文章目录
- 1、代码演示
- 1.1、pom.xml
- 1.2、KafkaProducerPartitioningStrategy.java
- 1.2.1、ProducerConfig.LINGER_MS_CONFIG取 0 值得情况,不轮询
- 1.2.2、ProducerConfig.LINGER_MS_CONFIG取 0 值得情况,轮询
- 1.2.3、ProducerConfig.LINGER_MS_CONFIG取 1000 值得情况,轮询
- 1.2.4、ProducerConfig.LINGER_MS_CONFIG取 1000 值得情况,不轮询
- 2、分区策略
- 2.1、linger.ms参数的含义
- 2.2、linger milliseconds
- 2.3、linger.ms配置参数的理解
1、代码演示
1.1、pom.xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><parent><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><version>3.0.5</version><relativePath/> <!-- lookup parent from repository --></parent><!-- Generated by https://start.springboot.io --><!-- 优质的 spring/boot/data/security/cloud 框架中文文档尽在 => https://springdoc.cn --><groupId>com.atguigu.kafka</groupId><artifactId>kafka-producer</artifactId><version>0.0.1-SNAPSHOT</version><name>kafka-producer</name><description>kafka-producer</description><properties><java.version>17</java.version></properties><dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><scope>test</scope></dependency><dependency><groupId>org.apache.kafka</groupId><artifactId>kafka-clients</artifactId><version>3.0.0</version></dependency></dependencies><build><plugins><plugin><groupId>org.springframework.boot</groupId><artifactId>spring-boot-maven-plugin</artifactId></plugin></plugins></build></project>1.2、KafkaProducerPartitioningStrategy.java
1.2.1、ProducerConfig.LINGER_MS_CONFIG取 0 值得情况,不轮询
不等待,不轮询,默认分区策略
package com.atguigu.kafka.producer;
import org.apache.kafka.clients.producer.*;
import java.util.Properties;
import java.util.UUID;
public class KafkaProducerPartitioningStrategy {public static void main(String[] args) {// 初始化Kafka生产者配置Properties props = new Properties();props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.74.148:9092"); // 指定Kafka broker的地址和端口// 确认消息写入策略,"acks"设置为all表示所有副本都确认消息接收后才会响应props.put("acks", "all");// 消息发送失败时的重试次数,设置为0表示不重试props.put("retries", 0);// 发送缓冲区等待时间,等待1秒后,发送//props.put(ProducerConfig.LINGER_MS_CONFIG, 1000);props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer"); // 指定键的序列化器props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer"); // 指定值的序列化器// 分区器选择RoundRobinPartitioner,实现消息在主题分区间的轮询分配//props.put(ProducerConfig.PARTITIONER_CLASS_CONFIG, "org.apache.kafka.clients.producer.RoundRobinPartitioner" );// 创建Kafka生产者实例Producer<String, String> producer = new KafkaProducer<>(props);for (int i = 0; i < 1000; i++) {producer.send(new ProducerRecord<String, String>("my_topic3", "88"), new Callback() {@Overridepublic void onCompletion(RecordMetadata recordMetadata, Exception e) {if (e == null) {System.out.println("recordMetadata.partition() = " + recordMetadata.partition());}}});}producer.close();}
}
1.2.2、ProducerConfig.LINGER_MS_CONFIG取 0 值得情况,轮询
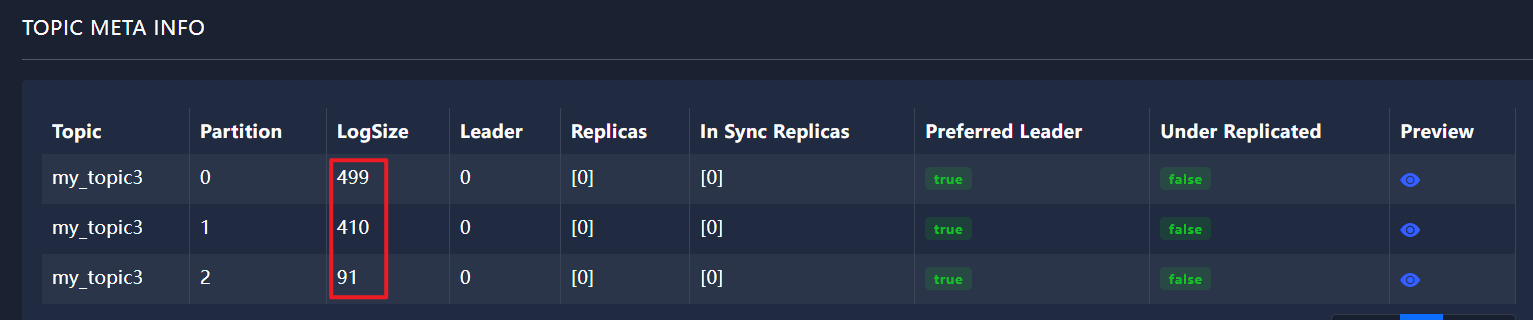
不等待,立即发送,轮询策略
package com.atguigu.kafka.producer;
import org.apache.kafka.clients.producer.*;
import java.util.Properties;
import java.util.UUID;
public class KafkaProducerPartitioningStrategy {public static void main(String[] args) {// 初始化Kafka生产者配置Properties props = new Properties();props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.74.148:9092"); // 指定Kafka broker的地址和端口// 确认消息写入策略,"acks"设置为all表示所有副本都确认消息接收后才会响应props.put("acks", "all");// 消息发送失败时的重试次数,设置为0表示不重试props.put("retries", 0);// 发送缓冲区等待时间,设置为0表示不等待,立即发送props.put(ProducerConfig.LINGER_MS_CONFIG, 0); props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer"); // 指定键的序列化器props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer"); // 指定值的序列化器// 分区器选择RoundRobinPartitioner,实现消息在主题分区间的轮询分配props.put(ProducerConfig.PARTITIONER_CLASS_CONFIG, "org.apache.kafka.clients.producer.RoundRobinPartitioner" );// 创建Kafka生产者实例Producer<String, String> producer = new KafkaProducer<>(props);for (int i = 0; i < 1000; i++) {producer.send(new ProducerRecord<String, String>("my_topic3", "88"), new Callback() {@Overridepublic void onCompletion(RecordMetadata recordMetadata, Exception e) {if (e == null) {System.out.println("recordMetadata.partition() = " + recordMetadata.partition());}}});}producer.close();}
}
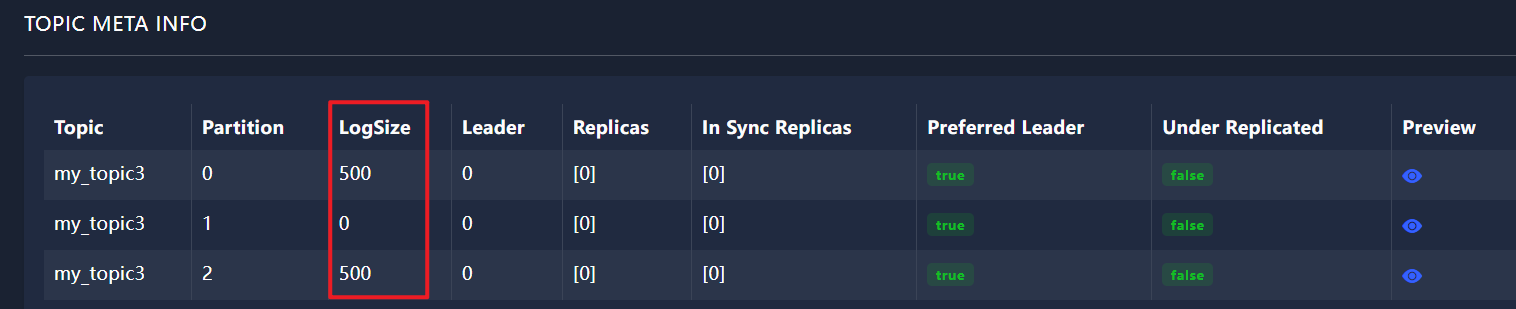
1.2.3、ProducerConfig.LINGER_MS_CONFIG取 1000 值得情况,轮询
等待1秒后发送,轮询策略
package com.atguigu.kafka.producer;
import org.apache.kafka.clients.producer.*;
import java.util.Properties;
import java.util.UUID;
public class KafkaProducerPartitioningStrategy {public static void main(String[] args) {// 初始化Kafka生产者配置Properties props = new Properties();props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.74.148:9092"); // 指定Kafka broker的地址和端口// 确认消息写入策略,"acks"设置为all表示所有副本都确认消息接收后才会响应props.put("acks", "all");// 消息发送失败时的重试次数,设置为0表示不重试props.put("retries", 0);// 发送缓冲区等待时间,等待1秒后,发送props.put(ProducerConfig.LINGER_MS_CONFIG, 1000);props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer"); // 指定键的序列化器props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer"); // 指定值的序列化器// 分区器选择RoundRobinPartitioner,实现消息在主题分区间的轮询分配props.put(ProducerConfig.PARTITIONER_CLASS_CONFIG, "org.apache.kafka.clients.producer.RoundRobinPartitioner" );// 创建Kafka生产者实例Producer<String, String> producer = new KafkaProducer<>(props);for (int i = 0; i < 1000; i++) {producer.send(new ProducerRecord<String, String>("my_topic3", "88"), new Callback() {@Overridepublic void onCompletion(RecordMetadata recordMetadata, Exception e) {if (e == null) {System.out.println("recordMetadata.partition() = " + recordMetadata.partition());}}});}producer.close();}
}
1.2.4、ProducerConfig.LINGER_MS_CONFIG取 1000 值得情况,不轮询
等待1秒后发送,不轮询
package com.atguigu.kafka.producer;
import org.apache.kafka.clients.producer.*;
import java.util.Properties;
import java.util.UUID;
public class KafkaProducerPartitioningStrategy {public static void main(String[] args) {// 初始化Kafka生产者配置Properties props = new Properties();props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.74.148:9092"); // 指定Kafka broker的地址和端口// 确认消息写入策略,"acks"设置为all表示所有副本都确认消息接收后才会响应props.put("acks", "all");// 消息发送失败时的重试次数,设置为0表示不重试props.put("retries", 0);// 发送缓冲区等待时间,等待1秒后,发送props.put(ProducerConfig.LINGER_MS_CONFIG, 1000);props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer"); // 指定键的序列化器props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer"); // 指定值的序列化器// 分区器选择RoundRobinPartitioner,实现消息在主题分区间的轮询分配//props.put(ProducerConfig.PARTITIONER_CLASS_CONFIG, "org.apache.kafka.clients.producer.RoundRobinPartitioner" );// 创建Kafka生产者实例Producer<String, String> producer = new KafkaProducer<>(props);for (int i = 0; i < 1000; i++) {producer.send(new ProducerRecord<String, String>("my_topic3", "88"), new Callback() {@Overridepublic void onCompletion(RecordMetadata recordMetadata, Exception e) {if (e == null) {System.out.println("recordMetadata.partition() = " + recordMetadata.partition());}}});}producer.close();}
}
2、分区策略
kafka的生产者分区策略
默认分区策略:减少重新建立分区连接的性能损耗 开发使用最多的分区方式,采用黏性分区,默认向第一次连接上的主题分区发送消息,直到消息累积到 batch.size大小(16kb)轮询分区策略:每个分区接收一次消息(linger.ms决定生产者一次批量发送多少条消息 到一个分区中),开发中一定不会用轮询分区策略,顶多自定义,因为轮询性能太差,频繁跟不同的分区建立连接,大数据会用轮询策略
2.1、linger.ms参数的含义
在Kafka的生产者(Producer)配置中,props.put("linger.ms", 1); 这行代码是用于设置生产者的linger.ms参数的。
linger.ms参数的含义是:生产者会在发送消息之前等待更多消息被发送到同一个分区(partition)的额外时间(以毫秒为单位)。这样做的目的是为了提高吞吐量,因为将多个消息批量发送到同一个分区可以减少网络传输的开销和服务器端的I/O开销。
具体来说,当你设置了linger.ms参数(比如设置为1毫秒),Kafka生产者会尝试在发送消息之前等待1毫秒,看看是否还有其他的消息要发送到同一个分区。如果有,这些消息将会被合并成一个批次(batch)一起发送。
注意,设置linger.ms参数可能会增加消息的延迟,因为生产者会等待指定的时间以合并更多的消息。所以,这个参数需要在吞吐量和延迟之间进行权衡。
这里是一个简化的示例,展示如何在使用Java Kafka生产者时设置linger.ms参数:
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;import java.util.Properties;public class KafkaProducerExample {public static void main(String[] args) {Properties props = new Properties();props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");// 设置linger.msprops.put("linger.ms", 1);KafkaProducer<String, String> producer = new KafkaProducer<>(props);// 发送消息...producer.close();}
}
在这个示例中,我们创建了一个KafkaProducer对象,并设置了包括linger.ms在内的多个配置参数。然后,你可以使用这个生产者对象来发送消息到Kafka集群。
2.2、linger milliseconds
linger.ms 的英文全称就是 “linger milliseconds”,其中 “linger” 是指延迟或等待,“milliseconds” 是毫秒的意思。
在 Kafka 的 Producer 配置中,linger.ms 参数用于控制 Producer 在发送消息之前等待更多消息到达相同分区(partition)的时间,以便可以将这些消息一起发送,从而提高吞吐量。默认情况下,linger.ms 的值为 0,这意味着 Producer 收到消息后会立即发送,不进行任何延迟。
linger.ms 参数与 batch.size 参数一起使用时,可以实现更复杂的消息发送策略。batch.size 参数定义了单个批次(batch)中允许的最大消息字节数。当 Producer 收到消息时,它会尝试将消息添加到当前批次中。如果linger.ms 大于 0,并且当前批次中的消息数量尚未达到 batch.size 的限制,那么 Producer 会等待 linger.ms 指定的时间,看看是否还有更多的消息要发送到相同的分区。如果有,这些消息将被添加到当前批次中;如果没有,那么在当前时间到达后,Producer 将发送当前批次中的所有消息。
需要注意的是,linger.ms 参数的值应该根据具体的业务场景和性能需求进行调整。较小的值可以提高消息的实时性,但可能会降低吞吐量;较大的值可以提高吞吐量,但可能会增加消息的延迟。因此,在实际应用中需要根据实际情况进行权衡和选择。
2.3、linger.ms配置参数的理解
在Kafka中,linger.ms是一个配置参数,用于控制生产者(producer)在发送消息到broker之前的等待时间,以便将更多的消息累积到同一批次中,从而提高吞吐量。linger.ms的取值可以是任何非负整数,表示毫秒数。
以下是关于linger.ms的一些关键点:
- 如果
linger.ms设置为0,生产者会立即发送消息到broker,不会等待其他消息来累积到同一批次。 - 如果
linger.ms设置为大于0的值,生产者会等待该指定的毫秒数,或者直到达到batch.size(批次大小)的限制,然后将累积的消息作为一个批次发送到broker。 - 增大
linger.ms的值可能会提高吞吐量,因为可以累积更多的消息到同一批次中,减少网络传输的次数。但是,这也会增加消息的延迟。 linger.ms的取值可以根据具体的应用场景和需求进行调整。在需要低延迟的场景中,可以将linger.ms设置为较小的值;在可以容忍一定延迟的场景中,可以尝试增大linger.ms的值以提高吞吐量。
综上所述,linger.ms的取值并没有固定的几个选项,而是可以根据实际需求设置为任何非负整数。在配置Kafka生产者时,需要根据具体的业务场景和需求来选择合适的linger.ms值。