文章目录
- 前言
- 一、函数
- 为什么要使用函数?
- 函数定义
- 函数定义和调用
- 定义
- 函数返回值
- 定义空函数
- 函数参数传递
- 传递实参
- 位置实参
- 关键词实参
- 默认值实参
- 等效函数调用
- 实参可选
- 传递任意数量的实参
- 任意数量关键字实参
- 任意参数`*`与`** `的区别
- 使用元组和字典传参
- 如果既有实参又有任意参数会怎么样
- 变量作用域
- 作用域概念
- 局部变量和全局变量
- 修改全局变量
- 匿名函数
- 作为内置函数的参数
- 递归函数
- 什么是方法递归调用
- 可变和不可变类型
- 二、类
- 面向对象与面向过程
- 类和对象相关概念
- 面向对象术语简介
- 实例化对象时候设置属性
- 类初始化时候设置了属性
- 定义构造方法
- 怎么修改实例中的属性
- 私有属性
- 私有方法
- 特殊方法
- 解释为什么调用len(stu)会执行的是__len__()这个方法
- 继承
- 子类可以复用父类的方法
- 子类方法可以覆盖父类方法
- 若子类没有重写_init_(self)
- 实例方法 类方法 静态方法
- 组合、绑定、内建函数
- 组合
- 绑定
- 内建函数
- issubclass()函数
- isinstance函数
- 属性相关函数
- 魔法方法
- `__new__`方法
- `_str_`_ 和 `__repr_` 方法
- 什么是迭代器
- 创建使用迭代器
- 使用iter()方法
- 把一个类作为迭代器
- 把一个对象变成可迭代对象
- 可迭代对象
- 生成器
- 三、模块
- 模块包
- 怎么导入模块
- 导入整个模块
- 导入特定的函数
- 起别名
- 导入模块中所有函数
- 怎么找到对应模块(搜索顺序)
- 如果模块找不到会怎么样
- 总结
前言
Python是一种高级编程语言,以其简洁、易读的语法而闻名。在Python中,函数,类和模块是构建复杂程序的基本构建块。函数可以理解为一段可被多次调用的代码块,类是一种数据结构的抽象,而模块则是一组相关代码的集合。本文将深入探讨Python中函数,类和模块的相关知识,展示它们在开发中的重要性和用途。
一、函数
为什么要使用函数?
计算张三家月净收入,平均月收入为 (爸爸收入+妈妈收入 - 开支)
计算李四家月净收入
zf = 10000 # 张父
zm = 8000 # 张妈
zz = 5000 # 张三
zjsr = zf + zm -zz
print("张三家月净收入为:"+str(zjsr))lf = 12000 # 李父
lm = 7000 # 李母
lz = 6500 # 李四
ljsr = lf + lm -lz
print("李四家净收入为:"+str(ljsr))
函数定义
函数是一段具有特定功能的、可重用的语句组,通过函数名来表示和调用。经过定义,一组语句等价于一个函数,在需要使用这组语句的地方,直接调用函数名称即可。
因此,函数的使用包括两部分:函数的定义和函数的使用
函数是一种功能抽象。
如果在开发程序时,需要某块代码多次,但是为了提供编写的效率以及代码的重用,所以把具有独立功能的代码块组为一个小模块,这就是函数
函数定义和调用
定义
函数名的命名规则要符号python中的命名要求,一般用小写字母和单下划线、数字等组合。函数名一律小写,若有多个单词用下划线隔开。另外,私有函数下划线开头。
def是定义函数的关键词,这个简写来自英文单词define函数名后面是圆括号,括号里面,可以有参数列表,也可以没有参数
千万不要忘记了括号后面的冒号
函数体(语句块)相对于def缩进,按照python习惯,缩进四个空格
'''
定义函数语法形式如下:
def <函数名>(<参数列表>):<函数体>
'''
# 举例如下
def function0():print("python function0") ## 函数定义if __name__ == '__main__':function0() ## 函数调用'''
定义有返回值的函数语法形式如下:
def <函数名>(<参数列表>):<函数体>return 数据
'''def function3(x,y):return x+yif __name__ == '__main__':a = function3(3,1)print(a)
函数返回值
函数并非是直接显示输出,相反,它可以处理一些数据,并返回一个或一组值。函数返回的值被称为返回值
在函数中,可使用return语句将值返回到调用函数的代码行。
返回值让你能够将程序的大部分繁重工作移到函数中去完成,从而简化主程序。
使用return来返回处理后的值。如果return后面的值默认了,就会返回一个None对象。
return语句自身也是可选的。如果它没有出现,那么函数将在控制流程执行完函数体时结束。
事实上,一个没有返回值的函数自动返回了None对象,这个值往往被调用者忽略掉
定义空函数
定义一个什么事也不做的空函数,可以使用pass语句;pass可以用来作为占位符,还没想好怎么写函数的代码,就可以先放一个pass,让代码能运行起来
def funciton2():pass
函数参数传递
形参:当定义函数时,给函数提供的参数,且该参数可以在函数中使用
def 函数名(形参1,形参2): # 定义函数的时候参数就叫形参x = 形参1 # 在函数体内使用形参y = 形参1 + 形参2 # 在函数体内使用向形参
实参:当调用函数时,给函数提供的参数
函数名(实参1,实参2) #调用函数,实现某些功能
当调用函数时,实参的值会按一定的方法赋值给形参
传递实参
鉴于函数定义中可能包含多个形象,因此函数调用中也可能包含多个实参。
向函数传递实参的方式很多:
可使用位置实参,这要求实参的顺序与形参的顺序相同;
可使用关键字实参,其中每个实参都由变量名和值组成
可使用元组和字典
位置实参
调用函数时,Python必须将函数调用中的每个实参都关联到函数定义中的一个形参。为此,最简单的关联方式是基于实参的顺序。这种关联方式被称为位置实参。
def function1(x,y):print("第一个形参值:{},第二个形参值:{}".format(x,y))function1('python','c')
function1('c','python')
关键词实参
如果像上面位置实参调用的时候你传参传过了怎么办?
本来function1('python','c')这么写你写成了function1('c','python')这样程序执行结果会有问题。
如下面程序,你调用时候x,y顺序写错了没关系,最终它是通过关键字x,y去匹配。最终执行结果都一样。
def function2(x,y):print(x,y,seq=' ')
if __name__ == '__main__':function2(x="this is",y="Python") # 这个跟顺序没关系function2(y="Python",x="this is")
默认值实参
写函数时,可给每个形象指定默认值。在调用函数中给形参提供了实参时,Python将使用指定的实参值;否则,将使用形参的默认值。因此,给形参默认值后,可在函数调用中省略相应的实参。使用默认值可简化函数调用,还可清楚地指出函数的典型用法。
'''
def 函数名(形参1,形参2=value): #定义函数代码块
函数名(实参1,实参2) #调用函数
函数名(实参1) #调用函数
'''
# 举例
def myFunciton(name,age,xclass='1班'):print("Name:{} Age:{} Class:{}".format(name,age,xclass))# def myFunction2(name,xclass='1班',age):
# print("Name:{} Age:{} Class:{}".format(name,age,xclass))if __name__ == '__main__':myFunction("zhangsan",13)
使用注意:
使用默认值时,在形参列表中必须先列出没有默认值的形参,在列出有默认值的实参。这让Python依次能够正确地解读位置实参。
使用默认值时,若对默认值没有确定的要求,可以使用None或者’'(空) 来赋值

等效函数调用
鉴于可混合使用位置实参、关键字实参和默认值,通常有多种等效的函数调用方式
我们定义的时候,默认值参数必须放最后,但是时候只要程序能匹配到参数就没问题
def myFunction(name,age,xclass='1班'):print("Name:{} Age:{} Class:{}".format(name,age,xclass))if __name__ == '__main__':myFunction("zhangsan",13)myFunciton(age=11,xclass='1班',age=11)# 关键字参数 跟顺序没有关系myFunction(xclass = '1班','小明',age=11)# 报错。位置参数和关键字参数混合使用的时候,位置参数必须放在关键字参数前面myFunction(name='小明',11,xclass='1班')# 报错,位置参数必须再关键字参数前面# 执行结果为:
# Name:zhangsan Age:13 Class:1班
# Name:xiaoming Age:11 Class:1班
# Name:小明 Age:11 Class:1班
实参可选
有时候需要让实参变成可选的,这样使用函数的人就只需要在必要时才提供额外的信息。可使用默认值来让实参变成可选的。这个实参是提供一个默认参数来实现的。
# 举例
def printData(*myinfo): # *代表可选参数print(myinfo) # 参数名字不带*if __name__ == '__main__':printData("xiaoming",11,"boy","1123@qq.com
")
传递任意数量的实参
有时候,你预先不知道函数需要接受多少个实参,好在Python允许函数从调用语句中收集任意数量的实参。使用(*info)来定义一个形参,形参名info中的星号让Python创建一个名为info的空元组,当调用函数时,将实参中的值封装到这个元组中。
# 举例def myFunction1(name,*info):print(name)for i in info:print("info >> "+str(i))print(type(i))if __name__ == '__main__':myFunction1("xiaoming",11,"boy","1123@qq.com") #
注意
当有固定参数和任意参数的时候,固定参数必须放在任意参数前面,这样的话就好匹配。
任意数量关键字实参
Python中,在定义函数时,不仅可以通过定义函数将未匹配到的位置实参打包成一个元组赋值给一个形参。
同时也可以通过定义函数,将为匹配到的关键字实参打包成一个字典,赋值给一个形参。
# 举例
def myFunction(name,**info): # 两个**的info时一个字典print(name)for i in info:print(i,info.get(i),seq=':')print(type(i))
if __name__ == '__main__':
'''Traceback (most recent call last):File "D:\100-csb-progroup\pygroup\py01\demofunction5.py", line 16, in<module>myFunction("xiaoming", 11,sex ="boy",email = "1123@qq.com")
TypeError: myFunction() takes 1 positional
argument but 2 were given'''
# 说明任意数量参数 不能 位置参数和key参数混合使用myFunction("xiaoming", age = 11,sex"boy",email = "1123@qq.com")'''
执行结果如下:
xiaoming
age:11
sex:boy
email:1123@qq.com
<class 'str'>
'''# 任意参数调用:
myFunction(name='xiaoming',info={'a':1,'b':2})
myFunction(name='xiaoming',a=1,b=2,c=3,d=4)
# a=1,b=2,c=3,d=4 会匹配成一个字段{a=1,b=2,c=3,d=4}传递给**info
'''
执行结果:
xiaoming
info:{'a': 1,
'b': 2}
<class 'str'>
xiaoming
a:1
b:2
c:3
d:4
<class 'str'>
'''
任意参数*与** 的区别
详细分析一下* 跟** 的区别是什么呢?
def foo(*args,**kwargs):print('args = ',args)print('kwargs = ',kwargs)print('-------------------------------------')if __name__ == '__main__':foo(1,2,3,4)foo(a=1,b=2,c=3)foo(1,2,3,4, a=1,b=2,c=3)foo('a', 1, None, a=1, b='2', c=3)foo( a=1, b=2, c=3,1, 2, 3, 4) # 报错,位置参数必须在关键字前面'''
-- 执行结果为:--
args = (1, 2, 3, 4)
kwargs = {}
---------------------------------------
args = ()
kwargs = {'a': 1,'b': 2,'c': 3}
---------------------------------------
args = (1, 2, 3, 4)
kwargs = {'a': 1,'b': 2,'c': 3}
---------------------------------------
args = ('a', 1, None)
kwargs = {'a': 1,'b': '2','c': 3}
---------------------------------------
'''
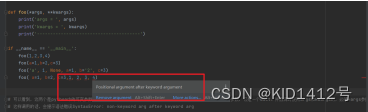
可以看出,这两个是python中的可变参数。args表示任何多个无名参数,它是一个tuple;*kwargs表示关键字参数,它是一个dict。并且同时使用args和kwargs时,必须args参数列要在kwargs前,像foo(a=1, b=‘2’, c=3,a’, 1, None, )
这样调用的话,会提示语法错误SyntaxError: non-keyword arg after keyword arg
如下图所示:
使用元组和字典传参
def foo1(name,* args,** kwargs):print('foo1-->name=',name)print('foo1-->args=',args)print('foo1-->kwargs=',kwargs)'''
执行结果:
foo1-->name= 1
foo1-->args= (2, 3, 4, (5, 6, 7)) # 这里元组也是可变参数作为一个整体传给了args
foo1-->kwargs= {'a': 1,'b': 2,'c': 3,'ee': {'e': 4,'f': 5}}
'''# 如果字典那里没有ke
foo1(1, 2, 3, 4,(5,6,7),{'e':4,'f':5},a=1, b=2, c=3)'''
执行结果:
foo1-->name= 1
foo1-->args= (2, 3, 4, (5, 6, 7), {'e': 4,'f': 5}) # 因为字典钱调用就只有{}没有key所以就当
做位置参数了 ,把元组 集合当作位置参数
foo1-->kwargs= {'a': 1,'b': 2,'c': 3}
'''
如果既有实参又有任意参数会怎么样
def foo(*args,**kwargs):print('foo-->args = ', args)print('foo-->kwargs = ', kwargs)print('---------------------------------------')
def foo1(name,* args,** kwargs):print('foo1-->name=',name)print('foo1-->args=',args)print('foo1-->kwargs=',kwargs)
if __name__ == '__main__':foo(1,2,3,4)foo(a=1,b=2,c=3)foo(1, 2, 3, 4, a=1, b=2, c=3)foo('a', 1, None, a=1, b='2', c=3)foo1( 1, 2, 3, 4,a=1, b=2, c=3)
python匹配的优先级
如果要让函数接受不同类型的实参,必须在函数定义中将接纳任意数量实参的形参放在最后。
Python先匹配实参
位置实参和关键字实参,再将余下的实参都收集到最后一个任意数量实参的形象中(任意数量的位置承参数–>任意数量关键字参数)
变量作用域
作用域概念
变量作用域,变量的可用性范围。通常来说,一段程序代码中所用到的名字不总是有效可用的,而现代这个名字的可用性的代码范围就是这个名字的作用域。作用域的使用,可提高程序逻辑的局部性,增强程序的可靠性,减少名字冲突。
Python中一切与变量名有关的事件,都发生在赋值的时候,Python中的变量名在第一次赋值时才能存在,并且必须经过赋值后才能使用。
根据程序中白能力所在的位置和作用范围,变量分为局部变量和全局变量。
局部变量仅在函数内部,且作用域也在函数内部,全局变量的作用域跨越多个函数。
# 看下段程序
yL = ['a','b','c','d']def foo(*args,**kwargs):xList = [1,2,3,4]print('xList = ',xList)if __name__ == '__main__':print('yList = ',yList)print('xList = ',xList) # 注意,xList定义了会报错'''
分析原因:
xList定义再foo()函数里面所以在main那里看不到而
yList是能够在main看到的。这说明了python中每个变
量都是有作用域的
'''
什么是作用域?
代码中给一个变量赋值的地方决定了这个变量将存在于哪个命名空间。也就是它的可见范围。当你在一个程序中使用变量名时,Python创建、改变或查找变量名都是在所谓的命名空间(变量名存在的地方)中进行。
局部变量和全局变量
根据程序中变量所在的位置和作用范围,变量分为局部变量和全局变量。局部变量仅在函数内部,且作用域也在函数内部。
除了在函数内部定义变量,Python还允许在所有函数的外部定义变量,这样的变量称为全局变量(Global Variable)。局部变量不同,全局变量的默认作用域是整个程序,即全局变量既可以在各个函数的外部使用,也可以在各函数内部使用。
上面例子中xList就是局部白能力,yList就是全局变量
修改全局变量
如果在函数中修改全局变量,那么就需要使用global进行声明。否则出错
如果全局变量的名字和局部变量的名字相同,那么使用的是局部变量的
yList = ['a','b','c','d']
xList = [6,7,8,9]def foo(*args,**kwargs):xList = [1,2,3,4]print('xList =',xList)def foo2(*args,**kwargs):global xListxList = xList+[11]print('xList = ',xList)if __name__ == '__main__':foo()print('---调用foo2---')foo2()'''
执行结果:
xList = [1, 2, 3, 4]
---调用foo2---
xList = [6, 7, 8, 9, 11]
'''
匿名函数
匿名函数指一类无须定义标识符的函数或子程序。
Python用lambda语法定义匿名函数,只需用表达式而无需声明。(省略了用def声明函数的标准步骤)
比如我们lambda定义一个求和的表达式:
sum = lanbda arg1,arg2:arg1+arg2
print('value of total:',sum(10,20))
print('value of total:',sum(20,20))# lambda函数的语法:
lambda [arg1[agr2,......argn]]:expression
# lambda 函数能接收任何数量的参数但只能返回一个表达式的值foo = [2, 18, 9, 22, 17, 24, 8, 12, 27]
x = map(lambda x:x*2 +10,foo)
x
print(list(x))# 更多例子:
a = [1,2,3,4,5]
# 把a集合里的每个数,1 2 3 4 5 都乘以2
b = map(lambda x:x*2,a) #function ,a 迭代list
print(list(b))# reduce使用:
from functools import reduce
y = reduce(lambda x,y:x+y,foo) $ 一定要跑一下
print(y)在对象遍历处理方面,其实Python的for…in…if已经很强大,并且在易读上胜过了lambda。
比如上面map例子,可以写成:
def fun(a,b,myfun=pow): # 参数myfun 对应的一个方法名字"""a,b 参数 myfun函数名"""print('a:{},b:{}'.format(a,b))print('result:{}'.format(myfun(a,b)))# print('result:{}'.format(pow(a,b)))if __name__ == '__main__':fun(5,3,lambda x,y:x+y)print(">>>>>>>>")fun(5,3,lambbda x,y:x*y)'''
这个例子告诉大家python参数可以传函数名字
我们自己定义一个add方法
'''
def add(a,b):return a+b
fun(5,3,add) # 执行结果8发现也可以,但是就是没有lambda表达式方便,因为你要单独定义一个函数
作为内置函数的参数
def fun1(xlist):xnum = len(xlist)for i in range(xnum):if < xnum-1:for j in range(i+1,xnum):if xlist[j][i] < xlist[i][1]:xlist[i],xlist[j] = xlist[j],xlist[i] # a,b = 1,2 这个就是变量的多个赋值def fuc(x):return x[1]if __name__ = '__main__':# 存在一个列表,保存了多个学生的姓名,年龄,学号xlist = [('小明',11,180119),('小红',10,180102),('小军',10,180124),('小王',13,180101)]# 如何通过每个学生的年龄把列表进行排序?fun1(xlist) # 这个地方传递引用print(xlist) # okxlist = [('小明',11,180119),('小红',10,180102),('小军',10,180124),('小王',13,180101)]print('>>>>>>>>>>>')xlist.sort(key=lambda x:x[1])print(xlist)print('>>>>>>>>>>>')xlist = [('小明',11,180119),('小红',10,180102),('小军',10,180124),('小王',13,180101)]xlist.sort(key=fuc)print(xlist)# 这里定义了一个lambda匿名函数作为.sort()内置函数的参数
# 举例2:
# 用来生成美观的ASCII格式的表格的第三方模块
improt prettytable as pt
def show(goods):"""友好的显示商品信息"""# 实例化表格对象table = pt.PrettyTable)_# 表头信息设置table.field_names = ["Name","Count","Price"]# 依次添加每一行信息到表格中;for good in goods:table.add_row(good)print(table)goods = [('Python核心编程',200,70.30),('Java核心编程',20,50.40),('Php核心编程',40,85.15),('Ruby核心编程',100,50.60),
]print("按照商品数量进行排序")
goods.sort(key = lambda x:x[1])
show(goods)print("按照商品价格进行排序")
goods.sort(key=lambda x:x[2])
show(goods)
递归函数
已知:函数可以调用函数。结论:一个函数在内部调用自己本身,这个函数就是递归函数
需求:计算阶乘 factorial: n!=1
*2*3*…*n
# 方法的嵌套调用:
def fun1():print("call fun()1")fun2() # 在一个方法中里面可以调用另外一个方法def fun2():print("call fun()2")if __name__ == '__main__':fun1()
什么是方法递归调用
我们想用代码实现阶乘factorial: n! = 1 * 2 * 3 * ... * n
结论:一个函数在内部调用自己本身,这个函数就是递归函数。
def nfactorial(num):result = 1for item in range(1,num+1):result *= itemreturn result# 5! = 4! *5
# n! = (n-1)! *n
# n!表示为factorial(n):
# 3! = 3*2!
# 2! =2 *1!
# 1! =1def factorial(num):if num == 1: #如果1 1的阶乘就是1return 1else: return num*factorial(num-1)if __name__ == '__main__':print(nfactorial(5))print(factorial(5))
递归原理:
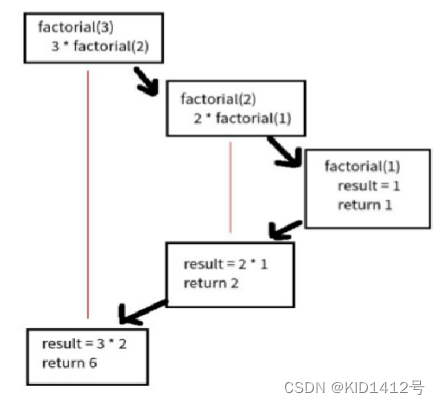
# 对应的代码
def factorial(num):if num >= 1:result = num * factioral(num-1)else:result = 1return resultif __name__ ='__main__':print("2的阶乘:",factorial(2))print("3的阶乘:",factorial(3))print("5的阶乘:",factorial(5))
可变和不可变类型
不可变类型:该对象所指向的内存中的值不能被改变。当改变某个值时候,由于其所指的值不能被改变,相当于把原来的值复制一份后再改变,这会开辟一个新地址,变量再指向这个新的地址。
数值类型(int 和 float)、字符串str、元组tuple都是不可变类型
可变类型:该对象指向的内存中的值可以被改变。变量(准确的说是引用)改变后,实际上是其所指的值直接发生改变,并没有发生复制行为,也没有开辟新的出地址,通俗点说就是原地改变
列表list、字典dict、集合set是可变类型
# 举例 列表是可变类型:
a = [1,2,3]
id(a)a += [4,5,6]
id(a) # 地址跟前面是一样的说明 变量还是原来那个
# 说明a 的内容是可以变的,所以是可变类型# 举例:元组是不可变类型
c = (1,2,3)
id(c)c += (4,5,6)
id(c) # 发现地址变了,只要修改元组的内容会新建一个元组(所以地址变了)。变相说明元组是不可变类型# 再深入一些
def changeList(xList):print("beforechangeListid(xList)",id(xList))xList += [4,5,6]print("after changeListid(xList)",id(xList))def changeYZ(xYZ):print("before changeYZid(xYZ)",id(xYZ))xYZ += (4, 5, 6) # 方法里面新生成一个元组# 这个元组是有xYZ形参指向,实际参数并没有指向print("after changeYZ-id(xYZ)",id(xYZ))if __name__ == '__main__':a = [1,2,3]print(id(a))changeList(a)print(id(a))print('>>>>>>>>>>>>>>>>>>')b = (1, 2, 3)print(id(b))changeYZ(b)print(id(b))'''
执行结果:
10216744
before changeList-id(xList) 10216744 # 跟前
面一样的(python里所有都是对象传的是地址)
after changeList-id(xList) 10216744 # xList
可变对象,所以地址不会变10216744
# 上面4个地址都一样 列表再函数外面和里面一直没有变
化
>>>>>>>>>>>>>>>>>>
# 调用元组
11258088
before changeYZ-id(xYZ) 11258088 # 传地址
after changeYZ-id(xYZ) 11184328 # 变了,原因是元组是不可变类型
# 元组不可变类型,修改新生成了一个元组,新生成一个元组只能函数内部可见
11258088 # 这个跟最开始 的 地址一样,为什么
'''
二、类
面向对象与面向过程
面向过程:面向过程就是分析出解决问题所需要的步骤,然后用函数把这些步骤一步一步实现,使用的时候一个一个依次调用就可以了;根据业务逻辑从上到下写代码,关注在代码。
面向对象:面向对象是把构成问题事务分解成各个对象,建立对象的目的不是为了完成一个步骤,而是为了描述某个事务在整个解决问题的步骤中的行为。
面向对象是一种编程思维,它的关注点在于谁来做
面向对象编程(Object Oriented Programming OOP)
是一种解决软件复用的设计和编程方法。这种方法把软件系统中相近相似的操作逻辑和操作应用数据、状态,以类的形式描述出来,以对象实例的形式在软件系统中复用,以达到提高软件开发效率的作用。
一个例子初步了解面向对象
一个对象有对象成员有函数,比如一个具体老师有名字身高 这些特征,这些再面向对象中可以成为对象属性(也可以成为对象成员)。那么这个老师可以做什么事情呢?比如可以教python那么这个对象就有教python的方法。
# 使用类的简单例子
class Student:height = 180def learnpython(self):print("身高:{}的学生学python".format(self.height))if __name__ == '__main__':stu = Student()stu.learnpython()
Python使用class关键字定义一个类,语法如下:
class 类名:属性1属性2...方法1方法2...
在类中定义方法时,与常规定义函数差不多。区别在于,定义方法时,函数中会存在一个参数,如上所示的self。这也是类的成员函数(方法)与普通函数的主要区别。类的成员函数最前面的参数就代表类的实例(对象)自身,可以使用self引用类的属性和成员函数。
上面例子中如果不加 self就会报错
def learnpython(self):print("身高:{}的学生学python".format(self.height)) # 如果不加self直接写 print("身高:{}的老师教python".format(height))会报错
如果是完成一个班级功能为例,面向对象与面向过程分别怎么实现
面向对象思路就是把构成问题事务分解成各个对象,建立对象的目的不是为了完成一个步骤,而是为了描述某个事务在整个解决问题的步骤中的行为。比如开设一个班级:这里我要让学生学习,我要让老师教。那我找到学生类 student.learnPython()、teacher.teacherPython()就可以这个时候方法具体实现后面再看。
# 面向过程就是:
1. 老师备课
2. 老师上课
3. 学生听课
def preparePython():pass
def lecturePython():pass
def learnPyhon():pass
面向对象是另外一种调用方式,让代码看起啦跟符号人的理解。都是完成一个功能面向对象写起来 燃尽大了更容易组织一些。
类和对象相关概念
类是一种数据结构,可以用它来定义对象,后者把数据值和行为特性融合在一起。
类是现实世界的抽象的实体以编程形式出现。实例是这些对象的具体化。可以类比一下,类是蓝图或者模型,用来产生真实的物体
类和对象是面向对象编程中重要的概念
- 类就是一个模板,模板里面可以包含多个函数,函数里面可以包含多个函数,函数里实现一些功能。
- 对象则是根据模板创建的实例,通过实例对象可以执行类中的函数。
上面例子中我们定义一个Student class 这称为一个
类,刚才我们定义了一个Student 类,一个班很多学生统称为Student。那么具体每个学生就是一个Student类实例。张三同学是Student实例 李四是Student实例。
# 怎么实例化呢?通过调用构造函数,比如下面# Student这是一个类
stu = Student() # 就是实例化了一个具体学生
stu1 = Student(haugnqixian) ## 没给他设置属性
# 班上所有学生都有共性:
# 1. 姓名
# 2. 性别
# 3. 学校
# 4. 年级:大一 大二
# 5. 专业:网络工程 计算机科学与技术
# 6. job :
# 7. 成绩面向对象术语简介
类(Class):用来描述具有相同的属性和方法的对象的集合。它定义了该集合中每个对象所共有的属性和方法。
- 类变量(或属性):类变量在整个实例化的对象中是公用的。类变量定义在类中且在方法之外。类变量通常不作为实例变量使用。类变靠标作属性。
- 数据成员:类变量或者实例变量用于处理类及其实例对象的相关的数据。
方法:类中的定义的函数
- 方法重写:如果从父类继承的方法不能满足子类的需求,如果对其改写,这个方法的覆盖(override),也称为方法的重写。
- 实例变量:定义在方法中的变量,只作用于当前实例的类。
- 多态(Polymorphism):对不同类的对象使用同样的操作。
- 封装(Encapsulation):对外部世界隐藏对象的工作细节。
- 继承(Inheritance):即一个派生类(derivedclass)继承基类(base class)的字段和方法。继承也允许把一个派生类的对象作为一个基类对象对待。以普通的类为基础建立专门的类对象。
- 实例化(Instance):创建一个类的实例,类的具体对象。
对象:通过类定义的数据结构实例。对象包括两个数据成员(类变量和实例变量)和方法。
Python中的类提供了面向对象编程的所有基本功能:类的继承机制允许多个基类,派生类可以覆盖基类中的任何方法,方法中可以调用基类中的同名方法。
对象可以包含任意数量和类型的数据。
实例化对象时候设置属性
类初始化时候设置了属性
class Student: # 类height = 180def learnpython(self): # 类里定义了方法那么就是类的成员方法print('id(self)',id(self))print("身高:{}的学生学python"。format(self.height))if __name__ == '__main__':# 没有定义构造方法,有一个默认的构造器stu = Student() # 实例化 --> 没有起名字stu.learnpython()print('id(stu)',id(stu)) # id是打印内存的地址print('学生身高为:',stu.height)stu = Student()
定义构造方法
但是上面这个学生没有名字,怎么办?我们可以自己定义一个构造方法,怎么定义:
class Student:def learnpython(self):print("身高:{}的学生学python".format(self.height))def __init__(self,name,height): # 特殊方法self.name = name # 注意python中不需要在类声明一个成员变量(而java需要)self.height = heightif __name__ = '__main__':stu = Student('张三',155) # 调用构造函数自动调用init()方法print('stu.name=',stu.name)
怎么修改实例中的属性
方法1:
if __name__ == '__main__':stu = Student('张三',155)print('stu.name=',stu.name)stu.height = 160print('stu.height=',stu.height)
方法2:通过定义一个方法来修改属性:
clss Student:def learnpython(self): # 默认就是public方法print("身高:{}的学生学python".format(self.height))def __init__(self,name,height): # 特殊方法 self是表示对象本身print("init方法被调用了")self.name = name # 注意python中不需要在类中声明一个成员变量(而java是需要的)self.height = heightdef changeHeight(self,height): # self关键字 不用我们输入自动出来的self.height = height;
if __name__ == '__main__':## stu = new Student(); java c++stu = Student('张三',155) ##调用构造函数自动调用init()方法print('stu.name=',stu.name) # 对象的属性被打印了print('stu.height=',stu.height)stu.height = 160 # 对象.属性print('stu.height=', stu.height)stu.changeHeight(180)print('stu.height=',stu.height)'''
上面定义的learnpython是public方法,name、
height是public属性,这跟其他语言不一样的地方,比
如java是要加public关键字猜表示public属性或方法。在
java语言中如果是protected 或者是private 那么就需要
在前面加上protected或private关键字
'''
私有属性
在定义类的时候,常规定义的属性都为公有属性,也是我们能直接通过实例化对象名,属性名去访问的。
在python中,没有关键词来定义私有和公有属性。在变量名或函数名前面加上“__” 两个下划线,那么方法或变量就变成私有的了。但是python,所谓定义私有变量,就是更改其名称 :_类名变量名就可以通过对象名.__类名__变量名,这个方法,直接访问私有变量和函数。
# 私有属性通过 __属性名称定义:
class Student:__age = 0 # 这里是两个下划线 age 是私有属性height = 0def learnpython(self):print("身高:{}的学生学python".format(self.height))def __init__(self,name,height):self.name = nameself.height = heightdef changeHeight(self,height):self.height = heightif __name__ == '__main__':stu = Student('张三', 155)print('stu.name =', stu.name)stu.height = 100print('stu.height=', stu.height)stu.changeHeight(180)print('stu.height=', stu.height)print('stu.__age:', stu.__age) # 私有属性不能通过 对象.属性名 来访问
'''
执行结果
stu.name = 张三
stu.height= 100
stu.height= 180
Traceback (most recent call last):in <module>print('stu.__age:', stu.__age)
AttributeError: 'Student' object has no attribute '__age'
'''
# 如果 要访问私有属性怎么访问;
# 1.通过定义一个公有方法来访问:
class Student:__age = 0 # 这里是两个下划线 age是私有属性height = 0def learnpython(self):print("身高:{}的学生学python".format(self.height)) def __init__(self,name,height):self.name = nameself.height = heightdef changeHeight(self,height):self.height = heightdef getAge(self):# 定义一个公有方法来访问私有成员return self.__ageif __name__ == '__main__':stu = Student('张三', 155)print('stu.name =', stu.name)stu.height = 100print('stu.height=', stu.height)stu.changeHeight(180)print('stu.height=', stu.height)print('stu.__age:', stu.getAge())# 2.可以通过object._className__attrName(对象名._类名__私有属性名) 访问属性print('stu._Student__age:',stu._Student__age)#
私有方法
class Student:__age = 0 # 这里是两个下划线 age 是私有属性height = 0def learnpython(self):print("身高:{}的学生学python".format(self.height))def __init__(self,name,height):self.name = nameself.height = heightdef changeHeight(self,height):self.height = heightdef __learn(self): # 私有方法print("偷偷的学习")if __name__ == '__main__':stu = Student('张三', 155)print('stu.name =', stu.name)stu.__learn() ## AttributeError: 'Student' object has no attribute '__learn'
# 私有方法不能在外面被调用那么用它干嘛:
class Student:__age = 0 # 这里是两个下划线 age 是私有属性height = 0def learnpython(self):print("身高:{}的学生学python".format(self.height))def __init__(self,name,height):self.name = nameself.height = heightdef changeHeight(self,height):self.height = heightdef __learn(self): # 私有方法print("偷偷的学习")if __name__ == '__main__':stu = Student('张三', 155)print('stu.name=', stu.name)stu.learnpython()
特殊方法
上面我们使用__init__是构造方法,在python中两边加了双下划线的就是特殊方法。
python中特殊方法(魔术方法)是被python解释器调用的,我们自己需要调用它们,我们统一使用内置函数来使用。例如:特殊方法**len()**实现后,我们只需要用len()方法即可(调用len()方法会自动调用_len_()); 也有一些特殊方法的调用是隐式的,例如:for i in x:背后其实用的是内置函数iter(x)…
如下图所示就是python的特殊方法一览表:
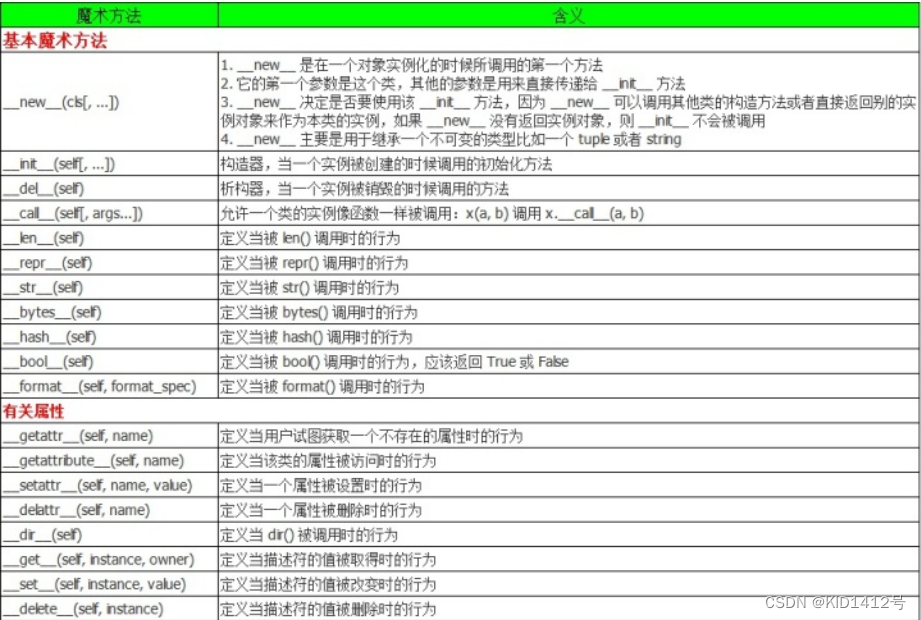


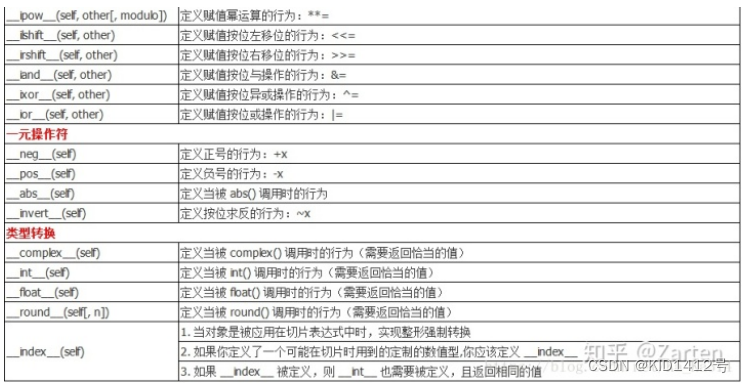
当然有人就会问,如果我自己定义一个方法也是以双下划线开头结尾但是不是上面表中的特殊方法名字那也不能作为特殊方法:
比如下面我定义了一个方法__learn__方法也是以双下划线开头结尾但是大家看到颜色跟__len__就不一样
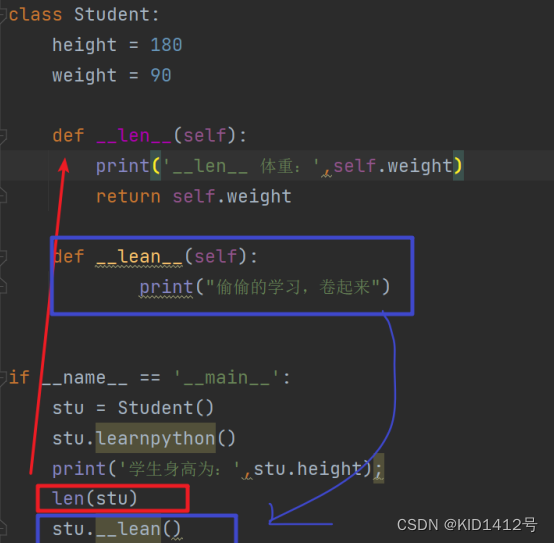
class Student:height = 180weight = 90def __len__(self): # 特殊方法print("__len__ 体重:",self.weight)return self.weightdef __learn__(self): # 也是双下划线开头和结尾 颜色是普通方法的颜色# 不会被python解释器调用print("偷偷的学习,卷起来")if __name__ == '__main__':stu = Student()print('学生身高为:',stu.height)len(stu) # 会不会自动调用__len__方法呢?stu.__learn__() # 只能把它当做普通方法调用,没有被python解释器调用'''
__foo__:定义的是特殊方法,一般是系统定义名字,类似init()之类的。
_foo:以但下划线开发的表示的是protected类型的变量,即保护类型只能允许其本身与子类进行访问,不能用于from module import *
__foo:双下划线的表示的是私有类型(private)的变量,只能是允许这个类本身进行访问了。protected 变量和类型表示只能被当前类或者子类来访
问(子类继承时候会讲)
'''
解释为什么调用len(stu)会执行的是__len__()这个方法
len是内置方法 len(stu1)会自动的去找student类的__len__
如果调用的是stu1+stu2,会自动的去找student类的__add__
# 有同学会问,我自己定义一个
def __m1__(self):print(">>>>m1>>>>")# 那么我可以这么调用嘛?
m1(stu) # 这么写直接会报错的,因为不是特殊方法,特殊方法在前面表里面都定好了
我们只能stu1.m1()这么来调用,把它当作普通函数,普通函数就最好不要带两个下划线,这样就不会混淆。python追求的是简洁。如果不是特殊方法就不要
def __m1__(self):这么来写
继承
我们想象一个场景如果一个学生毕业了那么他会拿到一份工作,所以他除了学校、名称这些还会增加新的特性,比如工作地方city和职位名称。
学生毕业之后变成一个员工 Employee 多了一些员工的属性,但是学生属性还是存在的:
//Student这是一个类
stu = Student() # 就是实例化了一个具体学生
stu1 = Student(haugnqixian) ## 没给他设置属性
# 班上所有学生都有共性:
# 1. 姓名
# 2. 性别
# 3. 学校
# 4. 年级:大四毕业
# 5. 专业:网络工程 计算机科学与技术
# 6. jobtitle 工作职位
# 7. workCity 工作的城市
这个时候如果你定义一个Employee类你不需要从空白开始从新给他新建名称 学校这些属性。从头开始写的代码如下:
class Student:__age = 0 ## 私有变量height = 0def learnpython(self):print("身高:{}的学生学python".format(self.height))# 1. 姓名# 2. 性别# 3. 学校# 4. 年级:大四毕业# 5. 专业:网络工程 计算机科学与技术def __init__(self,name,sex,school,grade,major):self.name = nameself.sex = sexself.school = schoolself.grad = gradeself.major = major# 如果不采用继承的情况
class Employee:# 1. 姓名# 2. 性别# 3. 学校# 4. 年级:大四毕业# 5. 专业:网络工程 计算机科学与技术# 6. jobtitle 工作职位# 7. workCity 工作的城市def __init__(self, name, sex, school,grade, major,jobtitle,workcity):self.name = nameself.sex = sexself.school = schoolself.grad = gradeself.major = majorself.jobtile = jobtitleself.workcity = workcityif __name__ == '__main__':# name,sex,school,grade,majorstu = Student('张三','男','理工大学','大三','网络工程') # 自动调用__init__print('stu.school=',stu.school)emp = Employee('张三','男','理工大学','大三','网络工程','渗透工程师','深圳')print('emp.workcity',emp.workcity)
你可以Employee 继承Student这样Employee就具有Student类的属性和方法。
# 我们来看一下继承怎么定义,先看一个案例:
class Employee(Student):# 1. 姓名# 2. 性别# 3. 学校# 4. 年级:大四毕业# 5. 专业:网络工程 计算机科学与技术# 6. jobtitle 工作职位# 7. workCity 工作的城市def __init__(self, name, sex, school,grade, major, jobtitle, workcity):super().__init__(name, sex, school,grade, major)# self.name = name# self.sex = sex# self.school = school# self.grad = grade# self.major = major# 子类特有的属性单独设置,父类有的属性调用父类的构造方法来初始化# 不用在子类中重新定义 name sex school grade major这些属性self.jobtile = jobtitleself.workcity = workcityif __name__ == '__main__':emp = Employee('张三','男','理工大学','大三','网络工程','渗透工程师','深圳')print('emp.workcity', emp.workcity)
我们来总结一下,编写类时,并非总是要从空白开始。如果你要编写的类是另一个现成类的特殊版本获取说细化版本时获取扩展版本时,可使用继承。一个类继承另一个类时,它将自动获得另一个类时,它将自动获取另一个类的所有属性和方法
Python中的提供了面向对象编程的所有基本功能:类的继承机制允许多个基类,派生类可以覆盖基类中的任何方法,方法中可以调用基类的同名方法。
子类可以复用父类的方法
class Student:__age = 0 ## 私有变量height = 0def learnpyton(self):print("身高:{}的学生学python ".format(self.height))# 1. 姓名# 2. 性别# 3. 学校# 4. 年级:大四毕业# 5. 专业:网络工程 计算机科学与技术def __init__(self, name, sex, school, grade, major):self.name = nameself.sex = sexself.school = schoolself.grad = gradeself.major = major# 如果不采用继承的情况
#class Employee:
class Employee(Student):# 1. 姓名# 2. 性别# 3. 学校# 4. 年级:大四毕业# 5. 专业:网络工程 计算机科学与技术# 6. jobtitle 工作职位# 7. workCity 工作的城市def __init__(self, name, sex, school, grade, major, jobtitle, workcity):super().__init__(name, sex, school, grade, major)# self.name = name# self.sex = sex# self.school = school# self.grad = grade# self.major = major# 子类特有的属性单独设置,父类有的属性调用父类的构造方法来初始化# 不用在子类中重新定义 name sex school grade major这些属性self.jobtile = jobtitleself.workcity = workcityif __name__ == '__main__':emp = Employee('张三','男','理工大学','大三','网络工程','渗透工程师','深圳')print('emp.workcity', emp.workcity) emp.learnpython() # 我没有在Employee里定义learnpython方法他可以直接调用因为继承了父类Student的
子类方法可以覆盖父类方法
接着上面例子,我们在Employee方法中执行
learnPython不应该 执行学生的方法(以前方法过时了)
class Student:__age = 0 ## 私有变量height = 0def learnpyton(self):print("身高:{}的学生学python ".format(self.height))# 1. 姓名# 2. 性别# 3. 学校# 4. 年级:大四毕业# 5. 专业:网络工程 计算机科学与技术def __init__(self, name, sex, school, grade, major):self.name = nameself.sex = sexself.school = schoolself.grad = gradeself.major = major# 如果不采用继承的情况
#class Employee:
class Employee(Student):# 1. 姓名# 2. 性别# 3. 学校# 4. 年级:大四毕业# 5. 专业:网络工程 计算机科学与技术# 6. jobtitle 工作职位# 7. workCity 工作的城市def __init__(self, name, sex, school, grade, major, jobtitle, workcity):super().__init__(name, sex, school, grade, major)# self.name = name# self.sex = sex# self.school = school# self.grad = grade# self.major = major# 子类特有的属性单独设置,父类有的属性调用父类的构造方法来初始化# 不用在子类中重新定义 name sex school grade major这些属性self.jobtile = jobtitleself.workcity = workcity# 子类中定义跟父类方法一样名字的方法会覆盖父类的方法def learnpython(self):print('工作之后员工重新开始学习python,查漏补缺的方式来学习')if __name__ == '__main__':emp = Employee('张三','男','理工大学','大三','网络工程','渗透工程师','深圳')print('emp.workcity', emp.workcity)emp.learnpython() # 我没有在Employee里定义learnpython方法他可以直接调用因为继承了父类Student的执行结果:
子类init()对属性进行复制,同样可以调用父类的init()的方法,减少子类init()中的操作

若子类没有重写_init_(self)
当子类继承父类的属性和方法后,若子类没有重写
init(self) 这个构造方法时, 实例化一个子类,父类的_init_(self)会自动执行
class Student:__age = 0 ## 私有变量height = 0def learnpyton(self):print("身高:{}的学生学python ".format(self.height))# 1. 姓名# 2. 性别# 3. 学校# 4. 年级:大四毕业# 5. 专业:网络工程 计算机科学与技术def __init__(self, name, sex, school, grade, major):self.name = nameself.sex = sexself.school = schoolself.grad = gradeself.major = major# 如果不采用继承的情况
# class Employee:
class Employee(Student):# 1. 姓名# 2. 性别# 3. 学校# 4. 年级:大四毕业# 5. 专业:网络工程 计算机科学与技术# 6. jobtitle 工作职位# 7. workCity 工作的城市def __init__(self, name, sex, school, grade, major, jobtitle, workcity):super().__init__(name, sex, school, grade, major)# self.name = name# self.sex = sex# self.school = school# self.grad = grade# self.major = major# 子类特有的属性单独设置,父类有的属性调用父类的构造方法来初始化# 不用在子类中重新定义 name sex school grade major这些属性self.jobtile = jobtitleself.workcity = workcity# 子类中定义跟父类方法一样名字的方法会覆盖父类的方法def learnpython(self):print('工作之后员工重新开始学习python,查漏补缺的方式来学习')if __name__ == '__main__':# 如果子类没有自己定义__init__方法会自动调用父类Student初始化方法__init__emp = Employee('张三', '男', '理工大学', '大三', '网络工程', '渗透工程师', '深圳')emp.learnpython() # 我没有在Employee里定义learnpython方法他可以直接调用因为继承了父类Student的如果父类跟子类都写了__init__方法那么 子类
Employee的init方法就会把父类init方法覆盖,想要调用父类init方法需要用super调用
super().init()有什么作用?
super()用来调用父类(基类)的方法,init()是类
的构造方法
super().init() 就是调用父类的init方法, 同
样可以使用super()去调用父类的其他方法。
有人可能会误解“覆盖”的意思,认为“覆盖”了就是没有,为什么还能通过super调用?
覆盖了并不是没有了,Student的方法终都还在,但需要在Employee内部用super调用。
super().init()就是调用父类的init方法同样也可以使用父类名._init_()方法去调用,他们区别是由于python是多继承使用使用super得话不知道是哪个父类这个使用可以使用父类名._init_,不过父类名._init_调用得时候第一个参数记得self,如下图所示:
class Student:school = ''name = ''def __len__(self):print('__len__ 体重:',self.weight)return self.weightdef __lean__(self):print("偷偷的学习,卷起来")def __init__(self, name, school):self.school = schoolself.name = nameprint('调用Student类构造方法_init__(self, name, school): ')def eat(self):print("学生在食堂吃饭")class Employee(Student):job = ''def __init__(self, job):self.job = job# self.nameprint('调用Employee类构造方法__init__(self, job)')# def __init__(self,job,name,school):# self.job = job# # self.name# self.name = name# self.school = school# print('调用Employee类构造方法 __init__(self, job, name, school) ')def __init__(self, job, name, school):# super().__init__(name,school)Student.__init__(self, name, school)self.job = jobprint('调用Employee类构造方法__init__(self, job, name, school)')def eat(self):print('员工在外面小店吃饭')
实例方法 类方法 静态方法
实例方法,前面例子中定义在类中没有加
@staticMethod 和@classMethod 都是实例方法绑定到对象上的方法
定义:第一个参数必须是实例对象,该参数名一般约定为“self”,通过它来传递实例的属性和方法(月可以传类的属性和方法):
调用:只能由实例对象调用。
类方法:类方法不是绑定到对象上,而是绑定在类上的方法。
定义:使用装饰器@classmethod。第一个参数必须是当前对象A,该参数名一般约定为“cls”,通过它来传递类的属性和方法(不能传实例的属性和方法)
调用:类和实例对象都可以调用。
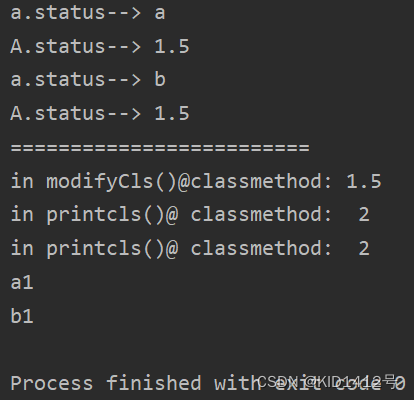
class A():def __init__(self):self.status = 1# passstatus = 1.5@classmethod # 类方法def modifyCls(cls): # 对象方法自带 self,类方法是clsprint("in modifyCls()@classmethod:", cls.status)cls.status = 2 # 这里不能有实例属性和方法,访问cls的属性# 修改的是 A.staus@classmethod # 类方法def printcls(cls):print('in printcls()@ classmethod: ', cls.status)def e(self):w = A.statusself.d()self.c()if __name__ == '__main__':a = A()a.status = 'a'print('a.status-->', a.status) # a对象的statusprint('A.status-->', A.status)b = A()b.status = 'b'print('a.status-->', b.status) # a对象的statusprint('A.status-->', A.status)print('=========================')a.modifyCls() # 这个类方法,修改的是类的status# 可以通过a.b()调用 也可以通过A.b()a.printcls() # 类的statusb.printcls() # 类的statusa.status = 'a1'b.status = 'b1'print(a.status) # a1 a对象的statusprint(b.status) # b1 b对象的status
执行结果:
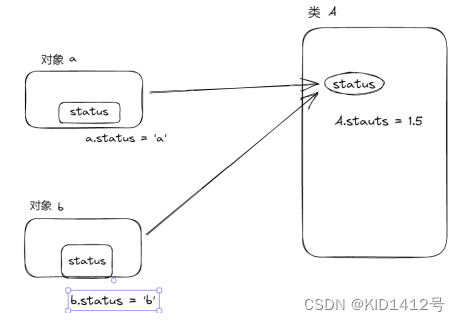
可以通过下面的图理解对象属性跟类属性的区别:
定义:使用装饰器@staticmethod。参数随意,没有“self”和“cls”参数,可以通过类名访问类的属性和方法但是不能访问实例的属性和方法因为没有对象引用(没有self)
调用:类和实例对象都可以调用。
在static方法中输入对象成员pycharm都不会提示
class A():def __init__(self):self.status = 1# passstatus = 1.5@classmethoddef clsmethod(cls):print("in b() @classmethod:cm()")# 实例方法def objMethod(self): # 对象方法w = A.statusself.d()self.c()@staticmethoddef staticmethod(): # 不能修改类属性 也不能修改对象属性print("in staticmethod ")# print("in staticmethod d",status)# 会报错print("in staticmethod A.status--> ",A.status)A.status = 'statis A'# 不能写 cls.status 也不能self.status不能修改对象属性也不能修改类属性# 但是可以通过 类名.方法 没有cls不能通过cls.方法来调用A.clsmethod()if __name__ == '__main__':a = A()print('================================')print(a.status)print(A.status)print('>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>')A.status +=6A.staticmethod();# print(A.d())print('oooooooooooooooooooooooo')
组合、绑定、内建函数
组合
组合:定义一个类,类中实例化其它类,即一个类中的成员是其它的类。
# 举例
class Student:def __init__(self,stuNums):self.stuNums = stuNums
class Teacher:def __init__(self,teaNums):self.teaNums = teaNumsclass Classroom:def __init__(self,stuNums,teaNUms):self.student = Student(stuNums)self.teacher = Teacher(teaNUms)def xprint(self):print('教室有{}个老师,{}个学生'.format(self.teacher.teaNums,self.student.stuNums))if __name__ == '__main__':a = Classroom(1,40)a.xprint()
绑定
绑定的概念,主要与方法调用相关联。
一、绑定方法(绑定给谁,谁来调用就自动将它本身当作第一个参数传入):
- 绑定到类的方法:用classmethod装饰器装饰的方法为类量身定制
- 类.boud_method(),自动将类当作第一个参数传入(其实对象也可调用,但仍将类当作第一个参数传入)
- 绑定到对象的方法:没有被任何装饰器装饰的方法为对象量身定制
- 对象.boud_method() 自动将对象 self参数 当作第一个参数传入
二、非绑定方法:用staticmethod装饰器装饰的方法
- 不与类或对象绑定,类和对象都可以调用,但是没有自动传值那么一说通过staticmethod修饰就是一个普通工具而已
内建函数
issubclass()函数
issubclass(class,classinfo):返回一个布尔值,判断一个类是另外一个类的子类或者子孙类。该函数也允许“不严格”的子类
class X:pass
class Y:pass
class Z(X):pass
a = (X,Y,Z)
issubclass(Z,a) # 第二参数可以是父类组成的元组(tuple),只要第一个参数为元素中任意一个类的子类,则返回Trueissubclass(Z,X)
isinstance函数
isinstance(obj1,classinfo):返回一个布尔值,判断一个对象是否是另一个给定类的实例。
x1 = X()
isinstance(x1,X)# 对于基本数据类型也可以这么来演示:
isinstance(1,int) # 所有类型都是对象
isinstance(1,str)
isinstance('1',str)
属性相关函数
hasattr(object,name):用来判断某个属性是否术语一个对象,是返回True,不是返回False
getattr(object,name[,default]):用来获取对象中某个属性值不存在返回依次。第三个参数可选,当属性不在对象中时输出第三个参数的内容。
class A:def __init__(self,x):self.x =x # python中不需要在class中声明一个成员变量if __name__ == '__main__':b = A(1)print(hasattr(b,'x')) ## 注意hasattr是一个对象print(getattr(b,'x','查看属性y'))print(getattr(b,'y','查看属性y'))
魔法方法
__new__方法
new方法是传入类(cls),该方法是实例化对象第一个被调用的魔法方法
init方法传入类的实例化对象(self),该方法是实例化对象后第二个被调用的魔法方法
new方法如果未返回一个 cls 的实例,则新实例的 **init()**方法就不会被执行
对象是由 new() 和 init() 协作构造完成的 (由 new() 创建,并由 init() 定制),所以 init() 返回的值只能是None
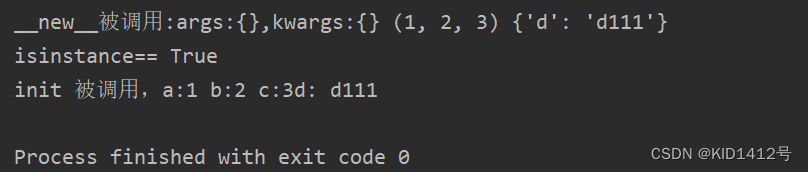
class NewInitA:def __new__ (cls,*args,**kwargs):print('__new__被调用:args:{},kwargs:{}',args,kwargs)a = super().__new__(cls)print('isinstance==',isinstance(a,NewInitA))# return a # 这里注释了,下面的__init__就没有被调用,请查看执行结果def __init__(self, a, b, c, d=0):self.a = aself.b = bprint('init 被调用,a:{} b:{}', a, b)if __name__ == '__main__':b = NewInitA(1,2,3,d='d111')
执行结果:

我们让_new_有返回值呢?看看结果如何
class NewInitA:def __new__ (cls,*args,**kwargs):# 隐含参数是clsprint('__new__被调用:args:{},kwargs:{}',args,kwargs)a = super().__new__(cls)print('isinstance==', isinstance(a, NewInitA))return adef __init__(self, a, b, c, d=0): # 隐含参数是self不是cls# self 意味着 对象已经生成,只不过这里给成员进行赋值罢了self.a = aself.b = bself.c = cself.d = dprint('init 被调用,a:{} b:{} c:{}d: {}'.format(a,b,c,d))if __name__ == '__main__':b = NewInitA(1,2,3,d='d111')执行结果:
_new_()的目的主要是允许不可变类型的子类(例如 int,str或tuple)定制实例创建过程。它也常会在自定义元类中被重载以便定制类创建过程。
class UpperStr(str):def __new__(cls,string1):string1 = string1.upper() # 全部变成大写return str.__new__(cls,string1) # 调用父类的__new__if __name__ == '__main__':# 先调用 __new__然后调用__init__x = UpperStr('xyz')print('x=',x)
执行结果:
x= XYZ
这个定制通过_init_ 是定制不了的,我们看下面代码:
class UpperStr(str):# def __new__(cls,*args,**kwargs):# def __new__(cls,string1):# string1 = string1.upper()# return str.__new__(cls,string1)# def __init__(self):def __init__(self,string1):super().__init__(string1.upper())returnif __name__ == '__main__':x = UpperStr('xyz')print('x=',x)
执行结果:

我们点进方法声明看到只有一个参数:
_str__ 和 __repr_ 方法
__str__是一个内置的方法,无需使用者去调用,其会在满足某一条件时自动触发,什么时候会触发呢?当调用print,str,%s就会被触发
class M:def __init__(self,x,y):self.x = xself.y = ydef __str__(self):return 'in __str__x:{},x:{}'.format(self.x,self.y)# def __repr__(self):# return 'in __repr__ x:{},x:{} '.format(self.x,self.y)if __name__ == '__main__':a = M(1,2)print(a)
执行结果:
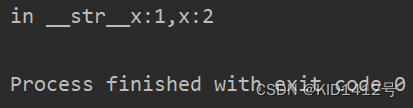
__repr__方法
被触发的条件为:有以下条件,分别为:print,str,%s,repr,%r
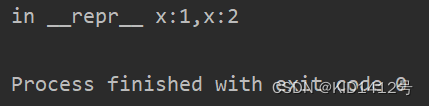
class M:def __init__(self,x,y):self.x = xself.y = y# def __str__(self):# return 'in __str__x:{},x:{}'.format(self.x,self.y)def __repr__(self):return 'in __repr__ x:{},x:{} '.format(self.x,self.y)if __name__ == '__main__':a = M(1,2)print(a)
执行结果:
__sub__
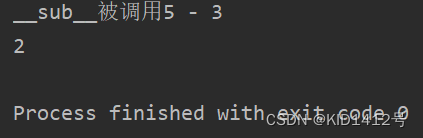
**sub(self,other)**当调用 - 时,自动触发该方法
class M:def __init__(self,x,y):self.x = xself.y = y# def __str__(self):# return 'in __str__x:{},x:{}'.format(self.x,self.y)def __repr__(self):return 'in __repr__ x:{},x:{} '.format(self.x,self.y)def __sub__(self, other):print('__sub__被调用{} - {}'.format(self.x, other.x))return int.__sub__(self.x, other.x)if __name__ == '__main__':a = M(5, 2)b = M(3, 2)print(a-b)
执行结果:
什么是迭代器
迭代器就是用于迭代操作(for循环)对象,它像列表一样可以迭代获取其中的每个元素,任何实现了next方法 (python2 是 next)的对象都可以称为迭代器。
它与列表的区别在于,构建迭代器的时候,不像列表把所有元素一次性加载到内存,而是以一种延迟计算(lazy evaluation)方式返回元素,这正是它的优点。
比如列表含有一千万个整数,需要占超过400M的内存,而迭代器只需要几十个字节空间。因为它并没有把所有元素装载到内存中,而是等到调用next方法时候才返回该运算(按需调用call by need的方式,本质上for循环就是不断地嗲要迭代器的next方法)。
迭代是Python最强大的功能之一,是访问集合元素的一种方式。它是一个可以记住遍历的位置的对象。
迭代器对象从集合的第一个元素开始访问,直到所有元素被访问完结束。迭代器只能往前不会后退。
迭代器有两个基本的方法:iter()和next()
创建使用迭代器
使用iter()方法
list=[1,2,3,4]
it = iter(list) # 创建迭代器对象
print (next(it)) # 输出迭代器的下一个元素
print (next(it))
迭代器可以用常规for循环遍历:
list=[1,2,3,4]
it = iter(list) # 创建迭代器对象
for x in it:print(x,end=" ")
其实for循环底层就是用的迭代器
list=[1,2,3,4]
it = iter(list)
next(it)
next(it)
for x in it:print (x, end=" ") # 如果里面不是用的迭代器,应该是从1开始输出
上面for循环也可以使用next
import sys # 引入sys模块
list=[1,2,3,4]
it = iter(list) # 创建迭代器对象
while True:try:print(next(it)) ## 看到这里next()嘛?不需要写list[i]这样,因为迭代器记住了位置,如果用while循环那么就需要i的,这个跟for循环效果一样。except StopIteration:sys.exit()
把一个类作为迭代器
把一个类作为一个迭代器使用需要在类中实现两个方法iter()与next()。
如果你已经了解的面向对象编程,就知道类都有一个构造函数,Python的构造函数为init(),它会在对象初始化的时候执行。
iter() 方法返回一个特殊的迭代器对象,这个迭代器对象实现了**next()**方法并通过Stoplteration 异常标识迭代的完成。
**next()**方法(Python 2 里是 next())会返回下一个迭代器对象。
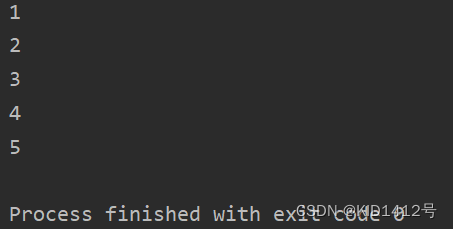
class MyNumbers:def __iter__(self):self.a = 1return selfdef __next__(self): # 调用next()方法会自动嗲要这个方法x = self.aself.a += 1 # a 会自增return xmyclass = MyNumbers()
myiter = iter(myclass)print(next(myiter))
print(next(myiter))
print(next(myiter))
print(next(myiter))
print(next(myiter))
执行结果:
把一个对象变成可迭代对象
a = 'python'
type(a)
myIter = iter(a)## __iter()__
myIternext(myIter)
next(myIter)
next(myIter)
next(myIter)
next(myIter)
next(myIter)
next(myIter)
可迭代对象
可以直接作为for循环对象:
- 一类是集合数据类型,如list,tuple,dict,set,str(字符串)等 和实现了next()方法的对象
- 一类是迭代器 generator,包括生成器和带yield的generator function 迭代器。
生成器
在 Python 中,使用了 yield 的函数被称为生成器
(generator)。
跟普通函数不同的是,生成器是一个返回迭代器的函
数,只能用于迭代操作,更简单点理解生成器就是一个迭代器。
在调用生成器允许的过程中,每次遇到yield时函数会暂时并保存当前所有的运行新,返回yield的值,并在下一次执行next()方法时从当前位置继续运行。
调用一个生成器函数,返回的时一个迭代器对象。
import sysdef fibonacci(n): # 生成器函数 - 斐波那契a,b,counter = 0,1,0while True:if (counter>n):returnyield aa,b = b,a+bcounter += 1f = fibonacci(10)# f是一个迭代器,由生成器返回生成while True:try:print(next(f),end=" ")except StopIteration:sys.exit()
执行结果:

模拟调用生成器运行过程中遇到yield会暂停并保存当前运行的信息:
import sys
# from democlassinherited import Student
def fibonacci(n): # 生成器函数 - 斐波那契a,b,counter = 0,1,0while True:if (counter > n):returnprint('准备yield a:{}'.format(a))yield a # 函数会停止 使用yield返回的就是生成器print('计算下一个值:a:{} b:{}'.format(a,b))a,b = b,a+bcounter += 1f = fibonacci(10)# f是一个迭代器,由生成器返回生成while True:count = input('pls input count:') # next(f)try:# eval(next(f))# 没调用一次next就会 接着迭代输出下一个数print('第{}:in while true'.format(count), end="\r\n")next(f)# print('in while true:{}'.format(eval(xtr)), end="\r\n")except StopIteration:sys.exit()
执行结果:

三、模块
函数可以将代码进行分块并且重用。通过给函数知道描述性名称,可让程序容易理解得多。
我们还可以更进一步,将函数存储在称为模块(module)的独立文件中,再将模块导入到主程序中。
比如数学函数、文件读写函数等等,将函数存储在独立文件中后,可以自己在众多不同的程度中重用函数,可与其它程序员共享这些文件重用函数,还可以让我们使用其它程序员编写的函数库。
模块就是工具包,要想使用这个工具包的工具(就好比函数),就需要导入这个模块。
模块是非常简单的Python文件(.py),单个Python文件就是一个模块,两个文件就是两个模块。
模块包
模块是非常简单的Python文件,单个Python文件就是一个模块。
模块就是工具包,要想使用这个工具包的工具(比如函数)就需要导入这个模块。
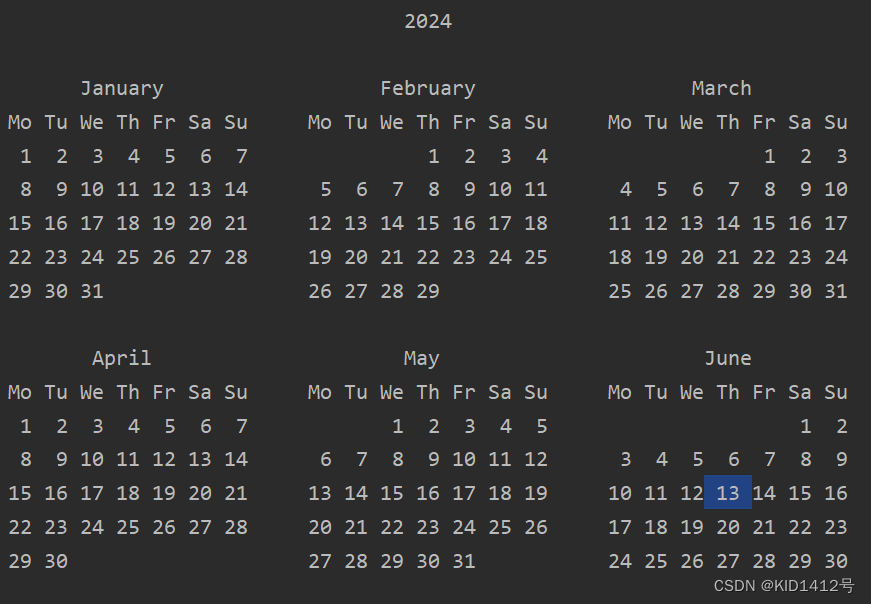
一个简单例子:我们想判断某一年是否闰年,我们不想自己写代码直接用别人写好的模块怎么办?
import calendar # 我们先要导入模块
calendar.isleap(2000)
cal = calendar.calendar(2024, l=0, c=5)
print(cal)
怎么导入模块
import 模块名1,就是导入了这个模块名1 下面的函数和变量
# 如果要导入同级目录下的模块
from ..chapter3.demofunction0 import
function3 ## ..chapter3 父级目录下chapter3 package
导入整个模块
导入整个模块: import 模块名
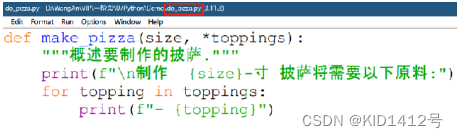

在do_pizza.py所在的目录中创建一个名为pizzas.py的文件。这个文件导入刚创建的模块do_pizza ,再调用do_pizza 模块中make_pizza() 两次
在pizzas.py中,可使用pizza.py中定义的所有函数。要调用被导入模块中的函数,可指定被导入模块的名称do_pizza 和函数名make_pizza() ,并用句点分隔
导入特定的函数
from 模块名 import 函数名1,函数名2,………
使用这种语法时,调用函数时直接写函数名即可

起别名
使用as 给函数指定别名
from 模块名 import 函数名 as 函数别名

如果要导入函数的名称可能与程序中现有的名称冲突,或者函数的名称太长,可指定简短而独一无二的别名:函数的另一个名称,类似于外号。
上面的代码将函数make_pizza()重命名为mp()。在这个程序中,每当需要调用make_pizza() 时,都可简写成mp()
使用as 给模块指定别名
Import 模块名 as 模块别名

通过给模块指定简短的别名(如给模块do_pizza 指定别名dp),能够更轻松地调用模块中的函数
导入模块中所有函数
from 模块名 import *

使用星号(*)运算符可让Python导入模块中的所有函数,由于导入了每个函数,可通过名称来调用每个函数,而无需使用句点表示法。
然而,使用并非自己编写的大型模块时,最好不要采用这种导入方法。这是因为如果模块中由函数的名称与当前项目中使用的名称相同,可能导致意想不到的结果。
最佳的做法是,要么只导入需要使用的函数,要么导入整个模块并使用句点表示法。这让代码更清晰,更容易阅读和理解,程序运行更不容易出错。
怎么找到对应模块(搜索顺序)
有时候,Python项目比较大,模块文件分布在不同路径下,要导入一个模块时,Python需要对模块文件进行搜索,搜索的顺序是:
导入一个模块,Python解析器对模块位置的搜索顺序是:
- 当前目录
- 如果不在当前目录,Python则搜索在shell变量
PYTHONPATH下的每个目录。- 如果都找不到Python会察看默认路径。
- 模块搜索路径存储在system模块的sys.path变量中。
# 打印sys.path查看一下:
if __name__ == '__main__':print(sys.path)## 执行结果:前两个是当前python文件所在目录,和工程文件对应的模块,python就按照这样顺序去搜索的
如果模块找不到会怎么样
如果搜索不到会怎么样?,比如我们将上面的
do_pizza.py移动到其他目录,再执行pizzas.py
总结
本文涵盖了Python中函数,类和模块的相关知识。首先,我们介绍了函数的概念和用法,解释了如何定义函数、传递参数、调用和返回值。接下来,我们讨论了类的概念,并详细介绍了如何定义类、创建对象和使用类的方法和属性。最后,我们探讨了模块的作用和用法,解释了如何导入和使用模块,以及如何在自己的程序中创建和使用模块。
通过本文,读者可以深入了解Python中函数,类和模块的使用方法,掌握它们在编程中的重要性和实际应用。无论是初学者还是有一定经验的开发者,都可以从本文中获得对Python编程更深入的理解,提升自己的编程能力。在今后的学习和开发中,读者可以借助函数,类和模块这些强大的工具,更高效地编写代码,实现自己的程序目标。