一、引言
分组查询的关键字是:GROUP BY。
二、DQL—分组查询
1、语法
SELECT 字段列表 FROM 表名 [ WHERE 条件 ] GROUP BY 分组字段名 [ HAVING 分组后过滤条件 ];
注意:
1、'[ ]' 里的内容可以有可以没有。
2、这条SQL语句有两块指定条件的地方,那它们之间有啥区别呢?
3、 WHERE 与 HAVING 区别:
(1)执行时机不同:WHERE 是分组之前进行过滤,不满足 WHERE 条件,不参与分组;而 HAVING 是分组之后对结果进行过滤。(2)判断条件不同:WHERE 不能对聚合函数进行判断,而 HAVING 可以。
三、案例操作:
接下来回到 DataGrip 工具进行数据的分组查询学习和操作。
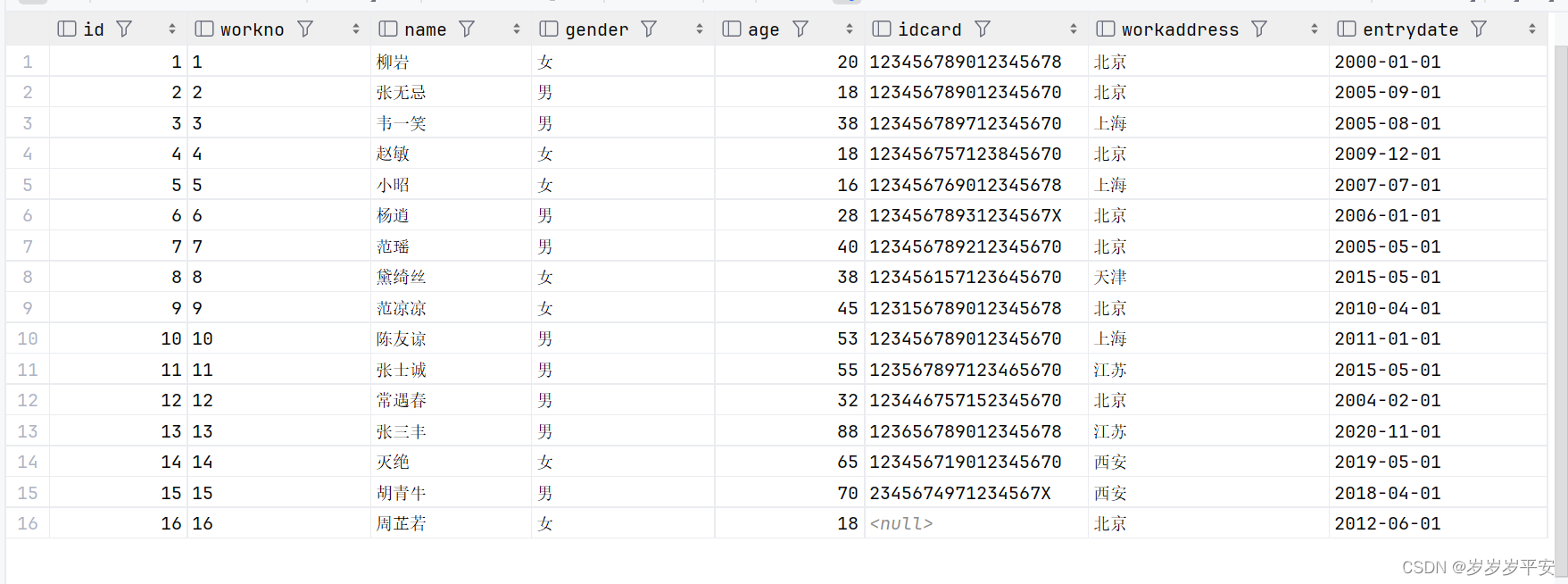
0、emp 表的初始数据
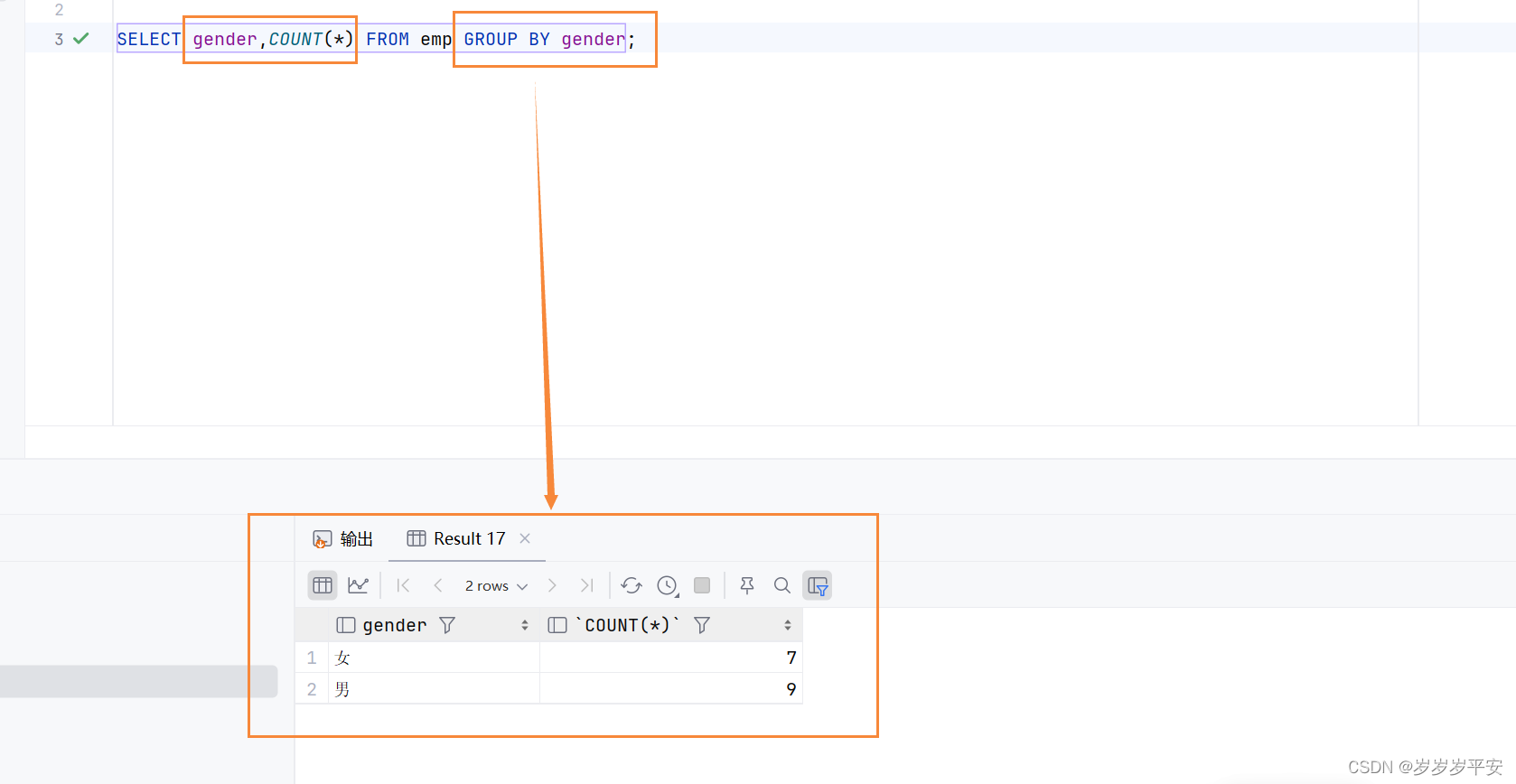
1、根据性别分组,统计男性员工和女性员工的数量
SELECT gender,COUNT(*) FROM emp GROUP BY gender;
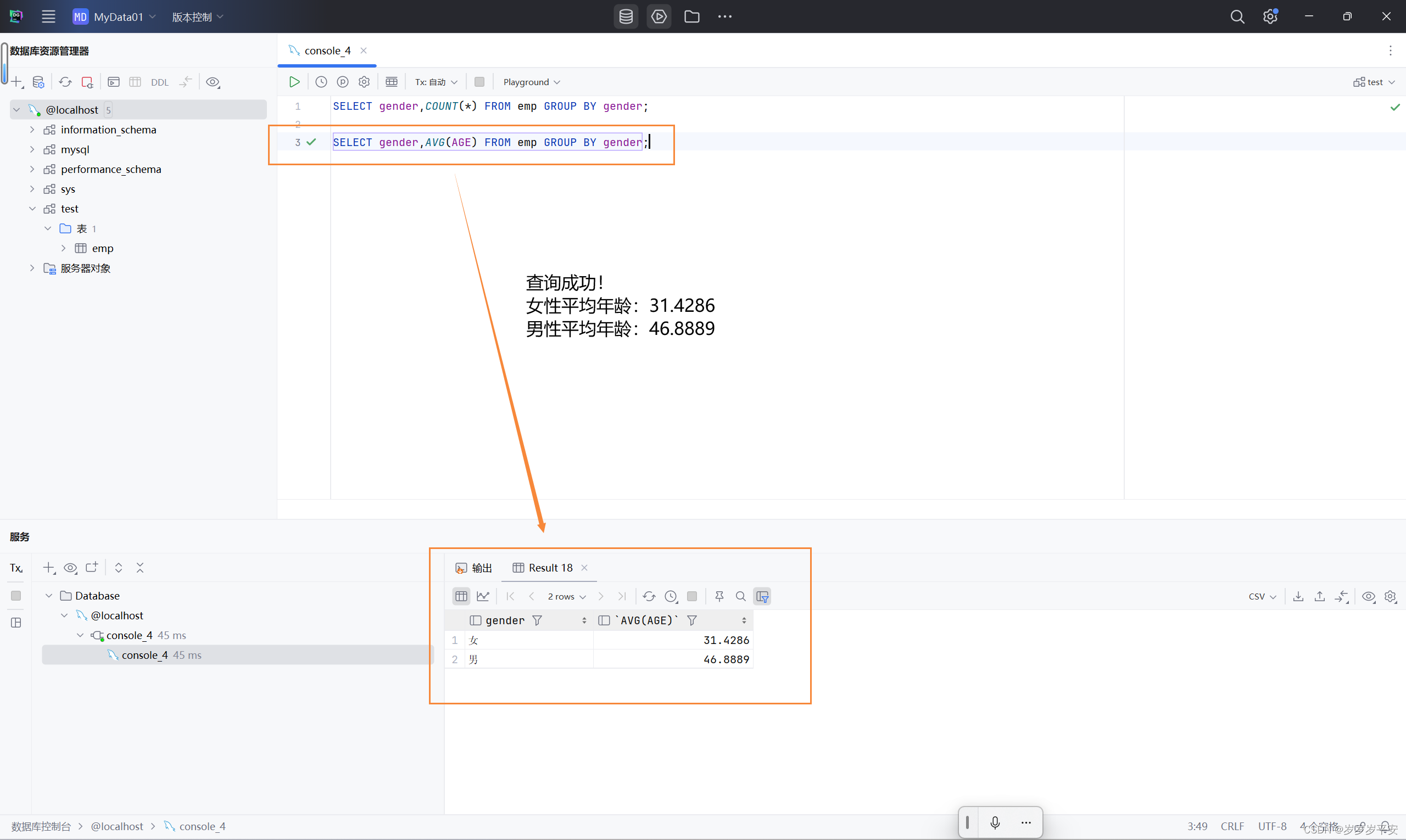
2、 根据性别分组,统计男性员工和女性员工的平均年龄
SELECT gender,AVG(AGE) FROM emp GROUP BY gender;
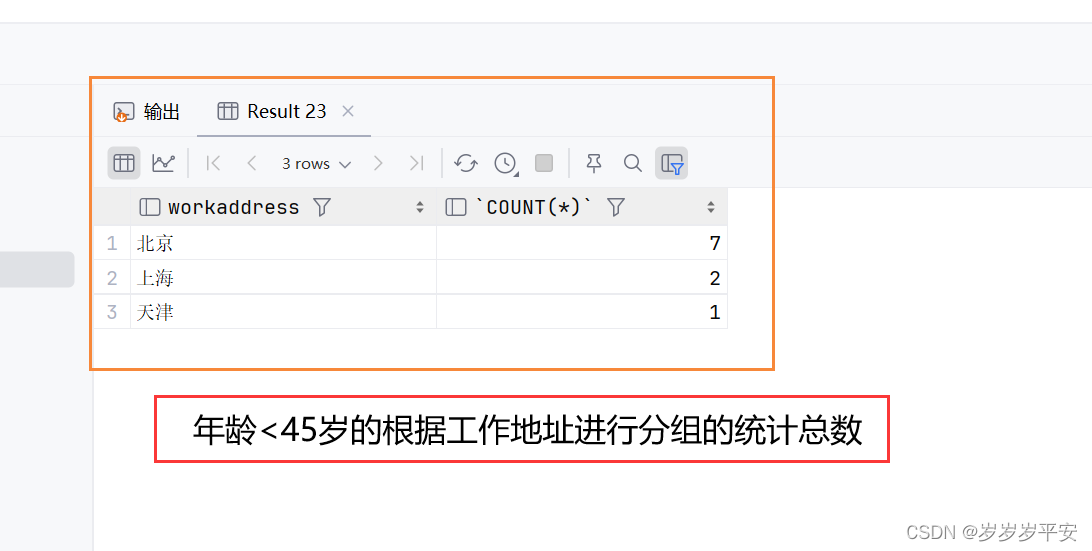
3、查询年龄小于45的员工,并根据工作地址分组,获取员工数量大于等于3的工作地址
首先可以查到:查询年龄小于45的员工,并根据工作地址分组
SELECT workaddress,COUNT(*) FROM emp WHERE age<45 GROUP BY workaddress;
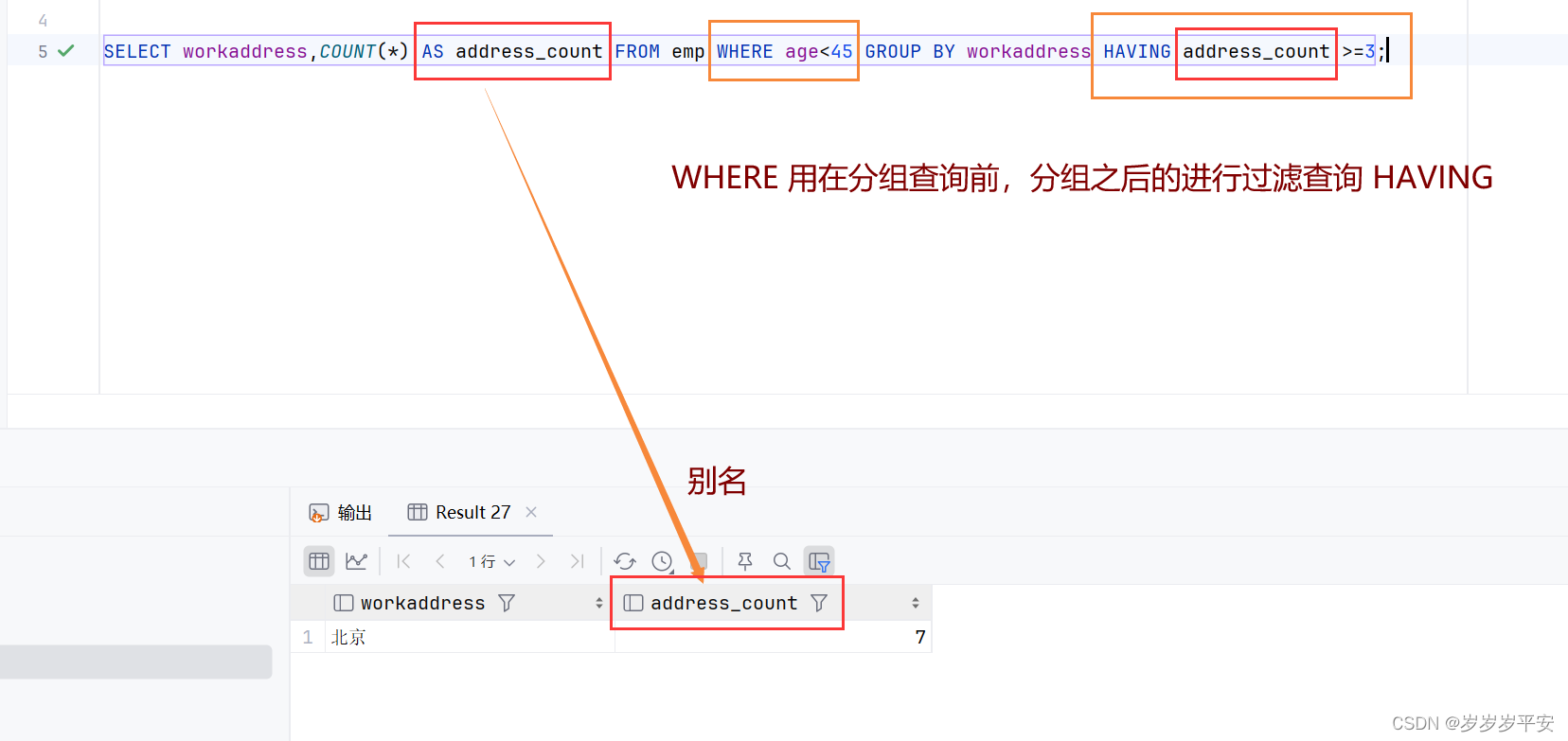
然后经过 WHERE 分组后再进行分组条件的判断:(HAVING),再进行分组查询得出结果。也就是要在分组的基础上再过滤
SELECT workaddress,COUNT(*) AS address_count FROM emp WHERE age<45 GROUP BY workaddress HAVING address_count >=3;
四、总结
1、分组查询要用到的关键字叫 GROUP BY。
2、在分组之前过滤叫 WHERE ,分组之后过滤叫 HAVING 。
3、注意:
(1)执行顺序:WHERE > 聚合函数 > HAVING 。
也就是说:WHERE 是在分组之前过滤的,分组的时候是在执行聚合函数,而 HAVING 是在我们分组聚合之后过滤的。
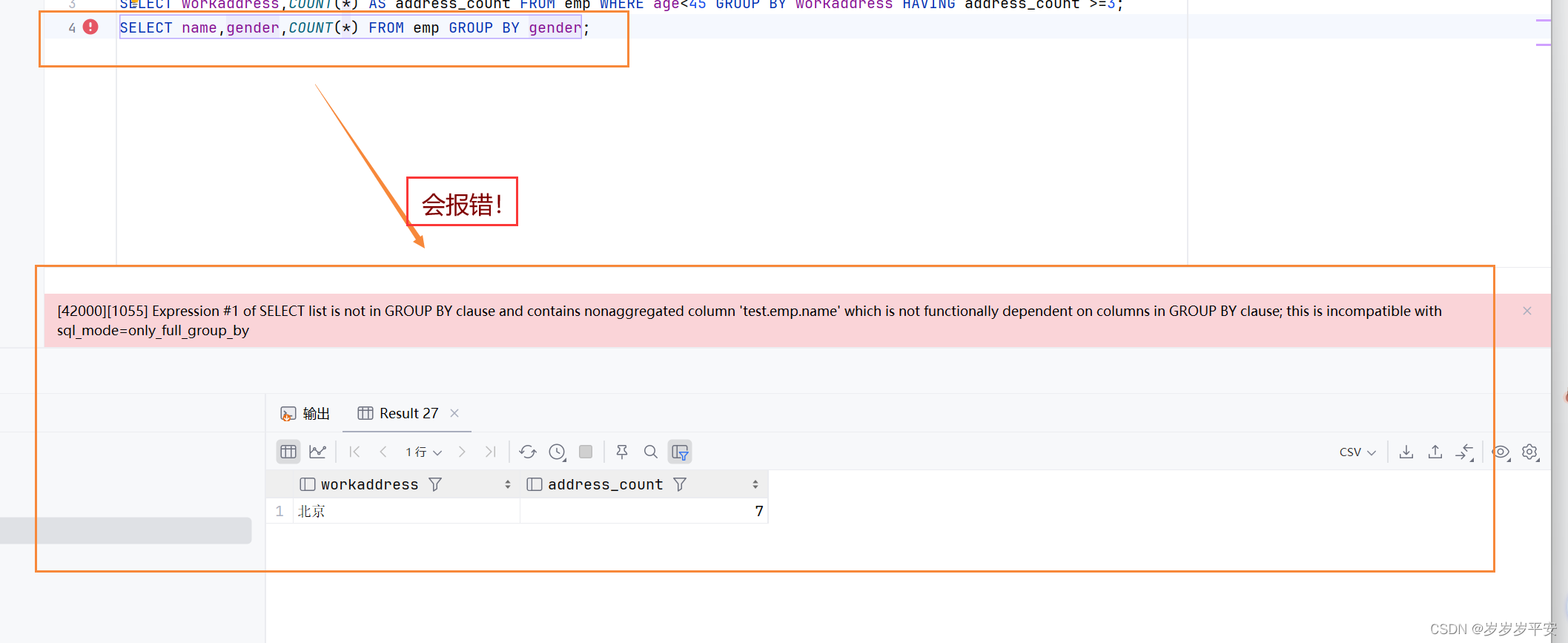
(2)分组之后,查询的字段一般为聚合函数和分组字段,查询其他字段无任何意义。
举个例子说明:就第一个查询操作。
SELECT gender,COUNT(*) FROM emp GROUP BY gender;根据编写的SQL语句的内容:聚合函数的字段是:COUNT(*),分组之后的字段是:gender
而我们 SELECT 关键字后面跟着的就是这两个字段,也就是查询的字段是这两个。如果在SELECT 后面加一个 name 字段,那查出来的值无任何意义。