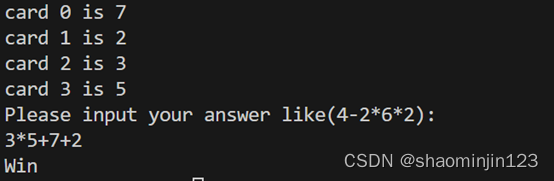
六,selenium
想要下载PDF或者md格式的笔记请点击以下链接获取
python爬虫学习笔记点击我获取
Scrapy+selenium详细学习笔记点我获取
Python超详细的学习笔记共21万字点我获取

1,下载配置
## 安装:
pip install selenium## 它与其他库不同的地方是他要启动你电脑上的浏览器, 这就需要一个驱动程序来辅助. ## 这里推荐用chrome浏览器## chrome驱动地址:http://chromedriver.storage.googleapis.com/index.html
https://googlechromelabs.github.io/chrome-for-testing/#stable
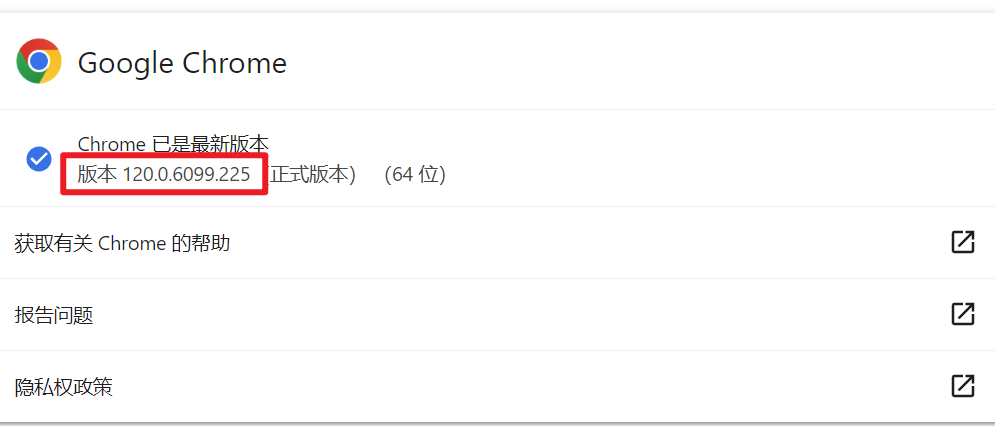
## 先查看自己谷歌浏览器的版本,我的是120.0.6099.255
然后打开这个驱动地址
https://googlechromelabs.github.io/chrome-for-testing/#stable

选stable 稳定版
然后在网页上搜索我们的版本,只要前三个部分对应上就行,也就是120.0.6099
如下图,就这样我们找到了我们想要的版本
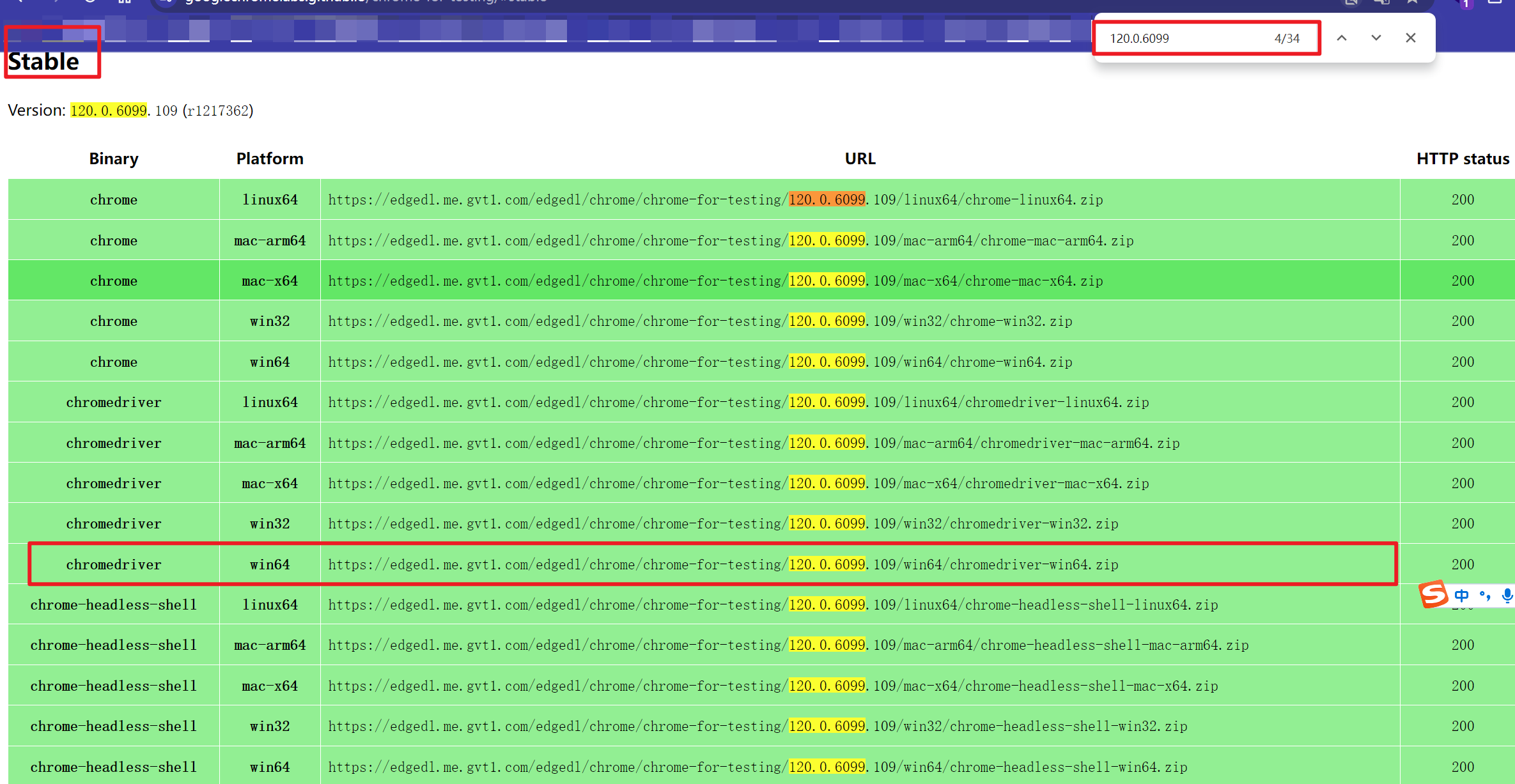
把URL地址复制下载去浏览器下载驱动

下完以后解压,发现里面是个exe文件(往后浏览器更新了,驱动也需要重新下载对应版本的)

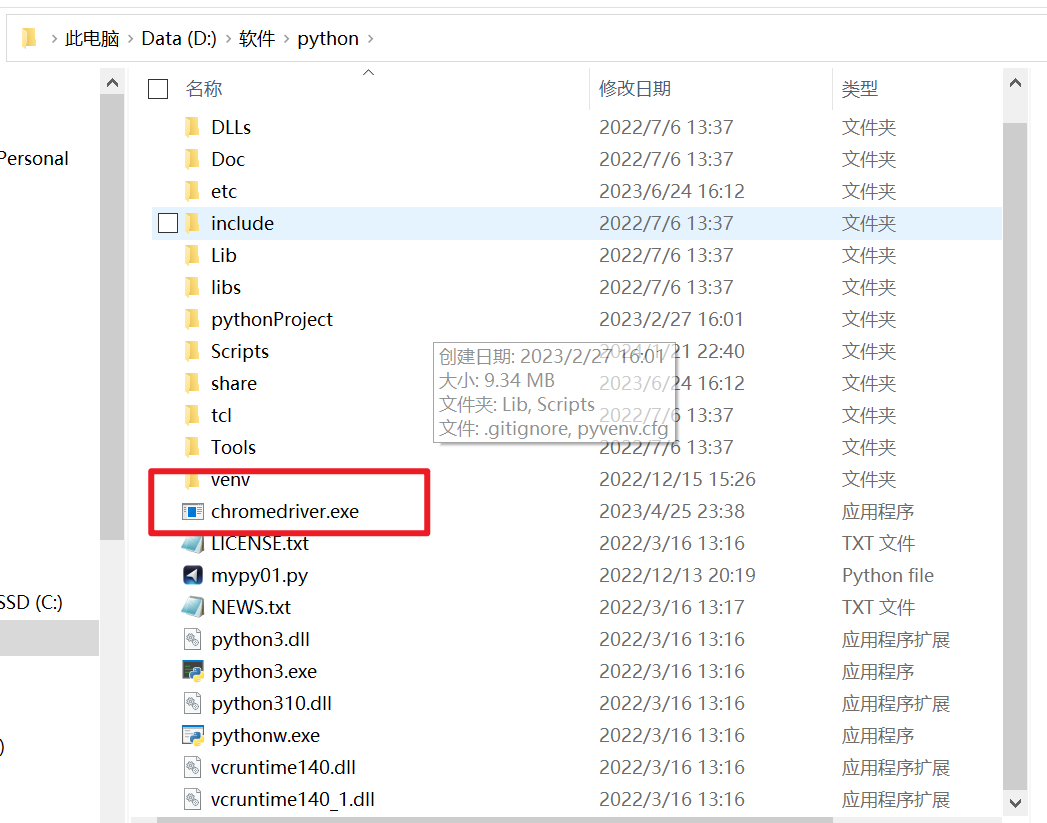
然后关键的来了. 把你下载的浏览器驱动放在python解释器所在的文件夹
Windwos: py -0p 查看Python路径
Mac: open + 路径
到此为止配置就结束了
2,selenium导入使用
from selenium.webdriver import Chrome # 导入谷歌浏览器的类# 创建浏览器对象
web = Chrome() # 如果你的浏览器驱动放在了解释器文件夹web.get("http://www.baidu.com") # 输入网址
2、selenium的基本使用
2.1 加载网页:
selenium通过控制浏览器,所以对应的获取的数据都是elements中的内容
from selenium import webdriver
from selenium.webdriver.common.by import Bydriver = webdriver.Chrome()
# 访问百度
driver.get("http://www.baidu.com/")
# 截图
driver.save_screenshot("baidu.png")
2.2 定位和操作:
# 搜索关键字 杜卡迪
driver.find_element(By.ID, "kw").send_keys("杜卡迪")
# 点击id为su的搜索按钮
driver.find_element(By.ID, "su").click()
3.3 查看请求信息:
driver.page_source # 获取页面内容
driver.get_cookies()
driver.current_url
3.4 退出
driver.close() # 退出当前页面
driver.quit() # 退出浏览器
3.5 小结
1. selenium的导包:from selenium import webdriver2. selenium创建driver对象:driver = webdriver.Chrome()3. selenium请求数据:driver.get("http://www.baidu.com/")4. selenium查看数据: driver.page_source5. 关闭浏览器: driver.quit()6. 根据id定位元素: driver.find_element_by_id("kw")/driver.find_element(By.ID, "kw")7. 操作点击事件: click()8. 给输入框赋值:send_keys()9,获取cookie:driver.get_cookies()10,刷新页面driver.refresh()11,执行js代码driver.execute_script(f'window.scrollBy(0, {step_length})')
3-6 小案例
3-6-1 简单案例
找到搜索框,输入内容,找到搜索按钮进行点击
import timefrom selenium.webdriver import Chrome # 导入谷歌浏览器的类# 创建浏览器对象
from selenium.webdriver.common.by import Byweb = Chrome() # 如果你的浏览器驱动放在了解释器文件夹web.get("https://www.gushiwen.cn/") # 输入网址# 查找搜索框
txtKey = web.find_element(By.ID,'txtKey')txtKey.send_keys('唐诗')# 找到点击按钮
search = web.find_element(By.XPATH,'//*[@id="search"]/form/input[3]')
search.click()
print(search)
time.sleep(5)
web.quit()
3-6-2 解决登录问题
2-1 基本代码
import timefrom selenium.webdriver import Chrome
from selenium.webdriver.common.by import Bydriver = Chrome()
# 访问的网址
driver.get('https://www.gushiwen.cn/')
"""
1 点击我的 到登录页面
2 获取账号节点 输入值
3 获取密码节点 输入值
4 获取验证码节点 输入值
5 点击登录
"""
# 点我的
driver.find_element(By.XPATH, '/html/body/div[1]/div[1]/div/div[2]/div/a[6]').click()# 获取账号节点
email = driver.find_element(By.ID, 'email')
email.send_keys('793390457@qq.com')
# 获取密码节点
password = driver.find_element(By.ID, 'pwd')
password.send_keys('xlg17346570232')
# 获取验证码节点
yzm = driver.find_element(By.ID, 'code')
yzm.send_keys('1234')
time.sleep(5)# 点击登录
driver.find_element(By.ID, 'denglu').click()time.sleep(5)
2-2 打码平台
import base64
import json
import requests
import timefrom selenium.webdriver import Chrome
from selenium.webdriver.common.by import Bydef base64_api(uname, pwd, img, typeid):with open(img, 'rb') as f:base64_data = base64.b64encode(f.read())b64 = base64_data.decode()data = {"username": uname, "password": pwd, "typeid": typeid, "image": b64}result = json.loads(requests.post("http://api.ttshitu.com/predict", json=data).text)if result['success']:return result["data"]["result"]else:#!!!!!!!注意:返回 人工不足等 错误情况 请加逻辑处理防止脚本卡死 继续重新 识别return result["message"]return ""if __name__ == "__main__":driver = Chrome()# 访问的网址driver.get('https://www.gushiwen.cn/')"""1 点击我的 到登录页面2 获取账号节点 输入值3 获取密码节点 输入值4 获取验证码节点 输入值5 点击登录"""# 点我的driver.find_element(By.XPATH, '/html/body/div[1]/div[1]/div/div[2]/div/a[6]').click()# 获取账号节点email = driver.find_element(By.ID, 'email')email.send_keys('793390457@qq.com')# 获取密码节点password = driver.find_element(By.ID, 'pwd')password.send_keys('xlg17346570232')# 验证码图片的节点img_path = "yzm.jpg"# screenshot截图并保存保存driver.find_element(By.ID, 'imgCode').screenshot(img_path)# 识别验证码result = base64_api(uname='luckyboyxlg', pwd='17346570232', img=img_path, typeid=3)print(result)# 获取验证码节点yzm = driver.find_element(By.ID, 'code')yzm.send_keys(result) # 输入识别后的值time.sleep(8)# 点击登录driver.find_element(By.ID, 'denglu').click()time.sleep(50)2-3 保存登录后的cookie
import base64
import json
import requests
import timefrom selenium.webdriver import Chrome
from selenium.webdriver.common.by import Bydef base64_api(uname, pwd, img, typeid):with open(img, 'rb') as f:base64_data = base64.b64encode(f.read())b64 = base64_data.decode()data = {"username": uname, "password": pwd, "typeid": typeid, "image": b64}result = json.loads(requests.post("http://api.ttshitu.com/predict", json=data).text)if result['success']:return result["data"]["result"]else:#!!!!!!!注意:返回 人工不足等 错误情况 请加逻辑处理防止脚本卡死 继续重新 识别return result["message"]return ""if __name__ == "__main__":driver = Chrome()# 访问的网址driver.get('https://www.gushiwen.cn/')"""1 点击我的 到登录页面2 获取账号节点 输入值3 获取密码节点 输入值4 获取验证码节点 输入值5 点击登录"""# 点我的driver.find_element(By.XPATH, '/html/body/div[1]/div[1]/div/div[2]/div/a[6]').click()# 获取账号节点email = driver.find_element(By.ID, 'email')email.send_keys('793390457@qq.com')# 获取密码节点password = driver.find_element(By.ID, 'pwd')password.send_keys('xlg17346570232')# 验证码图片的节点img_path = "yzm.jpg"# screenshot截图并保存保存driver.find_element(By.ID, 'imgCode').screenshot(img_path)# 识别验证码result = base64_api(uname='luckyboyxlg', pwd='17346570232', img=img_path, typeid=3)print(result)# 获取验证码节点yzm = driver.find_element(By.ID, 'code')yzm.send_keys(result) # 输入识别后的值time.sleep(8)# 点击登录driver.find_element(By.ID, 'denglu').click()time.sleep(4)# 获取cookie保存到本地cookies = driver.get_cookies()print(cookies)with open('cookies.txt', 'w', encoding='UTF-8') as f:f.write(json.dumps(cookies))2-4 携带cookie进行访问
import time
from selenium.webdriver.common.by import By
from selenium.webdriver import Chrome
import jsondriver = Chrome()
# 访问登录
driver.get('https://so.gushiwen.cn/user/login.aspx?from=http://so.gushiwen.cn/user/collect.aspx')
# 本地cookie加载
with open('cookies.txt', 'r', encoding='UTF-8') as f:cookies = json.loads(f.read())# cookie加载到selenium中
for cookie in cookies:driver.add_cookie(cookie)# 刷新一下
driver.refresh()driver.get('https://so.gushiwen.cn/user/collect.aspx')time.sleep(10)
3-6-3 抓取网易
import time
from selenium.webdriver import Chrome
from selenium.webdriver.common.by import Bydef window_scroll(driver, stop_length, step_length):'''向下滚动方法封装:param driver: selenium对象:param stop_length: 滚动终止值:param step_length: 每次滚动步长:return:'''while True:# 终止不滚的条件if stop_length - step_length <= 0:driver.execute_script(f'window.scrollBy(0, {stop_length})')break# 执行js代码 向下滚动driver.execute_script(f'window.scrollBy(0, {step_length})')stop_length -= step_lengthtime.sleep(1) # 1秒滚一下# driver.execute_script('window.scrollBy(0, 30000)')
if __name__ == '__main__':driver = Chrome()driver.get('https://news.163.com/')stop_length = 30000 # 终止值step_length = 2000 # 每次滚动的值# 循环5次点击加载更多for i in range(1, 6):window_scroll(driver, stop_length, step_length)# 点击加载更多more = driver.find_element(By.XPATH, '//*[@id="index2016_wrap"]/div[3]/div[2]/div[3]/div[2]/div[5]/div/a[3]/div[1]/span')# more.click() # 点击driver.execute_script('arguments[0].click()', more)print(f'第:{i}次 点击加载更多')time.sleep(5)# 获取页面所有源代码page = driver.page_sourceprint(page)
3、selenium的定位操作
1,元素定位的两种写法:
-
直接调用型
el = driver.find_element_by_xxx(value)# xxx是定位方式,后面我们会讲,value为该方式对应的值 -
使用By类型(需要导入By) 建议使用这种方式
# 直接掉用的方式会在底层翻译成这种方式 from selenium.webdriver.common.by import By driver.find_element(By.xxx,value)
2,元素定位的两种方式:
-
精确定位一个元素,返回结果为一个element对象,定位不到则报错
driver.find_element(By.xx, value) # 建议使用 driver.find_element_by_xxx(value) -
定位一组元素,返回结果为element对象列表,定位不到返回空列表
driver.find_elements(By.xx, value) # 建议使用 driver.find_elements_by_xxx(value)
3,元素定位的八种方法:
以下方法在element之后添加s就变成能够获取一组元素的方法
-
By.ID 使用id值定位
el = driver.find_element(By.ID, '') el = driver.find_element_by_id() -
By.XPATH 使用xpath定位
el = driver.find_element(By.XPATH, '') el = driver.find_element_by_xpath() -
By.TAG_NAME. 使用标签名定位
el = driver.find_element(By.TAG_NAME, '') el = driver.find_element_by_tag_name() -
By.LINK_TEXT使用超链接文本定位
el = driver.find_element(By.LINK_TEXT, '') el = driver.find_element_by_link_text() -
By.PARTIAL_LINK_TEXT 使用部分超链接文本定位
el = driver.find_element(By.PARTIAL_LINK_TEXT , '') el = driver.find_element_by_partial_link_text() -
By.NAME 使用name属性值定位
el = driver.find_element(By.NAME, '') el = driver.find_element_by_name() -
By.CLASS_NAME 使用class属性值定位
el = driver.find_element(By.CLASS_NAME, '') el = driver.find_element_by_class_name() -
By.CSS_SELECTOR 使用css选择器定位
el = driver.find_element(By.CSS_SELECTOR, '') el = driver.find_element_by_css_selector()
注意:
find_element与find_elements区别
1. 只查找一个元素的时候:可以使用find_element(),find_elements()find_element()会返回一个WebElement节点对象,但是没找到会报错,而find_elements()不会,之后返回一个空列表
2. 查找多个元素的时候:只能用find_elements(),返回一个列表,列表里的元素全是WebElement节点对象
3. 找到都是节点(标签)
4. 如果想要获取相关内容(只对find_element()有效,列表对象没有这个属性) 使用 .text
5. 如果想要获取相关属性的值(如href对应的链接等,只对find_element()有效,列表对象没有这个属性):使用 .get_attribute("href")
4、元素的操作
find_element_by_xxx方法仅仅能够获取元素对象,接下来就可以对元素执行以下操作 从定位到的元素中提取数据的方法
4.1 从定位到的元素中获取数据
el.get_attribute(key) # 获取key属性名对应的属性值
el.text # 获取开闭标签之间的文本内容
4.2 对定位到的元素的操作
el.click() # 对元素执行点击操作el.submit() # 对元素执行提交操作el.clear() # 清空可输入元素中的数据el.send_keys(data) # 向可输入元素输入数据
5,小结
## 1. 根据xpath定位元素:driver.find_elements(By.XPATH,"//*[@id='s']/h1/a")## 2. 根据class定位元素:driver.find_elements(By.CLASS_NAME, "box")## 3. 根据link_text定位元素:driver.find_elements(By.LINK_TEXT, "下载豆瓣 App")## 4. 根据tag_name定位元素:driver.find_elements(By.TAG_NAME, "h1")## 5. 获取元素文本内容:element.text## 6. 获取元素标签属性: element.get_attribute("href")## 7. 向输入框输入数据: element.send_keys(data)
4、无头浏览器
我们已经基本了解了selenium的基本使用了. 但是呢, 不知各位有没有发现, 每次打开浏览器的时间都比较长. 这就比较耗时了. 我们写的是爬虫程序. 目的是数据. 并不是想看网页. 那能不能让浏览器在后台跑呢? 答案是可以的
from selenium.webdriver import Chrome
from selenium.webdriver.chrome.options import Optionsopt = Options()
opt.add_argument("--headless")
opt.add_argument('--disable-gpu')
opt.add_argument("--window-size=4000,1600") # 设置窗口大小web = Chrome(options=opt)
from selenium.webdriver import Chrome
from selenium.webdriver.chrome.options import Optionsopt = Options()
opt.add_argument("--headless")
opt.add_argument('--disable-gpu')web = Chrome(options=opt)
web.get('https://www.baidu.com')
print(web.title)
5、selenium 处理cookie
通过driver.get_cookies()能够获取所有的cookie
-
获取cookie
dictCookies = driver.get_cookies() -
设置cookie
driver.add_cookie(dictCookies) -
删除cookie
#删除一条cookie driver.delete_cookie("CookieName") # 删除所有的cookie driver.delete_all_cookies()
6,其他知识
6.1 当你触发了某个事件之后,页面出现了弹窗提示,处理这个提示或者获取提示信息方法如下:
alert = driver.switch_to_alert()
6.2 页面前进和后退
driver.forward() # 前进
driver.back() # 后退
driver.refresh() # 刷新
driver.close() # 关闭当前窗口
6.3 设置浏览器最大窗口
driver.maximize_window() #最大化浏览器窗口
十四,scrapy框架
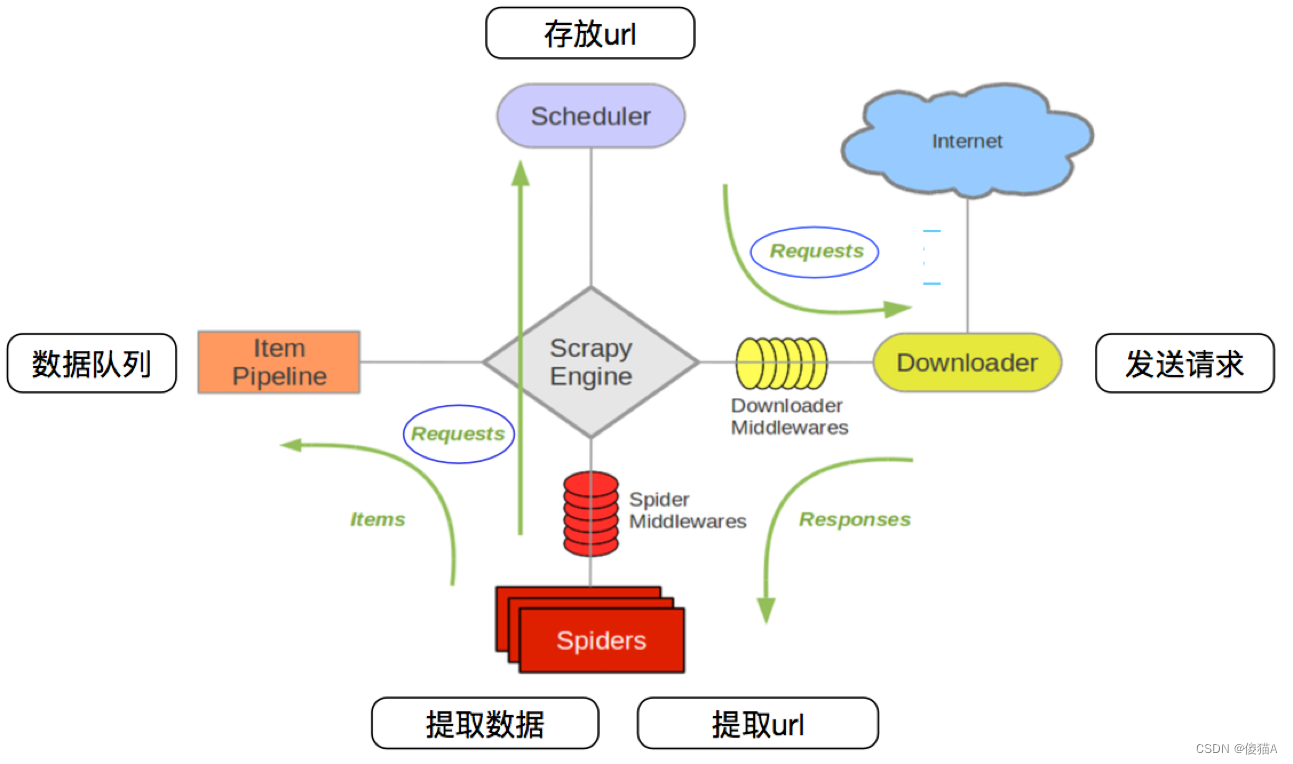
1,scrapy的工作流程
1-1 回顾之前的爬虫流程
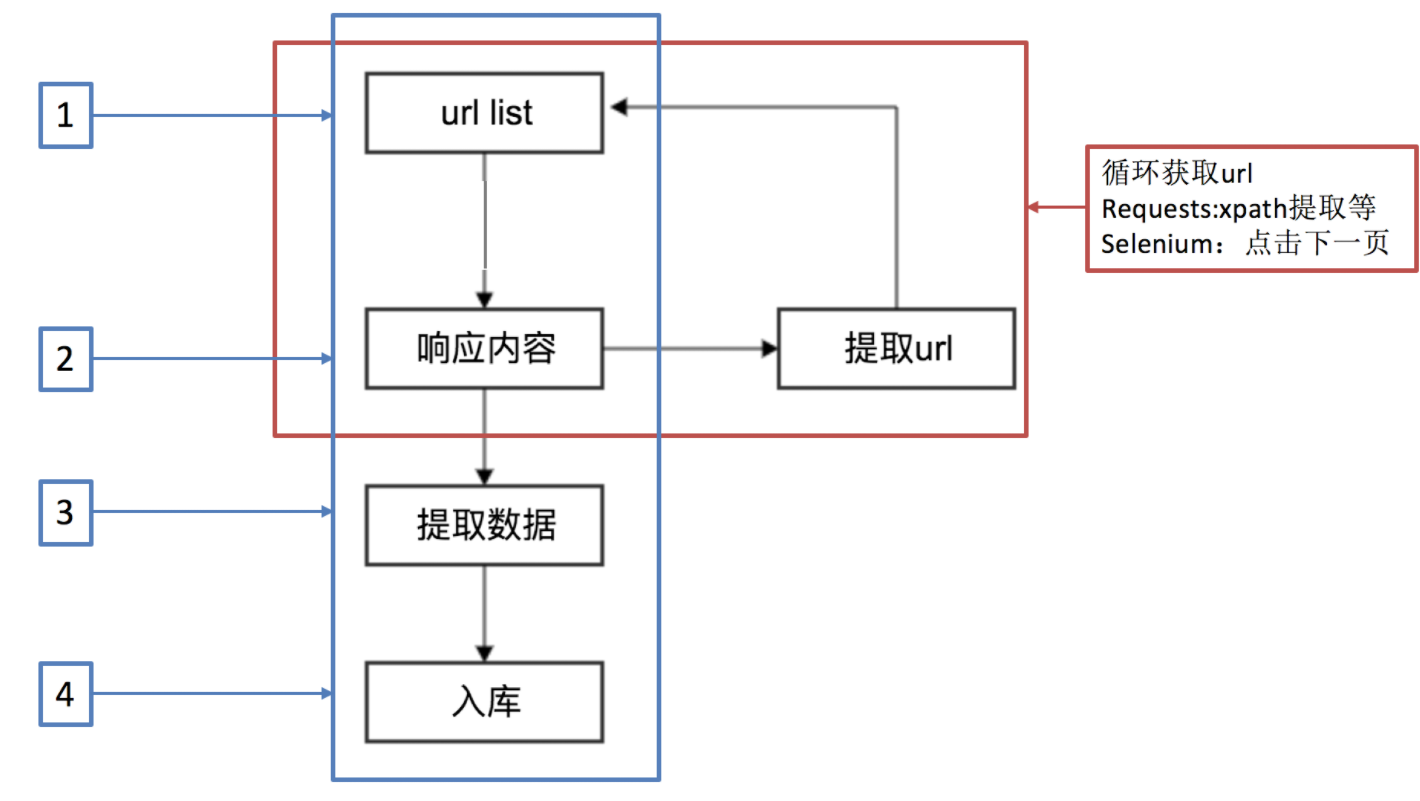
1-2 上面的流程可以改写为
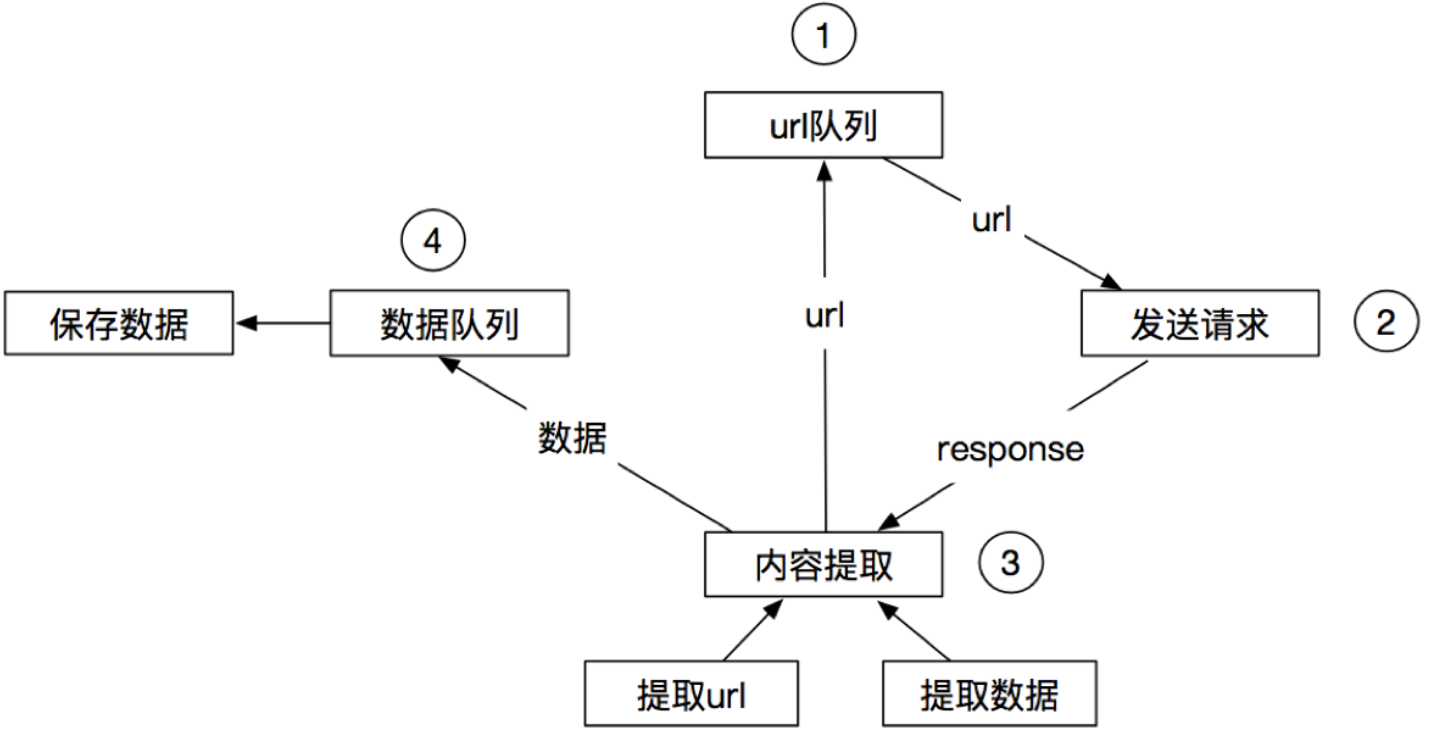
1-3 scrapy的流程
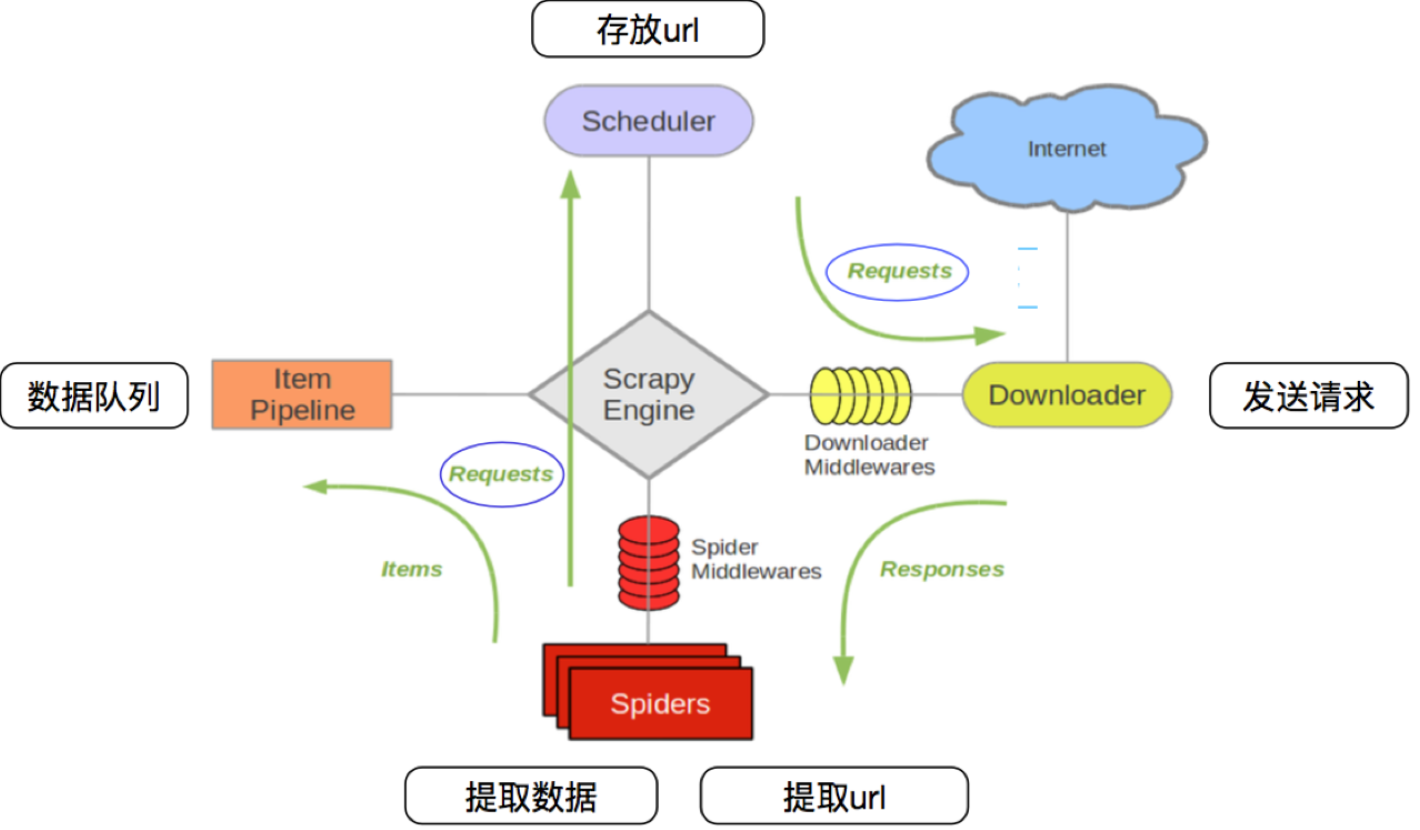
其流程可以描述如下:
- 调度器把requests–>引擎–>下载中间件—>下载器
- 下载器发送请求,获取响应---->下载中间件---->引擎—>爬虫中间件—>爬虫
- 爬虫提取url地址,组装成request对象---->爬虫中间件—>引擎—>调度器
- 爬虫提取数据—>引擎—>管道
- 管道进行数据的处理和保存
注意:
- 图中绿色线条的表示数据的传递
- 注意图中中间件的位置,决定了其作用
- 注意其中引擎的位置,所有的模块之间相互独立,只和引擎进行交互
1-4 scrapy中每个模块的具体作用

1-5 小结
-
scrapy的概念:Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架
-
scrapy框架的运行流程以及数据传递过程:
- 调度器把requests–>引擎–>下载中间件—>下载器
- 下载器发送请求,获取响应---->下载中间件---->引擎—>爬虫中间件—>爬虫
- 爬虫提取url地址,组装成request对象---->爬虫中间件—>引擎—>调度器
- 爬虫提取数据—>引擎—>管道
- 管道进行数据的处理和保存
-
scrapy框架的作用:通过少量代码实现快速抓取
-
掌握scrapy中每个模块的作用:
引擎(engine):负责数据和信号在不同模块间的传递
调度器(scheduler):实现一个队列,存放引擎发过来的request请求对象
下载器(downloader):发送引擎发过来的request请求,获取响应,并将响应交给引擎
爬虫(spider):处理引擎发过来的response,提取数据,提取url,并交给引擎
管道(pipeline):处理引擎传递过来的数据,比如存储
下载中间件(downloader middleware):可以自定义的下载扩展,比如设置代理ip
爬虫中间件(spider middleware):可以自定义request请求和进行response过滤
-
理解异步和非阻塞的区别:异步是过程,非阻塞是状态
2,scrapy的入门使用
2-1 安装
pip install scrapy==2.5.1pip install -i https://pypi.tuna.tsinghua.edu.cn/simple scrapy==2.5.1 pip install scrapy-redis==0.7.2
如果安装失败. 请先升级一下pip. 然后重新安装scrapy即可.
最新版本的pip升级完成后. 安装依然失败, 可以根据报错信息进行一点点的调整, 多试几次pip. 直至success.
2-2 安装(2-1安装失败用这个)
如果上述过程还是无法正常安装scrapy, 可以考虑用下面的方案来安装:
2-2-1 安装wheel
pip install wheel
2-2-2 下载twisted安装包,
https://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted
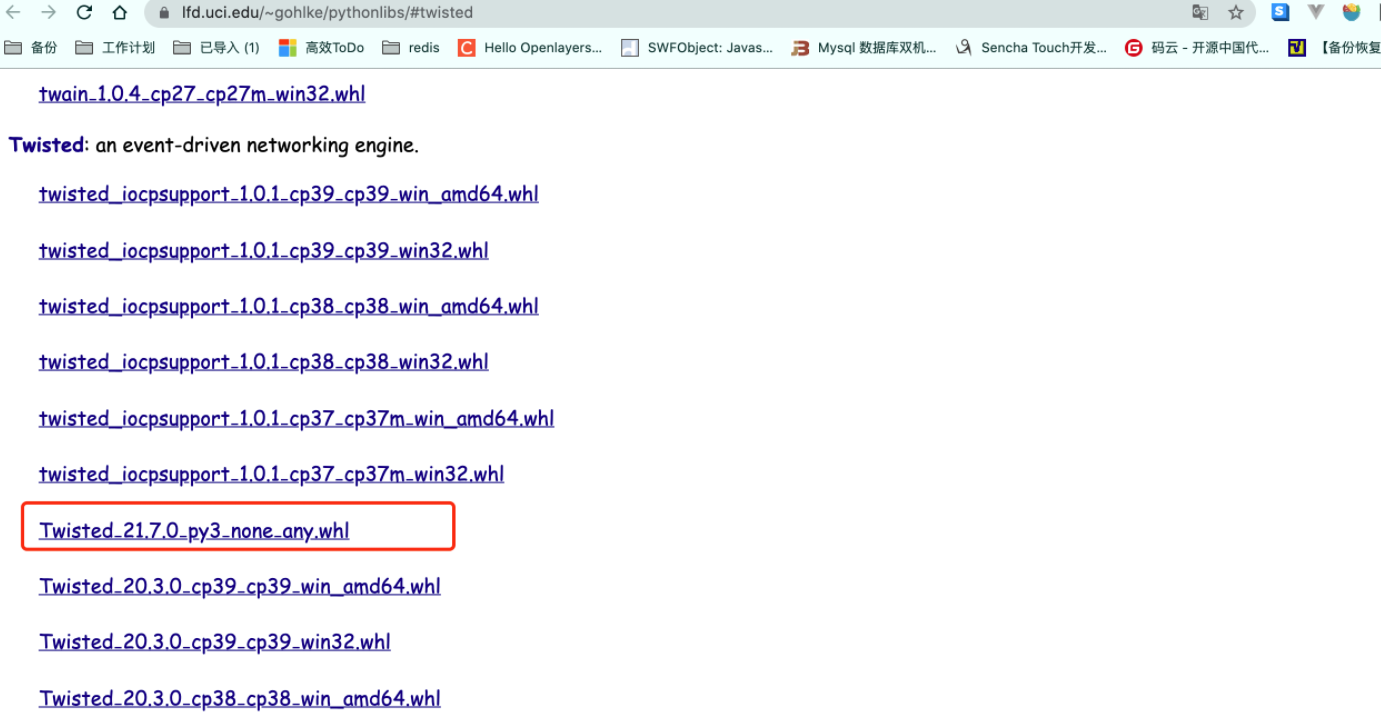
2-2-3 用wheel安装twisted.
pip install Twisted‑21.7.0‑py3‑none‑any.whl
2-2-4 安装pywin32
pip install pywin32
2-2-5 安装scrapy
pip install scrapy
总之, 最终你的控制台输入scrapy version能显示版本号. 就算成功了
2-3 scrapy项目实现流程
- 创建一个scrapy项目:scrapy startproject mySpider
- 生成一个爬虫:scrapy genspider myspider www.xxx.cn
- 提取数据:完善spider,使用xpath等方法
- 保存数据:pipeline中保存数据
2-4 创建scrapy框架
## 创建scrapy项目的命令:scrapy startproject +<项目名字>## 示例:scrapy startproject myspider
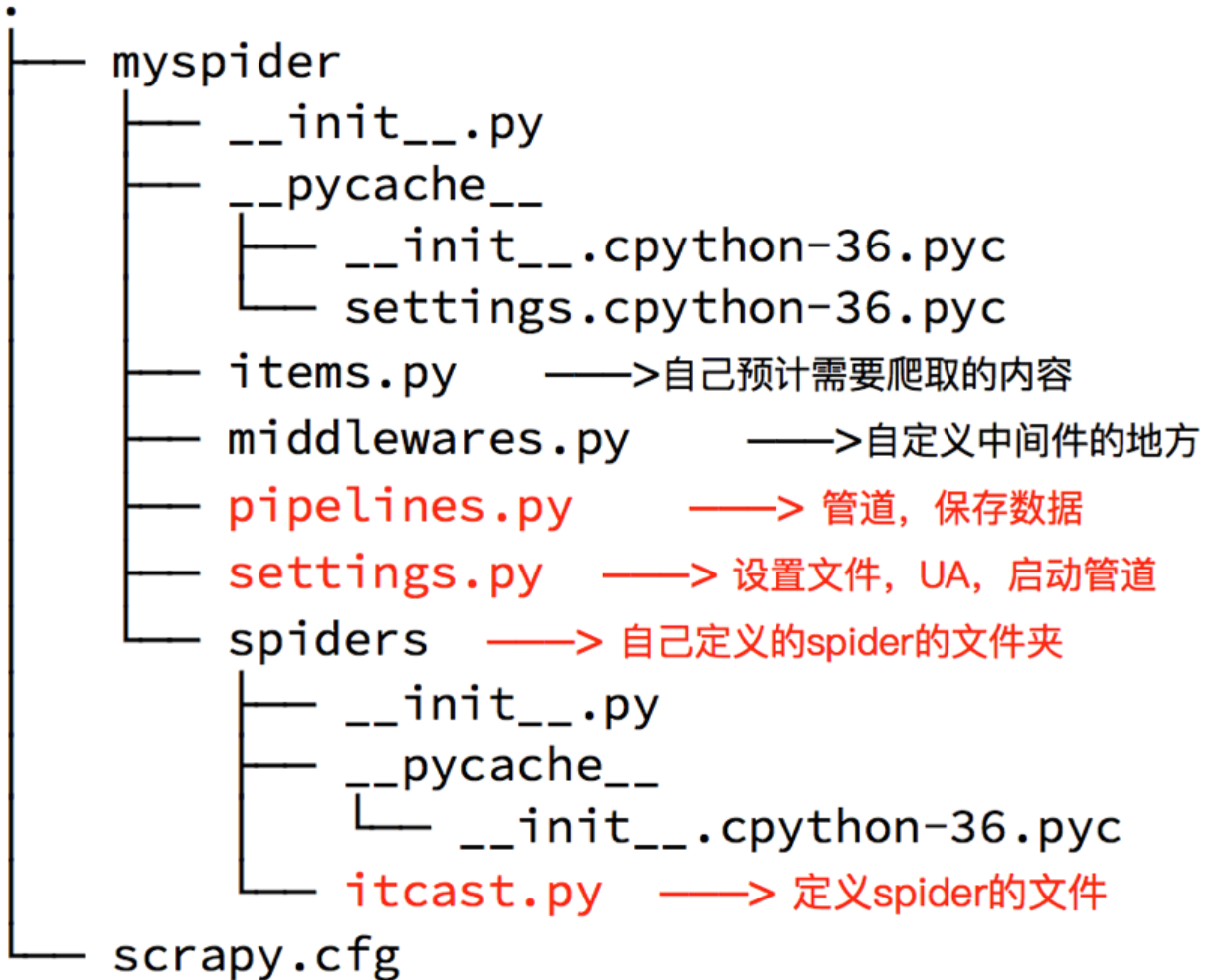
生成的目录和文件结果如下:

2-5 scrapy的核心组件
- 引擎(Scrapy)
用来处理整个系统的数据流处理, 触发事务(框架核心) - 调度器(Scheduler)
用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回. 可以想像成一个URL(抓取网页的网址或者说是链接)的优先队列, 由它来决定下一个要抓取的网址是什么, 同时去除重复的网址 - 下载器(Downloader)
用于下载网页内容, 并将网页内容返回给蜘蛛(Scrapy下载器是建立在twisted这个高效的异步模型上的) - 爬虫(Spiders)
爬虫是主要干活的, 用于从特定的网页中提取自己需要的信息, 即所谓的实体(Item)。用户也可以从中提取出链接,让Scrapy继续抓取下一个页面 - 项目管道(Pipeline)
负责处理爬虫从网页中抽取的实体,主要的功能是持久化实体、验证实体的有效性、清除不需要的信息。当页面被爬虫解析后,将被发送到项目管道,并经过几个特定的次序处理数据。
2-6 创建爬虫
命令:在项目路径下执行:scrapy genspider +<爬虫名字> + <允许爬取的域名>
示例:
- scrapy startproject duanzi01
- cd duanzi01/
- scrapy genspider duanzi duanzixing.com
生成的目录和文件结果如下:
2-7 完善spider
完善spider即通过方法进行数据的提取等操作
在/duanzi01/duanzi01/spiders/duanzi.py中修改内容如下:
import scrapy# 自定义spider类,继承scrapy.spiderclass DuanziSpider(scrapy.Spider):# 爬虫名字name = 'duanzi'# 允许爬取的范围,防止爬虫爬到别的网站allowed_domains = ['duanzixing.com']# 开始爬取的url地址start_urls = ['http://duanzixing.com/']# 数据提取的方法,接受下载中间件传过来的response 是重写父类中的parse方法def parse(self, response, **kwargs):# 打印抓取到的页面源码# print(response.text)# xpath匹配每条段子的article列表article_list = response.xpath('//article[@class="excerpt"]')# print(article_list)# 循环获取每一个articlefor article in article_list:# 匹配标题# title = article.xpath('./header/h2/a/text()')# [<Selector xpath='./header/h2/a/text()' data='一个不小心就把2000块钱的包包设置成了50包邮'>]# title = article.xpath('./header/h2/a/text()')[0].extract()# 等同于title = article.xpath('./header/h2/a/text()').extract_first()# 获取段子内容con = article.xpath('./p[@class="note"]/text()').extract_first()print('title', title)print('con', con)
启动爬虫命令:
scrapy crawl duanzi
注意:
-
如果运行出现一下错误
AttributeError: module 'OpenSSL.SSL' has no attribute 'SSLv3_METHOD' -
解决
1. 卸载cryptography:pip uninstall cryptography 2. 重新安装cryptography 36.0.2:pip install cryptography==36.0.2 3. 卸载pyOpenSSL:pip uninstall pyOpenSSL 4. 重新安装pyOpenSSL 22.0.0:pip install pyOpenSSL==22.0.0
发现会打印许多无用的info信息,我们需要关闭
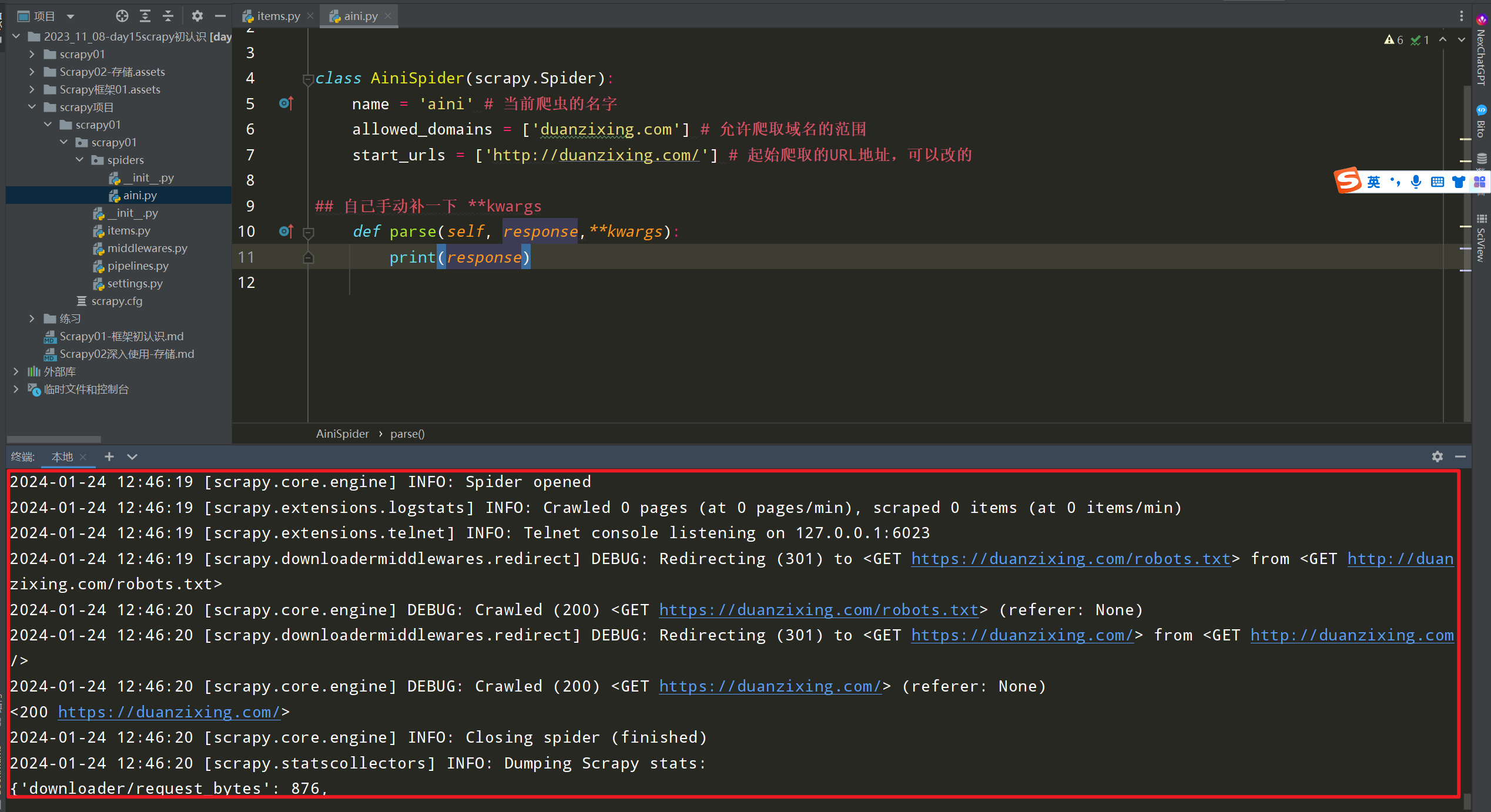
2-8 配置settings文件
(settings.py文件)
-
ROBOTSTXT_OBEY = False
robots是一种反爬协议。在协议中规定了哪些身份的爬虫无法爬取的资源有哪些。
在配置文件中setting,取消robots的监测:
-
在配置文件中配置全局的UA:USER_AGENT=‘xxxx’
-
在配置文件中加入日志等级:LOG_LEVEL = ‘ERROR’ 只输出错误信息
其它日志级别
-
CRITICAL 严重错误
-
ERROR 错误
-
WARNING 警告
-
INFO 消息
-
DEBUG 调试
-
代码实例:
# Scrapy settings for mySpider projectUSER_AGENT = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.127 Safari/537.36'ROBOTSTXT_OBEY = False## 没有这个配置项,自己加上LOG_LEVEL = 'ERROR'
3,respone对象常用属性
- response.url:# 当前响应的url地址
- response.request.url:## 当前响应对应的请求的url地址
- response.headers:## 响应头
- response.request.headers:## 当前响应的请求头
- response.body:## 响应体,也就是html代码,byte类型
- response.text ## 返回响应的内容 字符串
- response.status:## 响应状态码
- response.json() ## 抓取json数据
import scrapyclass DzSpider(scrapy.Spider):name = 'dz' # 爬虫的名字allowed_domains = ['duanzixing.com'] # 允许爬取的域名范围start_urls = ['http://duanzixing.com/'] # 起始网址def parse(self, response, **kwargs):print(response)print(response.url, '响应的URL')print(response.request.url, '响应对应请求的URL')print(response.request.headers, '响应对应请求的请求头')print(response.status, '响应状态码')print(response.body, '返回bytes 字节')print(response.text, '返回字符串')## 如果返回的不是JSON数据,用这个属性会报错print(response.json(), '返回JSON数据')
注意:
import scrapyclass AiniSpider(scrapy.Spider):name = 'aini' # 当前爬虫的名字allowed_domains = ['duanzixing.com'] # 允许爬取域名的范围start_urls = ['http://duanzixing.com/'] # 起始爬取的URL地址,可以改的## 自己手动补一下 **kwargsdef parse(self, response,**kwargs):## 可以使用xpath语法article_list = response.xpath('//article[@class="excerpt"]')for a in article_list:title1 = a.xpath('./header/h2/a/text()')# print(title) 打印发现还是selector对象,# [<Selector xpath='./header/h2/a/text()' data='你们发朋友圈我也发'>]# 需要用到response.xpath 对象的一个extract方法拿到字符串的内容,返回的是列表title2 = a.xpath('./header/h2/a/text()').extract()# 但是里面就一个内容,所以可以用extract_first()title3 = a.xpath('./header/h2/a/text()').extract()[0] ## 跟下面的效果一样title4 = a.xpath('./header/h2/a/text()').extract_first()print(title4) ## 你们发朋友圈我也发
-
response.xpath方法的返回结果是一个类似list的类型,其中包含的是selector对象,操作和列表一样,但是有一些额外的方法
-
extract() 返回一个包含有字符串的列表
如果使用列表调用extract()则表示,extract会将列表中每一个列表元素进行extract操作,返回列表
-
extract_first() 返回列表中的第一个字符串,列表为空没有返回None
-
spider中的parse方法必须有
-
需要抓取的url地址必须属于allowed_domains,但是start_urls中的url地址没有这个限制
-
启动爬虫的时候注意启动的位置,是在项目路径下启动
4,scrapy 深入使用
4-1 scrapy shell
scrapy shell是scrapy提供的一个终端工具,能够通过它查看scrapy中对象的属性和方法,以及测试xpath
使用方法:
scrapy shell http://www.baidu.com
在终端输入上述命令后,能够进入python的交互式终端,此时可以使用:
- response.xpath(): ## 直接测试xpath规则是否正确
- response.url:## 当前响应的url地址
- response.request.url:## 当前响应对应的请求的url地址
- response.headers:## 响应头
- response.body:## 响应体,也就是html代码,默认是byte类型
- response.request.headers:## 当前响应的请求头
4-2 settings.py中的设置信息
4-2-1 为什么项目中需要配置文件
在配置文件中存放一些公共变量,在后续的项目中方便修改,如:本地测试数据库和部署服务器的数据库不一致
4-2-2 配置文件中的变量使用方法
- 变量名一般全部大写
- 导入即可使用
4-2-3 settings.py中的重点字段和含义
- USER_AGENT ## 设置ua- ROBOTSTXT_OBEY ## 是否遵守robots协议,默认是遵守- CONCURRENT_REQUESTS ## 设置并发请求的数量,默认是16个- DOWNLOAD_DELAY ## 下载延迟,默认无延迟 (下载器在从同一网站下载连续页面之前应等待的时间(以秒为单位)。这可以用来限制爬行速度,以避免对服务器造成太大影响)- COOKIES_ENABLED ## 是否开启cookie,即每次请求带上前一次的cookie,默认是开启的- DEFAULT_REQUEST_HEADERS ## 设置默认请求头,这里加入了USER_AGENT将不起作用- SPIDER_MIDDLEWARES ## 爬虫中间件,设置过程和管道相同- DOWNLOADER_MIDDLEWARES ## 下载中间件- LOG_LEVEL ## 控制终端输出信息的log级别,终端默认显示的是debug级别的log信息- LOG_LEVEL = "WARNING"- CRITICAL 严重- ERROR 错误- WARNING 警告- INFO 消息- DEBUG 调试- LOG_FILE ## 设置log日志文件的保存路径,如果设置该参数,终端将不再显示信息LOG_FILE = "./test.log"## 其他设置参考:https://www.jianshu.com/p/df9c0d1e9087
4-3 scrapy 管道
4.1 使用终端命令行进行存储
代码配置
scrapy练习/duanzi/duanzi/spiders/dz.py
import scrapyclass DzSpider(scrapy.Spider):name = 'dz'# allowed_domains = ['duanzixing.com']start_urls = ['http://duanzixing.com/']def parse(self, response,**kwargs):article_list = response.xpath('//article[@class="excerpt"]')for article in article_list:title = article.xpath('./header/h2/a/text()').extract_first()con = article.xpath('./p[@class="note"]//text()').extract_first()data = {'title':title,'con':con}## 把数据传给管道yield data终端命令
只能存储csv格式,而且数据传给管道以后才可以用这个命令
## scrapy crawl 爬虫名称 -o 文件名.csv
scrapy crawl ITSpider -o ITSpider.csv ## 将文件存储到ITSpider.csv 文件中
思考:为什么要使用yield?
- 让整个函数变成一个生成器,有什么好处呢?
- 遍历这个函数的返回值的时候,挨个把数据读到内存,不会造成内存的瞬间占用过高
- python3中的range和python2中的xrange同理
注意:yield能够传递的对象只能是:BaseItem,Request,dict,None
4-2 开启管道
settings.py 打开当前注释
ITEM_PIPELINES = {'doubanfile.pipelines.DoubanfilePipeline': 300,
}
pipeline中常用的方法:
1. process_item(self,item,spider): ## 实现对item数据的处理
2. open_spider(self, spider): ## 在爬虫开启的时候仅执行一次
3. close_spider(self, spider): ## 在爬虫关闭的时候仅执行一次
class DuanziPipeline:## 开启的时候走一次def open_spider(self,spider):pass# 每次yield的数据过来走一次def process_item(self, item, spider):return item# scrapy之心完走一次def close_spider(self,spider):pass
4-3 把数据存储在数据库中
代码配置
scrapy练习/duanzi/duanzi/spiders/dz.py
import scrapyclass DzSpider(scrapy.Spider):name = 'dz'# allowed_domains = ['duanzixing.com']start_urls = ['http://duanzixing.com/']def parse(self, response,**kwargs):article_list = response.xpath('//article[@class="excerpt"]')for article in article_list:title = article.xpath('./header/h2/a/text()').extract_first()con = article.xpath('./p[@class="note"]//text()').extract_first()data = {'title':title,'con':con}## 把数据传给管道yield data
管道中连接数据库进行存储
from itemadapter import ItemAdapterimport pymysqlclass DuanziPipeline:## 开启的时候走一次def open_spider(self,spider):# 连接MySQL数据库self.db = pymysql.connect(host='127.0.0.1', user='root', password='aini5726', db='duanzi',port=3306)# 设置字符集 防止乱码self.db.set_charset('utf8')# 创建游标对象self.cursor = self.db.cursor()# 每次yield的数据过来走一次def process_item(self, item, spider):## item是传递过来的数据## 把数据存储到数据库中title = item['title']con = item['con']try:sql = f'insert into dz set title = "{title}",con = "{con}"'self.cursor.execute(sql)self.db.commit()except Exception as e:print(sql,'===>',e)self.db.rollback()return item# scrapy之心完走一次def close_spider(self,spider):## 关闭数据库连接self.db.close()
4-4 把文件写入到文件中
from itemadapter import ItemAdapterclass Duanzi01Pipeline:def open_spider(self,spider):self.f = open('duanzi.txt','w',encoding='utf-8')def process_item(self, item, spider):title = item['title']con = item['con']## 写入到文件中件中self.f.write(f'{title}\n{con}\n')return itemdef close_spider(self,spider):self.f.close()
4-5 同时写入到MySQL和文件中
首先在setting中开启管道
ITEM_PIPELINES = {# 写入到MySQL数据库中'duanzi03.pipelines.DuanziMYSQLPipeline': 300,# 写入到文件中'duanzi03.pipelines.DuanziFILEPipeline': 400,
}
然后写两个管道,分别把数据存储到数据库和文件中
from itemadapter import ItemAdapter
import pymysql
# 写入到MySQL数据库之
class DuanziMYSQLPipeline:# 开启一次def open_spider(self, spider):# print(spider.name)# 连接MySQL数据库self.db = pymysql.connect(host='127.0.0.1', user='root', password='123456', db='duanzi')# 设置字符编码self.db.set_charset('utf8')# 创建游标对象self.cursor = self.db.cursor()# 每次yield的数据过来走一次def process_item(self, item, spider):title = item['title']con = item['con']try:sql = f'insert into dz(title, con) values("{title}", "{con}")'self.cursor.execute(sql) # 执行SQL语句self.db.commit() # 事务提交 写入到MySQL数据库中except Exception as e:print(sql, '===>', e) # 打印错误异常信息self.db.rollback() # 事务回滚# item是传递过来的数据return item# scrapy执行完走一次def close_spider(self, spider):# 关闭数据库连接self.db.close()# 写入到文件中
class DuanziFILEPipeline:def open_spider(self, spider):self.f = open('duanzi.txt', 'w', encoding='UTF-8')def process_item(self, item, spider):title = item['title']con = item['con']# 写入到文件中self.f.write(f'{title}\n{con}\n')return item # return不能去掉!!!def close_spider(self, spider):self.f.close()
4-6 管道注意点
思考:pipeline在settings中能够开启多个,为什么需要开启多个?
1. 不同的pipeline可以处理不同爬虫的数据,通过spider.name属性来区分
2. 不同的pipeline能够对一个或多个爬虫进行不同的数据处理的操作,比如一个进行数据清洗,一个进行数据的保存
3. 同一个管道类也可以处理不同爬虫的数据,通过spider.name属性来区分
4-6-1 pipeline使用注意点
1. 使用之前需要在settings中开启
2. pipeline在setting中键表示位置(即pipeline在项目中的位置可以自定义),值表示距离引擎的远近,越近数据会越先经过
3. 有多个pipeline的时候,process_item的方法必须return item,否则后一个pipeline取到的数据为None值
4. pipeline中process_item的方法必须有,否则item没有办法接受和处理
5. process_item方法接受item和spider,其中spider表示当前传递item过来的spider
6. open_spider(spider) :能够在爬虫开启的时候执行一次
7. close_spider(spider) :能够在爬虫关闭的时候执行一次
8. 上述俩个方法经常用于爬虫和数据库的交互,在爬虫开启的时候建立和数据库的连接,在爬虫关闭的时候断开和数据库的连接
4-6-2 总结
1. debug能够展示当前程序的运行状态
2. scrapy shell能够实现xpath的测试和对象属性和方法的尝试
3. scrapy的settings.py能够实现各种自定义的配置,比如下载延迟和请求头等
4. 管道能够实现数据的清洗和保存,能够定义多个管道实现不同的功能,其中有个三个方法- process_item(self,item,spider):实现对item数据的处理- open_spider(self, spider): 在爬虫开启的时候仅执行一次- close_spider(self, spider): 在爬虫关闭的时候仅执行一次
4-7 下载图片
4-7-1 安装模块
pip install pillow
4-7-2 抓取网址
https://desk.zol.com.cn/dongman/
4-7-3 创建工程
+ scrapy startproject desk
+ cd desk
+ scrapy genspider img desk.zol.com.cn/dongman
4-7-4 配置settings.py
# 设置日志级别
LOG_LEVEL = 'ERROR'
ROBOTSTXT_OBEY = False
# 设置请求头
DEFAULT_REQUEST_HEADERS = {'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8','Accept-Language': 'en','User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.0.0 Safari/537.36'
}
4-7-5 img.py 爬虫代码书写
思路:
抓取到详情页中图片的url地址,交给图片管道进行下载
import scrapy
from urllib.parse import urljoinclass ImgSpider(scrapy.Spider):name = 'img'# allowed_domains = ['desk.zol.com.cn/dongman']start_urls = ['http://desk.zol.com.cn/dongman/']def parse(self, resp, **kwargs):# 先抓取到每个图片详情的urlurl_list = resp.xpath('//ul[@class="pic-list2 clearfix"]/li/a/@href').extract()# 获取到url列表后 进行循环进行每一个url详情页的请求for url in url_list:# 因为抓取到的url并不完整,需要进行手动拼接# urljoin('https://desk.zol.com.cn/dongman/', '/bizhi/8301_103027_2.html')url = urljoin('https://desk.zol.com.cn/dongman/', url)# 拼凑完发现当前url中有下载exe的url,将其去除if url.find('exe') != -1:continueyield scrapy.Request(url, callback=self.parse_detail)# 对详情页进行解析def parse_detail(self, resp):# 获取当前详情页中最大尺寸图片的urlmax_img_url = resp.xpath('//dd[@id="tagfbl"]/a/@href').extract()# 判断当前最大图片的url地址,为倒数第二个,如果当前图片列表url长度小于2 则当前证明不是图片的urlif len(max_img_url) > 2:max_img_url = urljoin('https://desk.zol.com.cn/', max_img_url[0])# 对url页面进行请求 获取最终大图的页面yield scrapy.Request(max_img_url, callback=self.parse_img_detail)def parse_img_detail(self, resp):# 解析出大图的urlimg_src = resp.xpath("//img[1]/@src").extract_first()return {'img_src': img_src}
注意:
如果抓取过程中遇到如下报错,可能是cryptography 版本问题
twisted.web._newclient.ResponseNeverReceived: [<twisted.python.failure.Failure OpenSSL.SSL.Error: [('SSL routines', '', 'unsafe legacy renegotiation disabled')]>]
解决:
## 1、pip卸载cryptography:pip uninstall cryptography## 重新安装cryptography 36.0.2:pip install cryptography==36.0.2## 2、pip卸载pyOpenSSL:pip uninstall pyOpenSSL## 重新安装pyOpenSSL 22.0.0:pip install pyOpenSSL==22.0.0
4-7-6 配置图片管道
打开Pipelines文件夹
因为我们不能再像之前存储文本一样,使用之前的管道类(Pipeline),我们需要用到新的存储图片的管道类ImagesPipeline,因此我们需要先导入该类
pipelines.py
-
导入
from scrapy.pipelines.images import ImagesPipeline -
定义一个Images类
from itemadapter import ItemAdapter from scrapy.pipelines.images import ImagesPipeline import scrapyclass Imgspipline(ImagesPipeline):# 1. 发送请求(下载图片, 文件, 视频,xxx)def get_media_requests(self, item, info):# 获取到图片的urlurl = item['img_src']# 进行请求yield scrapy.Request(url=url, meta={"url": url}) # 直接返回一个请求对象即可# 2. 图片存储路径def file_path(self, request, response=None, info=None, *, item=None):# 当前获取请求的url的方式有2种# 获取到当前的url 用于处理下载图片的名称file_name = item['img_src'].split("/")[-1] # 用item拿到url# file_name = request.meta['url'].split("/")[-1] # 用meta传参获取return file_name# 3. 可能需要对item进行更新def item_completed(self, results, item, info):# print('results', results)for r in results:# 获取每个图片的路径print(r[1]['path'])return item # 一定要return item 把数据传递给下一个管道
4-7-7 保存数据
接着我们再定义一个保存数据的函数,并设置好存储的文件名,然后存储的路径需要在设置中(setting)文件中,添加IMAGE_STORE设置好存储的路径
开启图片管道
settings.py
ITEM_PIPELINES = {'desk.pipelines.DeskPipeline': 300,'desk.pipelines.Imgspipline': 400, # 开启图片管道
}
# 配置存储图片的路径
IMAGES_STORE = './imgs'
4-4 模拟登录
4-4-1、之前的模拟登陆的方法
1.1 requests模块是如何实现模拟登陆的?
1. 直接携带cookies请求页面
2. 找url地址,发送post请求存储cookie
1.2 selenium是如何模拟登陆的?
- 找到对应的input标签,输入文本点击登陆
1.3 scrapy有二种方法模拟登陆
1. 直接携带cookies
2. 找url地址,发送post请求存储cookie
4-4-2、scrapy携带cookies登录
17k小说网
https://user.17k.com/
2.1 应用场景
1. cookie过期时间很长,常见于一些不规范的网站
2. 能在cookie过期之前把所有的数据拿到
3. 配合其他程序使用,比如其使用selenium把登陆之后的cookie获取到保存到本地,scrapy发送请求之前先读取本地cookie
2.2 通过修改settings中DEFAULT_REQUEST_HEADERS携带cookie
settings.py
DEFAULT_REQUEST_HEADERS = {'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8','Accept-Language': 'en','User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.0.0 Safari/537.36','Cookie': 'ASP.NET_SessionId=n4lwamv5eohaqcorfi3dvzcv; xiaohua_visitfunny=103174; xiaohua_web_userid=120326; xiaohua_web_userkey=r2sYazfFMt/rxUn8LJDmUYetwR2qsFCHIaNt7+Zpsscpp1p6zicW4w=='
}
注意:需要打开COOKIES_ENABLED,否则上面设定的cookie将不起作用
# Disable cookies (enabled by default)
COOKIES_ENABLED = False
其他配置也别忘了
ROBOTSTXT_OBEY = False
LOG_LEVEL = 'WARNING'
xiaoshuo.py
import scrapyclass DengluSpider(scrapy.Spider):name = 'denglu'allowed_domains = ['17k.com']start_urls = ['https://user.17k.com/ck/user/mine/readList?page=1&appKey=2406394919']def parse(self, res):print(res.text)
局限性:
当前设定方式虽然可以实现携带cookie保持登录,但是无法获取到新cookie,也就是当前cookie一直是固定的,如果cookie是经常性变化,那么当前不适用
4-4-3 重构scrapy的start_rquests方法
把cookie处理成字典的代码
cookie_str = 'GUID=bb4eef9b-1b8f-417e-9264-3cdc3bad8eb1; c_channel=0; c_csc=web; Hm_lvt_9793f42b498361373512340937deb2a0=1697788773,1698241318,1699877224; accessToken=avatarUrl%3Dhttps%253A%252F%252Fcdn.static.17k.com%252Fuser%252Favatar%252F18%252F98%252F90%252F96139098.jpg-88x88%253Fv%253D1650527904000%26id%3D96139098%26nickname%3D%25E4%25B9%25A6%25E5%258F%258BqYx51ZhI1%26e%3D1715429231%26s%3D14c085a75371ffc5; sensorsdata2015jssdkcross=%7B%22distinct_id%22%3A%2296139098%22%2C%22%24device_id%22%3A%2218b4c18c0cf39c-0a8b44b4b81a83-26031151-1866240-18b4c18c0d06e0%22%2C%22props%22%3A%7B%22%24latest_traffic_source_type%22%3A%22%E7%9B%B4%E6%8E%A5%E6%B5%81%E9%87%8F%22%2C%22%24latest_referrer%22%3A%22%22%2C%22%24latest_referrer_host%22%3A%22%22%2C%22%24latest_search_keyword%22%3A%22%E6%9C%AA%E5%8F%96%E5%88%B0%E5%80%BC_%E7%9B%B4%E6%8E%A5%E6%89%93%E5%BC%80%22%7D%2C%22first_id%22%3A%22bb4eef9b-1b8f-417e-9264-3cdc3bad8eb1%22%7D'# 规律
"""
key=val;key=val;key=val;key=val;
"""
# list_cookie = cookie_str.split(';')
# print(list_cookie)
"""
cookie_dict = {}
for cookie in cookie_str.split(';'):list_cookie = cookie.split('=')cookie_dict[list_cookie[0]] = list_cookie[1]
# print(cookie_dict)
"""
cookie_dict = {cookie.split('=')[0]: cookie.split('=')[1] for cookie in cookie_str.split(';')}
print(cookie_dict)
scrapy中start_url是通过start_requests来进行处理的,其实现代码如下,这样的话setting中的COOKIES_ENABLED = True不用关了。
def start_requests(self):cls = self.__class__if method_is_overridden(cls, Spider, 'make_requests_from_url'):warnings.warn("Spider.make_requests_from_url method is deprecated; it ""won't be called in future Scrapy releases. Please ""override Spider.start_requests method instead (see %s.%s)." % (cls.__module__, cls.__name__),)for url in self.start_urls:yield self.make_requests_from_url(url)else:for url in self.start_urls:yield Request(url, dont_filter=True)
所以对应的,如果start_url地址中的url是需要登录后才能访问的url地址,则需要重写start_request方法并在其中手动添加上cookie
settings.py
import scrapyclass DengluSpider(scrapy.Spider):name = 'denglu'# allowed_domains = ['https://user.17k.com/ck/user/mine/readList?page=1']start_urls = ['https://user.17k.com/ck/user/mine/readList?page=1&appKey=2406394919']def start_requests(self):cookies = 'GUID=796e4a09-ba11-4ecb-9cf6-aad19169267d; Hm_lvt_9793f42b498361373512340937deb2a0=1660545196; c_channel=0; c_csc=web; accessToken=avatarUrl%3Dhttps%253A%252F%252Fcdn.static.17k.com%252Fuser%252Favatar%252F18%252F98%252F90%252F96139098.jpg-88x88%253Fv%253D1650527904000%26id%3D96139098%26nickname%3D%25E4%25B9%25A6%25E5%258F%258BqYx51ZhI1%26e%3D1677033668%26s%3D8e116a403df502ab; sensorsdata2015jssdkcross=%7B%22distinct_id%22%3A%2296139098%22%2C%22%24device_id%22%3A%22181d13acb2c3bd-011f19b55b75a8-1c525635-1296000-181d13acb2d5fb%22%2C%22props%22%3A%7B%22%24latest_traffic_source_type%22%3A%22%E7%9B%B4%E6%8E%A5%E6%B5%81%E9%87%8F%22%2C%22%24latest_referrer%22%3A%22%22%2C%22%24latest_referrer_host%22%3A%22%22%2C%22%24latest_search_keyword%22%3A%22%E6%9C%AA%E5%8F%96%E5%88%B0%E5%80%BC_%E7%9B%B4%E6%8E%A5%E6%89%93%E5%BC%80%22%7D%2C%22first_id%22%3A%22796e4a09-ba11-4ecb-9cf6-aad19169267d%22%7D; Hm_lpvt_9793f42b498361373512340937deb2a0=1661483362'cookie_dic = {}for i in cookies.split(';'):v = i.split('=')cookie_dic[v[0]] = v[1]# {i.split('=')[0]:i.split('=')[1] for i in cookies_str.split('; ')} # 简写for url in self.start_urls:yield scrapy.Request(url, cookies=cookie_dic)def parse(self, response):print(response.text)
注意:
- scrapy中cookie不能够放在headers中,在构造请求的时候有专门的cookies参数,能够接受字典形式的coookie
- 在setting中设置ROBOTS协议、USER_AGENT
4-4-4 scrapy.FormRequest发送post请求
# 我们知道可以通过scrapy.Request()指定method、body参数来发送post请求;那么也可以使用scrapy.FormRequest()来发送post请求
4-1 scrapy.FormRequest()的使用
通过scrapy.FormRequest能够发送post请求,同时需要添加fromdata参数作为请求体,以及callback
import scrapyclass DlSpider(scrapy.Spider):name = 'dl'allowed_domains = ['17k.com']start_urls = ['https://user.17k.com/ck/user/myInfo/96139098?bindInfo=1&appKey=2406394919']def start_requests(self):# 登录的url地址login_url = 'https://passport.17k.com/ck/user/login'data = {'loginName': '17346570232','password': 'xlg17346570232'}# data = 'loginName=17346570232&password=xlg17346570232'# yield scrapy.Request(login_url, body=data, method='POST', callback=self.parse_do_login)yield scrapy.FormRequest(login_url, formdata=data, callback=self.parse_do_login)def parse_do_login(self, response, **kwargs):# 当前对于start_urls中的地址进行请求yield scrapy.Request(self.start_urls[0])def parse(self, response, **kwargs):print(response.text)
4-2 使用scrapy.FormRequest()登陆
4-2-1 思路分析
1. 找到post的url地址:点击登录按钮进行抓包,然后定位url地址为https://user.17k.com/ck/user/mine/readList?page=1&appKey=2406394919
2. 找到请求体的规律:分析post请求的请求体,其中包含的参数均在前一次的响应中
3. 否登录成功:通过请求个人主页,观察是否包含用户名
4-2-2 代码实现如下:
import scrapyclass DengluSpider(scrapy.Spider):name = 'denglu'# allowed_domains = ['17k.com']start_urls = ['https://user.17k.com/ck/user/mine/readList?page=1&appKey=2406394919']def start_requests(self):'''请求登陆的账号和密码'''login_url = 'https://passport.17k.com/ck/user/login'# 使用request进行请求# yield scrapy.Request(url=login_url, body='loginName=17346570232&password=xlg17346570232', callback=self.do_login, method='POST')# 使用Request子类FormRequest进行请求 自动为post请求yield scrapy.FormRequest(url=login_url,formdata={'loginName': '17346570232', 'password': 'xlg17346570232'},callback=self.do_login)def do_login(self, response):'''登陆成功后调用parse进行处理cookie中间件会帮我们自动处理携带cookie'''for url in self.start_urls:yield scrapy.Request(url=url, callback=self.parse)def parse(self, response, **kwargs):print(response.text)
4-4-3、小技巧
在settings.py中通过设置COOKIES_DEBUG=TRUE 能够在终端看到cookie的传递传递过程
注意关闭LOG_LEVEL
4-4-5 验证码处理
5-1 传统登录处理
import base64
import json
import requestsurl = 'https://so.gushiwen.cn/user/login.aspx?from=http%3a%2f%2fso.gushiwen.cn%2fuser%2fcollect.aspx'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36','Referer':'https://so.gushiwen.cn/user/login.aspx?from=http://so.gushiwen.cn/user/collect.aspx',
}
data = {'__VIEWSTATE': 'mz408EoRxmRm5lSHqJ2RgFvDmJqOk/mNy0oQveKPJPdj0PQK8DemwQgoq6A8jEwXORmftrgcWnfuSWI1oRJrgp6x5kl+ouo08OG//6RLDTfZF2Zgi6K9midMNOik8R5upVE3d0PXol3YVxWLqkfOYpZRLHk=','__VIEWSTATEGENERATOR': 'C93BE1AE','from': 'http://so.gushiwen.cn/user/collect.aspx','email': '793390457@qq.com','pwd': 'xlg17346570232','code': '','denglu': '登录'
}def base64_api(uname, pwd, img, typeid):with open(img, 'rb') as f:base64_data = base64.b64encode(f.read())b64 = base64_data.decode()data = {"username": uname, "password": pwd, "typeid": typeid, "image": b64}result = json.loads(requests.post("http://api.ttshitu.com/predict", json=data).text)if result['success']:return result["data"]["result"]else:#!!!!!!!注意:返回 人工不足等 错误情况 请加逻辑处理防止脚本卡死 继续重新 识别return result["message"]return ""if __name__ == "__main__":img_path = "yzm.jpg"# 验证码地址yzm_url = 'https://so.gushiwen.cn/RandCode.ashx'session = requests.Session()img_res = session.get(yzm_url)# 验证码存入本地with open(img_path, 'wb') as f:f.write(img_res.content)# 识别验证码result = base64_api(uname='luckyboyxlg', pwd='17346570232', img=img_path, typeid=3)print(result)# 验证码扔进表单data['code'] = result# 请求登录接口res = session.post(url, headers=headers, data=data)with open('gsw.html', 'w', encoding='UTF-8') as f:f.write(res.content.decode())5-2 scrapy处理验证码
import scrapy
import json
import base64
import requestsclass DlSpider(scrapy.Spider):name = 'dl'# allowed_domains = ['dl.com']start_urls = ['https://so.gushiwen.cn/RandCode.ashx']def parse(self, response, **kwargs):img_path = "yzm.jpg"with open(img_path, 'wb') as f:f.write(response.body)# 识别验证码result = self.base64_api(uname='luckyboyxlg', pwd='17346570232', img=img_path, typeid=3)print(result)data = {'__VIEWSTATE': 'mz408EoRxmRm5lSHqJ2RgFvDmJqOk/mNy0oQveKPJPdj0PQK8DemwQgoq6A8jEwXORmftrgcWnfuSWI1oRJrgp6x5kl+ouo08OG//6RLDTfZF2Zgi6K9midMNOik8R5upVE3d0PXol3YVxWLqkfOYpZRLHk=','__VIEWSTATEGENERATOR': 'C93BE1AE','from': 'http://so.gushiwen.cn/user/collect.aspx','email': '793390457@qq.com','pwd': 'xlg17346570232','code': result,'denglu': '登录'}# 请求登录接口url = 'https://so.gushiwen.cn/user/login.aspx?from=http%3a%2f%2fso.gushiwen.cn%2fuser%2fcollect.aspx'yield scrapy.FormRequest(url, formdata=data, callback=self.parse_login)def parse_login(self, response):with open('gsw.html', 'w', encoding='UTF-8') as f:f.write(response.text)def base64_api(self, uname, pwd, img, typeid):with open(img, 'rb') as f:base64_data = base64.b64encode(f.read())b64 = base64_data.decode()data = {"username": uname, "password": pwd, "typeid": typeid, "image": b64}result = json.loads(requests.post("http://api.ttshitu.com/predict", json=data).text)if result['success']:return result["data"]["result"]else:#!!!!!!!注意:返回 人工不足等 错误情况 请加逻辑处理防止脚本卡死 继续重新 识别return result["message"]return ""
4-5 scrapy发送翻页请求
4-5-1 传统抓取四大名著
5-1-1 request抓取
from urllib.parse import urljoin
import requests
from lxml import etreeheaders = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36',
}
url = 'https://www.shicimingju.com/bookmark/sidamingzhu.html'
response = requests.get(url, headers=headers)
con = response.content.decode()
tree = etree.HTML(con)
# print(con)
book_list = tree.xpath('//div[@class="book-item"]/h3/a')
for a in book_list:href = urljoin('https://www.shicimingju.com/',a.xpath('./@href')[0])book_name = a.xpath('./text()')[0]print(href, book_name)
5-1-2 抓取章节
from urllib.parse import urljoin
import requests
from lxml import etree# 获取章节名称和url
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36',
}
url = 'https://www.shicimingju.com/book/sanguoyanyi.html'
response = requests.get(url, headers=headers)
con = response.content.decode()
tree = etree.HTML(con)
# 获取所有的章节的超链接
mulu_list = tree.xpath('//div[@class="book-mulu"]/ul/li/a')
for mulu in mulu_list:# 拼接完整的章节urlmulu_url = urljoin('https://www.shicimingju.com/', mulu.xpath('./@href')[0])# 获取章节名称mulu_name = mulu.xpath('./text()')[0]print(mulu_url, mulu_name)
5-1-3 抓取书的内容
from urllib.parse import urljoin
import requests
from lxml import etreeheaders = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36',
}
url = 'https://www.shicimingju.com/book/sanguoyanyi/1.html'
response = requests.get(url, headers=headers)
con = response.content.decode()
tree = etree.HTML(con)
# 抓取章节的内容
con = ''.join(tree.xpath('//div[@class="card bookmark-list"]//text()'))
print(con)
5-1-4 最终版本
import os.path
import time
from urllib.parse import urljoin
import requests
from lxml import etree
import randomdef get_data(url):'''对url发起请求 返回tree对象:param url: 请求的url地址:return: tree对象'''headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36',}response = requests.get(url, headers=headers)con = response.content.decode()tree = etree.HTML(con)return treedef get_book(tree):'''获取书的名称和url地址:param tree: 当前内容的tree对象:return: 书名和url的字典 {'三国演义': ‘http://www......’}'''book_list = tree.xpath('//div[@class="book-item"]/h3/a')book_href_name = {}for a in book_list:href = urljoin('https://www.shicimingju.com/', a.xpath('./@href')[0])book_name = a.xpath('./text()')[0]# print(href, book_name)book_href_name[book_name] = hrefreturn book_href_namedef get_mulu(tree):'''获取书章节的url和名称:param tree: 请求章节内容返回的tree对象:return: dict {'第一章': 'http://www....'}'''mulu_list = tree.xpath('//div[@class="book-mulu"]/ul/li/a')mulu_href_name = {}for mulu in mulu_list:# 拼接完整的章节urlmulu_url = urljoin('https://www.shicimingju.com/', mulu.xpath('./@href')[0])# 获取章节名称mulu_name = mulu.xpath('./text()')[0]# print(mulu_url, mulu_name)mulu_href_name[mulu_name] = mulu_urlreturn mulu_href_namedef get_content(book_name, mulu_name, tree):'''将章节内容写入到本地:param book_name: 书的名称:param mulu_name: 章节名称:param tree: tree对象:return: None'''# 如果当前书的目录不存在 则创建if not os.path.exists(book_name):os.mkdir(book_name)# 抓取章节的内容con = ''.join(tree.xpath('//div[@class="card bookmark-list"]//text()'))# print(con)with open(os.path.join(book_name, mulu_name+'.txt'), 'w', encoding='UTF-8') as f:f.write(con)print(book_name, mulu_name, '下载完成')if __name__ == '__main__':url = 'https://www.shicimingju.com/bookmark/sidamingzhu.html'# 获取书的url和书的名称for book_name, book_url in get_book(get_data(url)).items():# 循环获取章节和章节urlfor mulu_name, mulu_url in get_mulu(get_data(book_url)).items():# 进行下载get_content(book_name, mulu_name, get_data(mulu_url))time.sleep(random.randint(1,3))
4-5-2 scrapy.Request的更多参数
scrapy.Request(url[,callback,method="GET",headers,body,cookies, meta,dont_filter=False])
参数解释
1. 中括号中的参数为可选参数
2. callback:## 表示当前的url的响应交给哪个函数去处理
3. meta:## 实现数据在不同的解析函数中传递,meta默认带有部分数据,比如下载延迟,请求深度等
4. dont_filter:## 默认为False,会过滤请求的url地址,即请求过的url地址不会继续被请求,对需要重复请求的url地址可以把它设置为Ture,比如贴吧的翻页请求,页面的数据总是在变化;start_urls中的地址会被反复请求,否则程序不会启动
5. method:## 指定POST或GET请求
6. headers:## 接收一个字典,其中不包括cookies
7. cookies:## 接收一个字典,专门放置cookies
8. body: ## 传递数据 字符串格式 为POST的数据
4-5-3 meta参数的作用
meta的形式:字典
meta的作用:meta可以实现数据在不同的解析函数中的传递
在爬虫文件的parse方法中,提取详情页增加之前callback指定的parse_detail函数:
def parse(self,response):...yield scrapy.Request(detail_url, callback=self.parse_detail,meta={"item":item})
...def parse_detail(self,response):#获取之前传入的itemitem = resposne.meta["item"]
特别注意
- meta参数是一个字典
- meta字典中有一个固定的键
proxy,表示代理ip,关于代理ip的使用我们将在scrapy的下载中间件的学习中进行介绍
4-5-4 scrapy抓取四大名著
爬虫的代码
import scrapyclass SdmzSpider(scrapy.Spider):name = 'sdmz'# allowed_domains = ['www.com']start_urls = ['https://www.shicimingju.com/bookmark/sidamingzhu.html']def parse(self, response, **kwargs):# 获取四大名著的书名和urla_list = response.xpath('//div[@class="book-item"]/h3/a')for a in a_list:book_url = response.urljoin(a.xpath('./@href').extract_first())book_name = a.xpath('./text()').extract_first()# print(book_url, book_name)# 传递书给下一个方法 用于最终创建书存储的路径yield scrapy.Request(book_url, callback=self.parse_mulu, meta={'book_name': book_name})# 处理书的章节的def parse_mulu(self, response, **kwargs):book_name = response.meta['book_name']# 获取书的章节和urla_list = response.xpath('//div[@class="book-mulu"]/ul/li/a')for a in a_list:mulu_url = response.urljoin(a.xpath('./@href').extract_first())mulu_name = a.xpath('./text()').extract_first()# 对章节url进行请求 并携带当前书名 章节名称 方便后续创建存储目录yield scrapy.Request(mulu_url, callback=self.parse_content, meta={'book_name': book_name, 'mulu_name': mulu_name})# 解析章节的内容def parse_content(self, response, **kwargs):# 获取书名, 章节名称,目的为了管道中进行目录层级的创建book_name = response.meta['book_name']mulu_name = response.meta['mulu_name']contnet = ''.join(response.xpath('//div[@class="card bookmark-list"]//text()').extract())# 将书名,章节名,章节的内容传递到管道 进行下载yield {'book_name': book_name, 'mulu_name': mulu_name, 'contnet': contnet}# print({'book_name': book_name, 'mulu_name': mulu_name, 'contnet': contnet})管道的代码
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
import osclass SidamingzhuPipeline:def process_item(self, item, spider):# 书名book_name = item['book_name']# 章节名称mulu_name = item['mulu_name']# 章节内容contnet = item['contnet']# 判断当前书的目录是否存在# if not os.path.exists(book_name):# os.mkdir(book_name)total = '四大名著'# 加一个总目录"""四大名著 水浒三国..."""dir = os.path.join(total, book_name)if not os.path.exists(dir):os.makedirs(dir) # 递归创建# 拼接路径 书的路径path = os.path.join(dir, mulu_name+'.txt')# 写入到本地with open(path, 'w', encoding='UTF-8') as f:f.write(contnet)print(book_name, mulu_name, '下载完成')4-5-5 item.py的作用
4-5-1 Item能够做什么
-
定义item即提前规划好哪些字段需要抓取,scrapy.Field()仅仅是提前占坑,通过item.py能够让别人清楚自己的爬虫是在抓取什么,同时定义好哪些字段是需要抓取的,没有定义的字段不能使用,防止手误
-
在python大多数框架中,大多数框架都会自定义自己的数据类型(在python自带的数据结构基础上进行封装),目的是增加功能,增加自定义异常
4-5-2 定义Item
在items.py文件中定义要提取的字段:
import scrapyclass DoubanItem(scrapy.Item):# define the fields for your item here like:# name = scrapy.Field()name = scrapy.Field() # 电影名称director = scrapy.Field() # 导演screenwriter = scrapy.Field() # 编剧to_star = scrapy.Field() # 主演
4-6 crawlspider爬虫
6-1 crawlspider是什么
回顾之前的代码中,我们有很大一部分时间在寻找下一页的url地址或者是内容的url地址上面,这个过程能更简单一些么?
思路:
- 从response中提取所有的满足规则的url地址
- 自动的构造自己requests请求,发送给引擎
对应的crawlspider就可以实现上述需求,能够匹配满足条件的url地址,组装成Reuqest对象后自动发送给引擎,同时能够指定callback函数
即:crawlspider爬虫可以按照规则自动获取连接
6-2 创建crawlspider
scrapy startproject projectcd projectscrapy genspider -t crawl dz duanzixing.com
进行settings.py配置
6-3 Rules规则
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule## 继承的是CrawISpider
class DzSpider(CrawlSpider):name = 'dz'# allowed_domains = ['dz.com']start_urls = ['https://duanzixing.com/']# 规则'''https://duanzixing.com/page/2/https://duanzixing.com/page/3/'''rules = (# 参数一 链接提取器 必须的(给定一个规则 他舅会按照这个规则进行url的匹配并请求)默认使用的是正则!!!# 参数二 回调 请求后的响应交给谁 跟之前的区别是 没有self# 参数三 是否进入再次匹配 如果不想改为False# Rule(LinkExtractor(allow=r'page/\d+/'), callback='parse_item', follow=False),# Rule(LinkExtractor(allow=r'page/\d+/'), callback='parse_item', follow=True),# Rule(LinkExtractor(allow=r'https://duanzixing\.com/page/\d+/'), callback='parse_item', follow=False),# 抓取所有超链接# Rule(LinkExtractor(allow=r''), callback='parse_item', follow=False),# 使用正则进行匹配Rule(LinkExtractor(restrict_xpaths='/html/body/section/div/div/div[2]/ul/li/a'), callback='parse_item', follow=False),)def parse_item(self, response):item = {}print(response.url)# print(response.url)# response.xpath('//article[@class="excerpt"]/header/a/text()').extract()# response.xpath('//article[@class="excerpt"]/p[@class="note"]/text()').extract()# article_list = response.xpath('//article[@class="excerpt"]')# for article in article_list:# title = article.xpath('./header/h2/a/text()').extract_first()# con = article.xpath('./p[@class="note"]/text()').extract_first()# print(title, con, response.url)return item
6-4 跟scrapy.spider的区别
在crawlspider爬虫中,没有parse函数
重点在rules中:
- rules是一个元组或者是列表,包含的是Rule对象
- Rule表示规则,其中包含LinkExtractor,callback和follow等参数
- LinkExtractor:连接提取器,可以通过正则或者是xpath来进行url地址的匹配
- callback :表示经过连接提取器提取出来的url地址响应的回调函数,可以没有,没有表示响应不会进行回调函数的处理
- follow:连接提取器提取的url地址对应的响应是否还会继续被rules中的规则进行提取,True表示会,Flase表示不会
6-5 crawlspider注意点:
- 除了用命令
scrapy genspider -t crawl <爬虫名> <allowed_domail>创建一个crawlspider的模板,页可以手动创建 - crawlspider中不能再有以parse为名的数据提取方法,该方法被crawlspider用来实现基础url提取等功能
- Rule对象中LinkExtractor为固定参数,其他callback、follow为可选参数
- 不指定callback且follow为True的情况下,满足rules中规则的url还会被继续提取和请求
- 如果一个被提取的url满足多个Rule,那么会从rules中选择一个满足匹配条件的Rule执行
6-6 LinkExtractor的更多常见参数
-
-
allow: 满足括号中的’re’表达式的url会被提取,如果为空,则全部匹配
-
deny: 满足括号中的’re’表达式的url不会被提取,优先级高于allow
-
allow_domains: 会被提取的链接的domains(url范围),如:
['https://movie.douban.com/top250'] -
deny_domains: 不会被提取的链接的domains(url范围)
-
restrict_xpaths: 使用xpath规则进行匹配,和allow共同过滤url,即xpath满足的范围内的url地址会被提取
如:
restrict_xpaths='//div[@class="pagenav"]' -
restrict_css: 接收一堆css选择器, 可以提取符合要求的css选择器的链接
-
attrs: 接收一堆属性名, 从某个属性中提取链接, 默认href
-
tags: 接收一堆标签名, 从某个标签中提取链接, 默认a, area
值得注意的, 在提取到的url中, 是有重复的内容的. 但是我们不用管. scrapy会自动帮我们过滤掉重复的url请求
-
-
模拟使用
正则用法: links1 = LinkExtractor(allow=r’list_23_\d+.html’)
xpath用法: links2 = LinkExtractor(restrict_xpaths=r’//div[@class=“x”]')
css用法: links3 = LinkExtractor(restrict_css=‘.x’)
5.提取连接
-
Rule常见参数
- LinkExtractor: 链接提取器,可以通过正则或者是xpath来进行url地址的匹配
- callback: 表示经过连接提取器提取出来的url地址响应的回调函数,可以没有,没有表示响应不会进行回调函数的处理
- follow: 连接提取器提取的url地址对应的响应是否还会继续被rules中的规则进行提取,默认True表示会,Flase表示不会
- process_links: 当链接提取器LinkExtractor获取到链接列表的时候调用该参数指定的方法,这个自定义方法可以用来过滤url,且这个方法执行后才会执行callback指定的方法
6-7 总结
- crawlspider的作用:crawlspider可以按照规则自动获取连接
- crawlspider爬虫的创建:scrapy genspider -t crawl xxx www.xxx.com
- crawlspider中rules的使用:
- rules是一个元组或者是列表,包含的是Rule对象
- Rule表示规则,其中包含LinkExtractor,callback和follow等参数
- LinkExtractor:连接提取器,可以通过正则或者是xpath来进行url地址的匹配
- callback :表示经过连接提取器提取出来的url地址响应的回调函数,可以没有,没有表示响应不会进行回调函数的处理
- follow:连接提取器提取的url地址对应的响应是否还会继续被rules中的规则进行提取,True表示会,Flase表示不会
5,scrapy中间件
5-1 scrapy中间件的作用
1. 主要功能是在爬虫运行过程中进行一些处理,如对非200响应的重试(重新构造Request对象yield给引擎)
2. 也可以对header以及cookie进行更换和处理
3. 其他根据业务需求实现响应的功能
但在scrapy默认的情况下 两种中间件都在middlewares.py一个文件中
爬虫中间件使用方法和下载中间件相同,常用下载中间件
5-2 下载中间件的使用方法
接下来我们对爬虫进行修改完善,通过下载中间件来学习如何使用中间件 编写一个Downloader Middlewares和我们编写一个pipeline一样,定义一个类,然后在setting中开启
Downloader Middlewares默认的方法:在中间件类中,有时需要重写处理请求或者响应的方法】
-
process_request(self, request, spider):【此方法是用的最多的】
- ## 当每个request通过下载中间件时,该方法被调用。 - ## 返回None值:继续请求 没有return也是返回None,该request对象传递给下载器,或通过引擎传递给其他权重低的process_request方法 【如果所有的下载器中间件都返回为None,则请求最终被交给下载器处理】 - ## 返回Response对象:不再请求,把response返回给引擎【如果返回为请求,则将请求交给调度器】 - ## 返回Request对象:把request对象交给调度器进行后续的请求 -
process_response(self, request, response, spider):
- ## 当下载器完成http请求,传递响应给引擎的时候调用 - ## 返回Resposne:通过引擎交给爬虫处理或交给权重更低的其他下载中间件的process_response方法 【如果返回为请求,则将请求交给调度器】 - ## 返回Request对象:交给调取器继续请求,此时将不通过其他权重低的process_request方法 -
process_exception(self, request, exception, spider):
-
请求出现异常的时候进行调用
-
比如当前请求被识别为爬虫 可以使用代理
def process_exception(self, request, exception, spider):request.meta['proxy'] = 'http://ip地址'request.dont_filter = True # 因为默认请求是去除重复的,因为当前已经请求过,所以需要设置当前为不去重return request # 将修正后的对象重新进行请求
-
-
在settings.py中配置开启中间件,权重值越小越优先执行 【同管道的使用方式相同】
-
spider参数:为爬虫中类的实例化可以在这里进行调用爬虫中的属性
如:spider.name
5-3 中间件的简单使用
spiders.py(爬虫代码)news.163.com/domestic/
import scrapyclass DzSpider(scrapy.Spider):name = 'dz'# allowed_domains = ['duanzixing.com']start_urls = ['https://duanzixing.com/']def parse(self, response, **kwargs):print(response.request.headers)settings.py(开启中间件)
也别忘了其他的配置(前面学习过程中讲过了)
DOWNLOADER_MIDDLEWARES = {'wangyi.middlewares.WangyiDownloaderMiddleware': 543,
}
middlewares.py
from scrapy import signals# 导入随机ua
from zhongjianjian01.settings import USER_AGENTS_LIST
import randomclass Zhongjianjian01DownloaderMiddleware:# Not all methods need to be defined. If a method is not defined,# scrapy acts as if the downloader middleware does not modify the# passed objects.@classmethoddef from_crawler(cls, crawler):# This method is used by Scrapy to create your spiders.s = cls()crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)return sdef process_request(self, request, spider):# 随机uaua = random.choice(USER_AGENTS_LIST)request.headers['User-Agent'] = uaprint(request.headers['User-Agent'])print('process_request')return Nonedef process_response(self, request, response, spider):print('process_response')return responsedef process_exception(self, request, exception, spider):print('process_exception', exception)def spider_opened(self, spider):spider.logger.info('Spider opened: %s' % spider.name)
运行查看
5-4 随机请求头
5-4-1 在settings中添加UA的列表
USER_AGENTS_LIST = [
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Win64; x64; Trident/5.0; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 2.0.50727; Media Center PC 6.0)",
"Mozilla/5.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 1.0.3705; .NET CLR 1.1.4322)",
"Mozilla/4.0 (compatible; MSIE 7.0b; Windows NT 5.2; .NET CLR 1.1.4322; .NET CLR 2.0.50727; InfoPath.2; .NET CLR 3.0.04506.30)",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN) AppleWebKit/523.15 (KHTML, like Gecko, Safari/419.3) Arora/0.3 (Change: 287 c9dfb30)",
"Mozilla/5.0 (X11; U; Linux; en-US) AppleWebKit/527+ (KHTML, like Gecko, Safari/419.3) Arora/0.6",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.8.1.2pre) Gecko/20070215 K-Ninja/2.1.1",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN; rv:1.9) Gecko/20080705 Firefox/3.0 Kapiko/3.0",
"Mozilla/5.0 (X11; Linux i686; U;) Gecko/20070322 Kazehakase/0.4.5"
]
5-4-2 在middlewares.py中完善代码
import random
from Tencent.settings import USER_AGENTS_LIST # 注意导入路径,请忽视pycharm的错误提示class UserAgentMiddleware(object):def process_request(self, request, spider):user_agent = random.choice(USER_AGENTS_LIST)request.headers['User-Agent'] = user_agent
5-4-3 在爬虫文件tencent.py的每个解析函数中添加
class CheckUA:def process_response(self,request,response,spider):print(request.headers['User-Agent'])
5-4-4 在settings中设置开启自定义的下载中间件,设置方法同管道
DOWNLOADER_MIDDLEWARES = {'Tencent.middlewares.UserAgentMiddleware': 543,
}
5-5 代理ip的使用
5-5-1 思路分析
-
代理添加的位置:request.meta中增加
proxy字段 -
获取一个代理ip,赋值给
request.meta['proxy']- 代理池中随机选择代理ip
- 代理ip的webapi发送请求获取一个代理ip
5-5-2 具体实现
class ProxyMiddleware(object):def process_request(self,request,spider):proxy = random.choice(proxies) # proxies可以在settings.py中,也可以来源于代理ip的webapi# proxy = 'http://192.168.1.1:8118'request.meta['proxy'] = proxyreturn None # 可以不写return
5-5-3 检测代理ip是否可用
在使用了代理ip的情况下可以在下载中间件的process_response()方法中处理代理ip的使用情况,如果该代理ip不能使用可以替换其他代理ip
class ProxyMiddleware(object):def process_response(self, request, response, spider):if response.status != '200' and response.status != '302':#此时对代理ip进行操作,比如删除return request
5-5-4 快代理的购买与使用
网址:https://www.kuaidaili.com/
- 输入网址 点击购买代理

- 选择你想购买代理的类型
- 以隧道代理为例 点击购买
- 购买后点击 文档中心
- 点击
- 选择隧道代理
- 向下拉 选择你当前要使用代理的模块
我们是scrapy使用隧道 所以选择 Python-Scrapy
- 找到middlewares.py
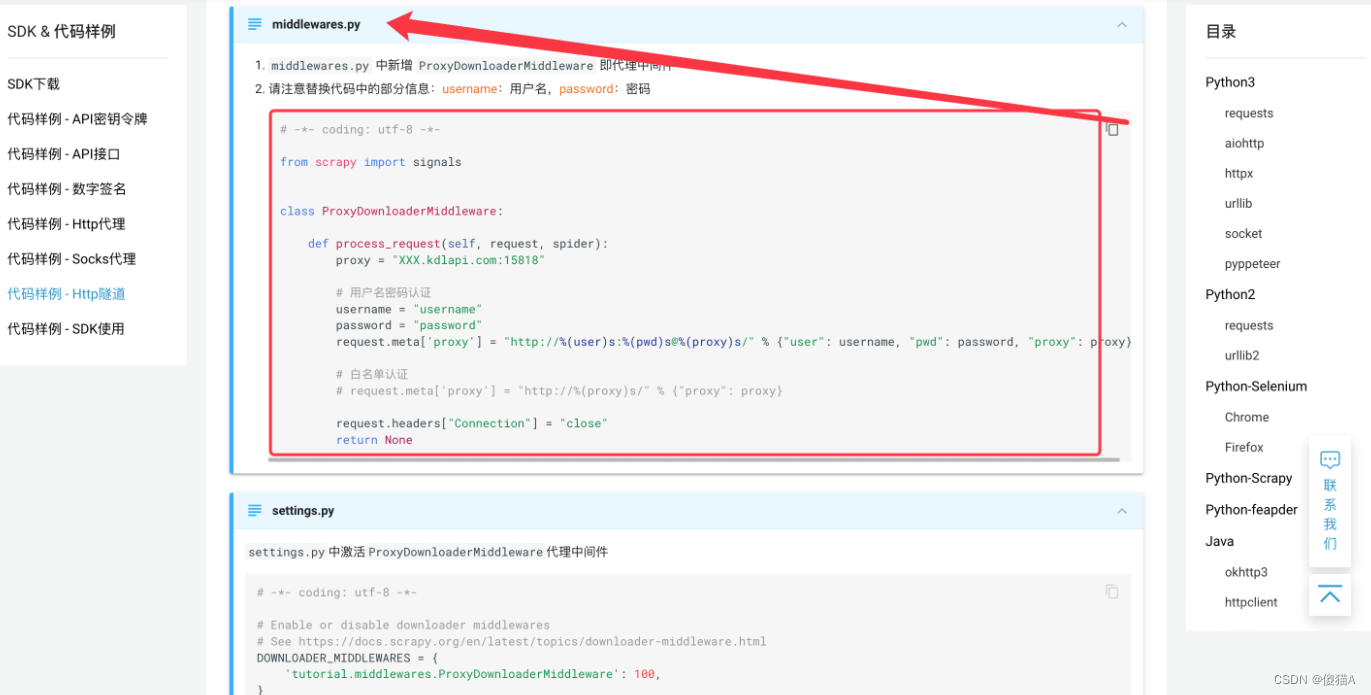
- 将中间件类代码复制到当前自己scrapy的中间件得文件中即可
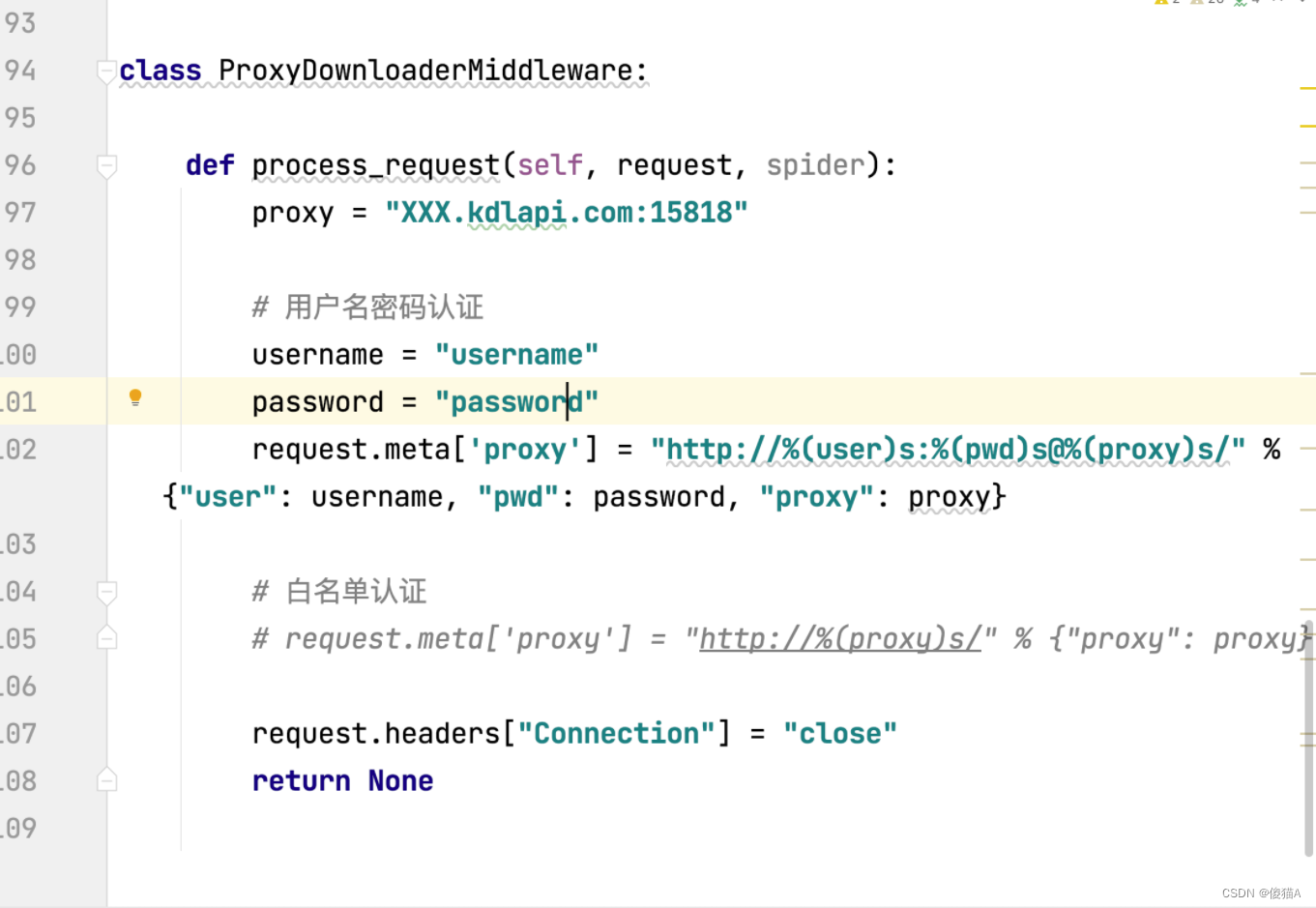
按照步骤开启中间件与填写自己的用户名与密码等信息即可
5-6 总结
中间件的使用:
- 完善中间件代码:
- process_request(self, request, spider):
- 当每个request通过下载中间件时,该方法被调用。
- 返回None值:继续请求
- 返回Response对象:不再请求,把response返回给引擎
- 返回Request对象:把request对象交给调度器进行后续的请求
- process_response(self, request, response, spider):
- 当下载器完成http请求,传递响应给引擎的时候调用
- 返回Resposne:交给process_response来处理
- 返回Request对象:交给调取器继续请求
- process_request(self, request, spider):
- 需要在settings.py中开启中间件 DOWNLOADER_MIDDLEWARES = { ‘myspider.middlewares.UserAgentMiddleware’: 543, }
5-7 抓取网易新闻(selenium)
url:https://news.163.com/
5-7-1 爬取前准备
- scrapy startproject wangyi
- cd wangyi
- scrapy genspider wy https://news.163.com/
5-7-2 爬取前分析
抓取 国内 国际 军事 航空
-
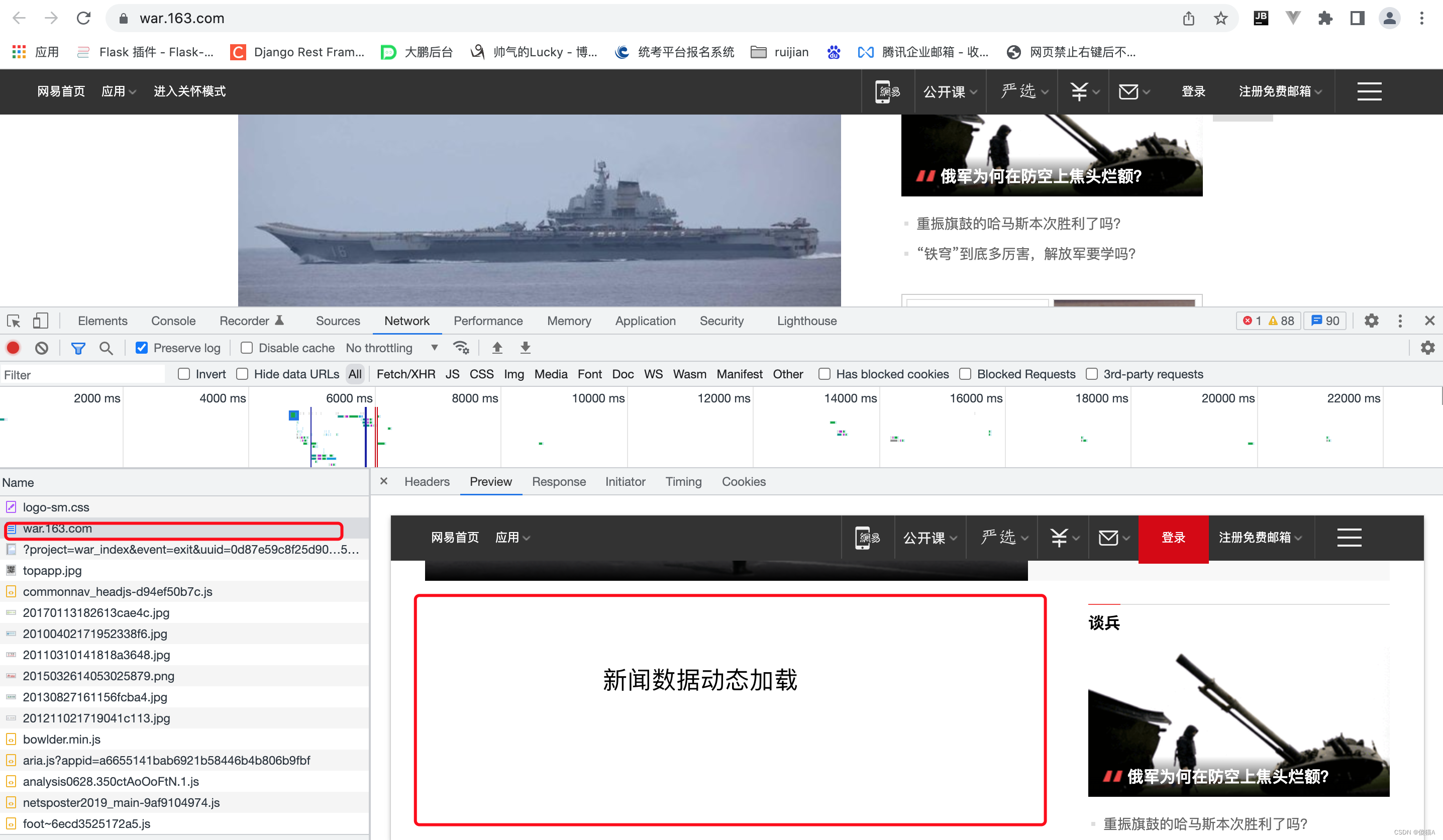
分析
国内等数据是由动态加载的 并不是跟着当前的请求一起返回的
解决方式2种
-
通过selenium配合爬虫抓取页面进行数据
-
找到加载动态数据的url地址 通过爬虫进行抓取
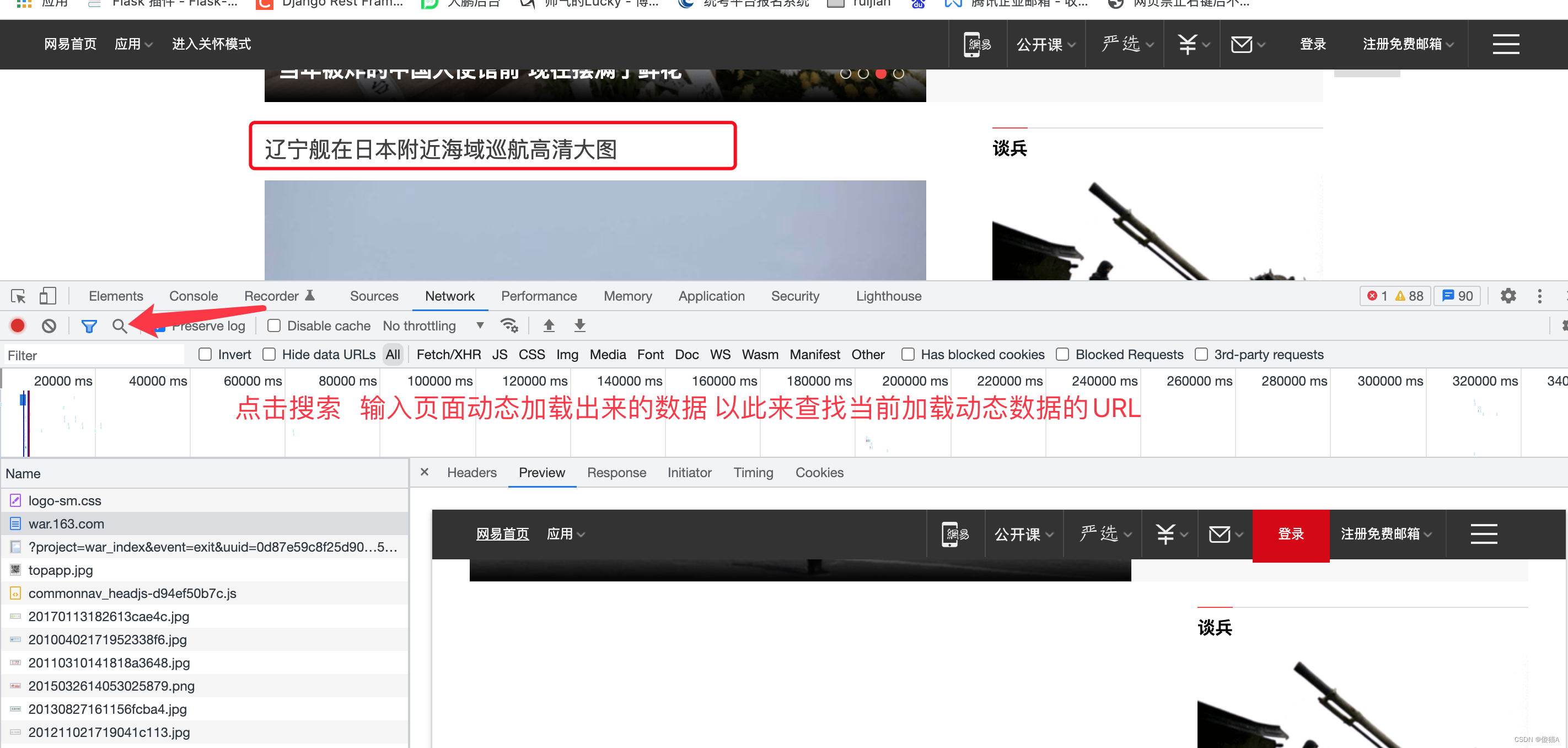
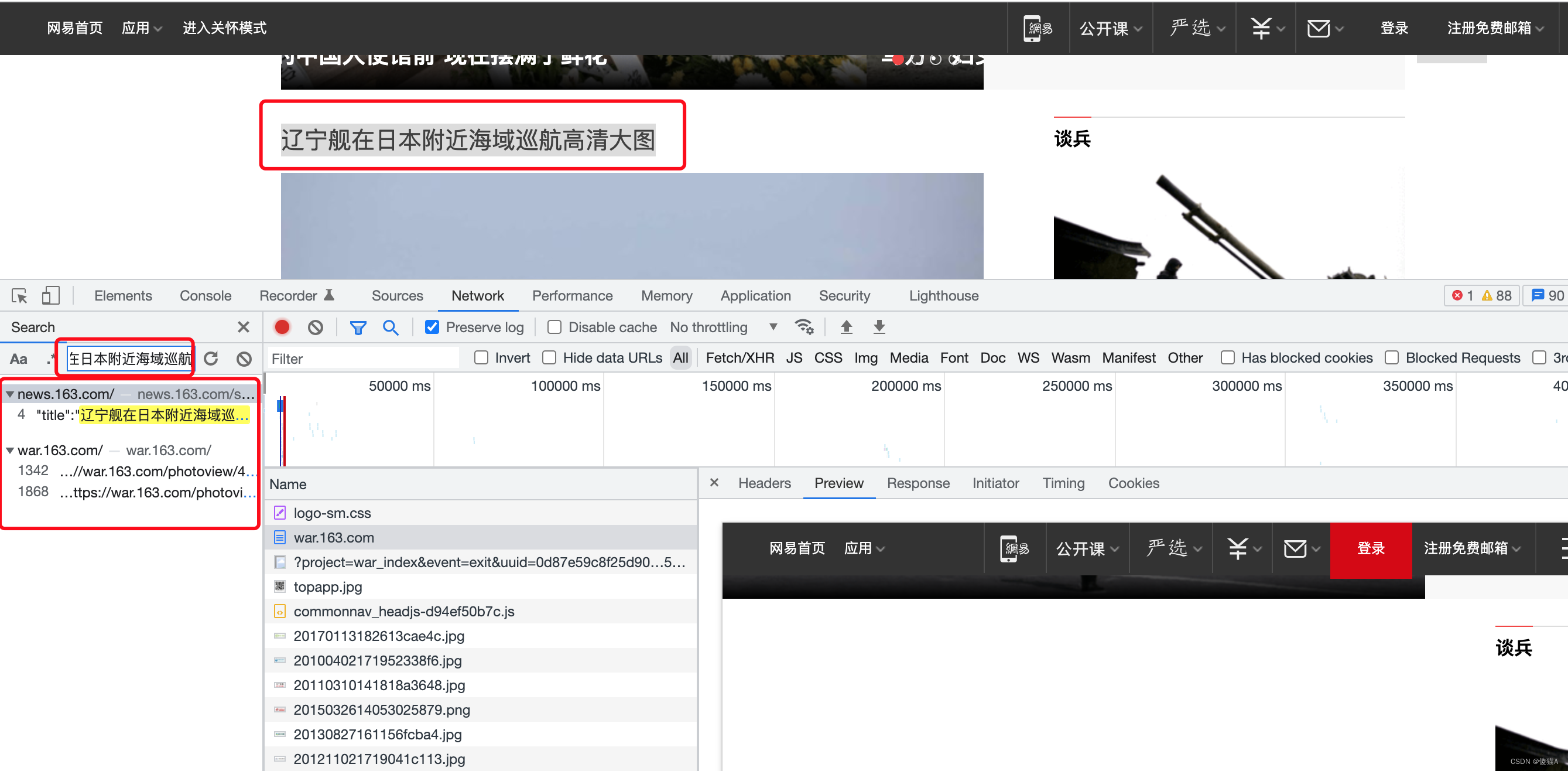
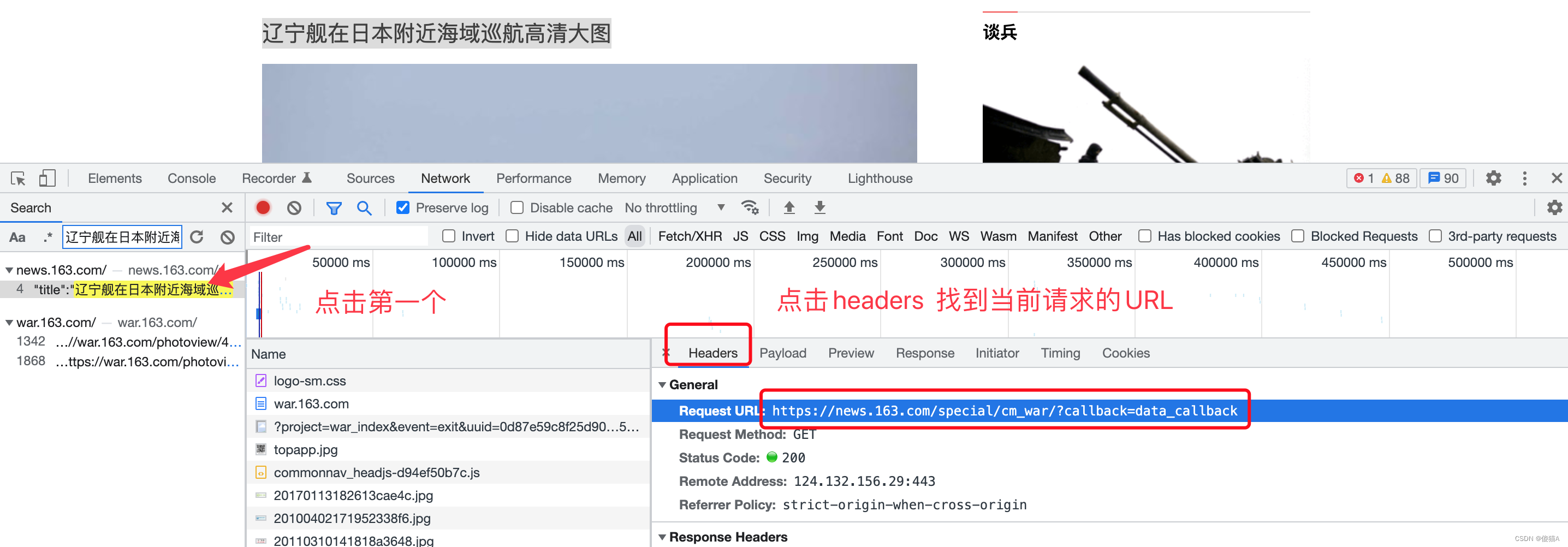
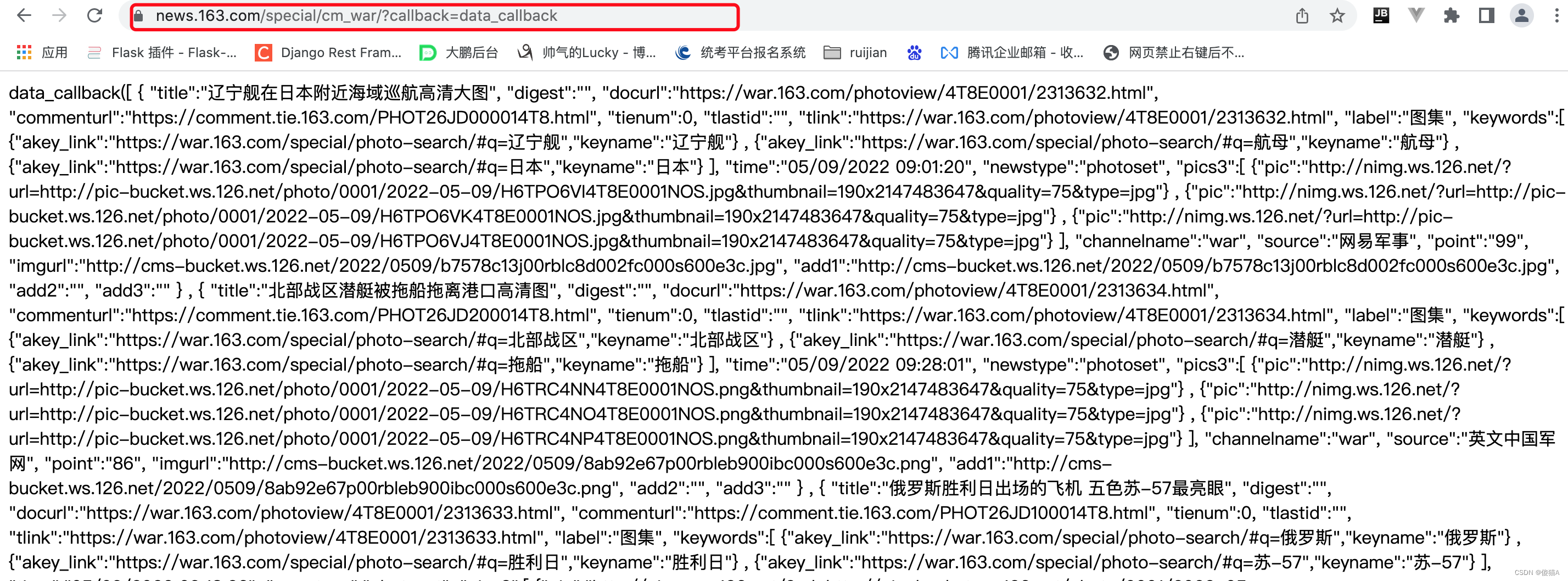
将找到的URL放到浏览器中进行请求 效果如下
-
5-7-3 代码配置
配置文件处理settings.py
# Scrapy settings for wangyi project
BOT_NAME = 'wangyi'SPIDER_MODULES = ['wangyi.spiders']
NEWSPIDER_MODULE = 'wangyi.spiders'# 默认请求头
USER_AGENT = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.127 Safari/537.36'# 用于更换随机请求头
USER_AGENTS_LIST = [
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Win64; x64; Trident/5.0; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 2.0.50727; Media Center PC 6.0)",
"Mozilla/5.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 1.0.3705; .NET CLR 1.1.4322)",
"Mozilla/4.0 (compatible; MSIE 7.0b; Windows NT 5.2; .NET CLR 1.1.4322; .NET CLR 2.0.50727; InfoPath.2; .NET CLR 3.0.04506.30)",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN) AppleWebKit/523.15 (KHTML, like Gecko, Safari/419.3) Arora/0.3 (Change: 287 c9dfb30)",
"Mozilla/5.0 (X11; U; Linux; en-US) AppleWebKit/527+ (KHTML, like Gecko, Safari/419.3) Arora/0.6",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.8.1.2pre) Gecko/20070215 K-Ninja/2.1.1",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN; rv:1.9) Gecko/20080705 Firefox/3.0 Kapiko/3.0",
"Mozilla/5.0 (X11; Linux i686; U;) Gecko/20070322 Kazehakase/0.4.5" ]LOG_LEVEL = 'ERROR'
ROBOTSTXT_OBEY = FalseDOWNLOADER_MIDDLEWARES = {'wangyi.middlewares.WangyiDownloaderMiddleware': 543,
}
ITEM_PIPELINES = {'wangyi.pipelines.WangyiPipeline': 300,
}
爬虫代码wy.py
import scrapy
from selenium.webdriver import Chrome
from selenium.webdriver.chrome.options import Options# 一定重新下载谷歌驱动!!!!!class WySpider(scrapy.Spider):name = 'wy'opt = Options()opt.add_argument("--headless")# opt.add_argument('--disable-gpu')# 实例化selenium对象web = Chrome(options=opt)# allowed_domains = ['news.163.com/domestic/']start_urls = ['https://news.163.com/']li_index = [1, 2]url_list = [] # 存放国内和国际的urldef parse(self, response, **kwargs):# 抓取我们要访问的url 国内 国际menu_list = response.xpath('//div[@class="ns_area list"]/ul/li/a/@href').extract()for i in range(len(menu_list)):if i in self.li_index:url = menu_list[i] # 取出国内 国际的urlself.url_list.append(url)yield scrapy.Request(url, callback=self.parse_page)# 解析国内,国际页面的数据def parse_page(self, response, **kwargs):# 解析新闻详情的urlpage_detail_url = response.xpath('//div[@class="ndi_main"]/div/a/@href').extract()for url in page_detail_url:yield scrapy.Request(url, callback=self.parse_page_detail)# 解析新闻详情def parse_page_detail(self, response, **kwargs):title = response.xpath('//h1[@class="post_title"]/text()').extract_first()# 新闻内容con = ''.join(response.xpath('//div[@class="post_main"]//text()').extract())data = {'title': title, 'con': con}print(data)yield dataMiddlewares.py
import time
from scrapy import signals
from itemadapter import is_item, ItemAdapter
from scrapy.http import HtmlResponserom wangyi.settings import USER_AGENTS_LIST
import random
class WangyiDownloaderMiddleware:# Not all methods need to be defined. If a method is not defined,# scrapy acts as if the downloader middleware does not modify the# passed objects.@classmethoddef from_crawler(cls, crawler):# This method is used by Scrapy to create your spiders.s = cls()crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)return sdef process_request(self, request, spider):ua = random.choice(USER_AGENTS_LIST)request.headers['User-Agent'] = uareturn Nonedef process_response(self, request, response, spider):driver = spider.web # 拿到selenium对象url = request.urlif url in spider.url_list:driver.get(url) # 开始访问的url# 滚动条滚动到底部driver.execute_script('window.scrollTo(0, document.body.scrollHeight)')time.sleep(random.randint(1, 3))driver.execute_script('window.scrollTo(0, document.body.scrollHeight)')time.sleep(random.randint(1, 3))source = driver.page_source # 获取页面源代码# 篡改响应return HtmlResponse(url=url, body=source, encoding='UTF-8', request=request)return responsedef process_exception(self, request, exception, spider):# Called when a download handler or a process_request()# (from other downloader middleware) raises an exception.# Must either:# - return None: continue processing this exception# - return a Response object: stops process_exception() chain# - return a Request object: stops process_exception() chainpassdef spider_opened(self, spider):spider.logger.info('Spider opened: %s' % spider.name)
6,scrapy_redis
6-1 scrapy_redis分布式原理
学习目标
- 了解 scarpy_redis的概念和功能
- 了解 scrapy_redis的原理
- 了解 redis数据库操作命令
在前面scrapy框架中我们已经能够使用框架实现爬虫爬取网站数据,如果当前网站的数据比较庞大, 我们就需要使用分布式来更快的爬取数据
6-1-1 scrapy_redis是什么
安装
pip install scrapy_redis == 0.7.2
6-1-2 为什么要学习scrapy_redis
Scrapy_redis在scrapy的基础上实现了更多,更强大的功能,具体体现在:
- 请求对象的持久化
- 去重的持久化
- 和实现分布式
6-1-3 scrapy_redis的原理分析
3.1 回顾scrapy的流程
那么,在这个基础上,如果需要实现分布式,即多台服务器同时完成一个爬虫,需要怎么做呢?
3.2 scrapy_redis的流程
- 在scrapy_redis中,所有的带抓取的对象和去重的指纹都存在所有的服务器公用的redis中
- 所有的服务器公用一个redis中的request对象
- 所有的request对象存入redis前,都会在同一个redis中进行判断,之前是否已经存入过
- 在默认情况下所有的数据会保存在redis中
具体流程如下:
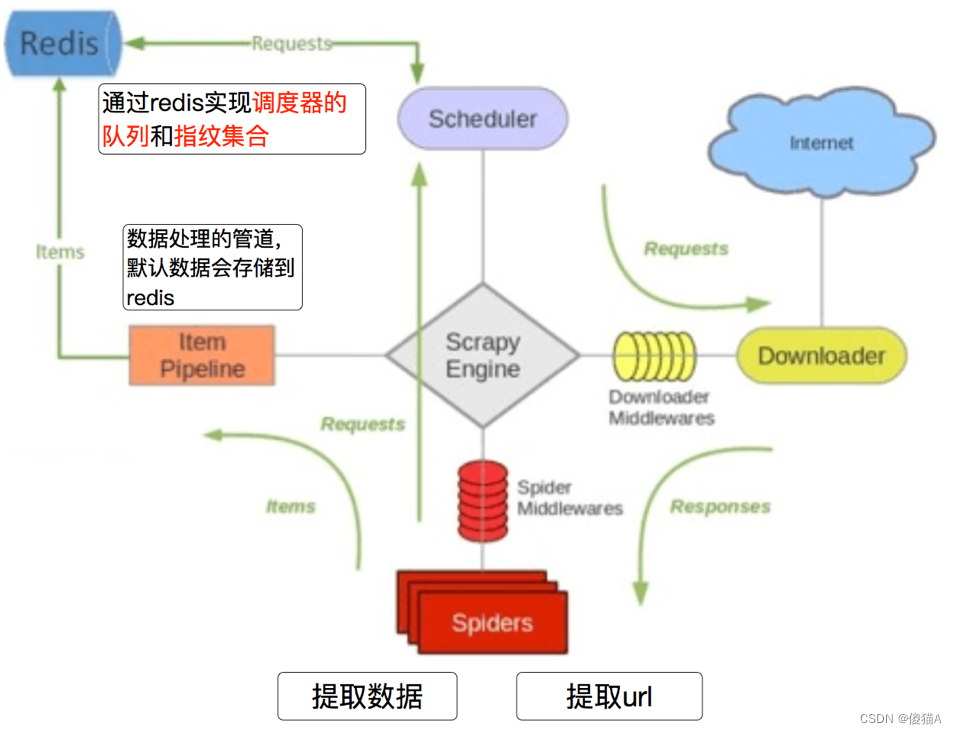
6-1-4 对于redis的复习
由于时间关系,大家对redis的命令遗忘的差不多了, 但是在scrapy_redis中需要使用redis的操作命令,所有需要回顾下redis的命令操作
4.1 redis是什么
redis是一个开源的内存型数据库,支持多种数据类型和结构,比如列表、集合、有序集合等,同时可以使用redis-manger-desktop等客户端软件查看redis中的数据,关于redis-manger-desktop的使用可以参考扩展阅读
4.2 redis服务端和客户端的启动
redis-server.exe redis.windows.conf启动服务端redis-cli客户端启动
4.3 redis中的常见命令
select 1切换dbkeys *查看所有的键type 键查看键的类型flushdb清空dbflushall清空数据库
4.4 redis命令的复习
redis的命令很多,这里我们简单复习后续会使用的命令

6-1-5 小结
scarpy_redis的分布式工作原理
- 在scrapy_redis中,所有的带抓取的对象和去重的指纹都存在所有的服务器公用的redis中
- 所有的服务器公用一个redis中的request对象
- 所有的request对象存入redis前,都会在同一个redis中进行判断,之前是否已经存入过
6-2 配置分布式爬虫
配置完成使用分布式爬虫
6-2-1 概述
分布式爬虫
- 使用多台机器搭建一个分布式的机器,然后让他们联合且分布的对同一组资源进行数据爬取
- 原生的scrapy框架是无法实现分布式爬虫?
- 原因:调度器,管道无法被分布式机群共享
- 如何实现分布式
- 借助:scrapy-redis组件
- 作用:提供了可以被共享的管道和调度器
- 只可以将爬取到的数据存储到redis中
6-2-2 创建分布式crawlspider爬虫
- scrapy startproject fbsPro
- cd fbsPro
- scrapy genspider -t crawl fbs www.xxx.com
6-2-3 redis-settings需要的配置
-
(必须). 使用了scrapy_redis的去重组件,在redis数据库里做去重
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter" -
(必须). 使用了scrapy_redis的调度器,在redis里分配请求
SCHEDULER = "scrapy_redis.scheduler.Scheduler" -
(可选). 在redis中保持scrapy-redis用到的各个队列,从而允许暂停和暂停后恢复,也就是不清理redis queues
SCHEDULER_PERSIST = True -
(必须). 通过配置RedisPipeline将item写入key为 spider.name : items 的redis的list中,供后面的分布式处理item 这个已经由 scrapy-redis 实现,不需要我们写代码,直接使用即可
ITEM_PIPELINES = {'scrapy_redis.pipelines.RedisPipeline': 100 , } -
(必须). 指定redis数据库的连接参数
REDIS_HOST = '127.0.0.1' REDIS_PORT = 6379 REDIS_DB = 0 # (不指定默认为0) # 设置密码 REDIS_PARAMS = {'password': '123456'}
6-2-4 settings.py
settings.py
这几行表示scrapy_redis中重新实现的了去重的类,以及调度器,并且使用的RedisPipeline
需要添加redis的地址,程序才能够使用redis
在settings.py文件修改pipelines,增加scrapy_redis。
# 配置分布式
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
SCHEDULER_PERSIST = TrueITEM_PIPELINES = {'scrapy_redis.pipelines.RedisPipeline': 400,
}# 或者使用下面的方式
REDIS_HOST = "127.0.0.1"
REDIS_PORT = 6379
REDIS_PARAMS = {'password': '123456'}
注意:scrapy_redis的优先级要调高
6-2-5 爬虫文件代码中 fbs.py
from scrapy_redis.spiders import RedisCrawlSpider# 注意 一定要继承RedisCrawlSpider
class FbsSpider(RedisCrawlSpider):name = 'fbs'# allowed_domains = ['www.xxx.com']# start_urls = ['http://www.xxx.com/']redis_key = 'fbsQueue' # 使用管道名称(课根据实际功能起名称)
6-2-6 scrapy-redis键名介绍
scrapy-redis中都是用key-value形式存储数据,其中有几个常见的key-value形式:
1、 “项目名:items” -->list 类型,保存爬虫获取到的数据item 内容是 json 字符串
2、 “项目名:dupefilter” -->set类型,用于爬虫访问的URL去重 内容是 40个字符的 url 的hash字符串
3、 “项目名:requests” -->zset类型,用于scheduler调度处理 requests 内容是 request 对象的序列化 字符串
5-2-7 完整代码配置
-
网址
阳光问政为例
https://wz.sun0769.com/political/index/politicsNewest
-
settings.py
BOT_NAME = 'fbsPro'SPIDER_MODULES = ['fbsPro.spiders'] NEWSPIDER_MODULE = 'fbsPro.spiders'USER_AGENT = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.127 Safari/537.36'# Obey robots.txt rules ROBOTSTXT_OBEY = False# 配置分布式 DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter" SCHEDULER = "scrapy_redis.scheduler.Scheduler" SCHEDULER_PERSIST = TrueITEM_PIPELINES = {'scrapy_redis.pipelines.RedisPipeline': 400, }# 或者使用下面的方式 REDIS_HOST = "127.0.0.1" REDIS_PORT = 6379 REDIS_PARAMS = {'password': '123456'} -
fbs.py
实现方式就是之前的
crawlspider类型的爬虫import scrapy from scrapy.linkextractors import LinkExtractor from scrapy.spiders import CrawlSpider, Rule from scrapy_redis.spiders import RedisCrawlSpider# 注意 一定要继承RedisCrawlSpider class FbsSpider(RedisCrawlSpider):name = 'fbs'# allowed_domains = ['www.xxx.com']# start_urls = ['http://www.xxx.com/']redis_key = 'fbsQueue' # 使用管道名称link = LinkExtractor(allow=r'/political/politics/index?id=\d+')rules = (Rule(link, callback='parse_item', follow=True),)def parse_item(self, response):item = {}yield item -
redis中
-
redis-windwos.conf
- 56行添加注释 取消绑定127.0.0.1 # bind 127.0.0.1
- 75行 修改保护模式为no protected-mode no
-
启动redis
-
队列中添加url地址
添加:lpush fbsQueue https://wz.sun0769.com/political/index/politicsNewest
查看:lrange fbsQueue 0 -1
-
-
运行
scrapy crawl fbs
-
去redis中查看存储的数据