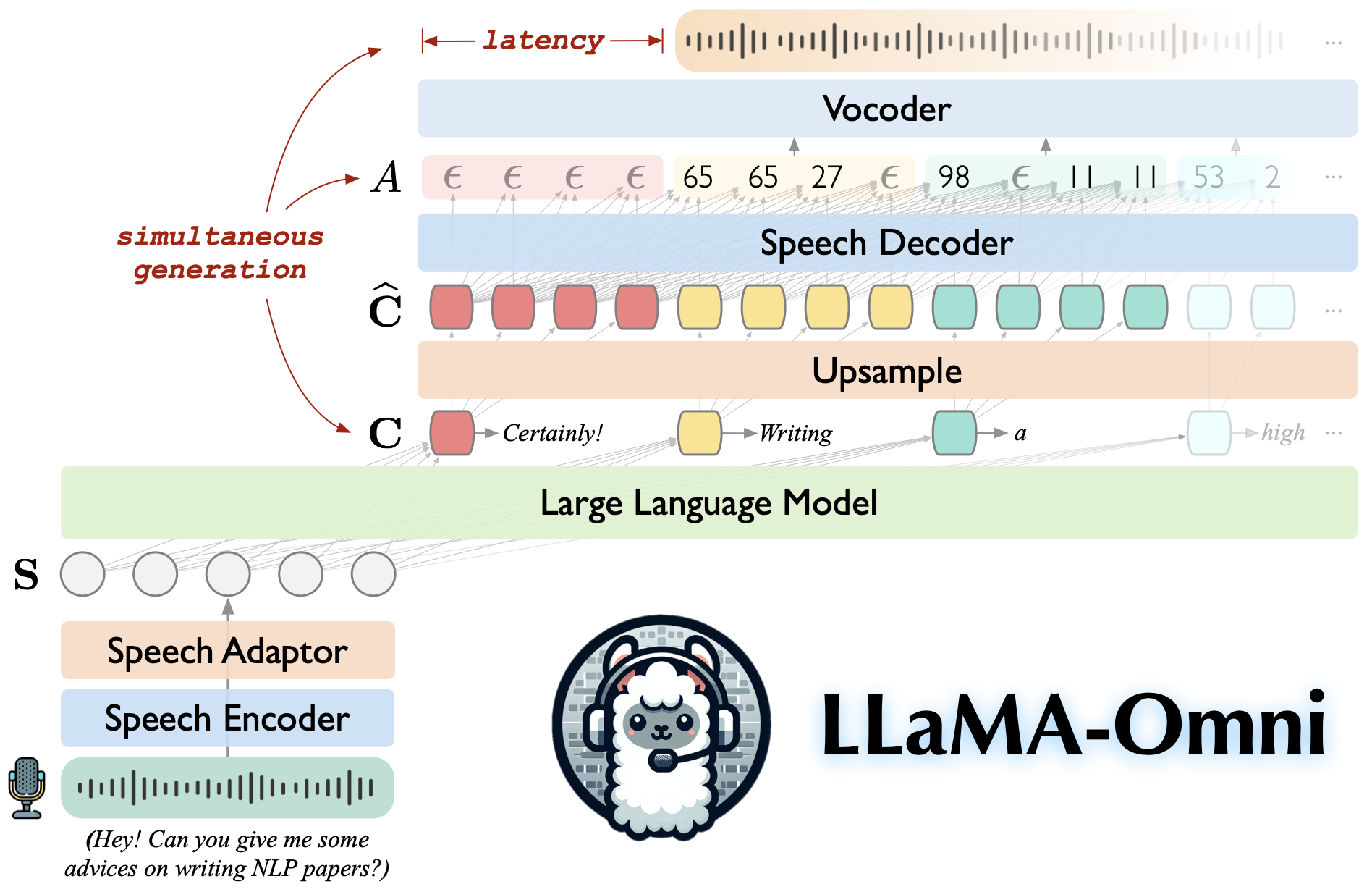
说明
在进行ocr文字识别的时候,有时候我们需要使用批量测试的功能,但是有些图片会识别失败或者个别根本识别不出来,这时候我们可以通过对原图片进行缩放,提高图像的分辨率,然后再次识别,这样可以大大提高图片文字识别的精度。
示例代码
# -*- coding='utf-8' -*-
'''
功能:将要识别的目录中的图片进行缩放后,再次使用ocr模型批量识别,并统计识别不成功的数目
'''
import os
from paddleocr import PaddleOCR, draw_ocr
from PIL import Image
import cv2def enlarge_images(input_folder, output_folder, scale_factor=2.0):# 检查输出文件夹是否存在,如果不存在则创建if not os.path.exists(output_folder):os.makedirs(output_folder)# 遍历输入文件夹中的所有文件for filename in os.listdir(input_folder):# 构建完整的文件路径file_path = os.path.join(input_folder, filename)# 检查文件是否为图像文件(例如,jpg, png 格式)if file_path.lower().endswith(('.png', '.jpg', '.jpeg', '.bmp', '.tiff', '.gif')):# 读取图像image = cv2.imread(file_path)if image is None:print(f"无法读取图像文件: {file_path}")continue# 获取图像的原始尺寸height, width = image.shape[:2]#image = image[int(0.4*height):int(0.8*height),int(0.15*width):int(0.85*width)]# 计算放大后的尺寸new_width = int(width * scale_factor)new_height = int(height * scale_factor)dsize = (new_width, new_height)# 放大图像resized_image = cv2.resize(image, dsize, interpolation=cv2.INTER_LINEAR)# 构建输出文件路径output_file_path = os.path.join(output_folder, filename)# 保存放大的图像cv2.imwrite(output_file_path, resized_image)print(f"已保存放大的图像: {output_file_path}")# 使用实例
input_folder = './images' # 输入文件夹路径
output_folder ='./imagesAfter' # 输出文件夹路径
# 对图片进行缩放,可以设置缩放倍数,默认缩放倍数为2
enlarge_images(input_folder, output_folder, scale_factor=3.0)# 初始化 PaddleOCR,使用英文和中文模型
ocr = PaddleOCR(use_angle_cls=True, lang='en') # 定义图片文件夹要识别的图片路径
image_folder = output_folder# 获取文件夹中所有图片文件名
image_files = [f for f in os.listdir(image_folder) if os.path.isfile(os.path.join(image_folder, f))]
count = 0
# 遍历每张图片进行识别
for image_file in image_files:try:image_path = os.path.join(image_folder, image_file)print(image_path)# 进行OCR识别result = ocr.ocr(image_path, cls=True)print('识别结果为:',result )if result[0]==None:count = count+1# 打印识别结果for line in result:print(f"File: {image_file}")for res in line:print(res)# 可视化识别结果# 显示原图image = Image.open(image_path).convert('RGB')boxes = [elements[0] for elements in result[0]] txts = [elements[1][0] for elements in result[0]]scores = [elements[1][1] for elements in result[0]]'''# 显示结果im_show = draw_ocr(image, boxes, txts, scores, font_path='./simfang.ttf')im_show = Image.fromarray(im_show)im_show.show()'''print(txts)except:pass
print('count的个数:',count)结果: