目录
- 集合
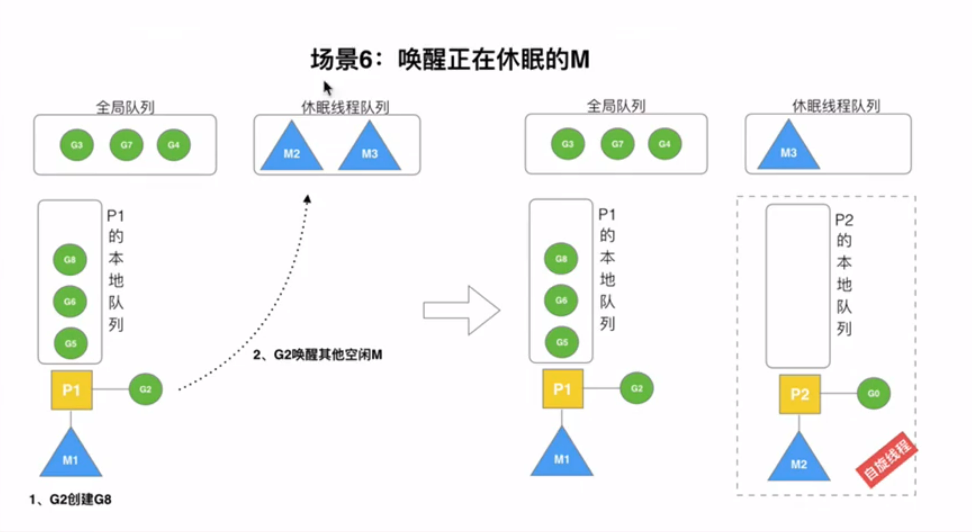
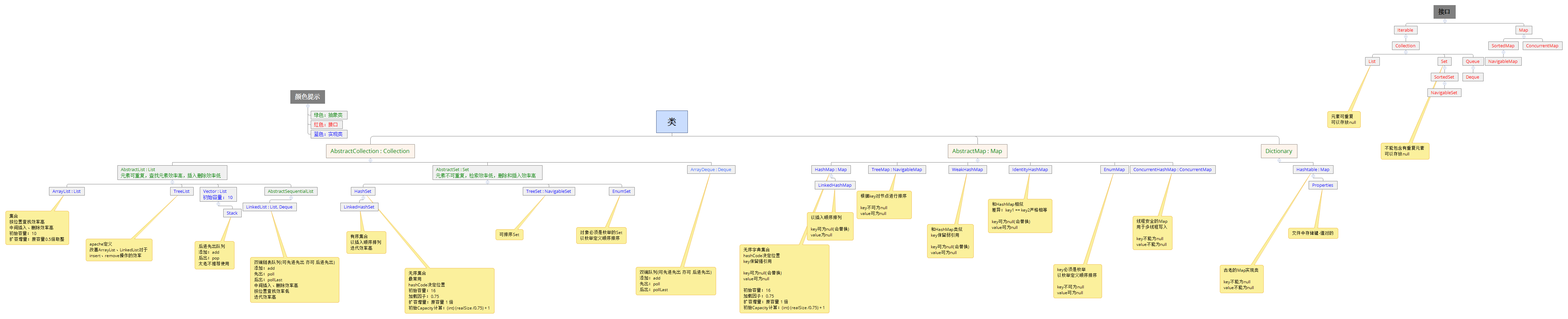
- 一、图解集合的继承体系?([图片来源](https://www.cnblogs.com/mrhgw/p/9728065.html))
- 点击查看大图
- 二、List,Set,Map三者的区别?
- 三、List接口的实现
- 3.1、Arraylist 、 LinkedList、Vector
- 3.2、Arraylist 、 LinkedList、Vector 三者的区别?
- 3.3、对RandomAccess接口的理解
- 四、Set接口的实现
- 4.1、HashSet、LinkedHashSet、TreeSet
- 4.2、HashSet、LinkedHashSet 、 TreeSet 三者的区别?
- 4.3、HashSet如何检查重复
- 五、Map接口的实现
- 5.1、HashMap、LinkedHashMap、TreeMap、Hashtable
- 5.2、HashMap、LinkedHashMap、TreeMap、Hashtable对比
- 5.3、Map的五种遍历方式
- 六、用Comparator和Comparable进行自定义排序
- 七、Queue、Deque、BlockingQueue接口的实现
- 7.1、Queue 、 Deque、BlockingQueue 接口的区别
- 7.2、LinkedList 、ArrayDeque、PriorityQueue
- 7.3、LinkedList 、ArrayDeque、PriorityQueue对比
- 7.4、BlockingQueue的实现
- 7.5、代码示例
- ArrayDeque、LinkedList、PriorityQueue代码示例:
- BlockingQueue的一些实现类代码示例
- ArrayBlockingQueue 和 LinkedBlockingQueue代码示例:
- PriorityBlockingQueue代码示例:
- DelayQueue代码示例:
- SynchronousQueue代码示例
- LinkedTransferQueue代码示例
- 7.6、利用双端队列实现栈
- 八、常见的线程安全集合
- 九、集合的适用场景总结
集合
集合是Java非常重要的基础知识点。
一、图解集合的继承体系?(图片来源)
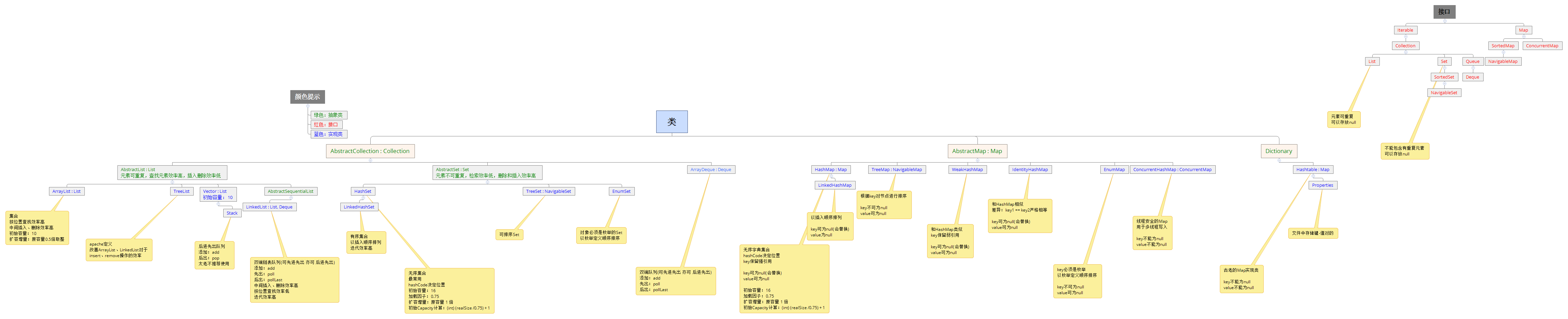
点击查看大图
二、List,Set,Map三者的区别?
List、Set 是用于存放单值集合的接口 ,Map 是用于存放双值(key,value)集合的接口。
- List(存取有顺,可重复): List接口存储一组不唯一且有序的对象(存储的元素允许重复,可以有多个元素引用相同的对象)。可以通过类似于数组的下标快速查找到对 应的值。
- Set(不可重复): 不允许重复的集合。不会有多个元素引用相同的对象。(注意Set只是接口,其实现类HashSet存取无序,LinkedHashSet存取有序,所以不能说Set集合存取无序)
- Map(双值集合,可以用Key来进行高效搜索): 使用键值对存储。Map会维护与Key有关联的值。两个Key可以引用相同的对象,但Key不能重复,典型的Key是String类型,但也可以是任何对象。
三、List接口的实现
3.1、Arraylist 、 LinkedList、Vector
- ①、Arraylist : 底层数据结构是Object 数组,可以存null(不建议存null值,可能出现NPE),线程不安全。
- ②、LinkedList: 底层数据结构是双向链表 ,可以存null(不建议存null值,可能出现NPE),线程不安全。
- ③、Vector :: 底层数据结构是Object 数组,可以存null(不建议存null值,可能出现NPE),线程安全,但是不建议使用,因为对外提供的全部是同步方法(被synchronized修饰),可能出现性能问题。
3.2、Arraylist 、 LinkedList、Vector 三者的区别?
| 特性 | ArrayList | LinkedList | Vector |
|---|---|---|---|
| 底层数据结构 | Object数组 | 双向链表(JDK1.7之前为循环链表,JDK1.7之后取消循环) | Object数组 |
| 插入和删除元素是否受位置影响 | 受影响。尾部插入/删除时间复杂度O(1),指定位置O(n-i) | 不受影响。尾部插入/删除时间复杂度O(1),指定位置O(n) | 受影响。尾部插入/删除时间复杂度O(1),指定位置O(n-i) |
| 内存空间占用 | 结尾预留一定容量空间 | 每个元素需要额外空间存放前驱和后继指针 | 结尾预留一定容量空间 |
| 是否支持快速随机访问 | 支持(实现了RandomAccess接口) | 不支持(需要从头遍历或从尾部遍历) | 支持(实现了RandomAccess接口) |
| 线程安全性 | 线程不安全 | 线程不安全 | 线程安全(public方法使用了synchronized修饰) |
| 性能 | 访问和遍历性能高,随机插入和删除性能受位置影响 | 随机插入和删除性能高,访问和遍历性能低 | 访问和遍历性能高,但由于同步开销性能低于ArrayList |
| 适用场景 | 频繁访问、遍历操作较多,插入、删除操作较少的场景 | 频繁随机插入、删除操作较多,访问、遍历操作较少的场景 | 多线程操作需要保证线程安全的场景 |
| 替代方案 | 如果需要线程安全,可使用CopyOnWriteArrayList | 如果需要线程安全,可使用ConcurrentLinkedDeque | CopyOnWriteArrayList(更好的线程安全集合) |
3.3、对RandomAccess接口的理解
Java 中的 RandomAccess 是一个标记接口(marker interface),它没有任何方法,只是用来标识某个类具备快速随机访问功能。这个接口主要是用在集合框架中的,特别是 List 接口的实现类上。
为什么需要 RandomAccess 接口?
在 Java 的集合框架中,有些集合是可以高效地进行随机访问的,而有些集合只能高效地进行顺序访问。比如:
数组(Array)和 ArrayList:可以通过索引在常数时间内(O(1))访问任意元素,适合随机访问。
链表(LinkedList):需要从头或尾开始遍历,查找某个特定位置的元素需要线性时间(O(n)),不适合随机访问。
JDK中是如何使用RandomAccess 接口的?
JDK 中使用 RandomAccess 接口的主要目的是通过识别集合是否具备快速随机访问能力来优化某些算法的执行。在 JDK 内部,很多方法都会检查传入的 List 是否实现了 RandomAccess 接口,然后根据情况选择最优的访问策略。
例如:
Collections.binarySearch 方法会对有序列表进行二分查找。如果列表实现了 RandomAccess 接口,则直接使用基于索引的二分查找,否则使用基于迭代器的方式。
四、Set接口的实现
4.1、HashSet、LinkedHashSet、TreeSet
-
①、HashSet: 保存的元素无序且唯一。底层是基于 HashMap 实现的,利用 HashMap的key来保存元素。
-
②、LinkedHashSet: 保存的元素有序且唯一。底层是基于 LinkedHashMap 实现的,是HashSet的子类。
-
③、TreeSet: 保存的元素有序且唯一。底层是基于 红黑树(自平衡的排序二叉树)。
注意点:
HashSet、LinkedHashSet 和 TreeSet 都是 Set 接口的实现类,都能保证元素唯一,且是线程不安全的。
4.2、HashSet、LinkedHashSet 、 TreeSet 三者的区别?
| 特性 | HashSet | LinkedHashSet | TreeSet |
|---|---|---|---|
| 存储顺序 | 无序存储 | 按插入顺序存储 | 按自然顺序或比较器顺序存储 |
| 底层实现 | 哈希表(HashMap) | 哈希表(HashMap)+ 双向链表 | 红黑树(TreeMap) |
| 插入/删除/查找复杂度 | O(1) | O(1)(维护链表使性能略低于 HashSet) | O(log n) |
| 唯一性保证方式 | hashCode() 和 equals() | hashCode() 和 equals() | compareTo() 或 Comparator |
| 适用场景 | 高效查找和修改,对顺序无要求 | 保持插入顺序,高效查找和修改 | 需要排序的场景 |
4.3、HashSet如何检查重复
把对象加入HashSet时,HashSet会先计算对象的hashcode值来判断对象加入的位置,同时也会与其他加入的对象的hashcode值作比较,如果没有相符的hashcode,HashSet会假设对象没有重复出现。但是如果发现有相同hashcode值的对象,这时会调用equals()方法来检查hashcode相等的对象是否真的相同。如果两者相同,HashSet就不会让加入操作成功。
hashCode()与equals()的相关规定:
如果两个对象相等,则hashcode一定也是相同的
两个对象相等,equals方法返回true
两个对象有相同的hashcode值,它们也不一定是相等的
综上,equals方法被覆盖过,则hashCode方法也必须被覆盖
hashCode()的默认行为是对堆上的对象产生独特值。如果没有重写hashCode(),则该class的两个对象无论如何都不会相等(即使这两个对象指向相同的数据)。
五、Map接口的实现
5.1、HashMap、LinkedHashMap、TreeMap、Hashtable
- ①、HashMap: 平时使用最多的Map,存储键值对(key,value),不保证插入顺序,同时需要注意 value可能为null。
- ②、LinkedHashMap: 如果需要保证插入的顺序,大部分情况下使用LinkedHashMap,同时需要注意 value可能为null。
- ③、TreeMap: 一般在需要特定的排序规则时使用TreeMap,注意TreeMap不允许 null 键或 null 值。
- ④、Hashtable: 基本上不再使用,如果需要保证线程安全 一般使用ConcurrentHashMap。
5.2、HashMap、LinkedHashMap、TreeMap、Hashtable对比
| 特性 | HashMap | LinkedHashMap | TreeMap | Hashtable |
|---|---|---|---|---|
| 存储顺序 | 无序 | 按插入顺序存储 | 按键的自然顺序或比较器顺序存储 | 无序 |
| 底层实现 | 哈希表(数组 + 链表/红黑树JDK.18) | 哈希表(数组 + 链表/红黑树JDK1.8) + 双向链表 | 红黑树(平衡二叉搜索树) | 哈希表(数组 + 链表) |
| 线程安全性 | 非线程安全 | 非线程安全 | 非线程安全 | 线程安全 |
| 是否允许 null 键值 | 允许一个 null 键和多个 null 值 | 允许一个 null 键和多个 null 值 | 不允许 null 键或 null 值 | 不允许 null 键或 null 值 |
| 性能 | 插入、删除、查找操作时间复杂度为 O(1) | 插入、删除、查找操作时间复杂度为 O(1) | 插入、删除、查找操作时间复杂度为 O(log n) | 插入、删除、查找操作时间复杂度为 O(1) |
| 适用场景 | 高效查找和修改,对顺序无要求 | 保持插入顺序,高效查找和修改 | 需要按键排序的场景 | 需要线程安全,且不关心顺序的场景 (不建议使用,线程安全的Map建议使用ConcurrentHashMap) |
5.3、Map的五种遍历方式
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;public class TestA {public static void main(String[] args) {Map<String, String> map = new HashMap<>();map.put("秀逗","博美");map.put("四眼","哈士奇");map.put("大黄","田园犬");// ========== map遍历方式一: for循环 EntrySetfor (Map.Entry<String, String> entry : map.entrySet()) {String key = entry.getKey();String value = entry.getValue();System.out.println("key: " + key + " value: " + value);}// ========== map遍历方式二: for循环 KeySetfor (String key : map.keySet()) {System.out.println("key: " + key + " value: " + map.get(key));}// ========== map遍历方式三: EntrySet 迭代器Iterator<Map.Entry<String, String>> iterator = map.entrySet().iterator();while (iterator.hasNext()) {Map.Entry<String, String> entry = iterator.next();System.out.println("key: " + entry.getKey() + " value: " + entry.getValue());}// ========== map遍历方式四: KeySet 迭代器Iterator<String> keyIterator = map.keySet().iterator();while (keyIterator.hasNext()) {String key = keyIterator.next();System.out.println("key: " + key + " value: " + map.get(key));}// ========== map遍历方式五: Lambda 表达式 forEach (推荐使用,简单好记)map.forEach((key,value)->{System.out.println("key: " + key + " value: " + value);});}
}推荐使用
map.forEach((key,value)->{// do something
});
六、用Comparator和Comparable进行自定义排序
先看下二者的区别:
| 特性 | Comparable | Comparator |
|---|---|---|
| 所在包 | java.lang | java.util |
| 比较方法 | compareTo(T o) | compare(T o1, T o2) |
| 是否需要修改类 | 需要修改比较的类本身 | 不修改比较的类,通常在外部定义 |
| 适用场景 | 类需要有固定的排序方式时 | 类不修改自身排序逻辑的情况时,使用比较灵活 |
代码示例:
import java.util.ArrayList;
import java.util.Collections;public class TestA {public static void main(String[] args) {ArrayList<Dog> dogs = new ArrayList<>();dogs.add(new Dog("四眼", 4, "吃馒头喝稀饭"));dogs.add(new Dog("秀逗", 8, "吃骨头"));dogs.add(new Dog("大黄", 5, "吃烤鸭屁股"));dogs.add(new Dog("跳跳", 8, "跳"));// 使用 ComparableCollections.sort(dogs);System.out.println(dogs);ArrayList<Dog> dogss = new ArrayList<>();dogss.add(new Dog("哈士奇", 7, "啃沙发"));dogss.add(new Dog("拉布拉多", 8, "拉得多"));dogss.add(new Dog("博美", 5, "吃帝王蟹"));dogss.add(new Dog("泰迪", 5, "蹦迪"));// 使用 Comparatordogss.sort((o1, o2) -> {Integer age1 = o1.getAge();Integer age2 = o2.getAge();if (age1 > age2) {return 1;} else if (age1 < age2) {return -1;}int hobbyL1 = o1.getHobby().length();int hobbyL2 = o2.getHobby().length();if (hobbyL1 > hobbyL2) {return 1;} else if (hobbyL1 < hobbyL2) {return -1;}return 0;});System.out.println(dogss);}
}class Dog implements Comparable<Dog> {private String name;private Integer age;private String hobby;public Dog(String name, Integer age, String hobby) {this.name = name;this.age = age;this.hobby = hobby;}public String getName() {return name;}public void setName(String name) {this.name = name;}public Integer getAge() {return age;}public void setAge(Integer age) {this.age = age;}public String getHobby() {return hobby;}public void setHobby(String hobby) {this.hobby = hobby;}@Overridepublic String toString() {return "Dog{" +"name='" + name + '\'' +", age=" + age +", hobby='" + hobby + '\'' +'}';}@Overridepublic int compareTo(Dog o) {// 先按照年龄正序排序if (this.age > o.getAge()) {return 1;} else if (this.age < o.getAge()) {return -1;}// 再按照hobby属性值的长度正序排序if (this.hobby.length() > o.getHobby().length()) {return 1;} else if (this.hobby.length() < o.getHobby().length()) {return -1;}// 如何前面两种情况都相等 则直接返回相等return 0;}
}
七、Queue、Deque、BlockingQueue接口的实现
7.1、Queue 、 Deque、BlockingQueue 接口的区别
| 特性 | Queue | Deque | BlockingQueue |
|---|---|---|---|
| 定义 | 先进先出(FIFO)的队列 | 双端队列,可以先进先出(FIFO)或后进先出(LIFO) | 支持阻塞操作的队列,用于生产者-消费者模型 |
| 插入元素 | 只能从队尾插入 | 可以从队头和队尾插入 | 只能从队尾插入 |
| 移除元素 | 只能从队头移除 | 可以从队头和队尾移除 | 只能从队头移除 |
| 阻塞操作 | 不支持 | 不支持 | 支持插入和移除时阻塞操作 |
| 常用方法 | add(e), offer(e), remove(), poll(), element(), peek() | addFirst(e), addLast(e), offerFirst(e), offerLast(e), removeFirst(), removeLast(), pollFirst(), pollLast(), getFirst(), getLast(), peekFirst(), peekLast() | put(e), offer(e, timeout, unit), take(), poll(timeout, unit) |
| 常用实现(非线程安全) | LinkedList, PriorityQueue, ArrayDeque | LinkedList, ArrayDeque | |
| 常用实现(线程安全) | ConcurrentLinkedQueue, LinkedBlockingQueue, ArrayBlockingQueue, PriorityBlockingQueue, DelayQueue, SynchronousQueue, LinkedTransferQueue | ConcurrentLinkedDeque, LinkedBlockingDeque | LinkedBlockingQueue, ArrayBlockingQueue, PriorityBlockingQueue, DelayQueue, SynchronousQueue, LinkedTransferQueue |
| 适用场景 | 通常用于简单的FIFO队列实现 | 需要双端插入和删除操作时使用 | 适用于需要阻塞操作的生产者-消费者模型 |
7.2、LinkedList 、ArrayDeque、PriorityQueue
- ①、LinkedList : LinkedList 是基于链表的数据结构,实现了
List和Deque接口,可以用作列表、队列(Queue)和双端队列(Deque)。 - ②、ArrayDeque: ArrayDeque是一个基于数组和双指针的双端队列,提供了可变大小的数组实现(存在动态扩容),支持
Deque接口的所有操作。还可以用于实现栈数据结构。注意:ArrayDeque不允许存null值。 - ③、PriorityQueue : PriorityQueue 是一个基于优先级堆(默认小顶堆)数据结构实现的无界优先级队列,元素按自然顺序或指定的比较器排序。注意:PriorityQueue 不允许存null值。 插入和删除元素的时间复杂度为 O(log n)。比较适合需要维护按优先级顺序处理元素的场景,或者需要动态获取最小(或最大)元素的场景。
7.3、LinkedList 、ArrayDeque、PriorityQueue对比
| 特性 | LinkedList | ArrayDeque | PriorityQueue |
|---|---|---|---|
| 底层数据结构 | 双向链表 | 动态数组 和 双指针 | 优先级堆(最小堆) |
| 实现接口 | List, Deque | Deque | Queue |
| 插入效率 | 对中间元素插入效率高 | 队头和队尾插入效率高 | 插入元素时间复杂度为 O(log n) |
| 删除效率 | 对中间元素删除效率高 | 队头和队尾删除效率高 | 删除最小元素时间复杂度为 O(log n) |
| 随机访问效率 | 效率低,需要从头或尾遍历 | 效率一般,不如 ArrayList | 不支持高效的随机访问 |
| 是否支持双端队列 | 是 | 是 | 否 |
| 元素排序 | 按插入顺序 | 按插入顺序 | 按自然顺序或指定的比较器排序 |
| 常用方法 | add(int index, E element), remove(int index), get(int index), addFirst(E e), addLast(E e), removeFirst(), removeLast() | addFirst(E e), addLast(E e), removeFirst(), removeLast(), peekFirst(), peekLast() | add(E e), offer(E e), remove(), poll(), peek() |
| 线程安全性 | 非线程安全,需要手动同步 | 非线程安全,需要手动同步 | 非线程安全,需要手动同步 |
| 适用场景 | 需要频繁插入和删除操作的场景,或需要使用双端队列功能的场景 | 需要高效队头和队尾插入删除操作的场景,或需要使用双端队列功能的场景 | 需要维护按优先级顺序处理元素的场景,或需要动态获取最小(或最大)元素的场景 |
7.4、BlockingQueue的实现
- ①、ArrayBlockingQueue: 使用线程池时相信大家都用过这个容器,ArrayBlockingQueue是一个基于数组的有界阻塞队列。队列的容量是在创建时指定的。支持公平和非公平锁的访问机制(默认非公平)。
- ②、LinkedBlockingQueue: LinkedBlockingQueue 是一个基于链表的可选有界阻塞队列。如果没有指定容量,则默认大小为
Integer.MAX_VALUE,使用时建议指定大小。仅支持非公平锁访问机制。 - ③、PriorityBlockingQueue: 是一个支持优先级排序的无界阻塞队列。元素按照自然顺序或提供的比较器排序。注意:不能插入 null值,且构造时必须传入比较器Comparator或者保存的元素实现Comparable接口。
- ④、DelayQueue: DelayQueue是一个支持延时获取元素的无界阻塞队列。队列中的元素必须实现
Delayed接口,只有在延迟期满时才能从队列中获取到元素。 - ⑤、SynchronousQueue: 这个队列是一个特殊的阻塞队列,它不存储元素。每个插入操作必须等待另一个线程进行相应的删除操作,反之亦然。所以这个队列通常被用来实现线程之前的同步。
- ⑥、LinkedTransferQueue: 是一个基于链表的无界阻塞队列,提供
TransferQueue接口的实现,在BlockingQueue接口的基础上又封装了一层。与其他阻塞队列相比,LinkedTransferQueue提供了更多的控制选项,尤其是transfer方法,可以实现多个线程之间的直接数据交换。适用于多生产者多消费者场景。
7.5、代码示例
由于Queue、Deque、BlockingQueue接口的实现在实际项目的业务操作中使用的不多,所以记录一下简单的代码使用示例,方便后续查阅。
ArrayDeque、LinkedList、PriorityQueue代码示例:
import java.util.ArrayDeque;
import java.util.LinkedList;
import java.util.PriorityQueue;public class TestA {public static void main(String[] args) {// ============= LinkedList使用示例 ===================LinkedList<Dog> dogs = new LinkedList<>();// 在队尾插入元素dogs.addLast(new Dog("秀逗", 8));dogs.addLast(new Dog("四眼", 6));// 在队头插入元素dogs.addFirst(new Dog("大黄", 4));System.out.println("LinkedList: " + dogs);// 移除队头元素Dog firstDog = dogs.removeFirst();System.out.println("移除队头元素: " + firstDog);// 移除队尾元素Dog lastDog = dogs.removeLast();System.out.println("移除队尾元素: " + lastDog);// 打印队列System.out.println("LinkedList 移除元素后: " + dogs);// ============= ArrayDeque 使用示例 参考LinkedList ===================ArrayDeque<Dog> dogsArrayDeque = new ArrayDeque<Dog>();dogsArrayDeque.addFirst(new Dog("秀逗", 8));dogsArrayDeque.addFirst(new Dog("四眼", 6));dogsArrayDeque.addLast(new Dog("二哈", 3));System.out.println(dogsArrayDeque);// 获取队列头部第一个元素Dog dogFirst = dogsArrayDeque.peekFirst();System.out.println("队列头部第一个元素: " + dogFirst);// 获取队列尾部第一个元素Dog dogLast = dogsArrayDeque.peekLast();System.out.println("获取队列尾部第一个元素: " + dogLast);// 移除队列头部第一个元素 (如果队列为空则返回 null元素)dogsArrayDeque.pollFirst();// 移除队列头部第一个元素 (如果队列为空则 抛出异常 NoSuchElementException)dogsArrayDeque.pop();// ============= PriorityQueue 使用示例 ===================PriorityQueue<Dog> dogsPriorityQueue = new PriorityQueue<>((dog1, dog2) -> {// 按照狗的年龄从小到大排序Integer age1 = dog1.getAge();Integer age2 = dog2.getAge();return age1.compareTo(age2);});// 插入元素 add 方法插入成功 返回true 插入失败 抛异常 IllegalStateException (尤其是有界队列满之后)dogsPriorityQueue.add(new Dog("大哈", 3));dogsPriorityQueue.add(new Dog("二哈", 2));dogsPriorityQueue.add(new Dog("细狗", 5));// 插入元素 offer 方法插入成功 返回true 插入失败返回 false 不会抛异常// 在PriorityQueue无界队列中 实际上 add方法 就是调用的 offer方法dogsPriorityQueue.offer(new Dog("柯基", 4));// 打印队列 注意点: PriorityQueue 的 toString 方法是从 AbstractCollection 类继承的,并没有重写。// 这意味着它直接返回内部数组的内容,而不展示实际的优先级顺序。 实际上展示的是 插入顺序。System.out.println("PriorityQueue: " + dogsPriorityQueue);// 依次移除并打印队头元素while (!dogsPriorityQueue.isEmpty()) {// 每次都是 年龄最小的被移除Dog dog = dogsPriorityQueue.poll();System.out.println("Removed: " + dog);}}
}class Dog {private String name;private Integer age;public Dog(String name, Integer age) {this.name = name;this.age = age;}public String getName() {return name;}public void setName(String name) {this.name = name;}public Integer getAge() {return age;}public void setAge(Integer age) {this.age = age;}@Overridepublic String toString() {return "Dog{" +"name='" + name + '\'' +", age=" + age +'}';}
}BlockingQueue的一些实现类代码示例
ArrayBlockingQueue 和 LinkedBlockingQueue代码示例:
public static void main(String[] args) throws InterruptedException {// ============== ArrayBlockingQueue 和 LinkedBlockingQueue的使用示例 (大致相同)// 创建一个容量为3的ArrayBlockingQueueBlockingQueue<Dog> arrayQueue = new ArrayBlockingQueue<>(3);// ============== 示例1:ArrayBlockingQueue ======================System.out.println("ArrayBlockingQueue 示例:");arrayQueue.put(new Dog("秀逗", 8));arrayQueue.put(new Dog("二哈", 2));arrayQueue.put(new Dog("四眼", 5));// 试图插入第四个元素(将阻塞线程)new Thread(() -> {try {System.out.println("尝试插入第四个元素到已经满的ArrayBlockingQueue...");arrayQueue.put(new Dog("大黄", 4)); // 阻塞直到队列有空闲空间System.out.println("大黄 插入成功");} catch (InterruptedException e) {Thread.currentThread().interrupt();}}).start();// 移除一个元素TimeUnit.SECONDS.sleep(2); // 等待2秒以模拟处理时间System.out.println("从ArrayBlockingQueue中移除第一个元素: " + arrayQueue.take());// 执行结果: // ArrayBlockingQueue 示例://尝试插入第四个元素到已经满的ArrayBlockingQueue...//从ArrayBlockingQueue中移除第一个元素: Dog{name='秀逗', age=8}//大黄 插入成功}
PriorityBlockingQueue代码示例:
public static void main(String[] args) throws InterruptedException {// 创建一个PriorityBlockingQueue,使用自定义的比较器按年龄排序BlockingQueue<Dog> priorityQueue = new PriorityBlockingQueue<>(10, (dog1, dog2) -> {Integer age1 = dog1.getAge();Integer age2 = dog2.getAge();return age1.compareTo(age2);});// 插入元素priorityQueue.put(new Dog("秀逗", 8));priorityQueue.put(new Dog("二哈", 2));priorityQueue.put(new Dog("四眼", 5));priorityQueue.put(new Dog("大黄", 4));// 打印队列内容 注意:PriorityBlockingQueue 重写了 toString 方法,展示了内部元素的优先级顺序(比较器比较后的顺序)。System.out.println("PriorityBlockingQueue: " + priorityQueue);// 依次移除并打印队头元素(按年龄排序)while (!priorityQueue.isEmpty()) {Dog dog = priorityQueue.take();System.out.println("移除: " + dog);}// 试图从空队列中取元素(将阻塞线程)System.out.println("从空的PriorityBlockingQueue中取元素...");new Thread(() -> {try {Dog dog = priorityQueue.take(); // 阻塞直到队列有新元素System.out.println("从PriorityBlockingQueue中取到了元素: " + dog);} catch (InterruptedException e) {Thread.currentThread().interrupt();}}).start();// 插入新元素以解除阻塞TimeUnit.SECONDS.sleep(2); // 等待2秒以模拟处理时间priorityQueue.put(new Dog("巴豆", 1));System.out.println("巴豆加入了PriorityBlockingQueue");// 运行结果 // PriorityBlockingQueue: [Dog{name='二哈', age=2}, Dog{name='大黄', age=4}, Dog{name='四眼', age=5}, Dog{name='秀逗', age=8}]//移除: Dog{name='二哈', age=2}//移除: Dog{name='大黄', age=4}//移除: Dog{name='四眼', age=5}//移除: Dog{name='秀逗', age=8}//从空的PriorityBlockingQueue中取元素...//巴豆加入了PriorityBlockingQueue//从PriorityBlockingQueue中取到了元素: Dog{name='巴豆', age=1}}
注意点:
PriorityBlockingQueue 和 PriorityQueue 均在取出元素时按优先级顺序排列(比较器规则排序),但 toString 方法展示的内容有所不同。 PriorityBlockingQueue 的 toString 展示了排序后的内容,而 PriorityQueue 的 toString 则展示了插入顺序的内容。
PriorityQueue 的 toString 方法是从 AbstractCollection 类继承的,并没有重写。这意味着它直接返回内部数组的内容,而不展示实际的优先级顺序。PriorityBlockingQueue 重写了 toString 方法,展示了内部元素的优先级顺序。
DelayQueue代码示例:
import java.util.concurrent.DelayQueue;
import java.util.concurrent.Delayed;
import java.util.concurrent.TimeUnit;public class TestA {public static void main(String[] args) throws InterruptedException {// 创建一个DelayQueueDelayQueue<DelayedDog> delayQueue = new DelayQueue<>();// 插入元素,设置不同的延迟时间delayQueue.put(new DelayedDog("秀逗", 8000));delayQueue.put(new DelayedDog("四眼", 5000));delayQueue.put(new DelayedDog("二哈", 2000));// 打印队列内容,仅仅是插入顺序System.out.println("DelayQueue: " + delayQueue);// 依次取出元素while (!delayQueue.isEmpty()) {DelayedDog dog = delayQueue.take();System.out.println("Removed from DelayQueue: " + dog);}// 执行结果// DelayQueue: [DelayedDog{name='二哈', delayTime=2000}, DelayedDog{name='秀逗', delayTime=8000}, DelayedDog{name='四眼', delayTime=5000}]//Removed from DelayQueue: DelayedDog{name='二哈', delayTime=2000}//Removed from DelayQueue: DelayedDog{name='四眼', delayTime=5000}//Removed from DelayQueue: DelayedDog{name='秀逗', delayTime=8000}}
}// 实现 Delayed 接口
class DelayedDog implements Delayed {private String name; // 狗的名字private long delayTime; // 延迟时间,以毫秒为单位private long expire; // 到期时间点,以毫秒为单位// 构造方法,传入狗的名字和延迟时间(毫秒)public DelayedDog(String name, long delayTimeInMillis) {this.name = name;this.delayTime = delayTimeInMillis;// 计算到期时间点,当前时间加上延迟时间this.expire = System.currentTimeMillis() + delayTime;}// 获取剩余延迟时间,以给定时间单位表示@Overridepublic long getDelay(TimeUnit unit) {// 计算剩余时间,单位为毫秒long remainingTime = expire - System.currentTimeMillis();// 将剩余时间转换为指定单位return unit.convert(remainingTime, TimeUnit.MILLISECONDS);}// 比较两个 DelayedDog 对象的顺序@Overridepublic int compareTo(Delayed other) {// 强制转换为 DelayedDog 类型DelayedDog otherDog = (DelayedDog) other;// 比较两个对象的到期时间点,返回比较结果return Long.compare(this.expire, otherDog.expire);}// 返回 DelayedDog 对象的字符串表示形式@Overridepublic String toString() {return "DelayedDog{" +"name='" + name + '\'' +", delayTime=" + delayTime +'}';}
}注意点:
getDelay() 方法返回的结果分为三种情况,分别对应着元素的状态:
-
正数:
如果 getDelay() 方法返回的延迟时间是一个正数,表示元素还需要等待一段时间才能被取出。
这意味着元素的延迟时间还没有到达,处于等待状态,调用 take() 或 poll() 方法时会被阻塞,直到延迟时间到达。 -
零:
如果 getDelay() 方法返回的延迟时间是零,表示元素的延迟时间已经到达或者已经过去。
这意味着元素可以被立即取出,调用 take() 或 poll() 方法会立即返回该元素。 -
负数:
如果 getDelay() 方法返回的延迟时间是一个负数,表示元素的延迟时间已经过去,但是元素还没有被取出。
这种情况可能是因为延迟队列中的元素延迟时间被手动修改,导致元素的延迟时间已经过去,但是还没有被取出。
SynchronousQueue代码示例
public static void main(String[] args) {SynchronousQueue<String> queue = new SynchronousQueue<>();// 生产者线程Thread producer = new Thread(() -> {try {String[] items = {"秀逗", "二哈", "四眼"};for (String item : items) {System.out.println("放入队列: " + item);Thread.sleep(2000);queue.put(item); // 阻塞直到有消费者取走该元素}} catch (InterruptedException e) {Thread.currentThread().interrupt();}});// 消费者线程Thread consumer = new Thread(() -> {try {for (int i = 0; i < 3; i++) {String item = queue.take(); // 阻塞直到有生产者放入一个元素System.out.println("拿出消费: " + item);}} catch (InterruptedException e) {Thread.currentThread().interrupt();}});producer.start();consumer.start();try {producer.join();consumer.join();} catch (InterruptedException e) {Thread.currentThread().interrupt();}}
LinkedTransferQueue代码示例
public static void main(String[] args) {TransferQueue<String> queue = new LinkedTransferQueue<>();// 创建生产者线程1 (使用 transfer)Thread producer1 = new Thread(() -> {try {String[] items = {"transfer-1", "transfer-2", "transfer-3"};for (String item : items) {System.out.println("生产者1 生产消息 并 transfer:" + item);queue.transfer(item);System.out.println("生产者1 transfer 完成:" + item);}} catch (InterruptedException e) {Thread.currentThread().interrupt();}});// 创建生产者线程2 (使用 put)Thread producer2 = new Thread(() -> {try {String[] items = {"put-1", "put-2", "put-3"};for (String item : items) {System.out.println("生产者2 生产消息 并 put:" + item);queue.put(item);System.out.println("生产者2 put 完成:" + item);}} catch (InterruptedException e) {Thread.currentThread().interrupt();}});// 创建消费者线程Thread consumer = new Thread(() -> {try {while (true) {Thread.sleep(2000); // 模拟消费者处理消息的延迟String item = queue.take();System.out.println("消费者 消费消息: " + item);}} catch (InterruptedException e) {Thread.currentThread().interrupt();}});// 启动生产者和消费者线程consumer.start();producer1.start();producer2.start();// 等待线程完成try {producer1.join();producer2.join();consumer.join();} catch (InterruptedException e) {Thread.currentThread().interrupt();}}7.6、利用双端队列实现栈
代码示例:
使用LinkedList或者ArrayDeque可以很方便的实现栈的功能。
class StackOne<T> {// // ================ LinkedList实现栈 ===========private LinkedList<T> list;public StackOne() {this.list = new LinkedList<>();}// ================ ArrayDeque实现栈 ===========
// private ArrayDeque<T> list;
// public StackOne() {
// this.list = new ArrayDeque<>();
// }/*** 往栈中添加元素* @param value 元素*/public void push(T value) {list.addFirst(value);}/*** @return 移除栈顶元素*/public T pop() {if (list.isEmpty()) {throw new IllegalStateException("Stack is empty");}return list.removeFirst();}/*** @return 返回栈顶元素*/public T peek() {if (list.isEmpty()) {throw new IllegalStateException("Stack is empty");}return list.peekFirst();}/*** 判断栈是否为空* @return true:空 false:非空*/public boolean isEmpty() {return list.isEmpty();}/*** @return 栈的元素个数*/public int size() {return list.size();}
}
八、常见的线程安全集合
这里先大致留个印象,后面会深入分析比较有代表性的集合实现细节。
| 类型 | 名称 | 适用场景 |
|---|---|---|
| 线程安全的List | CopyOnWriteArrayList | 适用于读多写少的场景[实际上写多的场景用也可以,尾插的时间复杂度是O(1)] |
| 线程安全的Set | CopyOnWriteArraySet | 适用于读多写少的场景 |
| 线程安全的Map | ConcurrentHashMap | 适用于高并发的场景,读操作和部分写操作不需要加锁,性能较好 |
| 线程安全的Queue | LinkedBlockingQueue | 适用于生产者消费者模式,支持阻塞式的生产者消费者通信 |
| ArrayBlockingQueue | 适用于固定容量的阻塞队列,生产者消费者线程间的同步和通信 | |
| ConcurrentLinkedQueue | 适用于高并发的无界队列,非阻塞式的线程安全队列 | |
| PriorityBlockingQueue | 适用于优先级队列,支持按优先级顺序存取元素 |
九、集合的适用场景总结
集合这个模块需要大量的实践,这里只做简单总结
| 类型 | 名称 | 适用场景 |
|---|---|---|
| List | ArrayList | 非线程安全,适用于读多写多,快速随机访问的场景(基本上都是尾插写多的场景用的也很多,用的最多的集合之一 |
| LinkedList | 适用于频繁插入、删除操作的场景(实际上用的很少[我个人很少用],即使是用队列的功能也是ArrayDueue用的多) | |
| CopyOnWriteArrayList | 适用于读多写少的线程安全场景(实际上用尾插,写也很快,除非随机写,但是随机写的场景很少) | |
| Vector | 适用于需要线程安全的场景,别用这个,用CopyOnWriteArrayList代替即可 | |
| Set | HashSet | 适用于快速查找和去重的场景 (快速查找可以理解为 contains方法,用的最多的集合之一) |
| LinkedHashSet | 适用于需要维护插入顺序,且去重的场景 | |
| TreeSet | 适用于需要自定义排序的场景 | |
| CopyOnWriteArraySet | 适用于读多写少的线程安全场景 | |
| Map | HashMap | 适用于快速查找键值对的场景(用的最多的集合之一) |
| LinkedHashMap | 适用于需要维护插入顺序的场景 | |
| TreeMap | 适用于需要排序的键值对的场景 | |
| ConcurrentHashMap | 适用于高并发的场景,读操作和部分写操作不需要加锁,性能较好 | |
| Queue | LinkedList | 非线程安全,适用于实现双端队列或栈的场景 |
| PriorityQueue | 非线程安全,适用于需要优先级排序的场景 | |
| ArrayDeque | 非线程安全,适用于需要双端队列的场景 | |
| LinkedBlockingQueue | 线程安全,适用于生产者消费者模式,支持阻塞式的生产者消费者通信 | |
| ArrayBlockingQueue | 线程安全,适用于固定容量的阻塞队列,生产者消费者线程间的同步和通信 | |
| ConcurrentLinkedQueue | 线程安全,适用于高并发的无界队列,非阻塞式的线程安全队列 | |
| PriorityBlockingQueue | 线程安全,适用于优先级队列,支持按优先级顺序存取元素 | |
| DelayQueue | 线程安全,适用于需要延迟处理的任务,例如定时任务调度(适用于比较简单的延时处理) | |
| SynchronousQueue | 线程安全,适用于不存储元素的场景,生产者必须等待消费者接受元素 |











{kind=link}