01 一文理解,Prometheus详细介绍
介绍
大家好,我是秋意零。
Prometheus 是一个开源的系统监控和报警工具包,最初由SoundCloud开发,并在2012年作为开源项目发布。Prometheus 目前由Cloud Native Computing Foundation(CNCF)维护,已经成为监控和报警系统的事实标准,尤其在云原生环境中。
主要功能
- 多维数据模型:通过标签(键值对)定义的时间序列数据模型,可以灵活地对指标进行分类和过滤。
- 强大的查询语言(PromQL):提供了强大的查询语言 PromQL,允许用户对存储的时间序列数据进行复杂的查询和聚合操作。
- 时间序列数据库:内置高效的时间序列数据库,用于存储所有抓取到的指标数据。
- 抓取拉模型:使用 HTTP 协议定期从被监控的目标抓取指标数据,采用“拉”的方式获取数据。
- 自动化服务发现:支持多种服务发现机制,如 Kubernetes、Consul、DNS 等,可以自动发现监控目标。
- 多种数据导出格式:支持多种 Exporter,可以通过标准化的格式暴露各种系统和应用的指标。
- 告警管理:集成 Alertmanager,用于定义和处理告警规则,并支持多种通知方式,如邮件、Slack、PagerDuty 等。
- 可视化:内置简单的图表展示功能,并且与 Grafana 深度集成,可以创建复杂的仪表盘进行数据可视化。
- 扩展性强:通过远程存储接口,可以与其他存储系统集成,扩展 Prometheus 的数据存储能力。
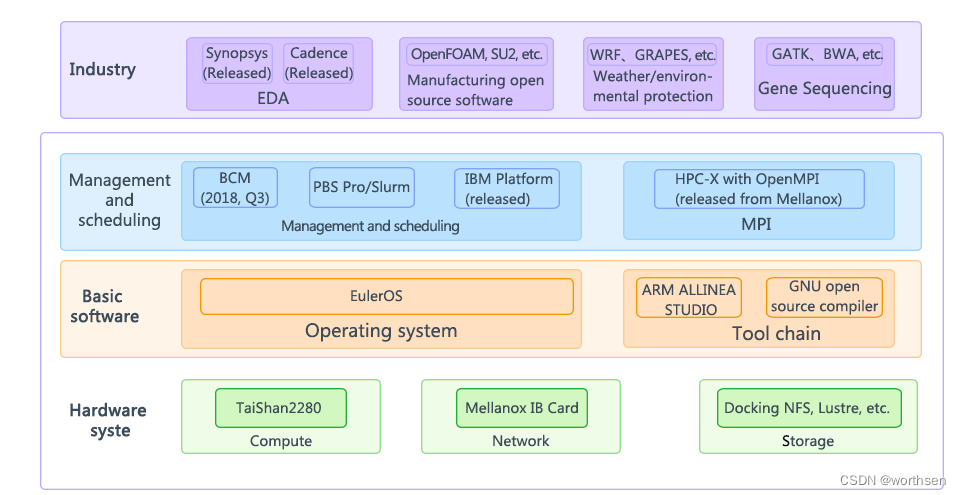
架构图
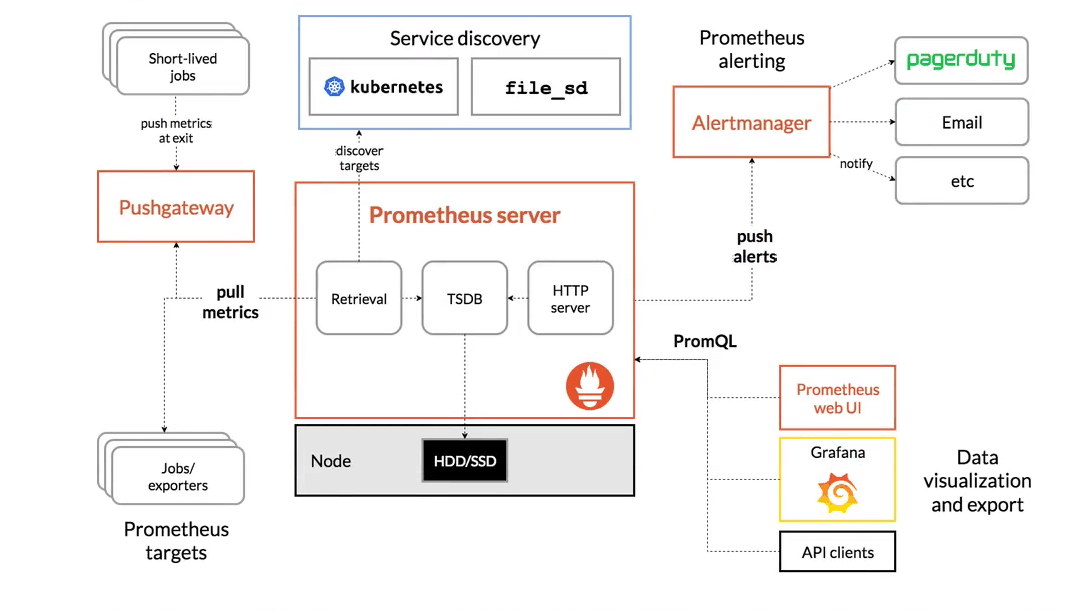
架构图分解:
- 左边部分:采集区(指标收集)
- 中间部分:存储计算区(数据处理)
- 右边部:应用区(告警、展示)
1)采集区
Exporters:用于将各种系统、服务和应用程序的指标转换为 Prometheus 可抓取格式的组件。它们通常运行在被监控系统的旁边,并持续暴露指标给 Prometheus 抓取。
特点:
持续运行: Exporters 通常作为长期运行的服务,持续暴露指标。
主动抓取: Prometheus 定期抓取 Exporters 暴露的指标。
标准化接口: Exporters 通常提供一个标准化的 HTTP 接口,Prometheus 通过配置抓取这些接口的数据。
应用场景:
- 系统级监控: Node Exporter 用于收集主机系统的指标(如 CPU、内存、磁盘使用情况)。
- 服务监控: MySQL Exporter、Redis Exporter 分别用于监控 MySQL 数据库和 Redis 服务。
- 应用监控: Prometheus Python Client 用于监控基于 Python 的应用程序,通过集成 Prometheus 客户端库暴露的指标。
示例:
node_exporter暴露主机系统的指标,Prometheus 定期抓取这些指标。
mysql_exporter暴露 MySQL 数据库的性能指标,Prometheus 抓取这些指标进行监控。
Pushgateway:用于收集短暂或非常驻任务的指标的组件,这些任务可能无法持续运行以供 Prometheus 主动抓取。
特点:
指标推送: 短暂或一次性的作业将指标推送到 Pushgateway,而不是等待 Prometheus 抓取。
临时存储: Pushgateway 作为一个中间层,临时存储这些推送过来的指标,直到 Prometheus 来抓取。
适合短期任务: 主要用于那些无法持续运行的任务,例如批处理作业、临时脚本等。
应用场景:
- 短暂作业监控: 例如,每天凌晨运行一次的数据处理批处理作业,通过 Pushgateway 推送指标。
- 非常驻任务: 例如,临时启动的脚本或作业,这些任务在完成后会立即终止。
示例:
一个定时运行的批处理作业在完成后推送其运行时间和错误数到 Pushgateway,Prometheus 定期从 Pushgateway 抓取这些指标。
2)存储计算区
Prometheus 的 Service Discovery 功能旨在自动发现并监控动态基础设施中的目标(例如,容器化环境中的服务实例)。这是 Prometheus 在云原生环境中广泛使用的一个关键特性。
主要功能:
- 自动发现监控目标:Prometheus 可以自动发现并监控动态变化的服务,无需手动更新配置。这对于容器化应用和动态伸缩的服务特别有用。
- 支持多种服务发现机制:Prometheus 支持多种常见的服务发现机制,涵盖了大多数现代基础设施和编排系统。
支持的服务发现机制:
- Kubernetes:自动发现 Kubernetes 集群中的所有服务、Pod 和 Endpoints,并根据标签和注解进行过滤和选择。
- Consul:使用 Consul 服务发现注册表来自动发现并监控注册的服务。
- DNS SRV 记录:基于 DNS SRV 记录来发现服务,适用于使用 DNS 进行服务发现的环境。
- EC2:自动发现 AWS EC2 实例,根据标签和元数据来筛选目标。
- GCE:自动发现 Google Cloud Engine (GCE) 实例,支持基于标签的过滤。
- Azure:支持 Azure 虚拟机和规模集的自动发现,基于标签进行筛选。
- OpenStack:支持 OpenStack 实例的自动发现,通过 OpenStack API 获取实例信息。
- Triton:支持 Triton 数据中心自动发现实例。
- Marathon:支持 Mesos/Marathon 环境的服务自动发现。
- 文件静态配置:通过静态文件配置实现自定义的服务发现机制,文件内容会被动态重新加载。
使用示例
以下是一个Prometheus 配置,使用 Kubernetes 服务发现的示例:
这段配置将会抓取 Kubernetes 集群中所有属于
default命名空间的 Pod。scrape_configs:- job_name: 'kubernetes-pods'kubernetes_sd_configs:- role: podrelabel_configs:- source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_pod_name]separator: ;regex: default;(.*)target_label: pod_namereplacement: $1action: replace
Prometheus Server 由多个核心组件组成,其中 Retrieval(收集)、TSDB(存储) 和 HTTP Server(查询) 是其关键部分。
a)Retrieval(数据检索) 组件负责从配置的监控目标(scrape targets)中定期抓取指标数据。它是 Prometheus 的数据采集部分。
主要功能:
- 抓取配置:根据
prometheus.yml中的scrape_configs配置,确定需要抓取的监控目标和抓取频率。- 数据抓取:通过 HTTP 请求定期访问每个监控目标的
/metrics端点,获取最新的指标数据。- 标签处理:在抓取过程中对指标数据进行标签重写(relabeling)和筛选,以确保数据的一致性和可用性。
工作流程:
- 配置抓取目标:Prometheus 根据
scrape_configs配置确定抓取目标。- 定期抓取数据:按照配置的抓取频率,通过 HTTP 请求抓取每个目标的指标数据。
- 标签处理和过滤:对抓取到的指标数据进行标签处理和过滤。
- 传递给存储组件:将处理后的数据传递给存储组件(TSDB)。
b)TSDB(时间序列数据库):TSDB(Time Series Database)是 Prometheus 内置的时间序列数据库,用于高效地存储和压缩时间序列数据。
主要功能:
- 数据存储:存储从监控目标抓取的所有指标数据。
- 数据压缩:使用高效的存储格式和压缩算法,减少存储空间占用。
- 数据检索:支持快速的时间序列数据检索,满足查询和分析需求。
工作流程:
- 接收数据:接收 Retrieval 组件抓取并处理后的指标数据。
- 存储和压缩:将数据按照时间序列的方式进行存储和压缩。
- 数据检索:提供高效的数据检索接口,支持 PromQL 查询操作。
存储结构:
- 块存储:TSDB 将数据划分为固定时间跨度的块,每个块包含一组时间序列数据。
- WAL(预写日志):在写入数据之前,首先记录在 WAL 中,确保数据的持久性和可靠性。
- 压缩算法:TSDB 使用了多种压缩算法来优化存储效率。
c)HTTP Server(HTTP 服务器):是 Prometheus 提供的 Web 服务接口,用于与用户和其他系统进行交互。它是 Prometheus 的外部接口部分。
主要功能:
- 查询接口:提供 PromQL 查询接口,允许用户通过 HTTP 请求查询时间序列数据。
- 管理接口:提供各种管理和调试接口,如
/config、/targets、/metrics等,用于查看当前配置、抓取状态和 Prometheus 自身的指标数据。- Web UI:提供内置的 Web 界面,用户可以通过浏览器访问 Prometheus 的查询和管理功能。
工作流程:
- 接收请求:接收用户和其他系统通过 HTTP 发起的请求。
- 处理查询请求:使用 PromQL 从 TSDB 中检索数据并返回结果。
- 处理管理请求:提供当前配置、抓取状态和 Prometheus 自身的监控数据。
- 展示 Web UI:通过 Web 界面展示查询结果和管理信息。
3)应用区
Alertmanager 是 Prometheus 监控系统的重要组成部分,专门用于处理和管理告警(alerts)。
主要功能
- 接收告警:Alertmanager 从 Prometheus Server 接收告警信息。这些告警是基于 Prometheus 的告警规则定义的,当规则条件满足时触发告警。
- 告警去重:对重复的告警进行去重处理,以避免多次发送相同的告警信息。
- 告警分组:将相似的告警进行分组,以便于批量处理和发送。例如,可以根据服务或严重程度对告警进行分组。
- 告警抑制:支持告警抑制规则,可以在某些条件下抑制告警的发送。例如,当有一个高优先级的告警时,可以抑制相关的低优先级告警。
- 告警路由:基于告警内容和标签,定义路由规则,将告警发送到不同的接收器(如邮件、Slack、PagerDuty 等)。
- 多种通知渠道:支持多种通知方式,包括邮件、Slack、PagerDuty、Webhook 等,用户可以根据需求配置不同的通知渠道。
工作流程
告警规则定义:在 Prometheus 的配置文件中定义告警规则,当特定条件满足时触发告警。例如:
groups:- name: examplerules:- alert: HighCPUUsageexpr: cpu_usage_seconds_total > 80for: 5mlabels:severity: criticalannotations:summary: "High CPU usage detected"description: "CPU usage has been above 80% for more than 5 minutes."告警发送到 Alertmanager:Prometheus 评估告警规则,当条件满足时,将告警发送到 Alertmanager。
告警处理:
- Alertmanager 接收告警后,对告警进行去重、分组、抑制等处理。
- 基于配置的路由规则,将告警路由到相应的接收器。
通知发送:Alertmanager 将处理后的告警通过配置的通知渠道发送给用户。例如,通过邮件、Slack、PagerDuty 等。
Grafana 是一个开源的、多平台的数据可视化和监控工具,广泛用于构建和查看数据的实时仪表盘。通过 PromQL 与 Prometheus 集成,以查询和可视化 Prometheus 收集的时间序列数据。
主要功能
- 数据可视化:提供丰富的图表类型,包括时间序列图、柱状图、饼图、热力图等,用户可以根据需要选择合适的图表类型展示数据。
- 多数据源支持:支持多种数据源,包括 Prometheus、Graphite、InfluxDB、Elasticsearch、MySQL、PostgreSQL 等,允许用户从不同的数据源中获取数据进行可视化。
- 动态仪表盘:支持创建动态和交互式的仪表盘,用户可以通过变量和模板在仪表盘中切换不同的视图和数据。
- 警报和通知:集成告警功能,允许用户基于指定的条件触发告警,并通过邮件、Slack、PagerDuty 等渠道发送通知。
- 用户管理:提供用户和团队管理功能,可以定义不同的用户角色和权限,控制仪表盘的访问和编辑权限。
- 插件扩展:支持插件系统,用户可以安装和配置第三方插件,扩展 Grafana 的功能和数据源支持。
- 共享和嵌入:支持将仪表盘和图表共享给其他用户,或嵌入到其他应用和网页中,方便数据展示和协作。
工作流程
安装 Grafana:Grafana 可以通过多种方式安装,例如使用 Docker、Kubernetes、二进制文件或包管理器。
使用 Docker 安装 Grafana:
docker run -d -p 3000:3000 --name=grafana grafana/grafana配置数据源:
- 启动 Grafana 后,访问其 Web 界面(默认地址为
http://localhost:3000),并登录(默认用户名和密码都是admin)。- 进入
Configuration->Data Sources->Add data source,选择需要添加的数据源类型,并根据提示填写数据源连接信息。创建仪表盘:
- 在 Grafana Web 界面中,进入
Dashboards->New Dashboard,创建一个新的仪表盘。- 添加图表和其他可视化组件,配置查询语句和展示方式。
设置告警:
- 在图表配置中,进入
Alert选项卡,定义告警规则和条件。- 配置告警通知渠道,例如邮件、Slack、PagerDuty 等。
共享和嵌入:在仪表盘设置中,选择
Share选项,可以生成共享链接或嵌入代码,将仪表盘或图表嵌入到其他应用中。