- 分类类型数据挖掘任务
基于卷积神经网络(CNN)的岩石图像分类。有一岩石图片数据集,共300张岩石图片,图片尺寸224x224。岩石种类有砾岩(Conglomerate)、安山岩(Andesite)、花岗岩(Granite)、石灰岩(Limestone)、石英岩(Quartzite)和5种,每种岩石图片各50张,共250张。请选择合适模型对该数据集进行建模,训练优化模型并给出模型评估指标,再利用GUI框架开发岩石图片分类界面。

1.1总体流程

1.2数据增强
定义:数据增强是利用现有数据生成新的数据来增加数据量的过程,能够有效地扩充训练数据集的大小,提高模型的泛化能力,同时也能够有效地防止过拟合现象的发生。

本项目采用的数据增强方法:
(1)水平翻转
(2)缩放
(3)旋转
(4)添加高斯噪音
(5)调整对比度和亮度
通过数据增强,数据集从之前的250张扩充至1500张,数据量为之前的6倍。
参考代码:
import cv2
import os
import glob
# 数据增强函数
def augment_data(img, save_path):rows, cols, _ = img.shape# 水平翻转图像img_flip = cv2.flip(img, 1)img_name = os.path.splitext(save_path)[0] + "_flip.jpg"cv2.imwrite(img_name, img_flip)print("Saved augmented image:", img_name)# 随机缩放图像scale = np.random.uniform(0.9, 1.1)M = cv2.getRotationMatrix2D((cols / 2, rows / 2), 0, scale)img_transformed = cv2.warpAffine(img, M, (cols, rows))img_name = os.path.splitext(save_path)[0] + "_transform.jpg"cv2.imwrite(img_name, img_transformed)print("Saved augmented image:", img_name)# 随机旋转图像angle = np.random.randint(-10, 10)M = cv2.getRotationMatrix2D((cols / 2, rows / 2), angle, 1)img_rotated = cv2.warpAffine(img, M, (cols, rows))img_name = os.path.splitext(save_path)[0] + "_rotated.jpg"cv2.imwrite(img_name, img_rotated)print("Saved augmented image:", img_name)# 添加高斯噪音mean = 0std = np.random.uniform(5, 15)noise = np.zeros(img.shape, np.float32)cv2.randn(noise, mean, std)noise = np.uint8(noise)img_noisy = cv2.add(img, noise)img_name = os.path.splitext(save_path)[0] + "_noisy.jpg"cv2.imwrite(img_name, img_noisy)print("Saved augmented image:", img_name)# 随机调整对比度和亮度alpha = np.random.uniform(0.8, 1.2)beta = np.random.randint(-10, 10)img_contrast = cv2.convertScaleAbs(img, alpha=alpha, beta=beta)img_name = os.path.splitext(save_path)[0] + "_contrast.jpg"cv2.imwrite(img_name, img_contrast)print("Saved augmented image:", img_name)return img
# 读取 data 文件夹中的所有图片,并进行数据增强
data_dir = r"images"
save_dir = r"images2"
if not os.path.exists(save_dir):os.makedirs(save_dir)
# 使用 glob 库来遍历 data 文件夹中所有图像
for img_path in glob.glob(os.path.join(data_dir, "*.jpg")):img = cv2.imread(img_path)if img is None:print("Error: Unable to read image at", img_path)continue# 获取保存增强后的图片文件名img_name = os.path.basename(img_path)save_path = os.path.join(save_dir, img_name)# 数据增强augmented_img = augment_data(img, save_path)if augmented_img is not None:# 保存原始图片cv2.imwrite(save_path, img)print("Saved original image:", save_path)结果:

1.3数据预处理
将1500张图片依次读入并转化为可训练的数据(特征变量(X)和标签(Y))
代码:
import os
import cv2
import numpy as np
from PIL import Image
# 设置图片文件夹路径
image_folder = r"images2"
# 获取所有类别的文件夹名(假设每个文件夹是一个类别)
categories = os.listdir(image_folder)# 初始化特征变量 X 和标签 Y 的列表
X_list = np.zeros((len(categories), 224, 224, 3))
Y_list = np.zeros((len(categories)))i=0
for name in categories:img = Image.open(image_folder + '\\' +name)img_rgb = img.split()X_list[i,:,:,0] = np.array(img_rgb[0])/255X_list[i,:,:,1] = np.array(img_rgb[1])/255X_list[i,:,:,2] = np.array(img_rgb[2])/255Y_list[i] = name.split('_')[0]i+=1
# 将特征变量 X 和标签 Y 的列表转化为 NumPy 数组
X = np.array(X_list)
Y = np.array(Y_list)# 打印特征变量 X 和标签 Y 的形状
print('特征变量 X 的形状:', X)
print('标签 Y 的形状:', Y) |

1.4模型构建

1.4.1模型结构定义
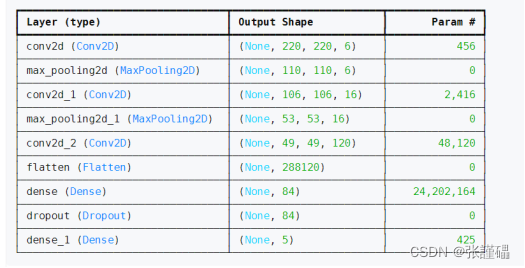
模型参数:
参考代码:
from sklearn.model_selection import train_test_split
import seaborn as sns
import matplotlib.pyplot as plt
import tensorflow as tf
from sklearn.metrics import confusion_matrix
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Flatten, Dense
# 5个类别
num_classes = 5
# 输入图像的大小是224x224,有3个颜色通道(对于彩色图像)
input_shape = (224, 224, 3)
# 假设X和Y是您的原始数据
# X: 图像数据,形状为(num_samples, 224, 224, 3)
# Y: 标签数据,形状为(num_samples,) 并且是整数形式的标签(从0到4)
# 将数据划分为训练集和测试集(只执行一次)
x_train, x_test, y_train, y_test = train_test_split(X, Y, test_size=0.2, random_state=42)
# 构建模型
model = tf.keras.models.Sequential([ tf.keras.layers.Conv2D(6, (5, 5), strides=(1,1), activation='relu', input_shape=input_shape), tf.keras.layers.MaxPooling2D((2,2), strides=2), tf.keras.layers.Conv2D(16, (5,5), activation='relu'), tf.keras.layers.MaxPooling2D((2,2), strides=2), tf.keras.layers.Conv2D(120, (5,5), activation='relu'), tf.keras.layers.Flatten(), tf.keras.layers.Dense(84, activation='relu'), tf.keras.layers.Dropout(0.3), tf.keras.layers.Dense(num_classes, activation='softmax') # 确保输出层的神经元数量与类别数量匹配
]) # 编译模型
model.compile(loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False),# 使用sparse categorical crossentropy损失函数 optimizer=tf.keras.optimizers.Adam(), # 使用Adam优化器 metrics=['sparse_categorical_accuracy']) # 监控准确率 # 打印模型概述
model.summary() # 使用model.fit()函数训练模型
history = model.fit(x_train, y_train, epochs=10, validation_split=0.2)

1.4.2模型译
编译参数参考:
# 优化器optimizer='adam'# 损失函数loss='sparse_categorical_crossentropy'# 评估指标metrics=['sparse_categorical_accuracy']1.5模型训练
1.5.1划分训练集和测试集
按照训练集:测试集=8:2的比例对数据集进行划分,建议使用sklearn库中的train_test_split函数。
1.5.2训练
使用fit函数对训练集进行拟合训练,并将训练过程中产生的历史数据history保存至变量中。
训练参数参考:
# 迭代次数epochs=20# 验证集比例validation_split=0.21.5.3训练过程可视化
对history中保存下来的训练过程中的loss和sparse_categorical_accuracy的变化情况进行绘图。
参考代码:
# 获取训练和验证的准确率和损失
acc = history.history['sparse_categorical_accuracy']
val_acc = history.history['sparse_categorical_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss'] # 使用model.evaluate()函数评估模型在测试集上的性能
test_loss, test_accuracy = model.evaluate(x_test, y_test)
print(f'Test accuracy: {test_accuracy}') # 使用model.predict()函数对新的图像进行预测。
plt.figure(figsize=(15,10))
plt.plot(history.epoch, history.history['loss'],label='loss')
plt.plot(history.epoch, history.history['val_loss'],label='var_loss')
plt.xlabel('Epoch')
plt.ylabel('loss')
plt.legend(loc='upper right')plt.figure(figsize=(15,10))
plt.plot(history.epoch,history.history['sparse_categorical_accuracy'],label='sparse_categorical_accuracy')
plt.plot(history.epoch,history.history['val_sparse_categorical_accuracy'],label='val_sparse_categorical_accuracy')
plt.xlabel('Epoch')
plt.ylabel('sparse_categorical_accuracy')
plt.legend(loc='upper right')
plt.show()plt.rcParams['font.sans-serif'] = ['SimHei']
y_pred = np.argmax(model.predict(x_test),axis=1)
cm = confusion_matrix(y_test, y_pred,labels=[0,1,2,3,4])
sns.heatmap(cm,annot=True,cmap="Blues",cbar=False,linewidths=2,linecolor='white',square=True,xticklabels=['砾岩','安山岩','花岗岩','石灰岩','石英岩'],yticklabels=['砾岩','安山岩','花岗岩','石灰岩','石英岩'])
plt.show 



1.6.3保存模型
使用save函数对训练好的模型进行保存,方便后续使用。
参考代码:
model.save('roch_classification_cnn.h5')![]()
1.7图形用户界面(GUI)开发
1.7.1配置开发工具
在PyCharm中配置QtDesigner和PyUIC工具。
注意:需提前在python环境中安装好PyQt5和PyQt5-tools库。
- 配置QtDesigner

Program:(对应designer.exe的路径)
Working directory: $FileDir$
- 配置PyUCI
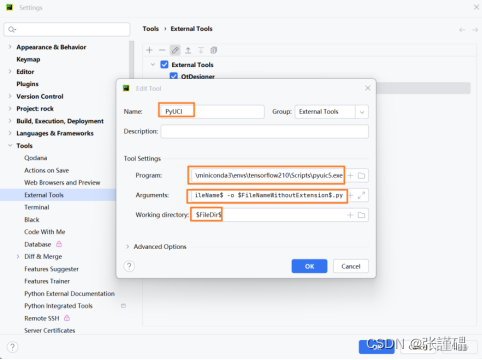
Program:(对应pyuic5.exe的路径)
Arguments: $FileName$ -o $FileNameWithoutExtension$.py
Working directory: $FileDir$
配置完成后的界面:
1.7.2设计图形用户界面
在PyCharm中“Tools”—“External Tools”中打开QtDesigner
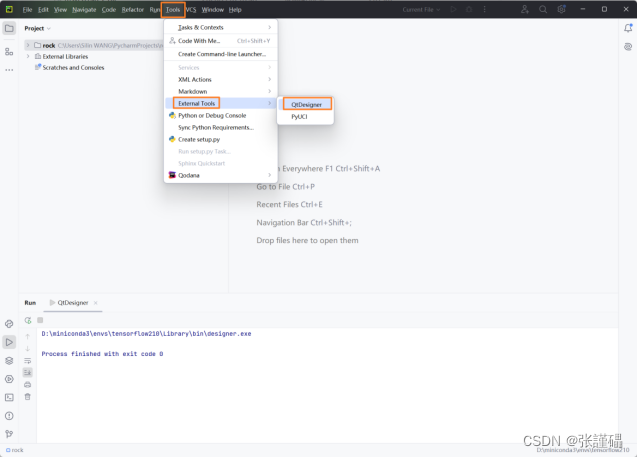
在QtDesigner主界面中选择创建Main Window,然后根据需求选择相应的控件进行设计。
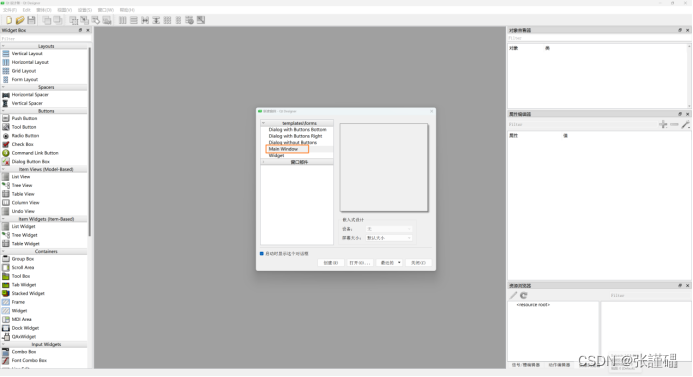
设计界面参考:

设计好之后保存为.ui文件。
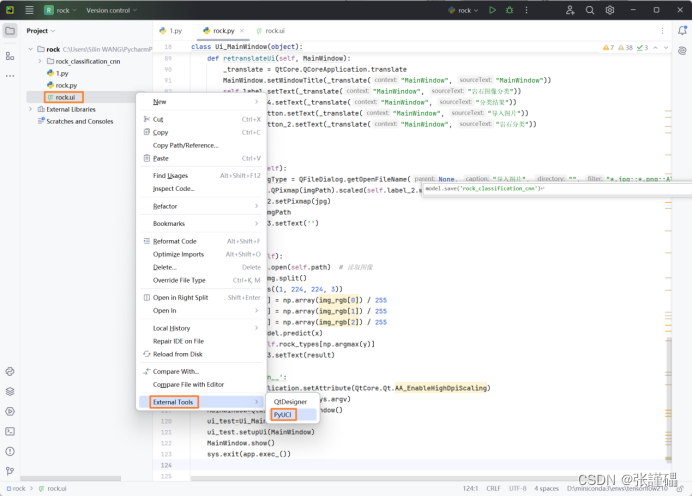
1.7.3 ui文件转换为代码
在PyCharm中右键点击.ui文件并使用PyUCI工具进行转换。
1.7.4代码与模型结合
将转化后的代码与之前训练的模型相结合。
参考代码:
# -*- coding: utf-8 -*-
import osfrom PyQt5 import QtCore, QtGui, QtWidgets
from PyQt5.QtWidgets import *
import tensorflow as tf
from PIL import Image
import numpy as np
import sys
class Ui_MainWindow(object):def setupUi(self, MainWindow):MainWindow.setObjectName("MainWindow")MainWindow.resize(800, 600)self.centralwidget = QtWidgets.QWidget(MainWindow)self.centralwidget.setObjectName("centralwidget")self.label = QtWidgets.QLabel(self.centralwidget)self.label.setGeometry(QtCore.QRect(220, 20, 291, 61))self.label.setScaledContents(False)self.label.setObjectName("label")self.pushButton = QtWidgets.QPushButton(self.centralwidget)self.pushButton.setGeometry(QtCore.QRect(160, 430, 93, 28))self.pushButton.setObjectName("pushButton")self.pushButton_2 = QtWidgets.QPushButton(self.centralwidget)self.pushButton_2.setGeometry(QtCore.QRect(440, 430, 93, 28))self.pushButton_2.setObjectName("pushButton_2")self.label_2 = QtWidgets.QLabel(self.centralwidget)self.label_2.setGeometry(QtCore.QRect(150, 90, 381, 321))self.label_2.setText("")self.label_2.setObjectName("label_2")self.label_3 = QtWidgets.QLabel(self.centralwidget)self.label_3.setGeometry(QtCore.QRect(550, 130, 141, 51))self.label_3.setText("")self.label_3.setObjectName("label_3")self.label_4 = QtWidgets.QLabel(self.centralwidget)self.label_4.setGeometry(QtCore.QRect(550, 90, 141, 31))self.label_4.setObjectName("label_4")self.textBrowser = QtWidgets.QTextBrowser(self.centralwidget)self.textBrowser.setGeometry(QtCore.QRect(150, 90, 381, 321))self.textBrowser.setObjectName("textBrowser")self.textBrowser_2 = QtWidgets.QTextBrowser(self.centralwidget)self.textBrowser_2.setGeometry(QtCore.QRect(550, 130, 141, 51))self.textBrowser_2.setObjectName("textBrowser_2")self.textBrowser_3 = QtWidgets.QTextBrowser(self.centralwidget)self.textBrowser_3.setGeometry(QtCore.QRect(220, 20, 291, 61))self.textBrowser_3.setObjectName("textBrowser_3")self.textBrowser_4 = QtWidgets.QTextBrowser(self.centralwidget)self.textBrowser_4.setGeometry(QtCore.QRect(550, 90, 141, 31))self.textBrowser_4.setObjectName("textBrowser_4")self.textBrowser_2.raise_()self.label.raise_()self.textBrowser.raise_()self.textBrowser_3.raise_()self.pushButton.raise_()self.pushButton_2.raise_()self.label_2.raise_()self.label_4.raise_()self.textBrowser_4.raise_()self.label_3.raise_()MainWindow.setCentralWidget(self.centralwidget)self.menubar = QtWidgets.QMenuBar(MainWindow)self.menubar.setGeometry(QtCore.QRect(0, 0, 800, 26))self.menubar.setObjectName("menubar")MainWindow.setMenuBar(self.menubar)self.statusbar = QtWidgets.QStatusBar(MainWindow)self.statusbar.setObjectName("statusbar")MainWindow.setStatusBar(self.statusbar)self.toolBar = QtWidgets.QToolBar(MainWindow)self.toolBar.setObjectName("toolBar")MainWindow.addToolBar(QtCore.Qt.TopToolBarArea, self.toolBar)self.retranslateUi(MainWindow)QtCore.QMetaObject.connectSlotsByName(MainWindow)# 模型相关变量初始化self.model = tf.keras.models.load_model(r'C:\Users\zjl15\PycharmProjects\pythonProject1\roch_classification_cnn.h5')self.path = ''self.rock_types = ['砾岩','安山岩','花岗岩','石灰岩','石英岩']# 将“导入图片”按钮与openImage函数绑定self.pushButton.clicked.connect(self.openImage)# 将“岩石分类”按钮与classify函数绑定self.pushButton_2.clicked.connect(self.classify)def retranslateUi(self, MainWindow):_translate = QtCore.QCoreApplication.translateMainWindow.setWindowTitle(_translate("MainWindow", "MainWindow"))self.label.setText(_translate("MainWindow", "岩石图像分类"))self.pushButton.setText(_translate("MainWindow", "导入图像"))self.pushButton_2.setText(_translate("MainWindow", "岩石分类"))self.label_4.setText(_translate("MainWindow", "分类结果"))self.textBrowser_3.setHtml(_translate("MainWindow","<!DOCTYPE HTML PUBLIC \"-//W3C//DTD HTML 4.0//EN\" \"http://www.w3.org/TR/REC-html40/strict.dtd\">\n""<html><head><meta name=\"qrichtext\" content=\"1\" /><style type=\"text/css\">\n""p, li { white-space: pre-wrap; }\n""</style></head><body style=\" font-family:\'SimSun\'; font-size:9pt; font-weight:400; font-style:normal;\">\n""<p align=\"center\" style=\" margin-top:0px; margin-bottom:0px; margin-left:0px; margin-right:0px; -qt-block-indent:0; text-indent:0px;\"><span style=\" font-size:24pt;\">岩石图像识别</span></p></body></html>"))self.textBrowser_4.setHtml(_translate("MainWindow","<!DOCTYPE HTML PUBLIC \"-//W3C//DTD HTML 4.0//EN\" \"http://www.w3.org/TR/REC-html40/strict.dtd\">\n""<html><head><meta name=\"qrichtext\" content=\"1\" /><style type=\"text/css\">\n""p, li { white-space: pre-wrap; }\n""</style></head><body style=\" font-family:\'SimSun\'; font-size:9pt; font-weight:400; font-style:normal;\">\n""<p align=\"center\" style=\" margin-top:0px; margin-bottom:0px; margin-left:0px; margin-right:0px; -qt-block-indent:0; text-indent:0px;\"><span style=\" font-size:11pt;\">分类结果</span></p></body></html>"))self.toolBar.setWindowTitle(_translate("MainWindow", "toolBar"))# 导入图片函数def resource_path(relative):if hasattr(sys, "_MEIPASS"):absolute_path = os.path.join(sys._MEIPASS, relative)else:absolute_path = os.path.join(relative)return absolute_path# 在原来引用该文件的地方加上这个函数 (resource_path("文件名"))def openImage(self):imgPath, imgType = QFileDialog.getOpenFileName(None, "导入图片", "", "*.jpg;;*.png;;All Files(*)")jpg = QtGui.QPixmap(imgPath).scaled(self.label_2.width(), self.label_2.height())self.label_2.setPixmap(jpg)self.path=imgPathself.label_3.setText('')def classify(self):img = Image.open(self.path) # 读取图像img_rgb = img.split()x = np.zeros((1, 224, 224, 3))x[0,:, :, 0] = np.array(img_rgb[0]) / 255x[0,:, :, 1] = np.array(img_rgb[1]) / 255x[0,:, :, 2] = np.array(img_rgb[2]) / 255y = self.model.predict(x)result = self.rock_types[np.argmax(y)]self.label_3.setText(result)
if __name__=='__main__':QtCore.QCoreApplication.setAttribute(QtCore.Qt.AA_EnableHighDpiScaling)app=QtWidgets.QApplication(sys.argv)MainWindow=QtWidgets.QMainWindow()ui_test=Ui_MainWindow()ui_test.setupUi(MainWindow)MainWindow.show()sys.exit(app.exec_())1.7.5测试
执行程序测试“导入图片”和“鉴定分类”功能。

1.8打包可执行文件(exe)
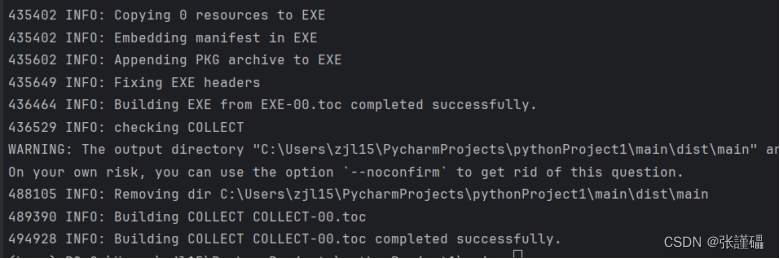
在命令窗口中使用如下指令对上一步的程序进行打包。
Pyinstaller -F -w xxxxx.py
运行生成的.exe文件并测试功能。
打完包之后可能出现错误
报错信息:
=============================================================
A RecursionError (maximum recursion depth exceeded) occurred.
For working around please follow these instructions
=============================================================
1. In your program's .spec file add this line near the top::
import sys ; sys.setrecursionlimit(sys.getrecursionlimit() * 5)
2. Build your program by running PyInstaller with the .spec file as
argument::
pyinstaller myprog.spec
3. If this fails, you most probably hit an endless recursion in
PyInstaller. Please try to track this down has far as possible,
create a minimal example so we can reproduce and open an issue at
https://github.com/pyinstaller/pyinstaller/issues following the
instructions in the issue template. Many thanks.
Explanation: Python's stack-limit is a safety-belt against endless recursion,
eating up memory. PyInstaller imports modules recursively. If the structure
how modules are imported within your program is awkward, this leads to the
nesting being too deep and hitting Python's stack-limit.
With the default recursion limit (1000), the recursion error occurs at about
115 nested imported, with limit 2000 at about 240, with limit 5000 at about
660.
————————————————
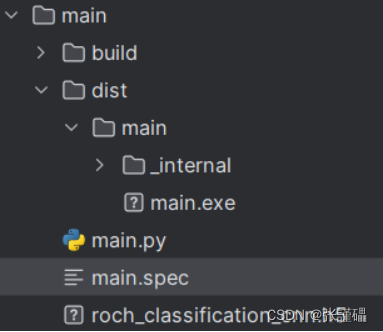
你打包目录下会生成如下文件
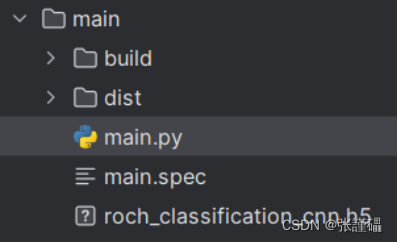

打开你的main.spec文件
在顶端添加代码:
import sys
sys.setrecursionlimit(sys.getrecursionlimit() * 5)
然后在运行命令(对应的文件名)
pyinstaller 你的文件名.spec
然后就完成了
打完包之的运行闪退问题:
先安装一个新的第三方库ordereddict
安装命令:
pip install ordereddict
注意自己python代码的文件引入路径(确保对应的路径下有对应的文件,我这里设置的是根目录下)

重新打包
完成之后
打开对应的文件夹双击就可以了

完整代码:
import cv2
import os
import glob
# 数据增强函数
def augment_data(img, save_path):rows, cols, _ = img.shape# 水平翻转图像img_flip = cv2.flip(img, 1)img_name = os.path.splitext(save_path)[0] + "_flip.jpg"cv2.imwrite(img_name, img_flip)print("Saved augmented image:", img_name)# 随机缩放图像scale = np.random.uniform(0.9, 1.1)M = cv2.getRotationMatrix2D((cols / 2, rows / 2), 0, scale)img_transformed = cv2.warpAffine(img, M, (cols, rows))img_name = os.path.splitext(save_path)[0] + "_transform.jpg"cv2.imwrite(img_name, img_transformed)print("Saved augmented image:", img_name)# 随机旋转图像angle = np.random.randint(-10, 10)M = cv2.getRotationMatrix2D((cols / 2, rows / 2), angle, 1)img_rotated = cv2.warpAffine(img, M, (cols, rows))img_name = os.path.splitext(save_path)[0] + "_rotated.jpg"cv2.imwrite(img_name, img_rotated)print("Saved augmented image:", img_name)# 添加高斯噪音mean = 0std = np.random.uniform(5, 15)noise = np.zeros(img.shape, np.float32)cv2.randn(noise, mean, std)noise = np.uint8(noise)img_noisy = cv2.add(img, noise)img_name = os.path.splitext(save_path)[0] + "_noisy.jpg"cv2.imwrite(img_name, img_noisy)print("Saved augmented image:", img_name)# 随机调整对比度和亮度alpha = np.random.uniform(0.8, 1.2)beta = np.random.randint(-10, 10)img_contrast = cv2.convertScaleAbs(img, alpha=alpha, beta=beta)img_name = os.path.splitext(save_path)[0] + "_contrast.jpg"cv2.imwrite(img_name, img_contrast)print("Saved augmented image:", img_name)return img
# 读取 data 文件夹中的所有图片,并进行数据增强
data_dir = r"images"
save_dir = r"images2"
if not os.path.exists(save_dir):os.makedirs(save_dir)
# 使用 glob 库来遍历 data 文件夹中所有图像
for img_path in glob.glob(os.path.join(data_dir, "*.jpg")):img = cv2.imread(img_path)if img is None:print("Error: Unable to read image at", img_path)continue# 获取保存增强后的图片文件名img_name = os.path.basename(img_path)save_path = os.path.join(save_dir, img_name)# 数据增强augmented_img = augment_data(img, save_path)if augmented_img is not None:# 保存原始图片cv2.imwrite(save_path, img)print("Saved original image:", save_path)
#%%
import os
import cv2
import numpy as np
from PIL import Image
# 设置图片文件夹路径
image_folder = r"images2"
# 获取所有类别的文件夹名(假设每个文件夹是一个类别)
categories = os.listdir(image_folder)# 初始化特征变量 X 和标签 Y 的列表
X_list = np.zeros((len(categories), 224, 224, 3))
Y_list = np.zeros((len(categories)))i=0
for name in categories:img = Image.open(image_folder + '\\' +name)img_rgb = img.split()X_list[i,:,:,0] = np.array(img_rgb[0])/255X_list[i,:,:,1] = np.array(img_rgb[1])/255X_list[i,:,:,2] = np.array(img_rgb[2])/255Y_list[i] = name.split('_')[0]i+=1
# 将特征变量 X 和标签 Y 的列表转化为 NumPy 数组
X = np.array(X_list)
Y = np.array(Y_list)# 打印特征变量 X 和标签 Y 的形状
print('特征变量 X 的形状:', X)
print('标签 Y 的形状:', Y)
#%%
from sklearn.model_selection import train_test_split
import seaborn as sns
import matplotlib.pyplot as plt
import tensorflow as tf
from sklearn.metrics import confusion_matrix
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Flatten, Dense
# 5个类别
num_classes = 5
# 输入图像的大小是224x224,有3个颜色通道(对于彩色图像)
input_shape = (224, 224, 3)
# 假设X和Y是您的原始数据
# X: 图像数据,形状为(num_samples, 224, 224, 3)
# Y: 标签数据,形状为(num_samples,) 并且是整数形式的标签(从0到4)
# 将数据划分为训练集和测试集(只执行一次)
x_train, x_test, y_train, y_test = train_test_split(X, Y, test_size=0.2, random_state=42)
# 构建模型
model = tf.keras.models.Sequential([ tf.keras.layers.Conv2D(6, (5, 5), strides=(1,1), activation='relu', input_shape=input_shape), tf.keras.layers.MaxPooling2D((2,2), strides=2), tf.keras.layers.Conv2D(16, (5,5), activation='relu'), tf.keras.layers.MaxPooling2D((2,2), strides=2), tf.keras.layers.Conv2D(120, (5,5), activation='relu'), tf.keras.layers.Flatten(), tf.keras.layers.Dense(84, activation='relu'), tf.keras.layers.Dropout(0.3), tf.keras.layers.Dense(num_classes, activation='softmax') # 确保输出层的神经元数量与类别数量匹配
]) # 编译模型
model.compile(loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False),# 使用sparse categorical crossentropy损失函数 optimizer=tf.keras.optimizers.Adam(), # 使用Adam优化器 metrics=['sparse_categorical_accuracy']) # 监控准确率 # 打印模型概述
model.summary() # 使用model.fit()函数训练模型
history = model.fit(x_train, y_train, epochs=10, validation_split=0.2) #%%
y_pred = model.predict(x_test)
print(y_pred)
#%%#%%
# 获取训练和验证的准确率和损失
acc = history.history['sparse_categorical_accuracy']
val_acc = history.history['sparse_categorical_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss'] # 使用model.evaluate()函数评估模型在测试集上的性能
test_loss, test_accuracy = model.evaluate(x_test, y_test)
print(f'Test accuracy: {test_accuracy}') # 使用model.predict()函数对新的图像进行预测。
plt.figure(figsize=(15,10))
plt.plot(history.epoch, history.history['loss'],label='loss')
plt.plot(history.epoch, history.history['val_loss'],label='var_loss')
plt.xlabel('Epoch')
plt.ylabel('loss')
plt.legend(loc='upper right')plt.figure(figsize=(15,10))
plt.plot(history.epoch,history.history['sparse_categorical_accuracy'],label='sparse_categorical_accuracy')
plt.plot(history.epoch,history.history['val_sparse_categorical_accuracy'],label='val_sparse_categorical_accuracy')
plt.xlabel('Epoch')
plt.ylabel('sparse_categorical_accuracy')
plt.legend(loc='upper right')
plt.show()plt.rcParams['font.sans-serif'] = ['SimHei']
y_pred = np.argmax(model.predict(x_test),axis=1)
cm = confusion_matrix(y_test, y_pred,labels=[0,1,2,3,4])
sns.heatmap(cm,annot=True,cmap="Blues",cbar=False,linewidths=2,linecolor='white',square=True,xticklabels=['砾岩','安山岩','花岗岩','石灰岩','石英岩'],yticklabels=['砾岩','安山岩','花岗岩','石灰岩','石英岩'])
plt.show
#%%
model.save('roch_classification_cnn.h5')# -*- coding: utf-8 -*-
import osfrom PyQt5 import QtCore, QtGui, QtWidgets
from PyQt5.QtWidgets import *
import tensorflow as tf
from PIL import Image
import numpy as np
import sys
class Ui_MainWindow(object):def setupUi(self, MainWindow):MainWindow.setObjectName("MainWindow")MainWindow.resize(800, 600)self.centralwidget = QtWidgets.QWidget(MainWindow)self.centralwidget.setObjectName("centralwidget")self.label = QtWidgets.QLabel(self.centralwidget)self.label.setGeometry(QtCore.QRect(220, 20, 291, 61))self.label.setScaledContents(False)self.label.setObjectName("label")self.pushButton = QtWidgets.QPushButton(self.centralwidget)self.pushButton.setGeometry(QtCore.QRect(160, 430, 93, 28))self.pushButton.setObjectName("pushButton")self.pushButton_2 = QtWidgets.QPushButton(self.centralwidget)self.pushButton_2.setGeometry(QtCore.QRect(440, 430, 93, 28))self.pushButton_2.setObjectName("pushButton_2")self.label_2 = QtWidgets.QLabel(self.centralwidget)self.label_2.setGeometry(QtCore.QRect(150, 90, 381, 321))self.label_2.setText("")self.label_2.setObjectName("label_2")self.label_3 = QtWidgets.QLabel(self.centralwidget)self.label_3.setGeometry(QtCore.QRect(550, 130, 141, 51))self.label_3.setText("")self.label_3.setObjectName("label_3")self.label_4 = QtWidgets.QLabel(self.centralwidget)self.label_4.setGeometry(QtCore.QRect(550, 90, 141, 31))self.label_4.setObjectName("label_4")self.textBrowser = QtWidgets.QTextBrowser(self.centralwidget)self.textBrowser.setGeometry(QtCore.QRect(150, 90, 381, 321))self.textBrowser.setObjectName("textBrowser")self.textBrowser_2 = QtWidgets.QTextBrowser(self.centralwidget)self.textBrowser_2.setGeometry(QtCore.QRect(550, 130, 141, 51))self.textBrowser_2.setObjectName("textBrowser_2")self.textBrowser_3 = QtWidgets.QTextBrowser(self.centralwidget)self.textBrowser_3.setGeometry(QtCore.QRect(220, 20, 291, 61))self.textBrowser_3.setObjectName("textBrowser_3")self.textBrowser_4 = QtWidgets.QTextBrowser(self.centralwidget)self.textBrowser_4.setGeometry(QtCore.QRect(550, 90, 141, 31))self.textBrowser_4.setObjectName("textBrowser_4")self.textBrowser_2.raise_()self.label.raise_()self.textBrowser.raise_()self.textBrowser_3.raise_()self.pushButton.raise_()self.pushButton_2.raise_()self.label_2.raise_()self.label_4.raise_()self.textBrowser_4.raise_()self.label_3.raise_()MainWindow.setCentralWidget(self.centralwidget)self.menubar = QtWidgets.QMenuBar(MainWindow)self.menubar.setGeometry(QtCore.QRect(0, 0, 800, 26))self.menubar.setObjectName("menubar")MainWindow.setMenuBar(self.menubar)self.statusbar = QtWidgets.QStatusBar(MainWindow)self.statusbar.setObjectName("statusbar")MainWindow.setStatusBar(self.statusbar)self.toolBar = QtWidgets.QToolBar(MainWindow)self.toolBar.setObjectName("toolBar")MainWindow.addToolBar(QtCore.Qt.TopToolBarArea, self.toolBar)self.retranslateUi(MainWindow)QtCore.QMetaObject.connectSlotsByName(MainWindow)# 模型相关变量初始化self.model = tf.keras.models.load_model(r'C:\Users\zjl15\PycharmProjects\pythonProject1\roch_classification_cnn.h5')self.path = ''self.rock_types = ['砾岩','安山岩','花岗岩','石灰岩','石英岩']# 将“导入图片”按钮与openImage函数绑定self.pushButton.clicked.connect(self.openImage)# 将“岩石分类”按钮与classify函数绑定self.pushButton_2.clicked.connect(self.classify)def retranslateUi(self, MainWindow):_translate = QtCore.QCoreApplication.translateMainWindow.setWindowTitle(_translate("MainWindow", "MainWindow"))self.label.setText(_translate("MainWindow", "岩石图像分类"))self.pushButton.setText(_translate("MainWindow", "导入图像"))self.pushButton_2.setText(_translate("MainWindow", "岩石分类"))self.label_4.setText(_translate("MainWindow", "分类结果"))self.textBrowser_3.setHtml(_translate("MainWindow","<!DOCTYPE HTML PUBLIC \"-//W3C//DTD HTML 4.0//EN\" \"http://www.w3.org/TR/REC-html40/strict.dtd\">\n""<html><head><meta name=\"qrichtext\" content=\"1\" /><style type=\"text/css\">\n""p, li { white-space: pre-wrap; }\n""</style></head><body style=\" font-family:\'SimSun\'; font-size:9pt; font-weight:400; font-style:normal;\">\n""<p align=\"center\" style=\" margin-top:0px; margin-bottom:0px; margin-left:0px; margin-right:0px; -qt-block-indent:0; text-indent:0px;\"><span style=\" font-size:24pt;\">岩石图像识别</span></p></body></html>"))self.textBrowser_4.setHtml(_translate("MainWindow","<!DOCTYPE HTML PUBLIC \"-//W3C//DTD HTML 4.0//EN\" \"http://www.w3.org/TR/REC-html40/strict.dtd\">\n""<html><head><meta name=\"qrichtext\" content=\"1\" /><style type=\"text/css\">\n""p, li { white-space: pre-wrap; }\n""</style></head><body style=\" font-family:\'SimSun\'; font-size:9pt; font-weight:400; font-style:normal;\">\n""<p align=\"center\" style=\" margin-top:0px; margin-bottom:0px; margin-left:0px; margin-right:0px; -qt-block-indent:0; text-indent:0px;\"><span style=\" font-size:11pt;\">分类结果</span></p></body></html>"))self.toolBar.setWindowTitle(_translate("MainWindow", "toolBar"))# 导入图片函数def resource_path(relative):if hasattr(sys, "_MEIPASS"):absolute_path = os.path.join(sys._MEIPASS, relative)else:absolute_path = os.path.join(relative)return absolute_path# 在原来引用该文件的地方加上这个函数 (resource_path("文件名"))def openImage(self):imgPath, imgType = QFileDialog.getOpenFileName(None, "导入图片", "", "*.jpg;;*.png;;All Files(*)")jpg = QtGui.QPixmap(imgPath).scaled(self.label_2.width(), self.label_2.height())self.label_2.setPixmap(jpg)self.path=imgPathself.label_3.setText('')def classify(self):img = Image.open(self.path) # 读取图像img_rgb = img.split()x = np.zeros((1, 224, 224, 3))x[0,:, :, 0] = np.array(img_rgb[0]) / 255x[0,:, :, 1] = np.array(img_rgb[1]) / 255x[0,:, :, 2] = np.array(img_rgb[2]) / 255y = self.model.predict(x)result = self.rock_types[np.argmax(y)]self.label_3.setText(result)
if __name__=='__main__':QtCore.QCoreApplication.setAttribute(QtCore.Qt.AA_EnableHighDpiScaling)app=QtWidgets.QApplication(sys.argv)MainWindow=QtWidgets.QMainWindow()ui_test=Ui_MainWindow()ui_test.setupUi(MainWindow)MainWindow.show()sys.exit(app.exec_())