🌍AI预测极端天气提速5000倍!微软发布Aurora,借AI之眼预测全球风暴
🎄理解老司机,超越老司机!LeapAD:具身智能加持下的双过程自驾系统(上海AI Lab等)
- 论文题目:Continuously Learning, Adapting, and, Improving: A Dual-Process Approach to Autonomous Driving
- 论文发表单位:浙江大学,上海人工智能实验室,华东师范大学
- 论文地址:https://arxiv.org/abs/2405.15324
- 代码地址:https://github.com/PJLab-ADG/LeapAD
✨ICML2024高分!魔改注意力,让小模型能打两倍大的模型
1.自动化所研发脉冲动态计算的毫瓦级超低功耗异步感算一体类脑芯片
人脑能够运行非常复杂且庞大的神经网络,总功耗却仅为20瓦,远小于现有的人工智能系统。因此,在算力比拼加速,能耗日益攀升的今日,借鉴人脑的低功耗特性发展新型智能计算系统成为极具潜力的方向。
近日,中国科学院自动化研究所李国齐、徐波课题组与时识科技公司等单位合作设计了一套能够实现动态计算的算法-软件-硬件协同设计的类脑神经形态SOC(System on Chip,系统级芯片)Speck,展示了类脑神经形态计算在融合高抽象层次大脑机制时的天然优势,相关研究在线发表于《自然·通讯》(Nature Communications)。

该研究提出了“神经形态动态计算”的概念,通过设计了一种类脑神经形态芯片Speck来实现基于注意力机制的动态计算,在硬件层面做到“没有输入,没有功耗”,在算法层面做到“有输入时,根据输入重要性程度动态调整计算”,从而在典型视觉场景任务功耗可低至0.7毫瓦,进一步挖掘了神经形态计算在性能和能效上的潜力。
Speck是一款异步感算一体类脑神经形态SoC,采用全异步设计,在一块芯片上集成了动态视觉传感器(DVS相机)和类脑神经形态芯片,具有极低的静息功耗(仅为0.42毫瓦)。Speck能够以微秒级的时间分辨率感知视觉信息,以全异步方式设计抛弃了全局时钟控制信号,避免时钟空翻带来的能耗开销,仅在有事件输入时才触发稀疏加法运算。
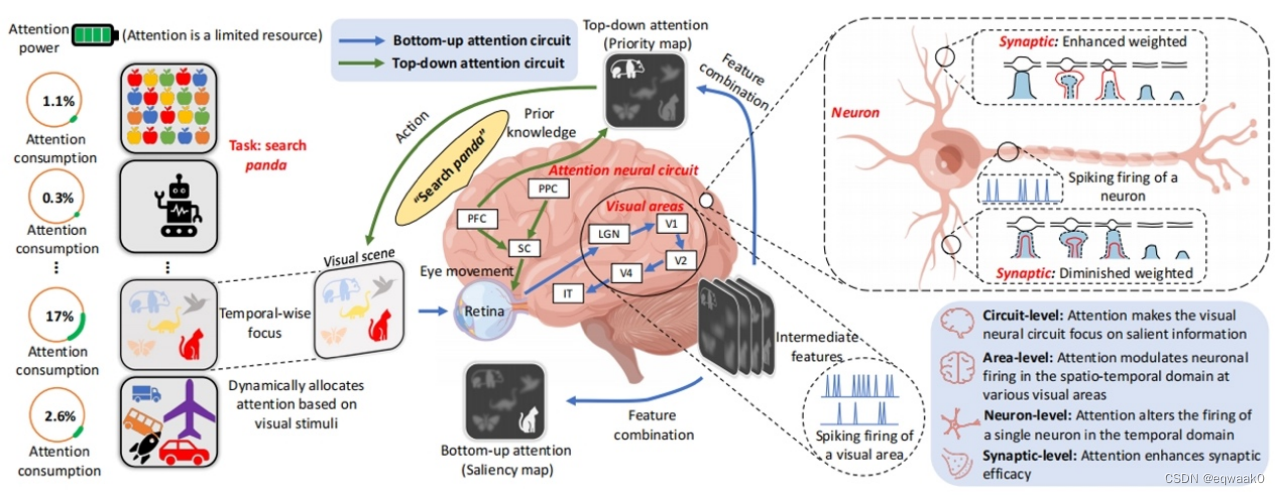
针对脉冲神经网络(SNN)在更高层面,比如时间维度中不能根据输入难易度调整其脉冲发放等“动态失衡”问题,该研究基于注意力机制的神经形态脉冲动态计算框架(图2),在多种粒度上实现对不同的输入进行有区分地动态响应;同时Speck软件工具链Sinabs编程框架支持动态计算SNN算法训练和部署。实验结果表明,注意力机制可使得SNN具备动态计算能力,即根据输入难易度调整其脉冲发放模式解决“动态失衡”问题,在显著降低功耗的同时,提升任务性能。在DVS128 Gesture数据集上,融合脉冲动态计算的Speck在任务精度提升9%的同时,平均功耗由9.5毫瓦降低至3.8毫瓦(图3)。
该工作的实践证实高、低抽象层次大脑机制的融合能进一步激发类脑计算潜力,为未来将大脑进化过程中产生的各种高级神经机制融合至神经形态计算提供积极启发。
相关工作得到了国家杰出青年科学基金、北京市杰出青年基金、国家自然科学基金委重点项目、区域创新联合重点项目等项目的支持。
2.再战Transformer!原作者带队的Mamba 2来了,新架构训练效率大幅提升
自 2017 年被提出以来,Transformer 已经成为 AI 大模型的主流架构,一直稳居语言建模方面 C 位。
但随着模型规模的扩展和需要处理的序列不断变长,Transformer 的局限性也逐渐凸显。一个很明显的缺陷是:Transformer 模型中自注意力机制的计算量会随着上下文长度的增加呈平方级增长。
几个月前,Mamba 的出现打破了这一局面,它可以随上下文长度的增加实现线性扩展。随着 Mamba 的发布,这些状态空间模型 (SSM) 在中小型规模上已经实现了与 Transformers 匹敌,甚至超越 Transformers。
Mamba 的作者只有两位,一位是卡内基梅隆大学机器学习系助理教授 Albert Gu,另一位是 Together.AI 首席科学家、普林斯顿大学计算机科学助理教授 Tri Dao。
Mamba 面世之后的这段时间里,社区反应热烈。可惜的是,Mamba 的论文却惨遭 ICLR 拒稿,让一众研究者颇感意外。
仅仅六个月后,原作者带队,更强大的 Mamba 2 正式发布了。

-
论文地址:https://arxiv.org/pdf/2405.21060
-
GitHub 地址:https://github.com/state-spaces/mamba
-
论文标题:Transformers are SSMs: Generalized Models and Efficient Algorithms Through Structured State Space Duality
总体而言,本文提出了 SSD(state space duality)框架,基于此,研究者设计了一个新的体系架构 Mamba-2,其核心层是对 Mamba 的选择性 SSM 的改进,速度提高了 2-8 倍,同时在语言建模方面继续与 Transformers 竞争。
Tri Dao 表示,他们构建了一个丰富的 SSD 理论框架,许多线性注意力变体和 SSM 是等效的,由此产生的模型 Mamba-2 比 Mamba-1 更好、更快。

Mamba-2 的新算法使其能够利用更大的状态维度 (16 → 256),同时训练速度更快。在需要更大状态容量的任务上,例如 MQAR 任务,它比 Mamba-1 有了显著的改进。
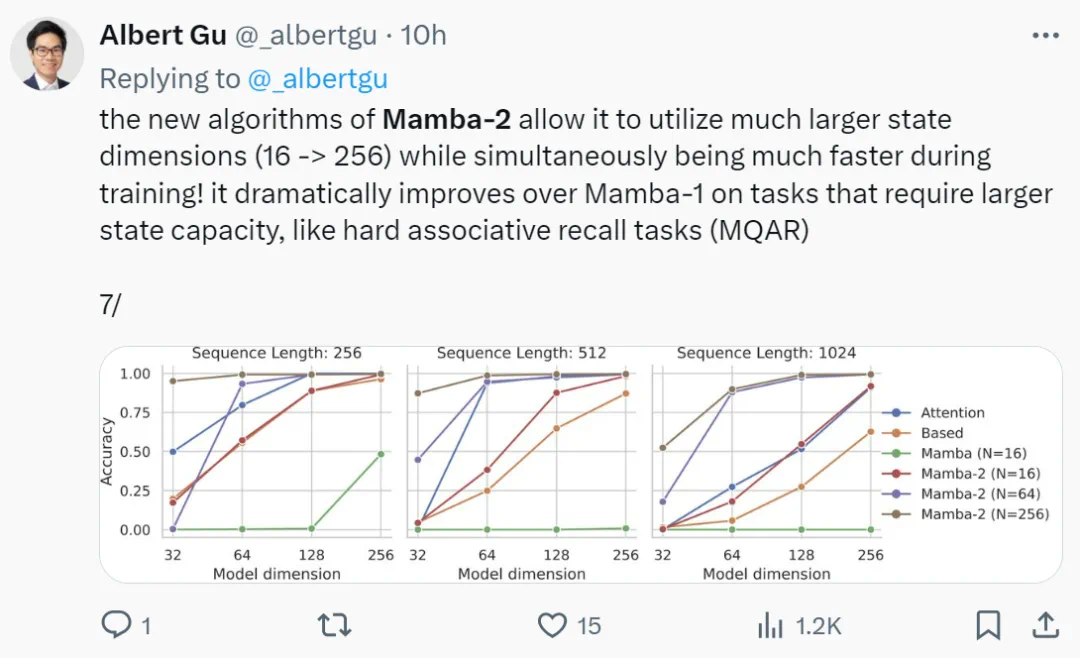
此外研究者还发现,最近新出的混合模型(Jamba、Zamba)增加了一些注意力层来提高模型质量。基于这些发现,研究者将 4-6 个注意力层与 Mamba-2 层混合,其表现优于 Transformer++ 和纯 Mamba-2,因而得出注意力和 SSM 是互补的。

这项研究的贡献概括为:
本文展示了状态空间模型与一类称为半可分矩阵的结构化矩阵族之间的等价性。这一联系是 Mamba-2 框架的核心,揭示了状态空间模型的新属性和算法。
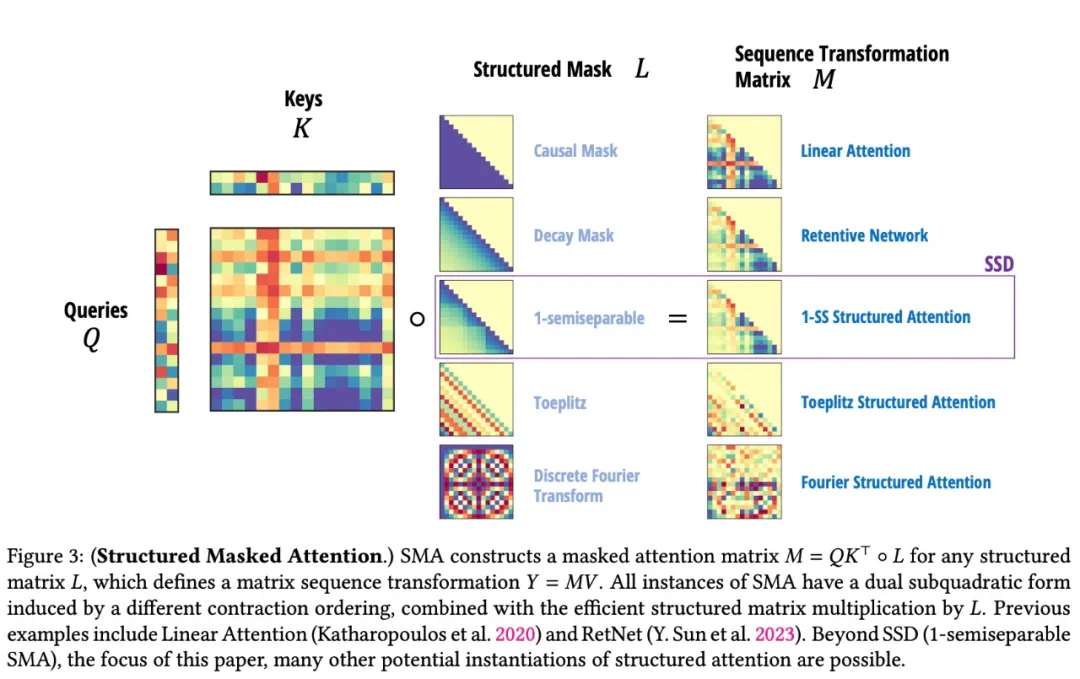
本文显著改进了线性注意力理论,首先通过张量收缩的语言对其循环形式提供了一个明确的证明,然后将其推广到一种新的结构化掩码注意力(SMA)家族。
本文将 SSM(状态空间模型)和 SMA(结构化掩码注意力)联系起来,显示它们有一个很大的交集,彼此是对偶的,同时具有 SSM 式的线性形式和类似注意力的二次方形式。本文还证明了任何具有快速循环形式的核注意方法都是 SSM。
除了内在的理论价值外,研究者所提出的框架为理解和改进序列模型开辟了广阔的方向。
在算法层面。所提框架为计算 SSM 提供了新的高效且易于实现的算法。本文提出了一种基于半可分离矩阵块分解的 SSD 算法,该算法利用了 SSM 线性递推和二次对偶形式,在所有主要效率轴上获得了最优的权衡。基于 SSD 的实现比 Mamba 的优化选择性扫描实现快 2 到 8 倍,同时允许使用更大的循环状态大小(是 Mamba 的 8 倍甚至更高,且几乎不影响速度)。SSD 与优化过的 softmax 注意力实现(FlashAttention-2)具有高度竞争力,在序列长度 2k 时性能相当,在序列长度 16K 时速度快 6 倍。
架构设计。采用 SSM 等新架构的一个主要障碍是针对 Transformers 量身定制的生态系统,例如用于大规模训练的硬件高效优化和并行技术。本文框架允许使用已建立的惯例和技术来构建 SSM 的架构设计选择词汇表,并进一步改进它们。
本文还对 Mamba 块做了一些修改,这些修改允许实现张量并行,其主要思想包括引入分组值注意力 (GVA,grouped-value attention) 头结构。
将修改后的并行 Mamba 块与作为内部 SSM 层的 SSD 结合使用,形成了 Mamba-2 架构。研究者在与 Mamba 相同的设置中研究了 Mamba-2 的 Chinchilla 扩展法则,发现它在困惑度和实际运行时间方面均优于 Mamba 和 Transformer++。研究者还在 Pile 数据集上训练了一系列 Mamba-2 模型,结果显示 Mamba-2 在标准下游评估中匹配或超过 Mamba 和开源的 Transformers。例如,在 Pile 上训练了 3000 亿 token 的 2.7B 参数的 Mamba-2 在性能上超过了在同一数据集上训练的 2.8B 参数的 Mamba 和 Pythia 以及 6.9B 参数的 Pythia。
系统优化:SSD 框架连接 SSM 和 transformer,允许利用为 transformer 开发的丰富的系统优化工作。
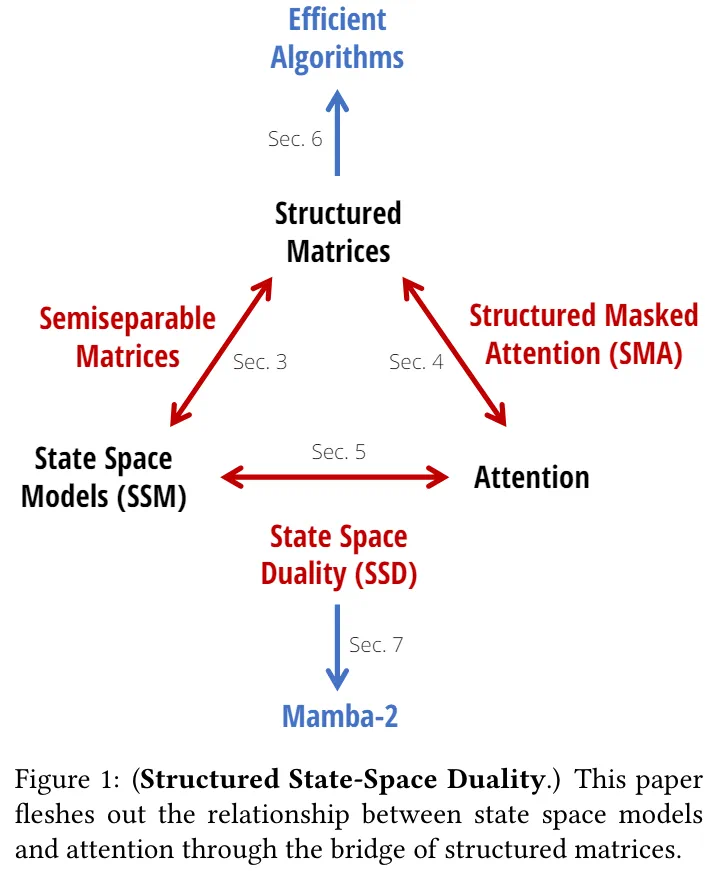
SSD 层
Mamba-2 的核心贡献是新的 SSD(state space dual)层。SSD 层可以被定义为选择性 SSM 的特例。与 Mamba 相比,Mamba-2 的改动会略微降低表达能力,但却显著提高了训练效率,特别是允许在现代加速器上使用矩阵乘法单元。
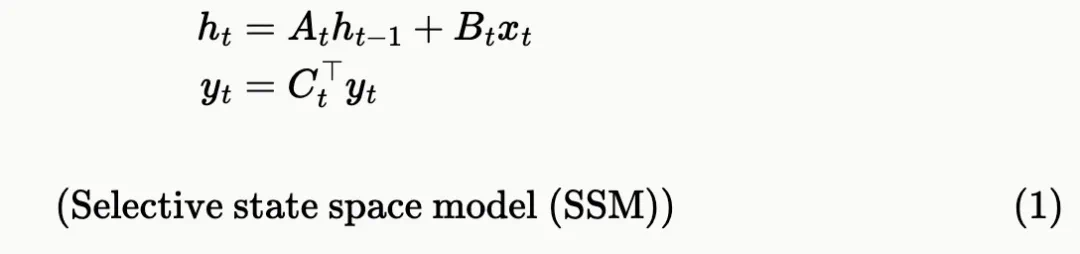
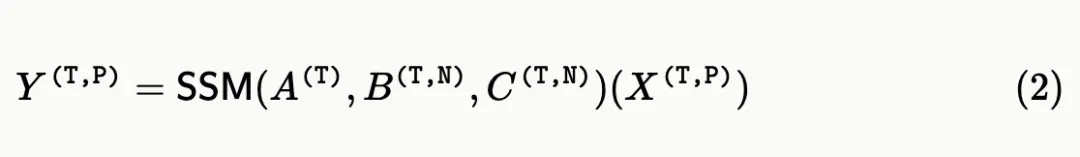
SSD 层的对偶注意力:
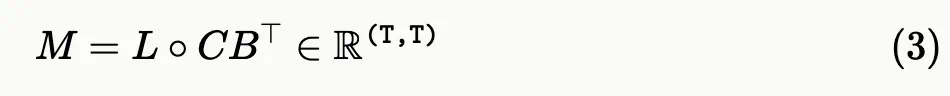
除了最新的 SSD 层,研究者也对 Mamba 的神经网络架构做了一些小的改变,Mamba-2 架构如下所示。
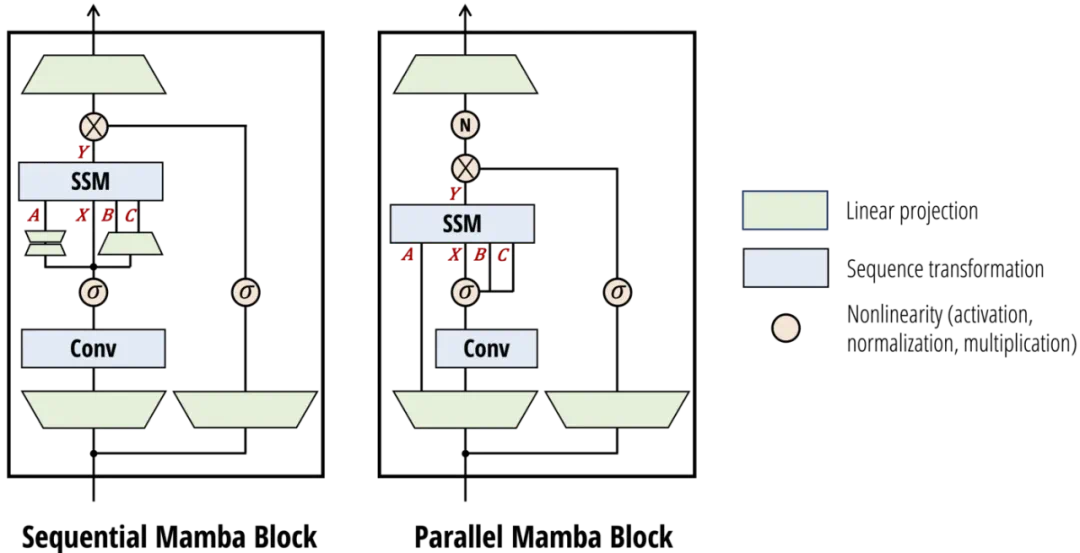
Mamba-2 在网络架构上的主要变化是从顺序生成变为并行生成 SSM 参数,并且 Mamba-2 更适合张量并行等扩展方法。
通过提供状态空间模型的显式矩阵变换形式,研究团队揭示了理解和使用它们的新方法。从计算的角度来看,任何计算状态空间模型前向传播的方法都可以看作是半可分离矩阵上的矩阵乘法算法。半可分离矩阵视角为 SSD 提供了一个视角,其中双重模式分别指的是线性时间半可分离矩阵乘法算法和二次时间朴素矩阵乘法。
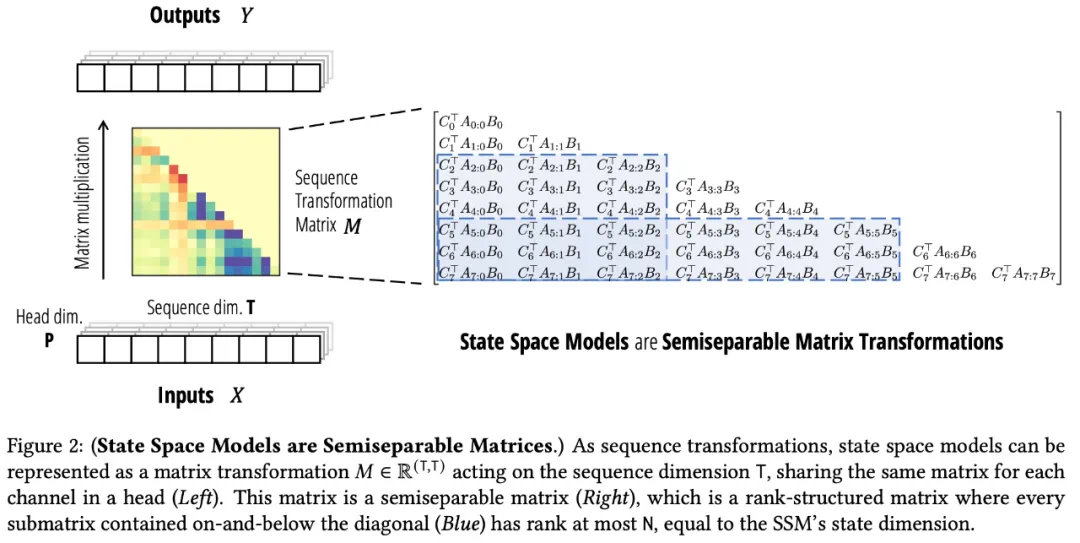
研究团队定义了结构化状态空间模型和结构化注意力,讨论了它们的属性,并表明它们都有二次算法和线性算法。
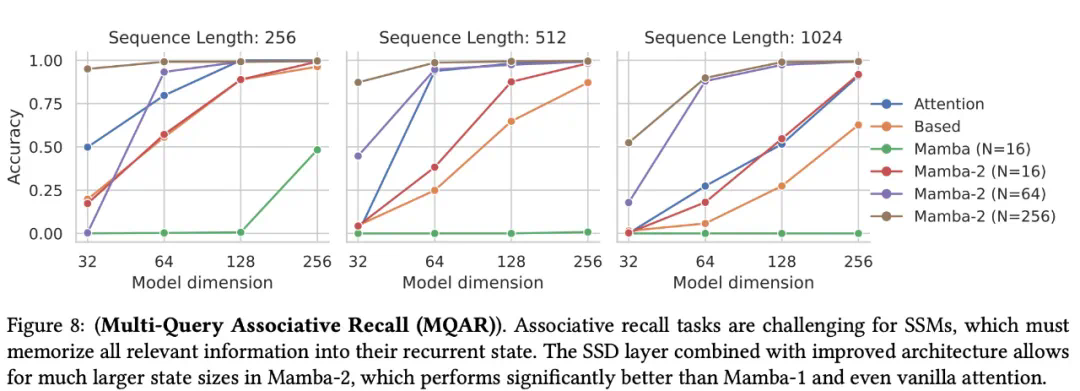
自最初的 Mamba 论文研究了合成任务 —— 如:合成复制和归纳 Head 以来,许多后续工作开始研究更难的关联回忆任务。由 Zoology 和 Based 系列工作引入的 MQAR(multi-query associative recall)任务已成为事实上的标准。
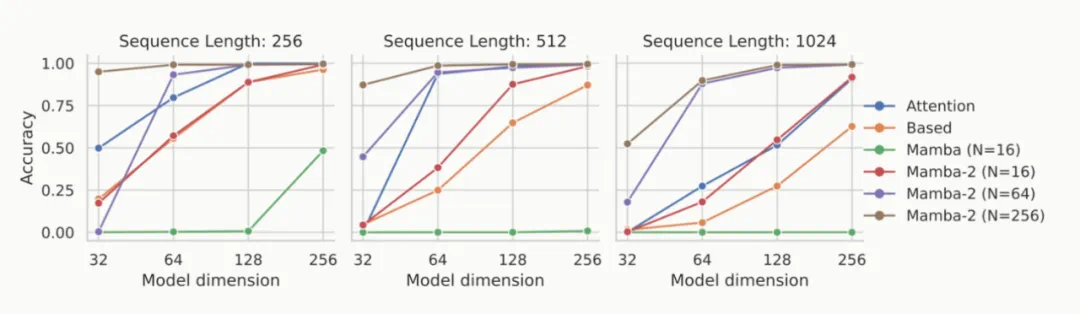
通过运行一个比文献中通常报告的版本要难得多的任务,该团队发现 Mamba-2 明显优于 Mamba-1,而改善性能的一个原因是状态大小(比 Mamba-1 大约 16 倍)。
在这篇文章中,作者深入探讨了模型背后的理论。
从两个完全不同的角度推导出 SSD 的「对偶性」:
-
一个从 SSM 的角度出发;
-
另一个从注意力机制的角度出发。
SSD 框架提供了状态空间模型、注意力机制和结构化矩阵之间丰富的联系。
虽然 SSD 模型可以被视为框架内每个分支的具体实例,但 SSD 框架本身更加通用,为未来的工作开辟了许多方向。
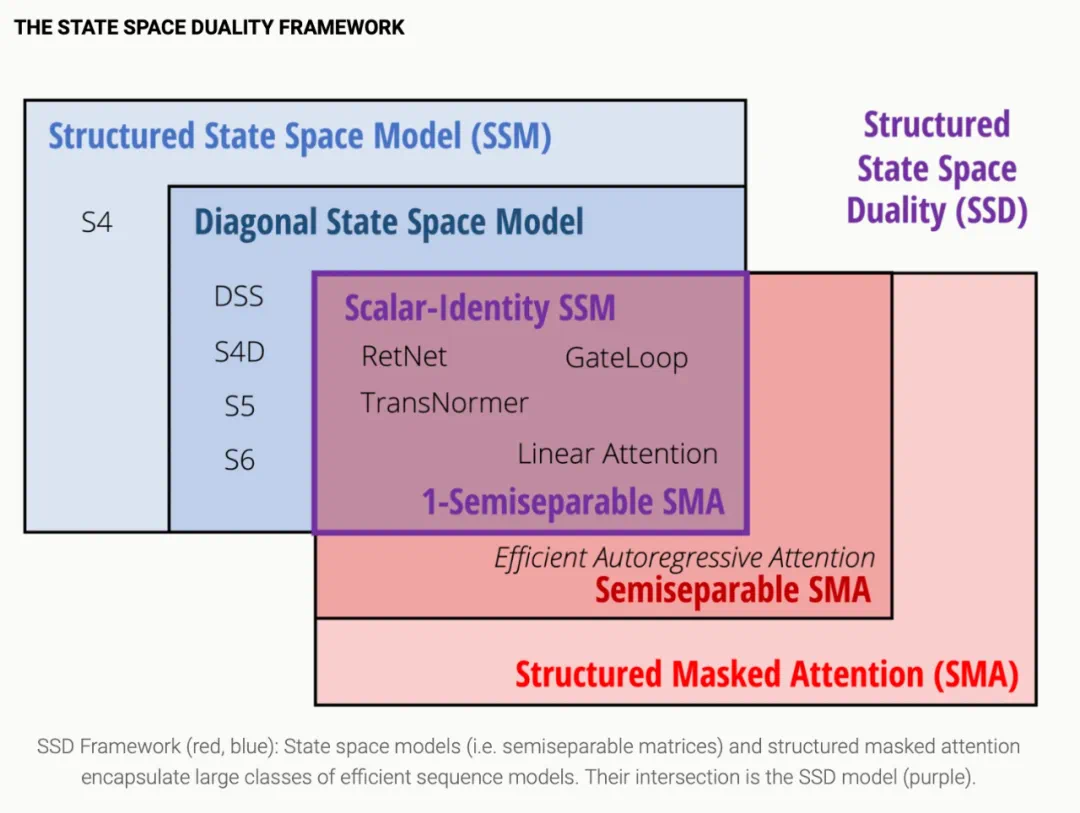
SSD 框架(红色,蓝色):状态空间模型(即半可分矩阵)和结构化掩码注意力机制包含了大量高效的序列模型。它们的交集是 SSD 模型(紫色)。
SSD 算法
通常,矩阵乘法(matmul)的 FLOPs 速度要比非矩阵乘法 FLOPs 快得多(高达 16 倍):A100 GPU 具有 312 TFLOPS 的 BF16 矩阵乘法性能,但只有 19 TFLOPS 的 FP32 算术性能,而 H100 具有 989 TFLOPS 的 BF16 矩阵乘法性能,但只有 67 TFLOPS 的 FP32 算术性能。
Mamba-2 的主要目标之一是「利用张量核心加速 SSM」。
在绑定参数并引入 Head 结构后,Mamba-1 中的 SSM 变成了 SSD,这是一种更具限制性的形式,具有类似注意力的公式。并且由于 SSD 连接 SSM 和结构化矩阵,计算 SSM 的高效算法直接对应于「token-mixing」或「sequence-mixing」矩阵 M 的不同分解。
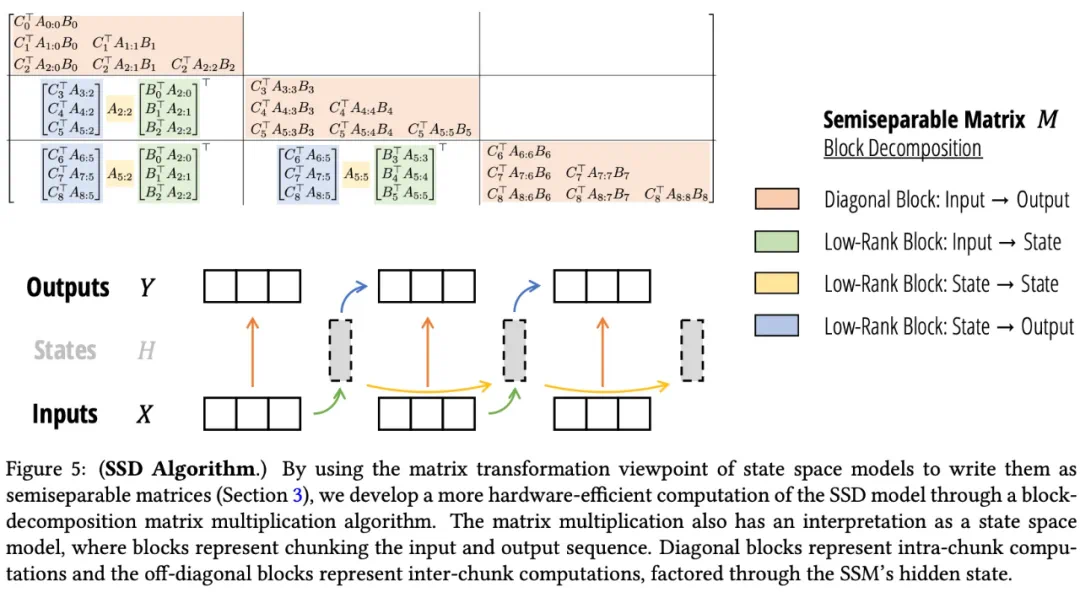
因此,可以通过寻找替代的矩阵乘法方式,例如通过各种方式对其进行分解,从而创建计算 SSM 的新算法。
通过精心选择块大小,对这个矩阵进行简单块分解,就可以集 SSD 线性递归和二次注意力对偶形式的两种优势于一身。
而这也就是 SSD 算法的起源,它有 4 个步骤,并且对于这个算法有两种完全不同的诠释。
SSD 算法:分块矩阵分解
首先将半可分 SSM 矩阵划分为大小为 Q×Q 的块,然后,利用半分矩阵的性质来分解每个低秩的非对角块:
-
(橙色)每个对角块是一个更小的半可分矩阵,可以以喜欢的方式计算这个乘法,特别是使用 SSD 的二次(类似注意力机制)形式。
-
(绿色)总共有 T/Q 个不同的绿色块,通过批处理矩阵乘法来计算。
-
(黄色)注意,黄色项本身是一个 1 - 半可分矩阵,这一步等价于对某些修改后的 A 因子的 SSM 扫描。
-
(蓝色)与绿色类似,通过批处理矩阵乘法来计算。
SSD 算法:分块和状态传递
该算法的另一种诠释涉及「推理 SSM 如何在实际序列上进行操作」。
首先将输入序列分割成大小为 Q 的块,步骤可以分为:
-
分块内部输出:计算每个块的局部输出(假设初始状态(对于块)为 0,则每个块的输出是多少?)
-
块状态:计算每个块的最终状态(假设初始状态(对于块)为 0,则每个块的最终状态是多少?)
-
传递状态:计算所有块的最终状态的递归 - 使用任何所需的算法,例如并行或顺序扫描(考虑到所有先前输入,每个块的实际最终状态是多少?)
-
输出状态:对于每个块,根据其真实的初始状态(在步骤 3 中计算),仅从初始状态得出的输出计算贡献
可以看到,大部分算法(步骤 1、2 和 4)利用了矩阵乘法(因此利用了张量核心),而且可以并行计算。
只有步骤 3 需要扫描,但它只操作一个非常短的序列,通常只需要很少时间。
系统及扩展优化
张量并行
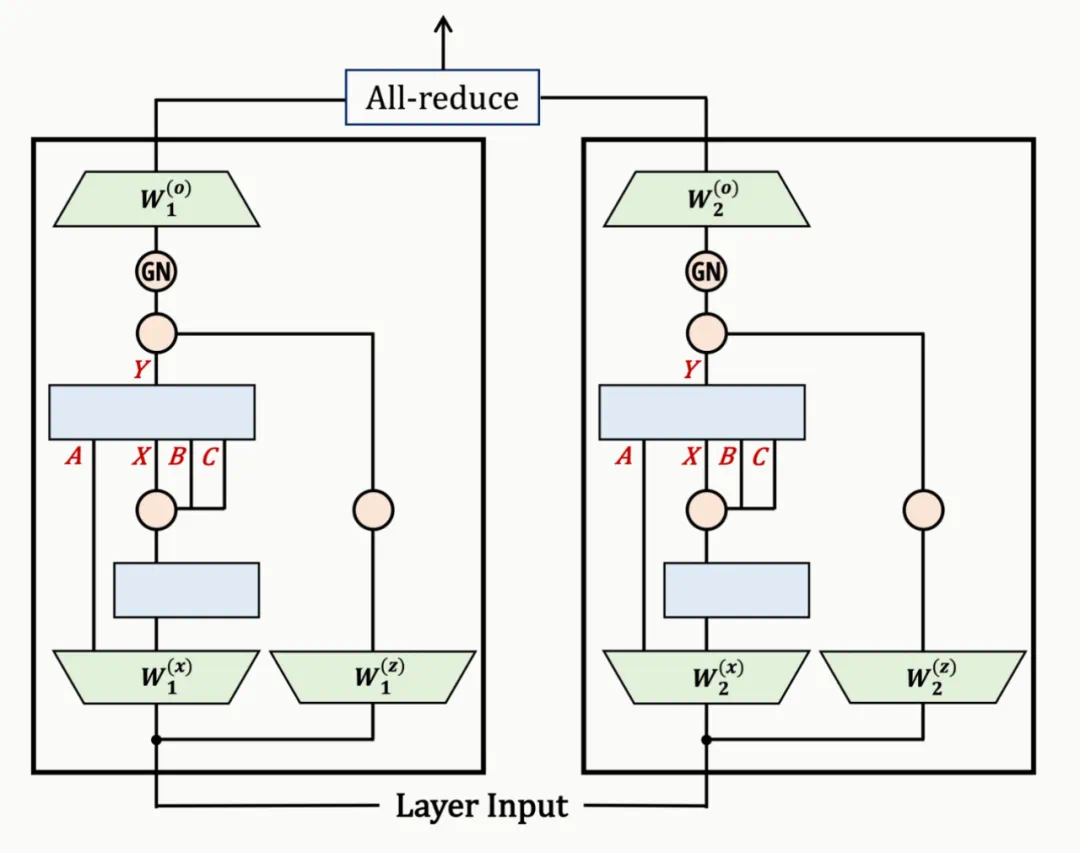
使用张量并行对 Mamba-1 进行大规模训练的一项困难是,每层都需要 2 次 all-reduce,而在 Transformer 中,每个注意力或 MLP 层只需 1 次 all-reduce。这是因为 SSM 的一些参数是内部激活的函数,而不是层的输入函数。在 Mamba-2 中,由于采用了「并行投影」结构,所有 SSM 参数都是层输入的函数,因此可以轻松地将张量并行应用于输入投影:将输入投影和输出投影矩阵分割成 2、4、8 个碎片,具体取决于张量并行度。研究者使用 grouped norm,分组数除以张量并行度,这样每个 GPU 都能单独完成归一化。这些变化导致每层只需 1 次 all-reduce,而不是 2 次。
序列并行
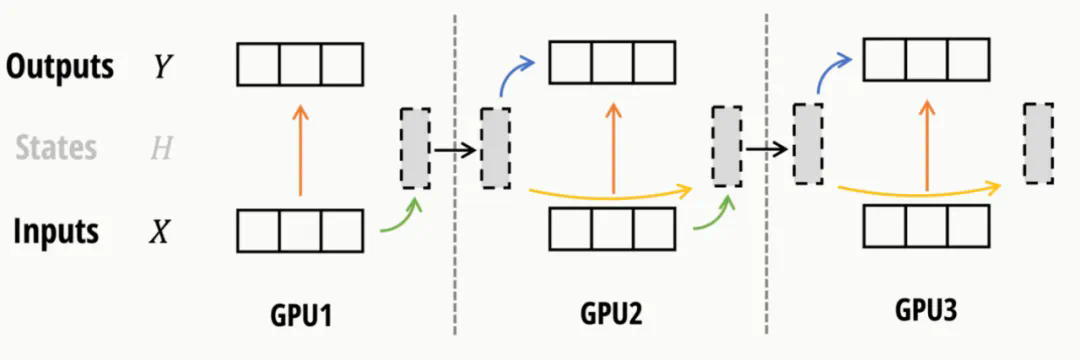
在对超长序列进行训练时,可能需要沿着序列长度进行分割,并将不同部分分配给不同的设备。序列并行主要有两种形式:对于残差和归一化操作,用 reduce-scatter、残差 + 归一化、然后 all-gather,取代张量并行中的 all-reduce。由于 Mamba-2 使用与 Transformer 相同的残差和归一化结构,因此这种形式的序列并行无需修改即可直接应用。对于注意力或 SSM 操作,又称上下文并行(CP)。对于注意力,可以使用环形注意力沿序列维度进行分割。对于 Mamba-2,SSD 框架再次提供了帮助:使用相同的蒯分解,可以让每个 GPU 计算其本地输出和最终状态,然后在更新每个 GPU 的最终输出之前,在 GPU 之间传递状态(使用发送 / 接收通信原语)。
实验结果
该研究在 MQAR 的一种具有挑战性的版本上,使用更难的任务、更长的序列和更小的模型进行了对比实验。基线包括标准的多头 softmax 注意力以及 Based 架构,实验结果如图 8 所示。
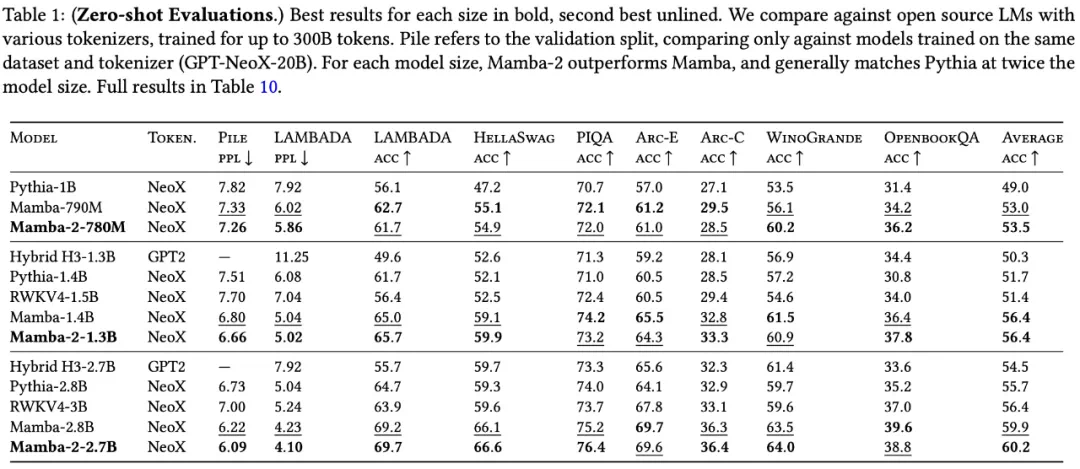
下表显示了 Mamba-2 在一系列下游零样本评估任务上的性能:
3.Python实现策略模式、观察者模式和责任链模式
1.策略模式
策略模式是一种行为设计模式,它允许在运行时选择算法的行为。它将算法封装在独立的策略类中,使得它们可以互相替换,而不会影响到客户端代码。在Python中,我们可以使用函数或者类来实现策略模式。
(1) 策略模式的结构
策略模式的核心是定义一个策略接口,所有的具体策略都要实现这个接口。然后,我们可以在客户端代码中使用策略对象,而不需要关心具体的实现细节。
以下是策略模式的基本结构:
# 策略接口
class Strategy:def do_operation(self):pass# 具体策略类
class ConcreteStrategyA(Strategy):def do_operation(self):print("执行策略A的操作")class ConcreteStrategyB(Strategy):def do_operation(self):print("执行策略B的操作")# 上下文类
class Context:def __init__(self, strategy):self.strategy = strategydef execute_strategy(self):self.strategy.do_operation()# 客户端代码
if __name__ == "__main__":strategy_a = ConcreteStrategyA()strategy_b = ConcreteStrategyB()context = Context(strategy_a)context.execute_strategy()context.strategy = strategy_bcontext.execute_strategy()(2) 策略模式的应用场景
策略模式适用于以下场景:
- 当一个系统有多个算法,并且需要在运行时根据不同情况选择其中一个算法时。
- 当一个类有多个行为,并且这些行为可以通过继承来扩展时。
- 当一个类的行为在运行时可以动态改变时。
(3) 策略模式的优点
- 策略模式将算法的实现与使用算法的客户端代码分离,使得它们可以独立地变化。
- 策略模式遵循开闭原则,新的策略可以很容易地添加到系统中,而不会影响到原有的代码。
(4) 策略模式的缺点
- 策略模式增加了系统中类的数量,增加了代码的复杂度。
- 客户端需要了解所有的策略类,才能选择合适的策略。
2.观察者模式
它定义了一种一对多的依赖关系,让多个观察者对象同时监听一个主题对象。当主题对象的状态发生变化时,它会通知所有的观察者对象,使得它们能够自动更新。
(1) 观察者模式的结构
观察者模式的核心是主题对象和观察者对象之间的关系。主题对象维护一个观察者列表,当主题对象的状态发生变化时,它会遍历观察者列表,通知每个观察者对象进行更新。
以下是观察者模式的基本结构:
# 主题接口
class Subject:def attach(self, observer):passdef detach(self, observer):passdef notify(self):pass# 具体主题类
class ConcreteSubject(Subject):def __init__(self):self.observers = []def attach(self, observer):self.observers.append(observer)def detach(self, observer):self.observers.remove(observer)def notify(self):for observer in self.observers:observer.update()# 观察者接口
class Observer:def update(self):pass# 具体观察者类
class ConcreteObserverA(Observer):def update(self):print("观察者A收到通知")class ConcreteObserverB(Observer):def update(self):print("观察者B收到通知")# 客户端代码
if __name__ == "__main__":subject = ConcreteSubject()observer_a = ConcreteObserverA()observer_b = ConcreteObserverB()subject.attach(observer_a)subject.attach(observer_b)subject.notify()subject.detach(observer_b)subject.notify()(2) 观察者模式的应用场景
观察者模式适用于以下场景:
- 当一个对象的改变需要同时改变其他对象时。
- 当一个对象的改变需要通知一组对象时。
- 当一个对象的改变需要让其他对象自动更新时。
(3) 观察者模式的优点
- 观察者模式将主题对象和观察者对象解耦,使得它们可以独立地变化。
- 观察者模式遵循开闭原则,新的观察者可以很容易地添加到系统中,而不会影响到原有的代码。
(4) 观察者模式的缺点
- 观察者模式可能会导致系统中观察者对象过多,增加了代码的复杂度。
- 观察者模式中,观察者对象与主题对象之间存在循环依赖的关系,可能会导致循环引用的问题。
3.责任链模式
它将请求的发送者和接收者解耦,使得多个对象都有机会处理请求。将这些对象串成一条链,并沿着这条链传递请求,直到有一个对象能够处理它为止。
(1) 责任链模式的结构
责任链模式的核心是责任链对象和处理对象之间的关系。责任链对象维护一个处理对象列表,当收到请求时,它会遍历处理对象列表,直到找到能够处理请求的对象。
以下是责任链模式的基本结构:
# 处理对象接口
class Handler:def set_successor(self, successor):passdef handle_request(self, request):pass# 具体处理对象类
class ConcreteHandlerA(Handler):def __init__(self):self.successor = Nonedef set_successor(self, successor):self.successor = successordef handle_request(self, request):if request == "A":print("处理对象A处理请求")elif self.successor is not None:self.successor.handle_request(request)class ConcreteHandlerB(Handler):def __init__(self):self.successor = Nonedef set_successor(self, successor):self.successor = successordef handle_request(self, request):if request == "B":print("处理对象B处理请求")elif self.successor is not None:self.successor.handle_request(request)# 客户端代码
if __name__ == "__main__":handler_a = ConcreteHandlerA()handler_b = ConcreteHandlerB()handler_a.set_successor(handler_b)handler_a.handle_request("A")handler_a.handle_request("B")handler_a.handle_request("C")(2) 责任链模式的应用场景
责任链模式适用于以下场景:
- 多个对象可以处理同一个请求,但具体由哪个对象处理是在运行时动态决定的。
- 需要将请求的发送者和接收者解耦,使得多个对象都有机会处理请求。
(3) 责任链模式的优点
- 责任链模式将请求的发送者和接收者解耦,使得它们可以独立地变化。
- 责任链模式遵循开闭原则,新的处理对象可以很容易地添加到系统中,而不会影响到原有的代码。
(4) 责任链模式的缺点
- 责任链模式中,请求可能会在责任链上被多次处理,可能会导致性能问题。