Java8-Stream:
- 一、Stream流概述
- 1.Stream流的特点:
- 2.使用步骤:
- 3.常用方法示例:
- 二、Stream流创建
- 1.常见的创建Stream的方法
- 2. `stream()`或`parallelStream()`方法的使用和选择
- 三、Stream流使用
- Optional
- 案例中使用的实体类
- 1.遍历/匹配(foreach/find/match)
- 2.筛选(filter)
- 3.聚合(max/min/count)
- 4.映射(map/flatMap)
- 5.归约(reduce)
- 6.收集(collect)
- 6.1 归集(toList/toSet/toMap)
- 6.2 统计(count/average)
- 6.3 分组(partitioningBy/groupingBy)
- 6.4 接合(joining)
- 6.5 归约(reducing)
- 7.排序(sorted)
- 8.distinct/limit/skip
一、Stream流概述
Java 8中的Stream流是一种全新的数据处理抽象,它革命性地改变了开发者处理集合数据的方式。Stream API并不是一个真正持有数据的集合,而是一种数据渠道,用于处理具有集合、数组等数据结构支持的数据序列。Stream的核心思想借鉴了函数式编程语言的处理数据方式,强调声明式编程风格,使得开发者能够以更高效、更简洁的方式表达数据处理逻辑。
1.Stream流的特点:
- 不存储数据:Stream自身不存储数据,而是按需计算,对数据源进行操作时,如集合或数组,它并不会改变这些数据源,而是对它们的视图进行操作。
- 惰性求值:Stream的操作分为中间操作(Intermediate Operations)和终端操作(Terminal Operations)。中间操作如
filter,map等会构建一个管道,直到遇到一个终端操作如collect,forEach,count等时,整个流的处理过程才会执行。这种设计可以优化计算资源,只在必要时处理数据。 - 函数式编程:紧密结合Lambda表达式,使得编写处理数据的代码变得极其简洁明了,鼓励无副作用的函数,提高了代码的可读性和可维护性。
- 易于并行处理:Stream API天然支持并行处理,通过调用
parallelStream()方法,可以轻松地利用多核处理器的优势,提高数据处理速度,而无需显式管理线程。
2.使用步骤:
- 创建Stream:可以从集合、数组或生成器等数据源获取Stream。例如,
List<String> names = ...; Stream<String> nameStream = names.stream(); - 链式操作:通过一系列中间操作(如
filter,map,sorted等)构建数据处理管道,每个操作都是一个函数,接受前一个操作的结果作为输入。 - 执行操作:通过调用一个终端操作来执行整个管道,如
collect,forEach,reduce等,执行后Stream不能再被使用。
3.常用方法示例:
filter(Predicate p):过滤出满足条件的元素。map(Function f):对每个元素应用函数f进行转换。sorted()/sorted(Comparator c):对元素排序。distinct():去除重复元素。limit(long maxSize):限制流中的元素数量。collect(Collectors.toList()):将流转换为列表或其他集合。reduce(T identity, BinaryOperator accumulator):聚合操作,如求和、求最大值等。
二、Stream流创建
1.常见的创建Stream的方法
在Java 8中,创建Stream流有多种方式,以下是几种常见的创建Stream的方法:
- 从集合创建:
最常用的创建Stream的方式是通过集合类提供的stream()或parallelStream()方法。几乎所有实现了Collection接口的类(如List, Set, Map(其键或值))都提供了这些方法。
List<String> list = Arrays.asList("a", "b", "c");
Stream<String> stream = list.stream();
- 从数组创建:
使用Arrays.stream()方法可以将数组转换为Stream。
String[] array = {"a", "b", "c"};
Stream<String> stream = Arrays.stream(array);
- 使用Stream.of()创建:
Stream.of()方法允许你直接从多个值创建一个Stream。
Stream<String> stream = Stream.of("a", "b", "c");
- 使用Stream.generate()创建无限流:
当你需要一个无限的Stream时,可以使用Stream.generate()方法,它需要一个Supplier函数来不断提供新的值,通常需要配合limit()来限制流的长度。
Stream<Integer> infiniteStream = Stream.generate(() -> 1).limit(10);
- 使用Stream.iterate()创建迭代流:
Stream.iterate()用于创建一个无限或有限的有序Stream,基于给定的初始值和生成下一个元素的函数。
Stream<Integer> stream = Stream.iterate(0, n -> n + 1).limit(10);
- 其他特殊方式:
对于数值类型,如整数、长整数或双精度浮点数,可以直接使用IntStream, LongStream, DoubleStream的工厂方法,如IntStream.range()或IntStream.rangeClosed()来创建基于范围的数值流。
IntStream intStream = IntStream.range(0, 10);
还可以使用特定API创建流,如从文件读取数据到流中,或者使用正则表达式分割字符串为流等。
Test:
2. stream()或parallelStream()方法的使用和选择
parallelStream是Java 8引入的一个特性,它允许以并行方式处理集合中的元素,可以更有效地利用多核处理器。从集合创建parallelStream非常直接,只需调用集合的parallelStream()方法即可
public static void main(String[] args) {// 创建一个列表List<String> names = Arrays.asList("Alice", "Bob", "Charlie", "David", "Eve");// 使用parallelStream进行并行处理,这里我们将所有名字转换为大写List<String> uppercaseNames = names.parallelStream().map(String::toUpperCase).collect(Collectors.toList());// 输出处理后的名字System.out.println(uppercaseNames);
}
stream
public static void main(String[] args) {// 创建一个列表List<String> names = Arrays.asList("Alice", "Bob", "Charlie", "David", "Eve");// 使用stream进行处理,这里我们将所有名字转换为大写List<String> uppercaseNames = names.stream().map(String::toUpperCase).collect(Collectors.toList());// 输出处理后的名字System.out.println(uppercaseNames);
}

比较与优势:
-
控制性与顺序:
stream是串行执行的,这意味着它按照元素的添加顺序依次处理集合中的每个元素。如果你的处理流程需要保持元素的处理顺序,或者处理过程中有严格的顺序依赖,使用stream是更安全的选择。它提供了对处理流程的精确控制。 -
简单性:对于简单的数据处理任务,使用
stream通常代码更加直观和简洁,不需要考虑多线程同步问题,减少了潜在的并发错误。
使用parallelStream的优势:
-
性能提升:在数据量较大且操作允许并行化的场景下,
parallelStream可以显著提高处理速度。它通过Java的Fork/Join框架自动将任务分割成多个子任务并行执行,充分利用多核处理器的计算能力。 -
资源利用率:对于CPU密集型的任务,
parallelStream能够更好地利用系统资源,减少处理时间,尤其是在多核处理器上。
选择依据:
-
数据量与任务性质:如果数据量不大,或者任务主要是I/O密集型(如文件读写、网络通信),并行处理可能不会带来太多性能上的提升,甚至由于线程创建和上下文切换的开销而降低效率。在这种情况下,使用
stream可能更合适。 -
顺序敏感性:如果处理流程中元素的处理顺序至关重要,比如需要基于前一个元素的处理结果来决定下一个元素的处理方式,那么应该使用
stream来确保顺序。 -
任务并行度:对于那些可以高度并行化且CPU密集型的任务,
parallelStream能发挥其并行处理的优势,特别是在数据量大的情况下。
总之,选择stream还是parallelStream,需要根据具体的应用场景、数据规模以及任务性质来决定,以达到最佳的性能和效率。
三、Stream流使用
Optional
Optional和Stream都是Java函数式编程风格的重要组成部分,它们共同促进了代码的清晰度、安全性和高效性,尤其是在处理集合和可能缺失的数据时。通过结合使用,可以编写出更加健壮和表达力强的Java代码。
Optional类是Java 8引入的一个容器类,用来表示可能存在也可能不存在的值,主要用于避免空指针异常(NullPointerException)。它是一个可以为null的容器对象,如果值存在则isPresent()返回true,调用get()方法会返回该对象;如果值不存在,则isPresent()返回false,调用get()会抛出NoSuchElementException异常。Optional类提供了一系列优雅的方法来处理可能缺失的情况,如orElse()、orElseGet()、orElseThrow()、ifPresent()等,鼓励程序员以更加防御性的编程方式处理空值问题。
Optional类的主要方法包括:
of(T value):创建一个包含非null值的Optional实例。ofNullable(T value):如果给定的值非null,创建一个Optional实例,否则创建一个空的Optional。empty():创建一个空的Optional实例。isPresent():检查是否有值存在。get():如果Optional中有值,则返回该值,否则抛出NoSuchElementException异常。ifPresent(Consumer<? super T> consumer):如果Optional中有值,则执行提供的消费函数。orElse(T other):如果有值则返回该值,否则返回指定的other值。orElseGet(Supplier<? extends T> other):如果有值则返回该值,否则返回由Supplier提供的值。orElseThrow(Supplier<? extends X> exceptionSupplier):如果有值则返回该值,否则抛出自定义异常。
Optional与Stream流的关系:
虽然Optional和Stream都是Java 8中引入的重要特性,它们各自服务于不同的目的,但它们之间存在一定的协同作用。
-
在Stream中使用Optional:你可以在Stream的操作中使用Optional,例如,通过
map操作将流中的每个元素转换为Optional,然后可以链式调用Optional的方法来安全地处理可能的空值情况,而不会中断流的处理流程。 -
Optional作为Stream的终点:在某些情况下,Stream的处理结果可能是一个可选值,这时可以使用
findFirst()、findAny()等终端操作返回Optional,表示可能没有找到匹配项。 -
flatMap与Optional结合:当处理嵌套的Optional或可选的Stream时,
flatMap方法特别有用。它可以将Optional中的值直接映射到另一个Stream,或者在Optional为空时直接返回一个空的Stream,这在处理复杂的链式调用时特别有效,避免了多次检查Optional是否为空。
import java.util.Optional;public class Java8Tester {public static void main(String args[]){Java8Tester java8Tester = new Java8Tester();Integer value1 = null;Integer value2 = new Integer(10);// Optional.ofNullable - 允许传递为 null 参数Optional<Integer> a = Optional.ofNullable(value1);// Optional.of - 如果传递的参数是 null,抛出异常 NullPointerExceptionOptional<Integer> b = Optional.of(value2);System.out.println(java8Tester.sum(a,b));}public Integer sum(Optional<Integer> a, Optional<Integer> b){// Optional.isPresent - 判断值是否存在System.out.println("第一个参数值存在: " + a.isPresent());System.out.println("第二个参数值存在: " + b.isPresent());// Optional.orElse - 如果值存在,返回它,否则返回默认值Integer value1 = a.orElse(new Integer(0));//Optional.get - 获取值,值需要存在Integer value2 = b.get();return value1 + value2;}
}
案例中使用的实体类
@Data
public class Order implements Comparable<Order>{String productName;double price;String customerName;public Order(String productName, double price, String customerName) {this.productName = productName;this.price = price;this.customerName = customerName;}@Overridepublic int compareTo(Order other) {// 这里为了演示,我们假设主要按价格排序,价格相同则按产品名排序int priceCompare = Double.compare(this.price, other.price);return priceCompare != 0 ? priceCompare : this.productName.compareTo(other.productName);}
}@Data
public class Person {String name;@Getterint age;public Person(String name, int age) {this.name = name;this.age = age;}
}@Data
public class Student {private String name;private int age;private double score;private List<String> interestGroups; // 新增字段,表示学生参加的兴趣小组public Student(String name, int age, double score, List<String> interestGroups) {this.name = name;this.age = age;this.score = score;this.interestGroups = interestGroups;}public Student(String name, int age, double score) {}
}
1.遍历/匹配(foreach/find/match)
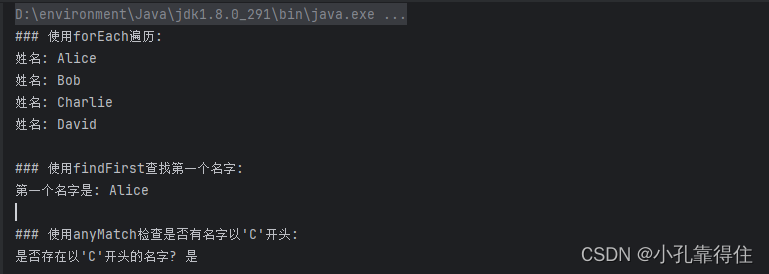
public static void StreamOperationsExample {// 创建一个字符串列表List<String> names = Arrays.asList("Alice", "Bob", "Charlie", "David");// 使用forEach遍历并打印名字System.out.println("### 使用forEach遍历:");names.stream().forEach(name -> System.out.println("姓名: " + name));// 使用findFirst查找第一个名字System.out.println("\n### 使用findFirst查找第一个名字:");Optional<String> firstName = names.stream().findFirst();firstName.ifPresent(name -> System.out.println("第一个名字是: " + name));// 使用anyMatch检查是否有名字以'C'开头System.out.println("\n### 使用anyMatch检查是否有名字以'C'开头:");boolean hasNameStartingWithC = names.stream().anyMatch(name -> name.startsWith("C"));System.out.println("是否存在以'C'开头的名字? " + (hasNameStartingWithC ? "是" : "否"));
}
2.筛选(filter)
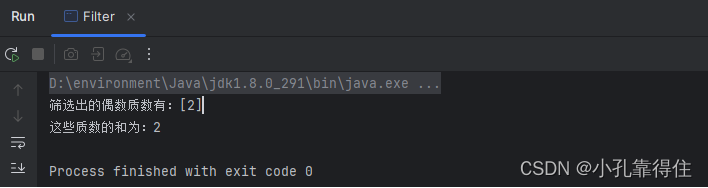
使用Java 8的Stream API中的filter方法,将处理一个数字集合,进行多步筛选操作。例如:筛选出偶数、去除负数,并找出这些数中的质数,最后计算这些质数的和
public class Filter {// 判断是否为质数的辅助方法public static boolean isPrime(int number) {if (number <= 1) return false;for (int i = 2; i <= Math.sqrt(number); i++) {if (number % i == 0) return false;}return true;}public static void main(String[] args) {// 创建一个包含一系列整数的列表List<Integer> numbers = new ArrayList<>();for (int i = -10; i <= 100; i++) {numbers.add(i);}// 使用Stream进行筛选操作// 1. 筛选出非负数// 2. 筛选出偶数// 3. 筛选出质数List<Integer> primeEvenNumbers = numbers.stream().filter(n -> n >= 0) // 去除负数.filter(n -> n % 2 == 0) // 筛选偶数.filter(Filter::isPrime) // 筛选质数.collect(Collectors.toList());// 计算筛选后的质数之和int sumOfPrimes = primeEvenNumbers.stream().mapToInt(Integer::intValue).sum();// 输出结果System.out.println("筛选出的偶数并且是质数有:" + primeEvenNumbers);System.out.println("这些质数的和为:" + sumOfPrimes);}
}
3.聚合(max/min/count)
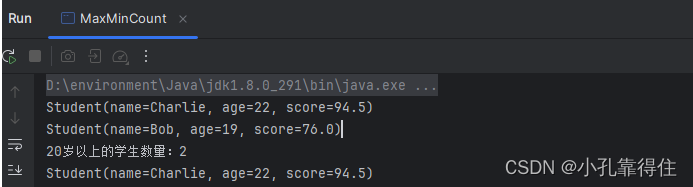
public class MaxMinCount {public static void main(String[] args) {// 创建学生列表List<Student> students = new ArrayList<>();students.add(new Student("Alice", 20, 88.5));students.add(new Student("Bob", 19, 76.0));students.add(new Student("Charlie", 22, 94.5));students.add(new Student("Diana", 21, 89.0));students.add(new Student("Evan", 18, 90.5));// 聚合操作// 1. 查找年龄最大的学生Optional<Student> oldestStudent = students.stream().max(Comparator.comparingInt(Student::getAge));oldestStudent.ifPresent(System.out::println);// 2. 查找分数最低的学生Optional<Student> lowestScoringStudent = students.stream().min(Comparator.comparingDouble(Student::getScore));lowestScoringStudent.ifPresent(System.out::println);// 3. 统计20岁以上的学生数量long countOfStudentsOver20 = students.stream().filter(student -> student.getAge() > 20).count();System.out.println("20岁以上的学生数量:" + countOfStudentsOver20);// 4. 查找年龄最大且分数最高的学生(假设不存在并列最高分的情况)Optional<Student> maxAgeAndScore = students.stream().max(Comparator.comparingInt(Student::getAge).thenComparingDouble(Student::getScore));maxAgeAndScore.ifPresent(System.out::println);}
}
4.映射(map/flatMap)
-
map:map操作是将流中的每个元素应用一个函数进行转换,生成一个新的流。这意味着原流中的每个元素都会被一对一地替换为转换后的结果。例如,如果你有一个数字流,你可以使用
map将每个数字转换为其平方。 -
flatMap:flatMap同样用于转换流中的每个元素,但它与
map的主要区别在于,flatMap能够将流中的每个元素转换为另一个流,然后再将这些流扁平化为一个单一的流。这在处理嵌套结构(如列表的列表)或需要将多个流合并为一个流时特别有用。
案例:使用map将兴趣小组列表转换为字符串;使用flatMap整合所有学生兴趣小组为一个去重列表
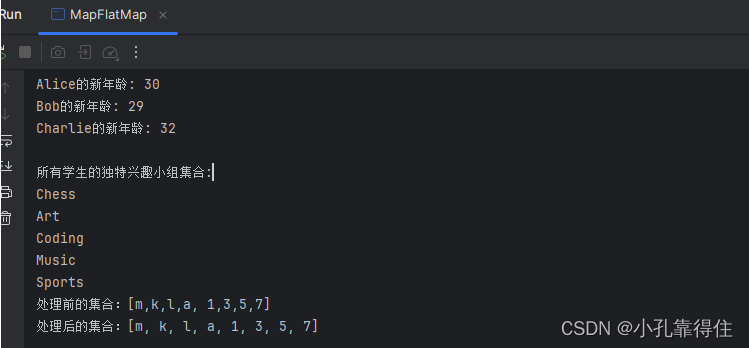
public class MapFlatMap {public static void main(String[] args) {// 初始化学生列表List<Student> students = Arrays.asList(new Student("Alice", 20, 88.5, Arrays.asList("Music", "Art")),new Student("Bob", 19, 76.0, Arrays.asList("Sports", "Chess")),new Student("Charlie", 22, 94.5, Arrays.asList("Chess", "Coding")));// 任务1: 使用map将兴趣小组列表转换为字符串List<String> groupStrings = students.stream().map(student -> String.join(",", student.getInterestGroups())).collect(Collectors.toList());System.out.println("\n每个学生的兴趣小组字符串:");groupStrings.forEach(System.out::println);//任务2:将学生的年龄全部增加10List<Student> studentsNew = students.stream().map(student -> {Student newStudent = new Student(student.getName(), 0, student.getScore(), new ArrayList<>(student.getInterestGroups()));newStudent.setAge(student.getAge() + 10);return newStudent;}).collect(Collectors.toList());studentsNew.forEach(s -> System.out.println(s.getName() + "的新年龄: " + s.getAge()));// 任务3: 使用flatMap整合所有学生兴趣小组为一个去重列表Set<String> uniqueInterestGroups = students.stream().flatMap(student -> student.getInterestGroups().stream()).collect(Collectors.toSet()); // 直接使用toSet去重System.out.println("\n所有学生的独特兴趣小组集合:");uniqueInterestGroups.forEach(System.out::println);//任务4: 使用flatMap将两个字符数组合并成一个新的字符数组List<String> list = Arrays.asList("m,k,l,a", "1,3,5,7");List<String> listNew = list.stream().flatMap(s -> {// 将每个元素转换成一个streamString[] split = s.split(",");Stream<String> s2 = Arrays.stream(split);return s2;}).collect(Collectors.toList());System.out.println("处理前的集合:" + list);System.out.println("处理后的集合:" + listNew);}
}

此外,map系列还有mapToInt、mapToLong、mapToDouble三个函数,它们以一个映射函数为入参,将流中每一个元素处理后生成一个新流。以mapToInt为例
假设我们有一个Person对象列表,我们想要计算所有人的年龄总和、平均年龄以及最年长和最年轻的人的年龄。
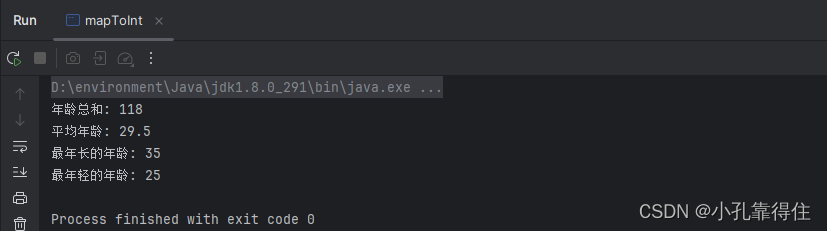
public class mapToInt {public static void main(String[] args) {List<Person> people = Arrays.asList(new Person("Alice", 30),new Person("Bob", 25),new Person("Charlie", 35),new Person("David", 28));// 计算年龄总和int totalAge = people.stream().mapToInt(Person::getAge).sum();System.out.println("年龄总和: " + totalAge);// 计算平均年龄double averageAge = people.stream().mapToInt(Person::getAge).average().orElse(Double.NaN);System.out.println("平均年龄: " + averageAge);// 查找最年长的人的年龄OptionalInt maxAge = people.stream().mapToInt(Person::getAge).max();System.out.println("最年长的年龄: " + (maxAge.isPresent() ? maxAge.getAsInt() : "无"));// 查找最年轻的年龄OptionalInt minAge = people.stream().mapToInt(Person::getAge).min();System.out.println("最年轻的年龄: " + (minAge.isPresent() ? minAge.getAsInt() : "无"));}
}
5.归约(reduce)
reduce方法是处理集合数据、执行聚合操作如求和、求积、求最大值/最小值等场景的强大工具,同时也是理解和掌握函数式编程思想的关键点之一。
在Java的Stream API中,reduce方法是一种强大的操作,它用于将流中的元素通过某种操作“规约”或“合并”成一个单一的结果值。这个过程涉及到一个累积函数,该函数将两个元素作为输入并产生一个输出,然后将此输出与流中的下一个元素再次应用累积函数,如此循环,直到整个流被处理完毕,最终得到一个单一的结果。
归约操作通常涉及四个关键要素:
-
初始值(Optional): 这是归约操作开始时的起始值。并非所有reduce操作都需要初始值,但如果没有提供,则流必须是非空的。
-
累积函数(BinaryOperator): 这是一个接受两个输入参数并返回一个结果的函数。累积函数定义了如何将两个元素合并成一个。例如,加法操作可以作为一个累积函数,用于计算总和。
-
身份元素(Identity): 如果提供了初始值,它就是累积过程的身份元素,对于加法来说,0是身份元素,因为任何数加上0都等于其本身;对于乘法,1是身份元素。
-
并行归约: Stream API中的
reduce方法支持并行处理,这意味着在多线程环境下,流可以被分割成多个部分,各自独立地进行归约,然后再将结果合并。为了确保并行处理的正确性,累积函数必须是关联的且最好是可交换的。
假设我们有一个整数列表,我们想计算所有数字的总和。
不使用初始值
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5);
Integer sum = numbers.stream().reduce((a, b) -> a + b).orElse(0); // 如果流为空,返回0作为默认值
System.out.println(sum); // 输出 15List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5);
Optional<Integer> sumOptional = numbers.stream().reduce((a, b) -> a + b); //返回一个Optional
sumOptional.ifPresent(sum -> System.out.println(sum)); // 输出 15
在这个例子中,没有提供初始值,因此流必须非空。累积函数 (a, b) -> a + b 定义了如何将两个元素相加。
使用初始值
Integer sumWithInit = numbers.stream().reduce(0, (a, b) -> a + b);
System.out.println(sumWithInit); // 同样输出 15
这里提供了初始值0,即使流为空,结果也是0,而不是返回一个Optional。
并行归约
当使用.parallel()方法使流并行处理时,reduce操作会自动适应并行环境,但需要注意累积函数的性质以确保正确性。
Integer parallelSum = numbers.parallelStream().reduce(0, Integer::sum);
System.out.println(parallelSum); // 输出 15,结果与串行相同
在这个并行处理的例子中,我们直接使用了Integer::sum方法引用作为累积函数,它保证了操作的正确性和高效性。
案例
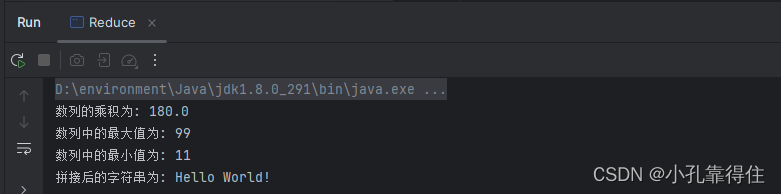
public class Reduce {public static void main(String[] args) {// 初始化一个数列,包含了一些数字List<Double> numbers = Arrays.asList(1.5, 2.0, 3.0, 4.0, 5.0);// 使用reduce计算所有数字的乘积OptionalDouble product = numbers.stream().mapToDouble(Double::doubleValue) // 转换为DoubleStream以进行乘法运算.reduce((a, b) -> a * b); // 累乘操作// 处理结果String resultMessage = product.isPresent()? "数列的乘积为: " + product.getAsDouble(): "数列为空,定义乘积为1";System.out.println(resultMessage);//找出一个数列中的最大值和最小值List<Integer> numberList = Arrays.asList(44, 55, 11, 99, 22);int max = numberList.stream().reduce(Integer.MIN_VALUE, Integer::max);int min = numberList.stream().reduce(Integer.MAX_VALUE, Integer::min);System.out.println("数列中的最大值为: " + max);System.out.println("数列中的最小值为: " + min);//字符串连接List<String> words = Arrays.asList("Hello", " ", "World", "!");String sentence = words.stream().reduce("", String::concat);System.out.println("拼接后的字符串为: " + sentence);}
}
6.收集(collect)
collect方法结合Collectors类的静态方法,能够轻松实现复杂的数据汇聚和转换操作,是处理流数据不可或缺的工具
collect是Java Stream API中的一个关键操作,它用于将流中的元素汇聚成一个结果容器,如List、Set、Map等,或者汇聚成一个特定的结果,如计算总数、平均值等。collect操作高度灵活,是通过Collector接口来定义的,但实际上,大多数情况下,我们会直接使用java.util.stream.Collectors类中提供的静态工厂方法来构造Collector实例,以完成常见的汇聚操作。
Collectors类简介
Collectors类提供了丰富的静态方法,用于创建各种Collector实例,从而实现流的归约操作。这些方法包括但不限于:
toList():将流中的元素收集到一个List中。toSet():将流中的元素收集到一个Set中,自动去除重复项。toMap(Function keyMapper, Function valueMapper):将流中的元素转换为键值对,收集到一个Map中。counting():计算流中元素的数量。summingInt(ToIntFunction mapper):计算流中元素的某个整数属性的总和。averagingDouble(ToDoubleFunction mapper):计算流中元素的某个double属性的平均值。joining(CharSequence delimiter):将流中的元素连接成一个字符串,元素间用指定的分隔符分隔。
6.1 归集(toList/toSet/toMap)
public class ToListToSetToMap {public static void main(String[] args) {List<Order> orders = Arrays.asList(new Order("Apple", 100.0, "Alice"),new Order("Banana", 50.0, "Bob"),new Order("Orange", 80.0, "Alice"),new Order("Pear", 70.0, "Charlie"),new Order("Apple", 120.0, "Alice"));// 1. 收集所有不同的商品名称到一个去重的列表中Set<String> uniqueProductNames = orders.stream().map(Order::getProductName).collect(Collectors.toSet());System.out.println("所有不同的商品名称: " + uniqueProductNames);// 2. 按客户名分组,收集每个客户的订单到单独的列表中Map<String, List<Order>> ordersByCustomer = orders.stream().collect(Collectors.groupingBy(Order::getCustomerName));System.out.println("按客户分组的订单列表: " + ordersByCustomer);// 3. 创建一个映射,键为客户名,值为该客户购买的所有不同商品名的集合Map<String, Set<String>> productsByCustomer = orders.stream().collect(Collectors.groupingBy(Order::getCustomerName,Collectors.mapping(Order::getProductName, Collectors.toSet())));System.out.println("每个客户购买的所有不同商品集合: " + productsByCustomer);// 4. 计算每个客户的总消费额,并以Map形式返回(键为客户名,值为总消费额)Map<String, Double> totalSpentByCustomer = orders.stream().collect(Collectors.groupingBy(Order::getCustomerName,Collectors.summingDouble(Order::getPrice)));System.out.println("每个客户的总消费额: " + totalSpentByCustomer);// 5. 将特定条件的订单收集到列表中(例如,价格超过100的订单)List<Order> expensiveOrders = orders.stream().filter(order -> order.getPrice() > 100.0).collect(Collectors.toList());System.out.println("价格超过100的订单列表: " + expensiveOrders);}
}所有不同的商品名称: [Apple, Pear, Orange, Banana]
按客户分组的订单列表: {Bob=[Order(productName=Banana, price=50.0, customerName=Bob)], Alice=[Order(productName=Apple, price=100.0, customerName=Alice), Order(productName=Orange, price=80.0, customerName=Alice), Order(productName=Apple, price=120.0, customerName=Alice)], Charlie=[Order(productName=Pear, price=70.0, customerName=Charlie)]}
每个客户购买的所有不同商品集合: {Bob=[Banana], Alice=[Apple, Orange], Charlie=[Pear]}
每个客户的总消费额: {Bob=50.0, Alice=300.0, Charlie=70.0}
价格超过100的订单列表: [Order(productName=Apple, price=120.0, customerName=Alice)]
toMap和mapping的区别
toMap直接生成Map,用于键值对的收集;而mapping则是作为数据转换的工具,用于在收集过程中的数据预处理,通常与其它收集器联合使用以达到最终的收集目标。
toMap和mapping在Java 8 Stream API中都是用来转换和收集数据的方法,但它们在用途和应用场景上有明显的区别。
toMap
toMap是一个收集器(Collector),它将流中的元素转换为键值对,并收集到一个Map中。toMap通常接收两个函数作为参数:一个是将流元素转换为Map的键的函数,另一个是转换为Map的值的函数。此外,还可以提供一个合并函数来处理键冲突的情况。toMap直接生成Map类型的输出,适用于将流数据结构转换为Map结构的场景。
例如:
Map<String, Integer> map = people.stream().collect(Collectors.toMap(Person::getName, Person::getAge));
在这个例子中,Person::getName用于提取人名作为键,Person::getAge用于提取年龄作为值。
mapping
mapping是另一个收集器工厂方法,它不是直接生成Map,而是用于在收集过程中对流元素进行中间转换。它通常与其他收集器一起使用,作为数据转换的一步,帮助准备数据进入最终的收集阶段。mapping接收一个函数,用于将流中的每个元素转换为新的形式,然后将这个转换应用于后续的收集操作中,如toList, toSet, 或者是进一步的toMap。
例如,如果我们想先将Person的姓名转换为大写,再收集到一个Set中:
Set<String> names = people.stream().collect(Collectors.mapping(Person::getName, Collectors.toCollection(HashSet::new)).toUpperCase());
注意这里的示例是概念性的说明,实际使用时,由于mapping返回的仍然是一个Collector,所以我们需要正确地嵌套它与其他收集器一起使用,如:
Set<String> names = people.stream().map(Person::getName).map(String::toUpperCase).collect(Collectors.toCollection(HashSet::new));
在这个修正后的例子中,我们先通过map方法转换,然后直接收集到Set中,因为直接使用mapping后接toCollection的语法在实际代码中并不直接适用。
6.2 统计(count/average)
public class CountAverage {public static void main(String[] args) {List<Order> orders = Arrays.asList(new Order("Apple", 100.0, "Alice"),new Order("Banana", 50.0, "Bob"),new Order("Orange", 80.0, "Alice"),new Order("Pear", 70.0, "Charlie"),new Order("Apple", 120.0, "Alice"));// 订单总数统计long totalOrders = orders.stream().count();System.out.println("订单总数: " + totalOrders);// 商品平均价格计算OptionalDouble averagePrice = orders.stream().mapToDouble(Order::getPrice).average();if (averagePrice.isPresent()) {System.out.println("商品平均价格: " + averagePrice.getAsDouble());} else {System.out.println("无法计算平均价格,列表为空");}// 特定商品的购买次数统计 - 以"Apple"为例long applePurchaseCount = orders.stream().filter(order -> "Apple".equals(order.getProductName())).count();System.out.println("\"Apple\"的购买次数: " + applePurchaseCount);// 每个客户的订单数量Map<String, Long> ordersPerCustomer = orders.stream().collect(Collectors.groupingBy(Order::getCustomerName, Collectors.counting()));System.out.println("每个客户的订单数量: " + ordersPerCustomer);}
}
运行结果:
订单总数: 5
商品平均价格: 84.0
"Apple"的购买次数: 2
每个客户的订单数量: {Bob=1, Alice=3, Charlie=1}
6.3 分组(partitioningBy/groupingBy)
- partitioningBy:适用于二分数据,即基于一个条件将数据分为两组。
- groupingBy:适用于多路分组,可以基于任意函数对数据进行灵活的分组,支持更复杂的分组逻辑和多级分组。
public class PartitioningByAndGroupingBy {public static void main(String[] args) {List<Order> orders = Arrays.asList(new Order("Apple", 100.0, "Alice"),new Order("Banana", 50.0, "Bob"),new Order("Orange", 80.0, "Alice"),new Order("Pear", 70.0, "Charlie"),new Order("Apple", 120.0, "Alice"));// 使用partitioningBy根据订单价格是否超过100元分组Map<Boolean, List<Order>> ordersByPriceThreshold = orders.stream().collect(Collectors.partitioningBy(order -> order.getPrice() > 100.0));System.out.println("根据价格是否超过100元分组: " + ordersByPriceThreshold);// 使用groupingBy按客户名分组,并进一步按商品名分组Map<String, Map<String, List<Order>>> ordersGroupedByCustomerAndProduct = orders.stream().collect(Collectors.groupingBy(Order::getCustomerName,Collectors.groupingBy(Order::getProductName)));System.out.println("按客户名和商品名分组的订单: " + ordersGroupedByCustomerAndProduct);// 使用groupingBy并配合reducing计算每个客户的总消费Map<String, Double> totalSpentByCustomer = orders.stream().collect(Collectors.groupingBy(Order::getCustomerName,Collectors.reducing(0.0, Order::getPrice, Double::sum)));System.out.println("每个客户的总消费: " + totalSpentByCustomer);}
}
运行结果:
根据价格是否超过100元分组: {false=[Order(productName=Apple, price=100.0, customerName=Alice), Order(productName=Banana, price=50.0, customerName=Bob), Order(productName=Orange, price=80.0, customerName=Alice), Order(productName=Pear, price=70.0, customerName=Charlie)], true=[Order(productName=Apple, price=120.0, customerName=Alice)]}
按客户名和商品名分组的订单: {Bob={Banana=[Order(productName=Banana, price=50.0, customerName=Bob)]}, Alice={Apple=[Order(productName=Apple, price=100.0, customerName=Alice), Order(productName=Apple, price=120.0, customerName=Alice)], Orange=[Order(productName=Orange, price=80.0, customerName=Alice)]}, Charlie={Pear=[Order(productName=Pear, price=70.0, customerName=Charlie)]}}
每个客户的总消费: {Bob=50.0, Alice=300.0, Charlie=70.0}
6.4 接合(joining)
joining是Java 8 Stream API中的一个收集器(Collector),主要用于将流中的元素连接成一个字符串。它属于Collectors类的一个静态方法,常用于生成CSV格式的字符串、构建SQL语句的IN子句、拼接描述性文本等场景。joining提供了灵活的选项来控制元素间的分隔符、前缀、后缀,以及如何处理空流的情况。
public class Joining {public static void main(String[] args) {List<Order> orders = Arrays.asList(new Order("Apple", 100.0, "Alice"),new Order("Banana", 50.0, "Bob"),new Order("Orange", 80.0, "Alice"),new Order("Pear", 70.0, "Charlie"),new Order("Apple", 120.0, "Alice"));// 使用joining连接所有订单的商品名称,以逗号分隔String productList = orders.stream().map(Order::getProductName).collect(Collectors.joining(", "));System.out.println("所有订单的商品列表: " + productList);}
}
运行结果:
所有订单的商品列表: Apple, Banana, Orange, Pear, Apple
6.5 归约(reducing)
reducing是Java 8 Stream API中的一个操作,它用于将流中的元素通过某个函数累积成一个单一的结果。归约是将集合中的元素反复结合起来,最终得到一个值的过程。这个过程通常包括一个起始值(identity),一个二元操作(binary operator)来合并两个元素,以及一个可选的映射函数(mapping function)来在应用二元操作之前转换元素。
归约的基本概念
- 起始值(Identity):累积操作的初始值,对于加法来说通常是0,乘法则是1。
- 二元操作(Binary Operator):定义了如何将两个元素结合成一个新值的函数。例如,
(a, b) -> a + b表示加法操作。 - 映射函数(Mapping Function):在实际累积之前对流中的每个元素应用的可选转换操作。例如,如果流中是对象,而你想累积它们的某个属性值,就需要先通过映射函数提取这个属性。
public class Reducing {public static void main(String[] args) {List<Order> orders = Arrays.asList(new Order("Apple", 100.0, "Alice"),new Order("Banana", 50.0, "Bob"),new Order("Orange", 80.0, "Alice"),new Order("Pear", 70.0, "Charlie"),new Order("Apple", 120.0, "Alice"));// 使用Collectors.reducing计算所有订单的总金额Double totalAmount = orders.stream().collect(Collectors.reducing(0.0, Order::getPrice, Double::sum));System.out.println("所有订单的总金额为: " + totalAmount);}
}
运行结果:
所有订单的总金额为: 420.0
7.排序(sorted)
在Java 8的Stream API中,sorted是一个中间操作,用于对流中的元素进行排序。排序可以根据元素的自然顺序进行,也可以根据**自定义的比较器(Comparator)**来进行。排序操作不会修改原有的数据源,而是返回一个新的流,其中的元素是排序后的顺序。
排序的分类
- 自然排序:当流中的元素实现了
Comparable接口时,可以使用自然排序。例如,数字和字符串可以直接按照它们的自然顺序进行排序。 - 定制排序:通过提供一个
Comparator对象,可以自定义排序逻辑。这允许根据对象的不同属性或复杂的比较规则进行排序。
public class sorted {public static void main(String[] args) {List<Order> orders = Arrays.asList(new Order("Apple", 100.0, "Alice"),new Order("Banana", 50.0, "Bob"),new Order("Orange", 80.0, "Alice"),new Order("Pear", 70.0, "Charlie"),new Order("Apple", 120.0, "Alice"));// 自然排序示例:假设Order实现了Comparable接口,根据compareTo方法定义的规则排序List<Order> sortedByNatural = orders.stream().sorted().collect(Collectors.toList());System.out.println("自然排序后的订单:");sortedByNatural.forEach(System.out::println);// 定制排序示例:根据价格降序排序,价格相同则按产品名升序排序Comparator<Order> priceDescProductAsc = Comparator.comparing(Order::getPrice, Comparator.reverseOrder()).thenComparing(Order::getProductName);List<Order> sortedByPriceAndProduct = orders.stream().sorted(priceDescProductAsc).collect(Collectors.toList());System.out.println("\n按价格降序、产品名升序排序后的订单:");sortedByPriceAndProduct.forEach(System.out::println);}
}
运行结果:
自然排序后的订单:
Order(productName=Banana, price=50.0, customerName=Bob)
Order(productName=Pear, price=70.0, customerName=Charlie)
Order(productName=Orange, price=80.0, customerName=Alice)
Order(productName=Apple, price=100.0, customerName=Alice)
Order(productName=Apple, price=120.0, customerName=Alice)按价格降序、产品名升序排序后的订单:
Order(productName=Apple, price=120.0, customerName=Alice)
Order(productName=Apple, price=100.0, customerName=Alice)
Order(productName=Orange, price=80.0, customerName=Alice)
Order(productName=Pear, price=70.0, customerName=Charlie)
Order(productName=Banana, price=50.0, customerName=Bob)
8.distinct/limit/skip
在Java 8的Stream API中,distinct, limit, 和 skip 是非常实用的中间操作,用于过滤和控制流中的数据。
- distinct
distinct操作用于去除流中的重复元素。它基于流元素的equals和hashCode方法来判断元素是否相同。这意味着如果流中的对象正确覆写了这两个方法,distinct就能准确地去除重复的对象。
- limit
limit操作用于限制流中元素的数量,只保留前N个元素。这对于性能优化特别有用,尤其是在处理大量数据时,你可能只需要查看前几条记录。
- skip
skip操作则是跳过流中的前N个元素,返回剩余的元素。这在实现分页或者跳过某些已知不需要处理的数据时非常有用。
public class DistinctLimitSkip {public static void main(String[] args) {List<Order> orders = Arrays.asList(new Order("Apple", 100.0, "Alice"),new Order("Banana", 50.0, "Bob"),new Order("Orange", 80.0, "Alice"),new Order("Pear", 100.0, "Charlie"),new Order("Apple", 120.0, "Alice") // 注意这里有重复的产品名但价格不同);// 使用distinct去除按compareTo定义的重复订单(这里会基于价格和产品名去重)List<Order> uniqueOrders = orders.stream().distinct().collect(Collectors.toList());System.out.println("去重后的订单(基于价格和产品名):");uniqueOrders.forEach(System.out::println);// 使用limit获取排序后的前两个订单List<Order> firstTwoSortedOrders = orders.stream().sorted() // 根据compareTo方法排序.limit(2).collect(Collectors.toList());System.out.println("\n排序后的前两个订单:");firstTwoSortedOrders.forEach(System.out::println);// 使用skip跳过排序后的前两个订单,然后取两个List<Order> nextTwoSortedOrders = orders.stream().sorted().skip(2).limit(2).collect(Collectors.toList());System.out.println("\n排序后,跳过前两个的两个订单:");nextTwoSortedOrders.forEach(System.out::println);}
}
运行结果:
去重后的订单(基于价格和产品名):
Order(productName=Apple, price=100.0, customerName=Alice)
Order(productName=Banana, price=50.0, customerName=Bob)
Order(productName=Orange, price=80.0, customerName=Alice)
Order(productName=Pear, price=100.0, customerName=Charlie)
Order(productName=Apple, price=120.0, customerName=Alice)排序后的前两个订单:
Order(productName=Banana, price=50.0, customerName=Bob)
Order(productName=Orange, price=80.0, customerName=Alice)排序后,跳过前两个的两个订单:
Order(productName=Apple, price=100.0, customerName=Alice)
Order(productName=Pear, price=100.0, customerName=Charlie)



![【CTF Web】NSSCTF 3868 [LitCTF 2023]这是什么?SQL !注一下 !Writeup(SQL注入+报错注入+括号闭合+DIOS)](https://img-blog.csdnimg.cn/direct/71c8c6ac12a04c00be3b090839564565.png)


![[STM32+HAL]LD-1501MG舵机二次开发指南](https://img-blog.csdnimg.cn/direct/531e455b98064619acef56090b2aa64a.png)