🤵♂️ 个人主页:@艾派森的个人主页
✍🏻作者简介:Python学习者
🐋 希望大家多多支持,我们一起进步!😄
如果文章对你有帮助的话,
欢迎评论 💬点赞👍🏻 收藏 📂加关注+
目录
1.项目背景
2.数据集介绍
3.技术工具
4.实验过程
4.1导入数据
4.2数据预处理
4.3数据可视化
4.4特征工程
4.5构建LSTM模型
4.6模型评价
5.结论
源代码
1.项目背景
黄金作为全球金融市场的重要组成部分,其价格变动不仅影响着投资者的收益,也是全球经济运行状况的晴雨表。随着全球化的推进和信息技术的飞速发展,黄金市场日益复杂多变,其价格受到众多因素的影响,包括全球经济状况、货币政策、地缘政治事件等。因此,对黄金价格进行准确预测,对于投资者而言,具有至关重要的意义。
传统的黄金价格预测方法往往基于统计分析或简单的机器学习模型,这些方法在处理复杂的非线性关系和长期依赖关系时存在局限性。而深度学习作为一种强大的机器学习方法,特别是长短期记忆网络(LSTM),在处理时间序列数据方面展现出了卓越的性能。LSTM模型通过其特殊的结构设计,能够有效地捕捉序列数据中的长期依赖关系,这对于预测黄金价格这种受多种因素长期影响的市场行为至关重要。
然而,尽管LSTM在黄金价格预测方面具有一定的优势,但现有的研究和实践仍面临一些挑战。一方面,黄金市场的复杂性和不确定性使得模型的预测精度和稳定性受到影响;另一方面,LSTM模型的参数调优和特征选择也是影响预测效果的关键因素。因此,对LSTM模型进行优化,提高其在黄金价格预测中的性能,具有重要的理论价值和实际应用意义。
基于以上背景,本研究旨在通过优化LSTM模型,提高黄金价格预测的准确性和稳定性。我们将从模型结构、参数优化、特征选择等方面入手,对LSTM模型进行改进和优化。通过本研究的开展,我们期望能够为投资者提供更加准确、可靠的黄金价格预测工具,同时推动深度学习技术在金融时间序列预测领域的进一步发展。
2.数据集介绍
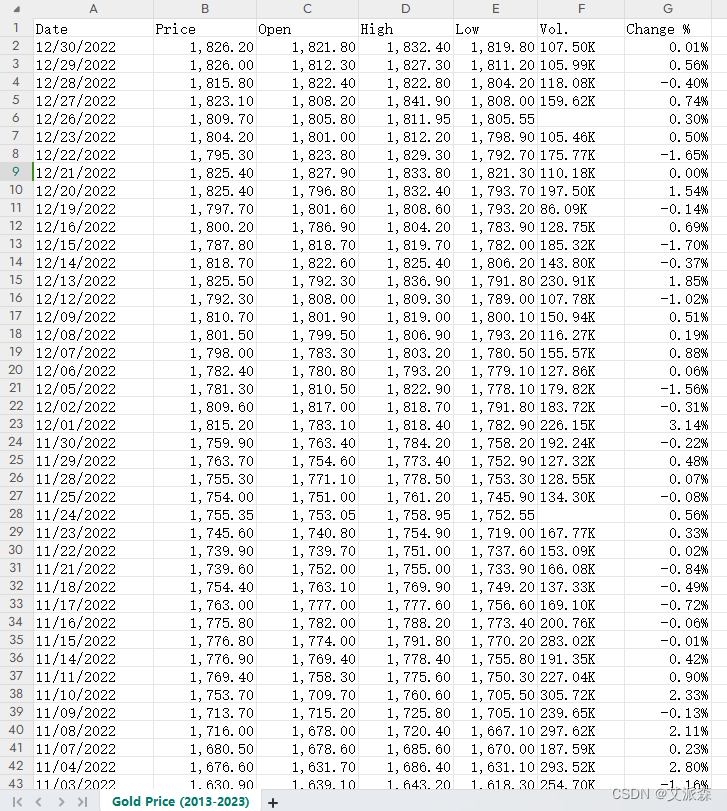
本数据集来源于Kaggle,这个全面的数据集提供了从2013年到2023年10年黄金价格趋势的见解。它细致地记录了每天的开盘价和收盘价,高点和低点,以及每天的交易量。原始数据集共有2583条,7个变量。
3.技术工具
Python版本:3.9
代码编辑器:jupyter notebook
4.实验过程
4.1导入数据
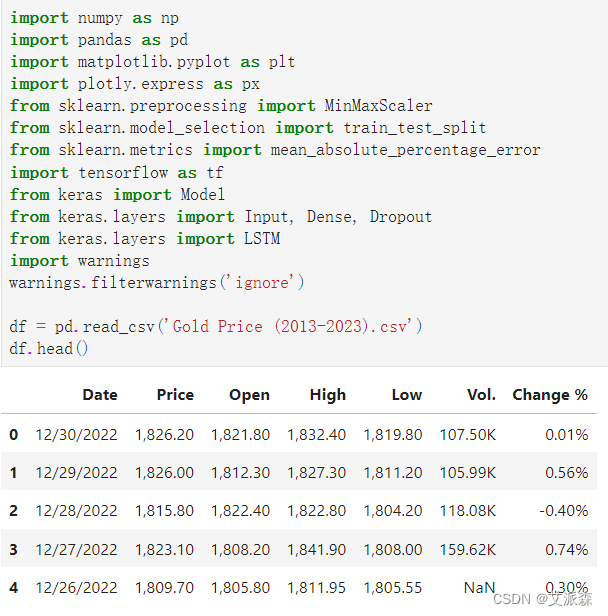
首先导入本次实验用到第三方库并加载数据集
查看数据大小
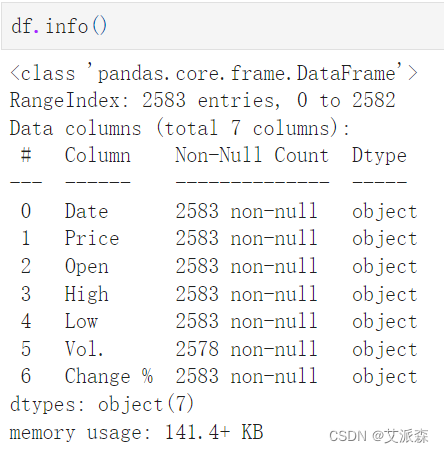
查看数据基本信息
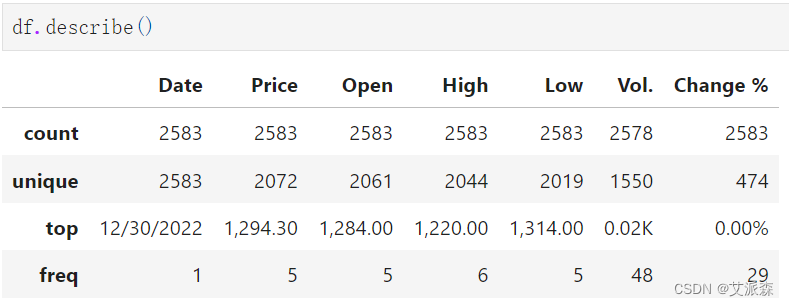
查看数据描述性统计
4.2数据预处理
由于我们不会使用Vol.和Change %特征来预测价格,我们将删除这两个特征:

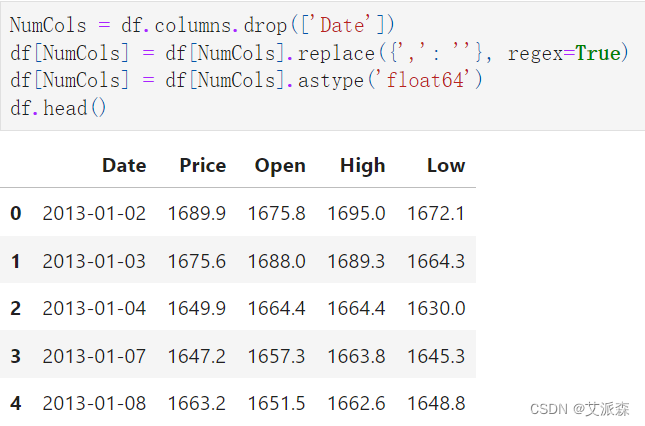
日期特征以对象的形式存储在数据帧中。为了提高计算速度,我们将其数据类型转换为datetime,然后按升序对该特征进行排序:

“,”符号在数据集中是冗余的。首先,我们将其从整个数据集中移除,然后将数值变量的数据类型更改为float:
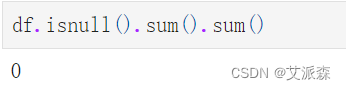
统计缺失值情况
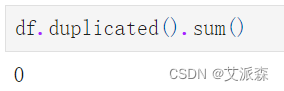
统计重复值情况
4.3数据可视化

4.4特征工程
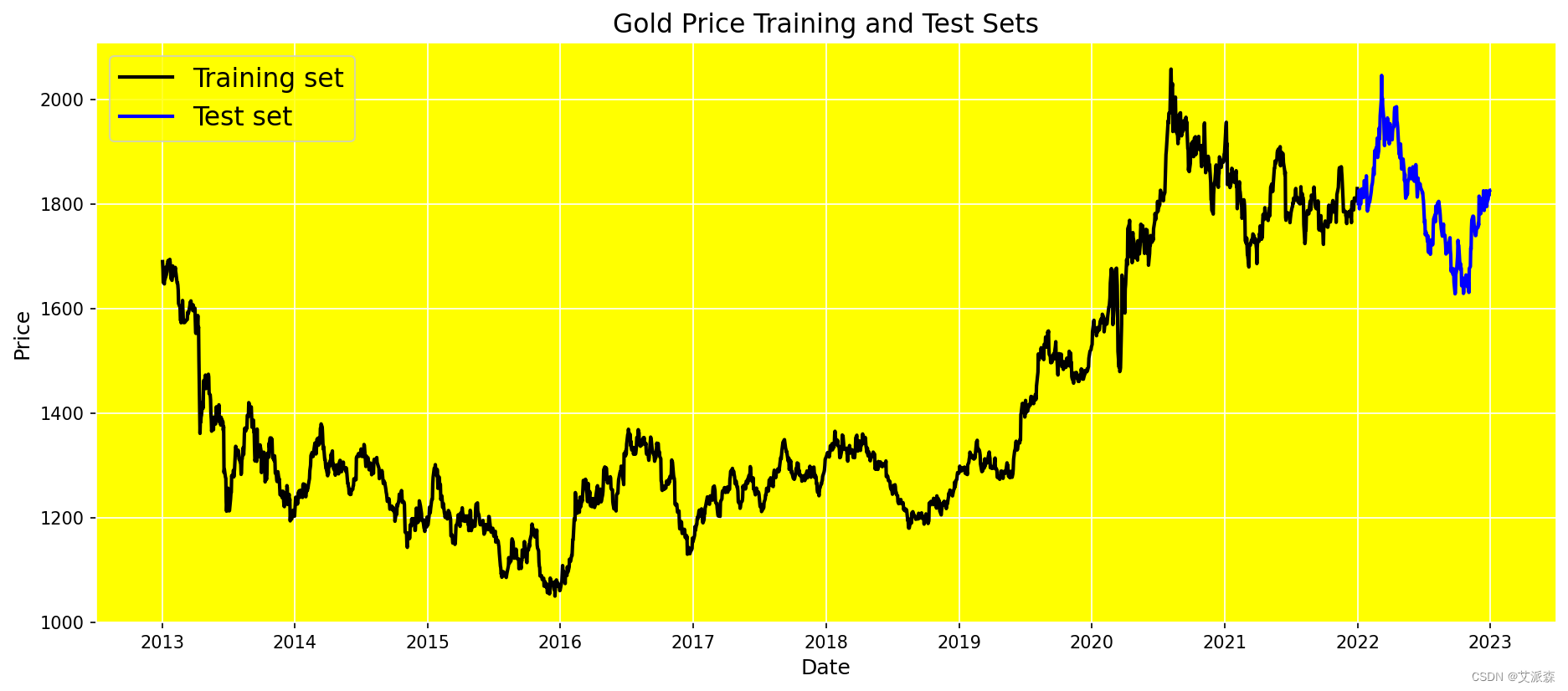
将数据分割为训练集和测试集 由于我们不能对时间序列数据中的未来数据进行训练,所以我们不应该对时间序列数据进行随机分割。在时间序列分割中,测试集总是晚于训练集。我们将最后一年的时间用于测试,其他时间用于训练。
黄金价格训练和测试集

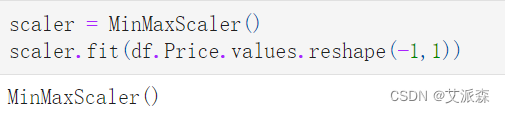
数据缩放
由于我们的目标是仅根据其历史数据预测价格,我们使用MinMaxScaler缩放价格以避免密集的计算:
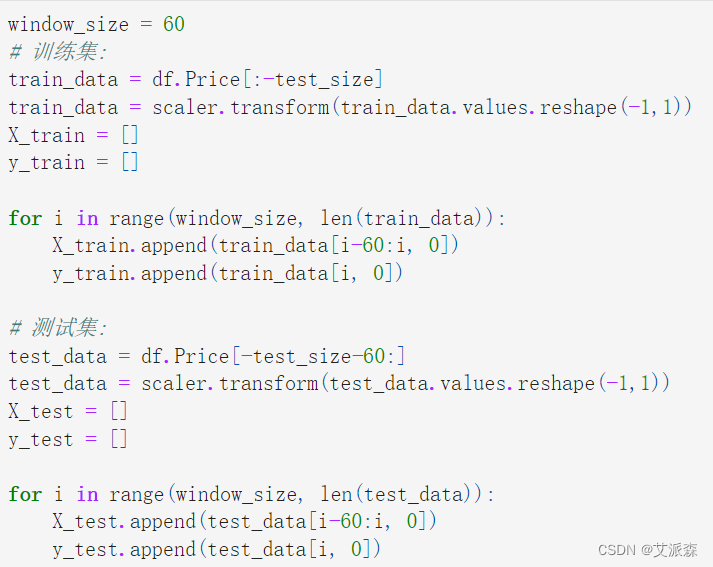
重构数据并创建滑动窗口
利用前一个时间步长来预测下一个时间步长称为滑动窗口。这样,时间序列数据就可以表示为监督学习。我们可以通过使用前一个时间步骤作为输入变量,并使用下一个时间步骤作为输出变量来做到这一点。前一个时间步长的数量称为窗口宽度。这里我们将窗口宽度设置为60。因此,X_train和X_test将是包含60个时间戳价格的嵌套列表。y_train和y_test也是黄金价格列表,其中包含第二天的黄金价格,分别对应X_train和X_test中的每个列表:
将数据转换为Numpy数组 现在X_train和X_test是嵌套列表(二维列表),y_train是一维列表。我们需要将它们转换为更高维度的numpy数组,这是TensorFlow在训练神经网络时接受的数据格式:

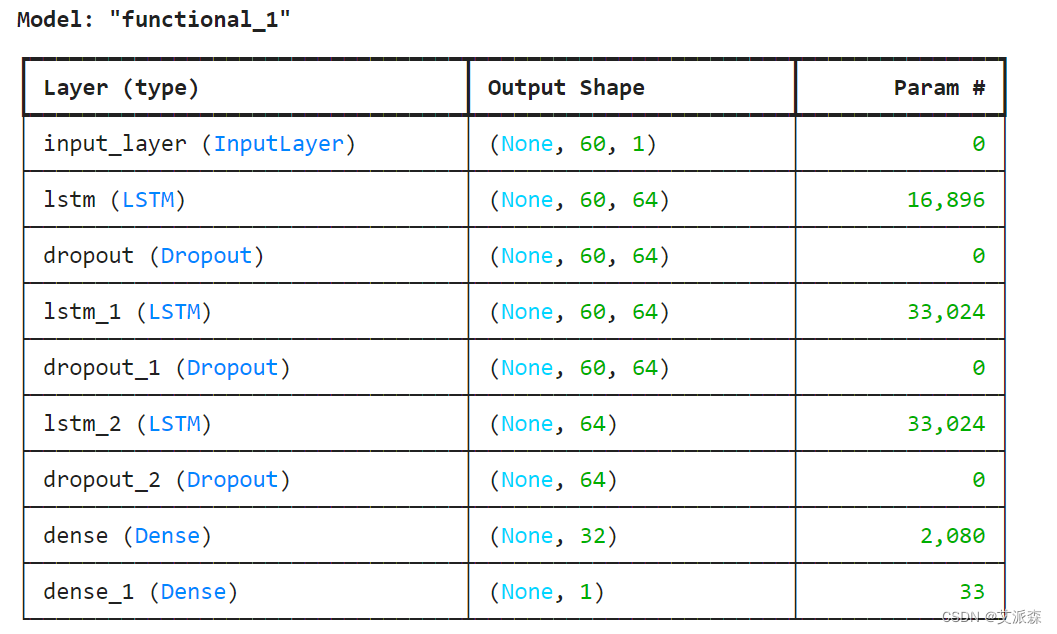
4.5构建LSTM模型
创建LSTM网络
我们建立了一个LSTM网络,它是一种递归神经网络,旨在解决梯度消失问题:

训练模型


4.6模型评价
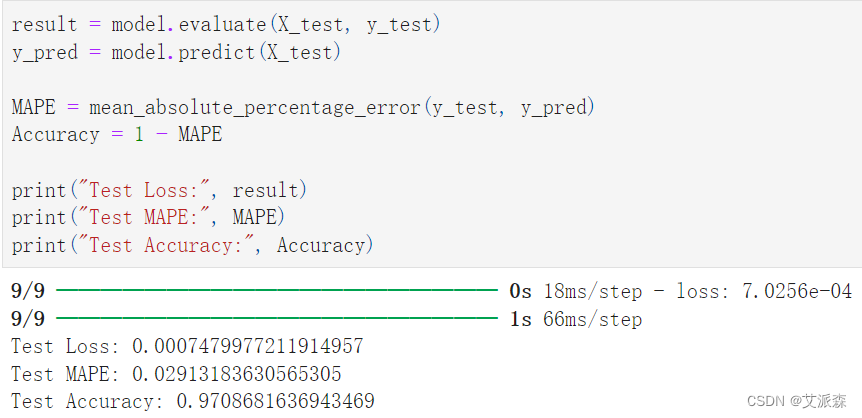
接下来,我们使用MAPE(平均绝对百分比误差)度量来评估我们的时间序列预测:
可视化结果
将实际和预测的Price值返回到它们的原始刻度:

调查模型预测的价格与实际价格的接近程度:

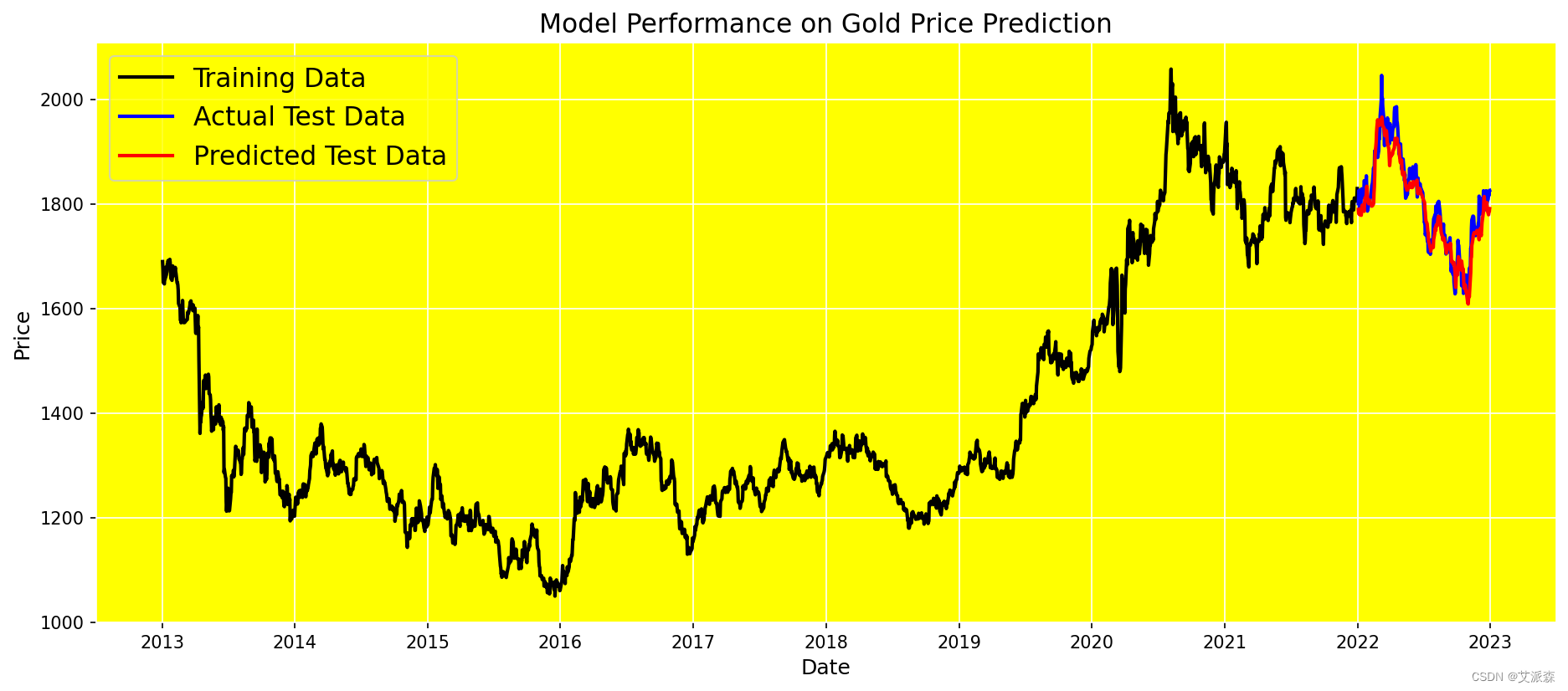
可以看到,LSTM模型预测的价格与实际价格有很大的吻合!在测试数据上得到的Loss and Accuracy (1-MAPE)值也证实了模型的良好性能!: 🏆损失:0.001 🏆准确率:97%
5.结论
本实验基于Kaggle上提供的从2013年到2023年的黄金价格数据集,运用长短期记忆网络(LSTM)构建了黄金价格预测模型。该数据集详细记录了每日的黄金价格信息,包括开盘价、收盘价、高点、低点和交易量等,为模型的训练提供了丰富的数据支持。
实验结果表明,LSTM模型在预测黄金价格方面展现出了卓越的性能。预测价格与实际价格高度吻合,证明了模型在捕捉黄金价格变化趋势方面的有效性。同时,模型在测试数据上取得了较低的损失值和较高的准确率(以1-MAPE衡量),具体数值为模型损失0.001和模型准确率97%,进一步验证了模型的稳定性和可靠性。
通过本次实验,我们可以得出以下结论:
-
LSTM模型能够充分利用历史数据中的时间序列信息,有效地预测黄金价格的未来走势。
-
模型对于黄金价格变化趋势的捕捉能力强,可以为投资者提供有价值的参考信息,帮助他们制定更为精准的投资策略。
-
本实验所采用的LSTM模型在黄金价格预测领域具有广泛的应用前景,可以进一步拓展到其他金融时间序列预测任务中。
需要注意的是,虽然本实验取得了较为理想的预测结果,但金融市场仍然受到众多不可预测因素的影响。因此,在实际应用中,我们需要持续关注市场动态,结合其他分析方法和技术手段,以提高预测精度和稳定性。同时,随着深度学习技术的不断发展,我们可以进一步探索和改进模型结构,以更好地适应复杂多变的金融市场环境。
源代码
在本笔记中,我们将建立一个时间序列模型来预测黄金的未来价格,这对交易者来说非常有用。为此,我们使用了10年(2013 - 2023年)的历史黄金价格数据。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import plotly.express as px
from sklearn.preprocessing import MinMaxScaler
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_absolute_percentage_error
import tensorflow as tf
from keras import Model
from keras.layers import Input, Dense, Dropout
from keras.layers import LSTM
import warnings
warnings.filterwarnings('ignore')df = pd.read_csv('Gold Price (2013-2023).csv')
df.head()
如您所见,该数据集包括每日黄金价格信息,包括每日开盘价、最高价和最低价以及每天的最终价格(price),以及每天的交易量和价格变化。
df.shape
df.info()
df.describe()
特征子集选择
由于我们不会使用Vol.和Change %特征来预测价格,我们将删除这两个特征:
df.drop(['Vol.', 'Change %'], axis=1, inplace=True)
转换数据
日期特征以对象的形式存储在数据帧中。为了提高计算速度,我们将其数据类型转换为datetime,然后按升序对该特征进行排序:
df['Date'] = pd.to_datetime(df['Date'])
df.sort_values(by='Date', ascending=True, inplace=True)
df.reset_index(drop=True, inplace=True)
“,”符号在数据集中是冗余的。首先,我们将其从整个数据集中移除,然后将数值变量的数据类型更改为float:
NumCols = df.columns.drop(['Date'])
df[NumCols] = df[NumCols].replace({',': ''}, regex=True)
df[NumCols] = df[NumCols].astype('float64')
df.head()
df.duplicated().sum()
df.isnull().sum().sum()
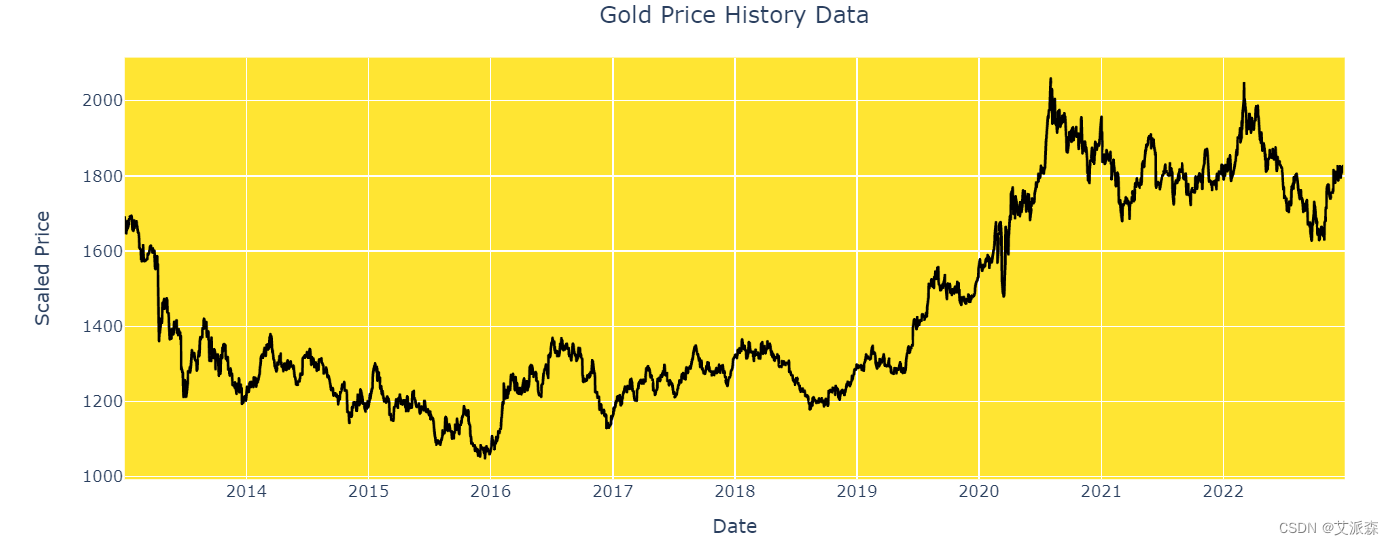
可视化黄金价格历史数据
互动黄金价格图表:
fig = px.line(y=df.Price, x=df.Date)
fig.update_traces(line_color='black')
fig.update_layout(xaxis_title="Date", yaxis_title="Scaled Price",title={'text': "Gold Price History Data", 'y':0.95, 'x':0.5, 'xanchor':'center', 'yanchor':'top'},plot_bgcolor='rgba(255,223,0,0.8)')
将数据分割为训练集和测试集
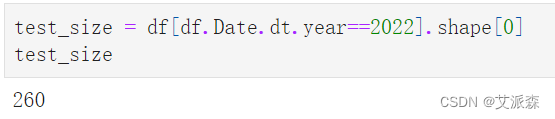
由于我们不能对时间序列数据中的未来数据进行训练,所以我们不应该对时间序列数据进行随机分割。在时间序列分割中,测试集总是晚于训练集。我们将最后一年的时间用于测试,其他时间用于培训:
test_size = df[df.Date.dt.year==2022].shape[0]
test_size
黄金价格训练和测试集
plt.figure(figsize=(15, 6), dpi=150)
plt.rcParams['axes.facecolor'] = 'yellow'
plt.rc('axes',edgecolor='white')
plt.plot(df.Date[:-test_size], df.Price[:-test_size], color='black', lw=2)
plt.plot(df.Date[-test_size:], df.Price[-test_size:], color='blue', lw=2)
plt.title('Gold Price Training and Test Sets', fontsize=15)
plt.xlabel('Date', fontsize=12)
plt.ylabel('Price', fontsize=12)
plt.legend(['Training set', 'Test set'], loc='upper left', prop={'size': 15})
plt.grid(color='white')
plt.show()
数据缩放
由于我们的目标是仅根据其历史数据预测价格,我们使用MinMaxScaler缩放价格以避免密集的计算:
scaler = MinMaxScaler()
scaler.fit(df.Price.values.reshape(-1,1))
重构数据并创建滑动窗口
利用前一个时间步长来预测下一个时间步长称为滑动窗口。这样,时间序列数据就可以表示为监督学习。我们可以通过使用前一个时间步骤作为输入变量,并使用下一个时间步骤作为输出变量来做到这一点。前一个时间步长的数量称为窗口宽度。这里我们将窗口宽度设置为60。因此,X_train和X_test将是包含60个时间戳价格的嵌套列表。y_train和y_test也是黄金价格列表,其中包含第二天的黄金价格,分别对应X_train和X_test中的每个列表:
window_size = 60
# 训练集:
train_data = df.Price[:-test_size]
train_data = scaler.transform(train_data.values.reshape(-1,1))
X_train = []
y_train = []for i in range(window_size, len(train_data)):X_train.append(train_data[i-60:i, 0])y_train.append(train_data[i, 0])# 测试集:
test_data = df.Price[-test_size-60:]
test_data = scaler.transform(test_data.values.reshape(-1,1))
X_test = []
y_test = []for i in range(window_size, len(test_data)):X_test.append(test_data[i-60:i, 0])y_test.append(test_data[i, 0])
将数据转换为Numpy数组
现在X_train和X_test是嵌套列表(二维列表),y_train是一维列表。我们需要将它们转换为更高维度的numpy数组,这是TensorFlow在训练神经网络时接受的数据格式:
X_train = np.array(X_train)
X_test = np.array(X_test)
y_train = np.array(y_train)
y_test = np.array(y_test)X_train = np.reshape(X_train, (X_train.shape[0], X_train.shape[1], 1))
X_test = np.reshape(X_test, (X_test.shape[0], X_test.shape[1], 1))
y_train = np.reshape(y_train, (-1,1))
y_test = np.reshape(y_test, (-1,1))print('X_train Shape: ', X_train.shape)
print('y_train Shape: ', y_train.shape)
print('X_test Shape: ', X_test.shape)
print('y_test Shape: ', y_test.shape)
创建LSTM网络
我们建立了一个LSTM网络,它是一种递归神经网络,旨在解决梯度消失问题:# 模型定义:
def define_model():input1 = Input(shape=(window_size,1))x = LSTM(units = 64, return_sequences=True)(input1) x = Dropout(0.2)(x)x = LSTM(units = 64, return_sequences=True)(x)x = Dropout(0.2)(x)x = LSTM(units = 64)(x)x = Dropout(0.2)(x)x = Dense(32, activation='softmax')(x)dnn_output = Dense(1)(x)model = Model(inputs=input1, outputs=[dnn_output])model.compile(loss='mean_squared_error', optimizer='Nadam')model.summary()return model
# 模型训练:
model = define_model()
history = model.fit(X_train, y_train, epochs=150, batch_size=32, validation_split=0.1, verbose=1)
模型评价
接下来,我们使用MAPE(平均绝对百分比误差)度量来评估我们的时间序列预测:
result = model.evaluate(X_test, y_test)
y_pred = model.predict(X_test) MAPE = mean_absolute_percentage_error(y_test, y_pred)
Accuracy = 1 - MAPEprint("Test Loss:", result)
print("Test MAPE:", MAPE)
print("Test Accuracy:", Accuracy)
可视化结果
将实际和预测的Price值返回到它们的原始刻度:
y_test_true = scaler.inverse_transform(y_test)
y_test_pred = scaler.inverse_transform(y_pred)
调查模型预测的价格与实际价格的接近程度:
plt.figure(figsize=(15, 6), dpi=150)
plt.rcParams['axes.facecolor'] = 'yellow'
plt.rc('axes',edgecolor='white')
plt.plot(df['Date'].iloc[:-test_size], scaler.inverse_transform(train_data), color='black', lw=2)
plt.plot(df['Date'].iloc[-test_size:], y_test_true, color='blue', lw=2)
plt.plot(df['Date'].iloc[-test_size:], y_test_pred, color='red', lw=2)
plt.title('Model Performance on Gold Price Prediction', fontsize=15)
plt.xlabel('Date', fontsize=12)
plt.ylabel('Price', fontsize=12)
plt.legend(['Training Data', 'Actual Test Data', 'Predicted Test Data'], loc='upper left', prop={'size': 15})
plt.grid(color='white')
plt.show()资料获取,更多粉丝福利,关注下方公众号获取