一 spark sql基础
1.1 Dataframe
1.介绍:
DataFrame也是一个分布式数据容器。然而DataFrame更像传统数据库的二维表 格,除了数据以外,还掌握数据的结构信息,即schema。同时,与Hive类似,DataFrame也支 持嵌套数据类型(struct、array和map)。
1.2 基础的spark-sql程序
1.2.1创建spark sql入口
1.使用SparkSession类,并设置其相关东西
.builder() :创建环境
.master() :明确部署
.appName :给任务取个名字
.getOrCreate() :创建
1.2.2 构建DF
使用SparkSession中的read方法并设置相关属性创建DF
.format("csv") //指定读取数据的格式
.schema("line STRING") //指定列的名和列的类型,多个列之间使用,分割
.option("sep", "\n") //指定分割符,csv格式读取默认是英文逗号
.load("spark/data/words.txt") // 指定要读取数据的位置,可以使用相对路径
1.2.3 创建视图
使用DF里面的方法
linesDF.createOrReplaceTempView("lines") // 起一个表名,后面的sql语句可以做查询分析
1.2.4 编写sql语句
使用SparkSession中的sql方法创建sql查询后的DF:
sparkSession.sql(".....................................")
1.2.5 查看
使用DF里面的show方法查看内容
使用DF里面的printSchema查看结构
1.2.6 写入
1.设置分区数,可以设置也可以不设置,使用的是DF中的方法,但是返回值是Dataset类型
val resDS: Dataset[Row] = resDF.repartition(1)
2.如果设置了分区使用DataSet中的write,没有使用DF中的write
.format("csv") //指定输出数据文件格式
.option("sep","\t") // 指定列之间的分隔符
.mode(SaveMode.Overwrite) // 使用SaveMode枚举类,设置为覆盖写
.save("spark/data/sqlout1") // 指定输出的文件夹
下面是完整代码
/*** 在新版本的spark中,如果想要编写spark sql的话,需要使用新的spark入口类:SparkSession*/val session: SparkSession = SparkSession.builder() //创建环境.master("local") //明确部署.appName("单词统计") //取名.getOrCreate() //创建/*** spark sql和spark core的核心数据类型不太一样** 1、读取数据构建一个DataFrame,相当于一张表*/val wordCountDataFrame: DataFrame = session.read //使用read构建DataFrame.format("csv") //指定读取文件的格式.schema("line STRING") //指定创建好的DataFrame中的列名和列的类型.option("sep", "\n") //指定分隔符,csv默认以逗号形式.load("spark/data/words.txt") //读取文件的路径// wordCountDataFrame.show()//查看DF的内容
// wordCountDataFrame.printSchema()//查看DF结构/*** 2、DF本身是无法直接在上面写sql的,需要将DF注册成一个视图,才可以写sql数据分析*/wordCountDataFrame.createOrReplaceTempView("words")//给DF取一个表名/*** 3、可以编写sql语句 (统计单词的数量)* spark sql是完全兼容hive sql*/val resFrame: DataFrame = session.sql("""|select|t1.word as word,|count(1) as counts|from|(select| explode(split(line,'\\|')) as word from words) t1| group by t1.word|""".stripMargin)// frame.show()/*** 4、将计算的结果DF保存到*/val resDataset: Dataset[Row] = resFrame.repartition(1)//指定分区,指定完后类型变成了Dataset类型resDataset.write.format("csv")//指定写入文件的格式.option("sep","\t")//指定分隔符.mode(SaveMode.Overwrite)//使用SaveMode枚举类,设置为覆盖写.save("spark/data/sqlout1")//指定输出路径1.3 DSL
1.3.1 基础的DSL
1.使用SparkSession类,并设置其相关东西
.builder() :创建环境
.master() :明确部署
.appName :给任务取个名字
.getOrCreate() :创建
2.使用SparkSession中的read方法并设置相关属性创建DF
.format("csv") //指定读取数据的格式
.schema("line STRING") //指定列的名和列的类型,多个列之间使用,分割
.option("sep", "\n") //指定分割符,csv格式读取默认是英文逗号
.load("spark/data/words.txt") // 指定要读取数据的位置,可以使用相对路径
3.导入相关包
导入Spark sql中所有的sql隐式转换函数
import org.apache.spark.sql.functions._
导入另一个隐式转换,后面可以直接使用$函数引用字段进行处理
import sparkSession.implicits._
4.写DSL语句
可以直接使用$函数引用字段进行处理例如 $"id"
5.保存数据
设置分区数,可以设置也可以不设置,使用的是DF中的方法,但是返回值是Dataset类型
val resDS: Dataset[Row] = resDF.repartition(1)
如果设置了分区使用DataSet中的write,没有使用DF中的write
.format("csv") //指定输出数据文件格式
.option("sep","\t") // 指定列之间的分隔符
.mode(SaveMode.Overwrite) // 使用SaveMode枚举类,设置为覆盖写
.save("spark/data/sqlout1") // 指定输出的文件夹
相关代码如下
/*** 在新版本的spark中,如果想要编写spark sql的话,需要使用新的spark入口类:SparkSession*/val session: SparkSession = SparkSession.builder().master("local").appName("DSL").getOrCreate()/*** spark sql和spark core的核心数据类型不太一样** 1、读取数据构建一个DataFrame,相当于一张表*/val wordDF: DataFrame = session.read.format("csv").schema("line STRING").option("sep", "\n").load("spark/data/words.txt")/*** DSL: 类SQL语法 api 介于代码和纯sql之间的一种api* spark在DSL语法api中,将纯sql中的函数都使用了隐式转换变成一个scala中的函数* 如果想要在DSL语法中使用这些函数,需要导入隐式转换*///导入Spark sql中所有的sql隐式转换函数import org.apache.spark.sql.functions._//导入另一个隐式转换,后面可以直接使用$函数引用字段进行处理//session.implicits 这个却决去上面的SparkSession的对象名字import session.implicits._/*** 开始写DSL*/val wordCountDF: DataFrame = wordDF.select(explode(split($"line", "\\|")) as "word").groupBy($"word").agg(count($"word") as "count")/*** 保存数据*/wordCountDF.repartition(1).write.format("csv").option("sep","\t").mode(SaveMode.Overwrite).save("spark/data/sparkout2")1.3.2 DataFrame的补充
1.可以读json文件,不需要手动指定列名
val session: SparkSession = SparkSession.builder().master("local").appName("DSL的基本语句").getOrCreate()val jsonDF: DataFrame = session.read.json("spark/data/students.json")jsonDF.show(100,truncate = false)2.show的方法可以传入展示总条数,并完全显示数据内容
1.3.3 select
1.select 直接加字段,这样只能查看信息,不能做如何操作
select("id","name","age")
2.selectExpr可以修改字段的值
electExpr("id","name","age","age + 1 as new_age").show()
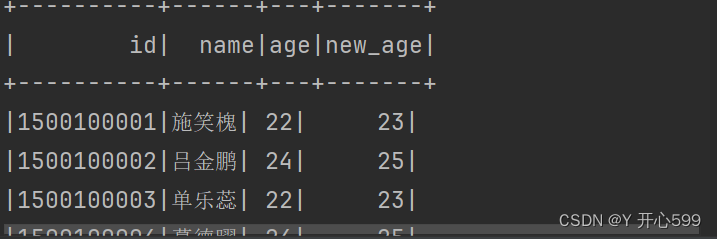
3.select+$ 将字段变成对象,更加贴切sql
select($"id",$"name",$"age",$"age" + 1 as "new_age").show()
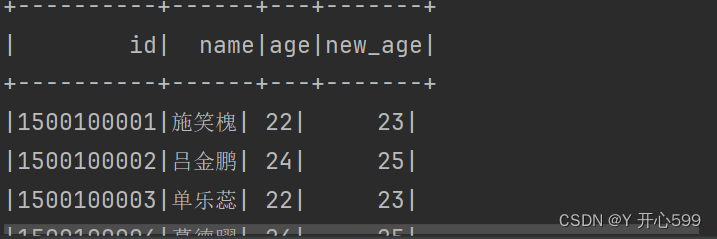
4.select可以加上sql的函数使用
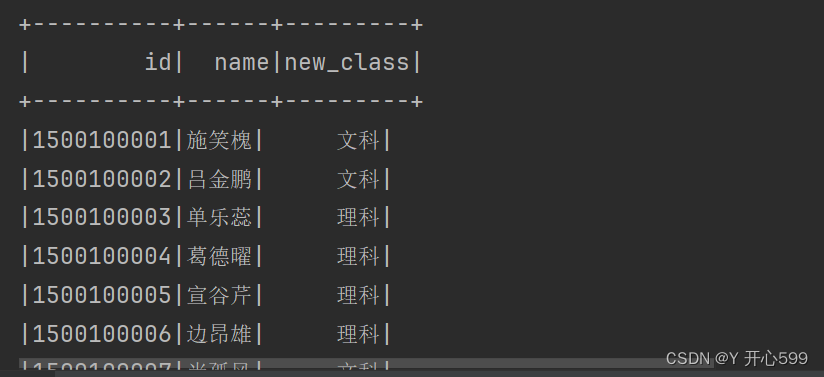
stuDF.select($"id",$"name",substring($"clazz",0,2) as "new_class").show()
1.3.4 where
1.直接过滤
where("gender='女' and age=23")
2.将字段名作为对象
where($"gender" === "女" and $"age" === 23)
3.===是判断2个值是否相等,=!=判断2个值不相等
1.3.5 分组聚合
1.groupBy与agg函数要在一起用,分组聚合之后的结果DF中只会包含分组字段和聚合字段
2.分组的字段是出现比较多的字段
stuDF.groupBy($"clazz")
.agg(count($"clazz") as "number",round(avg($"age"),2) as "avg_age").show()
1.3.6 排序
1.排序的操作优先级很低
2.desc:降序,默认是升序
stuDF.groupBy($"clazz")
.agg(count($"clazz") as "number")
.orderBy($"number").show()
1.3.7 join
1.关联字段名相同的
stuDF.join(scoreDF,"id")
2.关联字段名不相同的
stuDF.join(scoreDF, $"id" === $"sid")
3.join后面还可以传一个参数,表示是啥连接的,默认是内连接
stuDF.join(scoreDF, $"id" === $"sid", "inner")
1.3.8 开窗
1.sql开窗
使用开窗函数
DF.select($"id", $"clazz", $"sum_score", row_number() over (Window partitionBy $"clazz" orderBy $"sum_score".desc) as "rn")
2.DSL开窗 使用withColumn函数(”列名“,sql语句)
.withColumn("rn",row_number() over (Window partitionBy $"clazz" orderBy $"sum_score".desc))
1.4 读取文件的类型
1.4.1 csv
1.读文件需要指定文件的类型,还要定义列的类型,还有分隔符,最后指定文件路径
.format("csv")
.schema("id STRING,name STRING,age INT,gender STRING,clazz STRING")
.option("sep", ",")
.load("spark/data/students.csv")
2.写文件需要指定分隔符
1.4.2 Json
1.读文件,指定类型与位置即可
.format("json")
.load("spark/data/students2.json")
2.写文件
2.读文件也是一样
1.4.3 arquet
1.读写文件跟json文件一样
1.5 jcbc
1.连接,MySQL数据库的时候,连接不成功,url加参数
/*** 读取数据库中的数据,mysql* 数据库连接不是加一个useSSL=false* 如果还是不行加这个 useUnicode=true&allowPublicKeyRetrieval=true&characterEncoding=utf8&useSSL=false*/val jodDF: DataFrame = session.read.format("jdbc").option("url", "jdbc:mysql://192.168.73.100:3306?useSSL=false").option("dbtable", "bigdata29.job_listing").option("user", "root").option("password", "123456").load()jodDF.show(10,truncate = false)1.6 RDD与DF的转化
1.6.1 RDD转DF
1.SparkSession包含了SparkContext,直接才用.点形式获取SparkContext对象
2.直接.toDF直接飙车DF类型,如果后续需要做sql查询,需要加上表名
DF.createOrReplaceTempView("表名")
val context: SparkContext = session.sparkContextval stuRDD: RDD[String] = context.textFile("spark/data/ws/students.csv")val linesRDD: RDD[(String, String, String, String, String)] = stuRDD.map((line: String) => {val stuList: Array[String] = line.split(",")val id: String = stuList(0)val name: String = stuList(1)val age: String = stuList(2)val gender: String = stuList(3)val clazz: String = stuList(4)(id, name, age, gender, clazz)})val frame: DataFrame = linesRDD.toDF("id","name","age","gender","clazz")frame.createOrReplaceTempView("students")val frame1: DataFrame = session.sql("""|select|clazz,|count(1) as num|from|students|group by clazz|""".stripMargin)1.6.2 DF转RDD
1.直接使用DF.rdd()方法即可,但是数据类型是Row类型
2.在Row的数据类型中 所有整数类型统一为Long 小数类型统一为Double
/*** 在Row的数据类型中 所有整数类型统一为Long 小数类型统一为Double* 转RDD*/val rdd: RDD[Row] = frame1.rddrdd.map{case Row(clazz:String,num:Long)=>(clazz,num)}.foreach(println)二 spark sql 的执行方式
2.1 代码打包运行
1.编写代码
val sparkSession: SparkSession = SparkSession.builder()//如果是提交到linux中执行,不用这个设置// .master("local").appName("spark sql yarn submit").config("spark.sql.shuffle.partitions", 1) //优先级:代码的参数 > 命令行提交的参数 > 配置文件.getOrCreate()import sparkSession.implicits._import org.apache.spark.sql.functions._//读取数据,如果是yarn提交的话,默认读取的是hdfs上的数据val studentsDF: DataFrame = sparkSession.read.format("csv").option("sep", ",").schema("id STRING,name STRING,age INT,gender STRING,clazz STRING").load("/bigdata29/spark_in/data/student")val genderCountsDF: DataFrame = studentsDF.groupBy($"gender").agg(count($"gender") as "counts")//将DF写入到HDFS中genderCountsDF.write.format("csv").option("sep",",").mode(SaveMode.Overwrite).save("/bigdata29/spark_out/out2")2.代码中读的数据是hdfs中的,保证hdfs中有这个文件
3.将代码打包好放到linux中
4.执行命令
spark-submit --master yarn --deploy-mode client --class com.shujia.sql.Demo8SubmitYarn --conf spark.sql.shuffle.partitions=100 spark-1.0.jar
master yarn:提交模式
deploy-mode client :执行方式
class com.shujia.sql.Demo8SubmitYarn:主类名
conf spark.sql.shuffle.partitions=1:设置分区
spark-1.0.jar:jar包名
5. 我代码里面设置了 分区数是1,但是我执行命令又写了100,最后执行结果是只有一个分区,故可以得到优先级:代码的参数 > 命令行提交的参数 > 配置文件
2.2 spark shell (repl)
1.输入命令 spark-shell --master yarn --deploy-mode client后可以来到这个交互式页面
输入一行执行一行命令
2.直接在这里输入spark代码运行,不过这里没有提示,不推荐
3.不能使用yarn-cluster Driver必须再本地启动
2.3 spark-sql
1.输入命令 spark-sql --master yarn --deploy-mode client后进入这个页面
2.注意输入这个命令,在哪个目录下,那个目录就有以下数据
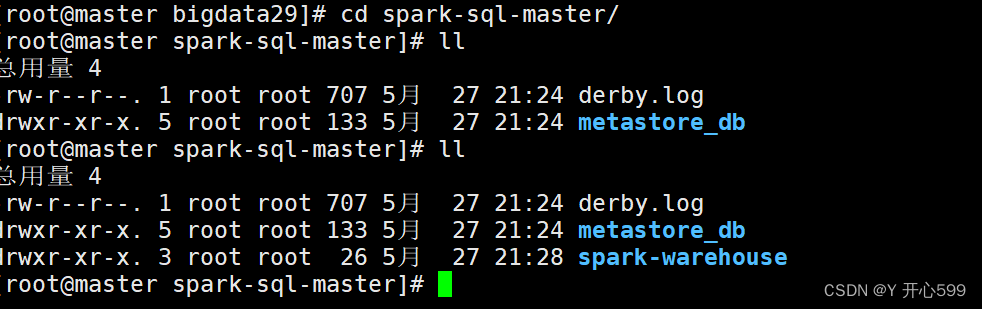
这些数据就是你在spark sql里面创建的库或者表的数据,如果把这个目录删了,在重新输入这个命令,里面的数据也不存在了
3.在spark-sql时完全兼容hive sql的
spark-sql底层使用的时spark进行计算的
hive 底层使用的是MR进行计算的
2.4 spark与hive的整合
1.配置hive-1.2.1中的conf
<property>
<name>hive.metastore.uris</name>
<value>thrift://master:9083</value>
</property>
2.将hive-site.xml 复制到spark conf目录下
3.将mysql 驱动包复制到spark jars目录下
4.配置好了过后启动spark-sql --master yarn --deploy-mode client 就可以在spark sql里面看见hive中的数据了
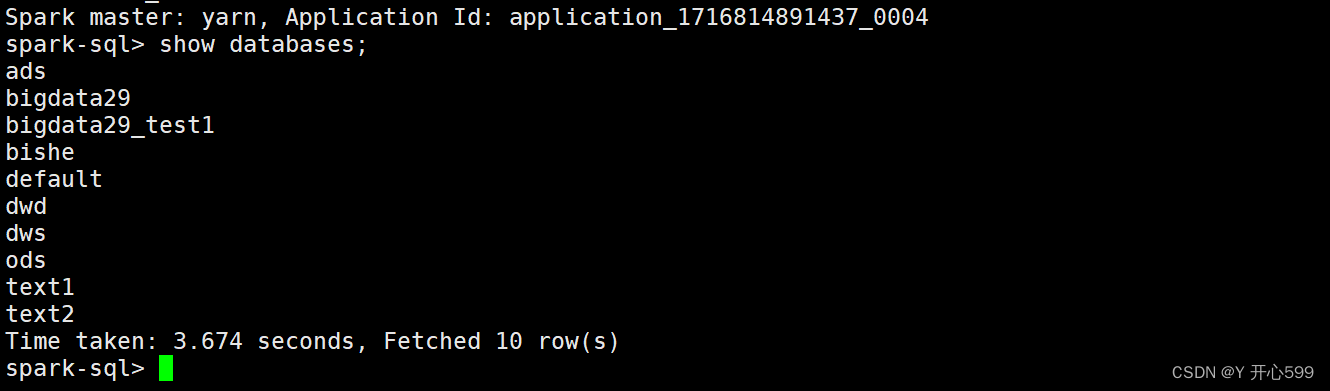
5.如果不想看到那么多的日志信息,可以去修改spark中的conf文件夹中的log4j文件,修改之前最好先复制一份将这个改成ERROR即可

6.再不进入客户端使用spark-hive sql查询
spark-sql -e "select * from student",他执行完自动退出
7.还可以编写一个sql脚本,里面是sql的语句
spark-sql -f 脚本名.sql
2.5 spark-hive
1.导入依赖
<dependency><groupId>org.apache.spark</groupId><artifactId>spark-hive_2.12</artifactId></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-client</artifactId></dependency><dependency><groupId>org.apache.hive</groupId><artifactId>hive-exec</artifactId></dependency><dependency><groupId>com.fasterxml.jackson.core</groupId><artifactId>jackson-databind</artifactId></dependency><dependency><groupId>com.fasterxml.jackson.core</groupId><artifactId>jackson-core</artifactId></dependency>
2.编写spark-hive代码
这里记得添加开启支持hive的
val sparkSession: SparkSession = SparkSession.builder().master("local").appName("spark读取hive数据")//开启hive支持.enableHiveSupport().config("spark.sql.shuffle.partitions", 1).getOrCreate()import sparkSession.implicits._import org.apache.spark.sql.functions._sparkSession.sql("use text2")sparkSession.sql("select clazz,count(1) as counts from students group by clazz").show()2.6 自定义函数
2.6.1 使用Scala编写
1.使用udf中的方法,里面可以传很多参数,如果你的函数只需要一个,那么选0那个
2.如果使用不成功,可以将scala的依赖提高一个版本
val hjx: UserDefinedFunction = udf((str: String) => "hjx" + str)2.6.2 spark-sql编写
1.先要2.6.1中的函数存在
2.再使用sparkSession.udf.register("shujia_str", hjx),将hjx函数在sql中命名为shujia_str的函数
3.再使用sql就可以使用shujia_str这个函数了
studentsDF.createOrReplaceTempView("students")//将自定义的函数变量注册成一个函数sparkSession.udf.register("shujia_str", hjx)sparkSession.sql("""|select clazz,shujia_str(clazz) as new_clazz from students|""".stripMargin).show()2.6.3 打包
1.编写一个Scala类继承 UDF,编写想要的函数
2.将类打包,放在linux中spark的jars目录下
3.进入spark-sql的客户端
4.使用上传的jar中的udf类来创建一个函数,这个命令在客户端输入
create function shujia_str as 'com.shujia.sql.Demo12ShuJiaStr';
5.然后客户端就可以使用shujia_str的函数
package com.shujia.sqlimport org.apache.hadoop.hive.ql.exec.UDFclass Demo12ShuJiaStr extends UDF {def evaluate(str: String): String = {"shujia: " + str}
}/*** 1、将类打包,放在linux中spark的jars目录下* 2、进入spark-sql的客户端* 3、使用上传的jar中的udf类来创建一个函数* create function shujia_str as 'com.shujia.sql.Demo12ShuJiaStr';*/