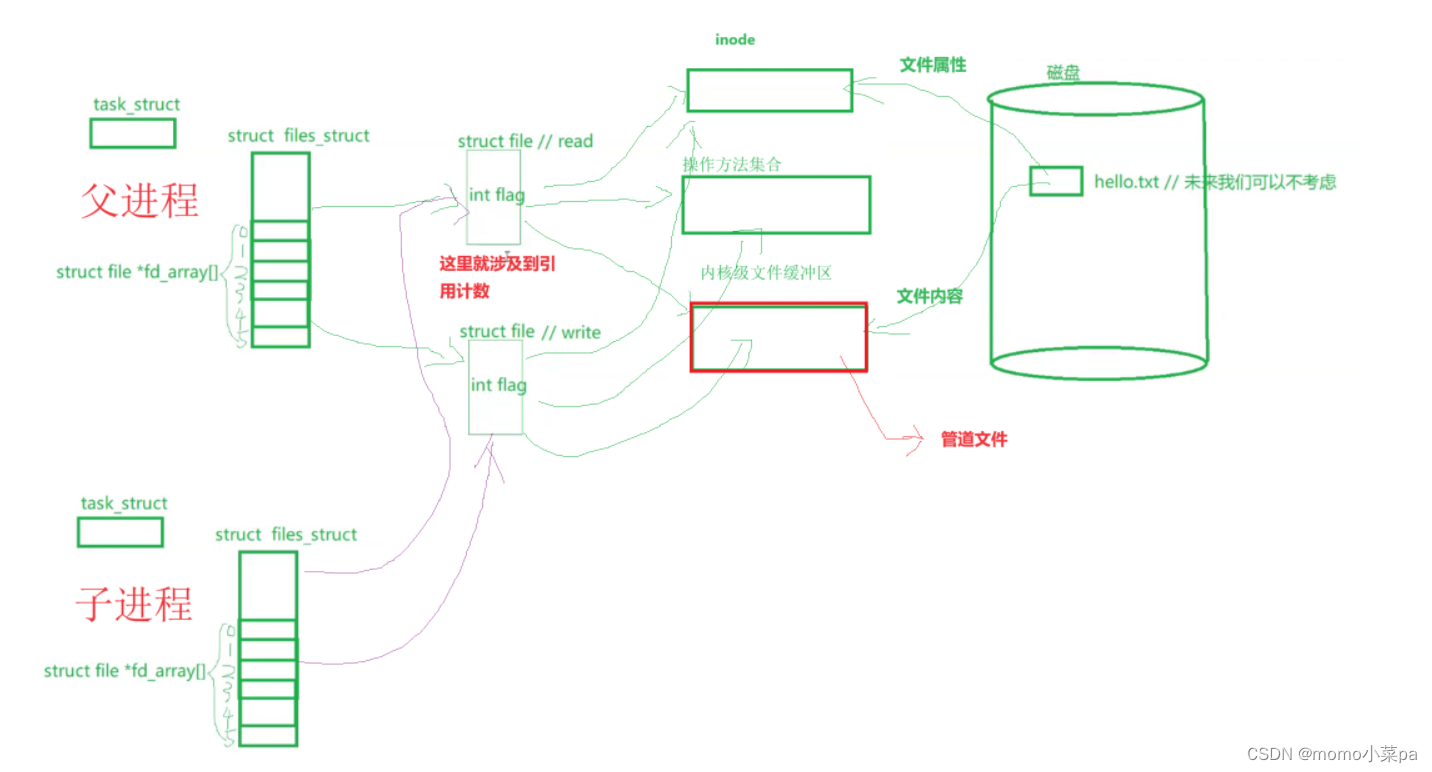
2.2站在文件描述符的角度-进一步理解管道
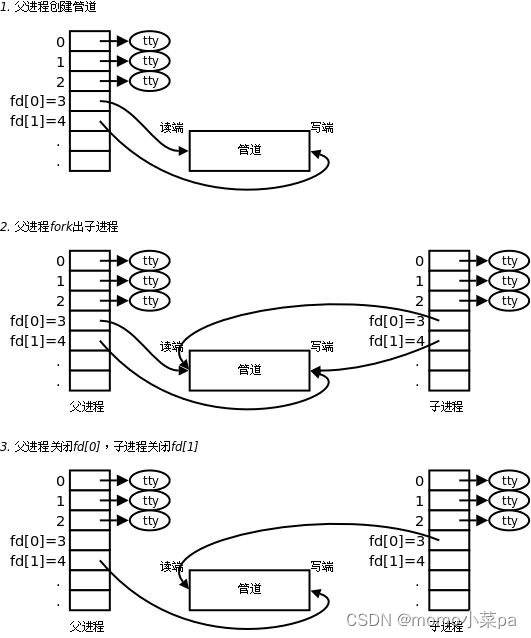
- 创建管道:父进程首先调用
pipe()系统调用来创建一个管道。这个系统调用会返回一个包含两个文件描述符的数组,通常表示为pipefd[2]。其中,pipefd[0]是管道的读端,pipefd[1]是管道的写端。- 创建子进程:父进程接着会调用
fork()系统调用来创建一个新的子进程。子进程会继承父进程的文件描述符表,包括刚才创建的管道文件描述符。- 关闭不需要的文件描述符:为了防止读写混乱,父子进程需要各自关闭不需要的文件描述符。通常,父进程会关闭管道的写端(
pipefd[1]),只保留读端;而子进程会关闭管道的读端(pipefd[0]),只保留写端。这样,子进程就可以向管道中写入数据,而父进程则可以从管道中读取数据。- 写入数据:子进程使用
write()系统调用,通过管道的写端(pipefd[1])向管道中写入数据。写入的数据会被存储在内核的缓冲区中,等待父进程读取。- 读取数据:父进程使用
read()系统调用,通过管道的读端(pipefd[0])从管道中读取数据。如果父进程在读取数据时,管道中没有数据可读(即子进程还没有写入数据),那么父进程的read()调用会被阻塞,直到有数据可读为止。同样地,如果子进程向已经写满的管道中写入数据,它的write()调用也会被阻塞,直到有空间可写为止。- 关闭文件描述符:当父子进程完成通信后,它们应该分别关闭各自的文件描述符,以释放资源。
管道的数据传输是直接在内存中进行的,不涉及硬盘I/O操作。当数据被写入管道时,它会被存储在内核的缓冲区中,等待读取进程来读取。读取进程通过系统调用从内核缓冲区中读取数据,最后父子进程都关闭文件描述符,管道被释放,不会被内存缓冲区刷新到磁盘
2.3 管道的系统调用接口(匿名管道)
2.3.1介绍接口函数:
我们通过文件的原理理解了管道,但是不能用文件的接口了,因为文件的接口没法让内存级缓冲区的数据不往磁盘刷新的,所以工程师做了一个专门的接口:pipe
pipe()系统调用
pipe()系统调用用于在调用进程中创建一个管道(pipe创建的管道就是一个文件,但它不是普通文件,而是单独构成一种文件系统,他没有名字,故又称为匿名管道,并且只存在于内存中。)它接受一个文件描述符数组作为参数,并在这个数组中填充两个文件描述符:一个用于读(pipefd[0]),另一个用于写(pipefd[1])。
这个管道只是让(父->子 / 子->父),那我想实现双向的通信呢?
可以创建两个管道!!!(多线程时讲解)
为什么管道是单向的呢?
简化设计:单向通信的管道设计简化了管道的实现和管理。通过限制数据只能在一个方向上流动,可以避免很多与双向通信相关的复杂性和潜在的同步问题。这种简单性使得管道成为一种高效、轻量级的进程间通信(IPC)机制。
避免冲突:在双向通信中,如果两个进程同时尝试读写同一个管道,可能会导致数据冲突和混乱。通过限制管道为单向通信,可以确保数据的有序性和一致性,从而避免这种冲突。
清晰性:单向通信使得管道的使用更加清晰明了。进程可以明确地知道哪个管道用于发送数据,哪个管道用于接收数据。这种明确性有助于减少编程错误和调试困难。
灵活性:虽然单个管道只能实现单向通信,但可以通过组合多个管道来实现双向通信或其他更复杂的通信模式。例如,可以使用两个管道来模拟双向通信:一个管道用于进程A向进程B发送数据,另一个管道用于进程B向进程A发送数据。这种灵活性使得管道可以适应各种不同的应用场景。
安全性:在某些情况下,限制通信方向可以提高系统的安全性。例如,在服务器和客户端之间的通信中,服务器可能只希望从客户端接收请求并发送响应,而不希望客户端能够直接读取或修改服务器的内部状态。通过使用单向通信的管道,可以确保这种安全性要求得到满足。
2.3.2编写一个管道的代码
1.初步代码:我们调用了pipe,创建管道成功后,我们查看了
pipefd[0]是读文件描述符(读端),而pipefd[1]是写文件描述符(写端),不出所料是3和4,管道创建是成功的,那么意味着创建了两个structfile指向缓冲区的。#include<iostream> #include<cerrno> #include<cstring> #include<unistd.h> int main() {//1.创建管道int pipefd[2];int n =pipe(pipefd);//输出型参数,rfd,wfdif(n!=0){std::cerr<<"errno:"<<errno<<":"<<"errstring :"<<strerror(errno)<<std::endl;return 1;}std::cout<<"pipefd[0]: "<<pipefd[0]<<", pipefd[1]: "<<pipefd[1]<<std::endl;return 0; }
2.完成这一步的代码,就让父子进程看到了同一份资源,但还没有进行通信:
//2.创建子进程//3.关闭不需要的fdpid_t id = fork();if(id==0){//子进程//子进程需要写,那就关闭读端colse(pipefd[0]);exit(0);}//父进程//子进程需要读,那就关闭写端colse(pipefd[0]);3.进行通信
#include <iostream> #include <string> #include <cerrno> // errno.h #include <cstring> // string.h #include <unistd.h> #include <sys/types.h> #include <sys/wait.h>const int size = 1024;std::string getOtherMessage() {static int cnt = 0;std::string messageid = std::to_string(cnt); // stoi -> string -> intcnt++;pid_t self_id = getpid();std::string stringpid = std::to_string(self_id);std::string message = "messageid: ";message += messageid;message += " my pid is : ";message += stringpid;return message; }// 子进程进行写入 void SubProcessWrite(int wfd) {int pipesize = 0;std::string message = "father, I am your son prcess!";char c = 'A';while (true){std::string info = message + getOtherMessage(); // 这条消息,就是我们子进程发给父进程的消息write(wfd, info.c_str(), info.size()); // 写入管道的时候,没有写入\0, 有没有必要?没有必要std::cerr << info << std::endl;}std::cout << "child quit ..." << std::endl; }// 父进程进行读取 void FatherProcessRead(int rfd) {char inbuffer[size]; // c99 , gnu g99while (true){sleep(2);// sleep(500);ssize_t n = read(rfd, inbuffer, sizeof(inbuffer) - 1); // sizeof(inbuffer)->strlen(inbuffer);if (n > 0){inbuffer[n] = 0; // == '\0'std::cout << inbuffer << std::endl;}else if (n == 0){// 如果read的返回值是0,表示写端直接关闭了,我们读到了文件的结尾std::cout << "client quit, father get return val: " << n << " father quit too!" << std::endl;break;}else if(n < 0){std::cerr << "read error" << std::endl;break;}// sleep(1);// break;} }int main() {// 1. 创建管道int pipefd[2];int n = pipe(pipefd); // 输出型参数,rfd, wfdif (n != 0){std::cerr << "errno: " << errno << ": "<< "errstring : " << strerror(errno) << std::endl;return 1;}// pipefd[0]->0->r(嘴巴 - 读) pipefd[1]->1->w(笔->写)std::cout << "pipefd[0]: " << pipefd[0] << ", pipefd[1]: " << pipefd[1] << std::endl;sleep(1);// 2. 创建子进程pid_t id = fork();if (id == 0){std::cout << "子进程关闭不需要的fd了, 准备发消息了" << std::endl;sleep(1);// 子进程 --- write// 3. 关闭不需要的fdclose(pipefd[0]);// if(fork() > 0) exit(0);SubProcessWrite(pipefd[1]);close(pipefd[1]);exit(0);}std::cout << "父进程关闭不需要的fd了, 准备收消息了" << std::endl;sleep(1);// 父进程 --- read// 3. 关闭不需要的fdclose(pipefd[1]);FatherProcessRead(pipefd[0]);std::cout << "5s, father close rfd" << std::endl;sleep(5);close(pipefd[0]);int status = 0;pid_t rid = waitpid(id, &status, 0);if (rid > 0){std::cout << "wait child process done, exit sig: " << (status&0x7f) << std::endl;std::cout << "wait child process done, exit code(ign): " << ((status>>8)&0xFF) << std::endl;}return 0; }子进程写入函数(
SubProcessWrite)逻辑:该函数在子进程中运行,用于不断向管道写入消息。具体逻辑如下:
初始化:定义一个
pipesize变量(但在此函数中并未实际使用),初始化一个字符串message作为要发送的基本消息,并定义了一个字符c(同样未使用)。构造消息:在每次循环中,将预定义的
message与通过调用getOtherMessage()函数(该函数未在代码中定义)获取的其他消息合并,形成一个新的info字符串。写入管道:使用
write系统调用将info字符串的内容(不包括结尾的\0字符)写入到管道的写端。由于管道是字节流,通常不需要在写入时添加\0字符。父进程读取函数(
FatherProcessRead)逻辑:该函数在父进程中运行,用于从管道读取子进程发送的消息。具体逻辑如下:
定义缓冲区:声明一个字符数组
inbuffer作为读取数据的缓冲区,但注意size变量并未在给出的代码片段中定义,需要确保在调用此函数之前定义了size的值。读取循环:函数进入一个循环,该循环将不断尝试从管道的读端读取数据。
休眠:在每次尝试读取之前,父进程会休眠2秒,模拟非阻塞或延迟读取的情况。
读取数据:使用
read系统调用从管道的读端读取数据到inbuffer中。读取的字节数由read的返回值n确定。在读取的数据后手动添加一个\0字符作为字符串的结束标志。处理读取到的数据:
- 如果读取到的字节数
n大于0,表示成功读取到数据,将inbuffer作为字符串输出。- 如果
n等于0,表示子进程已经关闭了写端,父进程读取到了文件结尾(EOF),于是退出读取循环。- 如果
n小于0,表示在读取过程中发生了错误,输出错误信息并退出读取循环。退出循环:当读取到文件结尾或发生错误时,退出循环。在函数结束时,并没有显式地关闭读端文件描述符,但在实际情况中,父进程可能需要在其他位置关闭这个文件描述符以避免资源泄漏。
管道的四种情况:
1.如果管道内部是空的,并且write fd没有关闭,读取条件不具备,读进程会被阻塞--wait->读取条件具备<-写入数据。
2.管道被写满,并且read fd不读且没有关闭,管道被写满,写进程会被阻塞(管道被写满--写条件不具备)--wait--写条件具备<-读取数据。
3.管道一直在读,并且写端关闭了wfd,读端read返回值会读到0,表示读到了文件结尾。
4.读端(rfd)直接被关闭了,写端进程会被操作系统直接使用13号文件关掉。相当于进程出现了异常。
管道的五种特征:
1.匿名管道:只用来进行有血缘关系进程之间的进程通信,常用于父子进程之间的通信。
2.管道内部,自带进程之间同步的机制(多执行流执行代码的时候,具有明显的顺序性)。
3.管道文件的生命周期是随进程的。
4.管道文件在通信的时候,是面向字节流的,write的次数和读取的次数不是一 一匹配的。由于管道是面向字节流的,并且可能涉及到缓冲,因此读取操作不一定会按照写入操作的次数来进行。例如,写进程可能分两次写入了100字节和200字节的数据,但读进程可能一次就读取了300字节的数据,或者分三次读取(100字节、100字节、100字节)。
5. 半双工模式:匿名管道(即常见的管道)是半双工的,这意味着数据只能在一个方向上流动,通常用于有亲缘关系的进程间通信,如父子进程之间。




![表空间[MAIN]处于脱机状态](https://img-blog.csdnimg.cn/direct/ec72dacc3d724991adc8baabe9e4c03b.png)