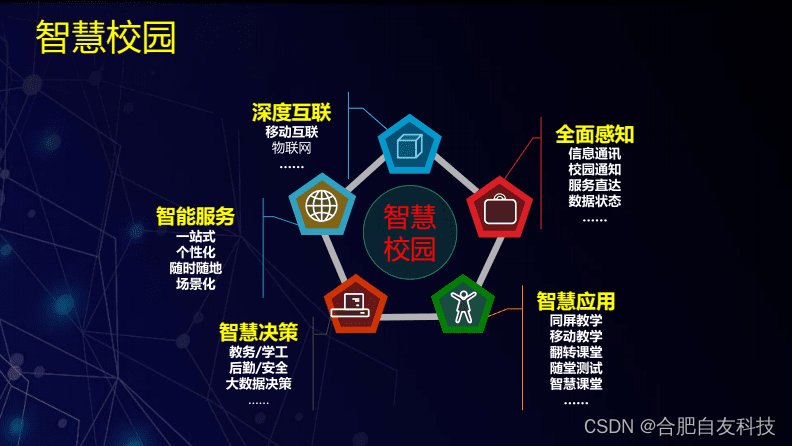
语音控制系统(VCS)提供了便捷的用户界面,涉及智能家居、自动驾驶汽车、智能客服等众多应用场景,已成为现代智能设备不可或缺的一部分。其市场规模预计到2023年达到70亿美元,这种扩张带来了重大的安全挑战,如数据隐私和易受网络攻击的脆弱性,这些问题已成为VCS领域的重要担忧。作为软件和硬件组件的复杂融合,VCS天生就具有多样化的安全漏洞。这些漏洞为攻击者提供了设计一系列攻击方法的途径,挑战VCS设计者预见和理解这些问题。
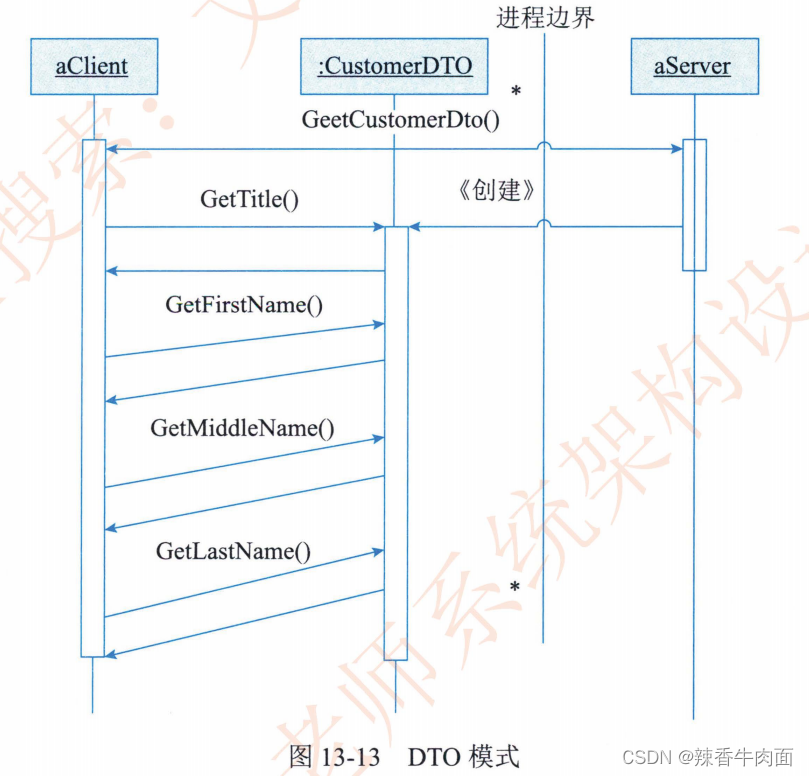
我们介绍一个VCS的分层模型结构,提供了一个新的视角,用于系统地分类和分析现有攻击方法。
1、VCS系统概述
当用户向VCS发出语音命令后,用户将从VCS接收到响应。基于该响应,用户可以选择向VCS发出另一个相关的命令。

分层工作流程图
1.1 物理层
传输通道:在VCS中,通过空气等媒介传输的声音信号会受到各种环境影响,这些影响可能会降低信号的质量。理想情况下,信号传输应该无损失地进行,但实际上,随着距离的增加,信号强度会减弱,减少了携带的信息量。这一限制在捕获足够的信号数据方面提出了挑战,从而限制了声源和目标设备之间的有效操作范围。
声学信号转换:为了让VCS处理声学信号,它们首先必须被转换成数字信号,这个过程涉及两个关键步骤:麦克风,将声学信号转换成电信号;模拟-数字转换器(ADC),将电信号数字化。
1.2 预处理层
信号预处理:信号预处理在VCS中至关重要,因为它涉及处理原始语音信号以提取清晰的语音进行分析。VCS使用带通滤波器将语音信号隔离在300-3400kHz的频率带内。使用多个麦克风进行多通道语音捕获需要采用多通道声学回声消除、混响控制和声源分离等技术。
声学特征提取:从语音信号中提取独特的特征,考虑到说话者特征、环境噪声和传输信道的变化。该过程首先使用滑动窗口技术将处理后的音频分割成帧,然后进行特征提取。常见的特征提取算法包括短时傅里叶变换(STFT)、线性预测编码(LPC)、梅尔频率倒谱系数(MFCC)和感知线性预测(PLP)。
1.3 核心层
声学模型:在预处理层提取特征后,声学模型通过机器学习算法建立这些特征与音素等声学单元之间的统计关系。传统模型通常使用高斯混合模型(GMM)和隐马尔可夫模型(HMM),而现代模型越来越多地采用神经网络,如卷积神经网络(CNN)和循环神经网络(RNN),提高了音素转换的准确性和效率。
语言模型:语言模型预测词序列形成连贯句子的可能性,基于上下文区分同音词。此模型在利用常用词和语法规则控制VCS输出中起着关键作用。模型通常分为统计型(例如,N-gram,HMM)和基于神经网络,后者在现代VCS中变得越来越普遍。
语音词典:该组件通过将单词映射到音素,连接声学模型和语言模型,对VCS中解码用户意图至关重要。语音词典有助于建立模型单元之间的关系,从而辅助系统有效解码。
端到端模型:这些模型直接将声学特征转换为词序列,集成了声学和语言模型的功能。这种简化减少了潜在的攻击载体,增强了系统安全性。包括CTC、Transducer和Attention模型。
自然语言处理(NLP):NLP使机器能够理解和操作自然语言输入。它的发展已经从基于规则的模型发展到统计模型,再到像Word2vec和BERT这样的基于神经网络的模型,反映了行业向更复杂、上下文感知处理的转变。
说话人验证:与VCS的传统用途不同,说话人验证专注于识别说话者而不是解释语音内容。它包括说话人识别(SI)和说话人验证(SV),后者确认说话者的身份。在核心层,说话人验证与标准VCS不同,它通过确定潜在说话者的概率,因此需要专门讨论其安全影响。
1.4 服务层
在理解了核心层中用户的意图之后,VCS在服务层做出响应。利用自然语言生成(NLG),系统通过文本或通过文本到语音(TTS)技术以听觉方式传达所需信息。技术进步已经扩大了VCS的能力,包括第三方服务,实现了更复杂的功能。然而,这种扩展引入了新的安全挑战,例如增加暴露于数据泄露和利用服务漏洞的风险,需要强大的安全措施。
2、对VCS的攻击及防御
VCS对一系列攻击的脆弱性,源于其复杂的架构,这在每一层都可能存在潜在的漏洞。为了使系统设计者能够全面了解这些威胁,本节深入探讨了针对VCS的攻击的性质,从威胁模型、攻击指标和攻击目标的角度进行检查。
2.1 物理层
VCS的物理层在将声音信号转换为数字格式中起着关键作用。这一转换过程涉及通过空气等传输媒介将声音信号传输到麦克风设备,然后将其数字化。然而,由于传输通道中缺乏信号验证以及麦克风设备易受操纵,这一层容易受到多种攻击。
2.1.1 攻击方法
针对传感器的攻击
- 激光信号:利用激光调制,攻击者可以通过超过100米的距离向VCS系统传输恶意指令。
- 电磁波:通过耳机线、充电端口、电源线等传导路径,向VCS系统注入电磁波,并利用非线性放大器将电磁波转换为恶意指令。
声音合成攻击
物理层的声音合成攻击与传感器攻击不同,它们主要利用人耳听不到但大多数麦克风可以接收的超声波信号。这些攻击利用了这样一个事实:高于20千赫兹的超声波可以通过非线性放大器在被麦克风接收后解调,从而干扰VCS的正常功能。
- 超声波信号:利用超声波信号与麦克风进行非线性调制,在VCS系统中产生恶意指令。
- 电流信号:通过开关电源产生的电流波动,生成可被麦克风检测到的超声波信号,从而攻击VCS系统。
2.1.2 防御方案
- 硬件防护:使用无法接收超声波信号的麦克风,类似于iPhone 系列麦克风;使用遮光罩保护麦克风免受激光攻击,或在现有VCS产品中添加信号检测器识别电磁信号如麦克风阵列可以计算不同麦克风处声波的衰减率,识别超声波起源的语音命令。
- 软件防护:在VCS中添加认证机制,如签名认证,用来检测和防御转换攻击。
- 端到端防护:通过传输、转换和认证三个阶段的防护,可以有效防止物理层攻击。
2.2 预处理层
在VCS中,预处理层对于提炼从物理层获得的数字信号至关重要。这一层的主要功能是过滤和增强通常包含人声和背景噪声的音频信号。例如,G.729 [132] 这样的语音活动检测算法被用来隔离包含人类语音的部分,随后应用低通滤波器以减少噪声并提高VCS的识别能力。除了降噪,这层还负责使用诸如DFC、MFCC、LPC、MFCS和PLP等技术从音频信号中提取相关特征,为后续的音素、字符或单词序列识别做准备。然而,这些特征提取过程中的漏洞已被识别出来,允许攻击者执行声音合成和对抗性攻击,欺骗VCS。
2.2.1 攻击方法
语音合成攻击: VCS预处理层的声音合成攻击利用技术创建特定的语音模式,这些模式可能被误解为合法指令。这些攻击可以利用VCS系统中信号处理和特征提取的弱点。例如,攻击者可以通过替换目标语音中的辅音音素来生成看似有语法错误的语音,但实际上仍然可以被VCS系统正确识别。
对抗攻击: 对抗攻击涉及在原始音频样本中引入微小的扰动,以欺骗VCS系统。这些扰动对人类听起来微不可闻,但足以导致VCS系统产生错误的识别结果。对抗攻击通常在特征提取阶段引入扰动,以破坏VCS系统对特征的理解和利用。
2.2.2 防御方案
防御VCS预处理层中的声音合成攻击涉及两种主要策略:检测和预防。
- 检测指的是系统识别攻击并向用户发出警报的能力。如使用像CAPTCHA 这样的验证机制,系统在执行语音命令之前请求用户提供验证响应。
- 预防是指调整VCS滤波器以稍微降低音频质量可以破坏合成音频,这些音频通常缺乏鲁棒性,同时仍然保留对人声的真实语音的识别 。