个人博客
Java GC问题排查的一些个人总结和问题复盘 | iwts’s blog
是否存在GC问题判断指标
有的比较明显,比如发布上线后内存直接就起飞了,这种也是比较好排查的,也是最多的。如果单纯从优化角度,看当前应用是否需要优化,有一些指标判断:
- 延迟(Latency):也可以理解为最大停顿时间,即STW最长时间。
- 吞吐量(Throughput):例如系统运行了 100 min,GC 耗时 1 min,则系统吞吐量为 99%。
两者是结合的,延迟越低越好,而吞吐量一般有各个业务指标,例如TP999,即99.9%的吞吐量,TP9999则是99.99%。
一般来说尤其是技术还不错的大厂,除了发布是很难碰到相关问题的。。尤其是阿里这种比较卷比的,早就优化甚至为了ppt而优化给整完了,确实没啥优化空间。
包括JVM在内,这种东西能不碰就不碰,真的性价比不高。不过日常代码还是要注意,比如内存泄露这种代码就别写出来了。
这里主要还是聊聊如果真碰到了问题,或者性能不是很行,想要分析是否是GC的话,有一些我个人工作的经验总结以及之前看到的解决方案的分析。
通用排查流程
GC日志分析
有一些网站,dump下来GC日志后上传上去,各种可视化信息。例如:Universal JVM GC analyzer - Java Garbage collection log analysis made easy
分析JVM内存配置
jmap -heap {pid}
先看看JVM启动参数&各代内存分配情况:


先看看分代参数不合理是否会影响本次GC问题。
堆内存对象大小分析
查看存活对象中的实例数量&具体占用内存大小:
jmap -histo 7276 | head -n20
后面的可以忽略,只看前面一部分就ok。
或者直接>重定向写到log中,慢慢看。

主要看是否有哪个对象占用量非常的大,远超过其他对象,如果有,那说明该对象的生成可能是不合理的。
堆文件dump分析
确定有比较异常的对象,才考虑dump下来看。
JProfile之类的比较高端,能直接远程监控VM,但是需要线上配置。自己负责的业务能线上直接操作,或者基建比较nb已经有相关内部工具,那么可以代替dump。
dump命令:
jmap -dump:format=b,file={文件名} {pid}
然后利用可视化工具装载,例如JProfile、JVisualVM。JProfile要破解,JDK自带JVisualVM。
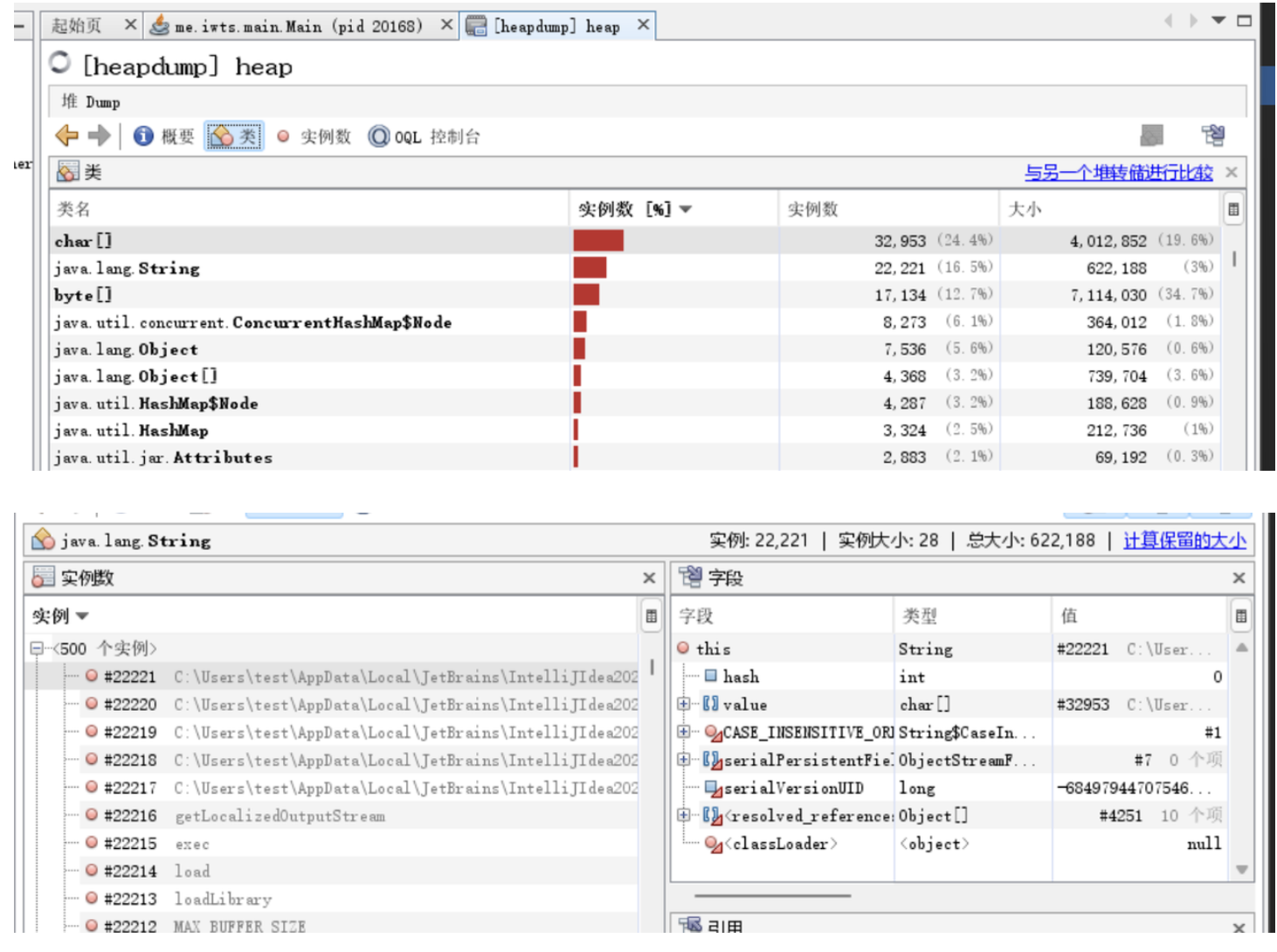
可以具体分析对象到底是哪些实例。
JVisualVM
JDK自带可视化分析工具。
路径JAVA_HOME/bin/jvisualvm.exe
Idea可以下载插件:VisualVM,配置后可以直接拉起比较方便。
本质上是监控,但是一般公司基建都不错,不在乎这种。主要还是快,直接打开exe文件,省的再去JDK下找。
类加载情况
JVM启动参数,增加内容:
-verbose:class # 查看类加载情况
-verbose:gc # 查看虚拟机中内存回收情况
-verbose:jni # 查看本地方法调用的情况
一般是class,启动后java -verbose:class,可以看到当前程序的加载情况。
代码分析
总归是要回归代码的。尤其是上线后导致的问题,更容易排查出问题的到底是在哪,必然是因为上线后更新的代码导致的。
不管怎么调优,最终还是要回归代码的。
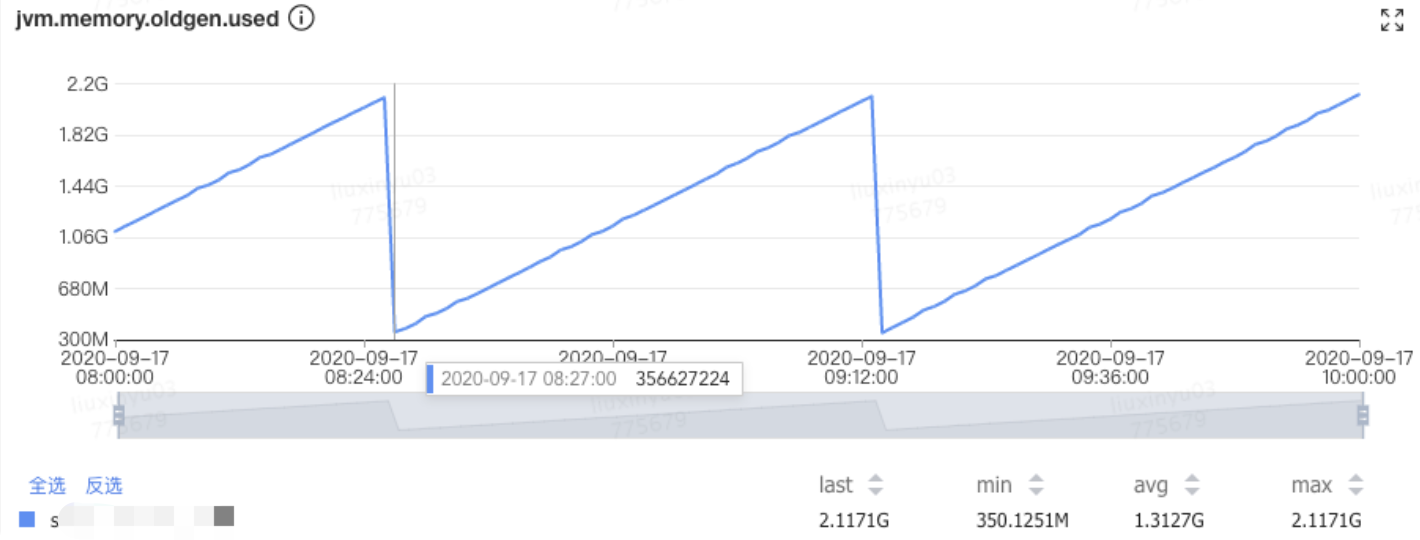
频繁Full GC
内存空间角度
- 先看JVM内存配置,是不是老年代太小,实在没啥空间,频繁触发阈值开启Full GC。
- 是否有内存泄漏,老年代增长速度非常快,回收后跟没回收一样,可能是内存泄漏。
大对象
例如单SQL未分页,同时刻大对象装载进入内存,此时由于超过了Eden区大小,会直接装载进老年代,从而导致Full GC频繁。
这样在观察heap的时候就能看出来,是否会出现某些对象实例少,占用空间大。
内存泄漏
比较经典了,每次Full GC只能回收一点,机器重启后解决问题。标准的内存泄漏。主要看看IO之类的是不是哪里没有close。
Minor GC角度
会不会是Minor GC频率太高导致的。高频次的Minor GC会导致大量的对象年龄增加以进入老年代。
晋升代数设置不合理-调整代数设置
如果Minor GC的频率确实这么高,那么考虑是不是晋升代数设置的太低导致的。例如对象A生命周期60秒,Minor GC 10s一次,而晋升代数设置的是3。
那么A对象30s就会晋升一次,导致大量A对象进入老年代。
如果设置成晋升代数为7,那么在60s后,A对象生命周期结束,年龄为6,Minor GC直接清除,不再丢入老年代。
OOM
一般伴随着Full GC的问题。场景不多,给一些比较常见的。
内存泄漏
同上,一般先是大量Full GC,老年代迟早要被完全填满的,填满后就是OOM。
ThreadLocal内存泄漏
比较经典,可以参考:详解Java ThreadLocal
new大量新类
比较少见,仍然是先高频率Full GC,最终填满导致OOM
内存空间不合理
可能有很多,哪个空间都有可能OOM,此时异常一般也说明了是哪个区OOM了,一般很少见,真碰见一般就是非常低的情况。比如之前CRM不知道谁给设置的,Heap 100MB还是多少,Full GC的🐎都不认识,但是最后只有少量OOM。(大对象还是少)
堆外内存泄漏
感觉还是相当少了,之前吃交易P0的瓜,好像是这个问题。
首先回顾以下堆外内存,JVM分为堆和非堆,堆之外的,包括本地内存、栈等。一般JVM控制的内存大小是固定的,反映在监控上,在内存占用这里基本就是一条直线。
蘑菇街这边基本就是75%这样。
出现时的表现:
- 内存使用率不断上升,甚至开始使用 SWAP 内存。
- GC 时间飙升。
- 线程被 Block。
- 通过 top 命令发现 Java 进程的 RES 甚至超过了 -Xmx 的大小。
例如:

结合上次交易的P0事故。一般发生堆外内存泄漏,都跟我们自己的代码关系不太大。因为大量调用栈这种情况一般不出现,出现也是OOM,不会产生对机器内存大量读写的场景。那么有那种情况下会对内存大量读写?native方法。
那么有个最重要的点:IO通信框架一般是会大量操作本地内存的。
大家都是RPC,内部可能是Netty或者NIO框架,所以RPC框架是很有可能导致堆外内存泄漏的,通信过程中大量使用JNI方法调用本地线程,这样指向了一个非常常见的问题:瞬时大量长时间请求。
比如接口日常请求100QPS,并发量也就10这样,如果跑任务之类的,瞬间QPS达到5000,直接堆外内存就打满了。
交易上次P0基本确定是这个问题。缓存击穿之后大量请求读写接口,Tesla接口QPS达到了万级,瞬间OOM机器开始挂。后续多次没起来也是,机器刚启动,Tesla线程拉起后直接OOM,继续挂。
给个云总的blog:netty oom
这里也有个小知识点:堆外内存是不由JVM管理的,所以大量占用的时候,GC不会被触发,同时JVM基本上也不限制本地内存大小。所以这块很难防止。
Metaspace OOM
具体分析可以看一下这个 深入JVM元空间以及弹性伸缩机制
已经聊了一些Metaspace OOM问题了。本质上就是一般设定都是固定大小不扩容,然后大量新class被load进去,导致OOM。
所以除了RPC框架,也有可能是跟IO相关的其他框架导致的,例如fastjson就有可能会在序列化中利用ASM技术执行字节码增强,产生大量的class对象。
这种情况本质上是类的内部方法建立的对象,存储在Metaspace的klass空间中。那么此时大量请求时就会不断创建,由于没有GC导致OOM。
此时两种方案:
- 设置Metaspace大小。默认情况下一般是非常大的,所以没有上限,设置一个大小触发卸载,可能会缓解这个问题。
- 本质上还是要看代码。一般这种情况还是代码有问题,能频繁不在堆上创建对象,说明该方法一般可以通过static固定到运行时常量池中,全部类只存一份。
Minor GC时间长
晋升代数不合理
和上面的Full GC恰好相反,有可能是晋升代数设置的太高了。那么此时的表现可能是:From区和To区Minor GC一次只能GC掉很少的数据,导致剩余空间小,每次Minor GC后,From/To区进行复制,这个时间花费太长了。
存在大量长生命周期对象
这个跟晋升代数类似,都是高龄对象堆满From/To区,但是不同点在于:此时晋升代数的设置是比较合理的。
那么这种情况就是高龄对象太多,导致的。还是要从heap 文件中找思路。很有可能是某个集合里面对象太多。比如一个list里面存几十万的对象。
那么主要就是先去找大对象,找到大对象后分析大对象的属性,看为什么能这么大。
频繁Minor GC
Eden扩容
一般来说可以对Eden区进行扩容来减少Minor GC次数,也就是说,增加了Minor GC的时间间隔,一次GC可以回收更多的对象。这里需要聊下新生代的GC算法:
- 新生代扫描。
- 复制Eden存活对象到Survivor。
这两步都存在时间消耗,但是复制要比扫描需要的时间多很多。
所以,对于Eden分区的扩容需要根据实际对象生命周期来计算,有这样的场景:
-
对象生命周期<扩容后Minor GC时间间隔。
a. 此时对象只会被扫描,扫描后标记清除,不进行复制。
-
对象生命周期>=扩容后Minor GC时间间隔。
a. 此时对象跟扩容前一样,先扫描后复制。
再结合上面扫描和复制的性能损耗:如果能保证扩容后Minor GC能将原来不能回收的对象给回收掉,那么收益是很大的。
反之,如果对象生命周期长,那么由于Eden区的扩大,会导致扫描时间变长,所以Minor GC时间也会增加。所以,有可能实际工作时间会降低。
所以Eden扩容并不是完美解决方案,依然要先分析对象存活时间之类的参数,然后再考虑扩容。
简而言之:如果对象平均代数低,那么扩容是有效的。
高峰期CMS Full GC时间突刺
CMS Full GC只有在Remark阶段会进行长时间STW,初始标记只是遍历GC Roots,STW很快。例如下面,Remark阶段STW时间为1.39s:

这里可能是Full GC慢的一个很重要的问题:跨代引用。具体可以看下:JVM CMS 在Full GC时针对跨代引用的优化
那么在高峰期可以看,在Full GC发生Remark的时候,新生代对象数量是否有很多,所以会出现这种突刺类型的问题:
-
如果Full GC前已经Minor GC一次。
a. 那么跨代引用扫描很少数据,Full GC快。
-
如果Full GC时恰好新生代很满,例如75%。
a. 那么跨代引用扫描大量数据,Full GC慢。
为了解决这个问题,CMS本身就有一些优化,上面link的文章已经聊到了。
那么同样是上图,发现CMS-concurrent-abortable-preclean阶段执行时间5.35s,超过了默认5s的等待,所以可以认为Remark时是没有进行Minor GC的。
这种情况下可以调高CMSMaxAbortablePrecleanTime(不推荐),或者设置CMSMaxAbortablePrecleanTime(推荐),在Remark前强制执行一次Minor GC。
启动时大量GC后趋于正常(空间震荡)

表现还是比较经典的:
- 启动后频繁GC。
- 每次GC时占用内存空间都很小,但是每次GC后都会增加。
JVM配置中,各个空间一般都是配置两个:一个正常,一个最大。而在JVM初始化的时候,是按正常的分配的。
所以说这种问题就是初始空间配置小了,很快就需要执行GC,调大即可。
显式调用
When you have eliminated the impossibles, whatever remains, however improbable, must be the truth.
如果确实排查不出来问题,全局搜一下
System.gc()
说不定确实有那个sb上传了测试代码,真的在调用。。。