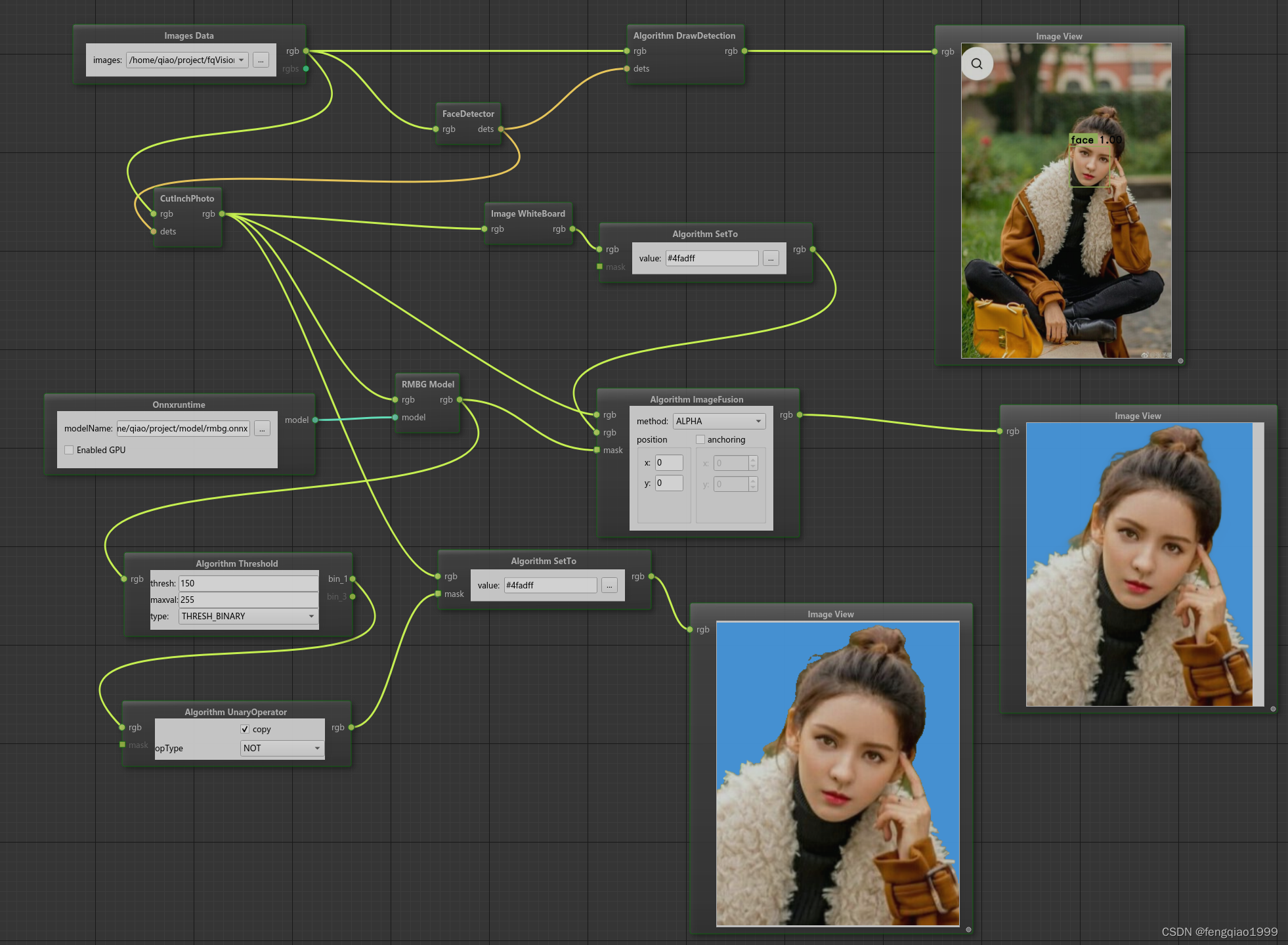
【面试干货】SQL中count(*)、count(1)和count(column)的区别与用法
- 1、count(*)
- 2、count(1)
- 3、count(column)
| 💖The Begin💖点点关注,收藏不迷路💖 |
在SQL中,count()函数被广泛用于统计行数或某列中非NULL值的数量。然而,对于count(*)、count(1)和count(column)这几种不同的使用方式,很多开发者可能存在一些困惑。本篇博客将深入探讨这三种用法之间的区别及各自的适用场景。

1、count(*)
首先,我们来看一下count()这种用法。count()会统计查询结果集中的行数,包括所有行,即使某些列的值为NULL也会计算在内。这种写法通常用于计算表中的总行数,因为它会忽略任何列中的NULL值,只关注行数。
例如:
SELECT COUNT(*) FROM table_name;
2、count(1)
接下来是count(1)这种写法,其实质和count(*)是一样的。count(1)会统计查询结果集中的行数,同样包括所有行,不受NULL值的影响。这种用法更像是在告诉数据库“只要计算行数就好,不需要关注具体的列值”。
例如:
SELECT COUNT(1) FROM table_name;
3、count(column)
最后是count(column),这种写法则是针对某特定列进行计数。它会统计指定列中非NULL值的数量,忽略NULL值所在的行。 这种用法适用于需要统计某列中有效数值的情况。
例如:
SELECT COUNT(column_name) FROM table_name;
通过上述例子,我们可以看出count(*)、count(1)和count(column)这三种用法的区别和适用场景。
在实际的SQL查询中,根据具体需求选择合适的count()用法可以更有效地对数据进行统计和分析。

| 💖The End💖点点关注,收藏不迷路💖 |