摘要
论文链接:https://arxiv.org/pdf/1911.07559v2
在这篇论文中,我们提出了一种端到端的特征融合注意力网络(FFA-Net)来直接恢复无雾图像。FFA-Net架构由三个关键组件组成:
-
一种新颖的特征注意力(FA)模块结合了通道注意力与像素注意力机制,考虑到不同通道特征包含完全不同的加权信息,且雾在图像的不同像素上分布不均匀。FA模块对不同的特征和像素进行非等权重处理,这在处理不同类型的信息时提供了额外的灵活性,扩展了卷积神经网络(CNNs)的表示能力。
-
一个基本块结构由局部残差学习和特征注意力组成,局部残差学习允许如薄雾区域或低频等不太重要的信息通过多个局部残差连接被绕过,从而让主要网络架构专注于更有效的信息。
-
一种基于注意力的不同层级特征融合(FFA)结构,特征权重从特征注意力(FA)模块中自适应地学习,给予重要特征更多的权重。这种结构还可以保留浅层层的信息并将其传递到深层层。
实验结果表明,我们提出的FFANet在定量和定性方面均大幅超越了先前最先进的单图像去雾方法,将SOTS室内测试数据集上已发布的最佳PSNR指标从 30.23 d B 30.23\ \mathrm{dB} 30.23 dB提升至 36.39 d B 36.39\ \mathrm{dB} 36.39 dB。代码已在GitHub上公开可用。
Introduction
作为计算机视觉和人工智能公司关注的基础低级视觉任务,单图像去雾在过去的几十年里吸引了越来越多的关注。

由于大气中存在烟雾、灰尘、烟雾、薄雾和其他悬浮颗粒,在这种大气中拍摄的图像经常会受到颜色失真、模糊、对比度低和其他可见质量下降的影响,并且输入的雾状图像会使得其他视觉任务(如分类、跟踪、人员再识别和对象检测)变得困难。鉴于这种情况,图像去雾旨在从受损的输入中恢复出清晰的图像,这将是高级视觉任务的预处理步骤。大气散射模型(Cartney 1976)(Narasimhan 和 Nayar 2000)(Narasimhan 和 Nayar 2002)为雾效提供了一个简单的近似,其公式如下:
I ( z ) = J ( z ) t ( z ) + A ( 1 − t ( z ) ) \boldsymbol{I}(z) = \boldsymbol{J}(z) t(z) + \boldsymbol{A}(1-t(z)) I(z)=J(z)t(z)+A(1−t(z))
其中, I ( z ) \boldsymbol{I}(z) I(z) 是观察到的雾状图像, A \boldsymbol{A} A 是全局大气光, t ( z ) t(z) t(z) 是介质透射图, J ( z ) \boldsymbol{J}(z) J(z) 是无雾图像。此外,我们有 t ( z ) = e − β d ( z ) t(z) = e^{-\beta d(z)} t(z)=e−βd(z),其中 β \beta β 和 d ( z ) d(z) d(z) 分别是大气散射参数和场景深度。大气散射模型表明,在不知道 A \boldsymbol{A} A 和 t ( z ) t(z) t(z) 的情况下,图像去雾是一个不确定问题。公式(1)也可以表示为:
J ( z ) = ( I ( z ) − A ) t ( z ) + A \boldsymbol{J}(z) = \frac{(I(z) - \boldsymbol{A})}{t(z)} + A J(z)=t(z)(I(z)−A)+A
从公式(1)和(2)中,我们可以注意到,如果我们为捕获的雾状图像正确估计了全局大气光和透射图,我们就可以恢复出一个清晰的无雾图像。
基于大气散射模型,早期的去雾方法做了一系列的工作(Berman, Avidan等人 2016)(Fattal 2014)(He, Sun, Tang 2010)(Jiang等人 2017)(Ju, Gu, Zhang 2017)(Meng等人 2013)(Zhu, Mai, Shao 2015)。DCP是其中基于先验的杰出方法之一,他们提出了暗通道先验,该先验基于室外无雾图像的图像块在至少一个通道中经常具有低强度值的假设。然而,基于先验的方法可能会因为先验在实际中容易被违背而导致透射图估计不准确,所以在某些实际情况下基于先验的方法可能效果不佳。
随着深度学习的兴起,许多神经网络方法也被提出来估计雾霾效应,包括DehazeNet(Cai等人 2016)的开创性工作,多尺度CNN(MSCNN)(Ren等人 2016),残差学习技术(He等人 2016),四叉树CNN(Kim, Ha, Kwon 2018),以及密集连接的金字塔去雾网络(Zhang和Patel 2018)。与传统的方法相比,深度学习方法试图直接回归中间透射图或最终的无雾图像。随着大数据的应用,它们取得了出色的性能和鲁棒性。
在本文中,我们提出了一种新颖的单图像去雾端到端特征融合网络(表示为FFA-Net)。
以往的基于卷积神经网络(CNN)的图像去雾网络将通道级和像素级的特征视为等同,但雾霾在图像中的分布是不均匀的,非常薄的雾霾区域的权重应该与厚雾霾区域像素的权重有显著差异。此外,DCP(暗通道先验)也发现,在一些像素中,至少在一个颜色(RGB)通道中的强度非常低,这进一步说明了不同通道特征具有完全不同的加权信息。如果我们平等对待它们,将会在不那么重要的信息上花费大量资源进行不必要的计算,网络将缺乏覆盖所有像素和通道的能力。最终,这会极大地限制网络的表示能力。
由于注意力机制(Xu et al. 2015)(Vaswani et al. 2017)(Wang et al. 2018)在神经网络设计中得到了广泛应用,并在网络性能中发挥了重要作用。受到(Zhang et al. 2018)工作的启发,我们进一步设计了一个新颖的特征注意力(FA)模块。FA模块分别在通道级和像素级特征中结合了通道注意力和像素注意力。FA模块以不同的方式处理不同的特征和像素,这可以为处理不同类型的信息提供额外的灵活性。
ResNet(He et al. 2016)的出现使得训练非常深的网络成为可能。我们采用了跳跃连接和注意力机制的思想,并设计了一个基本块,该基本块由多个局部残差学习跳跃连接和特征注意力组成。一方面,局部残差学习允许薄雾霾区域和低频信息通过多个局部残差学习被绕过,使主网络学习更有用的信息。并且,通道注意力进一步提高了FFA-Net的能力。
随着网络层数的加深,浅层特征信息往往难以保留。为了识别和融合不同层级的特征,U-Net(Ronneberger、Fischer和Brox 2015)等网络努力整合浅层和深层信息。类似地,我们提出了一种基于注意力的特征融合结构(FFA),这种结构能够保留浅层信息并将其传递到深层。最重要的是,FFA-Net在将所有特征送入特征融合模块之前,会给不同层级的特征分配不同的权重,这些权重是通过FA模块的自适应学习获得的。这比直接指定权重要好得多。
为了评估不同图像去雾网络的性能,峰值信噪比(PSNR)和结构相似性指数(SSIM)常被用来量化去雾图像的恢复质量。对于人的主观评估,我们还提供了大量从损坏输入中产生的网络输出。我们在广泛使用的去雾基准数据集RESIDE(Li et al. 2018)上验证了FFA-Net的有效性。我们将PSNR和SSIM指标与以前的最先进方法进行了比较。实验表明,FFA-Net在定性和定量上都大幅超越了所有先前的方法。此外,我们进行了许多消融实验来证明FFA-Net的关键组件具有出色的性能。
总的来说,我们的贡献如下:
- 我们提出了一种新颖的单图像去雾端到端特征融合注意力网络FFA-Net。FFA-Net在性能上大幅超越了之前的图像去雾最先进方法,尤其在厚雾区域和纹理细节丰富的区域表现尤为出色。在图像细节和颜色保真度的恢复方面,我们也具有显著的优势,如图1和图8所示。
- 我们提出了一种新颖的特征注意力(FA)模块,该模块结合了通道注意力和像素注意力机制。这个模块在处理不同类型的信息时提供了额外的灵活性,能够更多地关注厚雾像素和更重要的通道信息。
- 我们提出了一种由局部残差学习和特征注意力(FA)组成的基本块。局部残差学习允许薄雾区域和低频信息通过多个跳跃连接被绕过,而特征注意力(FA)则进一步提升了FFA-Net的能力。
- 我们提出了一种基于注意力的特征融合(FFA)结构,该结构能够保留浅层信息并将其传递到深层。此外,它不仅能够融合所有特征,还能够自适应地学习不同层级特征信息的不同权重。最终,它在性能上比其他特征融合方法要好得多。
相关工作
之前,大多数现有的图像去雾方法都依赖于物理散射模型方程的构建,这是一个高度不适定问题,因为传输图和全局大气光是未知的。这些方法大致可以分为两类:基于传统先验的方法和基于现代学习的方法。无论使用哪种方法,关键是求解传输图和大气光。对于传统方法,它们基于不同的图像统计先验,将其用作额外的约束来补偿在腐蚀过程中损失的信息。
DCP(He, Sun, 和 Tang 2010)提出了一个暗通道先验来估计传输图。然而,当场景对象与大气光相似时,这些先验被发现是不可靠的。(Zhu, Mai, 和 Shao 2015)通过为雾霾图像的场景深度创建线性模型,提出了一个简单但强大的颜色衰减先验。(Fattal 2008)提出了一种新的方法来估计雾霾场景中的光学传输,通过消除散射光来增加场景的可见性并恢复无雾场景的对比度。(Berman, Avidan, 等人 2016)提出了一个非局部先验来表征清晰图像,该算法依赖于无雾图像的颜色可以通过几百种不同颜色很好地近似,这些颜色在RGB空间中形成紧密的簇。尽管这些方法已经取得了一系列成功,但这些先验并不鲁棒,无法处理所有情况,如野外无约束的环境。
鉴于深度学习在图像处理任务中的普遍成功以及大型图像数据集的可用性,(Cai et al. 2016)提出了一种基于卷积神经网络的端到端去雾模型DehazeNet,它以雾霾图像为输入,输出其介质传输图,然后通过大气散射模型恢复无雾图像。(Ren et al. 2016)采用了一种多尺度MSCNN,能够从雾霾图像中生成精细的传输图。(Yang and Sun 2018)通过将雾霾相关的先验学习融入到深度网络中,结合了传统基于先验的去雾方法和深度学习方法的优势。(Li et al. 2017)提出的AOD-Net通过轻量级CNN直接生成清晰图像。这种新颖的端到端设计使得AOD-Net易于嵌入到其他深度模型中。门控融合网络(GFN)(Ren et al. 2018)利用手动选择的预处理方法和多尺度估计,这些方法本质上是通用的,有待进一步改进。(Chen et al. 2019)提出了一种端到端的门控上下文聚合网络,用于直接恢复最终的无雾图像,该网络采用了最新的平滑扩张技术,有助于去除广泛使用的扩张卷积引起的网格伪影,同时几乎不需要额外的参数。EPDN(Qu et al. 2019)则嵌入了一个生成对抗网络,后跟一个精心设计的增强器,不依赖于物理散射模型。
特征融合注意力网络(FFA-Net)
在本节中,我们主要介绍我们的特征融合注意力网络FFA-Net。如图2所示,FFA-Net的输入是一张雾霾图像,它首先通过一个浅层特征提取部分,然后输入到具有多个跳跃连接的N个组架构中。N个组架构的输出特征通过我们提出的特征注意力模块进行融合,之后这些特征将被传递到重建部分和全局残差学习结构中,最终得到无雾的输出图像。
此外,每个组架构结合了B个基本块架构和局部残差学习,每个基本块结合了跳跃连接和特征注意力(FA)模块。FA是一个注意力机制结构,由通道注意力(Channel-wise Attention)和像素注意力(Pixel-wise Attention)组成。
特征注意力(FA)
大多数图像去雾网络对通道级和像素级特征都一视同仁,这无法妥善处理雾霾分布不均和加权通道级特征的问题。我们的特征注意力(如图3所示)由通道注意力和像素注意力组成,这为处理不同类型的信息提供了额外的灵活性。
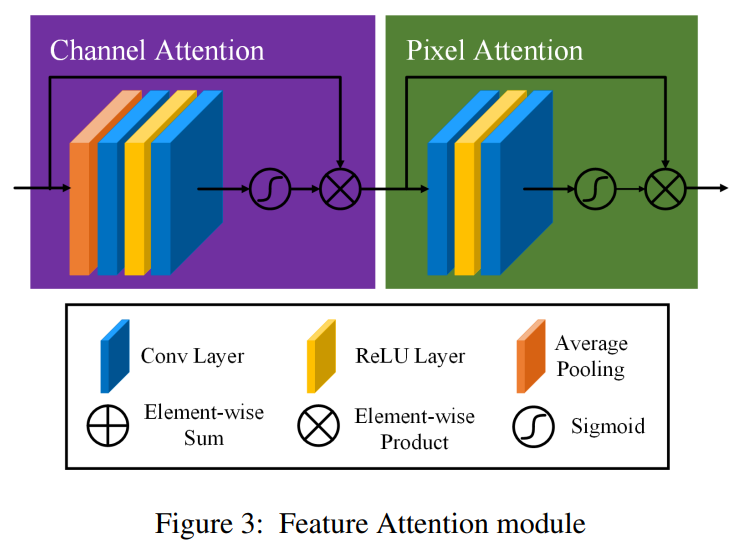
FA对不同的特征和像素区域给予不同的重视,这增加了处理不同类型信息的灵活性,并且可以扩展卷积神经网络的表示能力。关键步骤是如何为每个通道级和像素级特征生成不同的权重。我们的解决方案如下。
通道注意力(CA)
我们的通道注意力主要关注不同通道特征相对于暗通道先验(DCP,由He, Sun, and Tang在2010年提出)具有完全不同的加权信息。首先,我们通过全局平均池化将通道级的全局空间信息纳入通道描述符中。
g c = H p ( F c ) = 1 H × W ∑ i = 1 H ∑ j = 1 W X c ( i , j ) g_{c} = H_{p}(F_{c}) = \frac{1}{H \times W} \sum_{i=1}^{H} \sum_{j=1}^{W} X_{c}(i, j) gc=Hp(Fc)=H×W1∑i=1H∑j=1WXc(i,j)
其中, X c ( i , j ) X_{c}(i, j) Xc(i,j)表示第 c c c个通道 X c X_{c} Xc在位置 ( i , j ) (i, j) (i,j)的值, H p H_{p} Hp是全局池化函数。特征图的形状从 C × H × W C \times H \times W C×H×W变为 C × 1 × 1 C \times 1 \times 1 C×1×1。为了得到不同通道的权重,特征图通过两个卷积层和sigmoid、ReLU激活函数。
C A c = σ ( Conv ( δ ( Conv ( g c ) ) ) ) C A_{c} = \sigma(\text{Conv}(\delta(\text{Conv}(g_{c})))) CAc=σ(Conv(δ(Conv(gc))))
其中, σ \sigma σ是sigmoid函数, δ \delta δ是ReLU函数。
最后,我们将输入 F c F_{c} Fc 与通道权重 C A c C A_{c} CAc 进行逐元素相乘。
F c ∗ = C A c ⊗ F c F_{c}^{*} = C A_{c} \otimes F_{c} Fc∗=CAc⊗Fc
像素注意力(PA)
考虑到雾霾在图像不同像素上的分布是不均匀的,我们提出了一个像素注意力(PA)模块,让网络更加关注信息丰富的特征,如雾霾浓厚的像素和高频图像区域。
与CA类似,我们直接将CA的输出 F ∗ F^{*} F∗ 输入到带有ReLU和sigmoid激活函数的两个卷积层中。特征图的形状从 C × H × W C \times H \times W C×H×W 变为 1 × H × W 1 \times H \times W 1×H×W。
P A = σ ( Conv ( δ ( Conv ( F ∗ ) ) ) ) P A = \sigma\left(\text{Conv}\left(\delta\left(\text{Conv}\left(F^{*}\right)\right)\right)\right) PA=σ(Conv(δ(Conv(F∗))))
最后,我们将 F ∗ F^{*} F∗ 和 P A P A PA 进行逐元素相乘, F ~ \tilde{F} F~ 是特征注意力(FA)模块的输出。
F ~ = F ∗ ⊗ P A \tilde{F} = F^{*} \otimes P A F~=F∗⊗PA
为了直观地展示特征注意力(FA)机制的有效性,我们打印了组结构输出的通道级和像素级特征权重图。我们可以清楚地看到,不同的特征图以不同的权重自适应地学习。图4显示,雾霾浓厚的图像像素区域以及物体的边缘和纹理具有更大的权重。像素注意力(PA)机制使FFA-Net更加关注高频和雾霾浓厚的像素区域。图5展示了一个 3 × 64 3 \times 64 3×64 大小的图表,三行分别对应三个组架构在通道方向上输出的特征图权重,说明不同的特征自适应地学习了完全不同的权重。

基础块结构
如图6所示,基础块结构由局部残差学习和特征注意力(FA)模块组成。局部残差学习允许通过多个局部残差连接绕过不太重要的信息(如薄雾或低频区域),使主网络专注于有效信息。
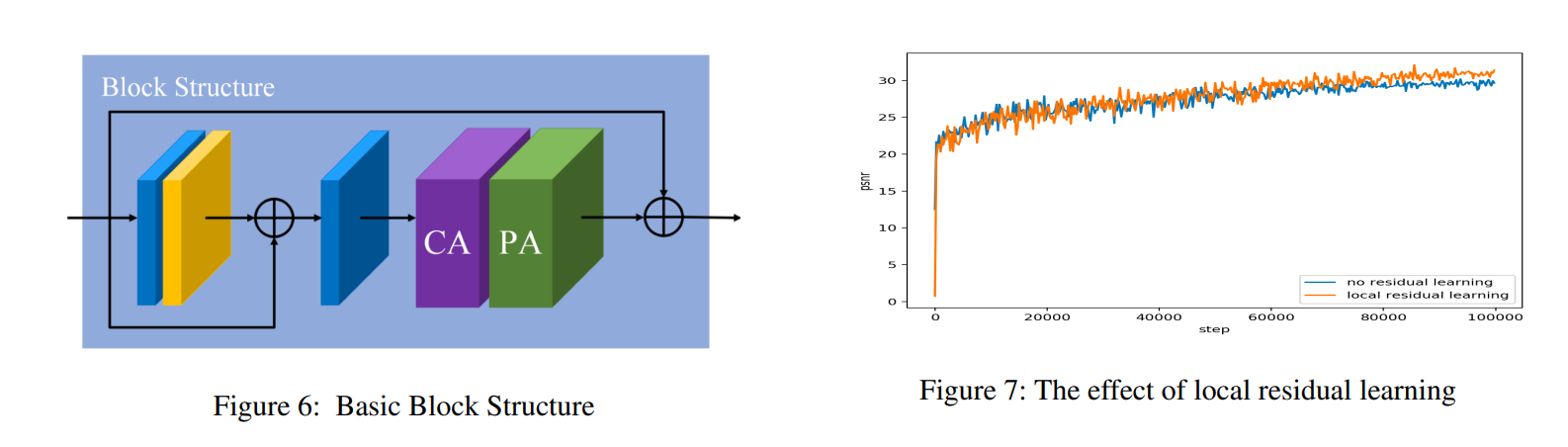
实验结果表明,这种结构可以进一步提高网络性能和训练稳定性。局部残差学习的效果可以在图7中看到,具体细节可以在消融研究部分查看。
组架构和全局残差学习
我们的组架构结合了B个基础块结构和跳跃连接模块。连续的B个块增加了FFA-Net的深度和表达能力。而跳跃连接使得FFA-Net能够绕过训练困难。在FFA-Net的末尾,我们使用一个两层的卷积网络实现和一个长捷径全局残差学习模块来添加一个恢复部分。最后,我们恢复了所需的去雾图像。
特征融合注意力
如上所述,首先,我们在通道方向上拼接G个组架构输出的所有特征图。进一步地,我们通过特征注意力(FA)机制获得的自适应学习权重来融合这些特征。通过这种方式,我们可以保留低层信息并将其传递到深层,使FFA-Net更加关注有效信息,如浓雾区域、高频纹理和颜色保真度,这得益于权重机制。
损失函数
均方误差(MSE)或L2损失是单一图像去雾任务中最广泛使用的损失函数。然而,(Lim et al. 2017)指出,在许多图像恢复任务中,使用L1损失进行训练在PSNR和SSIM指标上比L2损失取得了更好的性能。遵循相同的策略,我们默认采用简单的L1损失。尽管许多去雾算法也使用感知损失和GAN损失,但我们选择优化L1损失。
L ( Θ ) = 1 N ∑ i = 1 N ∥ I g t i − F F A ( I haze i ) ∥ L(\Theta)=\frac{1}{N} \sum_{i=1}^{N}\left\|I_{g t}^{i}-FFA\left(I_{\text{haze}}^{i}\right)\right\| L(Θ)=N1∑i=1N Igti−FFA(Ihazei)
其中, Θ \Theta Θ 表示FFA-Net的参数, I g t I_{g t} Igt 表示真实值(ground truth), I haze I_{\text{haze}} Ihaze 表示输入图像。
实现细节
在本节中,我们将详细说明我们提出的FFA-Net的实现细节。组结构(Group Structure)的数量G设置为3。在每个组结构中,我们将基本块结构(Basic Block Structure)的数量B设置为19。除了通道注意力(Channel Attention)模块的卷积核大小为1x1之外,我们设置所有卷积层的滤波器大小为3x3。除了通道注意力模块之外,所有特征图的尺寸都保持不变。每个组结构输出64个滤波器。
实验
数据集和指标
(Li et al. 2018)提出了一个名为RESIDE的图像去雾基准,它包含了从深度数据集(NYU Depth V2,由Silberman et al. 2012提出)和立体数据集(Middlebury Stereo datasets,由Scharstein和Szeliski 2003提出)中生成的室内和室外场景下的合成有雾图像。RESIDE的室内训练集包含1399张清晰图像和由相应清晰图像生成的13990张有雾图像。全局大气光的范围从0.8到1.0,散射参数的变化范围为0.04到0.2。为了与之前的最先进方法进行比较,我们采用了PSNR和SSIM指标,并在合成目标测试集(SOTS)中进行了综合比较测试,该测试集包含500张室内图像和500张室外图像。我们还在真实有雾图像上进行了主观评估测试。
训练设置
我们在RGB通道上训练FFA-Net,并通过随机旋转90、180、270度和水平翻转来增强训练数据集。从大小为 240 × 240 240 \times 240 240×240的有雾图像块中提取两个作为FFA-Net的输入。整个网络在室内和室外图像上分别训练了 5 × 1 0 5 5 \times 10^{5} 5×105和 1 × 1 0 6 1 \times 10^{6} 1×106步。我们使用Adam优化器,其中 β 1 \beta 1 β1和 β 2 \beta 2 β2分别取默认值0.9和0.999。
初始学习率设置为 1 × 1 0 − 4 1 \times 10^{-4} 1×10−4,我们采用余弦退火策略(He et al. 2019)来通过余弦函数从初始值调整学习率到0。假设总批次数为 T T T, η \eta η是初始学习率,那么在批次 t t t时,学习率 η t \eta_{t} ηt计算为:
η t = 1 2 ( 1 + cos ( t π T ) ) η \eta_{t}=\frac{1}{2}\left(1+\cos \left(\frac{t \pi}{T}\right)\right) \eta ηt=21(1+cos(Ttπ))η
我们使用PyTorch(Paszke et al. 2017)在RTX 2080Ti GPU上实现了我们的模型。
RESIDE数据集上的结果
在本节中,我们将从定量和定性两个方面将FFA-Net与之前的先进图像去雾算法进行比较。
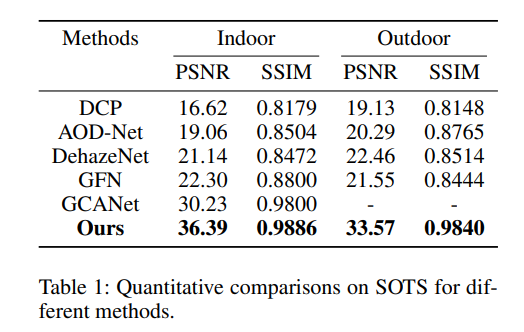
我们与四种不同的先进去雾算法进行了比较,分别是DCP、AOD-Net、DehazeNet和GCANet。比较结果如表1所示。


为了方便起见,我们引用的PSNR和SSIM指标来自(Li et al. 2018)和(Qu et al. 2019)。可以看出,我们提出的FFA-Net在PSNR和SSIM方面大幅超越了所有四种不同的先进方法。此外,我们在图8中给出了视觉效果的比较以进行定性评估。
从室内和室外的结果来看,前三行是室内结果,后三行是室外结果。我们可以观察到DCP由于其潜在的先验假设而遭受严重的颜色失真,因此它丢失了图像的深度细节。AOD-Net无法完全去除雾气,并且倾向于输出低亮度的图像。相比之下,DehazeNet恢复的图像相对于真实情况来说亮度过高。GCANet在处理高频细节信息(如纹理、边缘和第五行中的蓝天)时的表现总是不尽如人意。
对于真实有雾图像的结果,我们的网络能够神奇地发现第一行图像深处隐约可见的塔。更重要的是,我们网络的结果几乎完全符合真实场景的信息,如第二行中带有纹理的湿路和雨滴。然而,我们发现第二行GCANet结果中的建筑物表面存在不存在的斑点。从其他网络恢复的图像并不令人满意。我们的网络在图像细节的现实表现和颜色保真度方面显然更加优越。
消融分析
为了进一步证明FFA-Net架构的优越性,我们通过考虑FFA-Net中不同的模块进行了消融研究。我们主要关注以下因素:1) FA(特征注意力)模块;2) 局部残差学习(LRL)与FA的结合;3) 特征融合注意力(FFA)结构。我们将图像裁剪为 48 × 48 48 \times 48 48×48作为输入,训练了 3 × 1 0 5 3 \times 10^{5} 3×105步,其他配置与我们的实现细节相同。结果如表2所示。

如果我们完全按照论文中的实现细节进行训练,则PSNR将达到 35.77 d B 35.77 \mathrm{dB} 35.77dB。结果表明,我们考虑的每个因素都在网络性能中起着重要作用,尤其是FFA结构。我们也可以清楚地看到,即使我们仅使用FA结构,我们的网络也能与先前的最先进方法相媲美。LRL在提高网络性能的同时使网络训练更加稳定。FA机制和特征融合(FFA)的结合将我们的结果提升到了非常高的水平。
结论
在本文中,我们提出了一种端到端的特征融合注意力网络(FFA-Net),并展示了它在单图像去雾方面的强大能力。尽管我们的FFA-Net结构很简单,但它大幅超越了先前的最先进方法。我们的网络在图像细节和颜色保真度的恢复方面具有强大的优势,有望解决其他低级视觉任务,如去雨、超分辨率、去噪。FFA-Net中的FFA和其他有效模块在图像恢复算法中发挥着重要作用。
致谢。本工作部分得到了中国国家重点研发计划(合同号:2016YFB0402001)的支持。










![[沫忘录]MySQL InnoDB引擎](https://img-blog.csdnimg.cn/direct/49e28021b6574e41ac7ccb41a35a6ff1.png)