前言:在数字化时代,图像已成为我们生活、工作和学习的重要组成部分。然而,随着图像获取方式的多样化,图像质量问题也逐渐凸显出来。噪声,作为影响图像质量的关键因素之一,不仅会降低图像的视觉效果,还可能影响图像分析、处理和识别的准确性。因此,图像去噪技术一直是计算机视觉领域的研究热点。
本文所涉及所有资源均在传知代码平台可获取
目录
概述
演示效果
核心代码
写在最后
概述
随着深度学习的发展,各种图像去噪方法的性能不断提升。然而,目前的工作大多需要高昂的计算成本或对噪声模型的假设。为解决这个问题,该论文提出了一种自监督学习方法。该方法使用一个简单的两层卷积神经网络和噪声到噪声损失(Noise to Noise Loss),在只使用一张测试图像作为训练样本的情况下,实现了低成本高质量的图像去噪,本文复现一篇 论文 相关内容,该论文提出的方法主要包含三个部分:成对下采样、残差损失、一致性损失。
该成对下采样器将原始图像下采样为长宽只有原先一半的子图。具体地,其通过将图像分割为大小为 2 × 2 的非重叠补丁,并将每个补丁的对角线像素取平均值并分配给第一个子图,然后将反对角线像素取平均值并分配给第二个子图像。该成对下采样器的示意图如下所示:

在非自监督的情况下,损失函数一般采用噪声图像与干净图像之间平方差的形式:
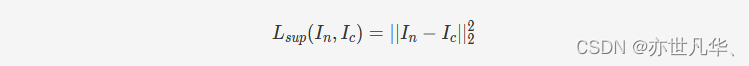
在自监督的情况下,没有干净图像作为训练目标,则可以将两张噪声图像子图互为训练目标,即噪声到噪声损失:
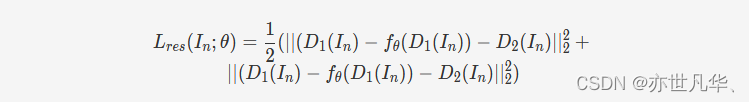
基于噪声独立性假设,可以证明这两种损失的期望值相同。
考虑到残差损失只使用了噪声图像子图训练模型,而测试时需要整张噪声图像作为输入,为了使网络对子图的噪声估计与对原图的噪声估计保持一致,作者还引入了一个一致性损失函数:
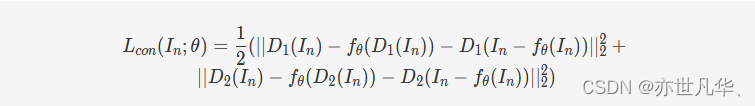
总的损失如下所示:

演示效果
进入工作目录。如果是Linux系统,请使用如下命令:
unzip Image_Denoising.zip
cd Image_Denoising代码的运行环境可通过如下命令进行配置:
pip install -r requirements.txt如果希望在本地运行程序,请运行如下命令:
python main.py如果希望在线部署,请运行如下命令:
python main-flask.py如果希望使用自己的文件路径或改动其他实验设置,请在文件config.json中修改对应参数。以下是参数含义对照表:
| 参数名 | 含义 |
|---|---|
| image | 输入的原始图像路径,默认为"dog.jpg",即我提供的样例 |
| learning_rate | 学习率 |
| epoch_count | 训练轮数 |
| step_size | 学习率衰减周期 |
| gamma | 学习率衰减比 |
| degree | 噪声程度,默认为0.2,范围是0~1 |
| max_bytes | 输入文件大小限制,默认为10240,即10KB,仅用于在线部署限制输入 |
配置环境并运行main.py脚本,效果如下:

核心代码
这段代码实现了一个用于图像去噪的神经网络模型的训练过程,主要包括以下几个部分:
1)下采样函数 diag_sample:该函数用于将输入的图像下采样成两张长宽只有原先一半的子图。首先将输入图像分割成2x2的补丁,然后对每个补丁提取出对角线元素平均值作为第一个子图,提取出反对角线元素平均值作为第二个子图。
2)噪声估计网络 NoisePredictor:这是一个用于估计图像噪声的神经网络模型。它包括若干个卷积层和激活函数,最终输出与输入图像通道数相同的图像,用于表示估计的图像噪声。
3)训练函数 train_once:该函数用于对噪声估计网络进行一轮训练。在训练过程中,通过下采样函数得到噪声图像的子图,然后利用噪声估计网络估计子图的干净图像,计算残差损失和一致性损失,并根据总损失进行梯度反向传播和模型参数更新。
4)加噪函数 add_noise:该函数接受一个图像和噪声程度,输出加入噪声后的图像。在这里使用了正态分布生成随机噪声,并将噪声加到输入图像上,最后通过 clip 函数将像素值限制在 0 到 1 之间。
这些部分共同构成了图像去噪神经网络模型的训练流程,代码如下:
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as npdef diag_sample(image):'''下采样函数,输入图像,输出两张长宽只有原先一半的子图'''# 分割成2x2的补丁height = int(image.shape[2] / 2)width = int(image.shape[3] / 2)image_patch = image[:, :, 0: height * 2, 0: width * 2].view(image.shape[0], image.shape[1], height, 2, width, 2).permute(0, 1, 2, 4, 3, 5)# 对角线元素取平均作为第一个子图image_sub1 = (image_patch[:, :, :, :, 0, 0] +image_patch[:, :, :, :, 1, 1]) / 2# 反对角线元素取平均作为第二个子图image_sub2 = (image_patch[:, :, :, :, 0, 1] +image_patch[:, :, :, :, 1, 0]) / 2return image_sub1, image_sub2class NoisePredictor(nn.Module):'''噪声估计网络,输入图像,输出估计的图像噪声'''def __init__(self, channels=3):super(NoisePredictor, self).__init__()self.net = nn.Sequential(nn.Conv2d(channels, 52, 3, padding=1),nn.LeakyReLU(negative_slope=0.2, inplace=True),nn.Conv2d(52, 52, 3, padding = 1),nn.LeakyReLU(negative_slope=0.2, inplace=True),nn.Conv2d(52, channels, 1))def forward(self, x):return self.net(x)def train_once(image_noise, model, optimizer):'''对模型进行一轮训练'''# 用于计算差方和mse_loss = nn.MSELoss(reduction='sum')model.train()optimizer.zero_grad()# 生成噪声的子图image_noise_s1, image_noise_s2 = diag_sample(image_noise)# 估计噪声图像子图的干净图像image_s1_clean = image_noise_s1 - model(image_noise_s1)image_s2_clean = image_noise_s2 - model(image_noise_s2)# 估计噪声图像的干净图像image_clean = image_noise - model(image_noise)# 生成噪声图像的干净图像的子图image_clean_s1, image_clean_s2 = diag_sample(image_clean)# 残差损失loss_res = (mse_loss(image_s1_clean, image_noise_s2) + mse_loss(image_s2_clean, image_noise_s1)) / 2# 一致性损失loss_con = (mse_loss(image_s1_clean, image_clean_s1) + mse_loss(image_s2_clean, image_clean_s2)) / 2# 总损失loss = loss_res + loss_con# 梯度反向传播loss.backward()# 更新模型参数optimizer.step()def add_noise(image, degree):'''输入图像和噪声程度(0~1),输出加入噪声的图像'''noise = np.random.normal(0, degree, image.shape)noisy_image = np.clip(image + noise, 0, 1)return noisy_image写在最后
在探索自监督高效图像去噪的旅程中,我们见证了技术的飞速进步与无限潜力。通过深度学习技术的赋能,自监督学习在图像去噪领域展现出了卓越的成效。这种方法不仅避免了大量标记数据的依赖,还通过内部生成的信息进行训练,大幅提高了模型的学习效率和泛化能力,随着技术的不断发展和优化,我们有理由相信自监督高效图像去噪将在更多领域展现出其独特的价值。我们期待看到更多创新性的研究和应用,让这项技术为人类社会带来更多的福祉和进步。在这个充满挑战和机遇的时代,让我们共同期待并见证这一技术的美好未来。
详细复现过程的项目源码、数据和预训练好的模型可从该文章下方附件获取。
【传知科技】关注有礼 公众号、抖音号、视频号