概述
是什么
- 索引像是一本书的目录列表,能根据目录快速的找到具体的书本内容,也就是加快了数据库的查询速度
- 索引本质是一个数据结构
- 索引是在存储引擎层,而不是服务器层实现的,所以,并没有统一的索引标准,不同存储引擎的索引的工作方式不同,也不是所有的存储引擎都支持所有类型的索引,即使多个存储引擎支持同一种类型的索引,其底层实现也可能不同————《高性能mysql》
优劣势
优点:
- 提高数据检索的效率,降低了数据库的IO成本
- 通过索引列对数据进行排序,降低数据排序的成本,降低了CPU的消耗
- 被索引的列会自动进行排序,包括【单列索引】和【组合索引】,只是组合索引的排序要复杂一些
缺点
- 索引会占用磁盘空间
- 索引虽然提高了查询的效率,但是会影响增删改的效率,因为每次增删改数据时,数据库要同时更新维护索引的结构
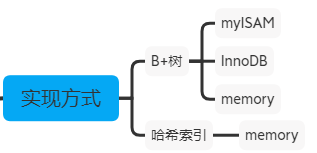
数据结构
索引是存储引擎层面实现的,所以不同的存储引擎使用的索引数据结构也不同,底层结构主要是B+树和哈希两种
hash索引
基于哈希表实现的,对选中的索引列计算出一个哈希码,在哈希表存储的是哈希码以及指向每个数据行的指针(在mysql中,只有memory存储引擎支持哈希索引,且是memory的默认索引方式)
优点: 查找的速度非常快(只需存储对应的哈希值,所以索引的结构十分紧凑)
缺点:
- 不能避免读取行。哈希表中只包含哈希值和行指针,而不存储字段值
- 无法用于排序。哈希表的索引数据并不是按照索引列匹配查找的
- 不支持部分索引列匹配查找。因为哈希索引始终是使用索引列的全部内容来计算哈希值的。
- 只支持等值比较查询,包括=,IN(),<=>,也不支持范围查找
- 存在哈希冲突。当出现哈希冲突时,必须遍历链表中所有的行指针,逐行进行比较,直到找到所有符合条件的行。同时,当哈希冲突很多的时候,一些索引维护操作的代价也会很高。例如,如果在某个选择性很低(哈希冲突很多)的列上建立哈希索引,那么当从表中删除一行时,存储引擎需要遍历对应哈希值的链表中的每一行,找到并删除对应行的引用,冲突越多,代价越大
B+树
默认的索引底层数据结构是B+树,B+树是一颗多叉平衡搜索树,如图:
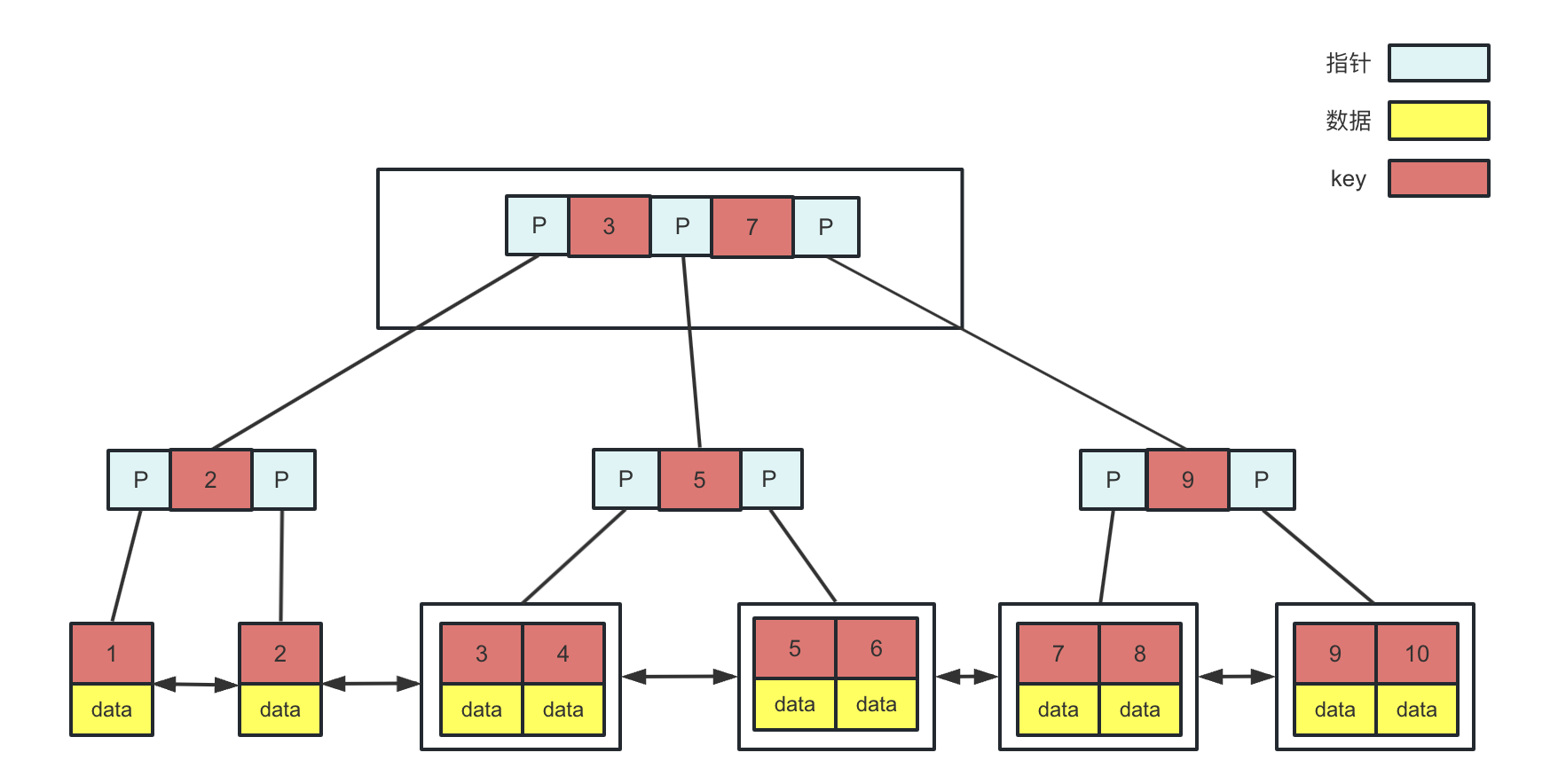
- B+树的节点中存储着多个元素,每个节点内有多个分叉
- 叶子结点包含了所有的索引项
- 只有叶子结点存储数据,非叶子结点只存储索引键
- 叶子结点使用双向指针连接,形成了一个双向有序链表,支持范围查询
- 在查找数据的时候,由于数据都存放在最底层的叶子节点上,所以每次查找都需要检索到叶子节点才能查询到数据。所以在需要查询数据的情况下每次的磁盘的IO跟树高有直接的关系
对比B树
B树也是一个平衡多叉树,结构如图:
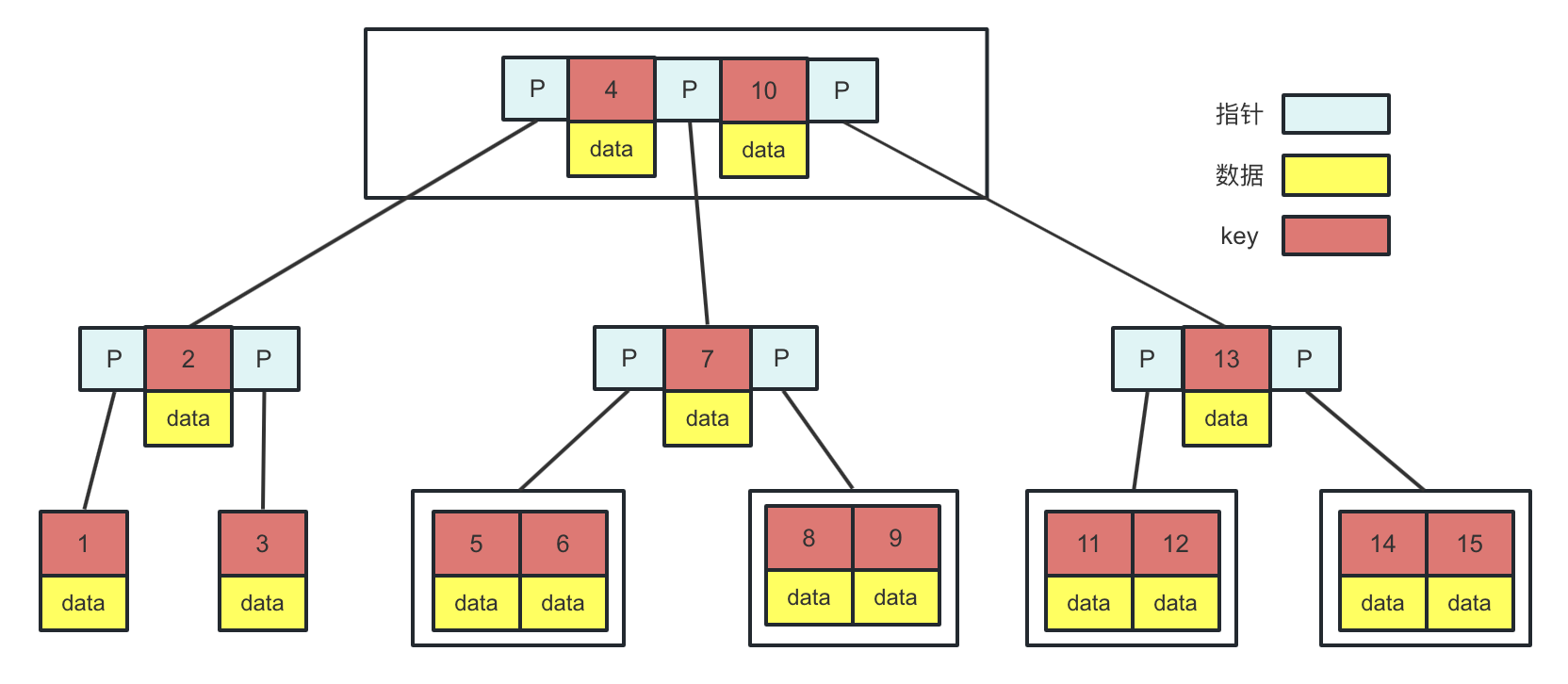
- B树的节点中存储着多个元素,每个内节点有多个分叉
- 所有节点中的元素包含键值和数据,如果data存储的是行记录,行的大小随着列数的增多,所占空间会变大。这时,一个页中可存储的数据量就会变少,树相应就会变高,磁盘IO次数就会变大
- 父节点当中的元素不会出现在子节点中
- 叶节点之间没有指针连接,不支持范围查询
Mysql索引
MyISAM索引(非聚簇索引)
使用B+树作为索引结构,叶节点的data域存放的是数据记录的地址(主键索引和辅助索引存储的都是数据记录的地址),也叫做“非聚簇索引”,如图
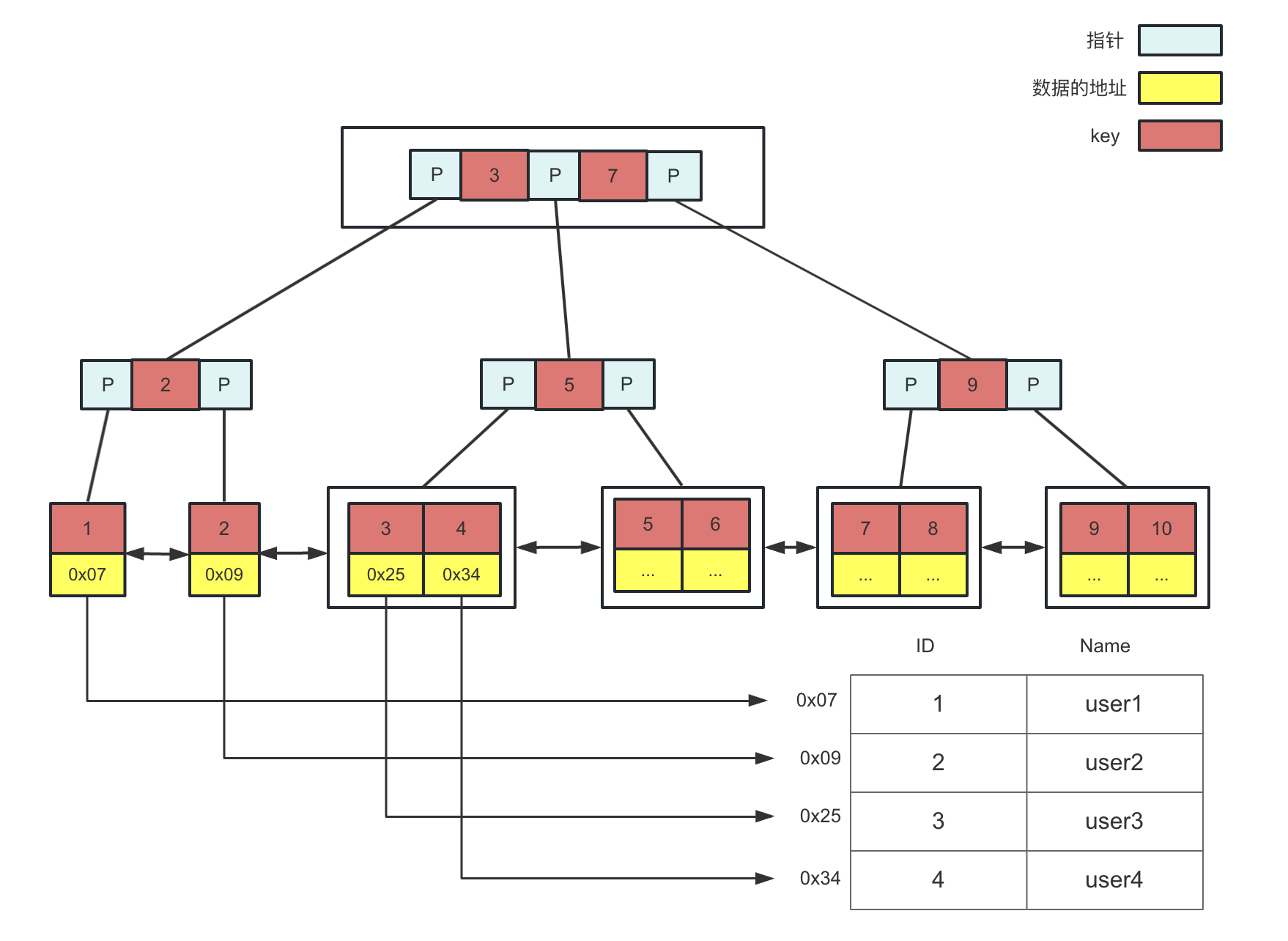
- 主键索引非必需,若存在则主键索引必须唯一
- 辅助索引的结构和主键索引结构一致,可以重复,会存在多个符合条件的数据,所以即使是等值查询,也需要按照范围查询的方式在辅助索引树中检索数据
- 检索过程:首先按照B+树搜索算法搜索索引,如果指定的key存在,则取出其data域的值,然后以data域的值为地址,去读取相应的表数据记录
InnoDB索引
主键索引(聚簇索引)
叶子节点的data域存储的是完整的数据记录,key就是数据表的主键,也叫做“聚簇索引,如图:
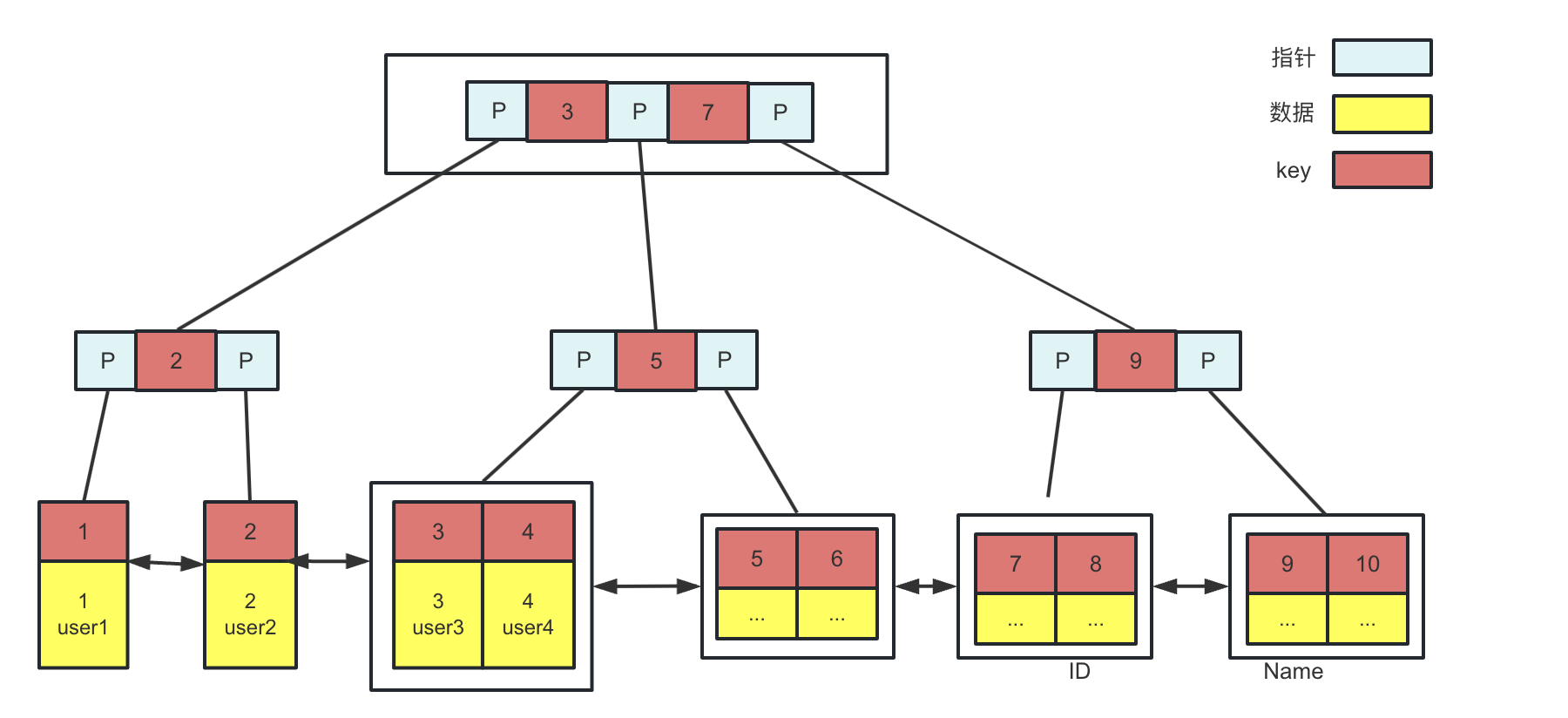
- 检索过程:首先按照B+树搜索算法搜索索引,如果指定的key存在,则取出其data域的值即为表数据
- InnoDB要求必须有主键,且唯一;如果没有显示指定,mysql系统会自动选择一个可以唯一标识数据记录的列作为主键,如果不存在这种列,mysql会自动为InnoDB表生成一个隐含字段作为主键,类型为long
- 尽量在InnoDB上采用自增字段做表的主键;因为InnoDB数据文件本身是一颗B+树,非单调的主键会造成在插入记录时数据文件为了维持B+树的特性而频繁的分裂调整,十分低效,如果表使用自增主键,那么每次插入新的记录,记录会顺序添加到当前索引节点的后续未知,当一页写满,就会自动开辟一个新的页
- 不推荐用uuid做主键;uuid无序,插入操作会频繁做分裂调整,而且字段更长占用的空间更大,空间一大,一页存储的索引数据就减少,就需要占用更多页,查询时的磁盘io次数会增加,影响效率
辅助索引
辅助索引的叶子结点的data域存储的是相应记录主键的值,也就是InnoDB的所有辅助索引都引用主键作为data域,当主键索引行移动或数据页分裂时,减少了辅助索引的维护工作,如图所示:
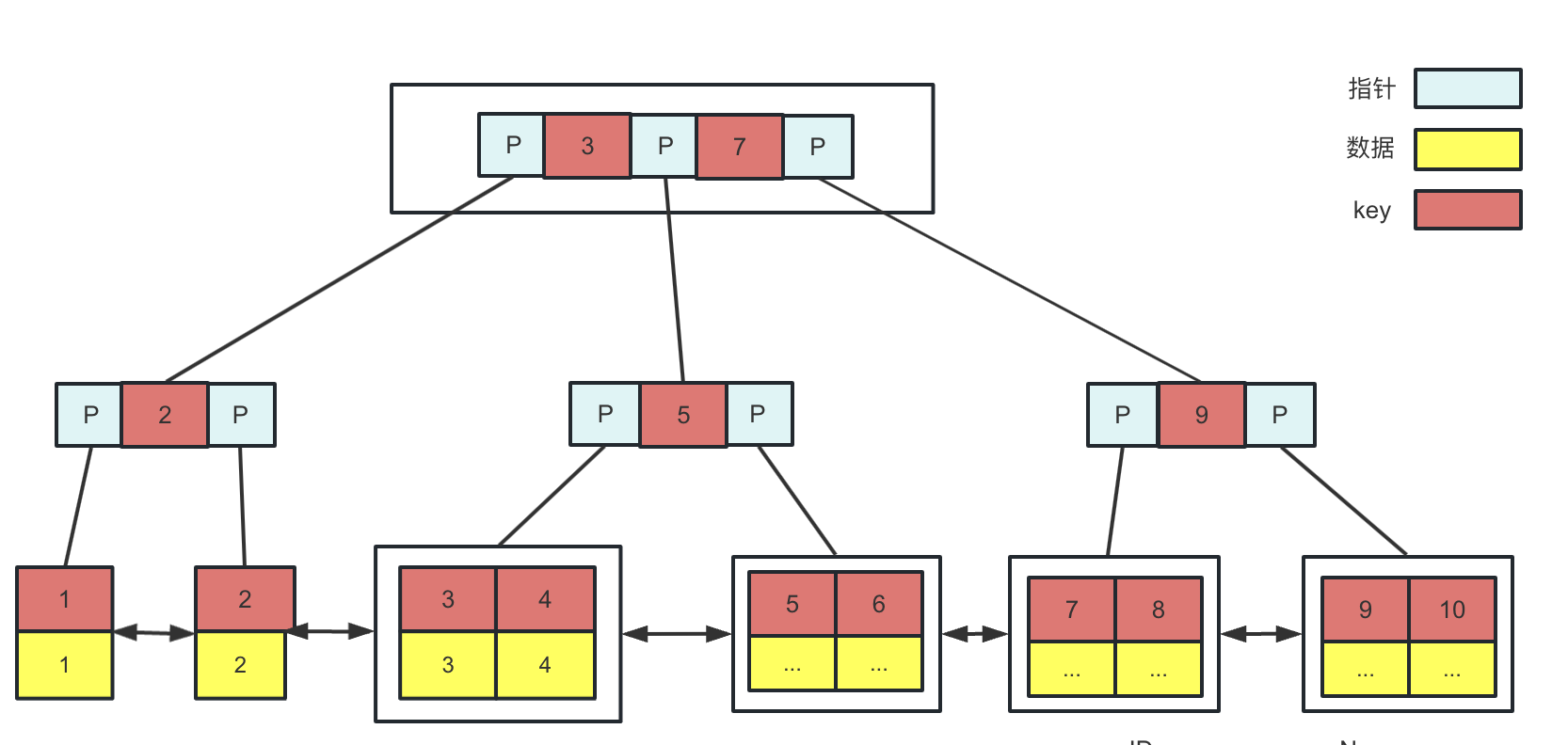
- 检索过程:首先按照B+树搜索算法搜索索引,如果指定的key存在,则取出其data域的值即主键id,然后用主键id去主键索引树查询,找到对应的数据。这个过程中去主键索引树查询的过程叫做“回表”
联合索引和最左匹配原则
- 联合索引是用表中的多个字段组成一个索引,比如创建一个联合索引idx_abc(a,b,c),那么该索引的每个键都包含这三个字段,且是按a,b,c依次排列
- 联合索引的存储方式:最底层的叶子节点按照第一列a列从左到右递增排列,但是b列和c列是无序的,b列只有在a列值相等的情况下小范围内递增有序,而c列只能在a,b两列相等的情况下小范围内递增有序
- 联合索引的检索方式:比如查询条件为where a=1 and b=28 and c=3,那么B+树会先比较a列来确定下一步应该搜索的方向,往左还是往右;如果a列相同再比较b列;但是如果查询条件没有a列,B+树就不知道第一步应该从哪个节点查起,所以这也是最左前缀匹配原则的原因
- 最左前缀匹配原则:使用组合索引查询时,mysql会一直向右匹配直至遇到范围查询(>、<、between、like)就停止匹配
- 用联合索引id_abc查询要符合最左匹配原则,相当于创建了(a)、(a,b)(a,b,c)三个索引
- 联合索引的创建原则:在创建联合索引的时候因该把频繁使用的列、区分度高的列放在前面,频繁使用代表索引利用率高,区分度高代表筛选粒度大,这些都是在索引创建的需要考虑到的优化场景,也可以在常需要作为查询返回的字段上增加到联合索引中,如果在联合索引上增加一个字段而就能用到覆盖索引,那就可以加上
覆盖索引
覆盖索引并不是一种索引结构,而是一种sql优化手段。这源于辅助索引和主键索引的关键,如果只用覆盖索引那么必然要去主键索引那回表查询到需要的字段,但是如果在辅助索引树上能查询到所需的字段呢,就不需要再去主键索引上查询了呀,减少了回表就减少了磁盘io,就提升了查询速度呀
辅助索引树上有两块数据,一个是索引key,一个是data域,data域固定是主键id没法变,前面讲的联合索引表明索引key可以是多个字段组合的,那么就可以合理使用联合索引实现覆盖索引,减少回表次数,提升查询效率
⚠️使用这种手段必须是频繁查询的字段,不然没提升速度反而增加了索引结点的占用空间导致效率下降
总结
希望这些内容可以帮助你更好的理解mysql的索引,对sql优化能有更好的想法💡
![[数据集][目标检测]焊接处缺陷检测数据集VOC+YOLO格式3400张8类别](https://img-blog.csdnimg.cn/direct/981fed37f1424cb49bd073230ff2d4d4.png)