什么是Spark RDD?(RDD的介绍与创建)
- 一、RDD介绍
- 1、特点
- 2、RDD的存储和指向
- 3、RDD与DAG
- 4、RDD的特性
- 5、RDD分区
- 6、RDD操作类型
- 二、RDD创建
- 1、引入必要的 Spark 库
- 2、配置 Spark
- 3、RDD创建
- 4、示例代码
一、RDD介绍
RDD: 弹性分布式数据集(Resilient Distributed Datasets)
核心概念:Spark的核心数据抽象。
通过对RDD的理解和使用,可以在分布式计算环境中高效地处理和计算大规模数据
1、特点
- 分布式数据集:RDD是只读的、分区记录的集合,每个分区分布在集群的不同节点上。RDD并不存储真正的数据,只是对数据和操作的描述。
- 弹性:默认存放在内存中,当内存不足,Spark自动将RDD写入磁盘。
- 容错性:根据数据血统,可以自动从节点失败中恢复分区。
2、RDD的存储和指向
- 存储在 (HIVE)HDFS、Cassandra、HBase等
- 缓存(内存、内存+磁盘、仅磁盘等)
- 或在故障或缓存收回时重新计算其他RDD分区中的数据
3、RDD与DAG
-
DAG(有向无环图):反映了RDD之间的依赖关系。
-
Stage:RDD和DAG是Spark提供的核心抽象,RDD的操作会生成DAG,DAG会进一步被划分为多个Stage,每个Stage包含多个Task。
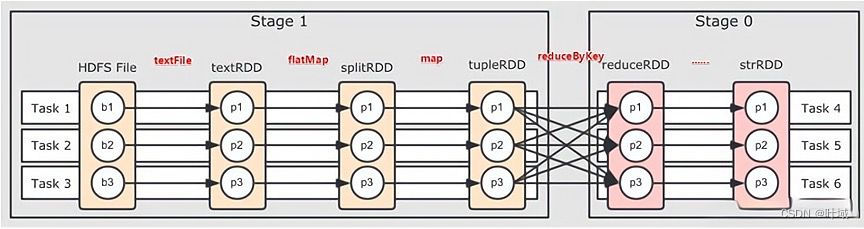
4、RDD的特性
- 分区(Partition):每个任务处理一个分区。
- 计算函数(compute):每个分区上都有compute函数,计算该分区中的数据。
- 依赖关系:RDD之间有一系列的依赖。
- 分区器(Partitioner)
- 决定数据(key-value)分配至哪个分区。
- 常见的分区器有Hash Partition和Range Partition。
- 优先位置列表:将计算任务分派到其所在处理数据块的存储位置。
5、RDD分区
- 分区(Partition):是RDD被拆分并发送到节点的不同块之一。
- 分区越多,并行性越强:我们拥有的分区越多,得到的并行性就越强。
- 每个分区都是被分发到不同Worker Node的候选者。
- 每个分区对应一个Task。
6、RDD操作类型
- Transformation(转换操作)
- Lazy操作:不会立即执行,只是记录操作,当触发Action时才会真正执行。
- 例如:map、filter、flatMap等。
- Actions(动作操作)
- Non-lazy操作:立即执行,会触发所有相关Transformation的计算。
- 例如:count、collect、saveAsTextFile等。
二、RDD创建
1、引入必要的 Spark 库
这里用的是scala语言的maven项目
<!-- 导入 spark-core jar 包 -->
<dependency><groupId>org.apache.spark</groupId><artifactId>spark-core_2.12</artifactId><version>3.1.2</version>
</dependency>
// 引入 Spark 库
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.rdd.RDD
2、配置 Spark
setMaster (设置运行模式) 方法的可选方案:
local: 在单核上运行local[N]: 在指定数量的 N 个核上运行,如 “local[4]”local[*]: 使用所有可用的核spark://HOST:PORT: 连接到指定的 Spark standalone clusteryarn: 连接到 YARN 集群mesos://HOST:PORT: 连接到 Mesos 集群
val conf = new SparkConf().setAppName("Spark RDD Example")// 设置应用程序名称.setMaster("local[*]") // 设置运行模式
val sc = new SparkContext(conf)
// sc.setLogLevel() // 设置日志显示级别
3、RDD创建
-
从集合创建 RDD,指定分区数
val rdd: RDD[T] = sc.parallelize(seq: Seq[T], numSlices: Int) // ✔ val rdd: RDD[T] = sc.makeRDD(seq: Seq[T], numSlices: Int) // 调用了 parallelize -
从外部数据源创建 RDD,指定最小分区数
从文件系统中的单个文件创建 RDD
- 本地文件系统使用
file:///前缀 - Hadoop 文件系统使用
hdfs://前缀
// 从文件系统创建 RDD,可以通过 minPartitions 指定分区数 val textRDD: RDD[String] = sc.textFile(filePath, minPartitions:Int) // 从文件系统创建 RDD val rdd: RDD[(String, String)] = sc.wholeTextFiles(dir: String, minPartitions: Int) // 从目录创建 RDD - 本地文件系统使用
4、示例代码
附加单词次数统计
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.rdd.RDD
object SparkRDDExample {def main(args: Array[String]): Unit = {// 配置 Spark val conf = new SparkConf().setAppName("Spark RDD Example").setMaster("local[*]")val sc = new SparkContext(conf)// 从集合创建 RDD,指定分区数val data = Seq(1, 2, 3, 4, 5)val rdd: RDD[Int] = sc.parallelize(data, numSlices = 2)rdd.collect().foreach(println)// 从外部数据源创建 RDD,指定最小分区数val filePath = "file:///F:\\sparkRDD\\spark01\\data\\story.txt"val textRDD: RDD[String] = sc.textFile(filePath, minPartitions = 4)textRDD.collect().foreach(println)// 将文本文件中的每行数据拆分为单词并统计每个单词的出现次数val wordCountRDD = textRDD.mapPartitions {_.flatMap {_.split("[^a-zA-Z]+") // 按非字母字符拆分字符串.map(word => (word, 1)) // 将每个单词转换为 (单词, 1) 的元组}}.reduceByKey(_+_)// 显示单词计数结果println("Word count from textFile:")wordCountRDD.collect().foreach(println)// 停止 SparkContextsc.stop()}
}