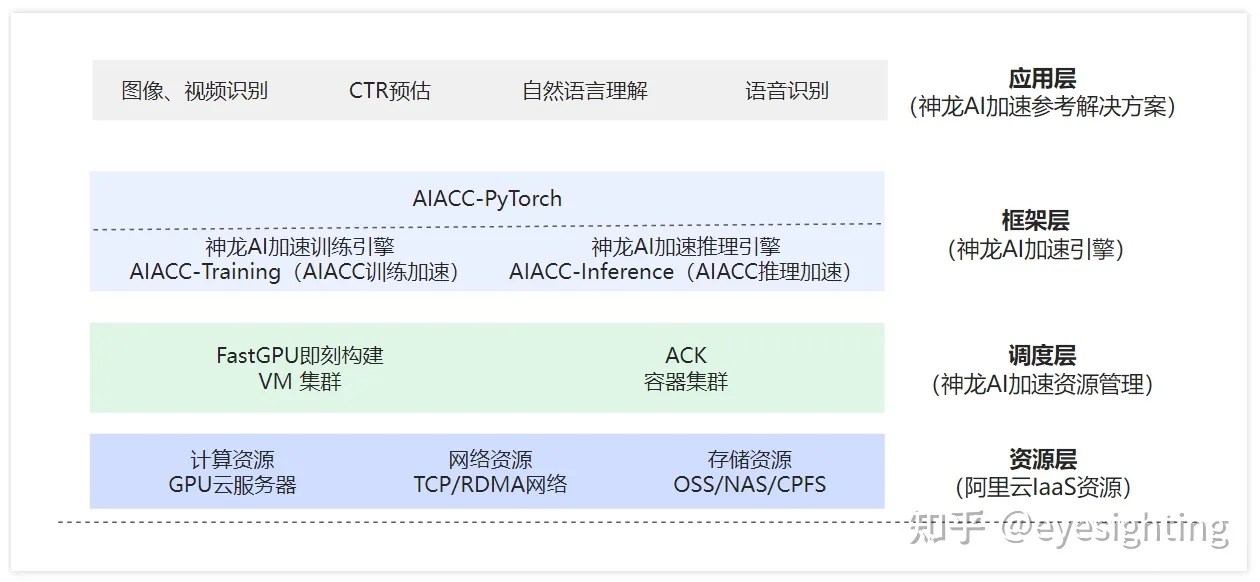
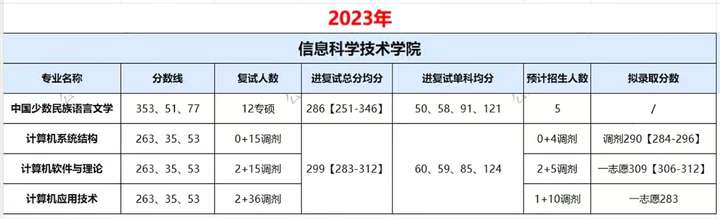
正则化
正则化是防止过拟合的一种方法,与线性回归等算法配合使用。通过向损失函数增加惩罚项的方式对模型施加制约,有望提高模型的泛化能力。
概述
正则化是防止过拟合的方法,用于机器学习模型的训练阶段。过拟合是模型在验证数据上产生的误差比在训练数据上产生的误差(训练误差)大得多的现象。过拟合的一个原因是机器学习模型过于复杂。正则化可以降低模型的复杂度,有助于提高模型的泛化能力。
在详细了解正则化的方法之前,我们先看一下使用了正则化的模型如何防止过拟合。这里使用的数据是图 2-7 中的训练数据(灰色的数据点)和验证数据(黑色的数据点)。这些数据点是对函数 ![]() 添加了遵循高斯分布的随机数而生成的。
添加了遵循高斯分布的随机数而生成的。
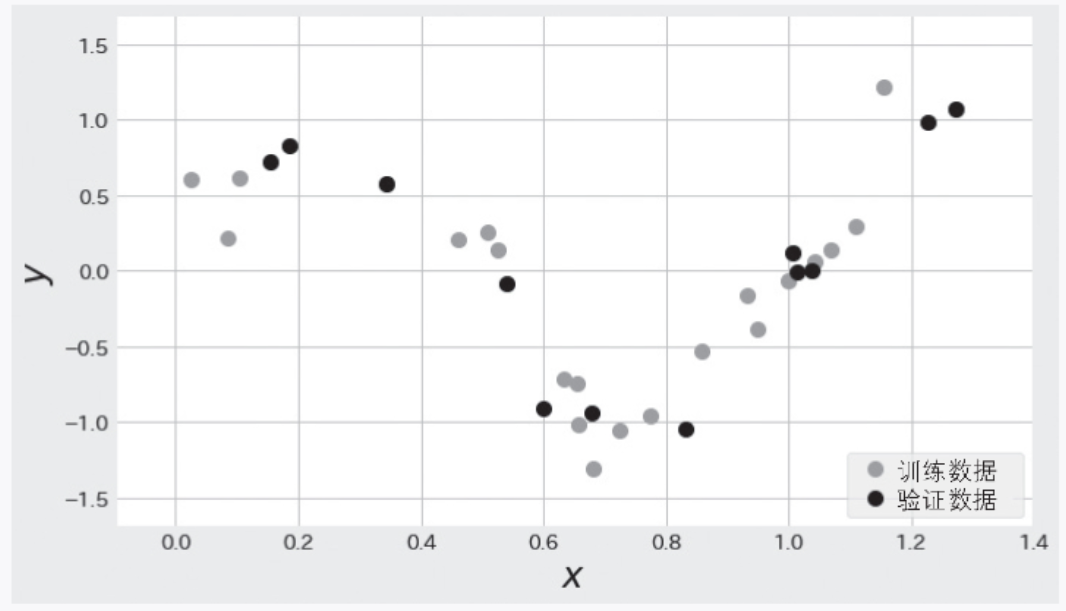
▲图 2-7 使用 ![]() 加随机数生成的数据
加随机数生成的数据
下面尝试用线性回归对这份数据建模。不断在线性回归中加入一次项、二次项……观察随着多项式的次数越来越大,训练误差和验证误差会如何变化。
不同次数d的训练结果如图 2-8 所示。此时,使用均方误差计算使误差最小的学习参数wi。一次线性回归函数是![]() ,因此图形是直线;二次线性回归函数是
,因此图形是直线;二次线性回归函数是 ![]() ,因此图形是二次曲线;六次线性回归函数是
,因此图形是二次曲线;六次线性回归函数是![]() ,它的图形看上去是一个非常复杂的曲线。
,它的图形看上去是一个非常复杂的曲线。
▲图 2-8 不同次数的线性回归的训练结果(对于同样的数据,复杂的模型会发生过拟合)
不同次数的训练误差和验证误差如表 2-5 所示。我们可以看出随着函数次数的增加,训练误差渐渐变小了。如果只看训练误差,那么六次线性回归的误差 0.024 是最小的,但此时的验证误差是 3.472,比训练误差大了很多。六次线性回归是一个复杂的模型,虽然它减小了训练误差,但是由于过拟合,它的泛化能力很低。
▼表 2-5 次数与训练误差、验证误差的关系
接下来看一下对线性回归应用正则化后的结果,如图 2-9 和表 2-6 所示。正则化可以通过向损失函数增加惩罚项的方式防止过拟合。从图 2-9 可以看出,正则化抑制了模型的复杂度,次数增加后验证误差也被抑制,从而防止了过拟合的出现。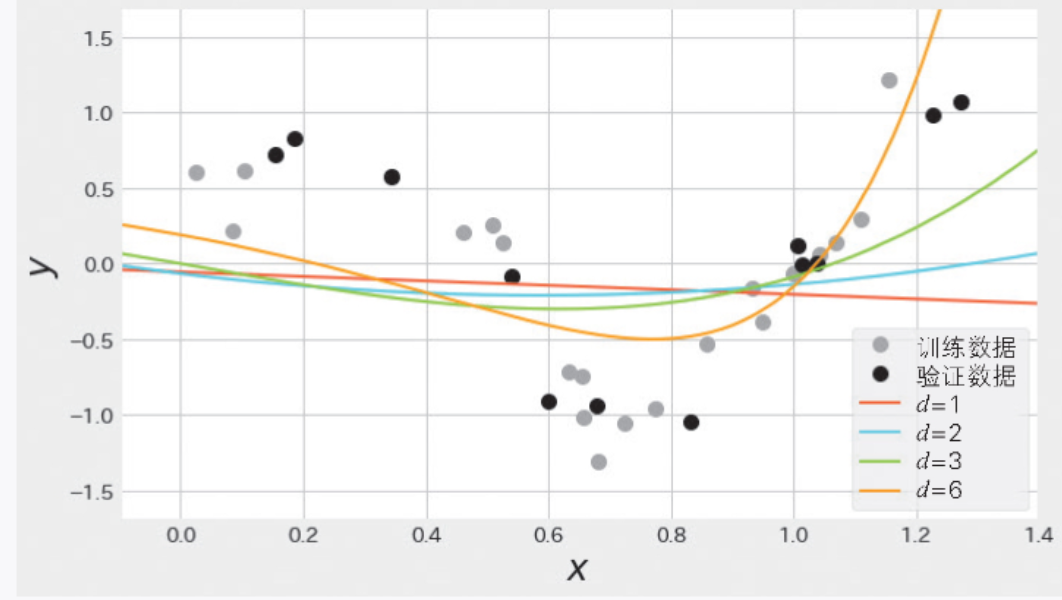
▲图 2-9 对不同次数的线性回归应用正则化后的训练结果(模型的复杂度得到了抑制)
▼表 2-6 应用正则化后的次数与训练误差、验证误差的关系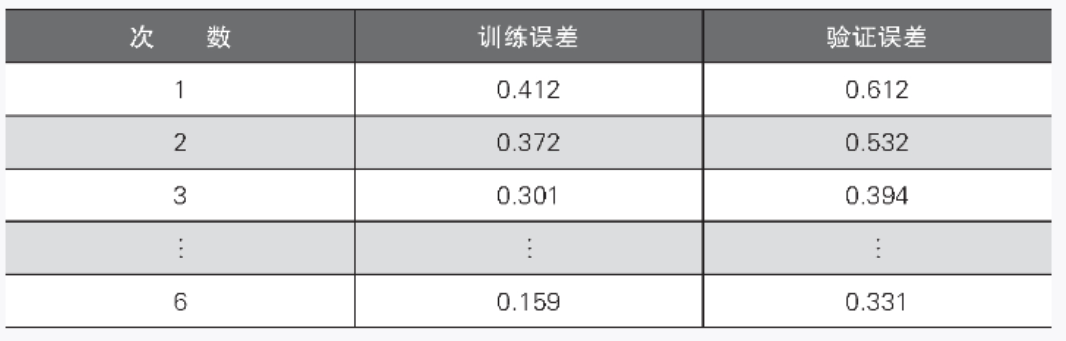
现在有许多正则化的方法。前面使用的回归模型是被称为岭回归(ridge regression)的具有代表性的回归方法。下面的“算法说明”部分将介绍如何防止岭回归出现过拟合,从而提高它的泛化能力。
算法说明
在“概述”部分,我们了解了复杂模型的过拟合以及使用正则化防止过拟合的知识。复杂模型过拟合的一个原因是学习参数 wi的值太大(或太小)。表 2-7 列出了不同次数的线性回归的学习参数。随着次数的增加,学习参数的绝对值变大。
表 2-8 列出了使用正则化后的学习参数。使用正则化能够抑制学习参数随着次数增加而变大。
▼表 2-7 不同次数的学习参数
▼表 2-8 应用正则化后的不同次数的学习参数
为什么正则化可以抑制学习参数变大呢?这里以下面的岭回归的误差函数为例进行说明。简单起见,这里考虑对二次线性回归应用正则化的情况:
等号右边的第 1 项![]() 是线性回归的损失函数。第 2 项
是线性回归的损失函数。第 2 项 ![]() 被称为惩罚项(或者正则化项),是学习参数的平方和的形式。一般来说,惩罚项中不包含截距。
被称为惩罚项(或者正则化项),是学习参数的平方和的形式。一般来说,惩罚项中不包含截距。
另外,α是控制正则化强度的参数,α越大,对学习参数的抑制越强;α越小,对训练数据过拟合的可能性越大。
下面思考岭回归的损失函数![]() 的最小化。
的最小化。
等号右边的第 1 项![]() 其实是求使得与训练数据 y 之间的误差变小的任意 w0、w1、w2 的问题,右边第 2 项(即惩罚项)是学习参数的平方和,因此学习参数的绝对值越大,损失函数整体的值就越大。由此可知,惩罚项具有“对绝对值大的学习参数给予损失变大的惩罚”的作用,这个作用可以抑制学习参数变大。
其实是求使得与训练数据 y 之间的误差变小的任意 w0、w1、w2 的问题,右边第 2 项(即惩罚项)是学习参数的平方和,因此学习参数的绝对值越大,损失函数整体的值就越大。由此可知,惩罚项具有“对绝对值大的学习参数给予损失变大的惩罚”的作用,这个作用可以抑制学习参数变大。
示例代码
下面是对 sin 函数进行岭回归建模时的示例代码。代码中使用 PolynomialFeatures 方法创建了六次多项式。
▼示例代码
# 使用一个简单的正弦函数和噪声数据来训练和测试一个 Ridge 回归模型,并计算预测值与真实值之间的均方误差。import numpy as np
from sklearn.preprocessing import PolynomialFeatures # PolynomialFeatures是scikit-learn库中的一个特征转换类,用于将输入数据进行多项式特征扩展。它的主要参数是degree,表示多项式的次数。
from sklearn.linear_model import Ridge
from sklearn.metrics import mean_squared_errortrain_size = 20
test_size = 12# np.random.uniform(low=0, high=1.0, size=None) 是 NumPy 中的随机数生成函数,用于生成在闭区间 [low, high] 内均匀分布的随机浮点数。
# 生成一个训练数据的数组,其中 low=0 表示数据的下限,high=1.2 表示数据的上限,size=train_size 表示生成的数组大小为 train_size。
train_X = np.random.uniform(low=0, high=1.2, size=train_size)
test_X = np.random.uniform(low=0.1, high=1.3, size=test_size)
# 生成一个训练标签的数组,其中 np.sin(train_X * 2 * np.pi) 表示一个正弦函数,np.random.normal(0, 0.2, train_size) 表示一个均值为 0,标准差为 0.2 的正态分布噪声。
train_y = np.sin(train_X * 2 * np.pi) + np.random.normal(0, 0.2, train_size)
test_y = np.sin(test_X * 2 * np.pi) + np.random.normal(0, 0.2, test_size)poly = PolynomialFeatures(6) # 创建了一个次数为 6 的多项式特征转换对象。
# fit_transform方法会遍历输入数据,并根据多项式特征转换的规则对每个数据点进行扩展。对于训练数据,通过train_X.reshape(train_size, 1)将其转换为一维数组,以便与PolynomialFeatures的输入要求匹配。同样,对测试数据进行相同的转换。
train_poly_X = poly.fit_transform(train_X.reshape(train_size, 1))
test_poly_X = poly.fit_transform(test_X.reshape(test_size, 1))# 创建一个岭回归模型,其中alpha=1.0是岭回归的正则化参数
model = Ridge(alpha=1.0)
# 使用训练数据train_poly_X和标签train_y对模型进行训练。
model.fit(train_poly_X, train_y)
train_pred_y = model.predict(train_poly_X)
test_pred_y = model.predict(test_poly_X)print(mean_squared_error(train_pred_y, train_y))
print(mean_squared_error(test_pred_y, test_y))注:多项式特征转换的目的是将原始数据转换为更高维的数据,以便更好地表示数据的特征。通过添加更高次的多项式特征,可以捕捉数据中的非线性关系。
详细说明
通过α控制正则化强度
下面来详细看一下控制正则化强度的超参数α。图 2-10 是使用不同的α 值时模型的可视化图形。当 α 增大时,可以看出学习参数被抑制,图形变得简单。相反,当 α 变小时,对学习参数的绝对值变大的惩罚力度变缓,模型变复杂。另外,当α = 0 时,惩罚项始终为 0,因此等同于不使用正则化的线性回归。一般来说,应一边验证误差一边对 α 进行调整,最终得到合适的 α。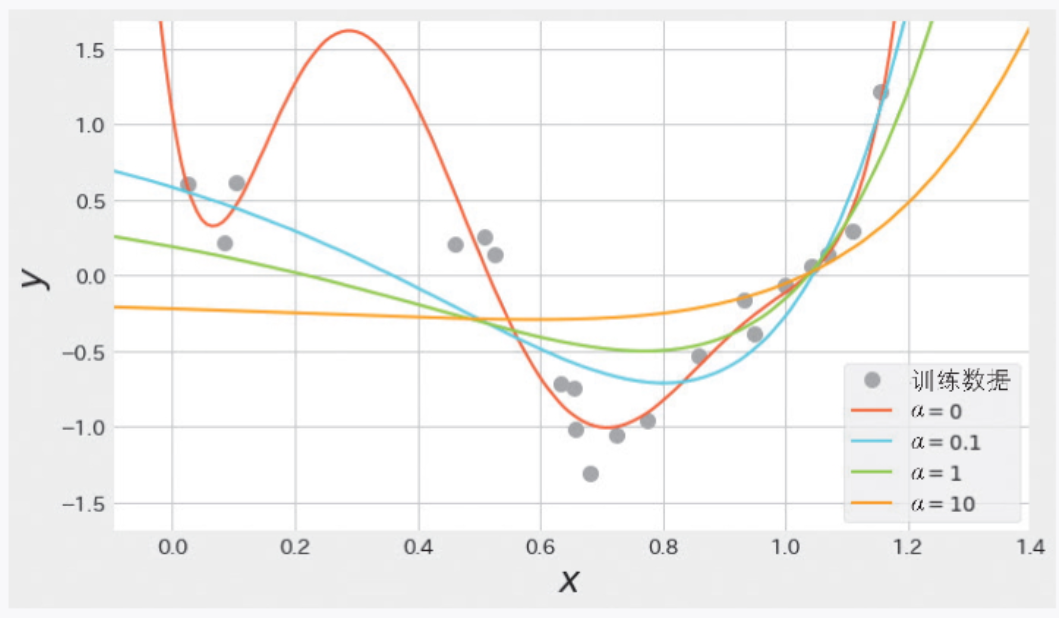
▲图 2-10 α 变化时的岭回归
岭回归和 Lasso 回归
前面介绍了作为正则化方法的岭回归。岭回归的误差函数的惩罚项是学习参数的平方和的形式,通过将该惩罚项改为其他形式,可以实现不同特点的正则化。除了岭回归以外,还有一种具有代表性的正则化方法——Lasso 回归。Lasso 回归的误差函数如下: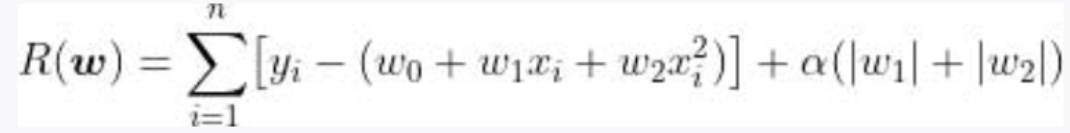
Lasso 回归的惩罚项是学习参数的绝对值之和,这一点与岭回归不同。岭回归和 Lasso 回归计算学习参数时的情况分别如图 2-11a 和图 2-11b 所示。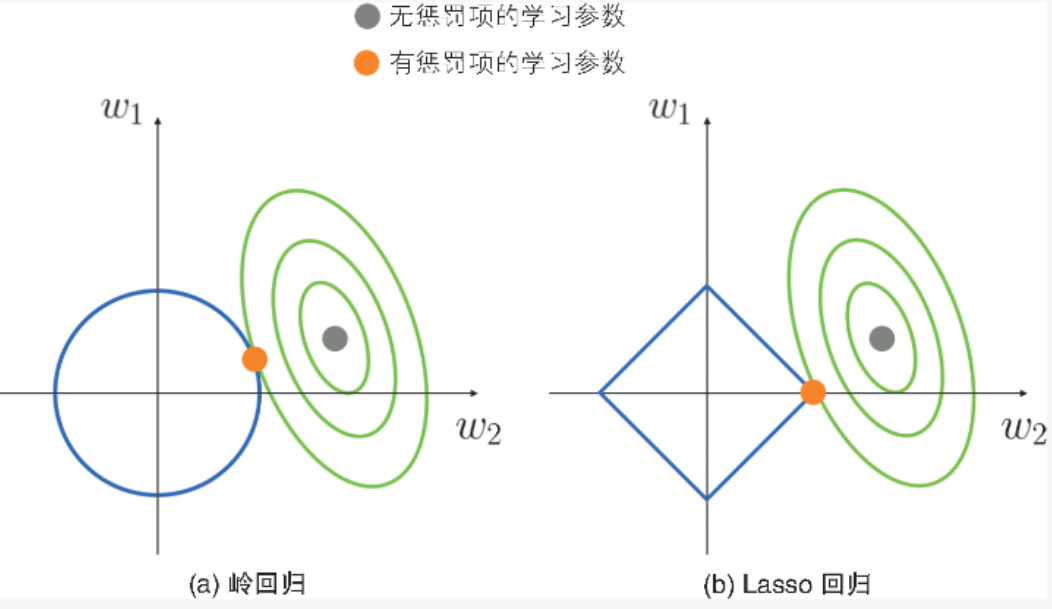
▲图 2-11 计算学习参数时的示意图
绿线是线性回归的误差函数,蓝线是惩罚项的相关函数。岭回归的惩罚项是学习参数的平方和,所以其图形是图 2-11a 所示的圆形;Lasso 回归的惩罚项是绝对值的和,所以其图形是图 2-11b 所示的四边形。原来的函数(线性回归的误差函数)与这些函数的交点就是带有正则化项的误差函数的最佳解。可以看出,在加入惩罚项后,图 2-11a 的岭回归的学习参数得到了抑制。图 2-11b 的 Lasso 回归的情况与岭回归相似,学习参数同样被抑制,但学习参数 w2 变为了 0。
Lasso 回归计算的是函数与这种四边形函数的交点,因此具有学习参数容易变为 0 的特点。利用这个特点,我们可以使用学习参数不为 0 的特征来构建模型,从而达到利用 Lasso 回归选择特征的效果。这样不仅能提高模型的泛化能力,还能使模型的解释变容易。
———————————————————————————————————————————
文章来源:书籍《图解机器学习算法》
作者:秋庭伸也 杉山阿圣 寺田学
出版社:人民邮电出版社
ISBN:9787115563569
本篇文章仅用于学习和研究目的,不会用于任何商业用途。引用书籍《图解机器学习算法》的内容旨在分享知识和启发思考,尊重原著作者宫崎修一和石田保辉的知识产权。如有侵权或者版权纠纷,请及时联系作者。
———————————————————————————————————————————