作者:来自 Elastic Jedr Blaszyk
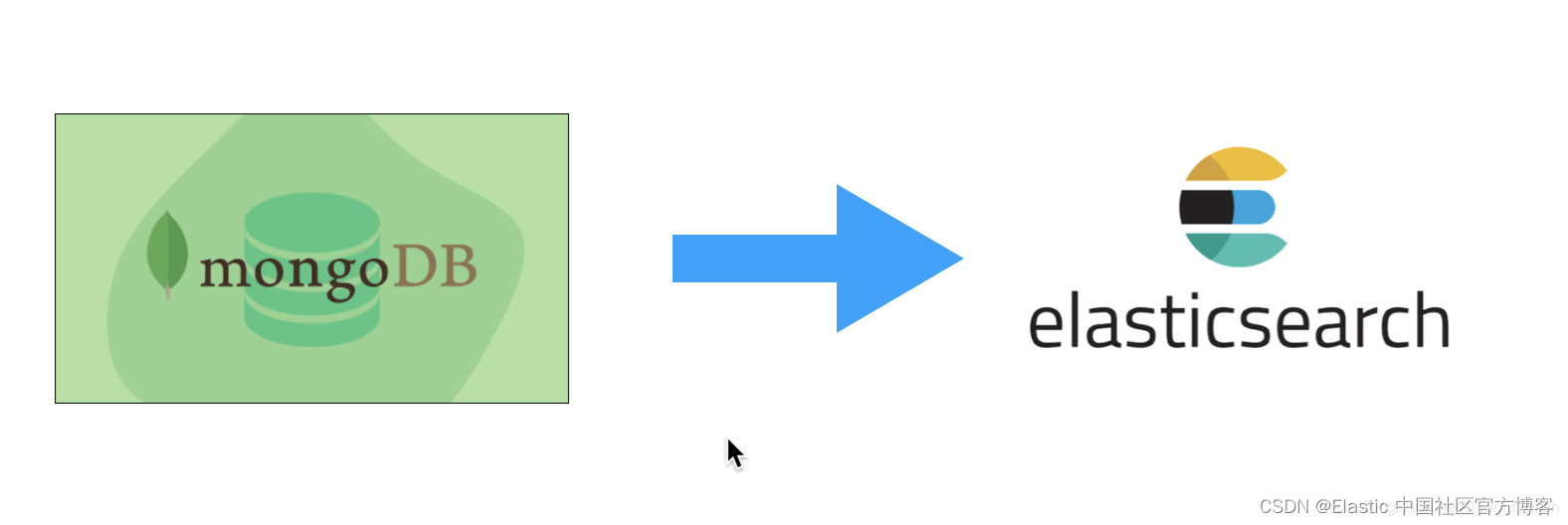
Elasticsearch 支持一系列摄取方法。 其中之一是 Elastic Connectors,它将 SQL 数据库或 SharePoint Online 等外部数据源与 Elasticsearch 索引同步。 连接器对于在现有数据之上构建强大的搜索体验特别有用。 例如,如果你管理一个电子商务网站,并希望通过跨产品目录的语义搜索来增强客户体验,Elastic Connectors 可以让这一切变得简单。 如果你的产品目录存储在 Elastic 支持的 connector sources 中包含的数据库中,则只需单击几下即可将此数据提取到索引中。 如果你的源当前不受支持,连接器框架使你能够实现自定义连接器并修改现有连接器。 有关更多详细信息,你可以阅读如何为 Elasticsearch 创建自定义连接器。
现在 Connector API 处于测试版,你可以直接从命令行界面完全管理 Elastic 连接器。 这对于特定工作流程特别有用,因为它可以自动化连接器管理、监控和测试,无需在终端和 Kibana UI 之间来回切换。
在这篇博文中,我们将研究从 MongoDB 同步产品目录并将其索引到 Elasticsearch 中,以构建搜索体验。 让我们开始吧!
注意:我们将主要使用终端命令来执行所有步骤。 但是,你还可以通过 Kibana UI 管理连接器,方法是导航到 Search -> Connectors 部分,或者使用 Kibana 开发控制台在此处执行请求。 此外,所有 API 调用都与 Elasticsearch Serverless 和任何标准 ES 部署兼容,无论托管在 Elastic Cloud 还是你自己的基础设施上。
有关从 MongoDB 同步数据到 Elasticsearch 的更多阅读,请参阅 “Elasticsearch:使用 MongoDB connector 同步数据到 Elasticsearch”。
先决条件
- Docker 安装在你的机器上
- 终端中可以使用 curl 和 jq
- Elasticsearch 无服务器或 Elasticsearch 版本 >= 8.14.0
Elasticsearch Serverless
我们将数据提取到 Elasticsearch Serverless,因为它允许你针对你的用例部署和使用 Elastic,而无需管理底层 Elastic 集群,例如节点、数据层和扩展。 Serverless 实例由 Elastic 完全管理、自动扩展和自动升级,因此你可以更加专注于从数据中获取价值和洞察。
你可以通过导航到 Elastic Cloud 部署概述并单击无服务器部分中的创建项目来创建 serverless 项目。
下一步是选择正确的部署类型。 由于我们对增强搜索体验感兴趣,因此我们选择 Elasticsearch。 你的新部署应在几分钟内准备就绪。
要安全地连接到 Elasticsearch 集群,请确保在 shell 控制台中将 ES_URL 和 API_KEY 导出为环境变量。 你可以按照下面概述的步骤找到它们的值并导出它们。
打开你的 Elasticsearch 部署,然后选择 cURL 作为我们的客户端。
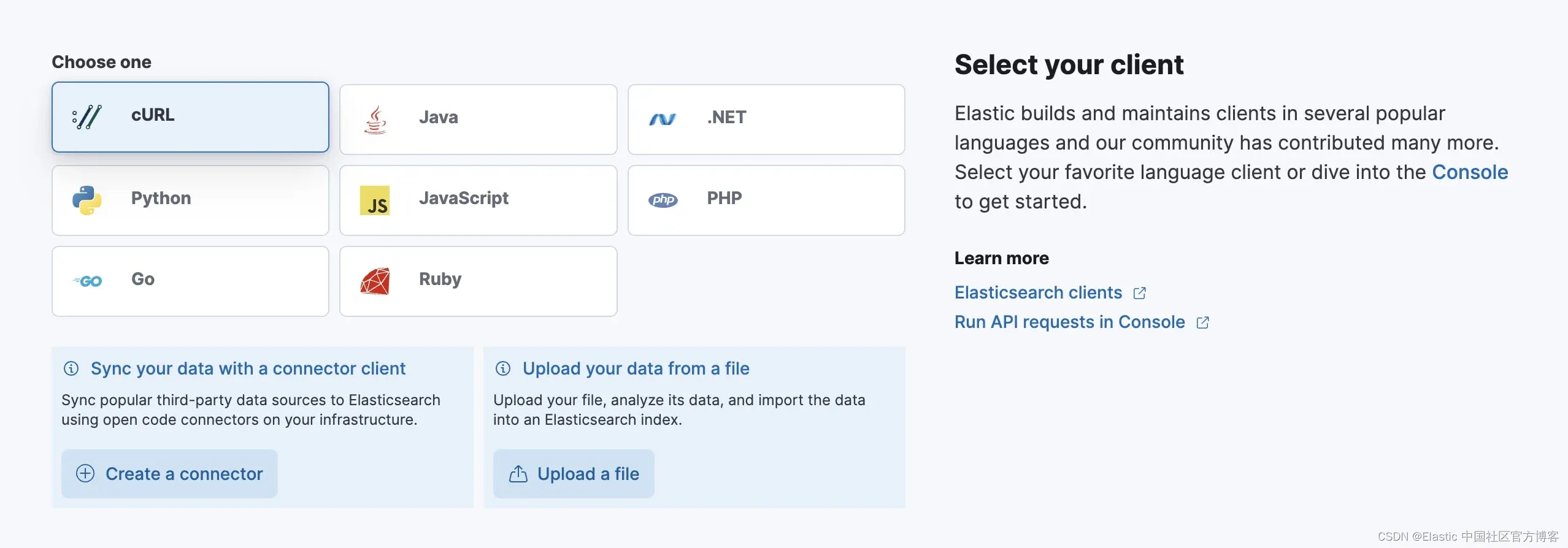
为你的部署生成一个 API 密钥,你可以将其称为 “connector-api-key”。

将 ES_URL 和 API_KEY 导出到 shell 控制台。
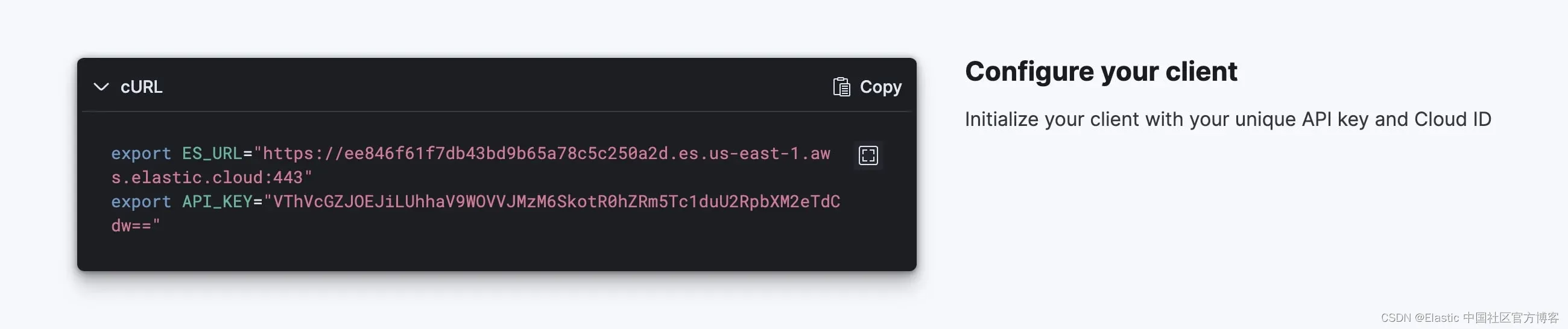
太好了! UI 就这样了,现在请随意关闭 ES 浏览器并让我们提取一些数据。
我们的产品目录
对于此示例,我们假设产品目录存储在 MongoDB 中。 但是,产品目录可以托管在 Elastic 连接器支持的任何数据源中。 对于尚不支持的任何数据源,该框架允许定义自定义连接器。
如果你需要使用示例数据设置本地 MongoDB 实例,你可以在附录中找到快速指南:使用 Docker 启动 MongoDB 实例,或者你也可以使用任何其他现有的 MongoDB 实例。 请记住,使用不同的实例可能需要调整如下所述的连接器配置。
在以下步骤中,我们假设 MongoDB 实例包含一个product_catalog 数据库,其中的 products 集合包含以下项目:
{ name: "Gadget", description: "A useful gadget", price: 19.99, stock_count: 100 }
{ name: "Widget", description: "An essential widget", price: 29.99, stock_count: 0 }
{ name: "Doodad", description: "A fancy doodad", price: 49.99, stock_count: 200 }创建 MongoDB 连接器
现在我们已经运行了 Elasticsearch,并且示例产品目录已准备好同步,我们可以专注于将数据索引到 Elasticsearch 中。
让我们从创建连接器开始。 我们的连接器会将数据从 MongoDB 同步到产品目录 ES 索引。 该索引将在第一次数据同步期间使用适当的映射创建,我们稍后会再讨论这一点。 此外,你可以随时使用更新索引名称 API 调用修改连接器索引。
export CONNECTOR_ID=product-catalog-connectorcurl -X PUT "${ES_URL}/_connector/${CONNECTOR_ID}" \
-H "Authorization: ApiKey "${API_KEY}"" \
-H "Content-Type: application/json" \
-d'
{"service_type": "mongodb","name": "Product Catalog","index_name": "product-catalog"
}
'
连接器应该被创建。让我们定义我们的工作目录:
export PROJECT_ROOT=$(pwd)让我们按照连接器文档中所述配置并启动自管理连接器服务:从 Docker 容器运行:
mkdir $PROJECT_ROOT/connectors-config
cat > $PROJECT_ROOT/connectors-config/config.yml << EOF
connectors:- connector_id: $CONNECTOR_IDservice_type: mongodb
elasticsearch.host: $ES_URL
elasticsearch.api_key: $API_KEY
EOF启动本地连接器服务。 检查官方 Docker 存储库中的可用版本并选择最近发布的版本。
export CONNECTOR_VERSION=8.13.4.0export CONNECTOR_VERSION=8.13.4.0docker run \
-v "$PROJECT_ROOT/connectors-config:/config" \
--rm \
--tty -i \
--network host \
docker.elastic.co/enterprise-search/elastic-connectors:$CONNECTOR_VERSION \
/app/bin/elastic-ingest \
-c /config/config.yml
启动连接器服务后,你应该看到如下所示的日志行:
[Connector id: product-catalog-connector, index name: product-catalog] Connector is not configured yet....使用 get connector 端点验证连接器是否已连接,并检查其状态(应为 need_configuration)和 last_seen 字段(请注意,时间以 UTC 格式报告)。 last_seen 字段表示连接器已成功连接到 Elasticsearch。
注意:我们使用 jq,一个轻量级命令行 JSON 处理器来处理原始响应。
curl -X GET "${ES_URL}/_connector/${CONNECTOR_ID}?pretty" \
-H "Authorization: ApiKey "${API_KEY}"" | jq '{id, index_name, last_seen, status}'{"id": "product-catalog-connector","index_name": "product-catalog","last_seen": "2024-05-13T10:25:52.648635+00:00","status": "error"
}现在我们必须配置连接器以使用我们的产品目录对 MongoDB 进行身份验证。 有关连接器配置的指导,你始终可以使用 MongoDB 连接器参考文档。 你还可以检查作为 get 请求的一部分返回的连接器 configuration 属性中的已注册 schema:
curl -X GET "${ES_URL}/_connector/${CONNECTOR_ID}?pretty" \
-H "Authorization: ApiKey "${API_KEY}"" | jq '.configuration | with_entries(.value |= {label, required, value})'{"tls_insecure": {"label": "Skip certificate verification","required": true,"value": false},"password": {"label": "Password","required": false,"value": ""},"database": {"label": "Database","required": true,"value": ""},"direct_connection": {"label": "Direct connection","required": true,"value": false},"ssl_ca": {"label": "Certificate Authority (.pem)","required": false,"value": ""},"ssl_enabled": {"label": "SSL/TLS Connection","required": true,"value": false},"host": {"label": "Server hostname","required": true,"value": ""},"collection": {"label": "Collection","required": true,"value": ""},"user": {"label": "Username","required": false,"value": ""}
}
我们可以使用 update configuration 端点来设置连接器配置值。 由于连接器是通过连接器协议与 Elasticsearch 通信的 stateless 服务,因此n 可能需要在连接器服务启动后等待一段时间才能注册配置 schema。 对于我们的测试设置,提供所需的 MongoDB host、database 和我们想要同步数据的 collection 就足够了。 我故意跳过用户名和密码的身份验证,因为我们在本地运行 MongoDB,并且禁用了安全性,以使我们的玩具示例更简单。
curl -X PUT "${ES_URL}/_connector/${CONNECTOR_ID}/_configuration" \
-H "Authorization: ApiKey "${API_KEY}"" \
-H "Content-Type: application/json" \
-d'
{"values": {"host": "mongodb://127.0.0.1:27017","database": "product_catalog","collection": "products"}
}
'
触发按需同步
现在我们已经创建并配置了连接器,并且连接器服务正在本地运行,我们可以同步数据以查看一切是否端到端正常工作。
curl -X POST "${ES_URL}/_connector/_sync_job" \
-H "Authorization: ApiKey ${API_KEY}" \
-H "Content-Type: application/json" \
-d'
{"id": "'"$CONNECTOR_ID"'","job_type": "full"
}
'
第一次同步时,将创建 product-catalog 索引。
同步开始可能需要 30 秒,你可以通过检查连接器服务日志来检查同步何时开始,你应该看到类似以下内容:
[Connector id: product-catalog-connector, index name: product-catalog, Sync job id: 37PQYo8BuUEwFes5cC9M] Executing full sync或者,你可以通过列出连接器的同步作业来检查上次同步作业的状态。 查看 status、error(如果有)和 indexed_document_count 属性可以帮助你了解当前作业的状态。
curl -X GET "${ES_URL}/_connector/_sync_job?connector_id=${CONNECTOR_ID}&size=1&pretty" \
-H "Authorization: ApiKey ${API_KEY}" | jq '.results[] | {status, error, indexed_document_count}'{"status": "completed","error": null,"indexed_document_count": 3
}
创建同步作业后,其状态将设置为 pending,然后连接器服务将开始执行同步,状态将更改为 in_progress。
最终,同步作业将完成,其状态将设置为 completed(如上面的响应所示)。 我们可以检查其他同步统计信息,例如 indexed_document_count 等于 3 并且它与我们的虚拟数据集计数匹配。 耶!
我们可以检查数据索引到的连接器索引,我们还应该看到 3 个条目!
curl -X POST "${ES_URL}/product-catalog/_search?pretty" \
-H "Authorization: ApiKey "${API_KEY}"" | jq '.hits.total.value'3
保持 ES 索引与源同步
在现实生活中,目录会发生变化。 例如,现有商品的库存数量可能会发生变化,或者你可能会在目录中引入更多产品。 在这种情况下,我们可以将连接器配置为定期同步数据,以了解 MongoDB 中的最新数据源。
让我们启用同步计划并将其设置为每 15 分钟运行一次。 我们可以使用更新调度端点:
curl -X PUT "${ES_URL}/_connector/${CONNECTOR_ID}/_scheduling" \
-H "Authorization: ApiKey "${API_KEY}"" \
-H "Content-Type: application/json" \
-d'
{"scheduling": {"full": {"enabled": true,"interval": "0 0,15,30,45 * * * ?"}}
}
'
只要你的连接器服务继续在后台运行,它就会按照设定的时间间隔安排和启动同步作业。 连接器服务是轻量级的,空闲时不会消耗太多资源,因此让它在后台运行应该没问题。
当然,你可以随时打开 Kibana 并导航到 “Connectors” 选项卡,例如检查其状态、作业历史记录或在 UI 中更改其计划。
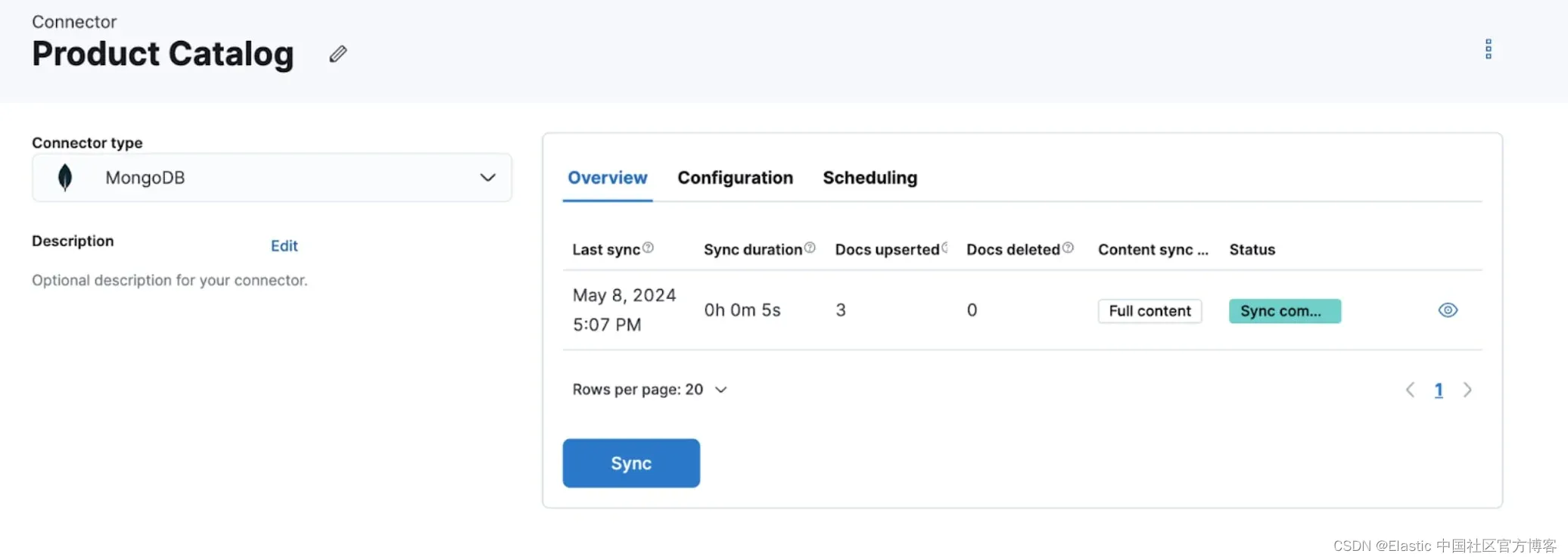
同步规则 - 仅索引你想要的内容
虽然你的产品目录可能包含数千种商品,但目前可能只有少数商品有库存(请参阅我们示例中的 stock_count)。
在我们的产品目录中,假设我们的目标是仅索引那些有库存的产品。 因此,缺货的产品 “Widget” 应该从我们的搜索索引中排除。
连接器服务支持两种方法来实现此目的:
- 基本同步规则:这些规则使你能够在将内容索引到 Elasticsearch (ES) 索引之前在连接器级别过滤内容。 本质上,所有数据都是从你的源检索的,但你可以使用基本过滤规则控制转发哪些数据。 此功能适用于所有连接器。
- 高级同步规则:此方法允许你直接在源处过滤数据。 考虑这样的 SQL 语句:SELECT * WHERE stock_count > 0;,它使你能够从源中仅获取所需的数据。 高级同步规则可以显着缩短同步时间,尤其是在仅对完整数据集的一小部分建立索引时。 请注意,高级过滤可用于特定的一些连接器。
在我们的示例中,请参阅有关支持的同步规则的 MongoDB 连接器文档。 我们可以设置高级过滤规则以仅使用更新过滤端点索引库存产品,该更新过滤端点允许你书写同步规则:
curl -X PUT "${ES_URL}/_connector/${CONNECTOR_ID}/_filtering" \
-H "Authorization: ApiKey "${API_KEY}"" \
-H "Content-Type: application/json" \
-d'
{"advanced_snippet": {"value": {"find": {"filter": {"stock_count": {"$gt": 0}}}}}
}
'
现在连接器将验证同步规则草稿。 初始草稿验证状态将被 edited。 如果提供的同步规则草稿有效,其验证状态将被标记为 valid,并且草稿同步规则将由正在运行的连接器服务激活。
你始终可以通过检查 GET _connetor/product-catalog-connector 请求的输出来检查同步规则草稿的验证状态。 如果你的草稿已经过验证,你应该会看到:
- 其过滤草稿验证状态标记为 valid
- 它应该被列为活动过滤(因为你的草稿已被激活)
curl -X GET "${ES_URL}/_connector/${CONNECTOR_ID}?pretty" \
-H "Authorization: ApiKey "${API_KEY}"" | jq '{filtering}'{"filtering": [{"domain": "DEFAULT","draft": {"advanced_snippet": {"updated_at": "2024-05-09T12:49:18.155532096Z","created_at": "2024-05-09T12:49:18.155532096Z","value": {"find": {"filter": {"stock_count": {"$gt": 0}}}}},"rules": [...],"validation": {"state": "valid","errors": []}},"active": {"advanced_snippet": {"updated_at": "2024-05-09T12:49:18.155532096Z","created_at": "2024-05-09T12:49:18.155532096Z","value": {"find": {"filter": {"stock_count": {"$gt": 0}}}}},"rules": [...],"validation": {"state": "valid","errors": []}}}]
}如果高级过滤规则在语法上不正确,例如 MongoDB 查询中的 filter 关键字将有一个拼写错误 filterrr,你应该在草稿的验证部分中看到相应的错误,例如:
{"filtering": [{"domain": "DEFAULT","draft": {"advanced_snippet": {"updated_at": "2024-05-10T13:26:11.777102054Z","created_at": "2024-05-10T13:26:11.777102054Z","value": {"find": {"filterrr": {"stock_count": {"$gt": 0}}}}},"rules": [...],"validation": {"state": "invalid","errors": [{"ids": ["advanced_snippet"],"messages": ["data.find must not contain {'filterrr'} properties"]}]}},"active": {...}}]
}
下一次同步应该只索引有库存的商品,因此现在你应该在搜索索引中找到 2 个 stock_count 大于 0 的产品。
curl -X POST "${ES_URL}/product-catalog/_search?pretty" \
-H "Authorization: ApiKey "${API_KEY}"" | jq '.hits.total.value'2
在摄取时生成向量嵌入
要启用语义搜索,请在摄取期间生成数据的向量嵌入。 你需要调整索引映射并创建摄取管道。 有关详细说明,请查看以下部分:使用 Elasticsearch 作为向量数据库或参阅教程:使用 ELSER 进行语义搜索。
创建并配置管道后,假设其名为 e5-small-product-catalog,你可以使用以下命令将自定义摄取管道添加到连接器:
curl -X PUT "${ES_URL}/_connector/${CONNECTOR_ID}/_pipeline?pretty" \
-H "Authorization: ApiKey "${API_KEY}"" \
-H "Content-Type: application/json" \
-d'
{"pipeline": {"extract_binary_content": true,"name": "e5-small-product-catalog","reduce_whitespace": true,"run_ml_inference": true}
}
'
每次从源同步数据时,这都会自动生成数据的向量嵌入。
监控你的连接器
有两个端点对于连接器监控特别有用:
- 列出连接器端点
- 列出同步作业端点
例如,你可以设置定期连接器运行状况检查,该检查将:
- 检索所有连接器的 ID
- 对于每个连接器 ID,检索关联的同步作业
- 记录同步作业类型(
full,incremental,access_control) - 跟踪其状态,例如
pending,in_progress,error,canceled或 completed - 跟踪平均同步持续时间
- 跟踪任何错误
- 记录同步作业类型(
API 调用如下所示,首先检索你的连接器 ID:
curl "${ES_URL}/_connector?pretty" -H "Authorization: ApiKey "${API_KEY}"" | jq '[.results[] | {id}]'[{"id": "product-catalog-connector"}
]
对于上述调用中的每个连接器,让我们列出其同步作业历史记录,注意作业按最新顺序列出:
curl -X GET "${ES_URL}/_connector/_sync_job?connector_id=product-catalog-connector&size=100&job_type=full" \
-H "Authorization: ApiKey "${API_KEY}"" | jq '[.results[] | {id, job_type, status, indexed_document_count, total_document_count, started_at, completed_at, error}]'[{"id": "fAJlZo8BPmy2hB-4_7jr","job_type": "full","status": "completed","indexed_document_count": 2,"total_document_count": 2,"started_at": "2024-05-11T06:45:39.779977+00:00","completed_at": "2024-05-11T06:45:43.764303+00:00","error": null}
]
如果你的连接器处理各种类型的同步作业,你可以将 job_type URL 参数设置为 full、incremental 或 access_control。 如果未提供此参数,则不会按作业类型过滤响应。
你可以使用状态字段来监控系统的运行状况。 考虑以下场景:
- 如果失败作业的百分比(status == error)不断增加,则可能表明你的数据源或 Elasticsearch 集群存在问题。 在这种情况下,请检查填充的错误字段以确定特定问题。
- 如果待处理作业(status == pending)的数量不断增加,则可能表明你的连接器服务无法维持所需的计划。 例如,将大型数据源与设置为每分钟运行的计划同步可能会导致框架中出现背压。 新的待处理作业将继续安排,但我们可能无法在下一个安排的作业开始之前开始并完成它们。
此外,你可以使用 started_at 和 completed_at 来跟踪同步的平均持续时间。 平均同步持续时间的突然变化可能是引发自动警报的良好条件。
自动化技巧
Connector API 可以成为支持自动化的强大工具。 以下是一些自动化工作流程的技巧。
- 对连接器配置使用版本控制时,请注意不要暴露配置值。 利用 GitHub 环境变量等专用解决方案或与 Vault 等服务的集成。
- 同样的注意事项也适用于用于连接 Elasticsearch 的任何凭据(用户名、密码和 API 密钥)。
- 应用于连接器服务 config.yml 的任何更改(例如添加新连接器)都需要重新启动服务。
下一步
现在,连接器服务将持续将你的数据库与 Elasticsearch 索引同步,让你能够将注意力转移到完善基于我们数据的搜索体验。
如果你希望合并来自其他来源的更多数据,你可以设置和配置更多连接器。 请参阅 Elastic 的连接器目录以获取支持的数据源。 如果你的源当前不受支持,连接器框架允许你开发自定义连接器并修改现有连接器。 有关更多详细信息,请参阅为 Elasticsearch 创建自定义连接器的指南。
使用 Elasticsearch Serverless 可以为任何开发人员带来显着的好处。 它由 Elastic 完全托管、自动扩展和自动升级,让你可以在新特性和功能发布后立即使用它们。 这使你可以更加专注于从数据中获取价值和见解,而无需管理底层集群。
对于构建搜索体验的后续步骤,我建议阅读以下文章:
- 语义搜索文档
- 教程:使用 ELSER 进行语义搜索
- 将文档级安全性 (DLS) 添加到你的内部知识搜索
- RBAC 和 RAG - 最好的朋友
此外,探索我们的 Elasticsearch 客户端库,它可以帮助加速你的搜索体验的发展。
附录
使用 Docker 启动 MongoDB 实例
为了本博文的目的,我们使用 Docker 来启动一个包含一些示例数据的数据库。
docker run --name mongodb -d -p 27017:27017 mongo:latest实例启动后,你可以准备并复制脚本以将虚拟数据插入到你的产品目录中。
这是 insert-data.js
// Connect to the MongoDB database
db = db.getSiblingDB('product_catalog');// Insert data into the 'products' collection
db.products.insertMany([{ name: "Gadget", description: "A useful gadget", price: 19.99, stock_count: 100 },{ name: "Widget", description: "An essential widget", price: 29.99, stock_count: 0 },{ name: "Doodad", description: "A fancy doodad", price: 49.99, stock_count: 200 }
]);
将脚本复制到容器并将数据插入 MongoDB:
docker cp insert-data.js mongodb:/insert-data.js
docker exec -it mongodb mongosh product_catalog /insert-data.js
你可以通过查询 Product_catalog 数据库中的条目来验证你的数据是否存在,此命令应返回你的 3 个条目:
docker exec -it mongodb mongosh product_catalog --eval "db.products.find().toArray()"现在,你的 MongoDB 实例应该已运行,并且产品目录数据已准备好用于本示例。
你可以使用任何来源的数据构建搜索。 观看此网络研讨会,了解 Elasticsearch 支持的不同连接器和源。
准备好自己尝试一下了吗? 开始免费试用。
原文:Elasticsearch Connector API: How to ingest data into Elasticsearch Serverless — Elastic Search Labs



![线上 | OpenSergo - [规范]](https://img-blog.csdnimg.cn/direct/0ecfa2bab42f42e8abfd14b9282f5cb4.png)