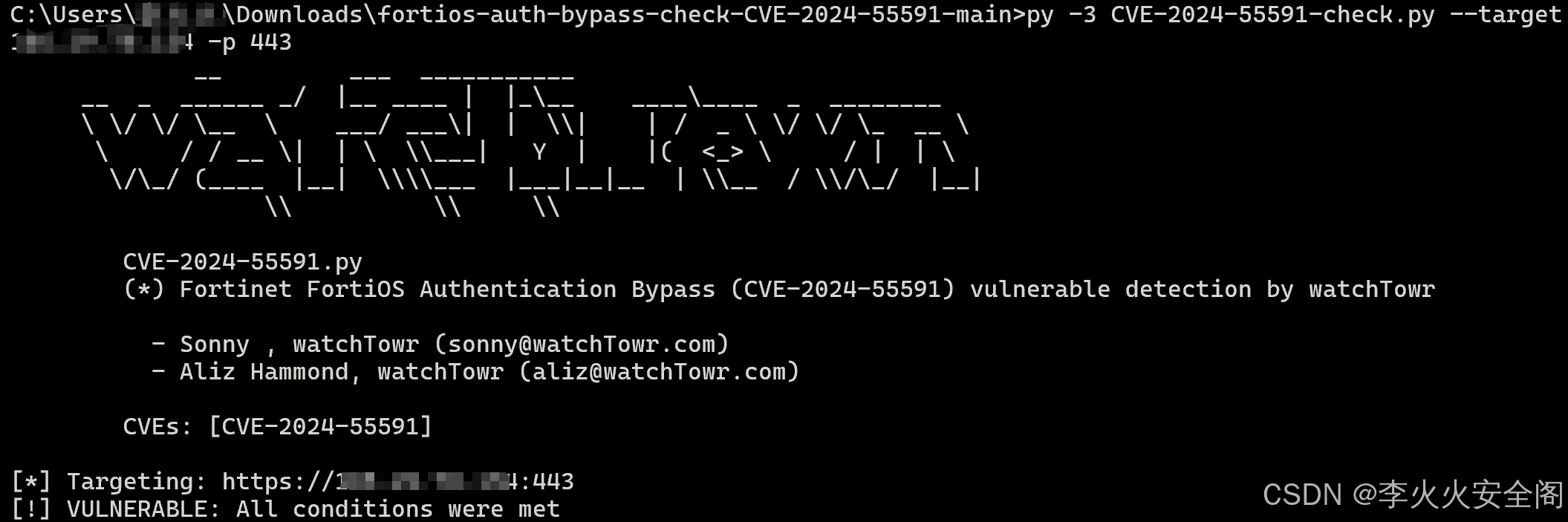
ComfyUI-PromptOptimizer 是 ComfyUI 的一个自定义节点,旨在优化文本转图像模型的提示。它将用户输入的提示转换为更详细、更多样化、更生动的描述,使其更适合生成高质量的图像。无需本地模型。
1、功能
- 提示优化:优化用户输入的提示以生成更适合文本转图像模型的版本。
- 多语言支持:自动将非英语提示翻译成英语。
- 丰富的细节:添加设置、颜色、灯光和整体氛围等细节。
- 风格扩展:如果提示中包含视觉风格或艺术家参考,则扩展这些参考。
- 多样化的输出:避免重复的词汇和短语,以确保提示独特而多样。
- 轻松集成:作为自定义节点无缝集成到您的 ComfyUI 工作流程中。
2、安装
将此存储库克隆到 ComfyUI 安装的 custom_nodes 目录中:
git clone https://github.com/ciga2011/ComfyUI-PromptOptimizer.git启动 ComfyUI 并确保节点列表中有 Free Prompt Optimizer 节点。
3、使用
- 将 Free Prompt Optimizer 节点添加到 ComfyUI 工作流。
- 在提示字段中输入原始提示。
- 运行工作流。节点将输出针对文本到图像模型定制的优化提示。
4、示例
工作流:

输入提示:
A beautiful sunset over the mountains.翻译:群山间美丽的日落。
优化提示:
Envision a breathtaking twilight spectacle as the sun dips below a rugged mountain range, casting vibrant shades of crimson, amber, and violet across the expansive sky. Silhouettes of jagged peaks frame the horizon, their rugged textures kissed by the warm, fading light. Wispy clouds scatter like delicate brush strokes, reflecting the day's final glow. The atmosphere is imbued with a sense of tranquility and awe, inviting viewers to lose themselves in the captivating beauty of nature’s masterpiece.翻译:想象一个令人惊叹的黄昏奇观,太阳落入崎岖的山脉之下,在广阔的天空中投射出鲜艳的深红色、琥珀色和紫色。锯齿状山峰的轮廓勾勒出地平线,其崎岖的纹理被温暖、渐弱的光线亲吻。一缕缕云朵像精致的笔触一样散开,反射出一天的最后一丝光芒。气氛充满了宁静和敬畏之感,让观众沉浸在大自然杰作的迷人美景中。
原文链接:ComfyUI-PromptOptimizer - 汇智网