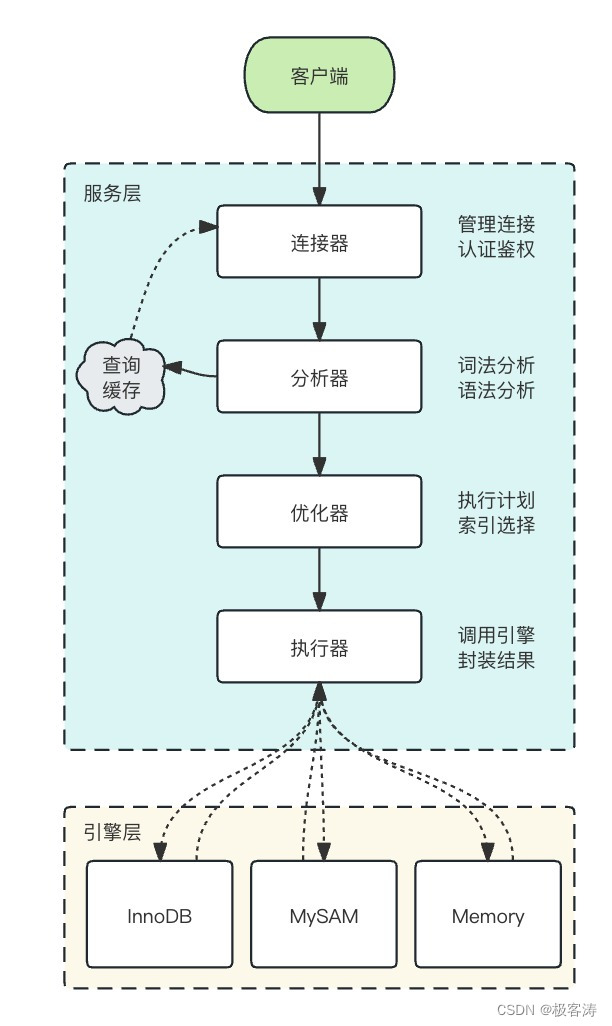
堆排序,无疑与堆这种数据结构有关。在了解堆排序之前,我们需要先了解堆的建立与维护方法。
堆
堆(二插堆)可以用一种近似的完全二叉树来表示,该二叉树除了叶子结点之外,其余节点均具有两个子女,每一个节点都有一个用于排序的关键字key。根据堆顶元素性质,堆可以分为大根堆和小根堆。对于大根堆而言,其堆顶是整棵树最大的节点,并且以其为祖先的每一个节点均是一个大根堆。小根堆反之亦然。堆排序采用大根堆完成,所以我们下面用大根堆来介绍堆的建立。
用一个长为 n n n 的数组表示一棵近似完全二叉树,其下标从0到n-1。那么对于其中的每一个节点,其父节点、左右子女节点可如下表示:
p a r e n t ( i ) = ( i − 1 ) / 2 parent(i) = (i - 1)/2 parent(i)=(i−1)/2
l e f t ( i ) = 2 i + 1 left(i) = 2i + 1 left(i)=2i+1
r i g h t ( i ) = 2 i + 2 right(i) = 2i + 2 right(i)=2i+2
显然,随便拿到的一个数组通常不具备最大堆的性质。以其中一个节点 i 为例,该节点有可能不是以该节点为根的子树中的最大节点。对此,我们的策略是,只要让每一个节点i,均比自己的左右子女大,那么就可以建立起来一个大根堆。
因此,我们考虑对每一个节点施加一种操作,使该索引上的节点满足大于左右子女的性质。这个操作被称之为堆化操作max-healpify。
堆化
堆化操作的步骤是,首先确定节点i左右子女中的最大值,然后将其与左右子女相比较,如果比左右子女小,则该节点不符合要求,需要与较大的那个子女相交换。原目标节点被交换到其子女位置后,可能仍旧比其当前子女小,这样相当于破坏了节点i子女的最大堆性质。因此需要继续跟新子女比较,并根据比较结果向下交换,直到其比子女大为止。
这样的max-heapify操作,既保证了i节点符合最大堆性质,又不会破坏其子女的最大堆的性质。示例代码如下:
void max_heapify(int *arr, int n, int i){int l = i * 2 + 1, r = i * 2 + 2;if (r >= n) return;int max_child = arr[l] >= arr[r] ? l : r;if (arr[i] < arr[max_child]) {swap(arr[i], arr[max_child]);max_heapify(arr, n, max_child);}
}
堆的建立
max-heapify操作的效果是,使目标节点i大于左右子女,并且不破坏以其为根节点的子树的所有子节点的最大堆性质。也就是说,如果以其为根的子树的其余节点,如果不符合最大堆性质,那么堆化操作实际上是失败的。
因此如果我们希望将任意一个数组转化为最大堆,应当自底向上对每一个节点执行堆化操作。由于,。在近似完全二叉树中,最后一个非叶子结点的索引是n/2。示例代码如下:
void make_heap(int *arr, int n){for (int i = n - 1; i >= 0; --i) {max_heapify(arr, n, i);}
}
建堆的时间复杂度是 O ( n ) O(n) O(n)。
堆性质的维护
最大堆提供抽取堆顶元素的操作。当最大堆的堆顶被删除时,堆大小减1。此时应当将堆的最后一个元素移至堆顶,然后对堆顶节点执行max-heapify操作,从而维护最大堆性质。
int pop(int *arr, int n) {int top = arr[0];arr[0] = arr[n - 1];max_heapify(arr, n - 1);return top;
}
使用C++标准库去处理堆
C++在<algorithm>头文件中提供了对数据结构堆的支持。主要包括以下几个API。C++的泛型算法库基于范围range概念对数据进行操作。一个范围可以由一对迭代器begin和end表示,这个范围的具体区间是左闭右开的[begin, end)。
1. make_heap 建堆
void make_heap( RandomIt first, RandomIt last, Compare comp );
该函数可以将一个范围,按照对应的比较器构建成堆。比较器默认为operator<(),且根据该小于运算符构建一个最大堆。如果想构建一个最小堆,可以提供一个大于运算对象std::greater<>()作为比较器。
2. push_heap 向堆中插入元素
void push_heap( RandomIt first, RandomIt last, Compare comp );
该函数将一个元素插入堆中,并使[first, last + 1)构建成堆。堆的大小此时相比之前+1。
3. pop_heap 删除堆顶
void pop_heap( RandomIt first, RandomIt last, Compare comp );
该函数将堆顶元素与last - 1表示的元素进行交换,并使范围[first, last - 1)维持堆的性质。注意,堆的大小减小,但是原堆顶元素仍然停留在容器中,没有被删除。举个例子,最大堆[9 5 4 1 1 3]经过pop_heap后,将变为[5 3 4 1 1 9],可以看到9仍旧停留在容器中,堆的范围减1。
4. 堆性质检验
bool is_heap( RandomIt first, RandomIt last, Compare comp );
如果范围是关于对应比较器的堆就返回 true,否则返回 false。
堆排序
堆排序是借助数据结构堆进行的一种基于交换的排序算法,其操作步骤是,对于一个长为n的数组,首先建立最大堆。然后在第i次循环中,将堆顶与堆底交换,堆的大小减1,直至堆的大小为1。这样可以逐步将一个升序数组中的较大元素按倒序填充到数组尾部。示例代码如下:
void heap_sort(int *arr, int n){make_heap(arr, n);for (int i = n - 1; i >= 1; --i) {swap(arr[0], arr[i]);max_heapify(arr, i, 0);}
}
堆排序的时间复杂度为 O ( n l g n ) O(nlgn) O(nlgn)。
技巧应用
面试题 17.14. 最小K个数 - 力扣(LeetCode)
设计一个算法,找出数组中最小的k个数。以任意顺序返回这k个数均可。
示例:
输入: arr = [1,3,5,7,2,4,6,8], k = 4
输出: [1,2,3,4]
提示:
0 <= len(arr) <= 100000
0 <= k <= min(100000, len(arr))
还是这道题。在之前的一节中,我们利用快速排序的划分思想,使数组中索引为k或k-1的元素,其前面的元素一定比它小,后面的元素一定比它大,进而获取前k小数字。这一节,我们利用堆的思想,去换一种方法解决这个问题。
首先,直观一点来处理,我们可以将这个数组转换为最小堆,依次从这个最小堆中弹出k个数,即为前k小的数。示例代码如下:
class Solution {
public:// 小根堆解法,堆排序vector<int> smallestK(vector<int>& arr, int k) {if (arr.empty() || arr.size() < k) return {};make_heap(arr.begin(), arr.end(), std::greater<int>());vector<int> rtn;while(k--) {pop_heap(arr.begin(), arr.end(), std::greater<int>());rtn.push_back(arr.back());arr.pop_back();}return rtn;}
};
- 时间复杂度: O ( n l g n ) O(nlgn) O(nlgn)
- 空间复杂度: O ( k ) O(k) O(k)
一种更好的思路是,使用最大堆来处理。在一开始,我们将数组的前k个元素放入结果数组中,并建立最大堆。此后,对于区间[k, n - 1]的数组元素,依次与堆顶进行比较。若比堆顶大,则其势必不在前k小数组中。若其比堆顶小,则其有可能为前k小数字,我们将该数设置为新堆顶,并对堆顶执行max-heapify操作。如此到最后,由于不要求按序返回结果,我们直接返回堆数组即可。示例代码如下:
`
class Solution {
public:// 最大堆解法vector<int> smallestK(vector<int>& arr, int k) {if(arr.empty() || arr.size() < k || k == 0) return {};vector<int> rtn(arr.begin(), arr.begin() + k);make_heap(rtn.begin(), rtn.end());for (int i = k; i < arr.size(); ++i) {if (arr[i] < rtn[0]) {pop_heap(rtn.begin(), rtn.end());rtn[k - 1] = arr[i];push_heap(rtn.begin(), rtn.end());}}return rtn;}
};
- 时间复杂度: O ( n l g k ) O(nlgk) O(nlgk)
- 空间复杂度: O ( k ) O(k) O(k)