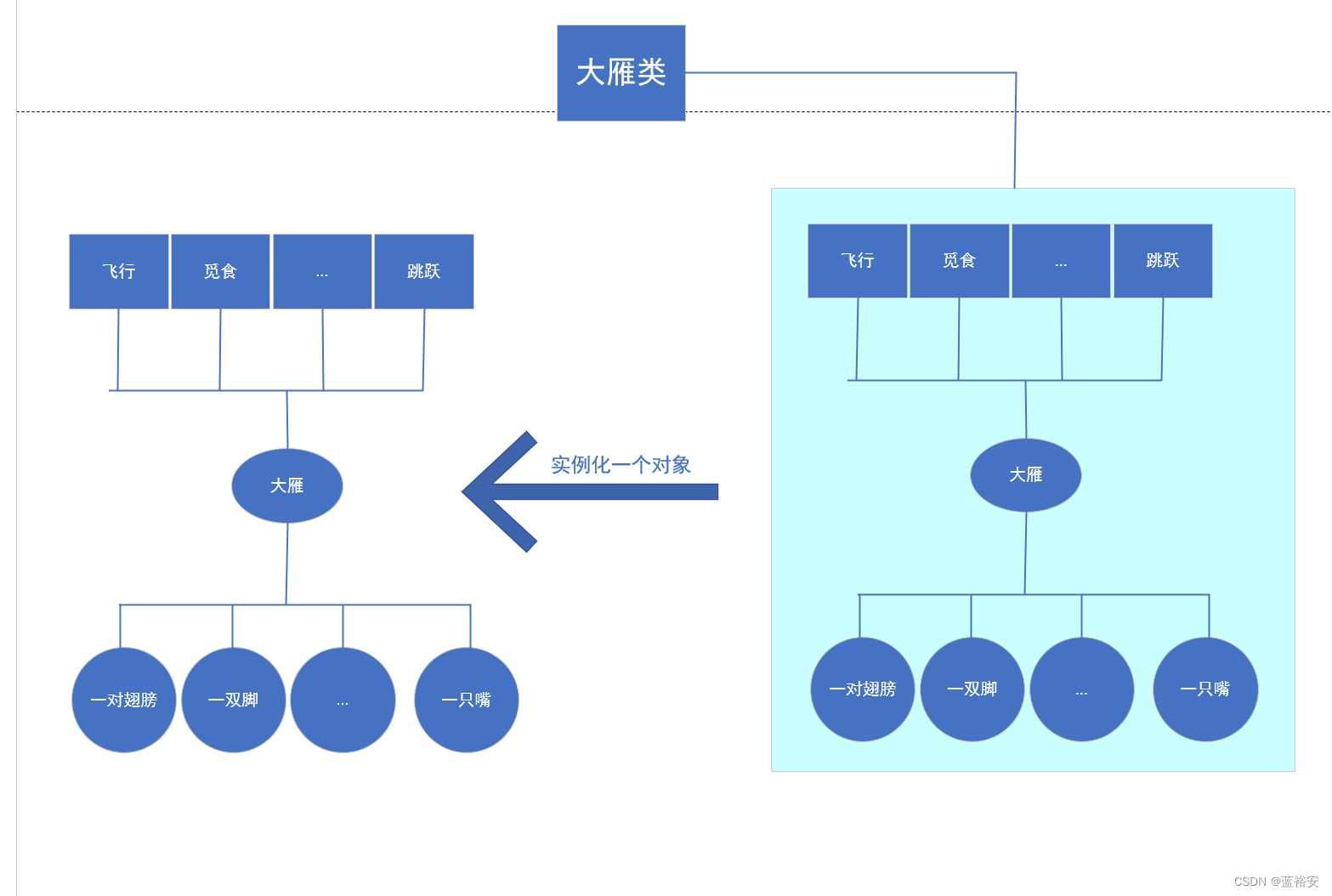
集合这个词,耳熟能详,从小学一年级开始,每天早上做操时都会听到这两个字:

高中数学又学习到了新的集合:

那么Java中的集合是什么呢?
一,前言
1,什么是Java集合
数学集合是Java集合的数学基础,所以有一致之处:
- 都是由一组集在一起的对象构成
- Java集合也可以应用数学集合的运算法则,如交集、并集、差集
但是,Java集合作为一个编程工具,更加突出了作为容器的作用:

就像一个果篮一样,Java容器具备存储、管理对象的功能,比如:
- 存储水果
- 向果篮中放入一个或者一批水果,动作是add、addAll、put、putAll
- 把果篮中一个或者一批腐败的水果丢掉,动作是delete、remove
- 从果篮中取出一个水果,动作是get
- 判断果篮中是否包含苹果,动作是contains
- 计算果篮中水果的个数,动作是size
Java集合是存储、管理对象的容器。
2,Java集合的作用
Java集合到底有什么作用呢?这个问题值得好好思考一下,只有这样,才能更好的使用Java集合。
以开发一个简单的订单管理系统为例,我们需要存储并管理一系列订单信息,包括订单号、客户姓名、商品列表、总价等。
让我们通过对比使用Java集合和不使用Java集合的情况,分析在实现该系统时可能遇到的困难。
使用Java集合的示例代码
import java.util.*;class Product {String name;double price;Product(String name, double price) {this.name = name;this.price = price;}
}class Order {String orderId;String customerName;ArrayList<Product> productList;double totalAmount;Order(String orderId, String customerName) {this.orderId = orderId;this.customerName = customerName;this.productList = new ArrayList<>();}void addProduct(Product product) {// 不需要考虑集合容器的大小,容器会自动扩容productList.add(product);totalAmount += product.price;}
}public class OrderManagement {public static void main(String[] args) {Order order = new Order("ORD123", "Alice");order.addProduct(new Product("Book", 19.99));order.addProduct(new Product("Pen", 4.99));System.out.println("Total Amount: " + order.totalAmount);}
}
不使用Java集合实现
如果Java集合框架不可用,我们需要手动实现数据结构来存储订单中的商品列表。这将涉及创建一个产品数组,并手动管理数组的大小调整、添加和删除产品等操作。
class OrderWithoutCollection {String orderId;String customerName;Product[] productList; // 假设产品数组int productCount;double totalAmount;OrderWithoutCollection(String orderId, String customerName) {this.orderId = orderId;this.customerName = customerName;this.productList = new Product[10]; // 初始化固定大小的数组this.productCount = 0;}boolean addProduct(Product product) {// 需要考虑数组的大小if (productCount == productList.length) {// 数组已满,需要手动扩展,这里简化处理,实际应复制数组并创建更大的数组System.out.println("Product list is full, cannot add more products.");return false;}productList[productCount++] = product;totalAmount += product.price;return true;}// 其他方法省略...
}public class OrderManagementWithoutCollection {public static void main(String[] args) {OrderWithoutCollection order = new OrderWithoutCollection("ORD123", "Alice");order.addProduct(new Product("Book", 19.99));order.addProduct(new Product("Pen", 4.99));System.out.println("Total Amount: " + order.totalAmount);}
}
两种方式的差异分析
-
复杂度增加:不使用集合框架,我们必须手动管理数组的大小,如上例中的
OrderWithoutCollection类,当商品列表超出初始分配的空间时,需要手动扩展数组,这增加了代码的复杂度 -
效率低下:手动数组管理缺乏动态调整大小的能力,可能导致空间浪费或频繁的数据复制(如果每次添加商品都动态扩展数组)。此外,查找和删除操作可能需要遍历整个数组,效率低下
-
类型安全风险:没有泛型,我们可能会在操作数组时忘记检查类型,导致运行时错误
-
功能缺失:没有现成的排序、过滤等操作,需要自己编写逻辑,如若想要按商品价格排序,需要实现复杂的排序算法
-
代码可读性和维护性降低:代码中充斥着底层数据结构管理逻辑,而非业务逻辑,降低了代码的可读性和未来的可维护性
综上所述,没有Java集合框架的支持,开发任务将变得繁琐且低效,不仅影响开发进度,也可能影响最终产品的稳定性和性能。
二,集合概览
集合是Java中极其高频使用的工具类,从接口到实现,形成了一个庞杂的体系,要掌握这个庞杂的体系,要避免盲人摸象的学习方法,先看一看大象完整的照片,知大象有四条腿、一个长鼻子、两只眼睛、两根象牙和一个庞大的身躯,然后再靠近观察研究细节!
那么集合这只大象的样子是什么呢?
1,最简化的集合体系

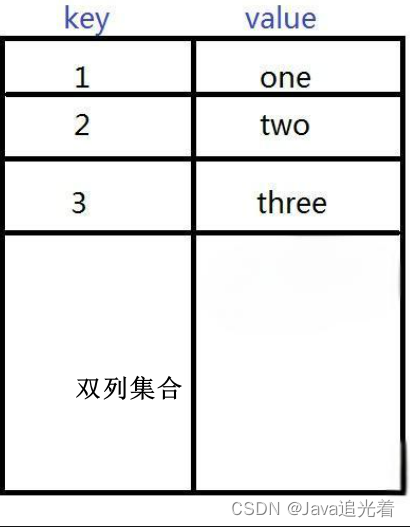
集合分为两种:
- 一种是
单列集合,称之为Collection,如下图,集合每个位置的元素是一个单值

- 一种是
双列集合,称之为Map,如下图,集合每个位置上的元素是一个键值对,注意一对相关联的key、value合称一个元素
2,完整的集合体系
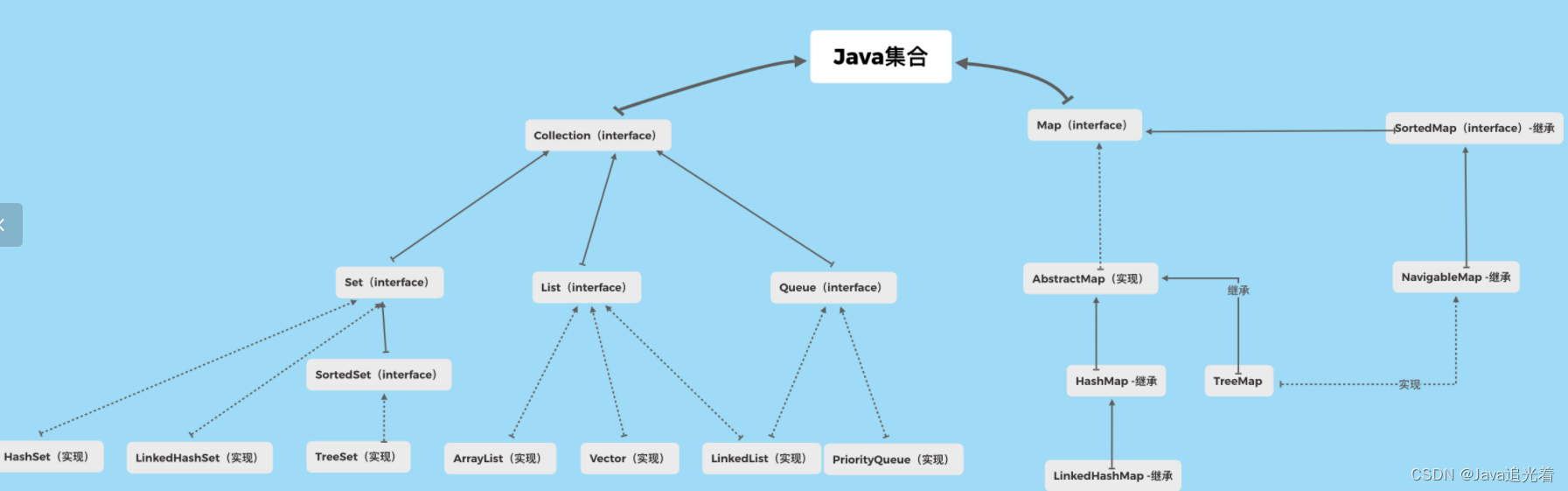
Java集合框架分为两大类:Collection 和 Map。
其中Collection又细分为List、Set和Queue:
List是有序的集合,即元素在List中的顺序和插入集合的先后顺序一致List中的元素可以重复,比如把数字1先后多次插入List集合中,插入多少次就保存多少个Set集合中的元素是无序的Set集合不可以重复,比如把数字1先后多次插入Set集合中,后插入的会覆盖先插入的,实际效果相当于仅插入一次Queue主要用于实现队列功能,遵循先进先出(FIFO)原则
继承体系简图
Collection
├── List
│ ├── ArrayList
│ ├── LinkedList
│ └── Vector
├── Set
│ ├── HashSet
│ ├── TreeSet
│ └── LinkedHashSet
└── Queue├── PriorityQueue└── Deque├── ArrayDeque└── LinkedList
Map
├── HashMap
├── TreeMap
└── LinkedHashMap
3,集合的主要操作
- 增删查改:
add(E element)、remove(Object o)、contains(Object o)、get(int index)/put(K key, V value) - 遍历:增强型for循环、迭代器(
Iterator)、Lambda表达式等 - 容量管理:如
ArrayList的ensureCapacity(int minCapacity)、trimToSize()
4,创建集合实现类示例
① LinkedList
import java.util.LinkedList;public class LinkedListDemo {public static void main(String[] args) {LinkedList<String> linkedList = new LinkedList<>();linkedList.add("Apple");linkedList.add("Banana");linkedList.addFirst("Cherry");System.out.println(linkedList); // 输出: [Cherry, Apple, Banana]linkedList.removeFirst();System.out.println(linkedList); // 输出: [Apple, Banana]}
}
LinkedList基于双向链表实现,每个节点包含前驱和后继节点的引用,这使得插入和删除操作非常高效(O(1)),特别是在列表的开始和结束。然而,由于需要遍历链表来访问元素,随机访问操作(如通过索引访问)效率较低(O(n))。与ArrayList相比,LinkedList更适合频繁的插入和删除操作,但在随机访问方面不如ArrayList高效。
② ArrayList
import java.util.ArrayList;public class ArrayListDemo {public static void main(String[] args) {ArrayList<String> arrayList = new ArrayList<>();arrayList.add("Apple");arrayList.add("Banana");arrayList.add(1, "Cherry");System.out.println(arrayList); // 输出: [Apple, Cherry, Banana]arrayList.set(0, "Orange");System.out.println(arrayList); // 输出: [Orange, Cherry, Banana]}
}
ArrayList基于动态数组实现,内部维护了一个可自动增长的数组来存储元素。这意味着它提供了快速的随机访问(通过索引,O(1)),但插入和删除操作(特别是位于数组中间的操作)可能较慢(O(n)),因为可能需要移动后续元素。与LinkedList相比,它在索引访问和遍历顺序元素方面更高效,但在频繁插入和删除的场景下不如LinkedList灵活。
③ Vector
import java.util.Vector;public class VectorDemo {public static void main(String[] args) {Vector<String> vector = new Vector<>(3);vector.add("Apple");vector.add("Banana");System.out.println(vector); // 输出: [Apple, Banana]}
}
Vector也是基于动态数组实现,与ArrayList相似,但其方法默认是线程安全的,通过同步机制确保了多线程环境下的安全访问。这增加了额外的性能开销,使得在单线程环境下,ArrayList通常比Vector更优。Vector在容量自动增长时,会增加当前容量的两倍,而ArrayList通常是1.5倍。一般情况下,不用Vector,因为其线程安全导致效率低。
④ HashSet
import java.util.HashSet;public class HashSetDemo {public static void main(String[] args) {HashSet<String> set = new HashSet<>();set.add("Apple");set.add("Banana");set.add("Apple"); // 重复元素,不会添加System.out.println(set); // 输出可能是 [Apple, Banana],顺序不确定}
}
: HashSet基于哈希表实现,使用hashCode()和equals()方法来确定元素的唯一性。它不保证元素的顺序,插入和查询操作平均时间复杂度为O(1),但最坏情况下(哈希冲突严重时)可能退化为O(n)。与TreeSet相比,它牺牲了排序特性,换取了更高的插入和查询性能。
⑤ TreeSet
import java.util.TreeSet;public class TreeSetDemo {public static void main(String[] args) {TreeSet<String> set = new TreeSet<>();set.add("Apple");set.add("Banana");set.add("Cherry");System.out.println(set); // 输出: [Apple, Banana, Cherry],自动排序}
}TreeSet基于红黑树实现,因此它能够对元素进行自然排序(根据元素的Comparable实现)或定制排序(通过Comparator)。插入、删除和查找操作的平均时间复杂度为O(log n),并保证了元素的有序性。与HashSet相比,它提供了排序功能,但牺牲了在无序集合中可能获得的更快的平均性能。
⑥ LinkedHashSet
import java.util.LinkedHashSet;public class LinkedHashSetDemo {public static void main(String[] args) {LinkedHashSet<String> set = new LinkedHashSet<>();set.add("Apple");set.add("Banana");set.add("Cherry");System.out.println(set); // 输出: [Apple, Banana, Cherry],保持插入顺序}
}
LinkedHashSet是HashSet的一个子类,它同时维护了一个双向链表来保持元素的插入顺序。因此,它既有HashSet的快速查找特性(基于哈希表),又保持了元素的插入顺序,类似于LinkedHashMap。相比于普通的HashSet,它提供了更好的迭代性能(特别是当频繁迭代且需要保持顺序时),但消耗了额外的内存。
⑦ PriorityQueue
import java.util.PriorityQueue;public class PriorityQueueDemo {public static void main(String[] args) {PriorityQueue<Integer> queue = new PriorityQueue<>();queue.add(5);queue.add(1);queue.add(3);System.out.println(queue.poll()); // 输出并移除最小元素: 1}
}
PriorityQueue是一个无界优先队列,它使用了堆数据结构(通常是二叉堆)来实现。这使得它能够高效地(O(log n))插入元素并返回队列中最小(或最大,取决于优先级比较器)的元素。与普通队列(FIFO)不同,PriorityQueue保证了队首元素始终是最优先的。它的实现不适合于随机访问,主要用于需要排序的插入和删除操作。
⑧ Deque
import java.util.ArrayDeque;public class ArrayDequeDemo {public static void main(String[] args) {ArrayDeque<String> deque = new ArrayDeque<>();deque.addFirst("Apple");deque.addLast("Banana");System.out.println(deque.pop()); // 输出并移除头部元素: Apple}
}
ArrayDeque(双端队列)基于可调整大小的环形数组实现,提供了两端高效的插入和删除操作(O(1)),同时支持作为栈(push/pop)和队列(addFirst/removeFirst)使用。它在大多数场景下比传统的LinkedList表现更优,特别是在频繁的两端操作时,因为它减少了内存分配的开销并优化了缓存局部性。
⑨ HashMap
import java.util.HashMap;public class HashMapDemo {public static void main(String[] args) {HashMap<String, Integer> map = new HashMap<>();map.put("Apple", 1);map.put("Banana", 2);System.out.println(map.get("Apple")); // 输出: 1}
}
HashMap基于哈希表实现,通过散列函数将键映射到数组的某个位置,以实现快速访问。它允许null键和null值,但不保证元素的顺序。插入、删除和查找操作的平均时间复杂度为O(1),在哈希冲突较少的情况下。与TreeMap相比,它放弃了排序功能,以换取更高的性能。
⑩ TreeMap
import java.util.TreeMap;public class TreeMapDemo {public static void main(String[] args) {TreeMap<String, Integer> map = new TreeMap<>();map.put("Apple", 1);map.put("Banana", 2);map.put("Cherry", 3);System.out.println(map.keySet()); // 输出: [Apple, Banana, Cherry],自动排序}
}
TreeMap基于红黑树实现,保证了键的自然排序或定制排序。它提供了对键的有序访问,并且所有键值对都按照键的排序顺序排列。插入、删除和查找操作的平均时间复杂度为O(log n)。与HashMap相比,它牺牲了快速的无序访问,但提供了排序和区间访问的能力。
⑪ LinkedHashMap
import java.util.LinkedHashMap;public class LinkedHashMapDemo {public static void main(String[] args) {LinkedHashMap<String, Integer> map = new LinkedHashMap<>();map.put("Apple", 1);map.put("Banana", 2);map.put("Cherry", 3);System.out.println(map.entrySet()); // 输出: 保持插入顺序}
}
LinkedHashMap继承自HashMap,并在其基础上增加了双向链表来维护元素的插入顺序或访问顺序(取决于构造参数)。这使得它既能提供快速的访问性能,又能维持元素的插入或访问顺序。与普通HashMap相比,它更适合那些需要按插入或访问顺序遍历键值对的场景,但会消耗更多内存。与TreeMap相比,它不提供键的自然排序。