1.Redis数据丢失场景
1.1 持久化丢失
采用RDB或者不持久化,就会有数据丢失,因为是手动或者配置以快照的形式来进行备份。
解决: 启用AOF,以命令追加的形式进行备份,但是默认也会有1s丢失,这是在性能与数据安全性中寻求的一个最适合的方案,如果为了保证数据一致性,可以将配置更改为always,但是性能很慢,一般不用。
# appendfsync always
1.2主从切换
因为Redis的数据是主异步同步给从的,提升了性能,但是由于是异步同步到从。所以存在数据丢失的可能。
1.master 写入数据 k1 , 由于 是异步同步到 slave ,当 master 没有同步给slave的时候, master 挂了2.slave 会成为新的 master ,并且没有同步 k1 ,3.master 重启,会成为新 master 的 slave ,同步数据会清空自己的数据,从新的master 加载4.k1 丢失
1.3 sentinel脑裂
a.假如有个sentinel集群跟redis集群,如图
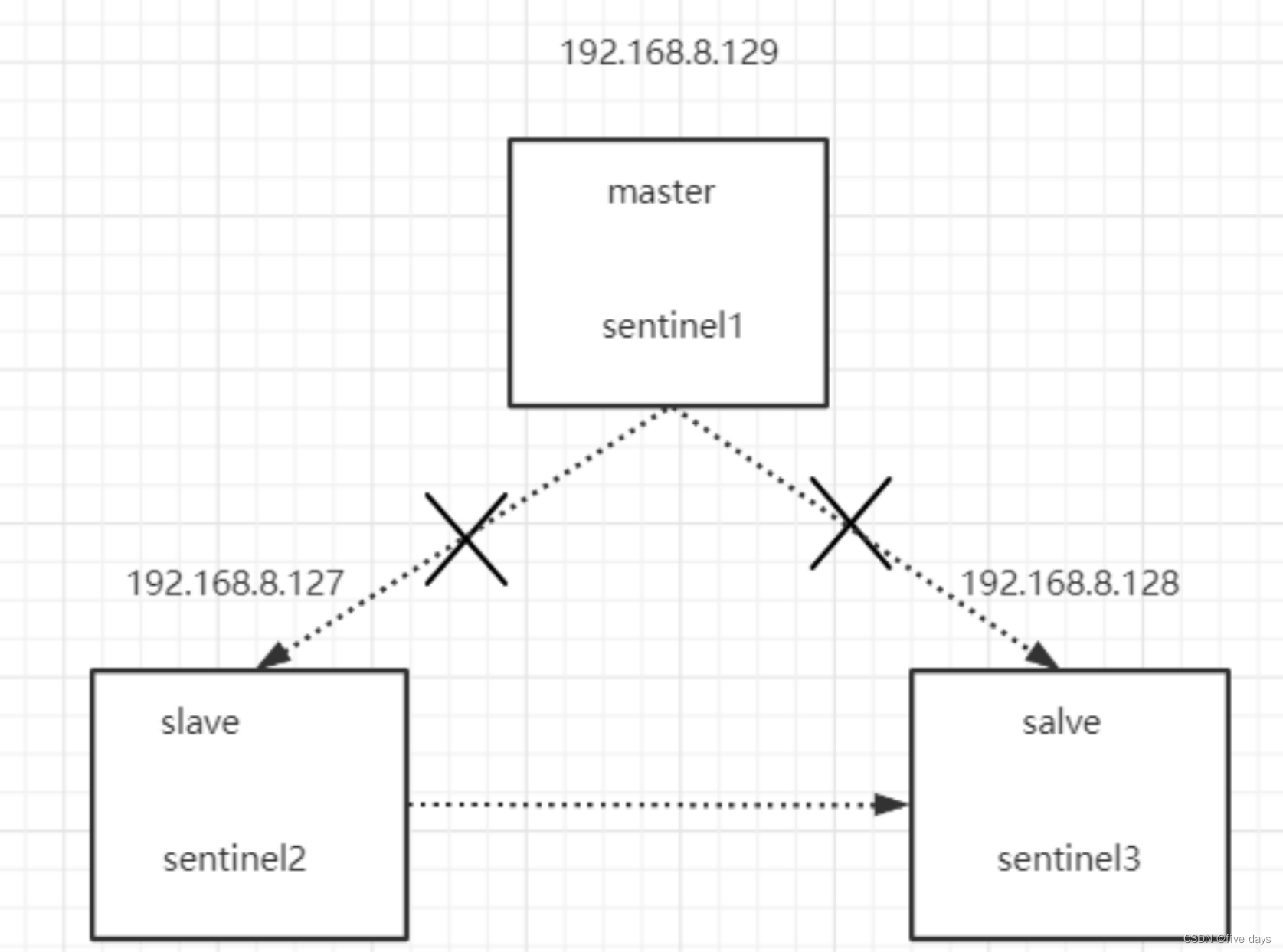
b. 当我的master机器(129)跟另外2台发生分区容错,网络断开
c. sentinel2跟sentinel3大于三分之二,满足故障转移条件(sentinel故障转移需要过半),这个时候会从2个slave中选出一个master
d. 客户端假如连接到sentinel1,我们数据会写入129,连接到sentinel2或sentinel3,数据就会写入128,同时有2个master写入数据。假如129写入了k1
e.当网络恢复后,129会变成128的从,129的数据全部从128同步
f. k1丢失
尽量减少主从切换跟sentinel数据丢失的解决办法:
min-replicas-to-write 1 至少有1个从节点同步到我主节点的数据(有的话让数据写入),但是由于是异步同步,所以是最终一致性 不会确保有数据写入
min - replicas - max - lag 10 判断上面 1 个的延迟时间必须小于等于 10s
2. Redis缓存跟DB一致性问题
在并发环境下,可能导致redis跟DB的数据产生不一致。
2.1 怎么产生?
查询缓存逻辑
a.在我们查询DB之前,先去查询Redis,如果Redis存在,直接返回;如果Redis不存在,从DB查询。
b.从DB查询后,回写到Redis
缓存依赖
当修改DB的数据,DB数据修改成功后,删除Redis数据,做好缓存依赖。
丢失场景
1. 线程 A 请求缓存,没有缓存,从 DB 拿到 1 。2. 线程 B 将 1 更新为 2 ,并且删除缓存, DB 的值为 23. 线程 A 更新缓存, redis 为 1
因此,最终我们发现,redis的数据为1,db数据为2,出现了数据一致性问题。
所以,数据一致性产生的根本问题,是查询DB跟操作Redis不是原子性的,所以并发会导致数据一致性问题。
2.2 怎么解决?
2.2.1 不可取的强一致性方案
延时双删
所谓延时双删,就是在更新 DB 后,等待一段时间,再进行 Redis 删除!来等待其他的线程拿到的都是最新数据!也会产生很多问题。1. 延时多久?不知道其他线程要多久。2. 不够优雅,代码中写入延时代码。
采用锁机制,不让有并发
在更新的时候,采取锁的机制,不让其他线程进行删除操作!
但是会拖慢整个性能,违背了 Redis 的初衷
综上,我们只能采用最终一致性,不应该去保证强一致性。
2.2.2 最终一致性方案
每个缓存设置过期时间
设置过期时间,就算不一致,也只是在有效时间内的不一致。
Mysql canal等数据同步工具
捕捉到DB的更改,同步到相关Redis,相对比较复杂,要知道每个数据对应的缓存。
3. edis缓存雪崩、穿透、击穿问题分析
3.1缓存雪崩
缓存雪崩就是redis大量的数据同时过期(失效) 并且并发很高,则会导致所有的key全部打到DB
1. 保证 Redis 的高可用,防止由于 Redis 不可用导致全部打到 DB2. 加互斥锁或者使用队列,针对同一个 key只允许一个线程到数据库查询( 一般不这么干 与redis初衷违背 )3. 缓存定时预先更新,避免同时失效4. 通过加随机数,使 key 在不同的时间过期
3.2 缓存穿透
缓存穿透就是恶意攻击,指的是查询的key redis没有 db也没有,就会导致每次请求都会走DB
怎么解决? 最好的办法就是找运维 封IP
能不能把数据放到另外一个地方, 在访问redis和db之间就过滤一次。举个例子
比如,你去按摩,你有指定的技师,那么你先看下这个技师会不会值班,如果值班,你就去,否则你就不去。并且这个值班表必须提前安排好!可以用一个在线表格,在就打钩,不能说你把这个人站在这里,看到这个人就说明在。
上面例子到我们的redis中,就是腾出一部分内存空间,为value值打标记,这就是我们布隆过滤器的思想。
3.2.1 布隆过滤器
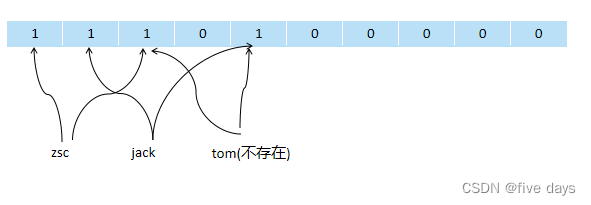
位图里面只有0和1 zsc jack tom代表的是 value值 布隆过滤器的key, 向上指向的1 为两次hash后得到的位置 标记为1.但是我们没有办法判断tom是不是真的存在,因为Tom所在的两个位置与zsc和jack的hash冲突,因为无法判断tom是不是存在,但是布隆过滤器一定能够判断数据不存在。
思考: 那么怎么减少hash冲突呢? 多次hash; 增大位图大小。
还有一个弊端: 必须首先初始化数据到布隆过滤器,并且不能删除(就拿tom来说,如果tom删除了,第3和第5的位置就会置为0,影响其他的元素会导致 zsc和jack即使db中有,也判断为了没有)
实现方式:
1Redission 封装基于 Redis 的 bitMap 实现分布2.google.guava 本地内存.3.Redis bloom模板 https://redis.io/docs/stack/bloom/
3.3 缓存击穿
缓存击穿是说单个key过期的时候有大量的并发访问。 解决办法: 使用互斥锁,回写redis,并且采用双重检查锁来提升性能,减少对DB的访问
以上,我们Mysql现在有集群等方案,所以也没那么脆弱,如果真的到了瓶颈我们也可以进行DB横向扩容
4. 慢查询分析
许多存储系统都会有慢日志查询,提供给开发跟运维来找到哪些指令是比较耗时的。比如Mysql,那么Redis中也会有慢日志查询。
但是Redis的慢查时间只会去统计执行指令的时间,不会统计网络消耗时间,所以没有慢查不代表没有超时。
多慢才是慢查询?可配
#The following time is expressed in microseconds , so 1000000 is equivalent 微秒表示#to one second . Note that a negative number disables the slow log , while 负数禁用慢日志记录#a value of zero forces the logging of every command . 为0记录每个命令slowlog - log - slower - than 10000 // 默认 10ms 建议1ms
最多存储多少慢查?可配
slowlog - max - len 128 // 最多存储 128 条数据
如果发现慢查,怎么避免?
1. 尽量不要使用 hgetall keys 等指令2. 调整大对象,变成多个子对象(一般超过 10K 就算比较大的 key ,但是根据业务来)
4.1 阻塞分析
1.业务记录好相关日志,以及降级报警等系统,知道有阻塞
2. 原因主要分为几个点2.1 外部原因:网络阻塞 CPU 竞争等2.2 内部原因:数据结构不合理导致大key 等单条指令耗时过大、 fork 子进程阻塞、AOF 刷盘阻塞





![[数据集][目标检测]室内积水检测数据集VOC+YOLO格式761张1类别](https://img-blog.csdnimg.cn/direct/9e58aa61e5c44340a230b80f0fcc0733.png)